
基于Spark的海量文本评论情感分析
2018-03-21 06:42:15奚雪峰顾建伟卓文婕陈帅天
苏州科技大学学报(自然科学版) 2018年1期
王 磊 , 曾 诚 , 奚雪峰 *, 皮 洲 , 顾建伟 , 卓文婕 , 陈帅天
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215009;2.苏州市虚拟现实智能交互及应用技术重点实验室,江苏 苏州215009;3.昆山市公安局指挥中心,江苏 苏州 215300)
随着网络的快速发展,越来越多的人活跃于网络,进行网络购物,进而产生大量的购物评论,购物评论不仅是用户在使用商品之后的一种反馈的有效方式,同时对于商户以及浏览者也都有较好的参考价值。但是目前绝大多数的评论都没有被有效利用,在浩如烟海的评论中,网站的管理者无法直接从中找到有用的信息,因而如何有效的挖掘处理这些评论具有重大意义。
最基础的情感分析方法是通过对句子进行打分来判定句子的情感类别。对句子中的每个单词都给予一个分数,例如带有乐观情感的单词得分为+1,带有悲观情绪的单词得分为-1。然后对句子中所有单词的得分进行求和得到一个最终的情感总分。
另外一个常见的方法是将文本视为一个“词袋”。将每个文本看成一个1×N的向量,其中N表示文本中包含的词汇的数量。该向量中每一列都是一个单词,其对应的值为该单词出现的频数。例如,词组“bag of bag of words”可以被编码为 [2,2,1]。这些数据可以被应用到机器学习分类算法中(如支持向量机,Logistic回归),从而预测未知数据的情感状况[1]。
Word2Vec[2]是由谷歌提出的一种模型,它包含两种不同的方法:Continuous Bag of Words(CBOW)和Skip-gram。CBOW的目标是根据上下文来预测当前词语的出现概率;而Skip-gram刚好相反,根据当前词语来预测上下文的概率。经过训练之后,该算法利用CBOW或者Skip-gram的方法获得了每个单词的最优向量。这些词向量已经捕获到了上下文的信息,并且可以代替词袋用来预测未知数据的情感状况,在得到相应的词向量之后,就能够将其作为各分类器的输入,从而实现句子情感的分析归类。赵刚[3],于潇[4]等通过构建情感词典并利用传统的机器学习算法完成文本情感的分析,有着较好的实验结果,但构建情感词典的方法费时费力且主观性较强。杨小平等[5]则利用统计模型进行情感词典的自动构建,通过Word2vec对文本进行相似度的计算,从而实现情感分类,该方法在二分类情感问题中取得了不错的效果,但面对情感的多分类问题时效果还有待确认。计莹华等[6]基于Word2Vec对文本进行语料训练,提出了多维情感词典的自动构建方法,研究了基于词分布密度的感情色彩消歧策略,对于情感分析的准确度有较大提升。
随着大数据时代的到来,以及硬件的飞速发展,神经网络再次被广泛关注,并在各个行业都取得了良好的应用效果。苏小英等[7]基于卷积神经网络实现了微博短文情感分析,模型对微博短文的情感分析有明显提升,但卷积神经网络结构复杂,参数众多,训练难度大。刘新星等[8]通过不同的神经网络来研究产品属性情感分析,采用直接循环图为语句建模,但提升效果并不明显。
笔者将利用word2vec及多层感知器完成情感分析任务。另外,随着文本数据量的不断增大,单机的内存和运算能力已经不能满足大数据量数据挖掘的要求,需要人们利用分布式计算系统进行并行处理。因此,文中采用Spark作为数据的处理平台。
1 任务定义
通过对现有语义分析模型的分析比较,选取适当的模型构建文本语义分析工具,实现批量处理用户生成的评论内容,提高工作效率,减少人力成本。
2 系统模型
为实现批量评论的提交与预测结果的快速获取,笔者设计了如图1所示的文本语义处理系统。

图1 系统流程图
在启动服务端之后,用户可在界面自行设置服务器ip以及端口号。在交互界面用户可以选择提交txt或xls格式的文档,点击提交将会触发监听事件,客户端获取文本框和文本域的内容并发送到服务端,在客户端内会设置消息头Path:或者String:;如果是文件,会通过scp协议的get、put方法将本地路径的文件放在内部设定的服务端文件位置,同时,文件名也会当作字符流发送到服务端;如果是字符流,则会将字符信息直接发送过去(此处使用的是socket)。当服务端处理完成后,客户端会将结果文本提取到对应的文件目录。
服务端启动后,会对设定的端口进行监听。当客户端发送请求时,会被socket接收,建立通信通道,传过来的字符信息会被MassageHandle类处理,其中的两个函数分别对应着获取消息类别:0代表路径,1代表字符消息,2代表消息头被篡改,无法被识别。消息内容因为消息包含消息头,所以要被处理掉,消息本身只会用作比较和处理,不会用来执行。获取的消息根据类别会被switch分类处理:如果是.xls文件则会被接收,直接执行handle方法进行处理;如果是字符内容,则会被写入新建的.xls文件中做统一处理。文本的处理流程如图1所示。
第一步 文件判别:在每次提交任务之后,首先服务端会删除对应的目录文件,服务端的脚本命令会放在指定目录下,del_*文件为对应脚本文件,在程序内会用java Progress类执行,调用Progress的waitFor()函数,在等待前一个脚本执行完成之后,开始执行第二个脚本;
第二步 分词:调用脚本对提交的文本文件进行处理,文本分词完成后,将结果保存在wordcut.txt文件;
第三步 将wordcut.txt提交至分布式文件存储系统hdfs,服务端将会首先判断是否有同名文件存在于hdfs当中,若存在则先删除上一次任务处理的文本;
第四步 数据标签预测:服务端向Spark集群提交处理任务,Spark集群从hdfs中读取wordcut.txt文件,调用训练好的相关模型,进行数据标签的预测;
第五步 获取结果:服务端调用脚本文件获取标签,并将其写入到.xls文件中,处理好后服务端会向客户端发送指令,触发在客户端的判断函数,调用scp的get方法,最终将处理好的文件存放到提交文件的目录中。Socket关闭,整个服务流程结束。
3 情感分析模型
文中设计的情感分析模型的执行流程如图2所示。首先,使用结巴分词对输入文本进行分词处理;其次,使用Wor2Vec模型进行词向量的转换,对文本进行特征的提取;最后,分别训练两个分类器,实现情感及评论价值的分类。
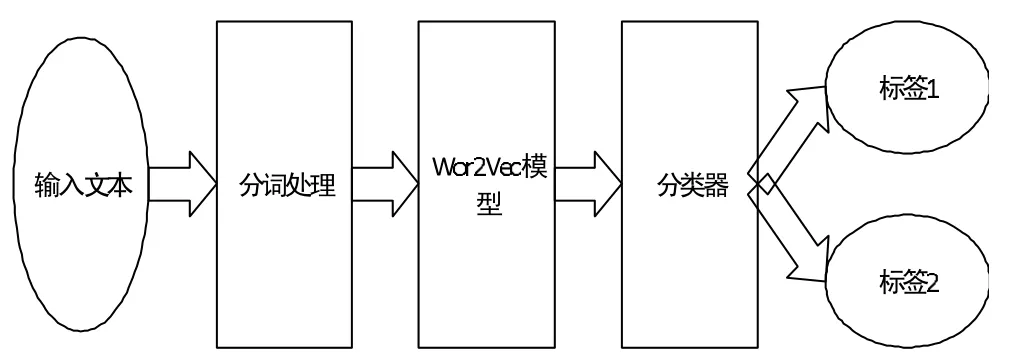
图2 情感分析流程图
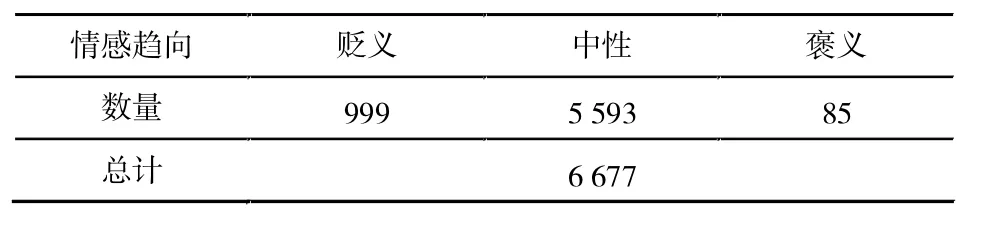
表1 情感趋向数据集规模

表2 评论价值数据集规模
3.1 数据清理与筛选
实验的数据集为第八届中国大学生服务外包创新创业大赛,A11赛题:基于机器学习的文本语义分析工具所提供的20 707条数据标注的评论数据。
笔者对数据进行人工清理与筛选,最终得到6 677条非重复评论,数据规模见表1和表2。每条评论带有两个标签:第一个标签代表该评论的情感趋向,包括“贬义”“中性”“褒义”三种类别;第二个标签代表该评论对于产品的改进所具有的价值,包含“关于产品的建议”“毫无意义的反馈”“问题但缺少关键信息”“问题,且包含关键信息(如详细的问题描述、步骤、场景、软硬件信息等)”四种类别。
筛选之后的数据各类别之间非常不平衡:(1)褒义评论85条,贬义评论999条,中性评论5 593条,褒义评论仅为中性评论的1.52%;(2)带有“关于产品的建议”标签的评论1 333条,“问题但缺少关键信息”的评论3 342条,“问题,且包含关键信息(如详细的问题描述、步骤、场景、软硬件信息等)”的评论1 756条,“毫无意义的反馈”的评论只有246条,约为“问题但缺少关键信息”评论的7.36%。
如此不平衡的数据集将会影响分类器的分类效果。因此,笔者又从京东爬取了5万条评论,标注了其中1 000条褒义评论和200条贬义评论,并对中性评论进行采样,抽取其中1 500条中性评论作为训练样本。
同样的,笔者标注了200条属于“毫无意义的反馈”的评论,对“问题但缺少关键信息”的评论进行采样,取出其中的1 500条,使各类数据达到平衡。
3.2 文本向量化
从维基百科爬取了约1G的中文文本,去除字符后使用结巴分词对文章进行分词,将分词后的文本作为Wor2vec模型的训练语料。随后对评论分词,并对每一句子的单词进行词向量转换,并将每一句的词向量同位相加来代表每一个句子向量。由于每一句评论的长短不一,为消除句子长短对最终结果造成的影响,对句向量做取平均处理,将其作为分类器的输入。
3.3 分类模型的选择
3.3.1 支持向量机(SVM)
支持向量机(SVM)算法被认为是文本分类中较为优秀的一种方法,它是一种建立在统计学习理论基础上的机器学习方法。它使用一种非线性的映射,把原训练数据映射到较高的维上,并在新的维上搜索最佳分离超平面。使用到足够高维上的、合适的非线性映射,两类的数据总可以被分开。
SVM分类器最初是为二值分类问题设计的,当处理多分类问题时,就需要构造合适的多分类器。可通过组合多个二分类器来实现多分类器的构造,而常见的两种方法分别为one-against-one和one-against-all[9]。
一对多法(one-versus-rest)在训练模型时,依次将一种类别作为一类,剩余的类别归为一类,对于一个k分类的问题需要训练出k个SVM模型。分别使用k个模型对给定数据进行分类,具有最大分类结果的类别即为数据所属类别。
一对一法(one-versus-one)则是在所有的类别中任选两类进行组合,进行模型训练,对于一个k分类问题需要训练k(k-1)/2个SVM模型,最后采取投票规则,对于给定数据,得票最多的类即为所属类别。
一对多法因为训练集任意产生偏倚,因而不是很实用。一对一法在分类类别较多时需要训练较多分类模型,但该实验中的分类问题是3分类和4分类,实际不会产生太大开销,因此,实验中采用一对一法对SVM算法进行多分类的扩展。
3.3.2 多层感知器
多层感知器是一种前馈神经网络,由多个节点层组成。每个层完全连接到网络中的下一层。输入层中的节点表示输入数据。所有其他节点,通过输入与节点的权重w和偏置b的线性组合,并应用激活函数,将输入映射到输出。

该系统使用的前馈神经网络共四层,分别为输入层、两个隐藏层和一个输出层。两个隐藏层分别包含25个节点。 中间层中的节点使用 sigmoid(logistic)函数 f(zi)=1/(1+e-zi),输出层中的节点使用 softmax 函数输出层中的节点数量N对应于类别数。
4 实验结果与分析
4.1 集群部署
通过sbt将程序及其依赖包打包成一个Jar包,启动hdfs及Spark集群,将测试数据上传到hdfs,通过Spark-Submit将Jar包和所需的参数提交给集群,待程序执行完毕即可从指定的hdfs输出路径中下载结果。
整个测试是在由三台Dell PowerEdge R720xd服务器组成的分布式集群上完成的,单节点核心数为32,内存为62G。程序通过Scala+sbt实现。Ubuntu版本为16.04,Hadoop版本为2.7.2,Spark版本为2.1.1,java版本为1.7.0_80,Scala版本为2.11.8。
4.2 模型评测指标
在文本分类中类别不平衡的情况经常出现,即一种类别远多于其他类别。

图3 算法评估指标
在这样的情况下,若测试样本中一类占所有样本90%,其他类只占10%,那么分类器只需要将所有样本都归为一类就能有90%的准确率,所以仅仅使用准确率无法判断分类器的性能优劣。为了关注所有类别的分类情况,于是在评价分类器效果时,引入信息检索中的混淆矩阵。算法评估指标见图3。
精度反映了被分类器判定的正例中真正的正例样本的比重。召回率也称为True Postive Rate,反映了被正确判定的正例占总的正例的比重,有一点值得注意的是当精度较高时往往召回率较低[10]。
使用F值和宏平均综合考虑精度和召回率两个指标,F值的计算公式如下

当A取1时,F-measure就是F1值。将所有类的F1值取算术平均就得到了宏平均(Macro-average)。
4.3 实验结果与分析
以召回率、准确率、宏平均值三个参数来作为评价指标。从表3评论情感的分类结果中可以看到,多层感知器在召回率、准确率、宏平均值三方面均要优于另两种分类器,而对于评论价值的分类效果,多层感知器也要略优于另外两种算法。
由实验结果可知,贬义评论的召回率很低。于是查看错分的贬义评论,发现大部分的贬义评论被分为了褒义,实际问题在于Wor2Vec转换的词向量虽然包含了上下文语义,但无法捕获情感信息,可能要尝试添加相应的情感维度,才能使褒义和贬义的情感能够有效区分。
由表4还发现对于评论价值的分类效果一般,其原因在于:一是通过Wor2Vec未能有效提取出评论价值的有效信息;二是获取句子向量时只是做了加和平均,损失了一部分句子的特征。
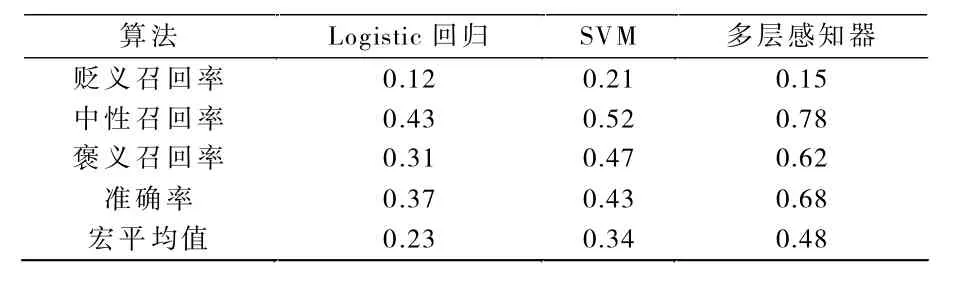
表3 评论情感实验结果对比

表4 评论价值分类实验对比
5 结语
该系统基于Spark平台实现了文本评论的情感分类以及评论价值的挖掘。通过实验比较,该系统以多层感知器作为情感分类算法,得到了较高的准确率(0.68)。同时对评论价值的分类也采用了与评论情感分类一样的策略,但两者的效果却存在偏差,可见对于评论价值挖掘并不能使用一般的情感分析方法[11]。接下来笔者将会进一步分析并提取关于评论价值的特征,并考虑采用卷积神经网络对转换后的句子向量进行分析处理。
[1]MUCHERINO A,PAPAJORGJI P J,PARDALOS P M.Introduction to Data Mining[M].Beijing:Posts&Telecom Press,2006.
[2]MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed representations of words and phrases and their compositionality[J].Advances in Neural Information Processing Systems,2013,26:3111-3119.
[3]赵刚,徐赞.基于机器学习的商品评论情感分析模型研究[J].信息安全研究,2017,3(2):166-170.
[4]于潇,万军,何翔,等.校园微博情感分析系统的设计与实现[J].河北工业大学学报,2013,42(6):24-29.
[5]杨小平,张中夏,王良,等.基于Word2Vec的情感词典自动构建与优化[J].计算机科学,2017,44(1):42-47.
[6]计莹华.基于机器学习的微博情感分析可视化系统[D].西安:西安电子科技大学,2014.
[7]苏小英,孟环建.基于神经网络的微博情感分析[J].计算机技术与发展,2015,25(12):161-164.
[8]刘新星,姬东鸿,任亚峰.基于神经网络模型的产品属性情感分析[J].计算机应用,2017,37(6):1735-1740.
[9]刘志刚,李德仁,秦前清,等.支持向量机在多类分类问题中的推广[J].计算机工程与应用,2004,40(7):10-13.[10]周志华.机器学习[M].北京:清华大学出版社,2016.
[11]杨东强.情感增强词向量构建方法及应用[D].上海:华东师范大学,2015.
猜你喜欢
东华大学学报(自然科学版)(2018年1期)2018-06-29 03:35:18
消费导刊(2018年8期)2018-05-25 13:19:48
电子测试(2018年1期)2018-04-18 11:52:35
网络安全和信息化(2017年9期)2017-11-07 06:30:48
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
