
关系数据库SQL代码的自动评分算法研究
2018-04-13 01:07吴娇娇何小卫
计算机技术与发展 2018年4期
吴娇娇,何小卫,赵 洋
(浙江师范大学 数理与信息工程学院,浙江 金华 321004)
0 引 言
随着计算机技术与应用的快速发展,数据成为所有计算机应用的操作对象。在进行各种信息处理的过程中,数据占据着不可取代的地位[1]。由此可见,在计算机处理的背后,数据库体系发挥着重大作用,对数据库的学习也成为掌握计算机技能必不可少的条件。在数据库的初级学习过程中,最重要的莫过于学习SQL(structured query language,结构化查询语言)。SQL语言结构清晰,但是编码有着多样性及结果不易观察的特点,使得代码的评分标准变得界限模糊,人工评判工作愈加繁重[2]。为减轻人工评测负担,构建自动评分模型及系统刻不容缓。而科学合理地评测SQL代码,也成为构建模型的一个重要问题。
目前,代码的自动评分技术主要分为动态测试和静态分析[3]。动态测试是通过代码执行的结果判定代码的正确性;而静态分析主要是通过分析代码的结构特征及语义信息评判代码。采用动态测试的评分系统,主要用于检测VB程序,如段汉周等[4]提出的自动评分系统,以及检测Java程序的BOSS系统[5];采用静态分析的评分系统发展得较为成熟,比如用系统依赖图分析语义相似度的基于语义相似度比较的编程题自动评分方法[6]和基于程序理解的编程题自动评分方法[7];当然,也有结合了动态测试和静态分析的Course Master系统[8]。
文中借鉴程序代码的自动评判技术,针对SQL代码的特殊性,采用静态分析方法构建自动评分模型,并通过实验对其进行验证。
1 自动评分模型
自动评分模型采用静态分析的方法,总体流程如图1所示。预处理删除及处理了一些语句,使SQL语句表达统一化与规范化;对SQL代码进行词法分析,对SQL代码每一部分进行分类,提取出特征结构,并进行分词处理,获得片段代码;构建同义库,对SQL片段代码的相似语句向操作符少的语句转化;利用LCS算法对参考片段代码与要测评的片段代码进行相似度比较,得到片段代码的相似度;对代码片段赋予相似度影响因子,计算出两SQL代码总的相似度;统计人工评审数据,用多项式拟合出相近数据,据此制定相应的评分策略。
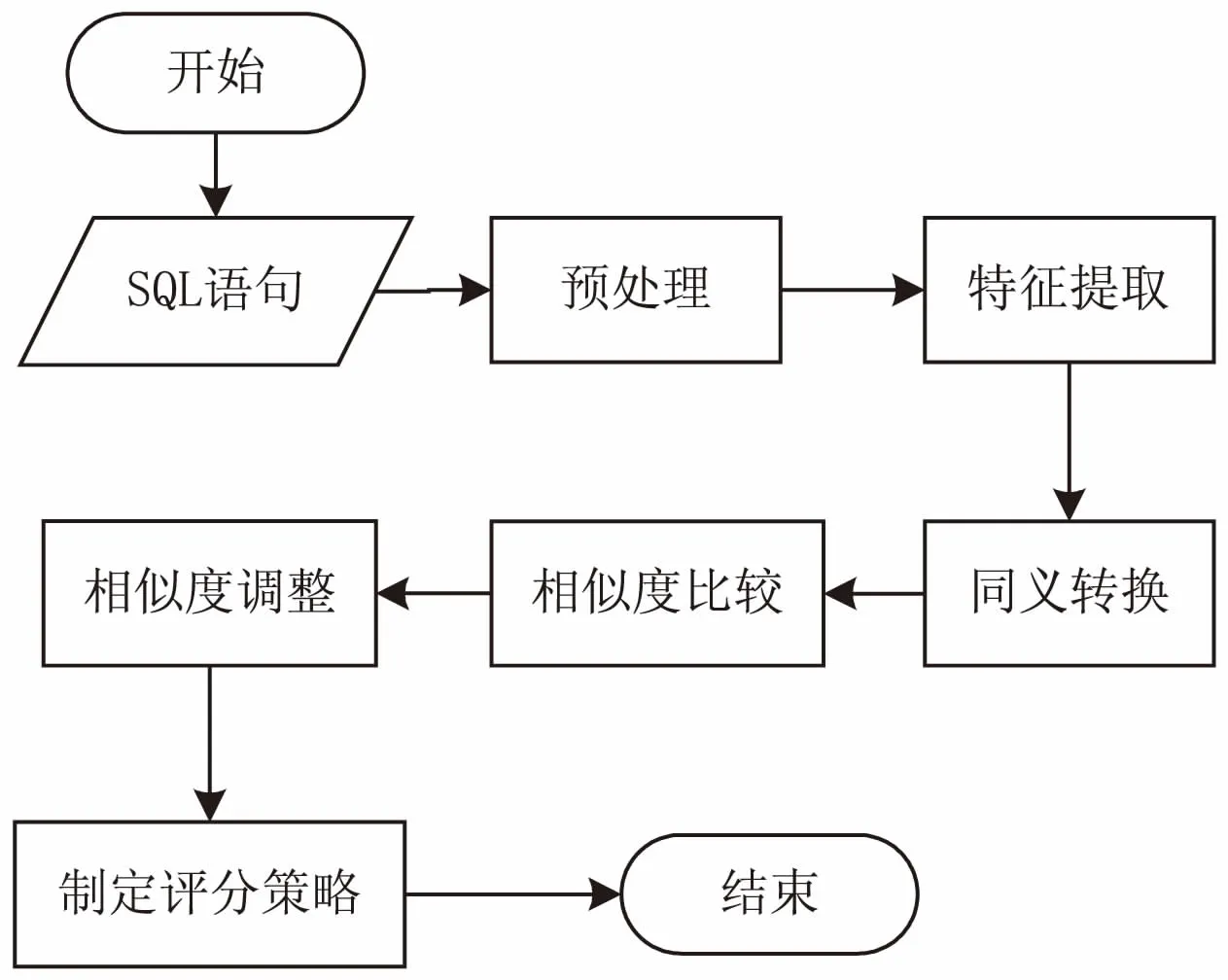
图1 自动评分模型总流程
1.1 预处理
由于书写SQL语句时的不规范性和SQL语句表达的多样性,为更好地识别SQL代码,首先需要对SQL代码进行规范化预处理,预处理流程见图2。
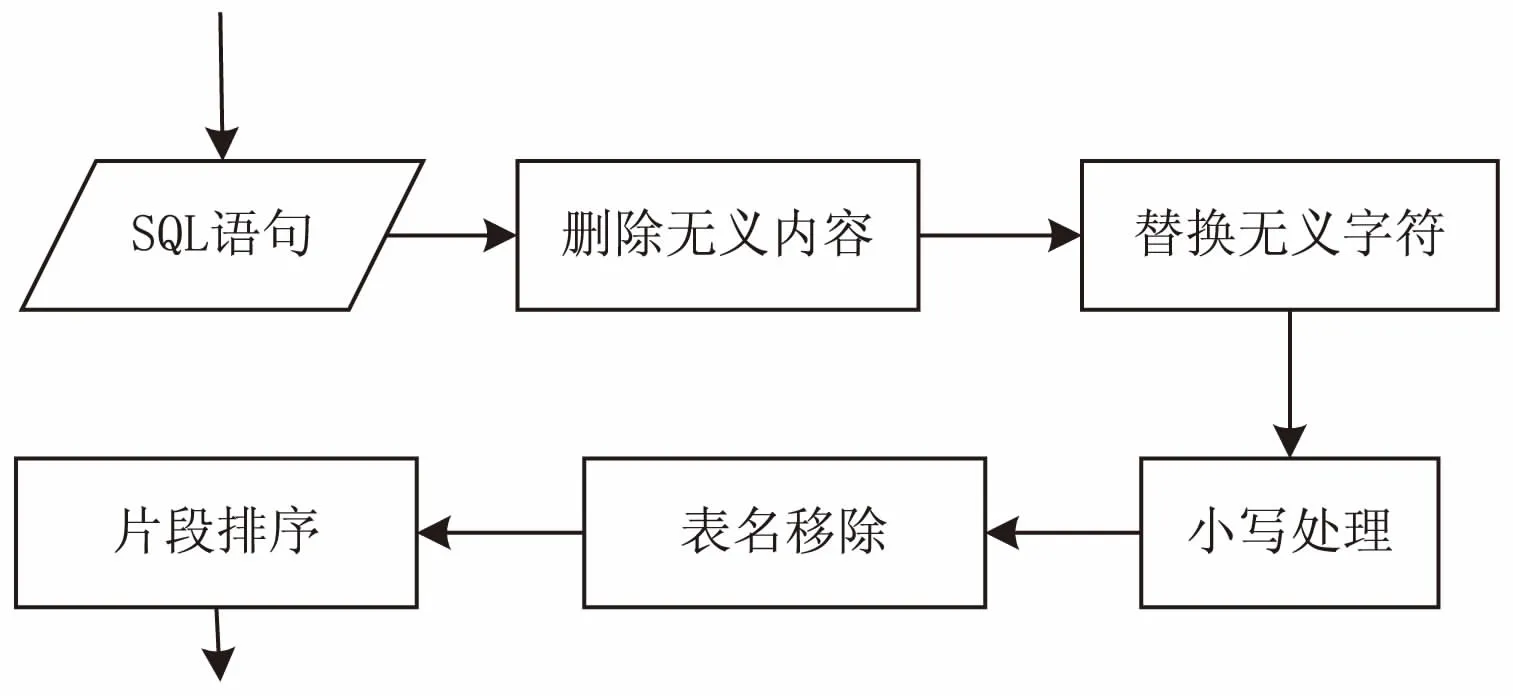
图2 预处理流程
(1)删除注释以及与SQL代码语义无关的内容;SQL代码中的注释可以随意敲入而不影响代码结构及语义,这对特征提取无用,因此,移除一切与语义无关的代码。
(2)用空格代替SQL语句中的回车符,以及移除多余的空格[9];在敲写代码的同时,可能无意地敲入一些空格、回车符等无义字符,使得代码愈加繁琐,需要移除,使得代码简洁明了。
(3)将SQL代码全部变成小写形式;统一规范大小写,也可以全部转化为大写形式。
(4)对于表名加字段名的代码,将表名移除,留下“.+字段名”。为体现代码中带有表名,保留“.”,但为了代码的易于识别,移除会给相似度带来较大误差的表名。例如:“select table1.ename, table2.ename from emp table1, emp table2 where table1.mgr=table2.empno;”进行处理后可转化为“select .ename, .ename from emp table1, emp table2 where .mgr=.empno;”。
(5)对SQL代码的各个关键词之间的字段以及子句按ASCII值先后顺序排序。其目的是保证相似语义的代码片段相似度匹配时能获得最大相似度[10]。例如:“select c1,a2,b3 from t1,t3,t2 where condi3=3 or condi1=1 order by o6,o2”进行排序处理后,可以转化为“select a2,b3,c1 from t1,t2,t3 where condi1=1 condi3=3 or order by o2,o6”。
1.2 特征提取
对SQL代码的特征提取及分词,首先对代码进行词法分析,然后将代码转化为可识别的含结构和语义信息的字符串序列。
由分析可知,SQL语句有其特有的语法规则以及明确的关键字,在评分时,关键词占据较大的比重,先查询到关键词的正确率,才会逐步分析关键词之后的字段差异。因此在提取结构时,首先按照关键词提取SQL的结构特征。将SQL代码进行分类标识,分为关键词和关键词之后的字段,并分别为此分配不同的类型,作标记为:keyword,body。可将SQL语句表述为:
SQL={ (Word1,C1) … (Wordi,Ci)|i∈N+}
(1)
其中,Wordi为SQL代码的关键词或关键词之后的字段;Ci为标记keyword或body。
给定如下SQL代码:update emp set sal=newsal where eid=id;可转化为(update,keyword)(emp,body)(set,keyword)(sal=newsal,body)(where,keyword)(eid=id,body)。
1.3 同义转换
在评分过程中,两段不同代码实现的功能及得到的结果一致,就可以认为这两段代码是相同的。SQL语句中存在一些相似句,虽然表现形式不一,但可以得出相同的结果,这些句子可称之为相似句。判断字段:sal between 3 000 and 5 000,它相当于sal>=3 000 and sal<=5 000;sal in (3 000,5 000)相当于sal=3 000 or sal=5 000,某些情况下的连接字段:from a1 left outer join a2 on a1.name=a2.name,和from a2 right outer join a1 on a1.name=a2.name。
相似度比较并不能很好地识别相似句,因此为提高匹配的精确度,对代码进行相似句转化很有必要。为精简转化,对相似的语句建立语句同义库,常用等价语句如表1所示。转化的过程向同义库规则靠拢。文中规定,将操作符多的向操作符少的转化,如前段判断字段所述,相同操作符的按ASCII值从大向小转化。

表1 常用等价语句表
1.4 基于LCS的相似度比较
计算相似度本质上是对要比较的字符串与标准字符串之间进行字符串匹配。对于字符串匹配研究,现今已发展到较为成熟的水平,尤其在相似度检测方面。字符串匹配算法大体上分为精确匹配与近似匹配,近似匹配就是在匹配时允许字符串出现一些误差。精确匹配主要应用于文本查找、网络安全等方面,近似匹配的应用域较为广泛,包括信号处理、生物DNA信息检测、语音识别、信息查询、相识度检测、查重等。字符串相似度匹配算法有简单字符串匹配,基于字符距离的算法[11],基于GST算法[12]或局部过滤的字符串比较。
经过特征提取,抽取出了keyword以及body。由于对SQL进行分词过程相当于对关键词进行抽取匹配,因此相似度比较只需比较关键词之后的字段即body字段,也可称之为body代码片段。body代码片段有其特有的规则和约束,有一定的规律和固定的表现形式。文中采用一种经典的简单字符串比较算法-最长公共子串算法进行相似度比较。LCS的经典算法有两种:动态编程(DP)或者后缀数组(suffix array)。文中采用DP求解最长公共子串。
针对该模型的最长公共子串问题可表述为:给定两个代码串,即参考代码的body片段S1,评测代码的body片段S2;求解S1,S2两代码串之间最长的相同字符串的长度。
定义1:
(1)两个字符串:参考body代码片段S1=[a1,a2,…,am],评测body代码片段S2=[b1,b2,…,bn],m,n∈N+,a1,a2,…,am为body代码片段S1中的每个字符,b1,b2,…,bn为body代码片段S2中的每个字符;
(3)由SL[i][j]可得对应的最长公共子串,标记为:LCS(S1,S2);
(4)最长公共子串的长度为max(SL[i][j]),i∈{1,2,…,m},j∈{1,2,…,n}。
若S1[i+1]和S2[j+1]不同,那么SL[i+1,j+1]就应该为0,因为任何以它们为结尾的子串都不可能完全相同;而如果S1[i+1]和S2[j+1]相同,那么只要在以S1[i]和S2[j]结尾的最长相同子串之后添上这个字符即可,这样就可以让SL增加一位;值得注意的是,若S1,S2中任何一个是空字符串,那么最长公共子串的长度SL就为0。这是一个递归问题的求解,为了更直观形象地表述,可以得到状态转移方程:
(2)
通过SL[i][j]可以得到对应的最长公共子串LCS。
定义2:参考和评测body代码片段的相似度为:
(3)
其中,S1.length和S2.length分别为字符串S1和S2的长度。
定义了以上两条,就可以对body代码片段进行相似度计算。编写代码,经过整合,可以得到一个相似度集合,将该集合表达成一个向量,以便观察。相似度集合表示为:
Similar=(sim1,sim2,…,simN),N∈N+
(4)
例1,现有两个SQL代码:S1={select count(ename), avg(sal), floor(sysdate-hiredate/365) from emp, info where ename='li' group by(deptno);};S2={select count(ename),floor(sysdate-hiredate/365) from emp where ename='li' group by(deptno);};根据定义1、定义2及式(4),可得到相似度集合similar=(1,0.83,1,0.43,1,0.92,1,1)。
(2)金标记BLI检测。将光纤传感器末端置于奶液中(200μL牛乳+50μL缓冲液+5μL金标BSA)中平衡120 s;然后,将光纤传感器末端没入待测奶液(200μL待测牛乳+50μL缓冲液+5μL金标氯霉素素单克隆抗体)中700 s。检测牛乳中氯霉素残留量。
1.5 相似度调整及评分策略
SQL评分时各个部分所占评分比重的不一致,使得对各个部分的相似度增加影响因子的处理很有必要[13-14]。又因为SQL评分时关键词对评分结果的影响较大,所以需赋予关键词较大的影响因子。为了使自动评分的结果更接近人工评审的结果,通过实验将影响因子定为:(α1,α2,…,αN),N为字段的个数,有以下约束关系:
(5)
赋予影响因子后的总相似度为:
SQLSim=sim1*α1+sim2*α2+…+simN*αN
(6)
从例1中可以得到总的相似度SQLSim=1*1/6+0.83*1/12+1*1/6+0.43*1/12+1*1/6+0.92*1/12+1*1/6+1*1/12=0.93。
为使自动评分更贴近人工评审,根据人工评判结果制定了评分策略。据人工评判数据统计,得到相似度sim和分数score的关系图(见图3)。由图3可知,score和sim之间存在某种映射关系,通过多项式拟合,得到函数为:f(x)=-47.5x2+121.8x+21.8,波形如图4所示。
最终得到分数与相似度之间关系:score=-47.5 sim2+121.8sim+21.8,拟合误差∑Δx2=251.08。
可以评定出例子1的分数为94分。
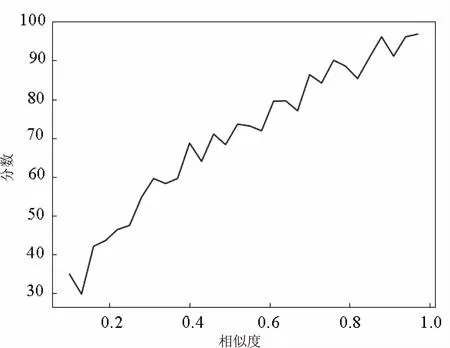
图3 人工评审得到的关系图
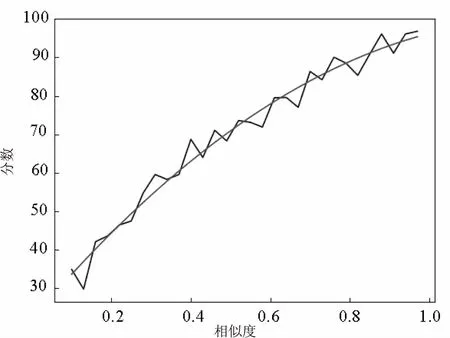
图4 拟合后的关系图
2 实验结果与分析
从图4可以看出,折线波动较大,是由于人工评审时误差较大,容易受到主观因素的影响,存在误判的概率。而对于自动评判,客观评分减小了误判的概率。
2.1 人工评分和自动评分数据分析
由于评分策略采用人工数据拟合的方法,对于相似度已知的代码,自动评分已贴合人工评判给出的分数。除去计算相似度之后的影响,整体评测人工评分和自动评分的数据。
现有测试集:A班作业SQL代码,共计200条数据。对该测试集进行自动评分测试,统计准确率,如图5所示。
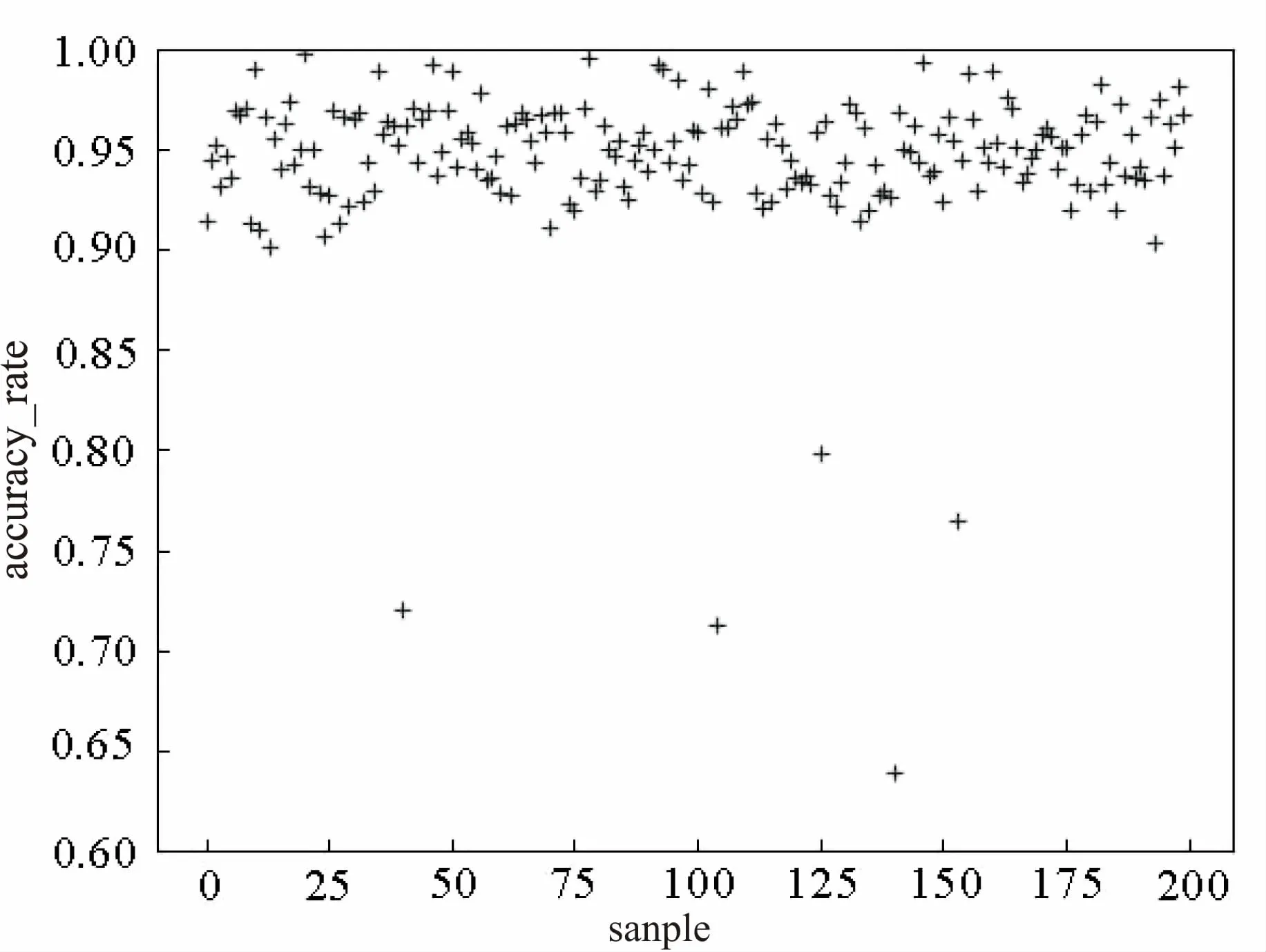
图5 样本的准确率
由图5可看出,样本的准确率区间大体在[0.92,0.98]之间,零星散落部分点在其他准确率较高和较低部分。据分析发现,较低部分的准确率是作业中出现了将关键词拼错,但是关键词之后的字段出错地方较少的情况。因此,除去关键词出错的情况,该自动评分模型对SQL代码的评分准确率高且稳定,总的来说可以达到较好的效果,因此可以定性地评判SQL代码。
2.2 相似度参数数据分析
SQL评分时关键词和body所占评分比重不同时,即影响因子不同,对评分准确率的影响也有差别[15]。为确定最精确的影响因子,实验统计了两个参数:关键词所占整个SQL代码的比重记为α,以及评分的准确率accuracy_rate;调整参数α,统计准确率。统计结果如图6所示。
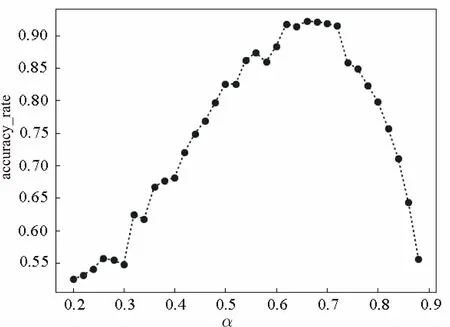
图6 α与accuracy_rate关系图
从图6可以看出,关键词的影响因子对评分的准确率有一定影响。在到达临界点之前,折线图大体随着α的增加而增加,临界点之后,准确率随α的减少而剧烈下降。经分析可知,这是由于SQL代码的结构性特点,评分时关键词需要占据一定的比重,如果比重过低体现不出SQL代码的结构,如果比重过高,难以体现细节之处。经过分析衡量,临界点大约在0.62~0.69之间,为便于计算,将关键词的影响因子定为总代码的2/3。
经过实验与数据统计,该模型可以对较长的SQL代码进行相似度匹配。采用同义库以及最长公共子串的算法,有效提高了自动评分的正确性。但是经过分析发现,自动评分也存在语义正确但是评分低的状况,如关键词错误。因此,对于关键词错误的情况,应该另行分析。
3 结束语
针对数据库SQL代码的评分,提出了新的SQL代码的自动评分模型。该模型借鉴了代码的静态分析方法,对相似语义构建了SQL代码的同义库,运用最长公共子串的算法对代码片段进行相似度匹配,又根据人工评判数据进行多项式拟合,制定了贴合实际的评分策略,并为此开发了原型系统。实验结果表明,该模型有效提高了SQL代码的评分效率及正确率,因此可以定量地衡量SQL代码的水平。但是,该模型存在一些问题,比如关键词出错的处理,尚需进一步深入,可作为未来工作的研究点。
参考文献:
[1] 解 萍.《数据库》课程在学生软件能力培养中的作用分析[J].科技视界,2012(15):101-102.
[2] 杨鹤标,刘 玲,杨立凡.基于结构相似匹配的SQL程序自动评估模型研究[J].计算机工程与科学,2010,32(11):92-96.
[3] 郑燕娥.Java编程题自动评分技术的研究与实现[D].泉州:华侨大学,2013.
[4] 段汉周,凌 捷,郑衍衡.VB程序设计考核自动评阅系统中若干问题的研究[J].计算机工程,2001,27(4):167-168.
[6] 王甜甜.基于语义相似度的编程题自动评分方法的研究[D].哈尔滨:哈尔滨工业大学,2005.
[7] 马培军,王甜甜,苏小红.基于程序理解的编程题自动评分方法[J].计算机研究与发展,2009,46(7):1136-1142.
[8] 牛永洁,张晓光.关于程序设计题自动评分方法的研究[J].信息技术,2010(11):155-156.
[9] CHEN Yaofei,CHEN Huantong.Research of automatic ma-rking on SQL server skill assessment based on XML[C]//International conference on web information systems and mining.Washington DC,USA:IEEE Computer Society,2010:8-12.
[10] HINKKA M,LEHTOAND T,HELJANKO K.Assessing big data SQL frameworks for analyzing event logs[C]//24th Euromicro international conference on parallel,distributed,and network-based processing.Washington DC,USA:IEEE Computer Society,2016:101-108.
[11] 王小凤,周明全,耿国华,等.一种基于字符距离的特征字符串近似匹配算法[C]//图像图形技术与应用学术会议.北京:北京师范大学出版社,2008.
[12] 徐黎明.基于GST字符串近似匹配算法的研究[J].内蒙古科技与经济,2016(7):87-89.
[13] KLEINER C,TEBBE C,HEINE F.Automated grading and tutoring of SQL statements to improve student learning[C]//Proceedings of the 13th Koli calling international conference on computing education research.New York,NY,USA:ACM,2013:161-168.
[14] 冯君远,赖明钦,李启良.C语言源代码抄袭识别的研究[J].福建电脑,2013,29(5):34-36.
[15] POHUBA D,DULIK T,JANKU P.Automatic evaluation of correctness and originality of source codes[C]//10th European workshop on microelectronics education.Washington DC,USA:IEEE Computer Society,2014:49-52.
猜你喜欢
无线互联科技(2020年11期)2020-12-01
新高考·高二数学(2016年7期)2017-01-23
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
股市动态分析(2015年16期)2015-09-10
中国信息技术教育(2015年21期)2015-09-10
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
