
基于引发序列的流程模型修正
2018-03-28 05:09:02杜玉越祁宏达
计算机研究与发展 2018年3期
王 路 杜玉越 祁宏达
(山东科技大学计算机科学与工程学院 山东青岛 266590) (wanglu253@126.com)
随着大数据[1-2]时代的到来,业务过程管理(business process management, BPM)必将得到进一步的改善.近年来,企业信息系统(enterprise infor-mation systems, EIS)通过集成提高了企业业务流程的功能[3],产生了大量的事件日志(event logs),并且这些日志被记录并存储在了系统中[4].流程挖掘(process mining)可以从记录的这些数据中提取出与流程相关的信息并发现流程模型(process model)[5-6].
事件日志通常作为流程挖掘的输入数据,是流程模型在执行过程中产生的事件序列集合.日志中的每一个事件对应于一个活动,并与一个特定的实例相关.事件日志记录的实例中的一条事件序列称为一条迹(trace).除了活动,事件日志同样包含其他信息,比如初始资源(initial resources)、事件的时间戳(timestamp)等.现有的流程挖掘技术有流程发现(process discovery)、合规性检查(conformance checking)、流程改进(process enhancement)[4-7].流程发现是通过挖掘日志中流程的主要步骤来创建 流程模型.合规性检查是将流程模型的行为与事件日志中记录的行为进行对比,从而找到建模的行为与记录的行为之间的共性和差异.流程改进是根据事件日志对流程模型进行改进或扩展.通过这3种流程挖掘技术可以进行瓶颈分析与延迟预测等.
目前,存在很多从控制流角度描述流程模型的形式化语言,比如业务流程建模标记法(business process modeling notation, BPMN)[8]、因果网(causal nets)[4]、事件驱动流程链(event-driven process chains, EPCs)[9]、Petri网[10]等.Petri网[10]能够作为分布式系统建模和分析的工具,并且具有严格的数学定义以及强大的图形表达能力.Petri网不仅能够描述流程的静态结构,还可以模拟流程运行过程中的动态行为.对于具有并行、并发、异步、分布和不确定性等性质的信息系统,可以利用Petri网对其进行有效地描述和分析[11-15],因此,本文用Petri网来描述流程模型.
如果现在有流程模型不能够重演(replay)对应的实例,原则上要用流程发现来得到一个新的流程模型.但是,重新发现的模型通常与原模型没有相似度并且丢弃了原模型的优势,特别是在原模型通过手工创建的情况下,丢失掉的优势显得由为重要.对于不能重演实例的流程模型,一个比较好的方法是对原模型进行修正,从而使模型可以重演(大多数)事件日志并且尽可能保留原模型的优势.本文介绍了一种新的流程挖掘技术——模型修正.该技术将流程模型N与日志L中的异常活动作为输入.如果模型N符合日志L,就没有必要修正N.但是如果N中的部分模型不能重演L中的某些活动,那么就需要对该部分模型进行修正.与流程发现不同,模型修正可以将流程模型中能够重演事件日志的部分保留下来.得到的修正模型N′ 可以看作是原模型N及事件日志L的一个协同(synergy)部分.模型修正技术保证了修正模型与原模型的相似度.
1 相关工作
本文提出的模型修正技术主要与2个方面的研究方向相关:模型合规性检查与模型发现.
如果模型可以重演事件日志中的活动行为,则该模型的拟合度比较好,如果模型可以重演日志中的所有迹,则该模型的拟合度为1.0[4]. 如今已经提出了很多合规性检查的方法.基于托肯(token)的重演[16]就是检测事件日志与Petri网之间一致性的方法.将日志中的每条迹分别在模型上进行重演,根据迹中的活动顺序,网中的变迁可以被依次引发.在流程执行的过程中可以计算产生(produced)、消耗(consumed)、丢失(missing)和剩余(remaining)的token,然后通过这些token的数目计算日志与模型之间的拟合度.Petkovic等人以BPMN的描述形式提出了流程与日志合规性检查的框架[17].
当已有的模型与流程的执行过程不一致时,可以通过流程发现(process discovery)技术得到一个新的流程模型.根据活动的次序关系发现流程模型的技术有Alpha算法[18]及其衍生算法[19-20],这种技术可以保证模型的同构-再发现(isomorphic-rediscover)能力[21],但是不能保证模型的拟合性与健壮性.基于语义(semantics-based)的发现技术有基于语言的区域挖掘(language-based region miner)[22-23]、基于状态的区域挖掘(state-based region miner)[24]和ILP挖掘(integer linear programming)[25],这种发现技术可以保证模型的拟合性,但是不能保证模型的健壮性与再发现能力.
2 基础知识
本节中简单地回顾了多重集与Petri网的定义,并介绍了事件日志与流程模型的概念.在本文中,表示一个自然数集合,S是一个有限集合.
定义1.S上的多重集Z是一个映射Z:S→.B(S)表示集合S上的所有多重集.
多重集Z=[a3,b,c2]表示集合S上的1个多重集,其中a,b,c∈S,Z(a)=3,Z(b)=1,Z(c)=2.Z1,Z2∈B(S)是2个多重集.2个多重集的和是Z3=Z1⊕Z2,其中Z3∈B(S),对于所有的a∈S:Z3(a)=Z1(a)+Z2(a).2个多重集的差是Z4=Z1-Z2,对于所有的a∈S:Z4(a)=max{0,Z1(a)-Z2(a)}.如果∀a∈S,Z1(a)≤Z2(a),则Z1≤Z2.比如:[b,c]≤[a3,b,c2],但[b2][a3,b,c2].
定义2.S*表示集合S上所有有限序列的集合,ε表示一个空序列.序列σ=〈σ[1],σ[2],…,σ[n]〉,其中σ[i]表示序列的第i个元素,〈σ[i],σ[i+1]〉表示2个相邻接的元素,|σ|=n表示序列σ的长度.对于∀a∈S,σ(a)表示a在σ中出现的次数.σsub表示σ的子序列,σ(σsub)表示子序列σsub在σ中出现的次数.
定义3.Z是集合S上的一个多重集,Q⊆S是集合S的一个子集,σ∈S*.σ|Q表示σ在Q上的投影,Z|Q表示Z在Q上的投影.
比如:如果σ=aabc,Q={a,b},Z=[a3,b,c2].则σ|Q=aab,Z|Q=[a3,b].
定义4.v=(a1,a2,…,an)∈S×…×S是集合S上的一个向量.πi(v)表示v的第i个元素,其中1≤i≤n.
比如v=(a,b)∈S×S,则π1(l)=a,π2(l)=b.可以将该定义扩展到序列中,比如σ∈(S×S)*,πi(σ)=〈πi(σ[1]),πi(σ[2]),…,πi(σ[|σ|])〉,i=1,2.
定义5[9].N=(P,T;F)为一个网,其中:
1)P是库所有限集合;
2)T是一个变迁有限集合,并且P∪T≠∅,P∩T=∅;
3)F⊆(P×T)∪(T×P)是一个流关系集合.
定义6[9]. 设N=(P,T;F)为一个网.对于x∈S∪T,记:
•x={y|y∈S∪T∧(y,x)∈F},
x•={y|y∈S∪T∧(x,y)∈F},
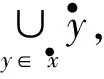
顺序、并行、选择和循环结构是工作流和流程模型的4种基本结构,如图1所示.流程所有的执行过程都可以由这4种结构组合而成.

Fig. 1 Four basic structures of Petri nets图1 工作流的4种基本结构
定义7[28].A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型,其中:
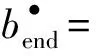
2)α:T→Aτ是变迁到活动的映射函数;
3)α-1:Aτ→T是α的逆函数,是活动到变迁的映射函数;
4)mi是初始标识,mf是终止标识.
除非特别指出,只有可见变迁可以标记为活动.假设τ∉A表示所有的不可见变迁.为方便起见,Aτ=A∪{τ} 表示A与{τ}的并集.
定义8[4].A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型,每一个变迁t∈T对应于流程执行中的一个活动.模型Ns的一条活动序列l∈A*,或空序列是活动的一条有限序列,即迹.L∈B(A*)是一个事件日志,即迹的一个多重集.ξ表示一个空事件日志.
由于不同的实例可能有相同的迹,因此一个事件日志是一个迹的多重集.如果不关心迹的发生频数,可以将一个日志看成一个迹的集合,即L={l1,l2,…,ln}.在定义8中,一个事件是指一个活动.通常,事件日志还记录了事件的其他信息,比如时间戳、资源和附加数据元素等.
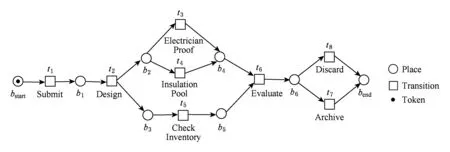
Fig. 2 An example of an engineering drawing process Nd图2 工程图设计流程Nd
图2给出了汽车制造厂的工程图设计流程.在这个模型中,A={Submit,Design,…,Archive},α(t1)=Submit,α-1(Insulation Proof)=t4.l=〈Submit,Design,Electrician Proof,Check Inventory,Evaluate,Archive〉是该模型的一条迹,对应的引发序列是σ=〈t1,t2,t4,t5,t6,t7〉.对于l和σ,有α(σ)=l,α-1(l)=σ.
如果一条迹缺少活动或者存在不同于模型的活动,则该迹不能被流程模型正确地重演.为了确定活动序列是否被完整地记录在事件日志中,给出了引发序列的概念.
定义9[26-27].Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型,则Ns的一条引发序列及其后集可递归定义为:
1) 空序列ε是一条引发序列,且ε*={bstart};
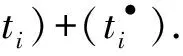
如果σ是模型Ns的一条引发序列且σ•={bend},则称序列σ符合流程模型,记为σNs.如果σ不符合Ns,则记为σ/Ns.
定义10[5].A表示一个活动集,迹l∈A*是一个活动序列.&(l)是一个多重集,包含迹l的所有活动.
比如,如果l′=〈a,b,h,i,k,s,m,o,m,o,t,p,r〉,那么&(l′)={a,b,h,i,k,s,m2,o2,t,p,r}.
定义11.A表示一个活动集,L∈B(A*)是一个事件日志,e∈A是L有一个活动,
◆e={a|∀l∈L∧a∈A∧〈a,e〉∈l},
e◆={a|∀l∈L∧a∈A∧〈e,a〉∈l},
称◆e为e的前活动集,e◆是e的后活动集.
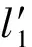
3 模型修正
本节主要基于引发序列给出一种模型修正的方法.通常,可以通过对流程模型进行移除活动与增加活动的方式对流程模型进行修正.移除活动是将活动从流程模型中移除,增加活动是在合适的位置对流程模型增加活动.模型修正的目标是使修正的流程模型可以重演其(大多数)事件日志.
定义12.Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型,L是Ns的一个事件日志.如果∀l∈L:lNs,则称Ns可以执行中L的每一个实例,即Ns可以重演L.如果∀l∈L:l/Ns,则称Ns不能够重演L.
如果模型Ns不能够重演其对应的事件日志L,
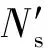
3.1 移除活动
当序列σt在实际情况下可以发生,但对于模型来说,•tσ•时,则需要在模型中将σ与t之间的变迁移除.如果模型中描述活动从来没有记录在事件日志中时,则需要将该活动从模型中删除,如果模型中描述有活动被记录但是只有记录在部分事件日志中时,则需要在模型执行的过程中跳过该活动.模型中的活动可以通过2种方式移除:跳过变迁、删除变迁.
定义13.A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型.l=lke是Ns的一条迹,且α-1(l)=α-1(lke)=α-1(lk)α-1(e)=σkti(1≤i≤|T|).如果•ti则是在σk和ti之间至少跳过一个变迁的间隔(gap).
间隔表明迹lke可以在实际情况下执行,但是lke不符合流程模型的描述规则.换句话说,在实际运行过程中,lk与e之间跳过了一些活动.
定义14.A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型,L∈B(A*)是Ns的一个事件日志.如果∃ti∈T(1≤i≤|T|),α(ti)=e,但L中从来没有记录e,则称活动e是一个删除的活动.
定义14指出,Ns描述了活动e,但是在流程实际运行过程中,e从来没有发生过,那么需要在Ns中删除活动e.
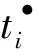
证明.
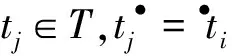
对于ti∈T,如果∃tj∈T,•(•tj)=•(•ti),则ti在并行结构中.
证毕.
给定流程模型Ns和需要从Ns移除的活动e,算法1给出了将e移出Ns的方法.
算法1. 从模型Ns中移除活动e.
FunctionRemoveActivity(Ns,e)
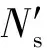
②T是变迁集合,T=transitions set;
③i=1;
④ while (i≤|T|) do
⑤ if (α(ti)=e)
⑥ break;
⑦ end if
⑧i++;
⑨ end while
⑩ if (ti是可跳过变迁)
在算法1中,首先判断e是可跳过的活动,还是删除的活动.当e是可跳过的活动时,可以加入不可见变迁τ.在流程执行的过程中,可以在e与τ之间进行选择.如果e是删除的活动时,需要确定包含e的结构.如果e在顺序结构中,需要加入从•(α-1(e))到((α-1(e))•)•的弧,删除变迁α-1(e)及库所(α-1(e))•,同时要删除连接α-1(e)与(α-1(e))•的弧.对于e在选择结构或并行结构中,可以类似的处理.需要删掉连接α-1(e)的弧与库所.根据算法1可以将一个活动从Ns中移除.如果有连续的活动需要在Ns中移除时,可以根据算法1将对应这些连续活动的一个子模型从Ns移除.函数DetermineStructure(Ns,e)可以用来确定包含e的结构,在算法2给出了该函数的实现方法.
算法2. 确定活动e所在的结构.
FunctionDetermineStructure(Ns,e)
①T是变迁集合,T=transitions set;
②S=null;
③i=1;
④ while (i≤|T|) do
⑤ if (α(ti)=e)
⑥j=1;
⑦ while (j≤|T|) do {
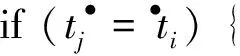
⑨k=j+1;
⑩ while (k≤|T|) do {
对于图3的非正确模型N1,假设事件日志中包含2条迹:l2=〈B,C,D,E,F,I〉和l3=〈B,C,E,D,F,G,I〉.对于l2=〈B,C,D,E,F,I〉,〈B,C,D,E,F〉是引发序列,且〈B,C,D,E,F〉•={b6},对于活动I,•I={b8}〈B,C,D,E,F〉•.因此,〈B,C,D,E,F〉与I之间存在间隔.对于l3=〈B,C,E,D,F,G,I〉,〈B,C,E,D,F,G〉是引发序列,且〈B,C,E,D,F,G〉•={b7},•I={b8}〈B,C,E,D,F,G〉•.〈B,C,E,D,F,G〉•与I之间跳过了活动K.
活动G记录在l3中,但是没有记录在l2中,如果要修正N1,需要在模型中跳过活动G.如果要跳过G,可以添加不可见变迁τ,•τ=•G且τ•=G•.同时要添加从b6到τ及从τ到b8的弧.活动K即没有记录在l2中也没有记录在l3中,因此需要在N1中删除K.从N1可以看出,K是在顺序结构中.要删除K,需要加入从G到b8的弧,且删除库所b7,删除从b7到K及从K到b8的弧.N1的修正模型如图4所示.

Fig. 3 An incorrect process model N1图3 非正确模型N1

Fig. 4 The repaired model of N1图4 流程模型N1的修正模型
3.2 添加活动
通过在流程模型中插入额外的活动来添加活动.但是,在插入活动e时,需要在模型中确定e的插入位置(定义为loc(e)).e并不会在每一条迹中都发生,因此,需要确定e和◆e∪e◆之间的关系.如果插入的位置以及关系类型都已确定,则可以通过添加活动对模型进行修正.
通常有2个插入额外活动的位置,1个是◆e之后的最后一个活动,另一个是e◆之前的第1个活动,现在还没有办法确定这2个位置中的哪一个.因此,这2个位置都需要检查,然后评价模型的质量,选择使模型质量高的位置.
定义15.A表示一个活动集,L∈B(A*)是Ns的一个事件日志,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型.l=lkelm是Ns的一条迹,如果ti∈T(1≤i≤|T|):α(ti)=e.则称活动e是一个额外的活动.
定义15表明迹l可以在实际情况下执行,但是有些活动在实际执行的过程中发生了,没有在Ns中描述,因此,需要将这些额外的活动添加到模型中.
定理2.A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型.L是关于Ns的一个事件日志,e对于Ns是一个额外活动.当在Ns中插入e时,可以通过◆e和e◆确定loc(e).
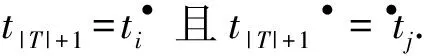
证毕.
定理2表明在流程模型中,loc(e)可以由◆e和e◆确定.由定理2可以确定e与模型中其他活动的关系.
给定流程模型Ns和模型Ns的额外活动e,算法3给出了将e插入Ns的方法.
算法3. 在模型Ns中添加活动e.
FunctionAddActivity(Ns,e)
②T是变迁集合,T=transitions set;
③t|T|+1是额外活动, 即α(t|T|+1)=e;
④α(tk)∈◆e;
⑤α(tm)∈e◆;
⑥ if (DetermineActivitiesRelationship(e,
α(tm))=sequential)
⑧ 添加库所t|T|+1•使•tm=t|T|+1•;
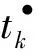
⑩ end if
α(tm))=choice)
α(tm))=parallel)
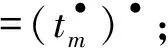

{•t|T|+1,•tm};
算法4. 确定活动a与b的关系.
FunctionDetermineActivitiesStructure(a,b)
①A是活动集合,A=activities set;
②L是一个事件日志,L∈B(A*);
③R=null;
④ if (a∈A且b∈A)
⑤ for (i=0;i≤|L|;i++)
⑥ if (a∈&(li))
⑦ if (b∈&(li))
⑧ if (a与b的顺序是〈a,b〉)
⑨j=i+1;
⑩ while (j≤|L|)
在算法4中,当a和b记录在一条迹中时,那么它们应该在顺序结构中或并行结构中.如果在每条迹中,它们的顺序总是〈a,b〉,则它们在顺序结构中.如果在一些迹中,它们的顺序是〈a,b〉,在其他迹中,它们的顺序是〈b,a〉,则a与b在并行结构中.如果a包含在一条迹中,但b不能被记录在该迹中.类似地,如果b包含在一条迹中,但a不能被记录在该迹中.则a与b在选择结构中.算法4需要遍历日志L中的所有迹,在算法4中包含2层循环.|L| 表示日志L中迹的数目.因此,算法4的复杂度是O(|L|2).
对于图5的非正确模型N2,假设事件日志中包含2条迹:l4=〈B,C,D,E,F,G,I〉和l5=〈B,C,E,D,F,G,J〉.对于l4=〈B,C,D,E,F,G,I〉,在变迁集T中不存在ti和tj(1≤i,j≤|T|),有α(ti)=D和α(tj)=I.因此,D和I是额外活动,需要插入到N2中.同样,对于l5=〈B,C,E,D,F,G,J〉,D是一个额外活动.

Fig. 5 An incorrect process model N2图5 非正确模型N2

Fig. 6 The repaired model of N2图6 流程模型N2的修正模型
在l4=〈B,C,D,E,F,G,I〉与l5=〈B,C,E,D,F,G,J〉中,◆D∩D◆={E}.因此,D与E在一个并行结构中,并且并行结构可以正确的重演这2条迹.由N2可以看出,E是在一个顺序结构中.因此,需要构建一个包含D与E的并行结构,将该并行结构插入到N2中.
l4=〈B,C,D,E,F,G,I〉包含I但不包含J.l5=〈B,C,E,D,F,G,J〉包含J但不包含I.这意味着迹中只能包含这2个活动中的1个.因此,只有包含I与J的选择结构可以正确的重演这2条迹.N2的修正模型如图6所示:
3.3 改变子流程
通过在模型中添加活动或删除活动可以改变模型的行为,但通过改变模型的子流程同样可以改变模型的行为.如果迹中的一些活动关系不能被模型中相应的子流程描述,则需要在模型用可以描述活动关系流程将相应的子流程替换.换句话说,如果迹中存在异常活动,则需要改变模型中的子流程.下面给出了替换模型子流程的方法.
如果迹中存在异常活动e,则必定存在包含e的子日志La.模型中对应于La的子流程Na不能重演

定义16.A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型.l=lsljlkelmlnlu是Ns的一条迹,且α-1(l)=α-1(lsljlkelmlnlu)=α-1(ls)α-1(lj)α-1(lk)α-1(e)α-1(lm)α-1(ln)α-1(lu)=σsσjσktiσmσnσu(1≤i≤|T|).如果•ti⊆或者•⊆•σn,则称e(α(ti)=e)是一个异常活动.
给定流程模型Ns和异常活动e,算法5给出了改变子流程的方法.
算法5. 改变Ns中包含e的子流程.
FunctionChangeBehavior(Ns,e)
②Na=null;
③T是变迁集合,T=transitions set;
④la=DetermineSubtrace(e);
⑤La=DetermineSublog(la);
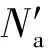
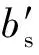
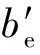
⑨σa=α-1(la);
⑩ for (i=0;i≤|T|;i++)
算法6. 确定Ns不能重演的子迹.
FunctionDetermineSubtrace(e)
①A是活动集合,A=activities set;
②L是一个事件日志,L∈B(A*);
③t=α-1(e);
④la=e;
⑤ for (i=0;i≤|L|;i++)
⑥σi=α-1(li);
⑦ if (t∈&(σi))
⑧j=σi(t);
⑨k=σi(t);
⑩ if (α(•(•t))∉◆la)


算法6首先判断◆e中的活动是否与•(•t)(t=α-1(e))相同,将不同的活动添加到la中.然后迭代的判断◆la中的活动,将所有不同的活动添加到la中.◆e中的活动查找完之后,对e◆中的活动进行相同的操作.在每一次的循环中需要对日志L中的所有迹进行遍历,需要遍历每条迹中的所有活动.|l|表示L中最长迹的长度,因此,算法6的复杂度是O(|L|×|l|).
算法7. 确定需要重新发现的子日志.
FunctionDetermineSublog(la)
①A是活动集合,A=activities set;
②L是一个事件日志,L∈B(A*);
③La={la};
④ for (i=0;i≤|L|;i++)
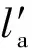
⑥ for (j=0;j≤|li|;j++)
⑦ if (li[j]∈&(la))
⑨ end if
⑩ end for
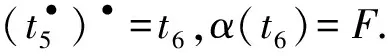

Fig. 7 An incorrect process model N3图7 非正确模型N3

Fig. 8 The repaired model of N3图8 流程模型N3的修正模型
3.4 修正循环结构
在修正有循环结构的模型时,需要确定迹中重复的子迹,在模型中找到可以描述该子迹的子模型,在迹中确定“redo”活动,通过在模型中添加“redo”活动,使模型可以重演重复的子迹[28].因此,在修正模型时需要在模型中确定循环体,并在模型添加“redo”活动.
定义17.A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型.l=lslbe…lblu是Ns的一条迹.lbe是一条循环子迹,且l(lb)-l(e)=1.如果Ns可以重演lb,但ti∈T(1≤i≤|T|):α(ti)=e,则称lb为循环体,e为“redo”活动.
定义17表明迹l可以在实际情况下执行,但是Ns中不存在“redo”活动e,因此只能重演第1次出现的子迹lb,其他重复的子迹lb不能重演.为了修正Ns可以重演其他的lb,需要在模型中添加活动e.
定理3.A表示一个活动集,Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型.L是关于Ns的一个事件日志,e对于Ns是一个额外活动,且∃l∈L:l(e)>1.那么可以通过e确定迹中的重复子迹.
证明.e是Ns的一个额外活动,且∃l∈L:l(e)>1.对于l(e)>1,那么在l中e至少迭代了2次.那么在这第1次e与第2次e之间存在一条子迹lb,且l(lb)-l(e)=1.因此e是“redo”活动,lb是重复子迹.
证毕.
给定流程模型Ns和“redo”活动e,算法8给出了发现和添加循环结构的方法.

Fig. 9 An incorrect process model N4图9 非正确模型N4
算法8. 在模型Ns发现并添加循环结构.
FunctionAddLoops(Ns,e)
②Nb=null;
③T是变迁集合,T=transitions set;
④t|T|+1是额外活动, 即α(t|T|+1)=e;
⑤lb=DetermineLoopbody(e);
⑥σb=α-1(lb);
⑦ for (i=0;i≤|T|;i++)
⑧ if (ti∈&(σb))
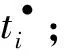
⑩ end if
在算法8中,e是1个“redo”活动.函数Determine-Loopbody(e)确定了重复子迹lb.根据lb中的活动,可以找到对应该于lb的子模型Na.在Ns中添加活动e之后,Ns可以重演其他迭代的lb.在本文中,假设循环体可以正确重演第1次迭代的lb,然后用算法8修正有循环结构的模型.如果循环体不能重演lb,就用前面提到的方法对循环体进行修正.有些情况下,迹中只包含重复子迹,没有“redo”活动,那么在修正模型时需要加入不可见变迁作为“redo”活动.函数DetermineLoopbody(e)可以确定重复子迹lb,在算法9中给出了其实现方法.
算法9. 确定重复子迹.
FunctionDetermineLoopbody(e)
①A是活动集合,A=activities set;
②L是一个事件日志,L∈B(A*);
③lb=ε;
④ for (i=0;i≤|L|;i++)
⑤ if (e∈&(li))
⑥ for (j=0;j≤|li|;j++)
⑦ if (li(li[j])>1且li[j]∉&(lb))
⑧lb=lbli[j];
⑨ end if
⑩ end for
在算法9中,需要确定活动e是否在li.如果e存在于li中,则可以通过li(li[j])确定重复的活动.其中li[j]表示li中的第j个活动,li(li[j])表示在li中li[j]的发生次数.li(li[j])>1表示li[j]是重复活动,li[j]应该在重复子迹lb.|l|表示日志L中最长迹的长度,在每次循环中需要遍历L中的每一条迹,对于迹li需要遍历迹中的每一个活动,因此,算法9的复杂度是O(|L|×|l|).
对于图9的非正确模型N4,假设事件日志中包含2条迹:l7=〈A,B,C,D,E,G,B,D,C,E,G,B,C,D,E,F,I〉和l8=〈A,B,D,C,E,G,B,C,D,E,H〉.
〈B,C,D,E,G〉或〈B,D,C,E,G〉是2条迹中的重复子迹.N4不能描述活动G,且l7(〈B,D,C,E〉)>1,l8(〈B,D,C,E〉)>1.因此,G是“redo”活动,〈B,D,C,E〉是循环体.N4可以正确重演〈B,D,C,E〉,在N4中添加活动G且•G={b6},G•={b1}.N4的修正模型如图10所示:
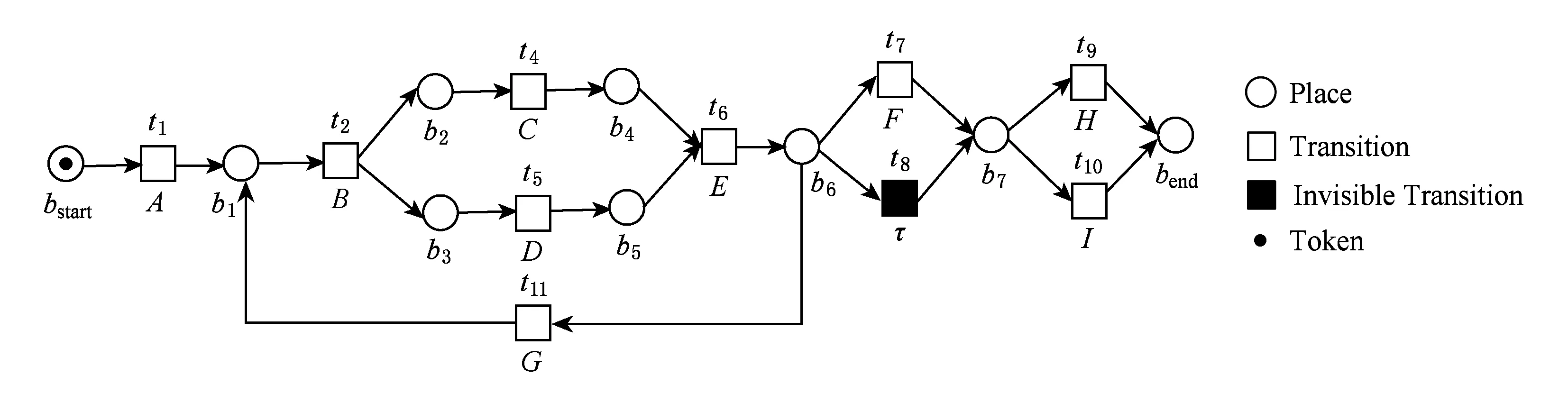
Fig. 10 The repaired model of N4图10 流程模型N4的修正模型
3.5 完整修正
如果流程模型Ns可以重演日志L,则不需要对模型进行修正.如果Ns不能重演L,则需要根据L对Ns修正.对于L中的迹,需要判断能否在模型重演,如果不能重演,则要找出迹与模型之间的偏差,然后根据偏差的类型,对模型进行相应的修正.根据日志L,算法10给出了对模型Ns的修正方法.
算法10. 根据日志L对模型Ns修正.
FunctionModelRepair(Ns,L)
② for (i=0;i≤|T|;i++)
④ break;
⑤ else
⑦ for (j=0;j<|DE|;j++)
⑧ if (dj是移除的活动)
⑩ end if
定理4.Ns=(P,T;F,α,α-1,mi,mf)是一个流程模型,L是关于Ns的一个事件日志.根据日志L,
证毕.
4 仿真实验
对本文提出的模型修正方法进行了手工模拟,对重新发现的挖掘方法与增加子流程的修正方法在ProM 6(process mining toolkit)上进行了验证.运行ProM的计算机需要是64位的Win7系统,3.20 GHz的处理器及1 GB的Java虚拟内存.在本节,给出了模型修正方法的实验评价.
4.1 实验数据
在这部分,根据青岛某三甲医院信息系统的流程模型与事件日志给出了2个实验,实验结果表明了本文方法的正确性与实用性.医院信息系统的住院流程模型如图11所示.但是由于每个医生和病人在执行流程时,根据不同的需求会有不同的处理方式.因此,在医院观察到的实际流程会与参考模型(reference model)存在偏差.
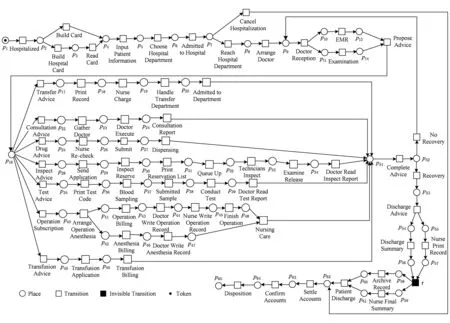
Fig. 11 A process model of hospitalization in a hospital图11 医院的住院流程模型
从医院信息系统中提取了5个未加工的日志(L1~L5).从这些日志中,通过删除明显不拟合参考模型的案例得到了5个过滤的日志(L1f~L5f),比如,删除缺少开始活动或不完整的日志.表1显示了这10个日志的一些属性,会在接下来的内容讨论.在这个表中列出了迹的数目、最小和最大长度,利用过滤的日志(L1f~L5f)进行手工修正时添加的变迁和库所的数目以及移除的变迁数目.

Table 1 10 Logs from Hospital to a Reference Model and the Properties of Manual Repaired Models
4.2 手工修正
为了获得指导模型修正的最优标准,我们得到了专家用手工修正的参考模型.根据日志L1f手工修正的模型如图12所示,对参考模型进行改变:添加了4个活动、跳过了1个活动、删除了2个活动、模型的修正部分由虚线圆标出.参考模型中有64个库所、68个变迁、149条弧,表1给出了根据每个过滤日志通过手工修正得到的模型与参考模型之间的差别.根据日志L5f修正,对模型的改变最大,因为需要添加子流程,跳过一些变迁并删除一些变迁.根据L1f和L2f的修正,对移除活动的改变比较少.根据L4f的修正,添加的活动与移除的活动相等.
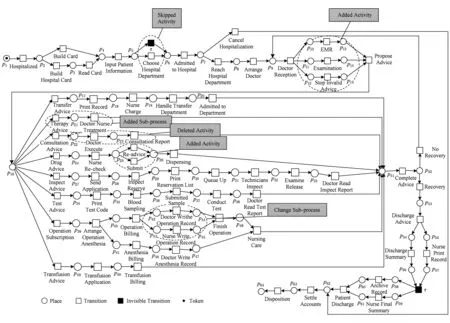
Fig. 12 Manually repaired model for log L1f图12 根据日志L1f手工修正的流程模型
4.3 实验对比
对于给定的日志与流程模型,第3节给出了模型修正的方法,使修正的流程模型符合给定的事件日志.函数RemoveActivity(Ns,e)可以识别跳过的活动与删除的活动,并将这些活动从流程模型中移除.函数AddActivity(Ns,e)可以识别额外的活动,并将这些活动添加到流程模型中.函数Change-Behavior(Ns,e)可以识别不能被模型描述的子日志,并用重新发现的子流程替换模型中的相应部分.函数AddLoops(Ns,e)可以识别日志中的“redo”活动,并在模型中添加循环结构.函数ModelRepair(Ns,L),可以根据日志L,对模型Ns进行整体修正.
根据提取的5个过滤日志,手工模拟本文提出的修正方法,对参考模型进行了修正.对于每个过滤日志,通过ProM 6上的Repair Model[29]插件完成了增加子流程方法对参考模型的修正,利用ProM 6中Alpha Miner[18]插件得到了重新挖掘的流程模型.为了评价论文中提出的模型修正技术,我们进行实验对比.
4.3.1 模型相似度
由定义11可知,修正的模型要与参考模型尽可能相似.图编辑相似度(graph edit similarity)[30]大致地表明了参考模型与修正/重新发现模型(repaired/rediscovered model)之间的差异部分,即1.0表示模型完全相同.为了证明基于引发序列修正的流程模型(process model repair via alignment)的有效性,根据文献[30]中的图编辑相似度公式,手工计算了参考模型与基于引发序列修正的模型之间的相似度、手工修正的模型与参考模型之间的相似度、增加子流程修正的模型(add sub-processes repaired model)[29]与参考模型之间的相似度以及Alpha算法[18]发现模型与参考模型之间的相似度,其结果如图13所示:

Fig. 13 Similarity on different repair methods图13 对于每个日志不同修正模型之间的相似度
由图13可知,手工修正模型、基于引发序列的修正模型、增加子流程的修正模型都与参考模型非常相似,因为其相似度值基本在0.9以上.手工修正的模型较基于校对序列修正的模型相似于参考模型,比如对于日志L2f来说,基于引发序列修正模型与参考模型的相似度是0.952 4,手工修正模型与参考模型的相似度是0.958 7.在有些情况下,基于引发序列修正的模型比增加子流程修正的模型更相似于参考模型,比如对于日志L3f来说,基于引发序列修正模型与参考模型的相似度是0.924 7,增加子模型修正模型与参考模型的相似度是0.880 9.但有些情况下,增加子流程修正的模型比基于引发序列修正的模型更相似于参考模型,比如对于日志L4f来说,增加子模型修正模型与参考模型的相似度是0.946 0,基于引发序列修正模型与参考模型的相似度是0.922 3.这是由于有些情况下,基于引发序列的修正方法会改变参考模型的子流程,而增加子流程的修正方法会在参考模型中加入一个结构比较复杂的子流程.通过Alpha算法重新挖掘得到的模型与参考模型之间的相似度比较差,其相似度基本都小于0.9,这是因为根据日志重新挖掘得到的模型可能会改变参考模型的结构.
4.3.2 迹的完全重演率
模型修正的目的是使修正的流程模型可以重演(大多数)相应的事件日志.迹的完全重演率指的是模型可以完全重演的迹所占日志中迹的百分比.通过迹的完全重演率可以证明修正方法的正确性,即100%意味着模型可以完全重演日志中的所有迹.为了检测基于引发序列模型修正的正确性,通过ProM中的Replay a Log on Petri Net for All Optimal Alignment插件,计算日志L1f~L5f在参考模型,增加子流程修正模型与Alpha算法发现模型上的所有最优校准,并统计了日志在各模型上重演得到的最优校准(即校准序列中只有同步动作,没有日志动作或模型动作)的条数,以此作为日志可以在模型完全重演迹的条数.对于基于引发序列修正模型,通过模拟迹在模型上的重演,统计了日志在模型上完全重演迹的条数.修正或重新发现模型上迹的完全重演率如图14所示:
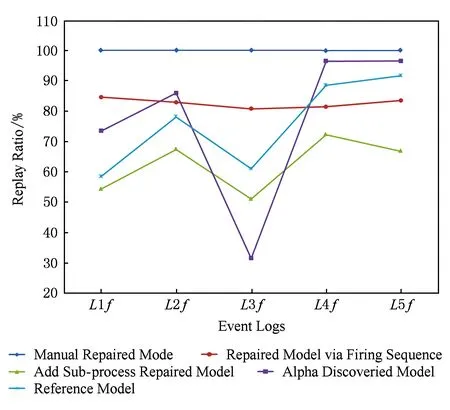
Fig. 14 Replayed trace percentages of different repair methods for logs图14 对于每个日志不同修正模型上迹的完全重演率
从迹的重演率上可以看出,手工修正模型可以完全重演过滤的5个日志中的所有迹,因为迹的重演率都是100%.基于引发序列修正的模型基本可以完全重演日志中80%以上的迹.而参考模型的迹重演率基本都在80%以下,由此可以证明本文所提修正方法的正确性.而通过Alpha算法挖掘发现模型的迹重演率不稳定,比如对于L2f来说,迹的重演率是85.95%;而对L3f来说,其结果是31.53%,这是由于重新挖掘的模型不一定能够解决现有模型存在的问题.而增加子流程修正模型的迹重演百分率都比较低,这是由于增加子流程的修正方法不能修正模型中的选择分支结构,而参考模型中存在多个选择分支.根据日志L1f~L5f,通过增加子流程修正的模型都将参考模型中的一条正确分支上所有活动修正为不可见变迁,这导致在求模型与日志的所有最优准时,将日志中的相应活动当作了日志动作.日志与模型最优校准的条数会相应减少,导致修正模型的迹重演率严重降低.
5 总 结
本文给出了一种流程模型的修正方法.在模型修正的过程中,主要考虑模型的拟合度.对于日志中从来没记录的活动,给出了将这些活动移除流程模型的方法.对于流程模型没有描述的活动,给出了在模型的合适位置添加子流程的方法.对于迹中活动关系与模型中相应的子流程描述不一致的,给出了改变模型子流程的方法.该模型修正方法目的是使得到的修正模型可以重演(大多数)相应的事件日志,并尽可能地与参考模型相似.最后通过相似度与迹的完全重演率证明了所提方法的有效性与正确性.
未来工作是如何修正存在循环结构的流程模型,并在模型修正的过程中参考模型的其他符合性标准,比如泛化度与精确度等.
[1] Manyika J, Chui M, Brown B. Big data: The next frontier for innovation, competition and productivity[EB/OL]. (2011-07-01)[2015-05-20]. http://www.mckinsey.com/insights/business-technology/big_data_the_next_frontier_for_innovation
[2] Li Guojie. The scientific value of big data research[J]. Communications of the CCF, 2012, 8(9): 8-15 (in Chinese)(李国杰. 大数据研究的科学价值[J]. 中国计算机学会通讯, 2012, 8(9): 8-15)
[3] Olson D L, Kesharwani S. Enterprise Information Systems: Contemporary Trends and Issues[M]. River Edge, NJ: World Scientific, 2009: 13-16
[4] van der Aalst W M P. Process Mining: Discovery, Conformance and Enhancement of Business Processes[M]. Berlin: Springer, 2011: 1-10
[5] Wang Lu, Du Yuyue, Liu Wei. Aligning observed and modelled behaviour based on workflow decomposition[J]. Enterprise Information Systems, 2017, 11(8): 1207-1227
[6] Wang Lu, Du Yuyue. An alignment-based identifying method of the problem areas within process models[J]. Journal of Shandong University of Science and Technology: Nature Science, 2015, 34(1): 42-46,53 (in Chinese)(王路, 杜玉越. 一种基于校准的模型问题域识别方法[J]. 山东科技大学学报:自然科学版, 2015, 34(1): 42-46,53)
[7] Du Yuyue, Sun Yanan, Liu Wei. Petri nets based recognition of model deviation domains and model repair[J]. Journal of Computer Research and Development, 2016, 53(8): 1766-1780 (in Chinese)(杜玉越, 孙亚男, 刘伟. 基于Petri网的模型偏差域识别与模型修正[J]. 计算机研究与发展, 2016, 53(8): 1766-1780)
[8] Rodrguez A, Fernndez-Medina E, Piattini M A. BPMN extension for the modeling of security requirements in business processes[J]. IEICE Trans on Information and Systems, 2007, 90(4): 745-752
[9] van der Aalst W M P. Formalization and verification of event-driven process chains[J]. Information and Software Technology, 1999, 41(10): 639-650
[10] Murata T. Petri nets: Properties, analysis and applications[J]. Proceedings of the IEEE, 1989, 77(4): 541-580
[11] Du Yuyue, Qi Liang, Zhou Mengchu. A vector matching method for analyzing logic Petri nets[J]. Enterprise Information Systems, 2011, 5(4): 449-468
[12] Du Yuyue, Qi Liang, Zhou Mengchu. Analysis and application of logical Petri nets to e-commerce systems[J]. IEEE Trans on Systems, Man, and Cybernetics: Systems, 2014, 44(4): 468-481
[13] Du Yuyue, Jiang Changjun, Zhou Mengchu. A Petri net-based model for verification of obligations and accountability in cooperative systems[J]. IEEE Trans on Systems, Man, and Cybernetics, Part A: Systems and Humans, 2009, 39(2): 299-308
[14] Du Yuyue, Jiang Changjun, Zhou Mengchu, et al. Modeling and monitoring of e-commerce workflows[J]. Information Sciences, 2009, 179(7): 995-1006
[15] Du Yuyue, Wang Lu, Qi Man. Constructing service clusters based on service space[J]. International Journal of Parallel Programming, 2017, 45(4): 982-1000
[16] Rozinat A, van der Aalst W M P. Conformance checking of processes based on monitoring real behavior[J]. Information Systems, 2008, 33(1): 64-95
[17] Petkovic M, Prandi D, Zannone N. Purpose control: Did you process the data for the intended purpose?[C] //Proc of the 8th VLDB Int Conf on Secure Data Management. Berlin: Springer, 2011: 145-168
[18] van der Aalst W M P, Weijters A J M M, Maruster L. Workflow mining: Discovering process models from event logs[J]. IEEE Trans on Knowledge and Data Engineering, 2004, 16(9): 1128-1142
[19] Wen Lijie, van der Aalst W M P, Wang Jianmin, et al. Mining process models with non-free-choice constructs[J]. Data Mining & Knowledge Discovery, 2007, 15(2): 145-180
[20] Wen Lijie, Wang Jianmin, Sun Jiaguang. Invisible tasks from event logs[G] //Advances in Data and Web Management. Berlin: Springer, 2007: 358-365
[21] Badouel E. On the α-reconstructibility of workflow nets[G] //Application and Theory of Petri Nets. Berlin: Springer, 2012: 128-147
[22] Bergenthum R, Desel J, Lorenz R, et al. Process mining based on regions of languagesn[C] //Proc of the 5th Int Conf on Business Process Management. Berlin: Springer, 2007: 375-383
[23] Bergenthum R, Desel J, Mauser S, et al. Synthesis of Petri nets from term based representations of infinite partial languages[J]. Fundamenta Informaticae, 2009, 95(1): 187-217
[24] Cortadella J, Kishinevsky M, Lavagno L, et al. Deriving Petri nets from finite transition systems[J]. IEEE Trans on Computers, 1998, 47(8): 859-882
[25] van der Werf J M E M, Dongen B F V, Hurkens C A J, et al. Process discovery using integer linear programming[J]. Fundamenta Informaticae, 2008, 94(3): 368-387
[26] Wang Jianmin, Song Shaoxu, Zhu Xiaochen, et al. Efficient recovery of missing events[J]. Proceedings of the VLDB Endowment, 2013, 6(10): 841-852
[27] Wang Jianmin, Song Shaoxu, Lin Xuemin, et al. Cleaning structured event logs: A graph repair approach[C] //Proc of the 31st IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2015: 30-41
[28] van der Aalst W M P. The application of Petri nets to workflow management[J]. The Journal of Circuits, Systems and Computers, 1998, 8(1): 21-66
[29] Fahland D, van der Aalst W M P. Model repair-aligning process models to reality[J]. Information Systems, 2015, 47(1): 220-243
[30] Dijkman R M, Dumas M, Garcabauelos L. Graph matching algorithms for business process model similarity search[C] //Proc of the 7th Int Conf on Business Process Management. Berlin: Springer, 2009: 835-842
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
军事运筹与系统工程(2016年3期)2016-09-26 11:41:04
电脑知识与技术(2016年10期)2016-06-16 19:27:57
西南科技大学学报(哲学社会科学版)(2015年1期)2015-02-28 10:28:32
连环画报(2014年6期)2014-11-14 08:30:56
电子设计工程(2014年19期)2014-02-27 12:00:42
锻压装备与制造技术(2013年1期)2013-06-29 02:26:28
重庆理工大学学报(自然科学)(2012年5期)2012-07-06 02:02:38
