
电子病历数据库在临床研究中的应用及偏倚控制
2018-03-28 06:00:34程凯亮
协和医学杂志 2018年2期
王 丽,程凯亮
中国医学科学院 北京协和医学院 基础医学研究所 流行病学系, 北京 100005
目前,大多数临床研究者仍然面临着研究经费不足、研究持续时间有限、人群研究应答率和依从性低等困境。电子病历数据库(electronic health records, EHRs)的及时出现为开展临床研究,尤其是基于队列的大样本临床研究提供了低成本的愿景和机遇。随着2009年美国卫生信息技术法案的推出,美国80%的医疗机构实现了病历电子化,全球EHRs的普及率亦逐渐增加。人们越来越关注如何基于EHRs开展二手数据分析,以期最终促进医疗服务的改善。但由于EHRs收集的初衷是为了临床诊疗而非临床研究需要,因此利用EHRs开展临床研究仍存在很多问题,包括数据信息的完整性、就诊人群的代表性、数据处理的复杂性等。本文将通过实例探讨EHRs的特征、如何利用EHRs开展临床研究以及在研究中如何控制偏倚。
1 电子病历数据库的定义及基本特征
无论哪种研究设计方法,临床流行病学研究的核心均是在控制了混杂变量的情况下,探讨暴露因素与结局之间的关联。EHRs是医疗机构对门诊、住院患者(或保健对象)临床诊疗和指导干预的数字化医疗记录,包括患者历次就诊的人口学信息、生命指征、诊断、实验室检查、用药、影像学检查、既往病史、免疫接种史等[1]。上述信息可对应临床研究中的不同角色,包括暴露因素、结局、混杂因素和/或效应修饰等(表1),提示利用EHRs开展临床流行病学研究的可行性。但由于EHRs信息的收集是基于临床诊疗需求,因此患者使用何种药物、进行何种检查以及被随访的频次等均受到患者及医生抉择的影响,最终影响对疾病患病率、发病率及暴露因素风险的估计。同时,基于不同环境建立的EHRs,如某单一医疗机构EHRs、区域医疗健康数据库,其涵盖的人群特征、用药信息、检查、诊断及其他个人信息(如人口学特征、生命指征、家族史及个人史等)的数据特点不同[2],导致在回答临床研究问题的优势与局限性方面亦不同。
以我国为例,目前各医院EHRs的现状大致可分为3类:(1)以各种临床业务为中心,患者信息散落在多个相对独立的系统中;(2)对于大部分三级医院,各医疗机构内部已实现了以患者为中心的信息收集,但数据库中仅涵盖了患者在该医疗机构的就诊信息;(3)极少数城市已实现建立区域化的EHRs,解决了区域内各医院数据的信息共享。研究者需根据所使用的EHRs特点来确定其可能回答的临床研究问题,并对结果进行合理解释。
2 基于电子病历数据库可以解决的研究问题
EHRs作为针对患者临床诊疗相关健康信息的纵向电子记录,可通过与多种机构日常监测、记录、储存的各类与健康相关的数据,如其他医院EHRs、医保理赔数据库、公共卫生调查与公共健康监测(如药品不良事件监测)、出生/死亡登记项目等对接[4],从而实现对疾病转归及诊疗全过程的评估。包括描述疾病的流行病学特征及分布,探讨疾病的疗效或病因,评价真实就诊环境下的依从性、疗效,以及政策对于临床用药的影响等。针对不同科学问题,其对应的研究设计方法不同,包括横断面研究、生态学研究、病例对照研究及队列研究。下文主要针对疾病流行病学特征分布、疗效研究以及政策对于疗效评价的影响等进行讨论。
2.1 疾病流行病学特征及其分布描述
2.1.1 患病率
患病率是指研究特定时间点或期间某特定人群现患病者所占比例,明确目标人群并实现准确诊断是获得真实患病率估计的前提。疾病患病率的估计通常基于严格的抽样调查而获得,耗时耗力。而EHRs中涵盖的大量患者的临床诊断及检验信息,为在较低成本下描述疾病的发病率及患病率提供了可能。以一项利用医院数据估计炎症性肠病(inflammatory bowel disease,IBD)疾病分布为例,该研究纳入了中国香港1981至2014年7个区13家医院就诊的IBD患者信息,以每年13家医院IBD就诊人群除以当年香港人口数来估算当年IBD患病率[5]。估算的前提是此13家医院覆盖95%的香港IBD患者,能否依靠EHRs来估计疾病患病率的前提是能确定产生病例的“源人群”。但更多情况下,尤其是基于某单一医疗机构的EHRs,由于不能确定EHRs中病例的“源人群”,即不能获得计算患病率所需的分母,此时只能计算构成比而非患病率。同时研究显示,即使能获得EHRs对应的“源人群”,其最终获得的患病率估计与人群调查获得的患病率之间仍存在差别,其差别的方向与疾病特征、年龄、性别等密切相关[6- 7]。
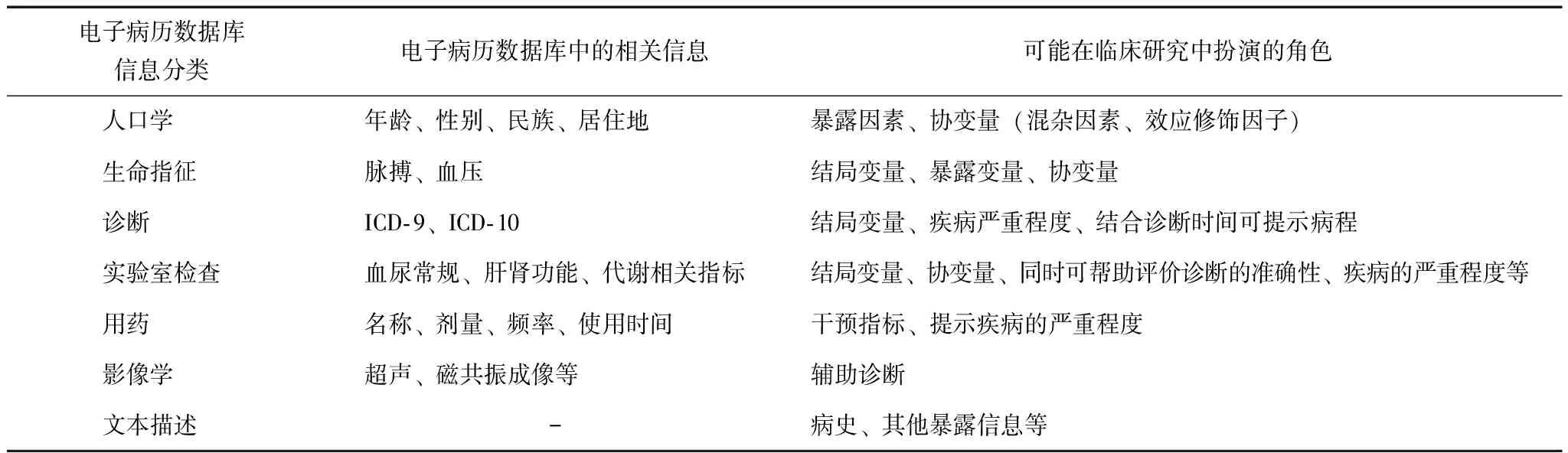
表 1 电子病历数据库中信息与临床研究中变量的对应关系[3]
ICD:国际疾病分类
2.1.2 发病率
EHRs作为针对患者临床诊疗相关健康信息的纵向电子记录,原则上研究者可利用其构建回顾性、前瞻性或双向队列以估计发病率。但其根本问题是不能仅仅依赖EHRs区分新发和现患病例。对于上述情况,可采用查病历或补充调查的方法应对,但其工作量大,费时费力,同时对于无住院病历的患者很难实现病历查询。研究者提出了多种解决EHRs新发病例确定问题的方法。最简单的方法是将首次诊断日期确定为新发日期,但前提是该数据库能长时间覆盖某个区域或全国人群,同时疾病严重程度高[8]。但对于大多数疾病,尤其是慢性病,上述方法并不能很好地区分新发和现患病例。Mamtani 等[9]的研究显示,采用Joinpoint回归通过确定不同时间间隔糖尿病发病率的变化拐点能较好区分EHRs中的现患与新发糖尿病患者。其他更复杂的方法,如基于回溯生存分析或等候时间分布等方法也越来越多被应用于EHRs数据中新发病例的确定[8]。
2.2 疗效评价
EHRs为在真实临床就诊环境下开展疗效研究提供了可能。中国台湾Wu等[10]基于全民健康保险研究资料库开展了“慢性乙型肝炎患者抗病毒治疗对肝癌发生影响”的研究,探讨核苷类似物抗病毒药物治疗是否可减少慢性乙型肝炎患者肝癌的发生风险。为此,该研究纳入了1997年1月1日至2010年12月31日台湾地区所有被诊断为慢性乙型肝炎[国际疾病分类- 9(international classification of diseases,ICD- 9):070.2,070.3和V02.61]至少3次,同时使用核苷类药物或保肝药物,并排除合并其他病毒性肝炎、艾滋病病毒感染以及在随访前3个月发生肝癌的患者。其中使用核苷类药物≥3个月者被定义为抗病毒治疗者,<3个月者被定义为非抗病毒治疗者。通过上述入选和排除标准,199 451例慢性乙型肝炎患者中72 458例纳入该研究。对于使用抗病毒治疗者,队列随访起点为首次核苷类药物处方时间,而对于非抗病毒治疗者,则以首次使用保肝类药物为随访起点;随访终点为发生肝癌、死亡或2010年12月31日。最终研究显示,抗病毒治疗者发生肝癌的风险较非抗病毒治疗者减少63%(HR=0.37,95% CI:0.34~0.39)。实现上述研究的前提主要包括以下3点:(1)研究人群代表性问题:中国台湾1997年开始实行强制性全民医保覆盖,同时所有乙型肝炎抗病毒药及保肝药均可报销,保证了所有可能使用抗病毒药物者的纳入;(2)可明确获得慢性乙型肝炎诊断时间和用药时间,保证了暴露信息及随访起点的可获得性;(3)该医保数据库中灾难性疾病患者登记数据库保证了结局信息的可获得性。但由于EHRs是基于真实就诊环境的数据收集,治疗不仅仅是一种暴露因素,更是一种临床决策,患者是否使用核苷类抗病毒药物受年龄、疾病严重程度、经济水平等多方面因素影响,导致使用核苷类药物者和未使用者在可能影响肝癌发生的因素分布上不可比,即存在选择偏倚,因此在分析时需要采用统计分析方法进一步控制。
除了选择偏倚外,当利用EHRs开展临床疗效研究时,通常还会面临一系列删失问题,包括不能保证获得每个随访者的结局(右删失)、不知道每个患者何时开始治疗(左删失)。右删失可通过生存分析方法解决,但左删失则需通过精巧的设计来避免。例如,在利用EHRs评价HBeAg阳性患者HBsAg滴度水平对未来HBsAg阴转的预测价值时,由于很难根据EHRs确定患者首次治疗时间,此时可结合临床实际意义,选择HBeAg阳性患者中发生HBeAg阴转的患者作为研究对象,从而确定随访起点。
2.3 政策对疗效评价的影响
临床药物使用与医保政策密切相关。医保政策对患者临床药物使用及疗效的影响不太可能使用实验性研究来评价。Qiu等[11- 12]利用北京市某传染病医院的医保和非医保患者在政策执行前后的EHRs探讨2011年7月1日开始执行的乙型肝炎抗病毒药物医保报销政策对于慢性乙型肝炎患者抗病毒用药种类选择、用药依从性及成本的影响,并开展成本效果分析,从而综合评价该政策对于北京市慢性乙型肝炎患者用药及疗效影响。但需注意的是,以单中心EHRs来评价患者用药时可能会因“不能获得患者在其他医院或药房拿药的信息”而产生信息偏倚,因此有必要评价不同类型患者(医保和非医保患者)在政策执行前后在外院取药的信息来校正可能产生的偏倚[11]。
3 基于电子病历数据库开展临床流行病学研究面临的问题
与科学研究驱动的研究设计不同,EHRs为基础的研究相对更省时省力、样本人群更大。然而,基于EHRs,尤其是基于单中心的EHRs研究,仍然面临人群代表性、影响暴露因素与结局关系的混杂因素在人群分布不均匀、混杂因素收集不完整、数据收集不准确等一系列问题,从而最终使研究结论产生系统误差。下文着重讨论选择偏倚和混杂偏倚的控制。
3.1 选择偏倚
当总体人群中单一个体进入样本的概率与暴露及结局因素密切相关,导致样本人群与总体人群在暴露因素与结局相关的特征分布上出现系统误差,则可能产生选择偏倚。对于基于EHRs的研究来说,产生选择偏倚的原因包括但不仅限于以下几方面:(1)入院率偏倚,即患者的年龄、性别、疾病严重程度、地域特点、医疗保险状态等均可能影响患者是否到医院就诊或是否到某个医院就诊,从而最终影响EHRs人群的代表性。因此,在使用EHRs开展临床研究时,有必要对患者年龄、性别、种族及其他相关人口学特征与总体患者人群比较,以评价研究对象的代表性。例如,如果想利用北京市某传染病医院的门诊及住院EHRs来估计慢性乙型肝炎患者的直接医疗费用,则需评价在该医院就诊的慢性乙型肝炎患者年龄、性别及疾病严重程度相关指标与总体慢性乙型肝炎患者人群的可比性。(2)数据缺失,尤其是非随机缺失。仍以利用EHRs评价HBeAg阳性患者HBeAg阴转时HBsAg滴度水平对未来HBsAg阴转的预测价值为例,由于临床并非所有慢性乙型肝炎患者在HBeAg阴转时均会行HBsAg滴度检查,此时如果有HBsAg滴度检查的患者疾病严重程度指标与未行检查者不可比,则会产生选择偏倚,从而最终影响对HBsAg阴转的预测。探讨数据缺失的机理(完全随机缺失、随机缺失或非随机缺失)是评价缺失对于研究结果影响的关键。
3.2 混杂偏倚
基于EHRs的疗效或病因学研究中,由于治疗不仅仅是一种暴露因素,更是一种临床决策,患者是否使用某种治疗受患者年龄、疾病严重程度、经济水平等多种混杂因素的影响,如何控制混杂因素是基于EHRs开展临床疗效或病因研究的关注热点。以Wu 等[10]开展的抗病毒治疗是否降低肝癌发生风险的研究为例,对最终纳入的符合入选和排除标准的47 611例未使用抗病毒药物和24 847例使用抗病毒药物治疗的患者基线特征分析显示,除年龄外,其他所有可能影响结局发生的因素如其他药物使用情况、主要共患病、肝硬化程度等均显著不同,提示控制混杂因素的必要性。目前除在研究设计阶段采用匹配或限制方法控制混杂因素外,还可在分析阶段采用传统控制混杂的统计方法,包括分层分析、多因素分析等[13- 15]。随着现代流行病学的发展,研究者们提出了倾向性评分法[16]、工具变量法[17]、双重差分法[18]等新的控制混杂偏倚的方法。
倾向性评分以给定的一组协变量,通过构建协变量与处理因素之间的函数关系,确定任意一个研究对象划分到处理组的概率,即倾向分值。基于估计的倾向分值,传统的倾向性评分方法包括倾向性评分匹配法、分层、协变量校正(又称回归法)和加权法。仍以Wu等[10]的研究为例,研究者以是否接受抗病毒治疗为因变量,以年龄、性别、主要共患病、肝硬化程度、其他药物使用情况等为协变量,建立Logistic回归模型,估算72 458例患者进入抗病毒治疗组的概率,即倾向分值。依据倾向分值按照最临近卡钳匹配法为每例抗病毒治疗患者匹配一例对照,匹配后的抗病毒治疗组和非抗病毒治疗组患者倾向分值的分布基本吻合,提示依据倾向分值抗病毒治疗组和对照组在协变量的整体分布上具有可比性;同时该研究对匹配后抗病毒治疗组和对照组每个协变量是否均衡可比进行了检验(但检验均衡性的统计分析方法并不合适,通常建议采用标准化差别的方法以校正样本量的影响)。最后通过比较匹配后的两组人群肝癌的发生率差异来评价抗病毒药物的长期疗效。
倾向性评分方法能否准确控制混杂偏倚的前提是如何构建协变量与处理因素的模型,从而准确估计倾向分值。目前纳入什么协变量仍然存在争议。以倾向性评分匹配法为例,Austin等[19]的研究显示,仅纳入与处理因素有关的协变量与其他纳入协变量的方法(包括仅与结局因素有关或同时与协变量和处理因素有关)相比,会导致可匹配的对子数减少,从而导致处理效应估计值的精度下降。需注意的是,最终确定哪些协变量纳入模型并不取决于模型拟合的好坏,而是基于倾向性评分匹配后处理组和对照组的各协变量分布是否可比。
贝叶斯倾向性评分则在传统倾向性评分基础上,进一步将倾向性评分引入由现有数据建立的结局事件与处理因素、协变量构建的联合分布模型[20- 21]。通过该分布模型可同时控制测量和未测量的混杂因素,包括缺失数据影响,从而获得比较真实可靠的效应值[22- 25]。但其计算量大,需借助马尔科夫链蒙特卡罗法实现。例如,在利用医院病历数据库评价他汀类药物对急性心肌梗死患者全因死亡率的影响研究发现,贝叶斯倾向性评分法较传统logistic倾向性评分所获得的效应值更准确,置信区间更宽[20]。
由于EHRs主要是因临床诊疗需要而构建,影响疾病预后的很多环境或遗传暴露因素很难在临床实际就诊记录中收集,因此控制未测量混杂因素在基于EHRs的研究中显得尤为重要。对未测量混杂因素的处理方法包括工具变量法[17]、双重差分法[18]、基于倾向性评分法的敏感性分析等。工具变量法主要是通过找到一个合适的变量,该变量与研究结局及混杂因素无关,仅与处理因素有关,将变量替代实际处理因素,通过比较不同工具变量状态人群结局的差异得到不同处理因素效应值的无偏估计[26]。例如Stukel等[27]基于1994至1995年全美566个冠状动脉造影服务机构急性心肌梗死患者的研究,由于不同服务机构患者疾病严重程度无差别,但30 d内接受心导管术的患者比例(即心导管手术率)不同,因此将不同地区心导管手术率作为工具变量,通过比较不同心导管手术率患者7年生存率的差别来评价心导管手术对于患者长期生存的影响。
双重差分法则主要用于干预效果评价研究[28]。例如,黄远飞等[29]分别从2014年和2015年广州市南沙区城乡居民医疗保险的就诊数据中分别抽取农村和城镇参保人各800人,评价广州市2015年1月1日开始执行的城镇居民基本医疗保险和新型农村合作医疗整合政策效果。由于整合前原新农合和城镇居民医保的参保人在医疗保险待遇、年龄、性别、家庭规模、患病情况等方面均可能存在差异,无法仅通过两种类型参保对象之间的前后或横向对比来分析政策实施对医疗服务消费的影响。故采用双重差分模型法,将原新农合参保人定义为处理组,假设整合实施后其医疗服务支出和补偿力度均增加,但城镇参保人由于待遇提升幅度不大,对其医疗服务支出影响较少,将其定义为对照组;通过比较原新农合居民政策前后医疗总费用及自付比例改变与城镇参保人政策前后医疗总费用及自付比例改变,同时校正参保人性别、年龄、慢性病患病情况以及家庭规模等变量,来评价新的政策对新农合患者的影响。
4 结语
综上所述,在目前这个充满前景、陷阱和挑战的大数据时代,仍需回归流行病学的本质,结合EHRs的具体特点和所提出的科学问题,充分考虑研究设计、数据分析等过程中出现的偏倚,并结合巧妙的设计和合理的统计学分析方法才能真正实现EHRs与临床研究的整合。
[1] ISO/TR 20514:2005. Health informatics-electronic health record-definition, scope, and context[EB/OL]. https://www.iso.org/standard/39525.html.
[2] 王雯,刘艳梅,谭婧,等. 回顾性数据库研究的概念、策划与研究数据库构建[J]. 中国循证医学杂志,2018, 18:230- 237.
[3] Casey JA, Schwartz BS, Stewart WF, et al. Using electronic health records for population health research: a review of methods and applications[J]. Annu Rev Publ Health, 2016,37:61- 81.
[4] Kavakiotis I, Tsave O, Salifoglou A, et al. Machine learning and data mining methods in diabetes research[J]. Comput Struct Biotechnol J, 2017,15:104- 116.
[5] Ng SC, Leung WK, Shi HY, et al. Epidemiology of inflammatory bowel disease from 1981 to 2014: results from a territory-wide population-based registry in HongKong[J]. Infl-amm Bowel Dis, 2016,22:1954- 1960.
[6] Esteban-Vasallo MD, Dominguez-Berjon MF, Astray-Moch-ales J, et al. Epidemiological usefulness of population-based electronic clinical records in primary care: estimation of the prevalence of chronic diseases[J]. Fam Pract, 2009,26:445- 454.
[7] Tomasallo CD, Hanrahan LP, Tandias A, et al. Estimating wisconsin asthma prevalence using clinical electronic health records and public health data[J]. Am J Public Health, 2014,104:E65-E73.
[8] Bagley SC, Altman RB. Computing disease incidence, prevalence and comorbidity from electronic medical records[J]. J Biomed Inform, 2016,63:108- 111.
[9] Mamtani R, Haynes K, Finkelman BS, et al. Distinguishing incident and prevalent diabetes in an electronic medical records database[J]. Pharmacoepidemiol Drug Saf, 2014,23:111- 118.
[10] Wu CY, Lin JT, Ho HJ, et al. Association of nucleos(t)-ide analogue therapy with reduced risk of hepatocellular carcinoma in patients with chronic hepatitis B: a nationwide cohort study[J]. Gastroenterology, 2014,147:143- 151
[11] Qiu Q, Duan XW, Li Y, et al. Impact of partial reimbursement on hepatitis B antiviral utilization and adherence[J]. World J Gastroenterol, 2015,21:9588- 9597.
[12] Qiu Q, Li Y, Cheng K, et al. Cost-effectiveness of partial reimbursement for hepatitis B anti-viral drugs in Beijing, China: an analysis based on a retrospective cohort study[J]. Lancet, 2015, 386:S23-S23.
[13] Lucas R, Ponsonby AL, McMichael A, et al. Observational analytic studies in multiple sclerosis: controlling bias through study design and conduct. The Australian Multicentre Study of Environment and Immune Function[J]. Mult Scler, 2007,13:827- 839.
[14] Brookhart MA, Sturmer T, Glynn RJ, et al. Confounding control in healthcare database research: challenges and potential approaches[J]. Med Care, 2010,48:S114-S120.
[15] Pearce N, Checkoway H, Kriebel D. Bias in occupational epidemiology studies[J]. Occup Environ Med, 2007,64:562- 568.
[16] Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects[J]. Biometrika, 1983,70:41- 55.
[17] Brookhart MA, Wang PS, Solomon DH, et al. Evaluating short-term drug effects using a physician-specific prescribing preference as an instrumental variable[J]. Epidemiology, 2006,17:268- 275.
[18] Ashenfelter O, Card D. Using the longitudinal structure of earnings to estimate the effect of training programs[J]. Rev Econ Stat, 1985,67:648- 660.
[19] Austin PC, Grootendorst P, Anderson GM. A comparison of the ability of different propensity score models to balance measured variables between treated and untreated subjects: a Monte Carlo study[J]. Stat Med, 2007,26:734- 753.
[20] Mccandless LC, Gustafson P, Austin PC. Bayesian propensity score analysis for observational data[J]. Stat Med, 2009,28:94- 112.
[21] Li L, Shen C, Wu AC, et al. Propensity score-based sensitivity analysis method for uncontrolled confounding[J]. Am J Epidemiol, 2011,174:345.
[22] Schlesselman JJ. Assessing effects of confounding variables[J]. Am J Epidemiol, 1978,108:3- 8.
[23] Greenland S. The Impact of Prior Distributions for uncont-rolled confounding and response bias[J]. JASA, 2003,98:47- 54.
[24] Mccandless LC, Gustafson P, Austin PC, et al. Covariate balance in a Bayesian propensity score analysis of beta blocker therapy in heart failure patients[J]. Epidemiol Perspect Innov, 2009,6:5.
[25] An W. Bayesian propensity score estimators: incorporating uncertainties in propensity scores into causal inference[J]. Sociol Methodol, 2015,40:151- 189.
[26] Greenland S. An introduction to instrumental variables for epidemiologists[J]. Int J Epidemiol 2000;29:1102.
[27] Stukel TA, Fisher ES, Wennberg DE, et al. Analysis of observational studies in the presence of treatment selection bias: effects of invasive cardiac management on AMI survival using propensity score and instrumental variable methods[J]. JAMA,2007,297:278- 285.
[28] Ashenfelter O. Estimating the effect of training programs on earnings[J]. Rev Econ Stat, 1978,60:47- 57.
[29] 黄远飞, 张家业. 城乡医保整合对农村居民医疗服务利用的影响-以广州市为例[J]. 中国公共政策评论, 2017,1:34- 52.
猜你喜欢
肝博士(2022年3期)2022-06-30 02:48:52
科普童话·神秘大侦探(2022年11期)2022-05-30 03:21:35
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
肝博士(2021年1期)2021-03-29 02:32:14
恋爱婚姻家庭(2020年27期)2020-10-09 04:16:18
肝博士(2020年4期)2020-09-24 09:21:26
疯狂英语·初中天地(2020年3期)2020-05-21 03:36:52
百花洲(2018年1期)2018-02-07 16:34:52
瞭望东方周刊(2017年45期)2017-12-08 21:37:48
新闻研究导刊(2015年17期)2015-12-25 12:36:42
