
基于计算机视觉的人脸识别算法的研究
2018-04-24 05:55肖彬李泽滔杨昱翔
新型工业化 2018年12期
肖彬,李泽滔,杨昱翔
(贵州大学电气工程学院,贵州 贵阳550025)
0 引言
在计算机网络和数据挖掘技术已然成为主流的现代社会,信息安全的重要性不言而喻。而信息安全其中的一个重要组成部分就是人脸识别(Face Recognition ,FR)[1-4],虽然这项技术已经发展了数十年,但却因为其自身独特的优势,很受关注,尤其是在商业界和学术界的广泛关注[5,6]。本设计想法是:首先通过对对光照与旋转具有鲁棒性的LBP 算法对人脸表情图片提取他的初次特征,然后对初次的特征进行第二次特征提取与分类学习使用的是概念深度学习模型DBN 网络。
1 系统总体框架
系统是由摄像头对进出房屋的人员进行人脸抓拍,将得到的数据传到PC 机,由PC 机进行处理并得到进出房间的人的具体信息来判断是否是 屋主还是犯罪人员,图1 为实物模拟图。PC 机的处理流程包括调用摄像头拍摄图像、图像预处理、人脸检测及人员判定等几个部分。本文的总体的设计框图如图2 所示。
图1 为实物模拟图 Fig. 1 Physical simulation diagram
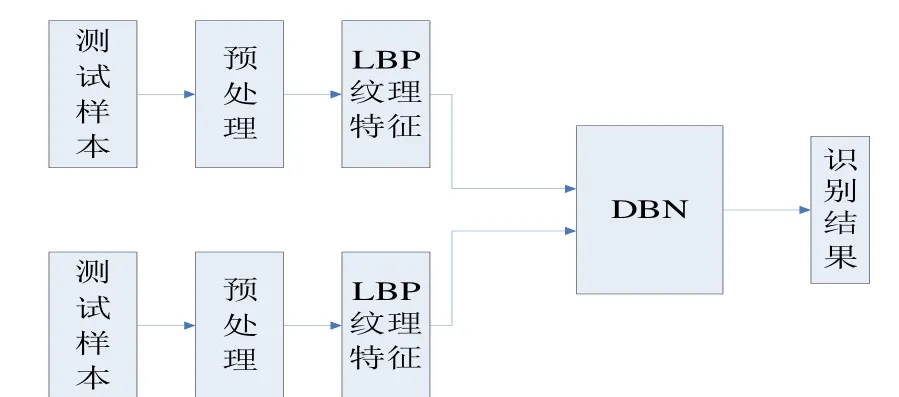
图2 系统总体框图 Fig. 2 System block diagram
2 系统具体设计
2.1 人脸识别常见问题
将不同人的人脸当作是一种模式,那么,任一一个人的人脸都有其自己的特定的模式,这也就是所谓的人脸识别。而先建立“自己人”的数据库,将要识别的人的人脸模式,和已有的数据库进行比对,对这个人进行身份确认,这个过程即称之为人脸识别的过程。有很多的性能因素会影响到人脸识别,这些影响主要可以分为以下几点[7-9]:
1)光照问题。由于长期以来,光照,一直是在生物识别的时候是个非常大的难题,而且,这个问题是一个“顽疾”很难彻底的把问题坚决。一般来说,现阶段的算法,都会对光照条件有依赖,同时,一些光照条件如偏光、光照过亮、光照不足等,这些条件会让人脸的识别的性能飞速下降。就目前情况来说,虽然有很多专家学者提出算法,但是仍然缺少有效的光照算法。
2)姿态问题。千变万化是人脸的姿态本生的特点,不同角度的摄像机拍到的人脸肯定的不一样的,而这些都是会影响这个人图像的信息的。摄像机拍摄的时候,不可能像取证拍照时是正常正面拍摄,而是会有很多的角度偏转,所以在实际的应用中,这些会对人脸的特征提取造成困难。虽然,这些年来,专家学者们对多姿态的研究逐渐深入,但是毕竟这个因素对特征提取的影响非常巨大,是将人脸识别实用化的时候的一道坎,是需要解决的关键问题所在。
3)表情问题。对于我们人来说,识别人的脸和表情都是毫无问题的,然而,于计算机来说,识别任何东西,都是需要建立一个模型,而如何建立一个人脸和表情的表情模型是一个非常巨大的难题。因为,人脸表情十分的丰富,而且复杂多变,所以这也将这个问题推向了更加困难的程度。
2.2 LBP(Local Binar y Pat t er ns)算法
提取局部特征是LBP(Local Binary Patterns,局部二值模式)的判别依据。LBP 算法对光照的不敏感是它的显著的优点,但是对于解决姿态和表情的问题,它存在很大的问题,即对这两个因素它的鲁棒性比较差[10]。不过,将它和特征脸方法进行对比,在识别率上LBP 算法比之特征脸有了巨大的提升。
2.2.1 LBP 特征提取
最开始的LBP 的定义是,有一个3*3 的像素邻域,在这个领域内,将它的中心像素灰度值设置为阈值,然后将它周围的8 个像素灰度值与中心阈值进行一一比对,倘若中心像素值比周围像素值小,那么这个点的位置的值被设定为1,反之,则是0。经过这样的比对,会产生一个8 位的二进制数(通常转换为十进制数即LBP 码,共256 种),数据书写顺序是从第一个开始顺时针排列即可得到,而这个二进制数转化的十进制数就是这个领域的像素点的LBP 值,即得到该邻域中心像素点的LBP 值,而这个数反映了该区域的纹理信息。如下图3 所示:
公式定义如下:
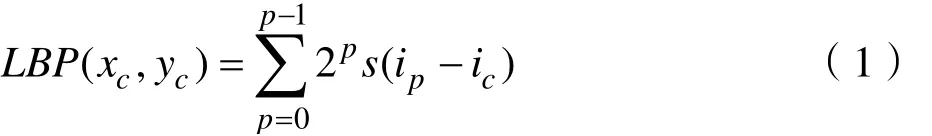
其中( xc,yc)代表3*3 邻域的中心元素,它的像素值为 ic, ip代表邻域内其他像素的值。s(x)是符号函数,定义如下:
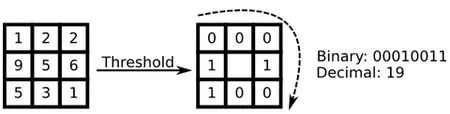
图3 特征提取示意图 Fig. 3 Feature extraction schematic diagram

2.2.2 圆形LBP 算子
最开始的LBP 算子有一个很大的缺点,这使得当要面对不同的尺寸和频率的纹理的要求的时候,这个算法不能很好的实现它的要求,这个缺点就是原始LBP 算子只是覆盖固定的,半径范围确定的小区域[1115]-。Ojala 等改进了LBP 算子,要求达到灰度和旋转不变性的要求,适应了不同的尺度和纹理特征,将3*3 邻域扩展到任意邻域,并将正方形邻域用圆形邻域来代替,允许在半径为R 的圆形邻域内有任意多个像素点是改进后的LBP 算子的特点。进而得到了一个内含有P 个采样点的LBP 算子,该算子是以半径为R 的圆形区域。比如下图4 定了一个5*5 的邻域:
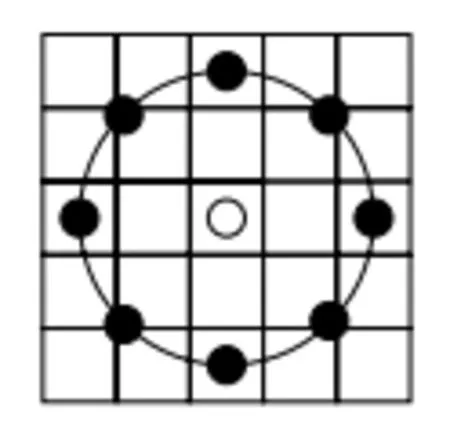
图4 圆形LBP 算子示意图 Fig. 4 Schematic diagram of circular LBP operator
上图内有八个黑色的采样点,每个采样点的值可以通过下式计算:

其中( xc,yc)为邻域中心点,( xp,yp), p ∈ P为某个采样点。通过上式可以计算任意个采样点的坐标,但是计算得到的坐标未必完全是整数,所以可以通过双线性插值来得到该采样点的像素值:
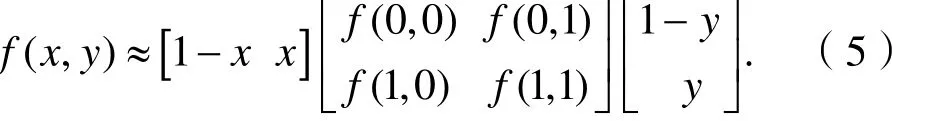
2.2.3 LBP 等价模式
同一个领域内,如果增加采样的点数,那么,它产生的二进制数的个数也会随着采样点的增加而随指数增加,这种指数的增加无疑是极其恐怖的。不同的LBP 算子会有不同的二进制数,对于半径为R 的圆形区域内含有P 个采样点的LBP 算子将会产生2P种模式。所以为了解决这种二进制模式太多的问题,我们需要对该算子进行降维,所谓降维即是减少二进制模式的个数。为了解决这个问题,专家提出了一种“等价模式”(Uniform Pattern)。即在实际图像中,绝大多数LBP 模式最多只包含两次从1 到0 或从0 到1 的跳变。“等价模式”定义为:当某个LBP 所对应的循环二进制数从0 到1 或从1 到0 最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类。如00000000(0 次跳变),00000111(只含一次从0到1 的跳变),10001111(先由1 跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)。比如下图5 给出了几种等价模式的示意图。
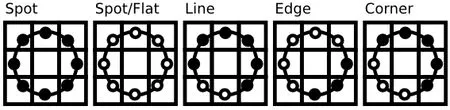
图5 几种等价模式的示意图 Fig.5 Schematic diagram of several equivalent patterns
在这中改进的算法下,二进制的种类将会大大减少,而且,这种改进之下不会使该领域内的数据信息发生丢失现象。从上面的讲解来看,等价模式的模式数量变成了P(P-1)+2 种较原来的2P种减少巨大,其中P 表示邻域集内的采样点数。比如,对于3*3 邻域内来说,我们如果设置8 个采样点,那么等价模式下二进制数为58 种,而原始的则为256种,这种情况下,特征向量的维数大大减少,并且还可以减少高频噪声带来的影响。
通过上述方法,每个像素都会根据邻域信息得到一个LBP 值,如果以图像的形式显示出来可以得到下图6 所示,明显LBP 对光照有较强的鲁棒性。

图6 经过LBP 算法处理后前后的图像 Fig.6 After LBP algorithm processing before and after the image
2.3 DBN(Deep Bel ief Net wor k)深度信念网络模型
DBN 模型是深度学习中唯一一种基于概率统计的模型,其基本组成单元为 RBM(Restricted Boltzmann Machine)机[15]。由于DBN 模型借助概率统计来对问题进行建模,所以对复杂度较高的问题具有良好的表征性能,特别是在大数据条件下,这种优势可以更好的得以体现。因此,随着大数据和互联网相关技术的不断发展,DBN 模型将逐渐成为深度学习领域研究的核心[1618]-。
2.3.1 RBM 受限玻尔兹曼模型的定义
RBM 受限玻尔兹曼模型共包含两层网络:隐含层和可视层。该模型满足下述约束条件:
(1)层间节点全连接,层内节点无连接
(2)模型中所有节点的取值均为二值化变量(值只能取0 或者1)
(3)隐含层和可视层间的概率约束P(v,h)须满足玻尔兹曼(Boltzman)分布
经典RBM 模型如图7 所示。图中,v 表示可视层,节点个数为m;h 表示隐含层;节点个数为n。因为RBM 模型层内无连接,所以,如果可以确定隐含层的情况,则对应可视层的节点均满足相互独立的条件,反之亦然[19,20]。因此,在确定了可视层v 的条件下,对应隐含层节点的状态满足如下关系:
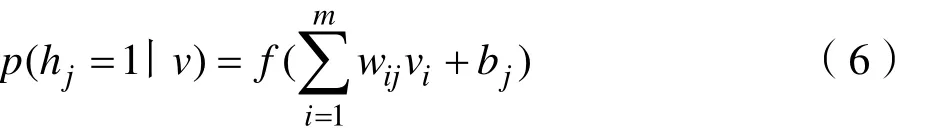
式中, p ( hj= 1丨 v )表示第j 个隐含层节点处于激活态(值为1)的概率,f(x)为激励函数, wij表示第i 个可视层节点和第j 个隐含层节点之间的连接权重,vi为第i 个可视层节点的值, bj为第j 个隐含层节点的偏置。
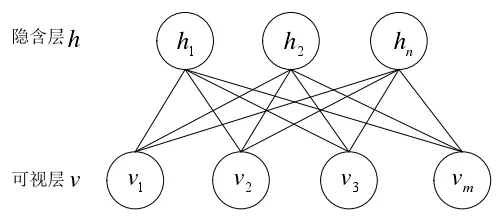
图7 RBM 受限玻尔兹曼模型示意图 Fig.7 Schematic diagram of RBM restricted boltzmann model
此时生成一个随机数ε ,如 果ε小于p (hj= 1丨v ),则 hj的值为1;反之,值为O。
同样的,如果给定了隐含层h,则通过下式能够获得对应的可视层值 vi′:
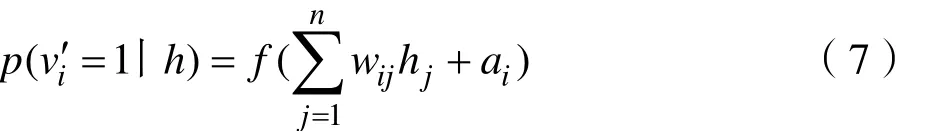
式中,ia 为第i 个可视层节点的偏置。如果通过某种方式调节参数ijw 、ia 和jb ,可以使得可视层的输入v 与经过重构得到的结果v′之间的差别尽可能小(理想情况下是无差别的),就能够认为隐含层h是可视层v 的同等特征描述。
2.3.2 RBM 训练步骤
1)第一层的RBM 是以LBP 纹理特征为输入,同时对RBM 进行无监督训练,获得这一层的最优参数;
2)低一层的RBM 输出数据作为高层RBM 输入,同时对RBM 进行无监督训练,获得这一层RBM网络最优的参数值;
3)最后需要对各层参数进行微调利用方法可以选择如全局训练,这样可以使得DBN 收敛到全局最优。
无监督逐层学习采用的是贪婪算法,其大致流程如图8 所示:
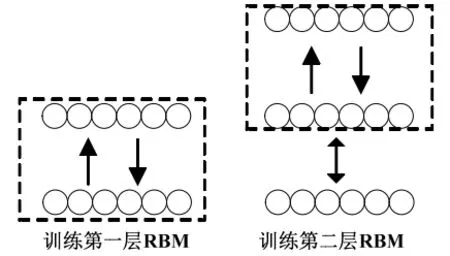
图8 DBN 模型训练示意图 Fig.8 DBN model training schematic diagram
3 实验结果
本实验中,为了验证本文的特征提取以及改进的算法识别的有效性,需要包含光照以及姿态的差别,所以我们采用FERET 和ORL 人脸库,则直接对FERET 库和ORL 的原始人脸图像采用CS-LBP结合DBN 的方法进行特征提取并识别。
为了保证实验的可靠性及有效性,所有实验均在相同的实验条件下进行。实验中选取FERET 库中每个个体的第1 幅图像作为测试样本集,其余6幅图像作为训练样本集,采用图像分块数为8*8。为了进一步验证本算法的有效性,在实验中,对比了本文方法和其他几种算法:LBP 结合 DBN,MB-LBP 结合DBN,LBP 结合PCA 和DBN。在FERET 人脸库中的实验结果如图9 所示;同样情况下将FERET 人脸库更换成ORL 人脸库,其他步骤一致,实验结果如图10 所示。
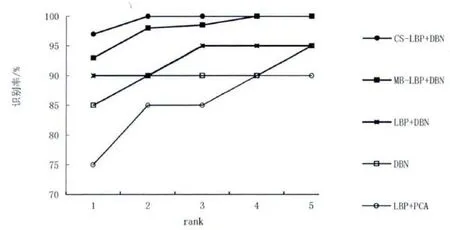
图9 FERET 人脸库中不同算法识别效果 Fig.9 The recognition effect of different algorithms in FERET face database
据图9 可知,本文各算法识别率如下:MB-LBP结合DBN 方法的首选识别率为93%,LBP 结合DBN 方法和DBN 方法的首选识别率分别为90%和85%,LBP 结合PCA 的首选识别率仅为75%。
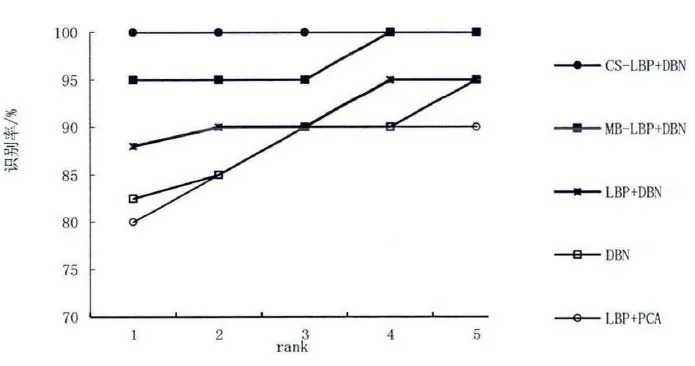
图1 0 ORL 人脸库中不同算法识别效果 Fig.10 The recognition effect of different algorithms in ORL face database
据图10 可知,本文各算法识别率如下:MB-LBP结合DBN 方法的首选识别率为95%,LBP 结合DBN 方法和DBN 方法的首选识别率分别为87.5%和82.5%,LBP 结合PCA 的首选识别率仅为80%。
本文在FERET 和ORL 人脸库即实验数据相同的情况下,并且使用一样的训练和测试的样本,选择了PCA、SVM、LBP、DBN、LBP+DBN 这几种方法进行了比较。验证了LBP+DBN 模型在分类识别上的有效性。结果如表1 所示。
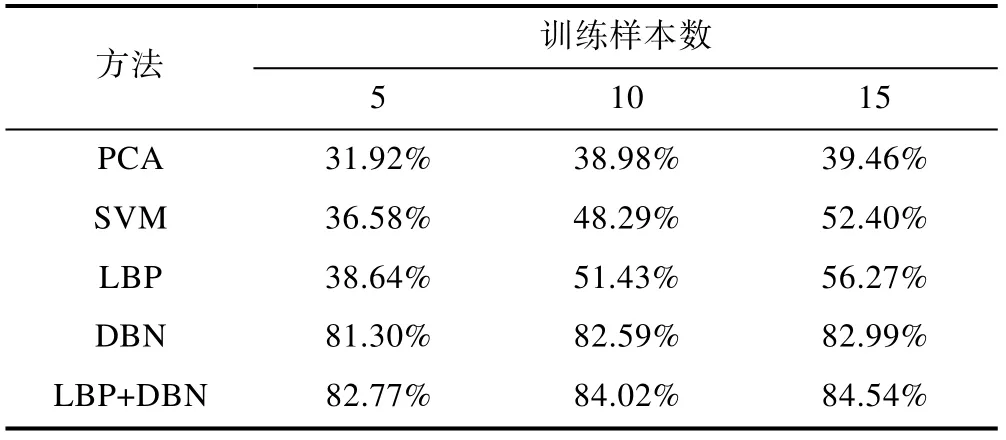
表1 不同训练样本数的正确识别率 Table 1 The correct recognition rate of different training sample Numbers
4 结论
本文提出了一种基于LBP 特征和深度学习中DBN 模型的表情识别方法。通过对输入图片预处理、提取LBP 特征,去除了光照的影响,将取得的特征作为DBN 的输入。经过DBN 网络的训练与学习,优化其在非限制条件下比如受姿态、光照、表情、遮挡等综合因素影响。由上述实验可知,在FERET 和ORL 人脸库条件下,LBP+DBN 明显优于LBP+PCA 和单独的DBN 算法的识别率,并且在上述实验中,实验对PCA、SVM、LBP、DBN、LBP+DBN 识别率进行对比,明显看出本文提出的LBP+DBN 算法在识别率上有着明显的优势。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
吉林大学学报(理学版)(2020年3期)2020-05-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
动漫星空(2018年9期)2018-10-26
自动化学报(2018年7期)2018-08-20
中国交通信息化(2018年3期)2018-06-13
周口师范学院学报(2016年5期)2016-10-17
