
基于知识关联度的电力大数据协同过滤推荐算法
2018-04-03 01:22:22曲朝阳刘耀伟
东北师大学报(自然科学版) 2018年1期
曲朝阳,周 宁,曲 楠,王 蕾,刘耀伟
(1.东北电力大学信息工程学院,吉林 吉林 132012; 2.吉林省电力大数据智能信息处理工程技术研究中心,吉林 吉林 132012; 3.国家电网江苏省电力有限公司检修分公司,江苏 南京 210024; 4.国家电网吉林省电力有限公司,吉林 长春 130021)
在智能电网深入推进的形势下,电力系统的数字化、信息化、智能化不断发展,带来了更多的数据源,电力系统运行时产生的数据数量庞大、增长快速、类型丰富,是典型的大数据.[1]如何根据用户的信息需求从海量数据中实时、快速、准确地向用户执行个性化的信息推荐,使其更好地为决策者服务,对电力系统提出了新的挑战.
推荐系统是信息检索、数据挖掘、机器学习和人工智能等领域的研究热点[2],个性化推荐技术对电力大数据个性化推荐的实现提供了有效支撑,因此电力大数据个性化推荐系统得到了广泛的关注,比如南方电网公司构建的电网情报智能个性化推荐系统,该系统通过检索日志对网络用户的信息需求与信息查寻行为进行分析和研究,在海量数据源中通过个性化推送的方式向用户执行信息推荐,从而保证信息推送的实时性和有效性.[3]
目前传统的推荐系统使用的推荐算法有基于内容的推荐、基于图结构的推荐、协同过滤推荐和混合推荐.[4]在众多的推荐算法中,协同过滤技术因具有较好的普适性、良好的推荐精度、共享他人经验的特点,在企业、政府等部门得到了广泛应用.传统的协同过滤推荐方法通过计算用户或物品的相似性来向用户进行推荐,推荐结果能够较好地反映目标之间的相似性,但相似的目标之间不一定具有关联性或关联程度比较低,不相似或相似度较小的目标之间也有可能具有关联性.协同过滤算法在向用户执行推荐的过程中,与目标相似的物品能够获得比较高的排名,但与目标相关联的物品有可能被忽略或排名比较低,因此针对这一问题本文采用基于关联规则挖掘和协同过滤的联合算法AR-Item CF,将目标物品之间的关联度作为影响推荐排名的因素之一,使得推荐结果的物品能够获得比较高的排名,从而实现向用户推荐既存在相似性,又具有关联性的推荐结果.
本文通过将电网领域知识组织成知识树,应用AR-Item CF对用户行为数据的Web日志挖掘,通过计算用户推荐列表得到最终推荐结果.实现不同知识项之间深层次的知识推荐,能够有效地解决上述问题并提升推荐质量和准确率.
1 基于知识关联度的电力大数据个性化推荐
1.1 知识树的构建
在电网领域,知识可概括为静态和动态2种.静态知识包括设备类知识、电力规程类知识[5]、电力故障诊断及决策知识[6]等;动态知识包括电网运行产生的实时数据和信息以及预测型知识,即由历史的或当前的数据推测未来的数据和状态,也可以认为是以时间为关键属性的知识.[7]不同知识之间没有明显的联系,用户理解困难,不能向用户提供有价值的推荐.对知识的查询往往涉及多张表,增加了查询的负担.
选择良好的知识表示方法不仅可以建立良好的知识结构,提高问题求解能力,而且有利于提高对知识的存储和检索效率,对减少关联规则的挖掘时间、提高挖掘效率有着重要的影响.将电网领域知识分解成不同粒度的知识项,使用知识树的结构将它们组织起来,有利于建立知识体系中的关联和推理机制,有利于知识的组织、管理和可视化,能够满足大多数知识表示的需求.
本文通过将电网数据按照知识点为单元进行分解形成知识项,在知识项之间建立联系,通过对知识点属性KP及关系KR进行描述,构建知识树模型KT{KP,KR}.
对知识点属性KP的描述采用五元组{KID,KN,KW,KI,KP}表示,具体说明如下:
KID:知识点编号,知识点唯一表示;
KN:知识点名称;
KW:知识点关键字;
KI:知识点重要程度;
KP:知识点对应资源路径.
知识点重要程度与被其他知识点引用到的次数有关,被引用的次数越多知识点越重要.设x为某知识点后继知识点的数量(x≥0),则其重要程度的隶属函数可表示为:
知识点之间的关系可以形式化定义为KR=(RN,KPN,Relation,Degree),其中:
RN:关系编号.
KPN:包括主知识点编号和关联知识点编号.
Relation:相关知识点与主知识点关系类型,Relation=(Compose,Dependence,Mutuality),其中:
Compose:组成关系,表示了元知识项和复合知识项之间的聚合关系;
Dependence:依赖关系,即前驱关系;
Mutuality:相关关系.
Degree:相关知识点与主知识点关系程度,Degree=(CP,DP,MP),其中:
CP:组成关系中,子知识点在构成父知识点中所占的比重;
DP:依赖关系中,知识点依赖知识点的程度;
MP:相关关系中,知识点相关的程度.
1.2 知识项相似度矩阵ASK生成
协同过滤算法分为基于用户的协同过滤推荐User CF[8]和基于物品的协同过滤推荐Item CF[9].User CF对于物品的数量是海量的,同时也是更新频繁;User CF的计算复杂度远远小于Item CF,User CF 加上社会网络信息,可以增加用户对推荐解释的信服程度.对于用户的数量大大超过物品的数量,同时物品的数据相对稳定的推荐系统,Item CF的计算复杂度远远小于User CF,同时 Item CF 便于为推荐做出解释[10].针对电力系统中领域知识相对稳定,用户数据多变的特点,本文采用协同过滤推荐算法AR-Item CF算法.
在系统日志中发掘用户对知识树中知识项产生的行为,包括用户浏览、收藏、关注、评分等,将不同行为划分权重,计算得到用户对某一个知识项的评分,形成用户-知识评分矩阵(见表1).

表1 用户-知识评分矩阵
(1) 选取评分矩阵中前3/4知识数据项集作为训练集,将剩下的1/4作为测试集,在训练集上建立用户兴趣模型,在测试集上进行预测.
(2) 计算知识项相似性.本文采用余弦相似性方法计算知识项之间的相似度.知识项i和知识项j之间的相似性为
(3) 形成知识项余弦相似度矩阵ASK(见表2).

表2 知识项余弦相似度矩阵
1.3 关联矩阵生成
知识项之间的关系是以知识项为中心,知识项与周边最近邻知识节点之间形成的关系,这是一种显性关系.而知识项与非最近邻知识项、多个知识项的组合与其他知识项之间也有可能存在关系,如不同知识点的组合会派生出新的知识点,这些关系属于隐性关系,需要进一步分析和挖掘,知识项关联程度用置信度表示.用Apriori算法[11]作为关联规则挖掘的经典算法,在计算关联支持度和置信度方面有较好的优势,因此本文采用Apriori算法来计算知识项之间的关联度,形成知识项关联矩阵ARK,算法过程如下:
(1) 将知识树中的知识项作为算法输入;
(2) 单遍扫描数据集,确定每个项的支持度,得到频繁1-项集;
(3) 算法扫描数据集,使用子集函数计算所有候选2-项集的支持度计数;
(4) 将支持度计数小于minsup的所有候选项集的置信度置为0,从而避免高相似性、低置信度的结果出现;
(5) 计算候选2-项集的置信度conf,形成知识项关联矩阵ARK(见表3).

表3 知识项关联矩阵
1.4 产生推荐
(1) 对知识项相似度矩阵ASK与知识项关联矩阵ARK求和,得到最终用于计算用户对知识项兴趣度的矩阵ASRK,即ASRK=ASK+ARK.
(2) 根据用户目标知识项,在ASRK中查找与目标知识项相关的前K个知识项.
(3) 计算用户对知识项的兴趣度公式为
其中:N(u)是用户喜欢的知识项的集合;ASRK(j,K)是和知识项j相似度和关联度之和较高的K个知识项的集合;Wji是知识项j和i在ASRK中对应的值;Rui是用户u对知识项i的兴趣.该公式的含义是和用户历史上感兴趣的知识项越相似且关联度越高的知识项,越有可能在用户的推荐列表中获得比较高的排名.
2 实验分析
本文对评价精度的度量采用平均绝对偏差MAE(mean absolute error),MAE通过计算预测用户评分与实际用户评分之间的偏差度量预测的准确性,MAE越小推荐质量越高.设预测的用户评分集合表示为{p1,p2,…,pN},对应的实际用户评分集合为{q1,q2,…,qN},则平均绝对偏差MAE定义为
项目推荐率(IRR)在项目推荐时,设一个用户的待推荐项目集为W={w1,w2,…,wN},其中wi(i=1,…,N)为待推荐项目,N为待推荐项目数,由于该用户的所有最近邻居中没有发现关于wk(wk∈W)的实际评估记录,而导致wk无法被推荐,不能被推荐的项目总数为M(M≤N),则称比值(N-M)/N为关于该用户的项目推荐率.项目推荐率主要用于衡量最近邻居查找的效率,也能从侧面反映出用户评分数据库的离散度.在相同的MAE下,IRR的值越高说明算法的推荐效率越高.
本文从电力安全规程系统的资源库中选择1 000条数据作为实验数据集,其中包含300个用户和700条知识,将实验数据集中的3 /4作为训练集进行挖掘以生成推荐的关联度,其余的1 /4作为测试集进行测试,与传统的Item CF进行对比得到在不同最近邻居下两种算法的MAE及项目推荐率IRR,实验结果如图1和2所示.
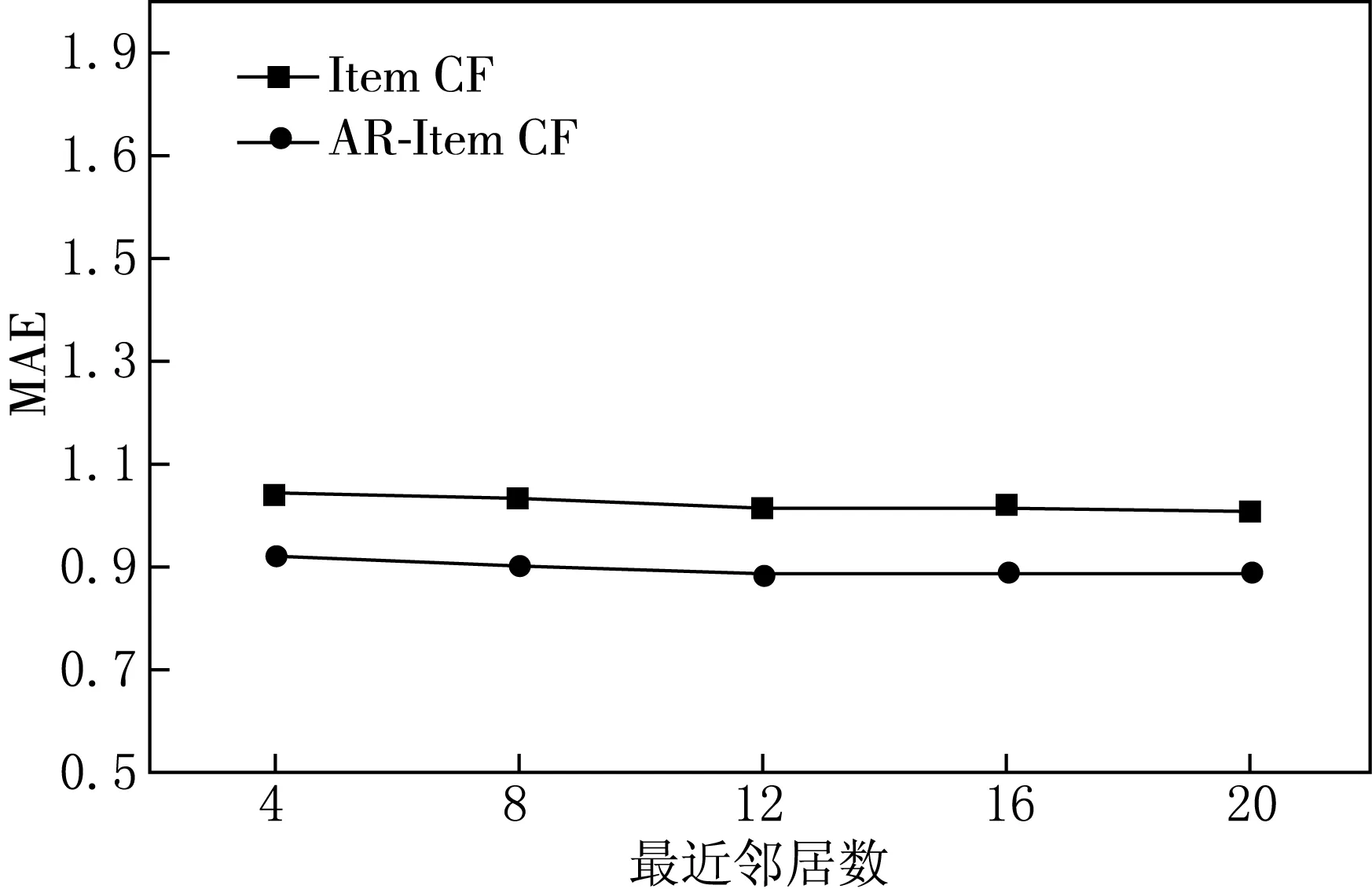
图1 MAE的实验结果 图2 IRR的实验结果
随着最近邻居数的增加,算法的项目推荐率IRR随之增加,与传统的协同过滤推荐算法相比,本文提出的AR-Item CF推荐算法具有最小的 MAE,较高的IRR,由此可知,本文提出的AR-Item CF推荐算法可以显著地提高推荐系统的推荐质量和推荐效率.
3 结论
本文提出的AR-Item CF推荐算法与传统的Item CF的最大不同在于计算用户对知识项兴趣度的过程中,将知识项之间的关联程度作为影响推荐结果排名的因素之一,采用关联规则挖掘和协同过滤推荐联合算法来向用户推荐相似度与关联度比较高的结果.实验结果证明相对于传统的协同过滤推荐,本文提出的AR-Item CF推荐算法不仅能够向用户执行高质量的推荐,对于推荐执行效率也有一定的提高.然而在最近邻居数较少的情况下,算法的项目推荐率IRR比较低,如何提高项目推荐率IRR也是下一步工作需要解决的问题,从而进一步完善该算法.
[参考文献]
[1]彭小圣,邓迪元,程时杰,等.面向智能电网应用的电力大数据关键技术[J].中国电机工程学报,2015,35(3):503-511.
[2]孟祥武,胡勋,王立才,等.移动推荐系统及其应用[J].软件学报,2013,24(1):91-108.
[3]周育忠,周宏龙,吴江.电网情报智能个性化推荐系统构建[J].图书情报知识,2014(4):50-56.
[4]杨博,赵鹏飞.推荐算法综述[J].山西大学学报(自然科学版),2011,34(3):337-350.
[5]赵峰,天恩,孙宏斌.电网安全运行知识的表达与演变[J].中国电机工程学报,2015,35(20):5117-5123.
[6]曲朝阳,陈帅,杨帆,等.基于双层次分析的智能变电站数据分类方法[J].东北电力大学学报,2014,34(2):61-65.
[7]曲朝阳,陈帅,杨帆,等.基于云计算技术的电力大数据预处理属性约减方法[J].电力系统自动化,2014,38(8):67-71.
[8]WANG WEI,ZHANG GUANGQUAN,LU JIE.Collaborative filtering with entropy-driven user similarity in recommender systems[J].Int J Intell Syst,2015,30(8):854-870.
[9]GAO MIN,FU YUNQING,CHEN YIXIONG,et al.User-weight model for item-based recommendation systems[J].Journal of Software,2012,7(9):2133-2140.
[10]HU LIANG,SONG GUOHANG,XIE ZHENZHEN,et al.Personalized recommendation algorithm based on preference features[J].Tsinghua Science and Technology,2014,19(3):293-299.
[11]苗苗苗,王玉英.基于矩阵压缩的Apriori算法改进的研究[J].计算机工程与应用,2013,49(1):159-162.
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
汽车观察(2019年2期)2019-03-15 06:00:50
水利科技与经济(2017年12期)2017-04-22 03:10:20
中国卫生(2016年5期)2016-11-12 13:25:26
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年1期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年4期)2015-09-10 07:22:44
电源技术(2015年11期)2015-08-22 08:50:18
生物进化(2014年2期)2014-04-16 04:36:26
