
基于文档对象模型和图像处理的网页分割方法
2018-04-24 07:58:46贾柯祯
现代计算机 2018年8期
贾柯祯
(四川大学计算机学院,成都 610065)
0 引言
随着互联网技术的发展,Web应用早已融入了人们的日常生活。从网易、搜狐等各种大型门户网站,到京东、淘宝等热门网上商城,再到微博、微信等流行社交平台,都或多或少地将Web应用作为其载体。可以说,Web应用已经与我们密不可分。
Web应用是一种通过Web访问的应用程序,它基于B/S(Browser/Server)结构。通常情况下,用户通过Web浏览器访问Web应用,并与它进行交互活动。自1990年第一款浏览器Nexus(原名WorldWideWeb)问世至今,浏览器的品牌已经达到了数十种之多。
跨浏览器差异的原因主要来自不同浏览器对于HTML、CSS以及JavaScript代码的不同解释。但差异并不意味着不兼容,界定何种程度的差异构成了不兼容是一件非常主观的事情。不论是Web应用的设计者还是最终用户,他们都希望网页在所有浏览器上具有相同或相似的表现,除非存在的差异是设计者有意为之。虽然某些Web应用声明了推荐浏览器及其版本,但对于用户来说,专门为了该应用使用特定浏览器十分不便。因此,以检测跨浏览器兼容性问题为目的的跨浏览器兼容性测试就显得尤为重要。
1 相关工作
现存的跨浏览器兼容性测试方法大部分通过分析文档对象模型 DOM(Document Object Model)来进行[1-5],有些也结合一些图像处理技术[2,4,6,7],其中大多数都选择使用“先分割再比较”的方法。
WebDiff[2]与CrossCheck[4]使用基于DOM的方法对网页截图进行分割。DOM是一个天然的树形结构,通过对树的遍历,我们可以提取DOM中的每个节点的属性。通过提取DOM节点的坐标以及尺寸信息,我们可以将其映射到网页截图的相应位置,并通过这些位置信息对网页截图进行分割,最终得到许多子图像,每个子图像都对应DOM中的一个节点。WebDiff的分割方法依赖于浏览器生成的DOM,它从根节点开始对DOM进行自底向上的遍历,逐个比较节点对应的图像区域。这将导致两个问题。首先,DOM树不尽相同,即使两个浏览器产生了相同的网页截图,其DOM节点也不能保证一一对应,这在比较子图时将产生问题。其次,在遍历DOM的过程中,截图的某些部位将会被重复比较多次,换言之,子图之间会有重叠,这些重叠的部分将增加计算开销。
Browserbite[6]使用基于图像的方法对网页截图进行分割。它首先使用Harris角点提取算法[8]提取图像的角点像素,使用膨胀方法对这些像素进行处理,得到若干连通区域。当连通区域面积或个数符合预设条件时,得到最终的分割结果。Browserbite的方法在减少计算开销上明显优于基于DOM的方法,但其分割得到的区域仍有较少重叠,并且对于部分网页,很难解释经过分割得到的区域有何意义。此外,网页上不构成不兼容的差异也可能导致出现不同的分割。而Browser⁃bite认为如果分割得到的子块不匹配,则网页构成不兼容,这将产生一部分假阳性。
本文将结合基于图像的方法和基于DOM的方法的思想,提出一种新的网页分割方法。该方法得到的网页分割更易于匹配,且假阳性率较低。
2 分割方法
本文提出的分割方法的主要步骤如图1所示。
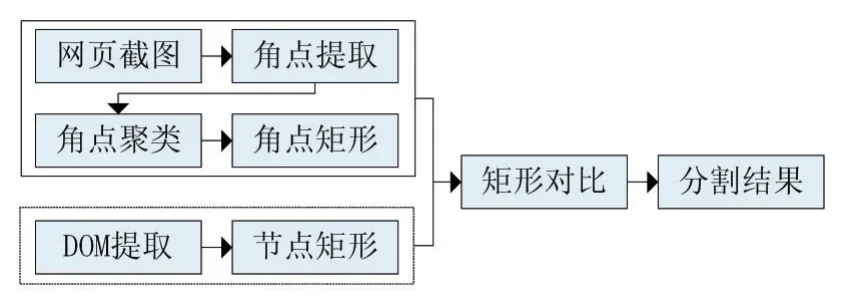
图1 分割方法主要步骤
我们首先对待测网页在不同浏览器上的渲染结果进行截图,并获得其相应的DOM对象。对得到的网页截图,我们将其进行灰度化操作,转为灰度图像。对灰度图像,我们进行角点提取,使用Harris角点算法,得到图像中的角点。通过将角点的灰度值设为255,其余点的灰度值设为0,我们将原图像转换为二值图像。
对二值图像,我们进行膨胀操作。对于一个在二值图像上滑动的3×3的窗口,如果其中心是一个值为255的点,则将整个窗口覆盖的二值图像的像素点都标记为255。当窗口遍历完一次二值图像之后,将所有标记为255的点的值置为255。
经过膨胀操作,二值图将形成若干个连通区域。我们将连通区域的个数或大小设置为终止条件,经过多次膨胀操作,得到最终的结果。我们取这些区域的最小横坐标、最大横坐标、最小纵坐标、最大纵坐标,得到一个包含了该区域的矩形。
接着,我们引入网页DOM信息,对这些矩形进行合并与分割。我们遍历DOM树,对于每个节点,调用JavaScript的 getBoundingClientRect()函数并计算得到其四角坐标,得到该节点对应的矩形。将节点矩形和之前得到的二值矩形进行对比,将出现下列情况:
●若节点矩形与二值矩形无交集,直接寻找下个二值矩形再进行比较,若所有二值矩形均与当前节点矩形无交集,则忽略当前节点矩形,访问其兄弟节点。
●若节点矩形仅包含一个二值矩形,将该节点矩形作为分割的最终结果。
●若节点矩形与二值矩形相交或被二值矩形包含,将二值矩形分割为节点矩形部分与剩余部分,每个部分作为一个新的二值矩形。若节点矩形中仅包含一个新的二值矩形,则将节点矩形作为最终结果。
●若节点矩形包含了两个及以上的二值矩形,若该节点为DOM树的叶子结点,则将该节点矩形作为分割的最终结果。否则,遍历该节点的下一层子节点,并进行对比。
经过以上步骤,我们将得到最终的网页分割。
3 结语
本文提出了一种新的基于文档对象模型和图像处理的网页截图分割方法,它通过图像处理的方法得到初步图像分割,并使用DOM信息约束它们,得到最终的结果。
相比于Browserbite,我们的方法得到的分割结果更合理,更易于匹配。相比于WebDiff和CrossCheck,我们的方法需要对比的次数更少,计算开销更低。
然而,本文的方法得到的结果仍有较少的假阳性出现,其主要原因来自DOM树结构的差异。我们未来希望提出不依赖于DOM树的新的分割方法,以杜绝这种假阳性。
参考文献:
[1]Mesbah A,Prasad M R.Automated Cross-browser Compatibility Testing[C].International Conference on Software Engineering.IEEE,2011:561-570.
[2]Choudhary S R,Versee H,Orso A.WEBDIFF:Automated Identification of Cross-browser Issues in Web Applications[C].IEEE International Conference on Software Maintenance.IEEE Computer Society,2010:1-10.
[3]Choudhary S R,Prasad M R,Orso A.CrossCheck:Combining Crawling and Differencing to Better Detect Cross-browser Incompatibilities in Web Applications[C].IEEE Fifth International Conference on Software Testing,Verification and Validation.IEEE Computer Society,2012:171-180.
[4]Choudhary S R,Prasad M R,Orso A.X-PERT:Accurate Identification of Cross-Browser Issues in Web Applications[C].International Conference on Software Engineering.IEEE,2013:702-711.
[5]Dallmeier V,Burger M,Orth T,et al.WebMate:Generating Test Cases for Web 2.0[J].2013,133:55-69.
[6]Saar T,Dumas M,Kaljuve M,et al.Browserbite:Cross Browser Testing Via Image Processing[J].Software-Practice&Experience,2016,46(11):1459-1477.
[7]Lu P,Fan W,Sun J,et al.Webpage Cross-browser Test From Image Level[C].IEEE International Conference on Multimedia and Expo.IEEE Computer Society,2017:349-354.
[8]Harris C.A combined Corner and Edge Detector[J].Proc Alvey Vision Conf,1988,1988(3):147-151.
猜你喜欢
黑龙江大学自然科学学报(2021年4期)2021-11-19 07:05:10
高技术通讯(2021年2期)2021-04-13 01:09:46
电子制作(2019年10期)2019-06-17 11:45:14
测控技术(2018年10期)2018-11-25 09:35:28
电子技术与软件工程(2018年10期)2018-07-16 12:04:18
计算机应用(2016年10期)2017-05-12 15:22:34
电子科技(2016年12期)2016-12-26 02:25:49
系统工程与电子技术(2016年4期)2016-08-24 07:46:28
环境与生活(2016年6期)2016-02-27 13:46:37
英语学习(2015年6期)2016-01-30 00:37:23
