
边缘计算应用:传感数据异常实时检测算法
2018-03-28 05:08:42胡宇鹏李学庆
计算机研究与发展 2018年3期
张 琪 胡宇鹏 嵇 存 展 鹏 李学庆
(山东大学计算机科学与技术学院 济南 250101) (d.steven@sdu.edu.cn)
近年来,随着互联网、物联网、云计算等技术的不断发展与相互融合,我们已经逐步进入“万物互联、全面感知”的互联网新时代[1].近年来物联网的发展导致了大量的数据传感设备广泛应用于不同的领域,例如金融与能源行业、化工与石油行业、生物和医药行业等等.这些传感设备在改变人们的生活方式的同时也产生了海量的时序数据资源.以浙江省的电力网络为例,截止目前整个网络中已经部署了2 000万台以上的智能电表设备,每台电表以1 Hz为单位采集“时序”用电信息,全省一年采集的用电数据量已经达到了拍字节规模(petabyte, PB)[2].
尽管传感设备的类型各有不同,但其获取的数据可以分为2类:1)实时状态数据.表示某个时刻运行状态,例如速度、功率等;2)累加数据.表示一定范围内的数据累加量,例如里程、热消耗等.通常情况下,传感器以一定的频率采集数据,并将数据发送至相应的数据接收端.数据接收端将收到一组或多组在时间上存在严格先后顺序的一组或多组观测值序列,即“时间序列数据”.这些时序数据精准地记录着某个具体参数的实时变化情况,并在一定的时间范围内反映该参数的发展趋势和变化规律.因此基于传感设备所采集的时间序列数据不仅为后续的数据趋势展现等数据可视化工作提供了重要的数据来源,同时也是后续数据挖掘工作(分类、聚类、关联、预测)的基础与前提.
以中国空间技术研究院的卫星总装集成测试(assembly, integration and test, AIT)为例,针对整颗卫星的AIT测试被分为11个不同的测试阶段,每个测试阶段平均需要高速采集5 000多个卫星参数的“时序”状态数据.AIT测试人员,可以根据所获取到的卫星参数时序数据来判断卫星的某个具体部件的运转状态是否正常,而卫星设计师们则可以根据卫星在不同测试环节中的各个部件运转状态的汇总情况,得出相应的卫星整体“健康度”分析结论.而得出正确的“整星分析”结论的前提条件是传感器采集并传输的数据是可靠的.
但是在实际的数据采集场景中,传感设备在数据采集与传输的过程中,总是会出现一些异常,文献[3]针对实际的传感器数据集进行了数据异常检测的相关研究,研究结果表明:通过传感器获取高质量的数据是一件非常困难的事情,因为故障的出现次数、频率等都让人无法预料,并且相应的数据清洗与校准工作也并不容易.
根据上述情况的介绍,我们希望采取从时间序列数据分析的角度,对传感数据中出现的相应数据异常进行有效地识别,帮助后续的数据清洗工作对相应的数据异常进行有效的“平滑”操作,并保留传感数据中正常的数据波动情况,从而为后续的时间序列数据挖掘研究工作提供高质量的来源数据.
目前已有一些异常检测算法被提出.从早期的基于统计的检测算法[4]、基于距离的检测算法[5-6]、基于密度的检测算法[7]、基于神经网络的方法[8]、基于支持向量机的方法[9]以及聚类分析的方法[10]等.时序数据具有一些特殊的性质,异常检测算法应该考虑其特性.如Fu所言,在时序数据领域,异常检测的方法大部分都是基于模式识别与聚类进行异常检测[11].Vlachos等人[12]提出了准确周期检测的非参数方法并引进了时间序列新的周期距离策略.相似地,Keogh等人[13]通过检测当前数据与预制数据模型之间是否存在较大差异,从而实现时序数据的异常检测.Keogh等人[14]后来引入了一个基于检测数据象征性版本的特定的重新排序策略.除了离线方法以外,还存在一些在线检测算法.Chan等人[15]从多个时序数据生成了可理解的准确模型来进行异常检测.Wei等人[16]利用时间序列位图来进行异常检测.Fujimaki等人[17]设计了一个应用于大量遥感数据的新颖的异常检测系统,该系统主要利用相关向量的回归和数据的自回归进行异常检测.周大镯等人[18]在基于重要点(important point, IP)时间序列分割的基础上,提出了基于k近邻的局部异常检测算法. Cai等人[19]通过构建分布式递归计算策略以及k近邻快速选择策略提出了一种新的时间序列数据异常检测算法.
然而这些方法主要是针对单一传感来源数据进行相应的异常监测工作,而在传感网络中不同传感来源数据之间往往存在着大量“已知”的相关关系,具有相关关系的传感数据之间则肯定存在着一定的数据趋势变化规律,这些变化规律可以帮助我们对相应的数据异常进行有效的识别.
此外,需要特别强调的是:目前常见的传感数据异常检测处理方式是利用相对成熟的云计算模型[20]以及常见的大数据处理产品:Hadoop[21],Spark[22]等,将各种数据采集设备所获取的数据直接传输到云计算中心进行数据存储,并利用云计算中心强大的计算能力完成相应的异常检测与数据清洗工作.这种方式也被称为:基于云计算的集中式大数据处理模式.根据思科、国际数据公司(International Data Corporation, IDC)等机构的相关研究表明,到2020年连接到网络的无线设备数量将达到500亿台,随着边缘设备数据量的增加,网络边缘设备产生的数据,受网络带宽与云数据中心计算能力的限制,已经无法像过去那样直接传输到数据中心进行相应的数据操作.因此需要对现有的集中式大数据处理模型进行相应的调整,将云计算模型的部分计算任务迁移到网络边缘设备上,在减缓网络带宽压力的同时,降低数据中心的计算负载.
根据目前基于云计算的集中式大数据处理模式所面临的限制和瓶颈,本文提出基于边缘计算的分布式传感数据异常检测模型.利用边缘计算的大数据处理思想,尽可能地将相应的数据在接近数据源的计算资源上进行相应地处理,在减轻网络传输带宽压力的同时,提高了数据处理的整体效率.在分布式传感数据异常检测模型的基础上,本文提出了基于时间序列的传感数据异常检测算法(anomaly detection of multi-source sensing data based on time series, ADMSD_TS).本算法将根据时间序列数据的离群距离测算以及时间序列之间的相关性对相应的传感数据异常进行检测.即通过对“单一”时间数据序列中离群点的识别以及对具有相关关系的“多源”时间序列之间的数据变化趋势为检测基础,高效识别出多源传感数据集中的相应数据异常.实验结果显示本算法性能良好,检测时间短并且异常检出率高.
1 问题定义
根据引言的介绍,本节将给出基于时间序列的数据异常检测问题的相关定义.
定义1. 传感器所采集并传输的多源传感数据,可以按照时间序列数据的形式,简化表示为
TSm={S1,S2,…,Si,…,Sm},
(1)
Si={s1,s2,…,sj,…,sn},
(2)
其中,1≤i≤m,1≤j≤n,TSm表示多源传感数据的时间序列表示数据集合,m表示集合内的数据个数.式(1)中Si表示单一传感数据,在式(2)中n表示Si的长度.其中sj表示某个具体采集时刻的数据值,sj=(vj,tj),tj表示sj的时间标签,vj表示时刻tj的数据值,在时间序列中tj是严格递增的.
根据上面单一传感数据的时间序列表示形式Si,我们将引入滑动窗口(slide window, SW)[23],用来存放Si的部分数据,设SW的长度为Lensw并忽略SW中时间序列数据的时间标签,我们给出SW中时间序列数据的离群距离的定义.
定义2. SW中的部分时间序列数据可以简化表示为
STn={v1,v2,…,vt,…,vn} (1≤t≤n),
(3)
(4)
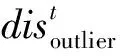
(5)
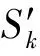
1) 基本相关
基本相关也被称为线性相关性,以热力系统为例,热功率P与轮轴转动速度V所组成的二元时间序列TS2={P,V},其中P=(p1,p2,…,pi,…,pn)与V=(v1,v2,…,vi,…,vn)(1≤i≤n),如满足vi≈kpi+b,则说明P,V之间存在二元线性相关性,并将其放入关系参数集合Ω2中,记为Ω2={P,V}.类似地,如三元时间序列数据TS3={S1,S2,S3}满足三元线性相关性.则将其放入参数集合Ω3中,记为Ω3={S1,S2,S3}.
2) 组合相关
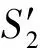
3) 转换相关
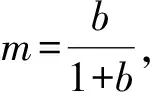
① 指数模型.y=aeb x对等式两边进行取对数操作,转换为lny=lna+bx,我们将原时间序列Y转换为新的时间序列lnY,并在随后的DCD中检测lnY与X的线性相关性.
③ 多项式模型.z=ax2+by+c,将原时间序列X进行乘方操作变为新的时间序列X2,然后在DCD中检测Z与X2,Y的线性相关性.
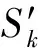
2 传感数据异常实时检测算法
本文提出的ADMSD_TS算法将会从传感数据本身的时序连续性检测(temporal continuity detection, TCD)以及传感数据之间的相关性检测(data correlation detection, DCD)两个方面,对传感数据的异常进行相应地检测.随后对这2种不同的检测结果进行相应地数据融合处理,完成最终的多源传感数据异常检测.本节将介绍基于传感数据异常检测的边缘式数据处理架构以及ADMSD_TS算法的具体实现.
2.1 基于边缘计算的数据架构
在我们的前期研究工作中,我们提出了基于异构设备的数据提取模型,基于此模型从多个企业的物联网数据源中提取各种形式的异构数据,并将这些多源异构数据保存到我们构建的一体化的工业大数据平台(industrial big data platform, IBDP)中,IBDP支持从数据提取、到数据处理、再到数据挖掘与可视化的智能大数据分析全过程[24].
根据引言部分的描述,我们不难发现:线性增长的集中式云计算能力已经无法满足数据量急剧增长的边缘数据的处理要求,此外将数据量持续增长的边缘数据集中到某个或某几个数据计算中心完成相应的数据计算任务,无论从技术上还是经济上来说,都将变得越来越不可行.根据文献[25]中边缘计算相关内容的介绍以及系统架构的描述如图1所示,我们考虑将IBDP的部分数据计算任务进行相应地迁移,并在相应的数据源附近建立边缘层数据处理节点,“就近”完成相应的数据处理任务.以本文所研究问题的具体场景为例,我们考虑在传感数据采集端附近,建立相应的边缘层数据节点,在接收传感数据的同时,完成相关数据的异常检测任务.相应的系统整体架构如图1所示:
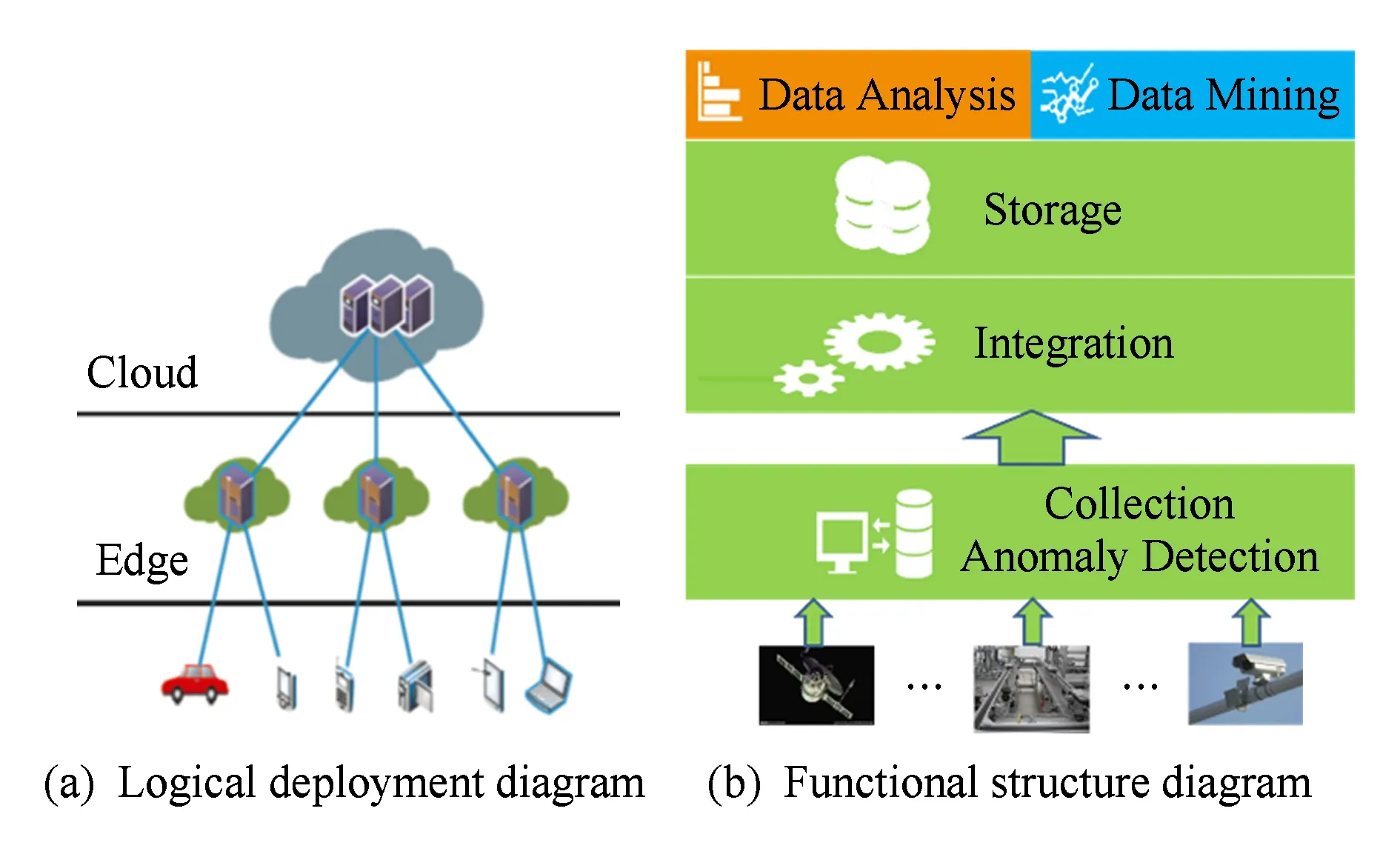
Fig. 1 System architecture diagram图1 系统整体架构图
根据图1的描述,我们将在数据采集层建立基于Storm的流数据处理结构,在进行数据接收的同时,对相应的传感数据进行异常检测.我们首先给出ADMSD_TS算法在Storm平台上的拓扑结构,如图2所示.
DataSpout接收采集到的传感数据(data source),并将其发送至各个TCDBolt,检查传感数据的时序连续性,如果通过DataSpout接收到的数据量大且参数类型繁多,还可以考虑通过数据划分模块(Partion)将数据进行相应的划分,并将划分后的数据传送至TCDBolt进行时序连续性检测.RelationSpout将接收用户发送的传感数据不同参数之间的关系模型集(relation source),RelationSpout会将相应的关系模型发送至DCDBolt,用于DCDBolt检测传感数据之间的相关性,如果关系模型集相对庞大,则也可以考虑采用数据划分模块先将其划分并再次发送至相应的DCDBolt.当TCDBolt完成时序相关性检测之后,多个TCDBolt将向对应的DCDBolt发送相应的传感数据,在DCDBolt进行数据相关性检查.与此同时,TCDBolt也会将时序连续性的检查结果发送至FusionBolt.等待DCDBolt中对应的相关性结果检测完毕以后,DCDBolt也会将对应的相关性检测结果发送至FusionBolt,完成最终的多源传感数据异常检测.用户也可以向QuerySpout发送相应的查询信息,QueryBolt会接收到用户的查询信息,并按照用户的要求查询相应的数据异常情况并进行输出.需要说明的是,如果在硬件设备条件允许的情况下(大容量SSD磁盘阵列或者大容量的内存)我们可以对DataSpout接收到的传感数据进行复制,并分别向TCDBolt与DCDBolt进行发送,同时进行相应地相关性检测与连续性检测,并将检测结果发送至FusionBolt进行相应的数据融合并完成多源传感数据异常检测.有关性能优化的相关工作,将会在我们今后的研究中进行分析与讨论.
Fig. 2 Topology diagram of ADMSD_TS图2 ADMSD_TS拓扑结构图
2.2 基于离群距离与序列相关性的异常检测
本节介绍基于时序数据的离群距离以及序列相关性的异常检测算法,该算法主要分为3步:1)对多元传感数据进行数据相关性检测(data correlation detection, DCD);2)对一元传感数据进行时序连续性检测 (temporal continuity detection, TCD);3)对前2步的异常检测结果进行融合处理(fusion process, FP),获取最终的检测结果.
2.2.1 基于相对离群距离的数据异常检测

算法1. 时间序列连续性检测TCD.
输入:时间序列数据TS、滑动窗口SW长度Lensw、子序列移动距离Lenmove、滑动窗口的最小长度阈值εsize以及相对离群距离阈值εdis;
输出:异常参数集合Ωab.
①Ωab=∅; /*初始化参数集合*/
② HashmapmapForTCD=newHashMap();
/*建立新的Haspmap用于存储异常参数*/
③qTS=InitQueue(Lensw);
/*初始化异常数据队列*/
④listSW=InitList(Lensw);
/*初始化滑动窗口列表*/
⑤ whileTS.length()>Lensw
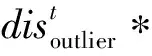
⑦ for eachvivaluein SW
⑨ts=(vi-lenmove-1,vi+lenmove);
⑩tssub={ts,vi,lenmove};
tsub.length<εsize/*如果vt在tssub中的εsize依然大于εdis且tssub的长度已经小于εsize*/
tssub.value+lenmove);
/*将异常参数存入Hashmap中*/
算法1主要利用传感数据自身的时序连续性并通过计算相对离群距离,对传感数据中可能出现的异常进行检测.本算法可以检测单源传感数据的数据异常情况,检测情况如图3所示,通过TCD算法,可以检测出该传感数据在框1、框2、框3中的数据异常情况.
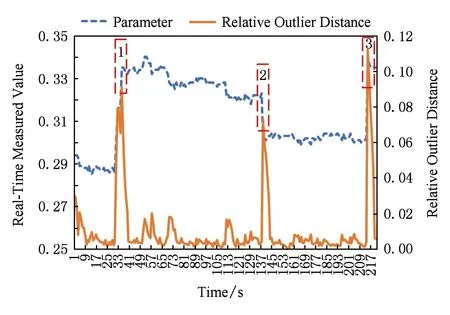
Fig. 3 Data abnormal detection for TCD图3 TCD数据异常检测
算法1只考虑了单源传感数据内在的时序连续性,而忽视了多源传感数据之间的相关性.因此只利用TCD进行传感数据的异常检测,可能存在部分数据异常无法有效发现的问题.
2.2.2 基于参数相关性的数据异常检测
传感器获取的传感数据之间往往具有一定的相关性.我们可以利用传感数据之间的相关性来判断某个传感数据在一定的时间范围内是否出现了异常.
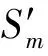
下面我们以定义3中的基本相关为例(组合相关、转换相关的处理流程与基本相关类似),说明DCD的异常检测流程.
例如在热力系统中,温度恒定时,热功率P与轮轴转动速度V是线性相关的.根据Pearson线性相关系数计算公式,可以求出P与V的线性相关系数:
(6)

另外,利用最小二乘法来求解线性逼近函数y=kx+b:
(7)
(8)
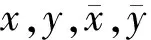
根据定义3,可以将热功率传感数据与流速传感数据以时间序列的形式表示为SP,SV. 利用式(6)验证2个参数之间的线性相关性,并利用式(7)与式(8)来获取热功率P与轮轴转动速度V的时间序列集合TS2={SP,SV}的二元线性模型的系数k与b.最后将TSm放入参数集合Ω2中,随后在DCD检测中验证TS2中时序数据实测值之间是否满足相应的线性相关性约束.
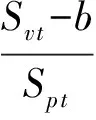
算法2. 基于数据相关性的异常检测DCD.
输入:参数集合Ωk列表、基于SW的传感数据集合TS;
输出:异常参数集合Ωa b.
①ΩR=ΩE=Ωa b=∅; /*初始化参数集合*/
② HashmapmapForDCD=newHashMap();
/*建立新的Haspmap用于存储异常参数*/
③qPare=InitQueue(Ωk);
/*初始化参数集合队列*/
④listTS=InitList(TS);
/*初始化传感数据集合列表*/
⑤ whileqPare.length()≠0
⑥item=qPare.Dequeue();
⑦ for each parameterpiinitem
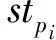
⑨ end for
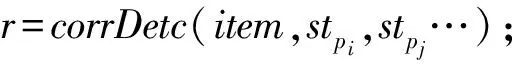
/*验证相关时序数据是否满足参数集合的约束*/
/*否则将参数并入ΩE*/
算法2主要利用传感数据之间的相关性,对传感数据中可能出现的异常进行检测.但该算法只考虑了传感数据之间的相关性,而忽视了传感数据自身的时序连续性.因此只利用DCD进行传感数据的异常检测,可能存在2个问题:
1) 如果参数集合Ωk中元素较少,很难利用传感数据的相关性对异常的传感数据进行准确的定位.假设参数集合Ω2中只存在一组线性相关序列TS2={S1,S2}.经过DCD的相关性检测,我们发现传感数据(S1,S2)中存在数据异常情况.如图4中框1、框2、框4所示.根据图4,我们只知道(S1,S2)中存在数据异常情况,但是到底是S1存在异常、还是S2存在异常、还是两者全部存在数据异常则无法进行更加准确的异常数据定位.
2) 如果参数集合Ωk中所有参数同时发生异常,则相应数据异常可能无法被DCD成功检测.根据图4中框3所示,当TS2={SP,SV}中SP与SV同时出现数据异常,且出现异常的数据也满足相应的二元线性模型的约束,则相应的数据异常在DCD中将无法被成功检测.

Fig. 4 Data abnormal detection for DCD图4 DCD数据异常检测示意图
2.2.3 ADMSD_TS算法实现
通过2.2.1节、2.2.2节的介绍,我们不难发现DCD与TCD均能对传感数据的异常进行相应地检测,但是这2个方法自身都存在着一些缺陷,可能导致相应的异常检测结果出现偏差.因此在前2步检测结果的基础上,再次对DCD与TCD的异常检测结果进行有效地数据融合处理(fusion process,FP),从而得出更加准确的异常检测结果.融合处理算法如算法3所示.
算法3. 异常检测结果的融合操作Fusion Process.
输入:异常ID列表listForAB,mapForTCD,mapForDCD,DCD算法中的ΩR;
输出:异常结果集Ωresult.
①Ωresult=∅; /*初始化异常结果集*/
②Ωdel=Ωadd=∅; /*初始化2个临时集合用于异常数据的整合*/
③ HashmapmapForResult=newHashMap();
/*建立新的Haspmap用于存储异常结果*/
④ for eachabIDinlistForAB
⑤Ωm=mapForDCD.get(abID);
⑥Ωc=mapForTCD.get(abID);
⑦ ifΩm≠∅ &&Ωc≠∅
⑧ for eachabminΩm
/*解决DCD中的问题1*/
⑨ ifabm∉Ωc
⑩traverse(abm,Ωm);
/*寻找abi∉{Ωk-abm}*/
/*利用TCD的数据异常,解决DCD的问题2*/
/*寻找abi∈Ωk-abc*/
/*将异常结果存入Hashmap中*/
融合处理算法将前2步DCD与TCD所获取的传感数据异常结果集进行了相应地融合,其基本步骤如下:
算法行①~③完成相应数据变量的初始化操作.
算法行④~⑥获取同一个abID的DCD检测异常集Ωm以及TCD检测异常集Ωc.
通过算法1~3的介绍,本文提出的ADMSD_TS算法实现如算法4所示.
算法4. 基于时间序列的多源传感数据异常检测算法ADMSD_TS.
输入:时间序列数据TS、滑动窗口SW长度Lensw、子序列移动距离lenmove、滑动窗口的最小长度阈值εsize以及相对离群距离阈值εdis;
输出:异常结果集Ωresult.
①Ωresult=∅; /*初始化异常结果集*/
② HashmapmapForTCD=newHashMap();
/*建立新的Haspmap存储TCD的异常集合*/
③ HashmapmapForDCD=newHashMap();
/*建立新的Haspmap存储DCD的异常集合*/
④ HashmapmapForResult=newHashMap();
/*建立新的Haspmap存储融合后的异常结果*/
⑤ whileTS.length()>Lensw
⑥mapForTCD=TCD(TSlen);
/*TCD检测*/
⑦mapForDCD=DCD(TSlen);
/*DCD检测*/
⑧mapForResult=Fusion(mapForTCD,mapForDCD); /*异常数据融合处理*/
⑨ end while
⑩ ReturnmapForResult. /*输出异常数据集,算法结束*/
2.3 ADMSD_TS算法性能分析
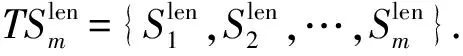
1) TCD复杂度分析.TCD的计算时间与滑动窗口SW长度Lensw以及子序列移动距离lenmove有关.由于最小长度阈值εsize、相对离群距离阈值εdis的限制,子序列的平均移动次数k将为某个固定常数,TSm中的m一般也为某个固定常数.TCD的计算复杂度为O(k×m×Lensw×lenmove),考虑到k与m为固定常数,而Lensw≪n且Lenmove≪n,TCD的计算复杂度在最坏情况下不超过O(n2).

3) FP复杂度分析.FP主要对TCD与DCD的异常检测结果,进行相应地优化操作,补充TCD与DCD未能发现的数据异常,同时也剔除了不存在异常的相应数据.根据算法3的详细流程,FP的计算复杂度为O(n2)
3 实验研究
3.1 实验环境
硬件环境:浪潮英信NF5270M4服务器、至强E5V4处理器、16 GB内存、2TB硬盘.
软件环境:JRE1.7.0_13,ZooKeeper-3.4.6,Storm0.9.1.
操作系统:CentOS6.5.
数据集:济南市政供暖系统中394栋楼宇的16 909个住户,预处理后的数据集为该规模下的住户供暖情况数据集(data of Jinan municipal steam heating system, JMSHSD).
在数据收集过程中,每个楼宇的发送器每个小时聚合了该楼宇中每个房间的数据,然后将这些数据传送给数据接收器.当一个接收器接收的数据达到阈值,或者接收器等待时间达到阈值.接收器一次将当前其接收的数据全部传输到我们预设的DataSpout端口,并将相关数据分发至TCDBolt开始进行时序连续性检测.当TCDBolt完成时序相关性检测之后,多个TCDBolt将向对应的DCDBolt发送相应的传感数据,在DCDBolt进行数据相关性检查.与此同时,TCDBolt也会将时序连续性的检查结果发送至FusionBolt.等待DCDBolt中对应的相关性结果检测完毕以后,DCDBolt也会将对应的相关性检测结果发送至FusionBolt,进行相应的异常数据集融合操作并完成最终的多源数据异常检测的最终结果.
数据根据处理方式的不同,其相应处理平均时间对比如表1所示,其中云计算的接收数据规模较大,带宽压力较高,其网络传输时间明显比边缘计算要长.由于云中心节点的计算能力相对较强,与边缘计算相比,其DCD所消耗的时间较短.在TCD与FP步骤中,由于受到数据规模及带宽的压力,云计算的处理时间相对较高.因此通过综合的比较与分析,边缘计算的异常检测性能更好.
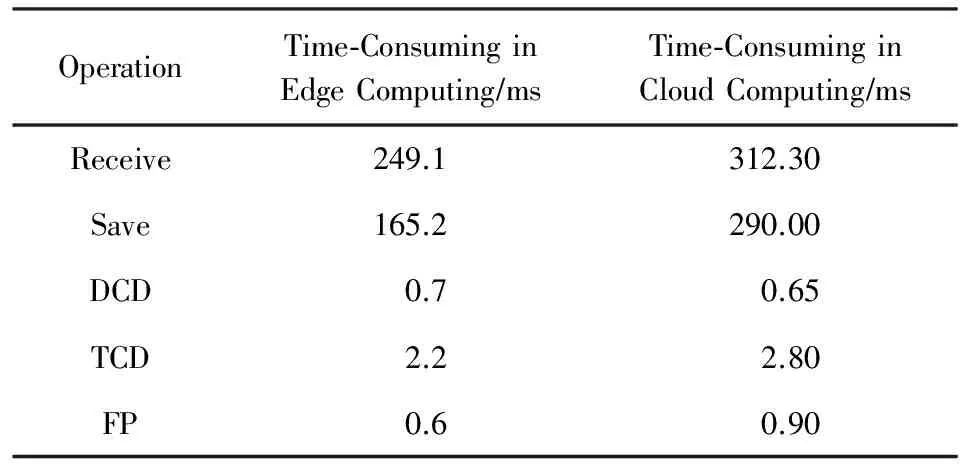
Table 1 Comparison of Time-Consuming in Each Step表1 各阶段耗费时间对比
3.2 异常检测结果分析
本节我们对传感数据异常检测的实验结果分析主要分为2个步骤:
1) 利用本文提出的异常检测算法(ADMSD_TS),对数据集JMSHSD中的部分传感数据(累计热量、热功率、累计流量、流速以及温差)进行相应的异常检测,并利用数据检测结果对ADMSD_TS算法及其内部的TCD,DCD操作检测的结果进行详细的分析.
选取数据集JMSHSD中部分传感数据(累计热量、热功率、累计流量、流速以及温差)共计100 000条,相关传感数据的参数描述如表2所示.传感数据部分实际观测值如表3所示.根据相应的热力学原理对表3的部分传感数据进行简单的分析,不难发现Pi和ΔWi/Δti以及si和Δvi/Δti可能具有线性相关性,随后我们利用相关系数的计算公式对上述传感数据进行了相应的计算. 计算结果显示:P和ΔW/Δt的相关系数为0.880,S和ΔV/Δt的相关系数为0.926.因此它们都满足线性相关的约束.
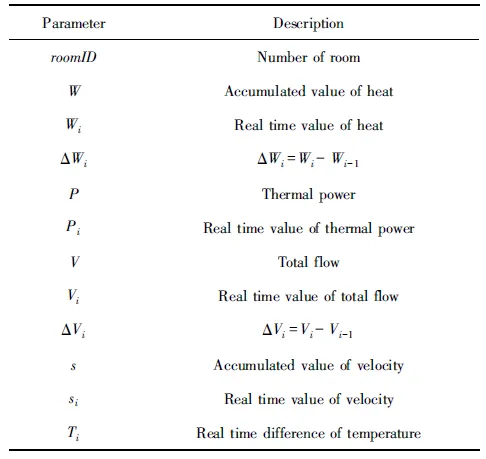
Table 2 Sensor Data Parameter Description

Table 3 Sensor Data Correlation Description
利用本文提出的ADMSD_TS算法进行异常数据检测,检测结果如表4所示.根据检测结果:在100 000条传感数据中,总共有560条P,W或PW异常数据,452条V,s或Vs异常数据以及213条T异常数据.异常数据总数可以表示为ADsum,成功检测出的异常数据可以表示为ADcor,则异常数据的检测精度ADpre的计算为
(9)
DCD只能发现560条异常数据中的430条(ADpre=0.77)以及452条中的382条异常数据,而且对于单一序列T,DCD则无法发现其中的异常数据. 而TCD能发现560条异常数据中的476条、452条异常数据中的354条,并能够对其发现的异常数据进行精确的定位.而本文提出的ADMSD_TS算法能够对DCD以及TCD的数据检测结果进行相应的数据融合操作,从而有效地避免了上述2个方法所存在的缺陷,因此ADMSD_TS算法的检测结果要明显好于前面的2个相对单一的异常数据检测方法.
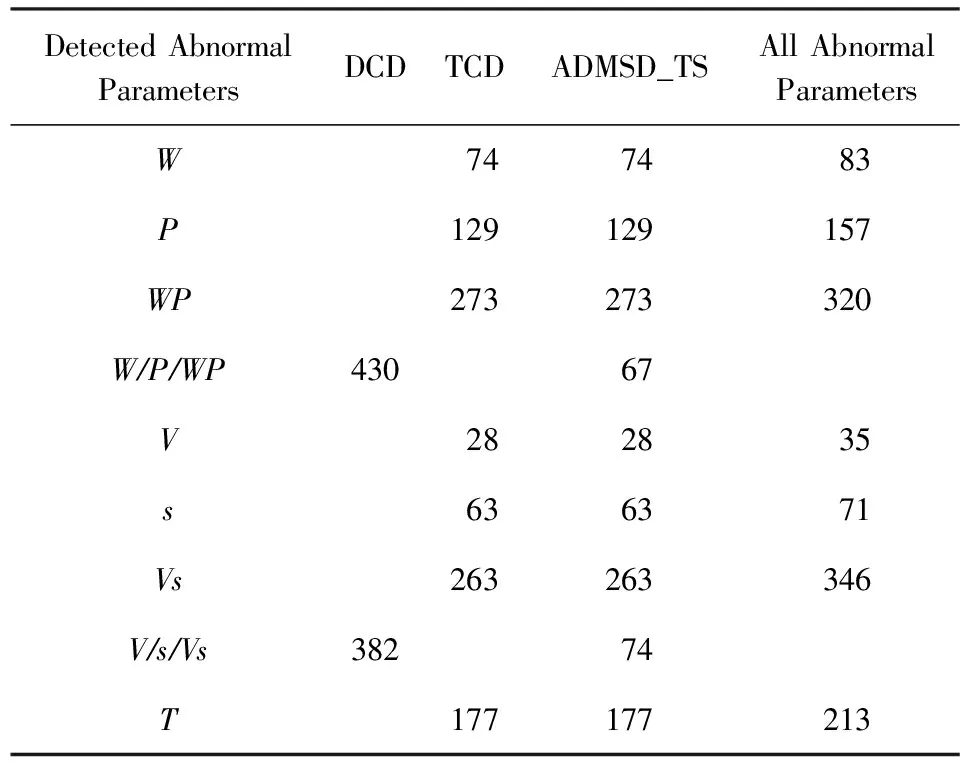
Table 4 Anomaly Detection Results
2) 基于数据集JMSHSD中的全部传感数据,分别利用本文提出的异常检测算法(ADMSD_TS)与基准方法(AD_IP[18],AD_KNN[19])进行传感数据异常检测,并对实验结果进行比较与分析.
我们选取数据集JMSHSD中近一年的全部传感数据共计2 016 983条,并将全部数据以月为单位分别利用ADMSD_TS,AD_IDP以及AD_KNN进行数据异常检测.随后计算异常数据检测精度ADpre的平均值,最后得到的异常数据检测结果如图5所示:

Fig. 5 Comparison of abnormal detection precision图5 异常数据检测精度对比
根据图5所示的异常数据检测精度比较,不难发现ADMSD_TS算法的检测结果要明显好于AD_IDP与AD_KNN.以上2个对比方法虽然分别采用基于时间序列重要点分割以及基于快速选择策略的k-近邻搜索去寻找相应的异常数据,但是上述方法并没有很好地利用多源时间序列之间“广泛”存在的相关关系对时间序列数据的变化趋势进行准确地判断,从而无法对多源相关数据异常进行有效地识别.因此上述方法的异常数据检测精度与ADMSD_TS算法相比,具有相对明显的差距.
4 结 论
本文提出了一种新的基于离群距离与序列相关性的异常检测算法,该算法采用边缘计算的处理模型,通过对参数之间的相关性与参数自身的时序连续性对相应的传感数据进行检测.通过在济南市政供暖数据集上的进行的算法验证,本算法具有处理速度快、异常检出率高的特性.未来我们还将继续优化该算法的边缘计算模型,并希望能将该检测算法推广到更广泛的实时数据应用场景中.
[1] Shi Weisong, Sun Hui, Cao Jie, et al. Edge computing—An emerging computing model for the Internet of everything era[J]. Journal of Computer Research and Development, 2017, 54(5): 907-924 (in Chinese)
(施巍松, 孙辉, 曹杰, 等. 边缘计算:万物互联时代新型计算模型[J]. 计算机研究与发展, 2017, 54(5): 907-924)
[2] Wang Xiaqing, Fang Zicheng, Wang Peng, et al. A distributed multi-level composite index for KNN processing on long time series[C] //Proc of the 21st Int Conf on Database Systems for Advanced Applications. Berlin: Springer, 2017: 215-230
[3] Sharma A B, Chen Haifeng, Ding Min, et al. Fault detection and localization in distributed systems using invariant relationships[C] //Proc of the 43th Int Conf on Dependable Systems and Networks (DSN). Piscataway, NJ: IEEE, 2013: 1-8
[4] Barnett V, Lewis T. Outliers in Statistical Data[M]. New York: Wiley, 1994: 20-29
[5] Knox E M, Ng R T. Algorithms for mining distancebased outliers in large datasets[C] //Proc of the 24th Int Conf on Very Large Data Bases. San Francisco: Morgan Kaufmann, 1998: 392-403
[6] Knorr E M, Ng R T. Finding intensional knowledge of distance-based outliers[J]. Journal of Very Large Data Bases, 1999, 99(12): 211-222
[7] Ramaswamy S, Rastogi R, Shim K. Efficient algorithms for mining outliers from large data sets[C] //Proc of the 29th Int Conf on Management of Data. New York: ACM, 2000: 427-438
[8] Markou M, Singh S. Novelty detection: A review—part 2: Neural network based approaches[J]. Signal Processing, 2003, 83(12): 2499-2521
[9] Mouräo-Miranda J, Hardoon D R, Hahn T, et al. Patient classification as an outlier detection problem: An application of the one-class support vector machine[J]. Neuroimage, 2011, 58(3): 793-804
[10] Wang J S, Chiang J C. A cluster validity measure with outlier detection for support vector clustering[J]. IEEE Trans on Systems, Man, and Cybernetics, Part B: Cybernetics, 2008, 38(1): 78-89
[11] Fu T-C. A review on time series data mining[J]. Engineering Applications of Artificial Intelligence, 2011, 24(1): 164-181
[12] Vlachos M, Philip S Y, Castelli V. On periodicity detection and structural periodic similarity[C] //Proc of the SIAM Int Conf on Data Mining. Society for Industrial and Applied Mathematics. Philadelphia: SIAM, 2005: 449-460
[13] Keogh E, Lonardi S, Chiu B Y. Finding surprising patterns in a time series database in linear time and space[C] //Proc of the 8th Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2002: 550-556
[14] Keogh E, Lin J, Lee S -H, et al. Finding the most unusual time series subsequence: Algorithms and applications[J]. Knowledge and Information Systems, 2007, 11(1): 1-27
[15] Chan P K, Mahoney M V. Modeling multiple time series for anomaly detection[C] //Proc of the 5th IEEE Int Conf on Data Mining. Piscataway, NJ: IEEE, 2005: 90-97
[16] Wei Li, Kumar N, et al. Assumption-free anomaly detection in time series[C] //Proc of the 17th Int Conf on Scientific and Statistical Database Management. Piscataway, NJ: IEEE, 2005: 237-242
[17] Fujimaki R, Yairi T, Machida K. An anomaly detection method for spacecraft using relevance vector learning[C] //Proc of the Advances in Knowledge Discovery and Data Mining. Berlin: Springer, 2005: 785-790
[18] Zhou Dazhuo, Liu Yuefen, Ma Wenxiu. Time series anomaly detection[J]. Journal of Computer Engineering and Applications, 2008, 44(35): 145-147 (in chinese)
(周大镯, 刘月芬, 马文秀. 时间序列异常检测[J]. 计算机工程与应用, 2008, 44(35): 145-147)
[19] Cai Lianfang, Thornhill N F, Kuenzel S, et al. Real-time detection of power system disturbances based onk-nearest neighbor analysis[J]. IEEE Access, 2017, 5(3): 5631-5639
[20] Armbrust M, Fox A, Griffith R, et al. A view of cloud computing[J]. Communications of the ACM, 2010, 53(4): 50-58
[21] Shvachko K, Kuang H, Radia S, et al. The hadoop distributed file system[C] //Proc of the 26th Symp on Mass Storage Systems and Technologies (MSST). Piscataway, NJ: IEEE, 2010: 1-10
[22] Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[J]. HotCloud, 2010, 15(1): 10-17
[23] Moon Y S, Whang K Y, Loh W K. Duality-based subsequence matching in time-series databases[C] //Proc of the 17th Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2001: 263-272
[24] Ji Cun, Shao Qingshi, Sun Jiao, et al. Device data ingestion for industrial big data platforms with a case study[J]. Sensors, 2016, 16(3): Article No.279
[25] Fang Wei. Paradigm shift from cloud computing to fog computing and edge computing[J]. Journal of Nanjing University of Information Science & Technology, 2016, 8(5): 404-414 (in Chinese)
(方巍. 从云计算到雾计算的范式转变[J]. 南京信息工程大学学报, 2016, 8(5): 404-414)
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
传感技术学报(2022年7期)2022-10-19 03:04:20
今日农业(2022年15期)2022-09-20 06:54:16
中国农业信息(2021年3期)2021-11-22 06:44:48
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
电子制作(2018年23期)2018-12-26 01:01:26
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
电子制作(2016年15期)2017-01-15 13:39:08
现代防御技术(2016年1期)2016-06-01 12:13:27
