
基于Word2Vec和HowNet的情感词典构建方法
2018-03-14 10:21元海霞
现代计算机 2018年4期
元海霞
(重庆师范大学计算机与信息科学学院,重庆 401331)
0 引言
随着移动互联网的迅速发展,网络在我们的生活中占据了举足轻重的地位。越来越多的人通过网络购买物品,而对购买物品的满意度,用户又可以通过互联网平台表达自己的情感和态度。通过对这些带着感情色彩的评论文本的分析,不仅可以使商家了解用户最关心的问题和对商品的满意度,明确商品的优点和不足,根据用户提出的不足改进商品,提升市场竞争力;还可以为待消费者节约时间和精力,提供参考方向。
在情感倾向性分析中,情感词典是有利的分析工具,具有重要的研究价值。通用手工或半自动方式构建的情感词典,如 General Inquirer(GI)、SentiWordNet,其覆盖范围有限,领域适应性和可靠性较差[1-2]。因此,越来越多的研究开始致力于情感词典的自动构建。其中一类主要方法是利用语义知识库扩充情感词典,如WordNet、HowNet等[3-5]。该类方法首先选择一组已知情感倾向的词语作为种子词,然后利用知识库中词语间的同义、反义、上下位,词语与义原的语义关系来确定候选词的情感倾向[6]。但是这类方法存在过于依赖语义知识库,覆盖范围有限,领域适用性较差等问题。针对以上问题,本文基于Word2Vec和HowNet进行情感词典的构建。该方法对语料首先利用Word2Vec训练词向量获取与候选词最接近的10个词,根据候选词与这10个相近词的语义相似度确定候选词的情感倾向,而对于用Word2Vec方法无法确定情感倾向的词语,则用HowNet方法进行判定,先从基础情感词典中选择种子词,然后计算词语之间的语义相似度,相似度越大则情感倾向越相近。
1 情感词典构建思路概述
本文提出的基于Word2Vec和HowNet的情感词典构建方法的基本思路如图1所示。
(1)将HowNet情感词典和台湾大学构建的NTU进行合并作为基础情感词典。
(2)选择训练语料中的形容词,动词组成候选情感词集。
(3)基于Word2Vec判断候选情感词的情感倾向。应用训练语料训练Word2Vec,得到词的向量表示,获取与候选情感词最接近的10个词,在基础情感词典中查找这10个相近词的情感倾向,基于候选情感词与这10个相近词中褒贬情感词的语义相似度确定候选情感词的情感倾向。
(4)对于最接近的10个词在基础情感词典中都找不到无法确定情感倾向的候选情感词,基于HowNet进行情感倾向判定。从基础情感词典选择总情感词数量的15%左右作为种子词[7],计算候选情感词与种子词的语义相似度确定候选词的情感倾向。

图1 情感词典构建流程
2 基于Word2Vec和HowNet的情感词典构建方法
2.1 候选情感词的提取
情感词指语句中具有情感倾向性的词语,它可以是名词、动词、形容词、副词以及短语等[8]。语句的情感倾向一般情况下主要通过情感词来表现,因此情感词是判断情感倾向的重要依据之一。情感词通常情感倾向强烈,例如表达心情的兴奋、高兴、悲伤、沉闷,或是表达喜好的喜欢、偏爱、厌恶、讨厌等,情感词通常分为褒义词与贬义词。本文通过对餐饮评论的分析,选择语料中的形容词和动词作为候选情感词。
2.2 基于Word 2Vec判断候选情感词的情感倾向
Word2Vec是2013年Google开源的一款用于词向量计算的工具,引起了学术界的广泛关注。它可以把词语用向量表示,映射到向量空间进行处理,为自然语言处理提供了便捷。Word2Vec首先在数据集上进行高效地训练,然后得到训练结果—词向量,利用词向量可以很好地度量词与词之间的相似性。
基于Word2Vec判断候选情感词的情感倾向步骤如下:
(1)获取与候选情感词最近的10个词
利用训练语料训练Word2Vec,得到词语的词向量并存入vector.bin文件中。如果在基础情感词典中能找到候选情感词,说明候选词的情感倾向能够确定则跳过;否则,在Word2Vec中执行distance vector.bin获取与候选情感词最接近的10个词。
(2)判断候选情感词的情感倾向
根据候选情感词与10个相近词中褒贬情感词的语义相似度确定情感倾向:
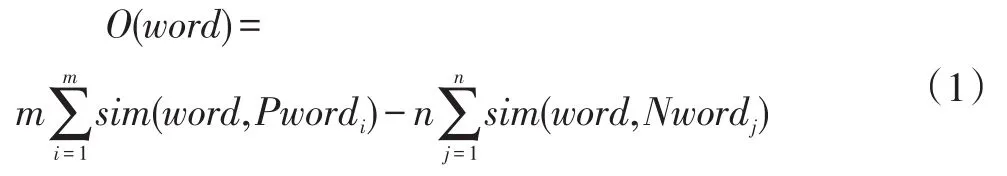
其中,sim(word1,word2)表示 word1和 word2之间的语义相似度;Pword表示褒义词,Nword表示贬义词;O(word)表示情感倾向,O(word)>0时,情感倾向为褒义,O(word)<0时,情感倾向为贬义。
词语之间的语义相似度用词向量的余弦值来表示。余弦值越大,两个词语的语义相似度越高,情感倾向越相近[9]。例如两个 n维向量 a(x11,x12,…,x1n)和 b(x21,x22,…,x·n),余弦值的计算公式如下:
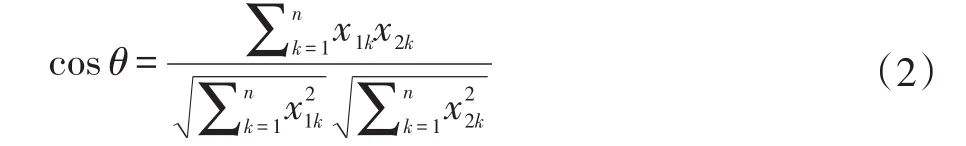
2.3 基于HowNet判断候选情感词的情感倾向
基于HowNet计算词语间语义相似度的思路是整体相似度由部分相似度加权平均进行计算,包含三个计算过程[10]。
(1)义原相似度计算
两个义原之间的语义距离计算公式如下:
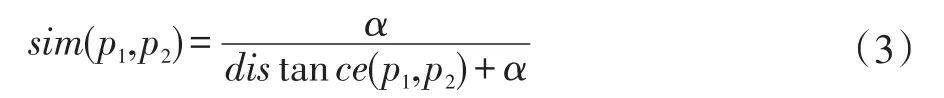
公式中,α为可调节参数,p1和p2代表两个义原,distance(p1,p2)代表两个义原的路径距离。
(2)概念相似度计算
概念相似度是义原相似度之和,得到义原之间相似度之后,计算公式如下:
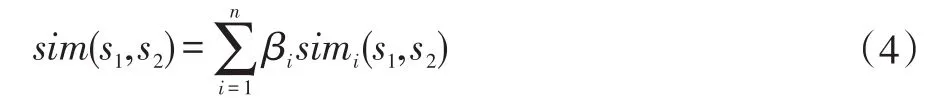
公式中,n一般取 2或 4,βi是可调节参数,β1+…+βn=1且 β1≥…≥βn。
(3)词语语义相似度计算
词语语义相似度计算公式如下:
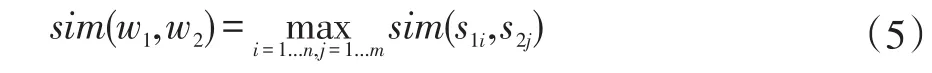
公式中,s1i是 w1的第 i个概念,s1j是 w2的第 j个概念,sim(w1,w2)代表w1和 w2的相似度,它的值是各个概念的相似度之中的最大值。
当用Word2Vec获取的最接近的10个词在基础情感词典中都找不到而无法确定候选情感词的情感倾向时则基于HowNet进行判断,步骤如下:
(1)种子词的选取
基于HowNet判断候选情感词的情感倾向的过程中需要选取一些情感倾向明显、强烈的词语作为种子词,包括褒义种子词和贬义种子词。与褒义种子词语义相似度越高,则越倾向贬义,反之与贬义种子词语义相似度越高,则越倾向贬义。柳位平等人经实验验证选取种子词的数量占总情感词数量的15%左右时情感倾向判断准确率达到90%左右[7]。因此,本文从基础情感词典中选择情感倾向明显的褒义词和贬义词各137个。
(2)判断候选情感词的情感倾向
根据候选情感词与两组种子词的语义相似度确定情感倾向,具体计算公式如下:
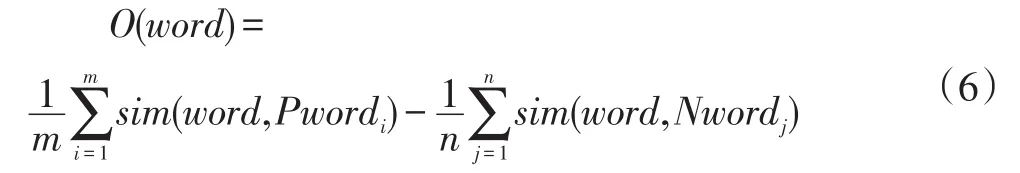
其中,sim(word1,word2)表示 word1和 word2的语义相似度,用公式(5)计算;m表示褒义词个数,Pword表示褒义词;n表示贬义词个数,Nword表示贬义词。O(word)表示情感倾向,当 O(word)>0 时表示候选词word为褒义词,O(word)<0时表示候选词word为贬义词。
3 实验分析
为了验证本文提出的情感词典构建方法的有效性,从词语情感类别判定准确性进行具体的实验验证。本实验的实验语料来自大众点评网美食类别,包括各餐馆的所有评论。利用八爪鱼采集器从大众点评网美食频道采集5万多条餐饮评论作为语料构建情感词典。采用中科院分词工具ICTCLAS对餐饮评论进行分词,选择分词结果中的形容词和动词作为候选情感词。为了保证分类结果的准确性,先由两名标注人员进行人工标注,对于标注结果不一样的候选词,由第三名人员进行标注。计算了Fleiss Fappa指标来评价标注结果的一致性。
本文使用精确率(Precision)、召回率(Recall)以及F1值(F1-measure)作为评价标准[1]。计算方式为:
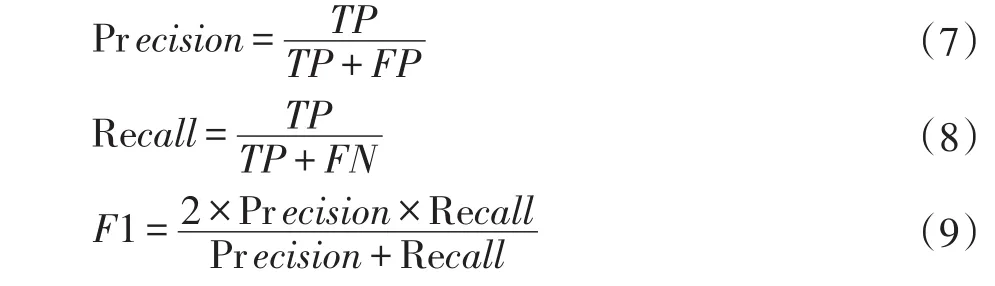
其中,TP表示正确识别的情感词个数,FP表示被错误划分为正类的情感词个数,FN表示被错误划分为负类的情感词个数。实验结果如表1所示。

表1 基于不同词典的情感分类实验对比
从表1可以看出,用Word2Vec+HowNet构建的褒义情感词典在精确率、召回率和F1值三个评价指标上都要高于用HowNet和Word2Vec构建的情感词典,虽然用Word2Vec+HowNet构建的贬义情感词典在召回率上没有Word2Vec构建的情感词典高,但仍然高于HowNet构建的情感词典,而且精确率和F1值都略高于其他两种方法。分析其原因:HowNet方法通过计算候选情感词与两类种子词集中所有词的语义相似度来确定情感词的情感倾向,但是种子词的选取具有较强的主观性和领域性,因此影响了该方法的分类准确率;Word2Vec方法是在语料库上训练一个模型,得到语料库中词语的词向量,计算词语间的余弦值得到与候选词最接近的词,根据相近词的情感倾向确定候选词的情感倾向,但是有时相近词的情感倾向也不确定,这就导致候选词的情感倾向不能确定;Word2Vec+HowNet方法针对Word2Vec方法的缺点用HowNet方法进行弥补,大大增加了情感词典的覆盖率。所以总体来看,本文提出的情感词典构建方法具有较高的准确性和可利用性。
4 结语
本文针对基于Word2Vec构建情感词典的不足,提出一种基于Word2Vec和HowNet构建情感词典的方法。该方法首先从语料中选择候选情感词,然后利用Word2Vec训练语料得到词向量,进而得到与候选词最接近的10个词,根据候选情感词与这10个相近词的语义相似度确定情感倾向,而对于最接近的10词都无法确定褒贬导致候选情感词情感倾向不确定时,则用HowNet方法来判断,即先从基础情感词典中选择种子词,然后计算候选词与种子词的语义相似度,相似度越大则情感倾向越相近。实验结果表明,本文提出的情感词典构建方法在餐饮评论情感词典构建中具有较高的准确性和可利用性。
下一步研究中,将在其他多种语料中对本文方法进行实验。通过实验发现种子词的选择对准确率有一定的影响,如何选择合适的种子词将是后续研究的重点。
[1]王科,夏睿.情感词典自动构建方法综述[J].自动化学报,2016,42(04):495-511.
[2]谢松县,刘博,王挺.应用语义关系自动构建情感词典[J].国防科技大学学报,2014,36(03):111-115.
[3]Kim S M,Hovy E.Determining the Sentiment of Opinions[C].Proceedings of the 20th International Conference on Computational Linguistics.Association for Computational Linguistics,2004.
[4]Hassan A,Radev D.Identifying Text Polarity Using Random Walks[C].Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.Association for Computational Linguistics,2010:395-403.
[5]周咏梅,杨佳能,阳爱民.面向文本情感分析的中文情感词典构建方法[J].山东大学学报(工学版),2013,43(06):27-33.
[6]张璞,王俊霞,王英豪.基于标签传播的情感词典构建方法[J/OL].计算机工程,:1-7(2017-06-01).http://kns.cnki.net/kcms/detail/31.1289.TP.20170601.1406.006.html.
[7]柳位平,朱艳辉,栗春亮,向华政,文志强.中文基础情感词词典构建方法研究[J].计算机应用,2009,29(10):2875-2877.
[8]陈晓东.基于情感词典的中文微博情感倾向分析研究[D].华中科技大学,2012.
[9]黄仁,张卫.基于word2vec的互联网商品评论情感倾向研究[J].计算机科学,2016,43(S1):387-389.
[10]黄时友.面向话题型微博评论的观点识别及其情感倾向分析研究[D].杭州电子科技大学,2015.
[11]张卫.互联网商品评论情感分析研究[D].重庆大学,2016.
[12]陈柯宇,何中市.基于情感词典的酒店评论情感分类研究[J].现代计算机(专业版),2017,(06):3-6.
[13]刘群,李素建.基于《知网》的词汇语义相似度计算[D].北京:中国科学院计算技术研究所,2002.
[14]陆峰.基于Word2Vec扩充情感词典的商品评论倾向分析[J].电脑知识与技术,2017,13(05):143-145+159.
[15]杨小平,张中夏,王良,张永俊,马奇凤,吴佳楠,张悦.基于Word2Vec的情感词典自动构建与优化[J].计算机科学,2017,44(01):42-47+74.
猜你喜欢
厦门大学学报(自然科学版)(2021年4期)2021-06-22
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
电脑知识与技术(2019年23期)2019-11-03
英语文摘(2019年5期)2019-07-13
作文周刊·小学五年级版(2018年17期)2018-09-05
公务员文萃(2016年11期)2016-11-21
外语教学理论与实践(2014年2期)2014-06-21
中关村(2014年5期)2014-05-15
意林(2013年9期)2013-05-14
