
基于前馈神经网络的焓差试验台故障预测
2018-04-16 01:59蔡博伟陈江平施骏业
制冷技术 2018年6期
蔡博伟,陈江平,施骏业,2
(1-上海交通大学制冷与低温工程研究所,上海 200240; 2-上海高效冷却系统工程技术研究中心,上海 200240)
0 引言
焓差试验台性能试验是空调系统优化过程中不可或缺的一环。焓差试验台是一个复杂的系统,包括压缩机、冷凝器、蒸发器、膨胀阀、连接管路等元器件。系统零部件和传感器的可靠性对空调系统台架试验的结果会产生重要影响。一旦系统发生故障,轻则影响台架试验结果精度,重则需要重新进行台架试验,并且可能存在安全隐患。状态监测与故障预测技术是降低焓差台故障率、保证试验顺利进行的有效手段。
焓差试验台常见的故障包括压缩机故障、风机电压异常、控制器故障、元件温度过高、气体压力过高、气体压力过低、水箱液位过高等[1]。目前的焓差试验台故障处理主要是依赖于操作与检修人员的经验,在故障发生后进行处理。该方法存在如下3 方面的问题。
1)外部依赖强。依赖于少数专家经验,成本比较高,且缺少成体系化的故障预测与处理能力。
2)预测能力弱。大多数故障处理方法的目标是在故障发生后能够快速响应,缺乏提前预测故障发生的能力。
3)缺乏通用型。不同专家经验能够处理的故障类型是不同的,缺乏能预测或处理通用故障的能力[2]。
以前的焓差台试验主要关心系统在稳定状态下的参数,试验数据积累较少。随着大数据技术的发展和相关状态监控设备的完善,焓差试验台积累的状态数据迅速增加。基于大数据找到一种数据驱动、准确率高、实用性强、不需要额外增加传感器的故障预测模型,成为工业界与学术界关注的一个热点[3]。
目前大多数相关的研究集中在两方面。一方面的研究是以神经网络为代表的机器学习技术在故障预测方面的应用。东南大学的钱宇宁[4]将基于一个三层BP 神经网络的粒子平滑算法用于机械系统旋转部件的故障预测,达到了远小于传统粒子滤波算法的平均误差。袁玥等[5]采用主成分分析和神经网络相结合的方法诊断制冷剂充注量故障,达到了97%以上的正确率。康健等[6]将神经网络用于发动机故障预测,使用15 个输入特征,获得了与实测计算值吻合的预测结果。寻惟德等[7]利用离散型Hopfield 神经网络提出制冷剂充注量故障预测新策略,使用18 个特征变量,达到了超过70%的总体故障诊断率。禹法文等[8]使用主成因分析(Principal Component Analysis,PCA)这一机器学习方法对多联机系统压缩机排气感温包漂移、脱落、精度下降以及完全失效故障进行诊断,其中对完全失效故障的检测率达到了100%。GEBRAEEL 等[9]基于轴承的历史退化数据建立神经网络模型,成功预测了轴承的退化轨迹。LIUKKONEN 等[10]使用神经网络与专家系统的复合模型分析电子产品的质量并诊断可能发生的故障,并分析了输入特征的变化对模型性能的影响。上海交通大学[11]、华东科技大学[12]等也进行着使用支持向量机机器学习技术进行故障预测的研究。另一方面的研究是以神经网络为代表的机器学习技术在热系统性能分析和预测方面的应用。韩国首尔大学的YANG 等[13]通过建立人工神经网络模型,预测不同环境和不同目标温度下室内热系统的最优启动时间,从而更好地控制热系统的启停,达到节能的目的。也研究了不同学习率、不同惯性系数、不同隐藏层数目、不同隐藏层节点数以及不同偏差参数对模型性能的影响。香港中文大学的ZHU 等[14]利用神经网络模型预测再生式换热器的出入口空气温度变化,达到了4%左右的误差水平,并基于模型分析了入口空气温度、入口空气相对湿度、入口空气速度等对系统性能的影响。魏峥等[15]比较了神经网络等机器学习模型和多元多项式模型、半经验公式模型在冷水机组能耗模型辨识上的性能差异,结果表明机器学习模型具备较高的计算精度,且可以在线实时建模。这些研究证明了基于数据驱动的神经网络模型对于系统状态的分析和预测能力。系统状态的异常往往与故障有着紧密的联系[16]。
本文基于焓差试验台长期运行数据和故障日志,提出了数据驱动的焓差试验台故障预测策略,并使用前馈神经网络模型建立了故障预测模型,并在测试集上验证了该模型对焓差试验台故障预测的有效性。
1 焓差试验台故障统计与分析
基于模型的焓差试验台数据从2015年11月30日开始记录,到2017年3月24日结束。在这期间,共有618 条故障报警日志,每一条日志可能包括多个类别并发的报警,一共获得968 条的报警数据,包括55 类不同的报警信息。
从图1的报警数据分析可以看出,焓差试验台的故障报警主要集中在风源水箱液位警告和公共水箱机组蒸发压力过低,共占了总报警数量的51.96%。此外,试验间压差过大、风源等温电加热温度过高、压缩机排气温度过高等也是较为常见的故障,其报警数均在30 以上。

图1 焓差试验台故障报警统计
2 前馈神经网络模型原理
2.1 前馈神经网络模型
深度前馈神经网络是多层神经网络节点组成金字塔形的层级结构。每个网络节点的权重基于反向传播算法更新,从训练集数据中学习得来。随着训练次数的增加,模型精度也会逐步提高,直到趋于稳定。前馈神经网络结构如图2所示。
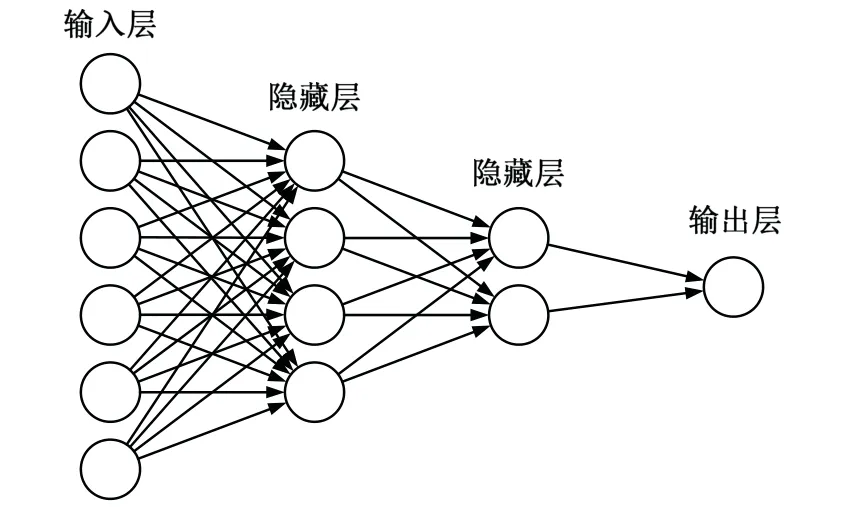
图2 前馈神经网络模型示意图
2.1.1 基本结构
每一个神经网络节点是类感知机结构的单一神经元,如图3所示。
其中x为输入特征,w为对应特征的权重,b为偏置量,σ为激活函数。
多层神经元组成金字塔形的层级结构,即深度前馈神经网络。在本模型中,每个时间节点的54个数据特征作为输入特征,经过第一层的神经元后,其输出又作为第二层神经元的输入特征,以此类推,直到神经网络的最后一层。这是神经网络的前向传播过程。
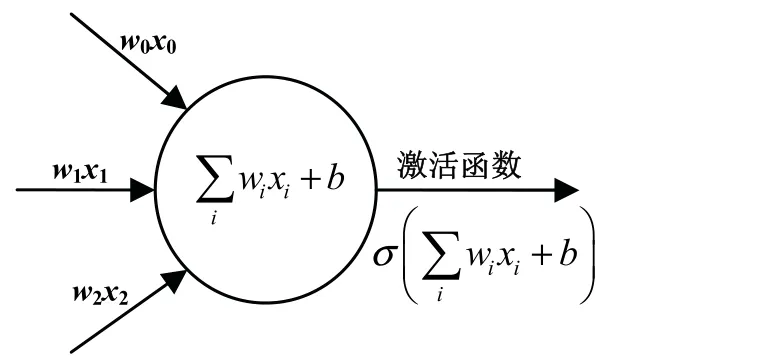
图3 神经网络节点结构
2.1.2 激活函数的选择
在神经网络单元中,权重与偏移量只能产生线性变化。需要引入激活函数,对节点进行非线性变换,使得神经网络具有良好的学习和泛化能力。
人工神经网络常用的激活函数有以下3 种。
1)Sigmoid 函数
Sigmoid 函数的公式如下:

Sigmoid 函数的输出映射范围为(0,1)的实数域,单调连续,输出范围有限,可以达到比较稳定的优化。
2)Tanh 函数
Tanh 函数的公式如下:

Tanh 函数比Sigmoid 函数收敛速度更快。其输出映射范围为(-1,1)之间的实数域。
3)Relu 函数
Relu 函数的公式如下:

即当x>0 时,取值为x;否则取值为0。
前两种激活函数在层数较多的神经网络结构中都容易产生梯度消失的现象。即因为处于函数饱和性区间导致在误差的反向传播过程中梯度过小,影响网络的优化效果。Relu 函数是一种非饱和的函数,可以有效地解决梯度消失的问题。
模型采用Relu 函数作为输入层和隐藏层的激活函数,输出层则采用Sigmoid 函数。在神经网络层数增加时,这样的激活函数组合可以防止梯度消失,也能将最终的输出映射到(0,1)之间,实现故障的二值化预测。
2.1.3 代价函数与反向传播算法
模型需要一个代价函数作为最优化问题的目标函数。定义交叉熵函数作为神经网络模型的代价函数:
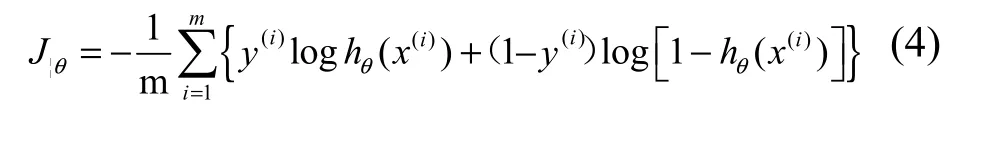
式中:
x(i)——第i 个输入样本;
y(i)——第i 个输出样本;
m——样本数量;
ℎθ——基于参数θ的神经网络模型。
模型建立起来后,关键是基于训练集数据对神经网络的节点权重进行优化,降低代价函数值。权重优化和迭代采用的是反向传播算法。
神经网络最后一层的输出值与真实值之间的误差,通过神经网络从输出层向隐藏层反向传播,直至传播到输入层。在误差信息反向传播的过程中,神经网络可以利用误差更新网络内部的各种参数,不断迭代这个训练过程,直至代价函数收敛。这也是神经网络模型学习能力的核心所在。
误差在两层之间反向传播的计算公式为:

式中:
δl——第l层的误差;
w——对应特征的权重参数;
σ——激活函数;
zl——第l层的带权输入;
T——矩阵转置符号;
⊙——向量点乘符号。
2.2 模型评价指标
故障预测的准确与否是一种可以标准化的离散值。对于这样的二值问题,如果使用准确率作为模型评价,能考察测试集中预测结果符合真实结果的样本比例,但并未能区分假正例与假反例的不同影响。特别是对于正反例数量不均衡的样本,准确率对模型实际性能的指示作用并不明显。
引入查准率、查全率与F1系数3 个模型评价指标[17]。其计算公式如下。
查准率:

查全率:

F1系数:

式中:
nTP——预测结果中真正例样本数;
nFP——预测结果中假正例样本数;
nFN——预测结果中假反例样本数。
查准率表征模型预测的正例中准确的比例,查全率表征实际的正例样本中模型预测准确的比例,F1值是这两者的调和平均。模型参数评估以F1系数为最重要的评价标准,同时也参考查准率和查全率。
3 前馈神经网络模型的建立
3.1 数据源分析
数据基于某冷热产品试验设备高新技术企业的焓差试验台,包括从2015年12月24日到2017年3月28日间的试验台架数据记录和报警日志,存在部分数据缺失。原始数据共有54 个输入特征,包括风源送风和出风的干球温度、湿球温度、相对湿度、喷嘴压差、进口容积风量,以及蒸发器、冷凝器的空气侧和制冷剂侧换热量、进出口温度和压力、出口过热度等。取每一天焓差试验台最早的4 组数据作为数据样本,样本间隔时间≤1 min,预测当天运行过程中是否发生故障报警。随机地取其中的75%的数据,作为训练集与验证集输入样本,采用5 折交叉验证策略训练与优化模型。剩余的25%数据作为测试集输入样本,用于测试模型的最终性能。原始数据输入特征统计结果如表1所示。

表1 焓差试验台数据输入特征统计
3.2 前馈神经网络模型建立流程
如图4所示,首先对焓差试验台原始数据和故障日志进行数据预处理和标准化,生成原始数据集。将数据集划分成两个部分,一部分是供每一个模型训练和优化的训练集和验证集,另一部分是供模型性能评估的测试集。之后基于训练集和验证集,搭建和训练神经网络,并采用多种策略进行优化与迭代。最终在测试集上进行模型的性能评估。
3.3 数据预处理与标准化
3.3.1 缺失特征与异常特征的处理
焓差试验台中由于传感器的不稳定,可能会产生一些缺失的数据,但占总体数据的比例较小。对于这样的缺失数据,一般有2 种处理方法:一种是删除含有缺失数值的数据行;另一种是采用其他逻辑合理的数值补全。模型中采用后者,使用该特征的平均值替代缺失的特征数据。
原始数据中可能存在少部分脱离合理范围的数值,比如温度、压力数据超出合理范围。对于多数机器学习模型,需要移除掉这些异常数值,但是我们的模型就是对试验台架故障进行预测,这些异常值可能也是台架故障的一种指示性预测特征。因此,这部分异常数值对于我们预测故障的模型来说就是有效的特征,应该保留。
报警日志是简单的非结构化的文本日志,主要记录报警时间和故障内容。采用Python 文本处理脚本对日志进行处理,映射成结构化的数据,包括时间信息和序列化后不同类型的报警信息。

图4 基于前馈神经网络的故障预测流程图
3.3.2 数据归一化
原始数据中,不同数值的波动范围是差别很大的。温度数据可能波动只有几十度,如果其他数据数值波动范围远远大于温度数据,会极大地降低模型初始化后梯度下降求最优解的速度,也会损害最终模型的精度,更容易陷入到局部最小值的次优解中。因此,需要采用合适的归一化方法,将数据放缩到相近的数据范围内。
常见的归一化方法有2 种。一种是最小-最大值线性归一化方法。同特征数值被放缩到[0,1]的有理数空间内。其计算公式如下:

式中:
x——输入特征值;
xmax——特征最大值;
xmin——特征最小值;
x∗——修正后的数值。
另一种为标准差归一化方法,同特征数值转化为均值为0,标准差为1 的标准正态分布。其计算公式如下:

式中:
μ——样本数据的均值;
σ——样本数据的标准差;
x∗——修正后的数值。
模型输入采用最小-最大值线性归一化方法,对原始数据进行归一化。
4 模型的迭代与优化
4.1 网络结构的优化
不同的网络结构对神经网络的性能会产生巨大的影响。一个理想的网络应该既满足性能目标,又不会有过高的计算能力要求。
关于网络结构,对比了2 种不同的方案。方案一为初始方案,使用最简单的2 层神经网络。即只有输入层、一层隐藏层与一层输出层,输入层不计入总层数,隐藏层节点数为10,即54-10-1 的网络结构。改良后的方案二采用5 层神经网络,即包括输入层、4 层隐藏层与一层输出层,网络呈现54-22-14-7-5-1 的结构。
不同方案的性能比较如图5。在网络层数加深后,模型的各项性能明显提升。5 层深度的神经网络结构比较合适目前的焓差台故障预测模型。

图5 网络结构优化前后性能对比
4.2 初始化优化
初始模型使用的是常规的随机参数初始化方案。优化方案采用He 初始化方案[20],其数学公式如下:

式中:
W——修正后的初始化数值;
W0——原随机初始化的数值;
nin——神经网络上一层节点数。
初始化优化前后的模型性能比较如图6。
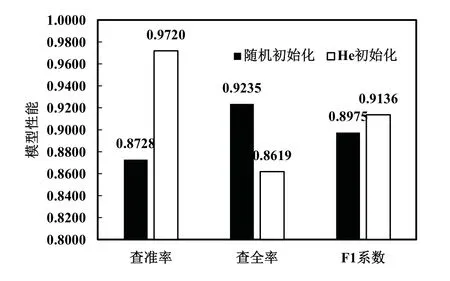
图6 初始化优化前后性能对比
4.3 小批量梯度下降
神经网络模型的训练是一个最优化问题,即寻找神经网络模型的误差在整个数据集状态空间内的最小值。每一次训练,神经网络都会使用反向传播算法更新网络的所有权重,直到收敛于极小值。最基本的做法是采用批量梯度下降法,每一次迭代时使用所有样本来进行权重的更新,这样能保证每一次权重更新后整个模型在训练集上的误差是减小的,能逐步趋近于最小值。
然而,基于整个训练集的误差计算和反向传播计算量比较大,会显著地降低模型的更新速度。因此,可以采用小批量梯度下降的方法,每一次训练一定数量的样本来对参数进行更新。这样可以极大地减小每一次模型训练的时间。虽然每一次更新不能保证模型在整个训练集上的误差减小,但是在多次训练中,模型能够快速地趋近于极小值。
模型采用每一批次100 样本量的样本进行小批量梯度下降更新。
4.4 正则化
评价神经网络性能的一个重要方面就是泛化能力[19]。一个神经网络可能在训练集上有着极好的表现,但是在测试集上的表现就会显著下降。这是因为神经网络将训练集数据独有的局部特征也学习进去,造成了过拟合。这表明训练过程中仅仅以模型在训练集上的误差进行衡量是不够的。越复杂的模型,能学到越多的局部特征,尤其是训练集数据的独有特征。越简单的模型,其泛化能力越好。
因此需要在代价函数中引入正则项来对抑制训练过程中对复杂模型的偏好。常见的正则化有一次正则项与二次正则项。模型采用二次正则项,其代价函数公式如下:

式中:
J0——原代价函数值;
w——权重系数;
α——正则化系数。
当权重系数越大,其代价函数值会显著变大。而神经网络学习的过程就是通过更新权重降低代价函数值,因此在训练过程中模型会趋向于权重值约接近0、越简单的模型。
4.5 引入动量项
模型使用反向传播算法更新神经网络的权重,学习率越小,每次权重更新变化幅度也就越小,学习速度也会更慢。如果学习率过大,可能会使得神经网络的权值变化量不稳定,陷入振荡。因此,可以在权重更新方程中引入动量项[20]来加速学习过程,同时保持稳定。
其公式如下:

式中:
Wn——模型第n次更新时的权重;
J——代价函数;
η——学习率;
α——动量项系数。
引入动量前后的前馈神经网络模型性能对比如图7。

图7 引入动量前后性能对比
4.6 最终模型性能评估
经过多次的优化与迭代,最终的模型是一个54-22-14-7-5-1 的5 层前馈神经网络结构,使用He初始化方案[20],具有2 次正则项和动量项,并采用小批量梯度下降方案的模型。
在基于真实数据的焓差试验台测试集上进行性能测试,模型达到了93.33%的查准率与95.02%的查全率,以及94.14%的F1系数。模型整体性能较好,具有进一步应用于焓差试验台故障预测的潜力。
5 结论
本文针对焓差试验台故障预测问题,基于真实的空调系统焓差试验台的长期运行数据,建立了一种基于人工神经网络的焓差试验台故障预测模型,并定义了查准率、查全率与F1系数作为模型的评判依据。根据以上分析结果,得到以下结论:
1)该前馈神经网络模型结构简单,层数适中,算法具有较好的实用性;
2)该前馈神经网络模型在一年的实验工况下,焓差台故障达到了93.33%的查准率与95.02%的查全率、以及94.14%的F1 系数。模型已经达到了较好的性能参数,为焓差台故障预测提供了一种基于机器学习和数据驱动的解决思路;
3)目前焓差台具有多种类型的故障。可以在模型的基础上进一步优化模型的预测粒度,实现不同类型的焓差台故障预测。
猜你喜欢
现代仪器与医疗(2022年3期)2022-08-12
现代电力(2022年2期)2022-05-23
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
装备制造技术(2020年11期)2021-01-26
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
电子制作(2019年19期)2019-11-23
制造技术与机床(2019年6期)2019-06-25
电子制作(2019年24期)2019-02-23
