
基于FPGA的卷积神经网络的实现*
2018-04-18 07:00:26李嘉辉蔡述庭陈学松熊晓明
自动化与信息工程 2018年1期
李嘉辉 蔡述庭 陈学松 熊晓明
基于FPGA的卷积神经网络的实现*
李嘉辉 蔡述庭 陈学松 熊晓明
(广东工业大学自动化学院)
现有基于CPU或GPU的卷积神经网络实现方案,无法兼顾实时性、功耗以及便携性的要求。基于FPGA强大的并行处理能力和超低功耗,在DE1-Soc开发板上采用Verilog HDL实现了使用MNIST数据集的阿拉伯数字手写体识别卷积神经网络。网络的每一层采用流水线和时分复用方法;单个时钟周期能完成72次乘累加操作,在100 MHz的工作频率下,加速器峰值运算速度可达7.2 GMAC/s。与PC上运行的定点数版本的C语言程序相比,在相同错误率6.43%的情况下,速度是其5.2倍。
卷积神经网络;FPGA;性能加速
0 引言
目前卷积神经网络(Convolutional Neural Network,CNN)的实现方案有基于CPU、GPU和FPGA三大类。因CPU的结构特点以及通用计算机的架构限制,导致基于CPU的方案功耗、便携性和实时性不可兼得。虽然GPU具有强大的浮点运算和并行处理能力,但基于GPU的方案,存在功耗过高,移动性能也不足的弱点[1-3]。因此,基于CPU或者GPU的实现方案在追求移动性能的场景下均不可取。FPGA具有强大的并行处理能力、灵活的可配置特性和超低功耗,可以考虑作为CNN的实现平台。
目前,FPGA开发有2种途径:一种是基于HDL的传统途径;另一种是使用高层次综合工具,如OpenCL或者Xilinx的HLS[4],虽能加快FPGA开发流程,但资源消耗大、性能低,且开发人员不能对生成的电路进行精准干预。因此本文使用Verilog HDL语言,在DE1-Soc平台下实现一个识别阿拉伯数字手写体的CNN网络。
1 网络结构
本文实现的CNN网络整体结构如图1所示。其中卷积层C1和C3的卷积核都是5×5的矩阵组;下采样层S4和输出层之间的192×1矩阵,由下采样层的12个4×4矩阵直接展开得到,再经过全连接层计算得到输出层。
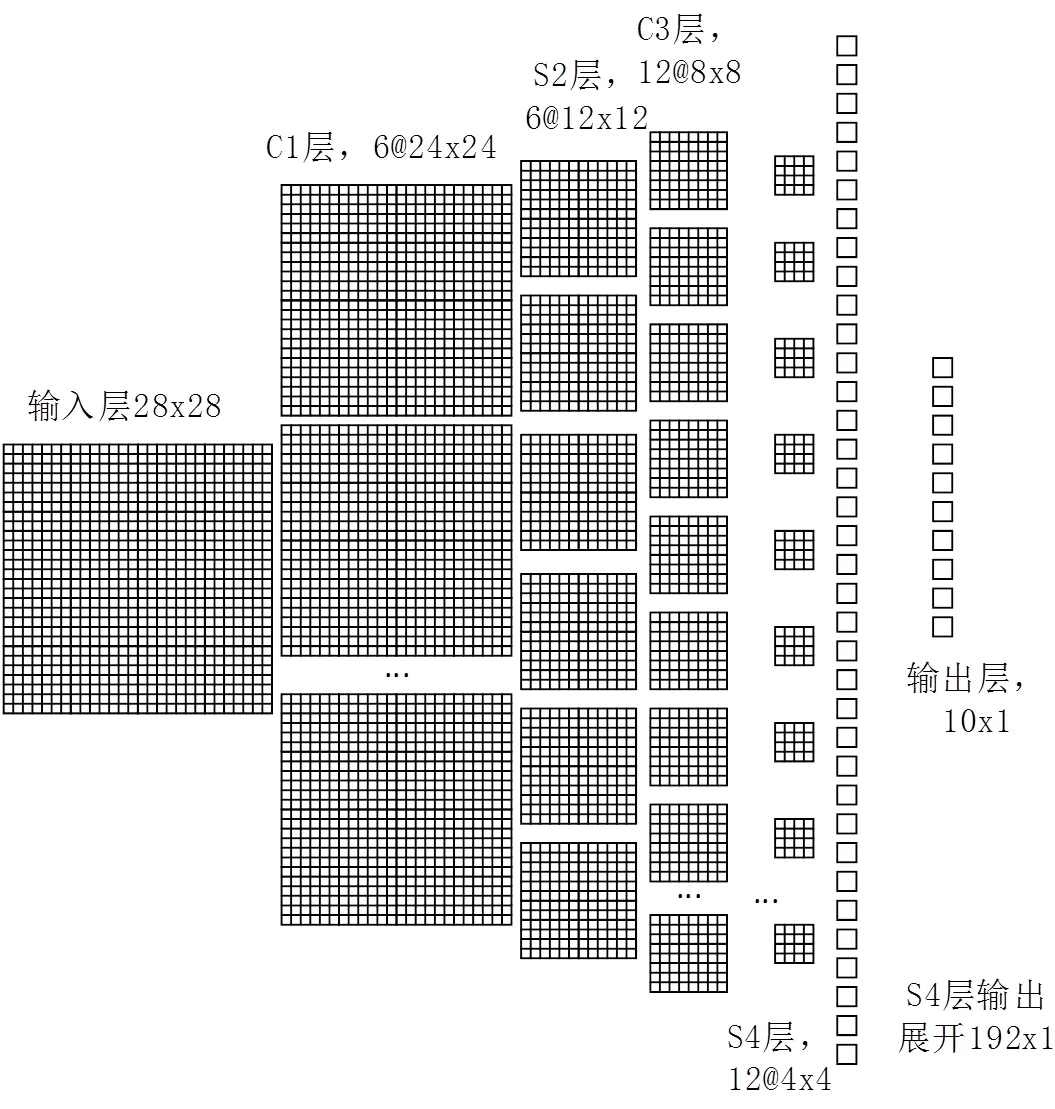
图1 CNN网络结构示意图
2 CNN加速模块的总体架构
2.1 总体架构
CNN加速系统分为2部分:一部分是在开发板上以Cortex-A9为中心的HPS,主要将样本数据读取并加载到DDR3 SDRAM的特定地址,然后告知CNN加速模块数据已经准备完毕;另一部分是FPGA内部实现的CNN加速模块,实现一个使用AXI-HP接口的AXI4总线主机,从DDR3 SDRAM中读取样本,计算并将结果写回DDR3 SDRAM,再通过中断通知HPS。另外,HPS通过AXI4-lite设置加速模块的参数,如数据存储地址。加速系统整体架构和CNN加速模块结构图如图2、图3所示。
2.2 CNN实现方案特点
本文CNN实现方案具有以下特点:
1)通过时分复用降低对FPGA上DSP等资源的需求;
2)具体到某一层的实现,采用流水线增加数据吞吐率;
3)使用定点数代替浮点数,进一步降低对BRAM和DSP的资源消耗;
4)对MNIST样本预处理,避免因数据位数有限导致溢出。

图2 加速系统整体架构

图3 CNN加速模块结构图
3 CNN各层的实现
3.1 卷积层的实现
以第一卷积层为例阐述卷积层的实现方法。第一卷积层的运算过程如图4所示,6个卷积核矩阵分别在输入矩阵进行平移,两者重叠部分相乘求和得到输出矩阵中的一个元素。输入输出矩阵和卷积核的数据在存储器中的组织情况如图5所示。每次对kernels的读操作,能够读取6个数据,故可同时计算6个输出元素。为提高模块处理能力,采取流水线结构,如图6所示,其中表示当前样本在一批样本中的序号;和表示输出元素的坐标;和表示卷积核与输入矩阵重叠部分中当前处理的元素的坐标(相对于重叠部分)。上述变量用于多层循环的遍历,并用于产生输入地址(i_addr,k_addr)和输出地址(o_addr)。i_addr和k_addr分别用于检索输入和卷积核数据。检索得到的数据相乘,各自进行累加求和,再由模块外部的sigmoid函数求值模块得到输出元素,写入到o_addr指定地址中(图6中,输出地址传输路径上省略了若干寄存器)。另外,图6中存储累加器输出结果的寄存器初值是偏置值;粗线表示其上同时传输多个数据。

图4 第一卷积层运算过程示意图

图5 第一卷积层的数据存储方式
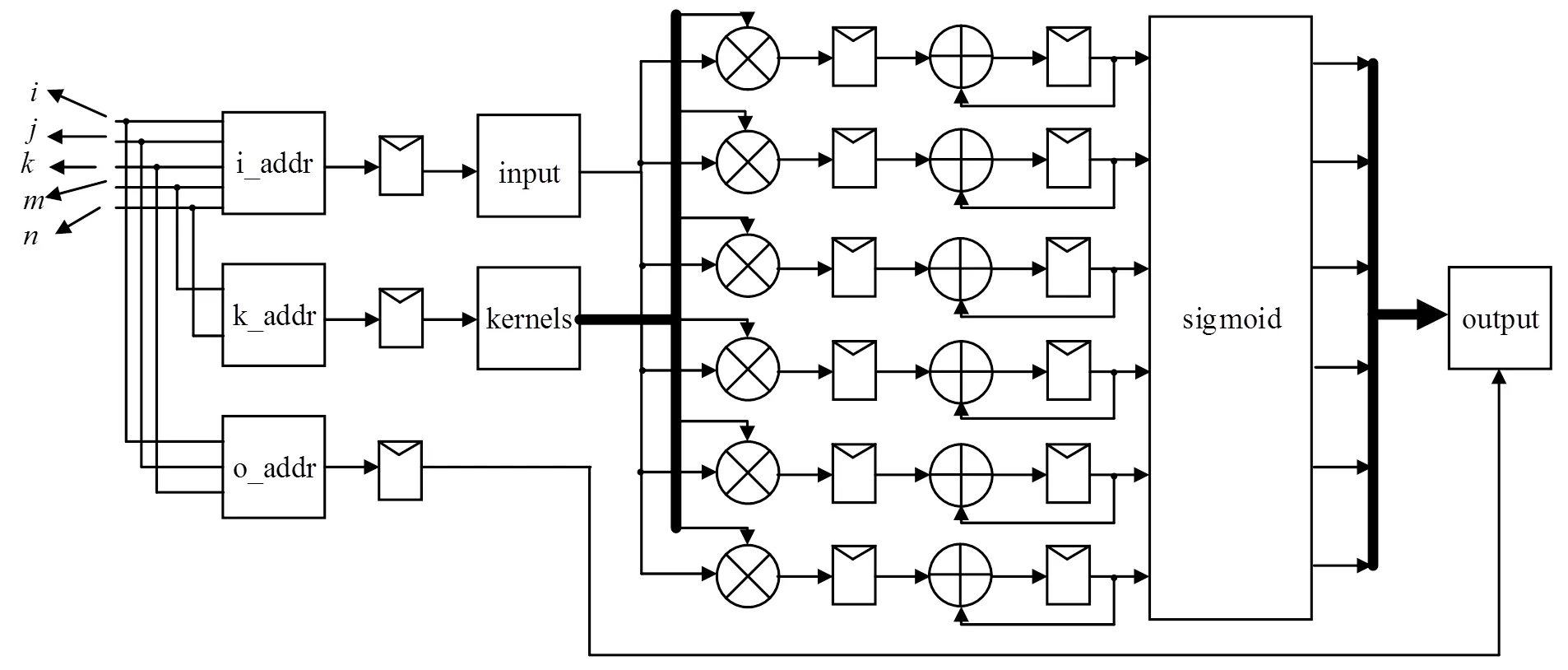
图6 第一卷积层的流水线示意图
3.2 下采样层的实现
以第一下采样层为例阐述下采样层的实现方法。第一下采样层的计算过程如图7所示,一个样本有6个24阶输入方阵,以二阶方阵作为单元对输入矩阵分块并计算各方阵元素平均值,作为其输出元素。
下采样层的输入输出数据存储排列方式,也是将矩阵按行展开为一维数组;存储器中某地址对应的字存储同一样本的多个矩阵相同坐标的元素,从而一次访问可同时计算多个输出矩阵的元素(称为一组输出元素)。另外,使用双端口ram存储输入输出元素,从而只需要2个时钟周期就能计算一组输出元素。下采样层也采取流水线的结构实现,如图8所示,其中表示当前样本在一批样本中的序号;和表示当前输出元素在输出矩阵中的行列坐标;使用双端口ram存储输入数据,故各输出元素的计算只需读2次输入数据存储器input,这2次读取标记为变量。2次读取的4个数据求和之后,舍弃结果最后2位,得到平均数存入寄存器。i_addr,o_addr和图中粗线与前文意义相同。另外,图8中输出地址传输路径省略了若干寄存器。
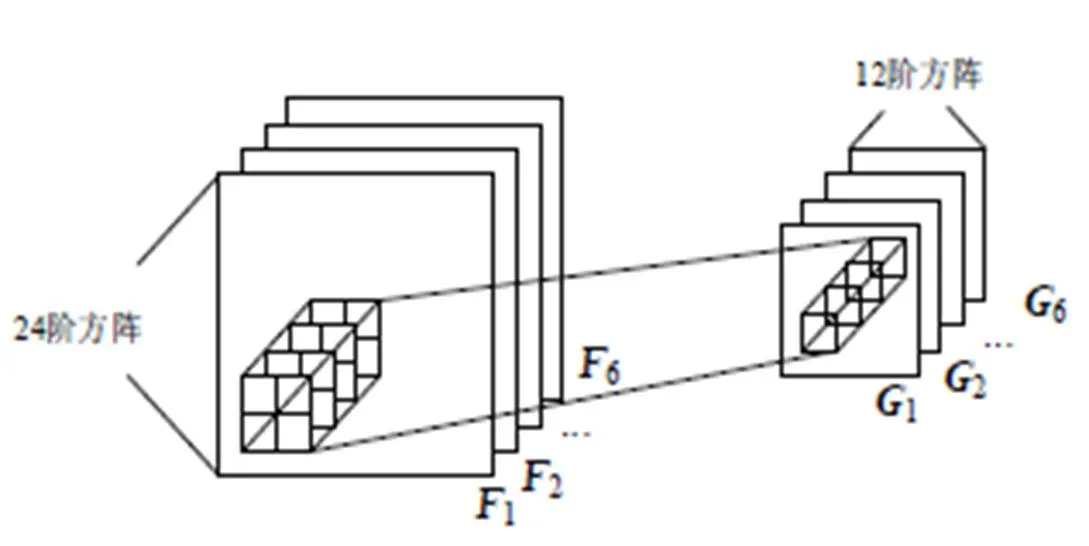
图7 第一下采样层的计算过程示意图

图8 第一下采样层的流水线示意图
3.3 全连接层的实现
全连接层的输入是12个4阶方阵,一个样本输入,最终输出10个数值结果。权值矩阵可看做是10组4阶方阵,每组12个方阵。10组权值矩阵均与输入的同型矩阵组按元素相乘求和。单个样本在该层的输入数据的存储排列情况,可以看做是字数为16、位宽为12个数据项的一段存储空间;共10组权值矩阵中的每一组也可以看成是相同大小的一段存储空间。整个权值矩阵可以存储在一个字数为160、位宽为12个数据项的存储器中。每组权值矩阵和单个样本输入数据存储情况如图9所示。

图9 全连接层数据的存储示意图
全连接层的实现也通过并行化和流水线提高数据吞吐率,输入数据和权值矩阵的存储也用双端口ram。其流水线示意图如图10所示,其中表示当前样本在一批样本中的序号;和表示当前处理的元素在4阶方阵中的坐标;表示当前使用哪组权值矩阵与输入数据相乘。图10中,w_addr表示用于检索权值数据的地址;wght是存储权值矩阵的存储器。输入到sigmoid求值模块的寄存器初值就是全连接层的某偏置值。
3.4 sigmoid函数求值模块的实现
常见的sigmoid函数求值模块的实现方法有3种:1)查表法,将预先计算的结果存储起来,把输入数据转换为查表地址,查询结果;2)直接计算法,使用较为复杂的逻辑构建计算电路;3)分段线性近似法,将函数曲线分为足够多段,每一段使用直线段近似代替原图像。因本文使用的FPGA内BRAM有限,本设计只用于预测,不需要太高精度,所以使用分段线性近似法进行sigmoid求值模块的实现。另外,该模块也采用流水线结构设计。
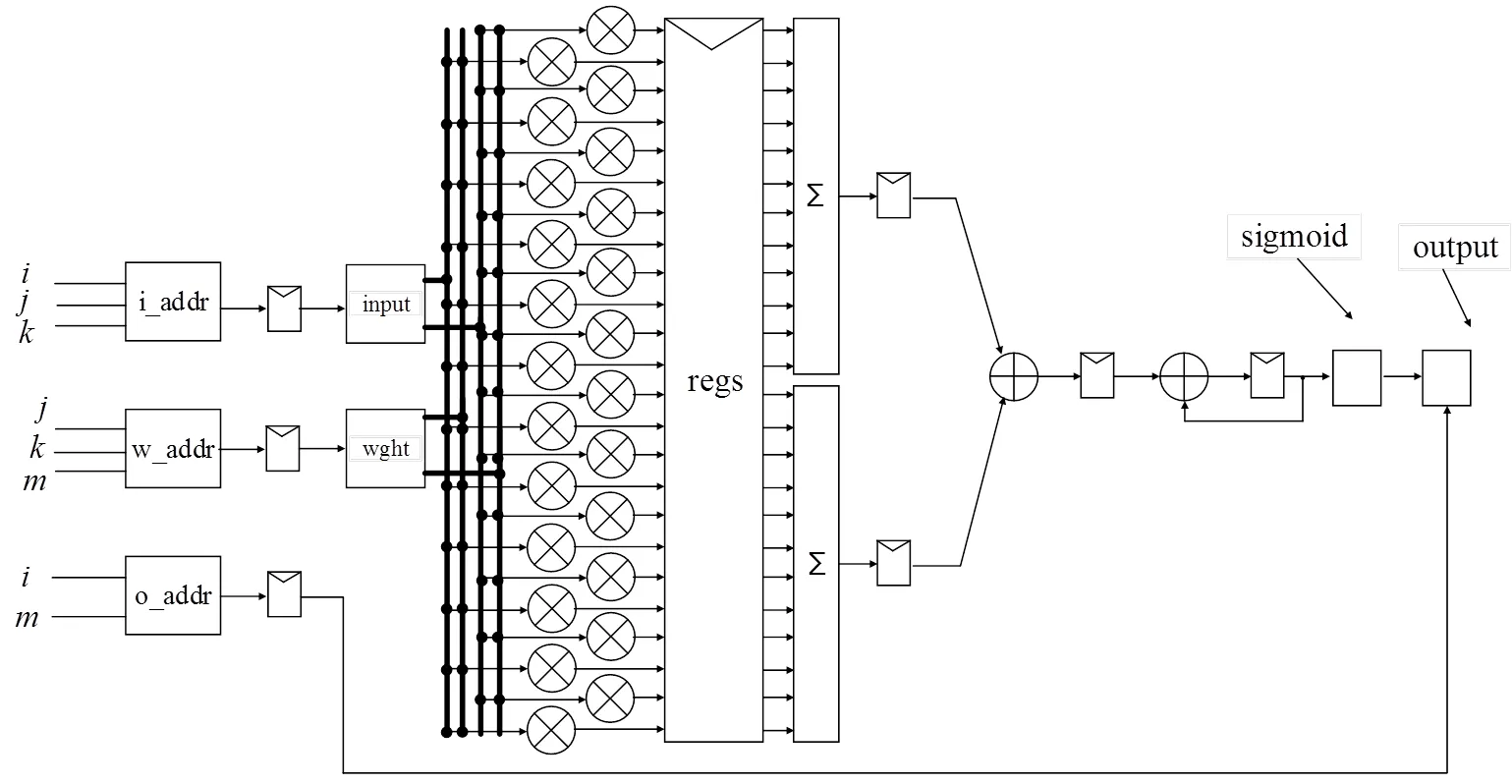
图10 全连接层的流水线示意图
3.4.1 sigmoid模块设计依据
1)本设计使用的定点数包含10位二进制小数,近似计算结果误差不应超过0.001;
3)当输入大于8时,函数值与1的差值小于0.001。
线性近似线段参数的计算:区间[0, 8]等分为32段,连接函数图像在相邻两分点的交点,得到线性近似;计算各线段的斜率和截距。可以验证,近似计算的误差不超过0.001。
3.4.2 模块计算过程
1)对输入取绝对值;
2)根据绝对值进行近似计算;
3)根据原数据符号,决定是否使用1减去第2步的结果;
4)输出结果。
4 实验结果与分析
4.1 实验平台和条件
本设计使用MNIST数据集作为训练和测试数据。PC配置:i5-3570,8GB DDR3-1600 MHz;开发板上的Soc FPGA芯片是5CSEMA5F31C6,逻辑容量为85 K,并包含一个以cortex-A9双核CPU为核心的HPS。首先在PC上使用C语言编写的程序(单精度浮点版本)进行网络训练(样本已预处理),得到参数;然后对参数定点化处理作为FPGA加速模块的参数;最后使用相同的测试集进行测试,与PC上定点版本的正向预测过程进行对比。CNN加速模块最终工作频率为100 MHz。
样本数据预处理:原MNIST数据集使用uint8存储数据;若采用20位定点数,则用原MNIST数据集运算很可能导致溢出,产生错误,因此对样本进行预处理:设定阈值,当输入数据不超过该阈值,那么保持原值,否则输出阈值。本设计使用16作为阈值。
4.2 实验结果
实验结果分2部分:PC上的正向预测过程错误率6.43%,平均每个样本耗时852 us;FPGA方案错误率为6.43%,平均每个样本总耗时164 us,因此加速效果为5.2倍。
本设计消耗的资源统计:
logic utilization:7%
DSP blocks:42%
total block memory bits:69%
total registers:4765
4.3 结果分析及改进
预测错误率6.43%与同类论文对比偏高,这是因为PC上网络训练过程中,只对训练集样本进行一次遍历,与FPGA加速模块的设计无关。另外,第二卷积层的实现中,一个时钟周期同时计算12个输出特征图的元素,每个输出元素需要计算6对乘法,因此峰值性能能够得到7.2 GMAC/s(工作频率100 MHz)。对于本设计实现的CNN网络算法,一个样本的处理需要约2.06×105次乘累加操作,因此加速模块的平均性能达到1.26 GMAC/s。对比文献[5]中的性能,本文提出的设计性能更优。另外,文献[5]中使用浮点数进行数据处理,以及关于激活函数计算使用查表法,都导致较高的BRAM使用率。
在正向预测过程中,卷积层用时最长,特别是第一卷积层,因其输出矩阵尺寸较大且模块的并行度不高(每个时钟计算5次乘法)。可以考虑将第一卷积层的输入数据的存储器从1个扩展为5个,那么可以同时从5个存储器获取数据来源,从而提高模块并行度;而由此导致BRAM不足的问题,将输入样本数据进行二值化即可。
5 结论
本文提出的基于FPGA的CNN加速器设计,采用流水线和并行计算的方法,提高了加速器的吞吐率;使用时分复用的方法以及用定点数代替浮点数,降低了资源利用率。通过采用MNIST数据集进行测试,对比PC运行的C语言程序,在相同预测准确率的情况下,性能是PC实现的5.2倍。
[1] 毕占甲.基于多GPU的多层神经网络并行加速训练算法的研究[D].哈尔滨:哈尔滨工业大学,2015.
[2] Strigl D, Kofler K, Podlipnig S. Performance and scalability of GPU-based convolutional neural networks[C]. 18th Euromicro Conference on Parallel, Distributed and Network-Based Processing, 2010.
[3] 刘琦,黄咨,陈璐艳,等.基于GPU的卷积检测模型加速[J].计算机应用与软件,2016,33(5):226-230.
[4] Zhang Chen, Li Peng, Sun Guanyu, et al. Optimizing FPGA-based accelerator design for deep convolutional neural networks[C]. In ACM Int. Symp. On Field Programmable Gate Arrays, 2015:161-170.
[5] 余子健.基于FPGA的卷积神经网络加速器[D].杭州:浙江大学,2016.
[6] Suda N, Chandra V, Dasika G, et al. Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks[C].Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. ACM, 2016: 16-25.
The Realization of the Convolution Neural Network Based on FPGA
Li Jiahui Cai Shuting Chen Xuesong Xiong Xiaoming
(School of Automation, Guangdong University of Technology)
Convolutional Neural Network is a computation intensive algorithm based on deep learning, and it is common used in image classification, video recognition, etc. Due to the powerful parallel capability and flexibility of FPGA, it is frequently used as the platform to implementation of CNN. Meanwhile, the rapidly emerging mobile application of deep learning suggest that it is very significant to implement a CNN on mobile platform. Therefore, a DE1-Soc development board was used to implement a CNN network by Verilog HDL approach, using mnist as samples data. Finally, the implementation is 5.2 times faster than that on PC.
Convolution Neural Network; FPGA; Performance Acceleration
李嘉辉,男,1991年生,在读硕士,主要研究方向:FPGA加速、深度学习。
蔡述庭(通讯作者),男,1979年生,博士,副教授,主要研究方向:FPGA加速、深度学习。E-mail:shutingcai@126.com
陈学松,男,1978年生,博士,副教授,主要研究方向:强化学习、机器学习。
熊晓明,男,1956年生,博士,教授,主要研究方向:IC设计、EDA技术。
国家自然科学基金(61201392);广东省自然科学基金-自由申请项目(2015A030313497)。
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
中国资源综合利用(2016年9期)2016-01-22 08:35:22
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
