基于Hadoop平台的数据迁移方法研究实现
2018-04-25 07:47:59,,,
计算机测量与控制 2018年4期
, , ,
(湖北大学 计算机与信息工程学院,武汉 430062)
0 引言
随着计算机与信息技术的迅速发展,企业应用系统的规模迅速扩大,所产生的数据呈海量型变化。大数据(Big Data)一词越来越多地被提及,人们就用它来描述和定义信息爆炸时代产生的海量数据,并命名与之相关的技术发展与创新[1]。在大数据时代,企业应用系统数据量快速增长已达到PB(1PB=1000TB)甚至EB(1EB=1000PB)级别,而大多数企业应用系统之前所使用的数据库都是传统关系型数据库[2],实际上关系型数据库已经无法满足当前海量数据处理的高扩展性、高可用性、高并发读写、高吞吐量、较低延迟及高效存储和查询等需求。与关系型数据库不同,NoSQL数据库[3]由于其扩展性和可用性强以及灵活的数据模型,在大数据时代得到广泛应用。
Hadoop生态系统中的HBase数据库是一个开源的基于列的非关系型分布式数据库,是Apache软件基金会的Hadoop项目的一部分,不仅拥有大部分NoSQL数据库所拥有的特点,而且因为能与Hadoop大数据平台进行集成,所以它能在数据存储方面提供更为强大的扩展性和在数据操作方面提供更为完善的操作性能[4]。基于HBase的巨大优势,如今企业的应用系统都开始将HBase数据库作为进行大数据的存储和处理的工具。但是,在实际需求的限制下,企业应用系统在更改存储系统时不应该丢失原有系统中的历史数据,而是需要将原有系统中的历史数据迁移到新构建的存储系统中,所以如何将原有应用系统中的历史数据尽量完整、有策略、自动迁移到新构建的HBase数据库中是一个值得研究的课题。
HBase本身是一种NoSQL数据库,由于其数据存储结构与传统关系型数据库的数据结构有很大的差异,因此在设计数据存储表结构及表关系时也有很大的不同,所以要实现从关系型数据库向分布式数据库HBase进行数据迁移,需要重新设计新构建的存储系统HBase的表模式,这个过程是个比较复杂的过程,在完成数据迁移过程后还需要考虑数据迁移后数据查询及存储的性能问题,因此实现一个从关系型数据库向分布式数据库HBase进行数据迁移的方法是非常有必要的。
本文在上述背景及需求下,通过对Hadoop大数据平台、HBase数据库存储原理及典型数据库迁移策略的研究,设计基于Hadoop平台数据迁移方法来实现将传统关系型数据库中的历史数据以及表模式向HBase数据库中进行迁移和转换,有效解决之前同类迁移工具无法对关系型数据库中表模式进行迁移不足的问题。
本文组织结构如下:第1部分简述相关理论基础;第2部分介绍数据迁移方法的设计思想及具体实现;第3部分对数据迁移方法实现后的查询与存储等方面与同类迁移工具进行比较;第4部分总结全文。
1 相关理论
1.1 Hadoop平台
Hadoop[5]是一个由Apache基金会根据Google公司发表的Google文件系统(GFS)和MapReduce的论文自行实现而成的分布式系统架构。使用者可以在不了解底层细节的情况下,开发分布式程序,充分利用集群的作用进行高速运算和存储。Hadoop框架最核心的设计就是由HDFS(Hadoop Distributed File System:分布式文件系统)和MapReduce(分布式计算框架)组成。
HDFS[6]在Hadoop系统中为海量数据提供了存储,为了高数据吞吐量而优化的,适合那些有超大数据集的应用程序,有高容错性、低成本的特点。一般情况下,HDFS集群主要由一个NameNode节点(master)和多个DataNode节点(slave)组成,在集群节点通信中,NameNode发挥着管理、协调、操控的作用,主要负责管理文件系统的命名空间,协助客户端对文件的访问,并对DataNode发起的请求进行响应;而DataNode是HDFS中最终存储数据的节点,负责自身及其他物理节点的存储管理。客户端向HDFS发起访问文件请求时,首先需要从NameNode节点上获取文件在HDFS中所处的位置信息,根据文件位置信息找到存储数据块所在的DataNode,最后读取DataNode上存储的数据。
MapReduce[7]是为海量数据提供了计算。它是面向大数据并行处理的计算模型、框架和平台。在一个MapReduce计算任务过程中,主要有两个阶段:Map(映射)阶段和Reduce(归约)阶段,每个阶段都是以键值对作为输入和输出,Map阶段负责对输入文件进行切分处理,然后汇总再分组给Reduce进行处理,达到高效的分布式计算效率。
1.2 HBase存储原理
HBase[8]是Apache Hadoop中的一个子项目,是Google BigTable的开源实现,依托于Hadoop的HDFS作为最基本存储基础单元,通过使用Hadoop的DFS工具就可以看到这些数据存储文件夹的结构,还可以通过Map/Reduce的框架对HBase进行操作。
HBase是一个分布式、面向列的数据存储系统,与关系型数据库的模式固定,面向行的数据库具有ACID性质不同,HBase是一个适合于非结构化数据存储的数据库,是介于Map Entry(key&value)和DB Row之间的一种数据存储方式。HBase中的数据是依靠行健(RowKey)、列族(ColumnFamily)、列标识(ColumnQualifier)、时间戳(TimeStamp)来标识一个单元格中的数据。表1是HBase的简单逻辑视图。
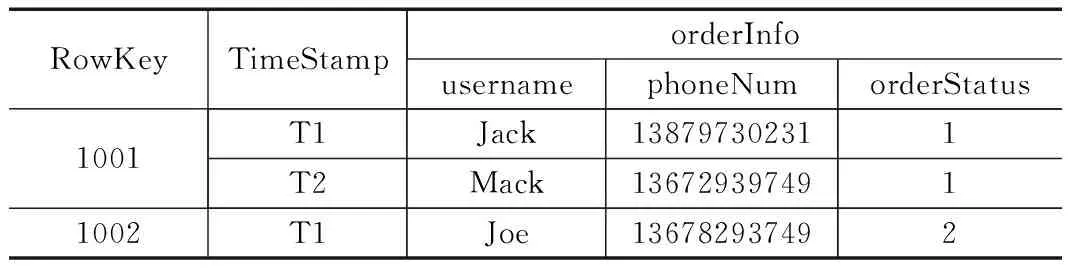
表1 HBase逻辑视图
表1表示的是在HBase数据库中保存的两条订单信息1001和1002,其中1001和1002是表示行键,orderInfo是列族,在orderInfo列族中包含有username、phoneNum、orderStatus列标识。如要获取某一单元格中的订单信息,则可使用{RowKey,column(=
RowKey{
ColumnFamily1{
Column1:
T2:value2
T1:value1
Column2:
T1:value3
}
ColumnFamily2{
T3:value4
}
}
由表1和HBase数据模型的JSON格式的一般形式可以看出HBase与RDBMS之间有很大的不同,其实HBase是基于列族的、稀疏的、多维的数据库系统,所以在设计数据迁移方法时需要充分考虑HBase数据模型的特点。
HBase的底层存储结构如图1所示,是按列族存储的。

图1 HBase底层存储结构
某一RowKey的数据(如表1)虽然在数据模型上看是在一行上,但是在HBase底层存储中是分开存储的,如图1所示,数据在存储时,HBase会自动的将表水平划分成多个区域(Region),每个Region中会保存某段连续的数据,而一个Region包含多个Store,这里每一个Store就是一个ColumnFamily(列族),由此可以看出,HBase在底层存储时,同一列族的数据存储在一个文件中,不同列族的数据存储在不同的文件之中,而且HBase中并不是所有的行和列中都存储数据,不存储数据的单元格不占存储空间,每一个store在初始化时设置了固定存储大小;另外,虽然HBase列标识可以有上百万列,由于HBase结构中的HFile有一定的大小限制,如果一行数据量太大,在存储时会导致HFile无法选择合适的分割点。
由于HBase底层存储有以上特点,在设计数据迁移方法的HBase表模式时应考虑无论数据量的大小,每个列族都占用固定的存储空间(初始化前确定)这一因素,所以应该尽可能少的创建列族,HBase官方文档推荐是创建最好不多于三个列族,故将相邻的数据、经常在一起使用的数据放在同一列族下,这样不仅可以减少数据存储空间而且可以有效减少检索时查询存储文件的次数。
综合考虑HBase数据模型及HBase数据存储的特点,在设计HBase的数据格式时需要充分利用行键(RowKey),适当的使用列族(ColumnFamily),将关系型数据库中需要索引的字段尽量放在RowKey或列族中来提高数据存储和查询的性能。
2 数据迁移方法的设计与实现
2.1 概述思想
由于HBase与关系型数据库的区别,所以在进行关系型数据库(MySQL)向非关系数据库(HBase)的数据迁移时,需要重新设计HBase的数据表模式。在设计HBase表模式时要充分考虑HBase数据的存储和查询特点,使得系统业务数据的存储性能和查询效率较高。
在数据存储上,由1.2节HBase存储原理可知,HBase底层是按列族进行存储的,每个表中包含有多个区域,而一个区域中包含多个store,这里的一个store就代表一个列族,每个store在初始化时给定固定值,由此可知,HBase表中的列族越多就越占用空间,所以在设计HBase表时尽量按照官方文档建议列族最好不多于三个,故将相邻的、经常使用的数据放在一个列族中以减少存储空间和提高查询效率。
在数据查询上,由于HBase不支持表间关联查询[10],所以在进行数据库迁移时需要充分考虑关系型数据库中的表间关系在HBase数据库中的体现,相对于关系型数据库,在HBase数据库中就需要对HBase表模式进行重新设计,提高HBase的查询效率,由此本文提出关于MySQL数据库到HBase数据库的几种表转换关系原则。
2.2 表模式设计
在对HBase的表模式进行设计时,以关系型数据库MySQL数据库的表间关系为基准,分为“基本变换”、“‘一对一’变换”、“‘一对多’变换”,“‘多对多’变换”四种变换,下面详细介绍其变换规则[11-14]。
2.2.1 基本变换
此类变换对应于MySQL数据库向HBase数据库进行单表迁移没有表间关系也即是基本表迁移的情况,表模式变换即用基本变换方法将MySQL数据库中表模式变换成符合HBase数据库的表模式。
具体变换方法说明:如图2所示,将MySQL数据库中A表的表名作为HBase数据库中对应表的表名HA,在HA中创建表A的自定义列族CF1,并将表A中的所有列作为HA表列族CF1中的列标识(ColumnQualifier)。最后以表A的主键作为HA的RowKey进行数据导入。

图2 基本变换
此类是数据库基本表的迁移,所以在海量数据的存储和查询的效率上与HBase的一般表的存储和查询效率一样。
2.2.2 “一对一”变换
此类变换对应于MySQL数据库中表间关系为“一对一”的关系类型的数据表迁移,表模式变换即将MySQL中两张表的记录转换成HBase中一张表的记录,存储两张相关联表的信息。
具体变换方法说明:如图3所示,在MySQL数据库中有数据表A和B,表A与表B的表间关系是“一对一”关系,现将表A的表名作为HBase数据表HA的表名,并创建表A和表B在HA中的列族CF1和CF2,将表A中所有列添加到表A对应的列族CF1中,同时将与表A相关联的表B的所有列添加到相对应的列族CF2中,根据实际需求对表B进行保留或删除操作,即完成“一对一”关系变换。

图3 “一对一”变换
此类“一对一”变换,可以有效解决HBase中无法进行表间的连接查询问题,由“一对一”变换图可知,存储的数据看似冗余,消耗更多的存储空间,但是提高了表间数据的连接查询效率。
2.2.3 “一对多”变换
此类变换对应于MySQL数据库中表间关系为“一对多”的关系类型的数据表迁移,表模式变换即将MySQL中“一”的一端对应的多条关联表记录在HBase中的一条记录进行存储,而“多”的一端与“一对一”变换类似。
具体变换方法说明:如图4所示,在MySQL数据库中有表A和表B,表A和表B的表间关系是“一对多”关系,现将表A的表名作为HBase中HA的表名,并创建表A的列族CF1以及关系表表B的列族CF2,同时将表A的所有列添加到对应的CF1中,将与表A相关联的N条记录的表B的主键添加到列族CF2中;对于MySQL中表B类似于“一对一”变换,完成表A和表B两表的变换即完成“一对多”变换。
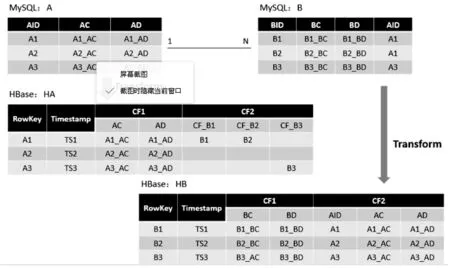
图4 “一对多”变换
此类“一对多”变换,可以在HBase中通过行键查询可以得到表A的记录,并且可以由关联关系快速查询到表A对应表B的关联信息,由“一对多”变换图可知,存储的数据看似冗余,消耗了更多的存储空间,但是提高了表间数据的连接查询效率。
2.2.4 “多对多”变换
此类变换对应于MySQL数据库中表间关系为“多对多”的关系类型的数据表,而且在中间表中有本表自有属性列的情况,表模式转换即根据中间表信息,将MySQL中两张关联表对应的多条记录在HBase中一条记录中存储,同理将中间表中自有属性根据“一对多”或“多对多”表模式转换方式进行转换。
具体转换方法说明:如图5所示,在MySQL数据库中有表A、表B以及表C,其中表A和表B表间关系是“多对多”关系,表A和表B的中间表为表C,表C中有本表自有属性。现将表A的表名作为HBase中HA的表名,并创建表A的列族CF1、关联表表B的列族CF2以及中间表表C的列族CF3,同时将表A中的所有列添加到列族CF1中,将与表A相关联的N条记录的表B的主键添加到CF2中,同理将中间表表C中与表A相关联的列添加到列族CF3中。对于表B的模式转换同表A一样,根据实际需求决定保存或删除表C,即完成“多对多”变换。
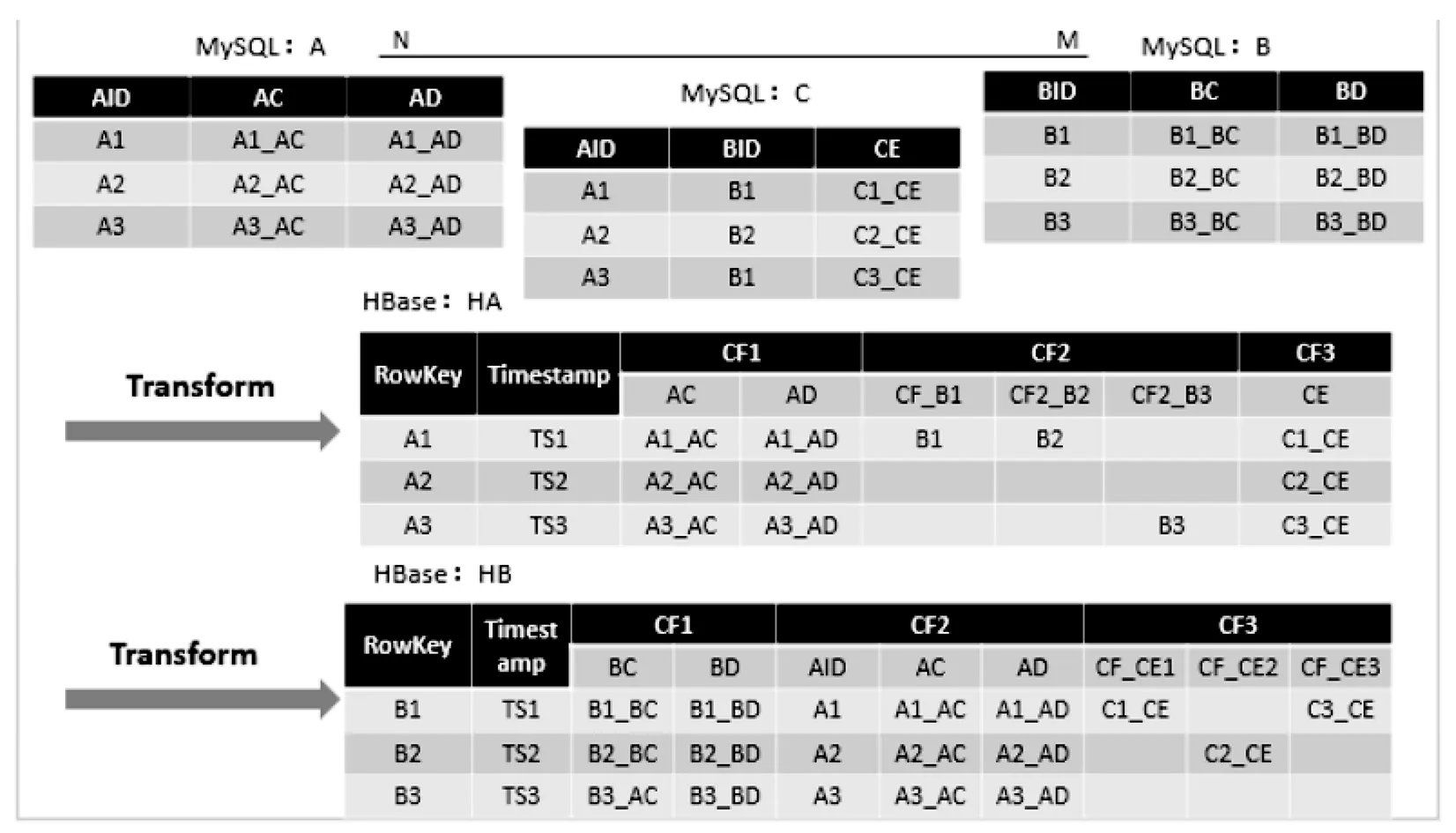
图5 “多对多”变换
此类“多对多”变换,可以在HBase中根据行键查询快速得到表A、表B中记录的关联信息,由以上变换图可知,存储的数据看似冗余,消耗了更多的存储空间,但是提高了表间数据的连接查询效率。
2.3 迁移方法及具体实现
2.3.1 迁移流程
在完成对HBase的表模式设计之后,需要了解数据迁移流程,本文在数据迁移过程中,利用了XML标记语言[15-16]对数据进行结构化处理的特点,采用XML文件作为存储源数据库表的元数据,由此对于基于Hadoop平台的数据迁移流程分为以下几个部分:
1)建立HBase数据库,并获得源数据库和目标HBase数据库的连接信息;
2)根据源数据库的连接信息,获取数据库表的元数据并保存在XML文件中;
3)根据XML文件信息,按照2.2节中表模式转换原则建立HBase数据库表模式;
4)将关系型数据库中的数据按照2.2节中表模式转换原则迁移至新建立的HBase数据表中。
整体数据迁移流程如图6所示。

图6 数据迁移流程
2.3.2 具体实现
在数据迁移的主要流程中,其中第二部分中需要创建源数据库表的元数据XML文件。在程序设计中通过以下步骤及方法获取数据库表元数据:
1)连接源数据库:public static Connection getConnectDB();
2)获取源数据库的元数据:DatabaseMetaDatadbMetaData = ct.getMetaData();
3)获取源数据库所有数据表:ResultSettablesResultSet = dbMetaData.getTables(catalog,null,null,new String[]{"TABLE"});
4)获取源数据库表的主键:ResultSetpkResultSet = dbMetaData.getPrimaryKeys(catalog,null,tableName);
5)获取源数据库表的外键:ResultSetfkResultSet = dbMetaData.getImportedKeys(catalog,null,tableName);
6)获取源数据库表的字段名:rsMetaData.getColumnName(i);
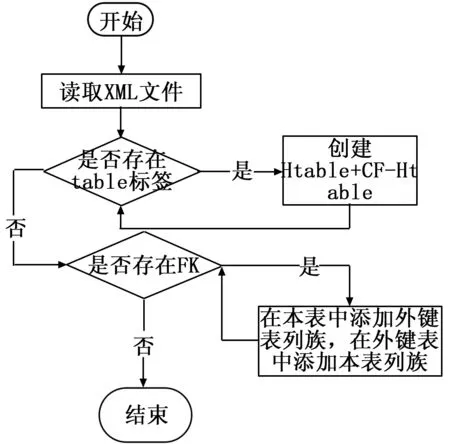
在获取源数据库所有表的元数据的基础上,创建保存源数据库表元数据的XML文件流程如图7所示。
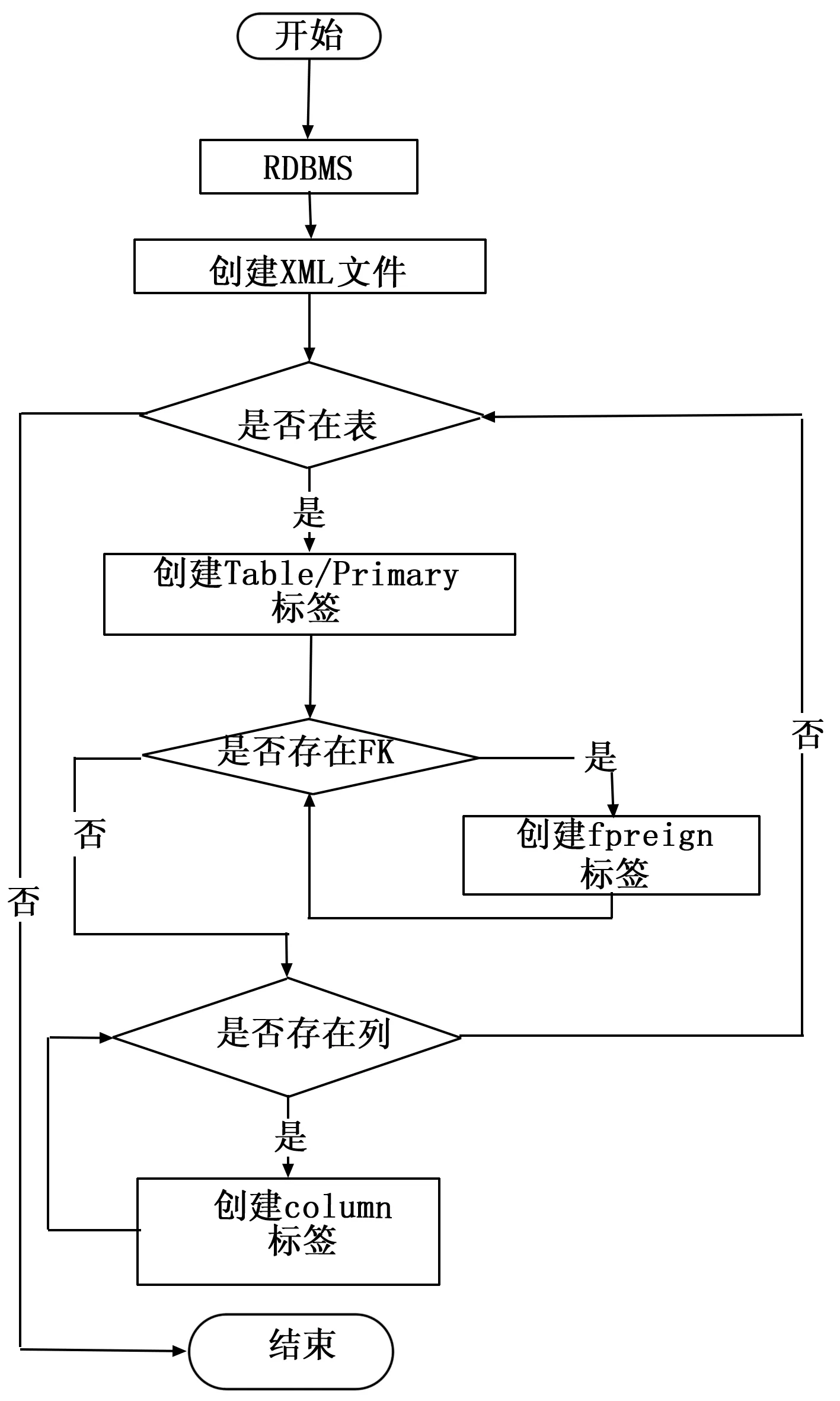
图7 创建XML文件流程图
根据创建XML文件流程,创建的XML文件格式如下:
在此XML文件中记录着源数据库中所有表的元数据,主要包括表名、主键、外键所在表、字段名及字段类型,通过源数据库表元数据文件创建目标数据库HBase的表模式。
创建HBase表模式步骤如下:
1)通过高性能的DOM4J方式读取源数据库表元数据XML文件;
2)根据XML文件中