
基于测度学习支持向量机的钢琴乐谱难度等级识别
2018-03-15 07:46:39郭龙伟关欣李锵
智能系统学报 2018年2期
郭龙伟,关欣,李锵
虽然互联网中存在海量的钢琴乐谱资源,但其难易程度不一,对于业余和初级乐器学习者来说,由于缺乏专业知识和指导,难以有效地找到与自身学习难度匹配的乐谱来学习。专业音乐学习者一般依据固定进阶教材,但缺乏个性化、灵活的学习方案。此外,一些经典但难度高的乐谱,会有诸多简化版本存在。因此,有必要对海量的钢琴乐谱资源的难度等级进行区分。
现在绝大部分乐谱难度等级仍然依赖于专业人士主观判断。对于海量的数字乐谱,人工判断难度等级会是一个耗时耗力的巨大工程。人工主观判断也很难稳定、可靠地把握每个难度等级之间的区别,尤其对于多类别问题。不同的人对于同一首乐谱可能会给出不同的难度等级,甚至对于同一首乐谱,同一个人在不同的时间也会给出不同的难度等级。因此,自动识别乐谱难度等级的系统具有重要的理论意义和应用价值。
为网络中存在的数字乐谱提供难度等级标签将会大大提高寻找合适难度等级乐谱的效率,并能提高音乐网站的用户体验。通常研究中将乐谱难度识别归为模式分类问题,从符号乐谱中定义并提取难度相关特征,利用分类思想实现乐谱难度等级的识别。下面将针对不同的技术来回顾钢琴乐谱难度等级识别领域的研究现状。
Shih-Chuan Chiu等[1]最先开始钢琴乐谱难度等级识别研究。由于钢琴乐谱难度识别是一个相对较新的研究问题,现有的符号音乐特征(symbolic music feature)较少直接用于难度等级识别。所以他们首先定义8个与乐谱难度密切相关的特征,将此8个难度相关特征与语义特征一起作为特征空间。后用特征选择算法ReliefF[2]按照特征重要程度(即各个特征对难度等级的辨别能力大小)分配权值,选择权值最大的10个特征作为后续实现难度等级识别的特征空间。最终用3个回归算法:多元线性回归、逐步回归[3]、支持向量回归[4]实现难度等级识别。实验中,支持向量回归算法得到最好的效果,其R2统计量为39.9%[3]。
Véronique Sébastien 等[5]也将乐谱难度等级识别看作分类问题,他们利用无监督的聚类算法实现乐谱难度等级识别。首先定义7个难度相关特征,这些特征从MusicXML格式[6]乐谱文件提取。之后用主成分分析 (principal component analysis,PCA)将特征投影到低维空间,以降低特征维数。然后,用分层聚类(hierarchical clustering)[7]将乐谱聚成3类,即3个难度类别。
总的来说,无论是多元线性回归还是逐步回归都假设特征与难度等级之间为线性关系,此假设过于简化特征与难度等级之间的实际关系。而支持向量回归虽然可实现非线性拟合,但拟合结果尚不令人满意。与有监督算法相比,非监督算法,如分层聚类,虽能充分利用特征与难度等级之间的自然分布关系,但无法利用已有的难度等级标签作为先验知识提高识别效果。例如,实验中,原始乐谱数据是4个类别,Véronique Sébastien经过PCA降维,应用聚类算法,最终仅得到3个难度类别。
在现有有监督的回归拟合算法识别钢琴乐谱难度等级的研究中,支持向量回归有最好的拟合效果(其R2统计量值为39.9%)。但支持向量回归,更适合逼近、拟合连续分布数据,对于此离散类别的分类问题能力有限。所以本文利用一种与支持向量回归算法原理相近,但更适用于解决分类问题的支持向量机分类算法实现数字钢琴乐谱难度等级识别。
1 支持向量机理论
SVM是基于统计学习理论中经验风险最小化原则的一种机器学习算法[8]。SVM已广泛应用于纹理分类 (texture classification)[9]、文本分类[10]、人脸识别[11]、语音识别[12]等各个领域。理论和实践证明,SVM对噪声和离群点鲁棒性好,泛化能力强,经过扩展可解决多分类问题[8]。
SVM实现分类的关键是核函数,利用核函数[13]可以将低维线性不可分的问题转化到高维空间实现线性可分,同时避免因维数增加而导致过大的计算量。常用的核函数有线性核函数(linear kernel function)、多项式核函数 (polynomial kernel function)、高斯径向基核函数(Gauss radical basis kernel function,GRB)等[13]。由于本研究问题的特征数目远小于样本数目,并且为降低分类模型的参数复杂度,本文考虑采用高斯径向基核函数。
然而传统的基于高斯径向基核函数的SVM(GRB-SVM)算法假设特征不相关且权重相同,即不能根据特征对难度等级的贡献度差别对待。而在本应用问题中,特征对难度区分的贡献度不同。为弥补GRB-SVM不能根据特征重要程度差别对待的不足,本文结合测度学习(metric learning)理论,充分利用训练乐谱中关于难度等级的先验知识,从带难度等级标签的乐谱特征空间中有监督地学习到能更好区分钢琴难度的投影矩阵,保留特征之间的相关关系,从而利用该矩阵改进高斯径向基核函数,提出一种测度学习支持向量机分类算法——ML-SVM算法,实现数字钢琴乐谱难度等级识别。
2 算法原理与算法描述
本文提出的ML-SVM乐谱难度识别算法主要包括以下3部分:基于测度学习从训练数据中有监督的学习到能增加钢琴乐谱难度区分度的投影矩阵;得到新的距离测度,并利用该测度改进高斯径向基核函数,建立ML-SVM算法模型;最后利用网格搜索算法得到核函数参数的最优组合,建立分类模型,实现数字钢琴乐谱难度等级的识别。MLSVM乐谱难度识别算法框图,如图1所示。
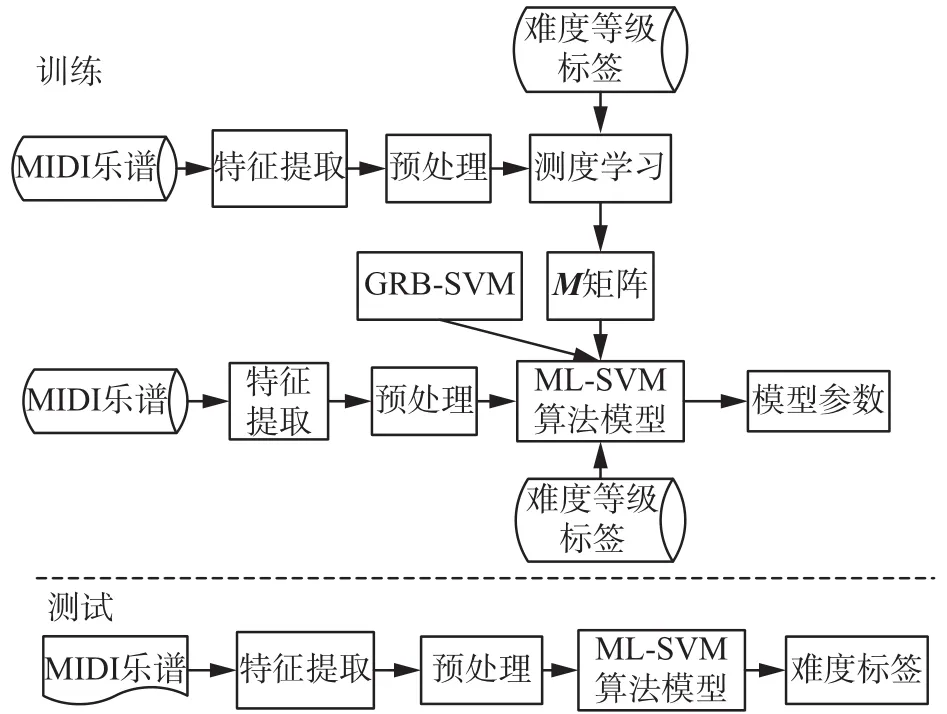
图1 ML-SVM算法的框图Fig. 1 The frame chart of ML-SVM algorithm
2.1 特征空间的建立
为获取更多的钢琴乐谱难度相关特征,本文采用文献[1]与文献[5]中的难度相关特征作为本文的特征空间。所以本文中的特征空间包括:文献[1]中除指法复杂度(属于乐谱标注层面信息,MIDI乐谱中不包含此信息),调号(key signature是元标签信息)之外的全部难度和语义特征;文献[5]中除去指法特征(同样属于标注层面特征)的全部特征,共22个特征,组成一个22维的特征向量来表示MIDI乐谱。
2.2 测度学习得到距离测度DM,改进GRB核函数
由于传统的SVM算法无法根据特征对类别的辨别能力差别对待,所以本文考虑利用测度学习从训练乐谱中有监督地学习到一个投影矩阵,充分考虑特征对难度等级的贡献度,为特征分配不同的权重,进而得到新的距离测度DM,改进原始高斯径向基核函数,改进后的高斯径向基核函数为
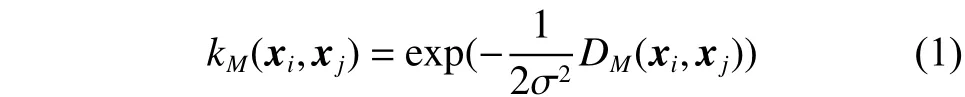
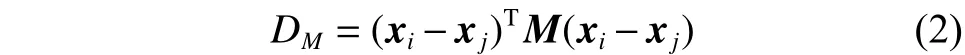
通过矩阵M,依据特征对难度等级的区别能力及特征之间的相关关系,将特征投影到一个类别区分度更高的空间[14]。DM的构建及投影矩阵M)的学习过程如下。
本算法的关键在于找到最佳的特征投影矩阵L。考虑用变换矩阵(n表示特征的维数)实现特征投影:
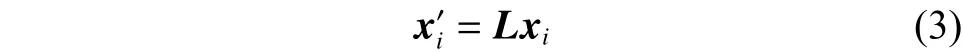
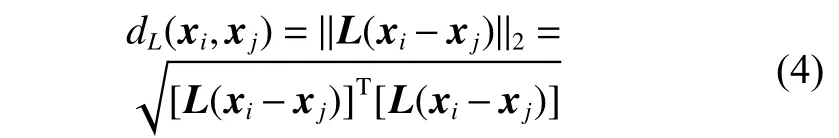
为避免求均方并保证距离为正值,取距离的平方并用矩阵形式表示,则新的距离测度DM为
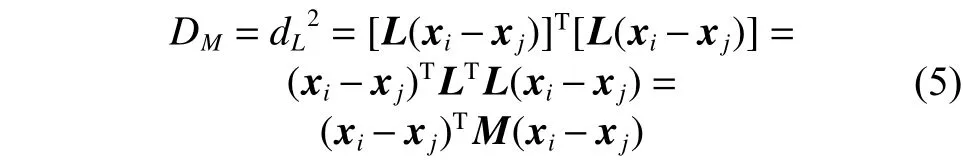
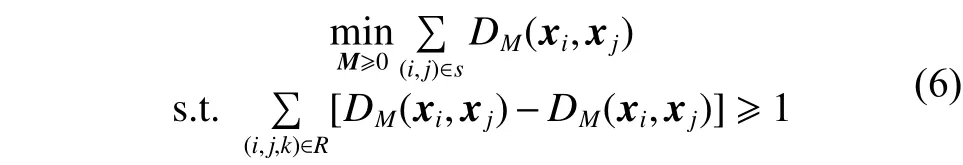
2.3 ML-SVM算法
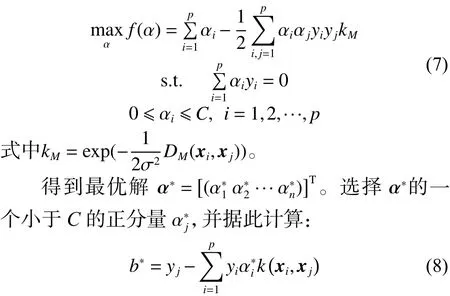
构造决策函数:
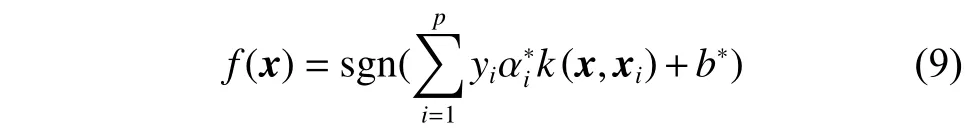
依据决策函数可以得到待分类乐谱x所属类别[8]。其中α是拉格朗日系数,C是错误分类的惩罚参数,kM是改进后的高斯径向基核函数,核函数表达式中的是测度学习得到的距离测度。
另外,原始SVM是二分类的,本文采用一对余(one versus rest)方法[8,16]将 ML-SVM扩展到多分类。主要思想是:对于一个m类分类问题,通过建立m个二分类ML-SVM模型,每一个ML-SVM模型需要训练所有的训练样本,但训练样本中只将某一个类别记为正,其余所有类别记为负。对于待识别的样本,依次调用训练好的m个ML-SVM模型,计算它在各个ML-SVM模型中决策函数的值,选择决策函数值最大的ML-SVM模型给出的类别,作为待识别乐谱难度类别。
3 实验
本文算法全部用MATLAB软件实现,所用的计算机环境为32位Windows 7操作系统,内置Intel I5-4200M处理器和4 GB的内存。
在实验中,为更好地评估本文提出的ML-SVM算法的分类性能和泛化能力,在9类和4类难度两个乐谱数据集中,将ML-SVM算法与逻辑回归、基于线性核函数的SVM、基于多项式核函数的SVM、基于原始高斯径向基核函数的SVM(均用one versus rest扩展到多分类)算法以及结合主成分分析的各个SVM算法进行对比试验,以识别准确率作为算法性能的评价指标。每个实验独立重复5次,并用五折交叉验证,取平均准确率作为最终识别准确率。同时为更全面评估识别算法性能,也给出各个算法结果的90%置信区间。
3.1 实验数据集
钢琴乐谱数据集采用包含音高、节拍、时间、和弦、速度和信道等钢琴乐谱信息的MIDI格式数字乐谱文件[17]。MIDI文件小,易于获得。为和现有的研究作对比,我们采用了文献[1]中包含9个难度等级,共176个MIDI文件的数据集。
另外考虑到实际钢琴学习与教学中很多情况会将乐谱分为4个难度等级,大量音乐网站也普遍提供 4 个难度等级 (easy,beginner,intermediate,advanced)的数字乐谱,所以为更好地评估本文算法的可拓展性,切合实际应用情况,我们还从大型音乐网站8notes[18]收集到400首MIDI乐谱组成有4个难度等级的数据集,每一个难度等级有100个MIDI乐谱。为书写及引用方便,9个难度等级的数据集简称为NineS数据集,4个难度等级的数据集简称为FourS数据集。
3.2 数据预处理
特征提取后,一些特征对应的值较大,而另一些特征对应的值较小,甚至相差超过两个数量级,为避免数值较大的特征对整体分类的影响,利用Min-Max归一化方法:
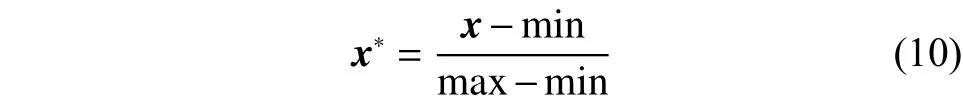
将特征向量归一化到[0, 1]。其中min和max分别表示特征的最小和最大值,表示特征经过归一化处理后的特征。
3.3 实验与结果分析
仿真试验中,将ML-SVM算法与逻辑回归(logistic regression,LR)[19],基于线性核函数的 SVM(记为L-SVM),基于多项式核函数的SVM(记为PSVM)和基于高斯径向基核函数的SVM算法(记为GRB-SVM)[16,20-21]进行对比。每个实验独立重复5次,每次用5折交叉验证,取平均准确率作为分类性能指标,同时计算出结果的90%置信区间。
各个SVM算法中核函数参数利用网格搜索算法[22],在 2–10~210内,以步长 0.5,5 折交叉验证寻找最优的参数设置。其中L-SVM,P-SVM(多项式阶数d=3)只需优化惩罚因子C,GRB-SVM与MLSVM需要优化惩罚因子C与核函数参数g(g =)的最优组合。最终的最优参数组合如表1所示。
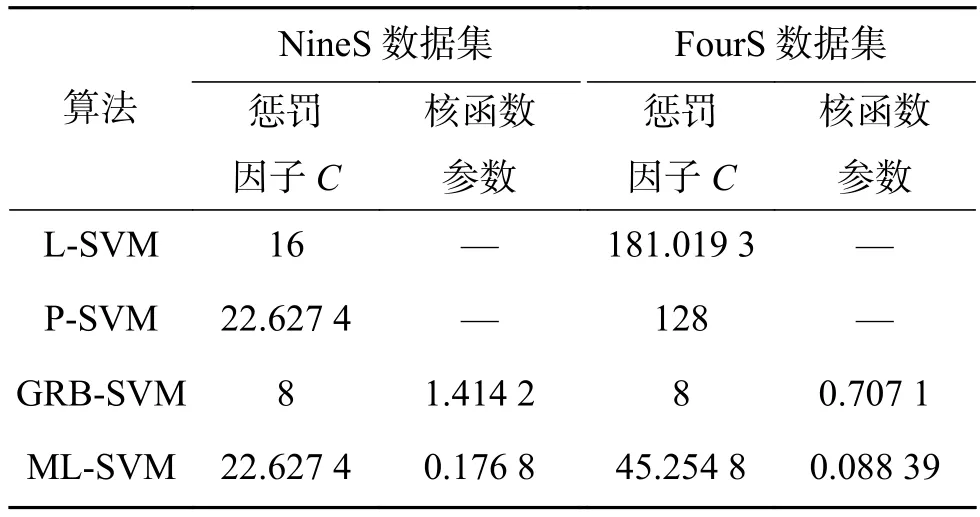
表1 各个算法的最优参数组合Table 1 Optimal parameter combination of each algorithm
表2给出了本文提出的ML-SVM算法与LR、L-SVM、P-SVM、GRB-SVM算法在NineS数据集和FourS数据集中的识别准确率及结果的90%置信区间。从表2中可以看出,在两个数据集上,本文提出的ML-SVM算法,识别准确率最高,分别达到68.74%和84.67%。两个数据集中,本文提出的算法最终识别准确率均高于GRB-SVM算法,尤其在FourS数据集中,本文所提算法得到84.67%的识别准确率,相对75.63%的GRB-SVM,识别准确率有较大提高。且更窄的置信区间表明结果更稳定、显著。基于线性核函数的SVM(L-SVM)一直表现欠佳,在两个数据集中识别效果不如逻辑回归(LR),基于多项式核函数的SVM(P-SVM)表现良好,在FourS数据集中识别效果仅次于本文算法。
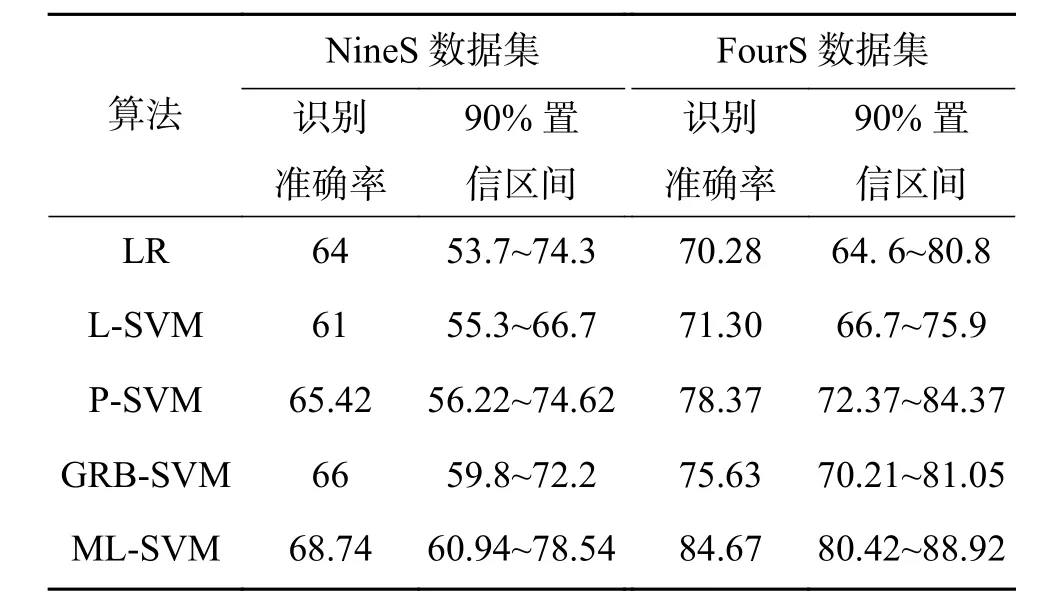
表2 各算法的识别准确率及90%置信区间Table 2 Recognition accuracy and 90% confidence interval of each algorithm %
为进一步验证本文所提算法的有效性,我们将ML-SVM算法与另一种主要用来实现特征降维的投影算法——主成分分析结合SVM的分类准确率进行对比。在对原始特征数据进行PCA处理时,保留原始特征95%信息量的投影特征。PCA投影处理后,最终NineS数据集中的特征降到13维,而FourS数据集的特征降到8维。之后再用基于各个核函数的SVM算法对PCA降维后的数据进行分类。实验结果如表3所示。从表中可以看出,原始特征数据经过PCA处理后,最终各个SVM的分类准确率都有所提高。这是因为原始特征数据经过PCA投影、降维之后,可以有效减少混叠以及冗余信息,进而提高最终分类的准确率。
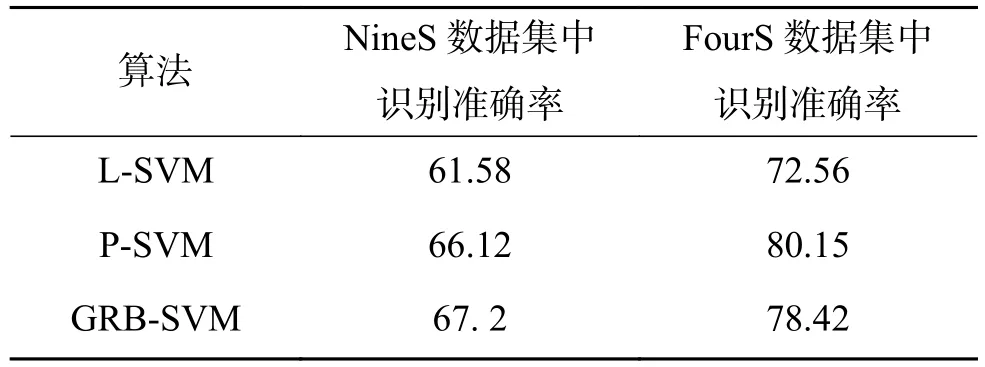
表3 PCA处理后,各算法的识别准确率Table 3 After features are processed by PCA, each SVM algorithm’s recognition accuracy in two data sets %
虽然原始特征数据经过PCA投影、降维处理后,利用GRB-SVM分类的准确率较之前有所提高,但分类准确率与本文提出的ML-SVM算法仍有差距,尤其在FourS数据集中,ML-SVM仍有较大优势,这也再次验证了本文提出的ML-SVM算法是有效的。
4 结束语
针对现有钢琴乐谱难度分类主要由人工方式完成,效率不高,区别于传统将乐谱难度等级识别归结为回归问题,本文直接将其建模为基于支持向量机的分类问题。并结合钢琴乐谱分类主观性强、特征之间普遍存在相关性等特点,利用测度学习改进高斯径向基核函数,从而提出一种测度学习支持向量机分类算法——ML-SVM算法。经过在9类和4类难度两个乐谱数据集上的对比实验,结果表明本文所提算法的识别准确率优于现有算法,且有效提高了基于高斯径向基核函数SVM的分类性能。实验结果说明,利用测度学习理论,保留特征之间的相关关系,更适合乐谱难度识别数据与分布特点,并能够有效识别算法的性能。未来的工作可以考虑应用半监督算法,以充分利用大量无难度标签数据,预期将会大大提高分类器的训练效果,进而提高算法的识别准确率。
[1]CHIU S C, CHEN M S. A study on difficulty level recognition of piano sheet music[C]//IEEE International Symposium on Multimedia. Irvine, CA, USA: IEEE, 2012: 17–23.
[2]ROBNIK-ŠIKONJA M, KONONENKO I. Theoretical and empirical analysis of Relief[J]. Machine learning, 2003,53(1/2): 23–69.
[3]JAMES G, WITTEN D, HASTIE T, et al. An introduction to statistical learning with applications in R[M]. New York:Springer, 2013: 59–102.
[4]SMOLA A J, SCHÖLKOPF B. A tutorial on support vector regression[J]. Statistics and computing, 2003, 14(3): 199–222.
[5]SÉBASTIEN V, RALAMBONDRAINY H, SÉBASTIEN O, et al. Score analyzer: automatically determining scores difficulty level for instrumental e-learning[C]//Proceedings of the 13th International Society for Music Information Retrieval Conference. Porto, Portugal: ISMIR, 2012: 571–576.
[6]CASTAN G, GOOD M, ROLAND P. Extensible markup language (XML) for music applications: an introduction, the virtual score: representation, retrieval, restoration[M]. Cambridge: MIT Press, 2001: 95–102.
[7]WARD JR J H. Hierarchical grouping to optimize an objective function[J]. Journal of the American statistical association, 1963, 58(301): 236–244.
[8]丁世飞, 齐丙娟, 谭红艳. 支持向量机理论与算法研究综述[J]. 电子科技大学学报, 2011, 40(1): 2–10.DING Shifei, QI Bingjuan, TAN Hongyan. An overview on theory and algorithm of support vector machines[J]. Journal of university of electronic science and technology of China,2011, 40(1): 2–10.
[9]LI Shutao, KWOK J T, ZHU Hailong, et al. Texture clas-sification using the support vector machines[J]. Pattern recognition, 2003, 36(12): 2883–2893.
[10]SIMON T, KOLLER D. Support vector machine active learning with applications to text classification[J]. The journal of machine learning research, 2002, 2: 45–66.
[11]OSUNA E, FREUND R, GIROSIT F. Training support vector machines: an application to face detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Juan, Puerto Rico, USA: IEEE,1997: 130–136.
[12]WAN V, CAMPBELL W M. Support vector machines for speaker verification and identification[C]//Neural Networks for Signal Processing X. Proceedings of the 2000 IEEE Signal Processing Society Workshop. Sydney, NSW,Australia: IEEE, 2000, 2: 775–784.
[13]SCHÖLKOPF B, SMOLA, A J. Learning with kernels[M].GMD-For Schungszentrum Information Stechnik, 1998:5–93.
[14]KULIS B. Metric learning: a survey[J]. Foundations and trends in machine learning, 2012, 5(4): 287–364.
[15]WEINBERGER K Q, SAUL L K. Distance metric learning for large margin nearest neighbor classification[J].Journal of machine learning research, 2009, 10: 207–244.
[16]HSU C W, LIN C J. A comparison of methods for multiclass support vector machines[J]. IEEE transactions on neural networks, 2002, 13(2): 415–425.
[17]MIDI Manufacturers Association. An introduction to MIDI[M]. California: MIDI Manufacturers Association,2009: 1–16.
[18]Fours set data sources[EB/OL]. [2015-07-24]. http://www.8notes.com.
[19]HOSMER D W, LEMESHOW S. Applied logistic regression[M]. New York: Wiley, 2000: 31–46.
[20]WESTON J, WATKINS C. Multi-class support vector machines, CSD-TR-98-04[R/OL]. Egham: Royal Holloway University of London, 1998: 1–10.
[21]CHANG C C, LIN C J. LIBSVM——a library for support vector machines[J/OL]. ACM transactions on intelligent systems and technology, 2011, 2(3): 27.
[22]徐晓明. SVM参数寻优及其在分类中的应用[D]. 大连:大连海事大学, 2014: 6–58.XU Xiaoming. SVM parameter optimization and its application in the classification[D]. Dalian: Dalian Maritime University, 2014: 6–58.
猜你喜欢
歌唱艺术(2022年6期)2022-10-23 07:03:36
数学物理学报(2022年3期)2022-05-25 13:33:12
数学物理学报(2022年2期)2022-04-26 14:07:54
歌唱艺术(2022年12期)2022-04-12 07:57:54
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
数学物理学报(2020年4期)2020-09-07 09:14:00
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
北方音乐(2019年20期)2019-12-04 04:07:14
