
个性化信息推荐方法研究
2018-03-15 07:46姜信景齐小刚刘立芳
智能系统学报 2018年2期
姜信景,齐小刚,刘立芳
随着互联网的迅速发展,海量的网络信息大大超过用户的想象。面对如此浩瀚的信息,用户如何从中能够阅读到满足其需求的信息是迫待解决的关键问题。个性化信息推荐主要处理消息和用户的匹配问题,即对于一个信息而言,通过个性化推荐算法能够从众多用户中找到需要了解它的用户集;对于用户而言,通过个性化信息推荐能够从众多的网络消息中快速地发现其需求的信息集。目前,针对信息的推荐方法主要包括:基于内容的推荐[1-3]、基于知识的推荐[4-5]、协同过滤推荐[6-7]、混合推荐[7-9]以及其他推荐[10-15]。
基于内容的信息推荐算法[1]是根据对用户的历史行为分析进行建立用户模型,并向用户推荐与其模型比较匹配的信息。该推荐算法的核心就是挖掘用户的历史行为数据,找到与其相似的信息进行推荐,所以基于内容的推荐算法能够准确捕获用户的兴趣,能够为其推荐新出现的信息。但是,由于用户的兴趣随着时间快速变化,以及该方法仅仅推荐与其模型比较匹配的信息,所以该方法在获取用户的潜在兴趣以及推荐列表多样性方面存在不足。基于知识的推荐算法[5,16]是针对特定领域建立规则,利用基于实例和规则的推理,实现对用户推荐。比如,效用知识是指一个项目为何满足某一特定用户的知识,其既能产生推荐也可以解释产生该推荐的原因。该方法的优点是把用户的需求直接映射到产品上以及考虑非产品属性,但是其缺点为知识难以获得并且推荐是静态的。协同过滤推荐算法[2,6–7]是推荐系统中最基本的算法,其包括基于用户的协同过滤算法和基于物品的协同过滤算法。基于用户的协同过滤算法的思想是根据目标用户的历史行为找到与其相似的用户,然后将它们比较喜欢的但目标用户没有发现的东西推荐给目标用户。基于物品的协同过滤的思想与其类似。该方法的优点在于不需要领域知识、推荐多样性好以及可以挖掘用户的潜在兴趣,但是其缺点包括存在冷启动问题、系统开始时推荐质量差、可扩展性差以及质量取决于历史数据集等。
由于信息的实时性与用户兴趣的不固定性,在上述推荐方法的启发下,论文提出了组合推荐算法——CR算法。该算法的基本思想是:首先是对目标用户历史行为日志进行发掘处理,根据基于内容的推荐算法生成用户的现存配置文件与当前兴趣配置文件;然后,由基于用户行为的协同过滤算法与基于用户内容的协同过滤算法共同生成用户的潜在配置文件;紧接着由现存用户配置文件与潜在配置文件共同产生用户的混合配置文件;最后根据信息集中信息的发布时间决定其有哪种方法产生推荐。当信息发布时间与当前时间的差小于某个阈值时,采用混合推荐算法;当消息发布时间与当前时间的差不小于上述阈值时,采用基于用户的协同过滤算法。
1 个性化推荐方法
1.1 问题定义
定义2 用户现存配置文件:对于任何用户,把其阅读过的信息生成的文件称为用户现存配置文件,并将用户现存配置文件表示成向量形式,其中表示在用户现存配置文件中主要特征词的权重。
定义4 用户潜在配置文件:对于任何用户,利用协同过滤的方法预测主要特征词的权重,进而获得用户潜在配置文件,其能够被表示为向量形式,其中表示在用户潜在配置文件中主要特征词的权重。
定义5 用户混合配置文件:对于任何用户,融合上述的用户当前兴趣配置文件和用户潜在配置文件,获得其用户混合配置文件,其能够被表示成向量形式,其中表示在用户混合配置文件中主要特征词的权重。
通过上面对一些概念的定义,下面给出论文的设计思路,如图1所示。
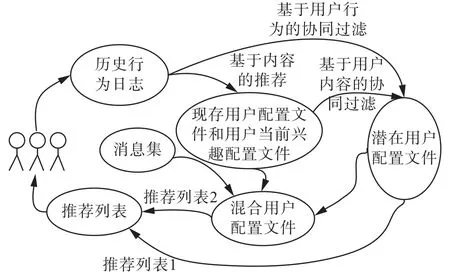
图1 方案框架Fig. 1 Scheme framework
1.2 现存用户配置文件
由于信息时效性强与用户的浏览兴趣并不是永久的,而是跟随社会流行和热点话题变化而变化,所以在进行信息推荐时需要考虑到用户的兴趣偏好变化。为此,论文引进截取因子、时间因子以及对用户的历史数据进行处理。
1.2.1 向量空间模型
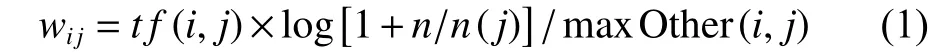
1.2.2 用户现存配置文件、时间因子以及用户当前兴趣配置文件
鉴于用户的兴趣会随着时间的变化而快速变化,而且用户的浏览兴趣往往和刚刚浏览过的前几条信息有很大的关联。所以论文在处理文本信息时首先对用户已阅读消息的浏览时间进行升序排序,进而生成现存用户配置文件,然后选取最后浏览的s个信息用于生成用户的当前兴趣配置文件。设用户已(阅读的按浏览时间)降序排列的信息集表示为{,所}以最新浏览的s个信息集合为,是用户阅读信息的时间。时间因子能够被定义为
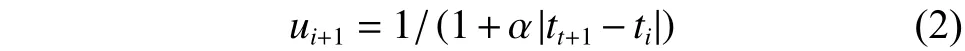
算法1
输入 Fu, Fus, 用户u阅读消息Fui的时间ti,α;
4) end for
其中,对用户浏览的信息集从最早阅读的消息开始,依次到最新阅读的信息进行下述5)~13)的操作。
8) else
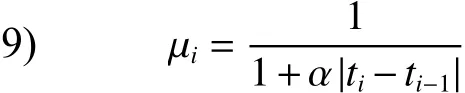
11) end for
12) end for
16) else
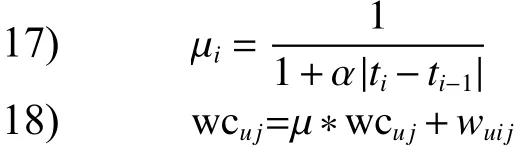
19) end if
20) end for
1.3 潜在配置文件
由于用户的浏览兴趣并不是永久的,是跟随社会流行和热点话题变化而变化,所以推荐信息的列表不应该仅仅包括用户现存兴趣,也应该包括用户的潜在兴趣。考虑到信息的特殊性,本文利用同时考虑行为相似和内容相似的基于用户的协同过滤方法来寻找目标用户的相似用户和潜在兴趣。
1.3.1 混合相似性的计算
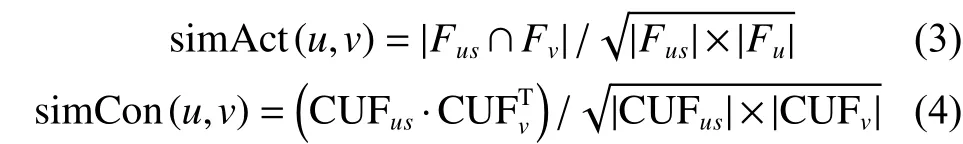
算法2
输入 Fus、Fv、UCFus和 UCFV,系数 β;
按2~2.5米分厢,以便于田间管理为度,将畦面整平。如畦面不平易造成播种深度和田间水层不均衡,影响种子出苗生长。
6) end if
7) end for
8) end for
14) end for
1.3.2 潜在用户配置文件和相似用户文件的生成
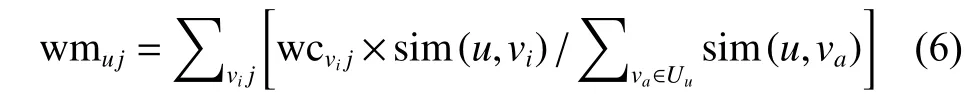
算法3
4) end for
7) end for
11) end for
12) end for
输出 UMFu。
1.4 用户混合配置文件的生成
用户混合配置文件UBF能够在获得目标用户的当前兴趣配置文件UCFs和潜在配置文件UMF后,通过对UCF,UMF上的每个主要特征词加权得到。设用户的,。利用式(7)计算。
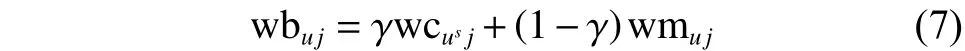
算法4
5) end for
输出 UBFu。
1.5 推荐结果的生成
由于信息的时效性和用户兴趣不固定等问题,在推荐列表中,信息由两部分组成:。
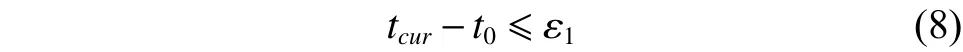
若不等式(8)成立,则检查
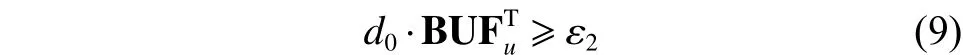
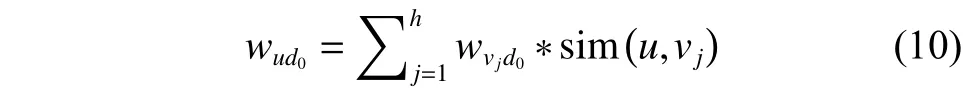
2 实验和分析
实验数据来源于财新网站2014年3月份的一万个用户的所有浏览记录。每个浏览记录由用户编号、新闻编号、浏览时间、新闻标题、新闻内容以及发表时间组成。从数据集中抽取阅读超过25条的新闻用户作为训练集。令包含在网站给定的测试集中的训练集用户作为测试集,其中测试集中的用户只有一个(测试记录)。论文采(用值、召)回率、准确率和多样性作为评价指标。值的定义为
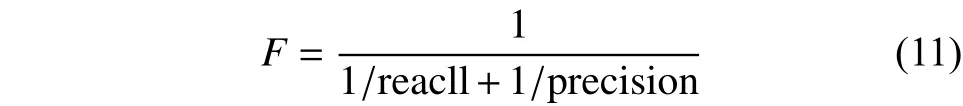
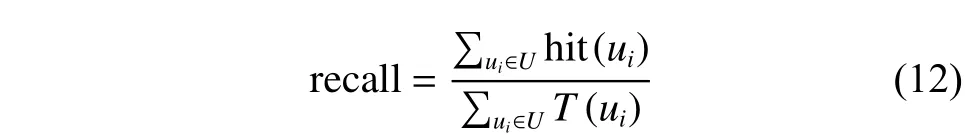
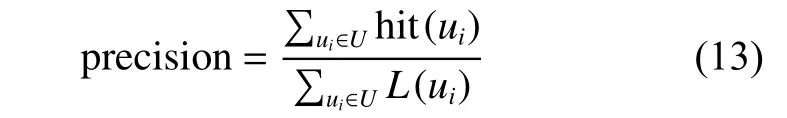
表1 recall与的关系Table 1 Relationship between recall and
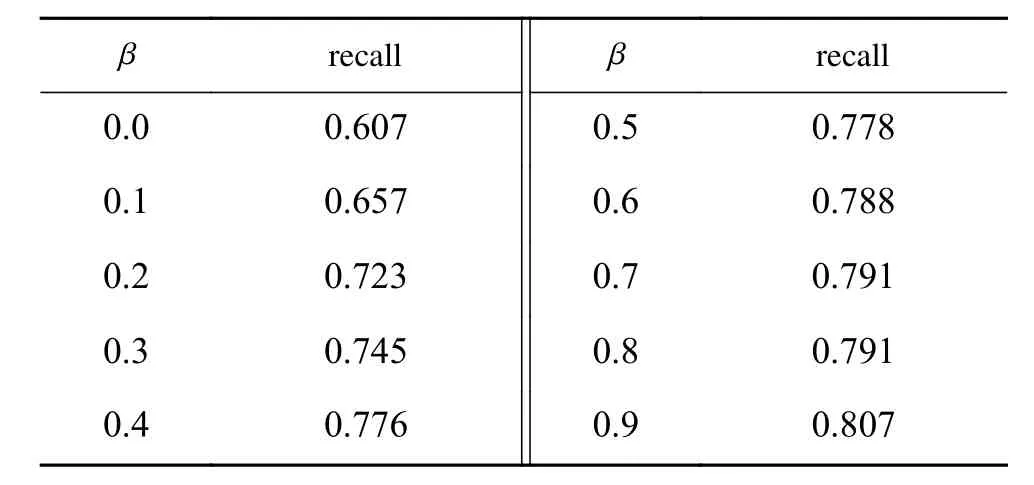
表1 recall与的关系Table 1 Relationship between recall and
0.0 0.607 0.1 0.657 0.2 0.723 0.3 0.745 0.4 0.7760.5 0.778 0.6 0.788 0.7 0.791 0.8 0.791 0.9 0.807
在图2中,随着推荐列表长度的增加,上述6种方法除CBR(基于内容的推荐算法)外,F值都逐渐减少。在相同的推荐列表长度的情况下。CR(组合推荐)的F值最大,除个别点,ICFBBS(改进的基于行为相似的协同过滤)、ICFCBS(改进的基于内容相似的协同过滤)、MR(混合推荐)、CFBBS(基于行为相似的协同过滤)、CFCBS(基于内容相似的协同过滤)依次减少。CBR的F值最小。图3为recall指标随推荐列表长度变化的情况。随着推荐列表长度的增加,6种方法的recall值都逐渐增加。在相同推荐列表长度的情况下,除个别点,CR、ICFBBS、ICFCBS、MR、CFBBS、CFCBS以及CBR的recall值依次减少。图4为precision指标随推荐列表长度变化的情况。随着推荐列表长度增加,6种方法值都逐渐减少。在相同列表长度的情况下,除个别点,CR、ICFBBS、ICFCBS、MR、CFBBS、CFCBS以及CBR的Precision值依次减少。
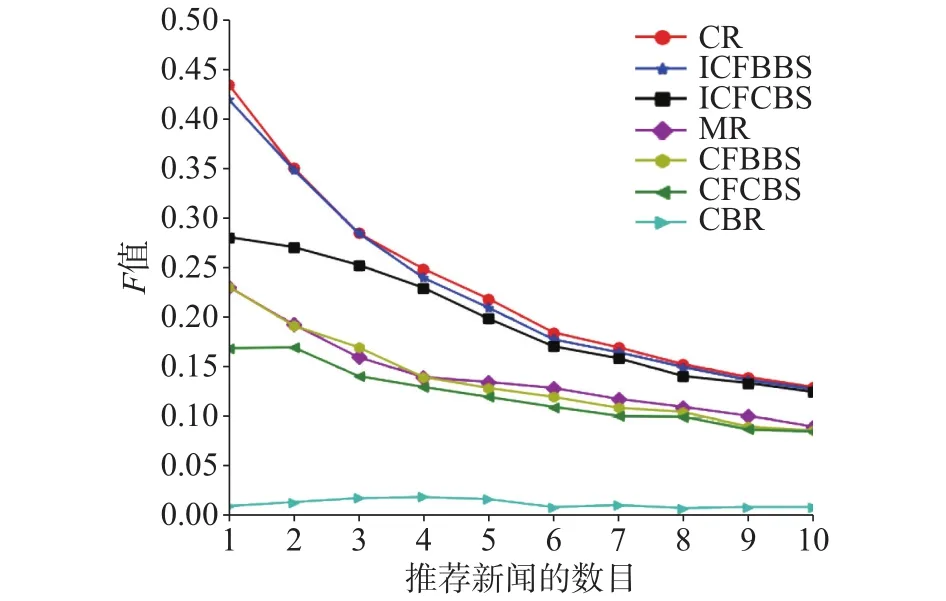
图2 F值比较Fig. 2 Comparison of F
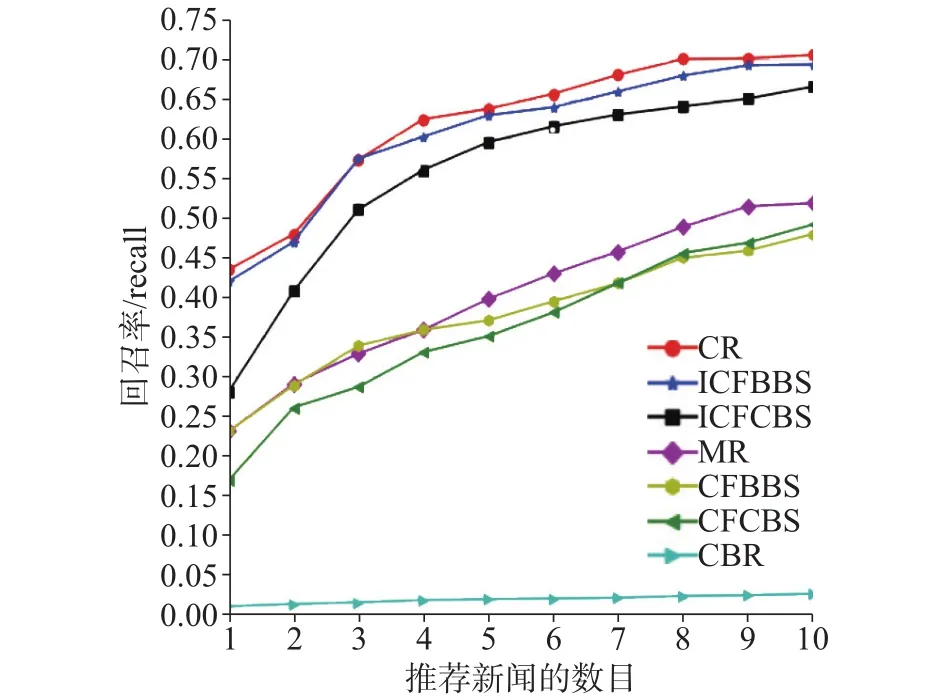
图3 召回率比较Fig. 3 Comparison of recall
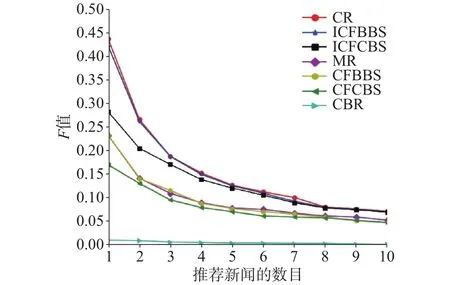
图4 精确度比较Fig. 4 Comparison of precision
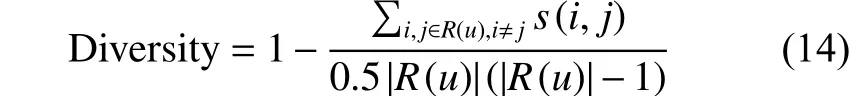
而推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值如式(15):
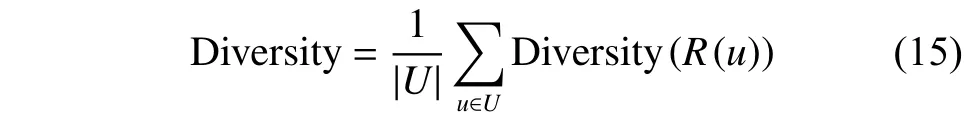
图5是上述7种方法在不同推荐长度下多样性。从图中可以看出,CBR算法是通过对用户先前消息的内容进行分析,然后推荐与其内容相似的消息,所以在推荐列表中的消息内容相似性特别高,进而多样性很差。ICFBBS、ICFCBS、CFBBS、CFCBS是目标用户通过找到与其行为相似或者内容相似的用户集,给目标用户推荐用户集中浏览最多的消息,所以多样性比CBR好。CR是混合推荐和直接基于用户的协同过滤算法的组合,所以多样性比CBR 好,比 ICFBBS、ICFCBS、CFBBS、CFCBS 差。MR推荐的消息是与用户的兴趣模型相似度较高的消息,所以多样性与CBR相似。
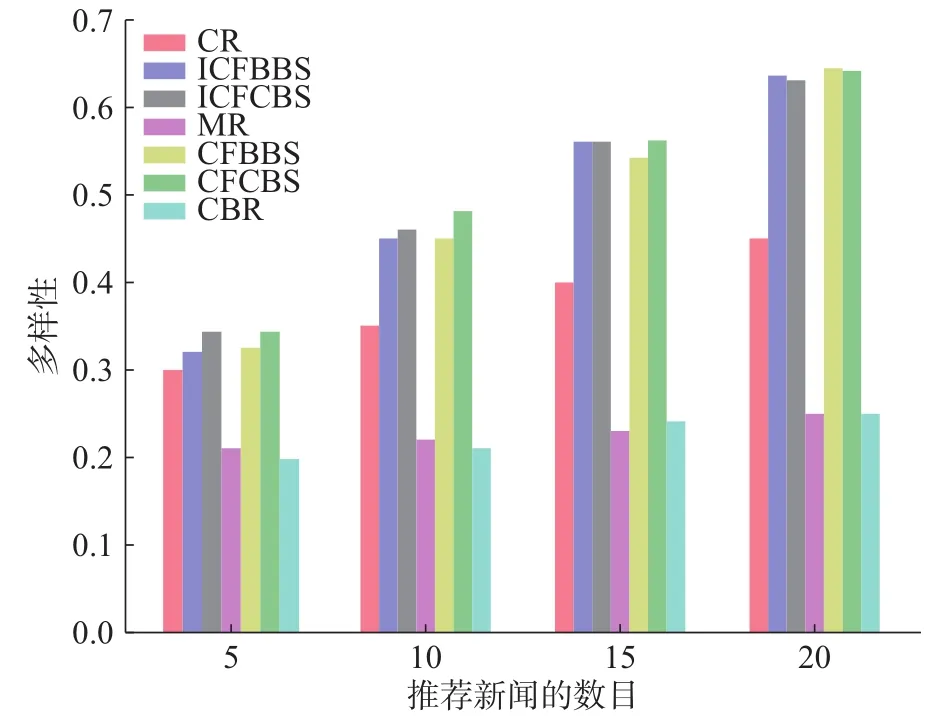
图5 多样性比较Fig. 5 Comparison of diversity
此外,CR方法在进行推荐时,由于对消息的分类推荐,所以推荐所用的时间远远小于基于内容的算法和用户的协同过滤混合推荐算法。
3 结束语
本文首先介绍了个性化信息推荐的传统方法,对基于内容推荐算法和基于协同过滤算法进行了简单说明。针对信息的特点,本文提出了组合推荐算法(CR算法)。针对该算法设计实验并分析了实验结果。数据显示CR方法显著优于其他同类方法。但是随着信息属性和用户权限的细分,通用的推荐算法已不适应某些特殊的信息领域,下一步,可以试着通过改造上述算法的结构进行比较精准的推荐。
[1]李佳珊. 个性化新闻推荐引擎中新闻分组聚类技术的研究与实现[D]. 北京: 北京邮电大学, 2013.LI Jiashan. Research and implementation of text clustering for personalized news recommandation system[D]. Beijing:Beijing University of Posts and Telecommunications, 2013.
[2]项亮. 推荐系统实践[M]. 北京: 人民邮电出版社, 2012.
[3]BALABANOVIĆ M, SHOHAM Y. Fab: content-based,collaborative recommendation[J]. Communications of the ACM, 1997, 40(3): 66–72.
[4]MANDL M, FELFERNIG A, TEPPAN E, et al. Consumer decision making in knowledge-based recommendation[J].Journal of intelligent information systems, 2011, 37(1):1–22.
[5]LI Xiaohui, MURATA T. A knowledge-based recommendation model utilizing formal concept analysis and association[C]//Proceedings of the 2nd International Conference on Computer and Automation Engineering. Singapore, 2010:221–226.
[6]GARCIN F, ZHOU Kai, FALTINGS B, et al. Personalized news recommendation based on collaborative filtering[C]//Proceedings of the 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology. Washington, DC, USA: IEEE, 2012: 437–441.
[7]DARVISHY A, IBRAHIM H, MUSTAPHA A, et al. New attributes for neighborhood-based collaborative filtering in news recommendation[J]. Journal of emerging technologies in web intelligence, 2015, 7(1): 13–19.
[8]YANG Wu, TANG Rui, LU Ling. A fused method for news recommendation[C]//Proceedings of the 2016 International Conference on Big Data and Smart Computing (BigComp).Hong Kong, China, 2016: 341–344.
[9]LU Zhongqi, DOU Zhicheng, LIAN Jianxun, et al. Contentbased collaborative filtering for news topic recommendation[C]//Proceedings of the 29th AAAI Conference on Artificial Intelligence. Austin, Texas, USA, 2015: 217–223.
[10]LIU Y, BAO L, GAO L. Trust-based new recommendation algorithm of collaborative filtering combination[J]. Information Japan, 2013, 16(7): 4555–4576.
[11]WANG Jingjin, LIN Kunhui, LI Jia. A collaborative filtering recommendation algorithm based on user clustering and slope one scheme[C]//Proceedings of the 2013 8th International Conference on Computer Science & Education(ICCSE). Colombo, Sri Lanka, 2013: 1473–1476.
[12]CAPELLE M, FRASINCAR F, MOERLAND M, et al. Semantics-based news recommendation[J]//Proceedings of the 2nd International Conference on Web Intelligence,Mining and Semantics. Craiova, Romania, 2012: 27.
[13]CUI Limeng, SHI Yong. A Method based on one-class SVM for news recommendation[J]. Procedia computer sci-ence, 2014, 31: 281–290.
[14]REN Rui, ZHANG Lingling, CUI Limeng, et al. Personalized financial news recommendation algorithm based on ontology[J]. Procedia computer science, 2015, 55: 843–851.
[15]LOMMATZSCH A, KENTER T, DE VRIES A P, et al.Real-time news recommendation using context-aware ensembles[M]//DE RIJKE M. Advances in Information Retrieval. Cham, Germany: Springer, 2014.
[16]杨博, 赵鹏飞. 推荐算法综述[J]. 山西大学学报: 自然科学版, 2011, 34(3): 337–350.YANG Bo, ZHAO Pengfei. Review of the art of recommendation algorithms[J]. Journal of Shanxi university: natural science edition, 2011, 34(3): 337–350.
[17]路永和, 李焰锋. 改进TF—IDF算法的文本特征项权值计算方法[J]. 图书情报工作, 2013, 57(3): 90–95.LU Yonghe, LI Yanfeng. Improvement of text feature weighting method based on TF-IDF algorithm[J]. Library and information service, 2013, 57(3): 90–95.
猜你喜欢
新班主任(2022年4期)2022-04-27
电脑爱好者(2021年11期)2021-06-07
小学生学习指导(中年级)(2021年4期)2021-04-27
科学大众(2020年23期)2021-01-18
电脑爱好者(2020年9期)2020-07-05
课堂内外(初中版)(2020年5期)2020-06-19
电脑爱好者(2019年20期)2019-12-10
汽车观察(2019年2期)2019-03-15
铁路计算机应用(2018年10期)2018-11-09
中国卫生(2016年5期)2016-11-12
