
一种基于视频特征及历史数据的流行度预测算法
2018-03-13 05:18赵命燕李泽平
计算机与现代化 2018年2期
赵命燕,李泽平
(贵州大学计算机科学与技术学院,贵州 贵阳 550025)
0 引 言
随着互联网技术的飞速发展,互联网提供的服务也发生了一定的变化。早期的互联网应用主要集中于网页浏览、文件共享等文本信息通信服务,已不能满足人们日益丰富和多样化的需求,视频会议、远程教学、视频点播等新的流媒体服务和应用如雨后春笋般地出现,因此流媒体的发展为存储及网络带宽等带来不小的挑战[1]。通过在离用户更近的服务器端缓存热点内容,能减少用户访问的响应时间,提高服务质量。如何合理地选取缓存内容以提高资源利用率是流媒体服务目前面临的主要问题,解决该问题的关键是需要对流媒体文件的流行度进行科学的预测。
近年来,随着网络中流媒体文件的激增,越来越多的研究者关注流行度预测问题。现有的流行度预测方法主要分为2大类,基于时间序列建模的流行度预测方法及基于机器学习的流行度预测方法[2]。Tan等人[3]将在线视频的流行度视为给定时间段的时间序列,并提出一种新的流行度预测时间序列模型,该模型基于视频累积的观看次数的方差之间的相关性进行预测,而不是其不同阶段的累积观看次数的值。该模型优于现有的几个流行度预测模型,但并未考虑外部因素,如视频的演员、上映时间等对视频点播量的影响。Li等人[4]提出一种新颖的在线学习方法来执行高效快速的缓存替换策略。该学习方法不直接了解每个内容的受欢迎程度,而是学习内容的未来流行度与上下文之间的关系,从而利用不同内容访问模式之间的相似性。但该方法需要大量的空间存储内容的上下文,各节点间的通信较复杂。朱琛刚等人[5]基于随机森林算法及主成分分析法构建了互联网+电视平台节目流行度的预测模型,并提出一种基于节目流行度的缓存调度算法。该算法在保证缓存命中率的同时能有效地降低存储空间,但该算法仅考虑了节目的部分因素对流行度的影响。Liu等人[6]提出一些新的微博动态特征,如转发深度、转发宽度等,并利用这些动态传播特征训练一个决策树预测微博的受欢迎程度,再使用线性回归算法来预测1 h后转发的动态特征值。该模型能较好地预测微博早期的流行度,但对长期的预测效果不佳。Abdelkrim等人[7]提出一种新型混合多回归模型预测用户生成视频(UGV)的流行度。该模型基于整个数据集的信息,定期更新最近的视频流行度,使用统计误差分析,将用户观看时间和分享次数作为模型中预测变量的最佳参数。此混合多回归模型预测胜过普通的在线回归模型,但该算法并没有考虑在线社交网络对用户生成视频流行度的影响。Hassine等人[8]使用不同领域(如统计、机器学习、控制理论)的各种预测方法作为专家,并根据累积损失、最大瞬时损失和最佳排名这3个标准来评估专家,然后根据K个最佳的专家的预测结果来预测视频的流行度。该模型能较好地对视频的流行度进行预测,但由于每位专家都必须对每次请求的视频做出判断,增加了模型的复杂程度。
本文在已有研究的基础上,提出一种基于流媒体特征及历史点播数据的混合预测模型。该模型将流媒体预测问题分为2个步骤:1)对流媒体流行程度的预测;2)对流媒体点播量的预测。通过将机器学习与基于时间序列的预测方法相结合,使用K-近邻(KNN)算法及自回归滑动平均(Autoregressive Moving Average, ARMA)模型的混合模型对流媒体流行度进行预测,该模型能对影片的流行程度进行大致预测,并能弥补动态时序预测模型仅利用历史点播量,未考虑不同视频之间的相关性的缺点及刚上线视频进行预测的不足。通过真实数据分析和预测结果表明,与朴素贝叶斯分类器及自回归滑动平均预测模型相比,本文提出的预测模型能更加有效地对流媒体流行度进行预测。
通过Eviews8.0软件绘制残差预测值图(见图1),以及历年财政教育支出的实际值和预测值的对比图(见图2),图2中横坐标01,02,…,16分别代表2001年、2002年、……、2016年.
1 视频流行度特征
流行度是度量视频热度的重要指标之一,一般以视频点播量作为流行度的度量。本文通过爬取优酷视频、新浪微博、豆瓣电影相关数据,分析视频的流行度与不同特征的关系如下。
1.1 流行度与内容的关系
假设训练集L={(R1,Y1),(R2,Y2),…,(Rn,Yn)},其中Ri表示第i个视频的特征向量,Yi表示第i个视频的点播量。
在动物脓毒症模型中,选择性激活S1PR1或抑制S1PR2和S1PR3表达均能改善内皮屏障功能。而血管内皮细胞主要表达S1PR1[20],因此,选择性激活S1P/S1PR1可能成为改善内皮屏障功能的主要途径。
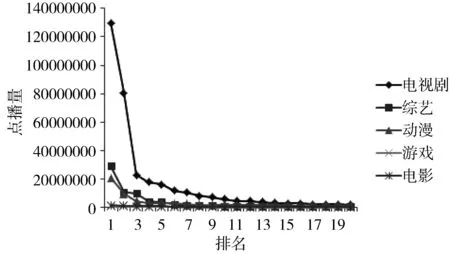
图1 流行度与内容的关系
1.2 流行度与类型的关系
1)获取测试样本K个近邻的历史点播数据{CRj(ti)|i∈[0,n],Rj∈Mk(R)}并计算测试样本的点播量:
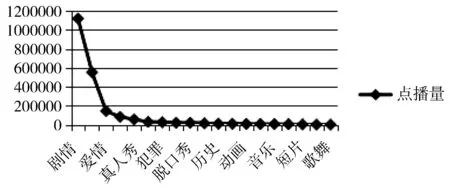
图2 流行度与类型的关系
1.3 流行度与时间的关系
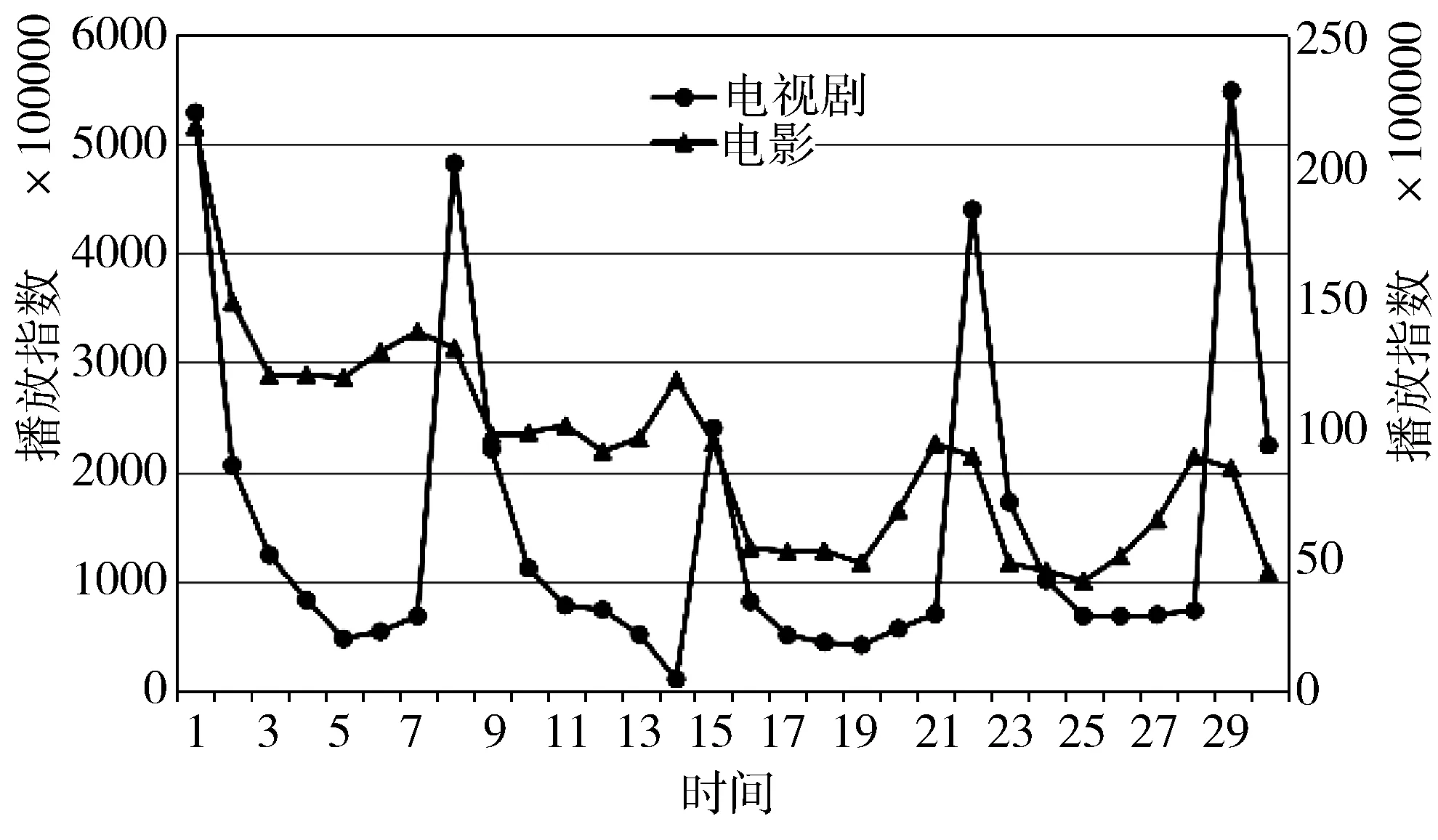
图3 流行度与时间的关系
如图3所示,视频的点播量会随着时间呈现周期性变化,周末的点播量远高于工作日的点播量。对于电视剧类视频,一般会在每周六更新一集,这时会有大量的点播量,之后点播量会逐渐降低,直到下一次更新,点播量会重新达到顶峰。电影类视频在上线初期会有很高的点播量,随着上线时间的增加,点播量也逐渐降低,但在周末会出现一个回升。
1.4 流行度与演员的关系
视频由不同演员参演,其点播量也明显不同,图4显示了3个不同的影星参演的影片的点播量变化情况,从图中可以看出,由同一个影星参演的影片点播量也大致相同。图5为影片演员在微博的影响力与影片点播量的关系,演员在微博的影响力越大,该影片的点播量也越大,呈现出一种正相关关系。
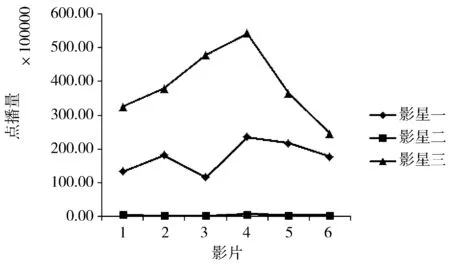
图4 参演演员与流行度的关系
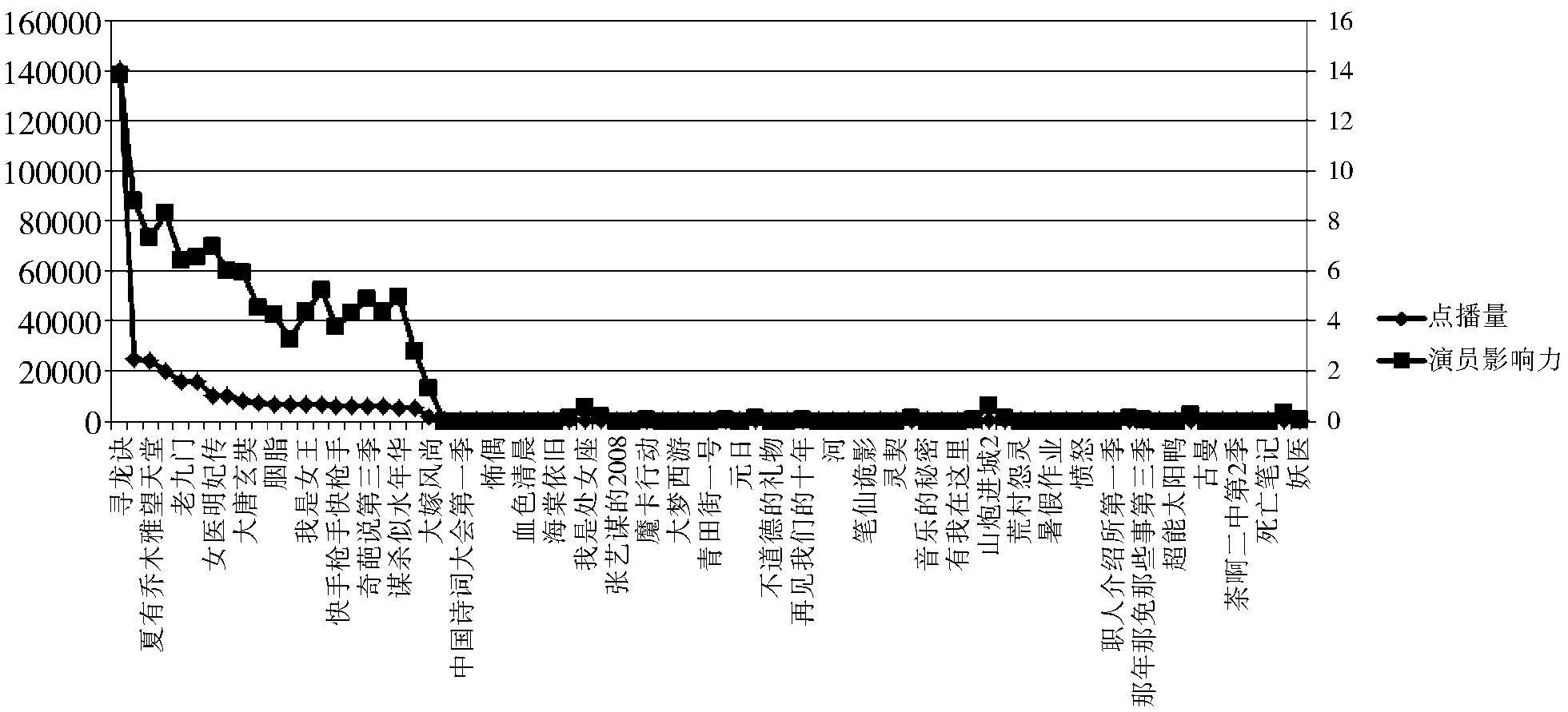
图5 参演演员与流行度的关系
2 流行度预测算法
本文研究新上传的视频的流行度问题,并把这个问题分为2个任务,预测视频的流行程度和预测视频的点播量。首先,根据新上传视频的特征值对视频是否会流行进行预测,这个任务可以看作是一个分类问题。然后,根据第一阶段的预测结果,预测视频上线之后的具体点播量,这个任务是依据时间序列进行建模。
视频的流行度是反应视频热度的重要指标[10],通过对视频的流行度进行预测,捕获用户的收视兴趣,根据用户的兴趣对系统的缓存内容进行调度能有效地降低用户的访问延时[11]。由第1章可知,视频的流行度与视频的类型、上线时长、参演演员等特征有着密切联系,因此,本文使用以上特征来对视频流行度进行预测,并据此进行合理的缓存调度。
2.1 数据预处理
本文将采用上线时间、演员、类型这3种特征作为视频特征向量。但这些特征不能直接作为算法的输入,需要对其进行预处理。
1)上线时间。视频在周末的点播量明显高于工作日的点播量,在周末上线的新视频也会获得相对较高的点播量。因此,本文将一周按7天分为7个时间点,根据视频上线的时间,标记1~7中对应的值。
目前的家装建材配送市场秩序很不规范,普遍存在配送时效差以及货损率高的情况,配送成本也是一直居高不下。家装企业必须规范其配送模式,加强对与配送相关的供应商以及承运商专业配送人员的管理,与对方建立合作伙伴关系,并且不断地进行优化,提高效率和效益,在降低配送成本的同时,努力实现供应商、企业、消费者三者共赢。
2)演员。演员的热度直接影响了视频的点播量。每个影片对应着多个演员,数量众多,直接使用比较困难,因此,将利用新浪微博的明星热搜榜及粉丝人数量化演员的热度,而对未上榜的演员,则视为影响因子为0。
3)类型。每个资源对应着一个或多个类型,将这些类型转换为0,1向量,每一列代表不同的取值,即如果数据集中包含N个类型,则对应一个的向量,某一个影片的类型所在的列为1,其余全为0。
刘清建船是为了亦失哈下奴儿干所用,责任重大,工期有限。古人崇拜司水的龙王,因而刘清就在船厂附近修建起一座龙王庙,以便就近供奉,祈请风调雨顺,按期完成造船任务。
每个特征对影片流行度的影响是同等重要的,有必要对数据进行归一化处理,本文将采用公式(1)处理数据,使特征值转化为0到1的区间。
(1)
其中,x为归一化后的特征值,x0为原特征值,xmax为原特征中的最大值,xmin为最小值。
2.2 视频流行程度预测
网络中视频数量巨大,每日上新的视频也层出不穷,但是只有20%的视频会收获80%的点播量,也就是说,只有20%的视频会流行[12]。因此,先预测上新的视频是否会流行,并据此决定是否继续预测视频的点播量会大大降低系统的运行成本。
“116号文”的规定是,内外部观测工程列入第一部分的其他建筑工程,外部观测设备列入第二部分的公用设备及安装工程。由于该规定没有对内外部观测工程和外部观测设备进行解释和界定,有的人士就要求将埋设于结构内部、固定于结构表面的监测设备列入公用设备及安装工程,但查阅水利工程造价有关资料,“116号文”的本意是列入其他建筑工程。
KNN算法是一种基本的机器学习算法,它利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”[13]。KNN算法的核心思想是在训练集中找出K个最相邻的样本,并根据这K个样本的大多数类别来确定测试样本的类别[14]。本文将基于KNN算法对视频的流行度进行预测。
关于资源建设的探讨,地方特色尤为突出。如李子贤指出天津海运高职院校图书馆应加强海洋特色数字资源建设,积极参与天津市海洋经济与文化建设[25];蒋冬英倡议创新岭南海洋文化资源建设,通过对文献资源及历史遗迹的专题研究建立“一带一路”特色资源库,包括自建电子资源、纸质文献及网络电子资源[26];张晓丹则分析了少数民族古籍文献的特点及分类,主张抓住“一带一路”重大项目“丝路书香工程”立项的机遇,统一协调、共建共享东北民族高校少数民族文献资源[27]。
不同于KNN算法,本文找出K个最近的样本后,根据距离给样本赋予一定的权值,距离越近,权值越大,然后根据这K个样本的流行度,计算预测样本的程度。
如图1所示,视频的流行度符合Zipf分布[9],即排名前20%的内容占了80%的点播量,除此之外,不同类型的视频,点播量也相差很大。优酷视频会和电视同步更新电视剧、综艺及动漫资源,这3类视频的点播量能较好地反应流行度的分布情况。游戏类型的视频主要是一些自媒体上传的视频,而且受众面相对较小,所以点播量远小于以上3类视频的点播量。而电影类视频由于版权问题,一般都在线下院线上映很长一段时间之后才会在线上上映,不具有实时性,点播量也远小于其他类型的视频。
其预测过程如下:
1)根据距离公式计算训练集中的所有样本与测试样本的距离,一般采用欧氏距离计算样本之间的距离:
C1m(tn)=θ1CR1(tn)+θ2CR2(tn)+…+θkCRk(tn)
(2)
预测完影片的流行程度之后,进行点播量的预测。在此,将利用2.2节的预测结果,并结合ARMA预测模型对影片的流行度进行预测。
3)根据分类决策规则决定测试样本的类别,即:
(3)
2.3 视频点播量预测
2)找出与测试样本距离最近的K个样本,包含这K个样本点播量的领域记作Mk(R)。
ARMA预测模型是一种时间序列预测模型,在理论上已经趋于成熟,并且广泛应用在各个领域[15]。假设影片m自上线之后的点播量序列{Cm(ti)|i∈[0,n]}是以等间隔采样的一组离散值,它的子序列{Cm(ti)|i∈[0,r]}是在时间[0,tr]内的历史点播量,则影片m在n+1时刻的流行度Cm(tn+1)为前n个单位时间间隔的点播量的线性组合。即:
Cm(tn)=α1Cm(tn-1)+…+αpCm(tn-p)+εn-β1εn-1-…-βqεn-q
(4)
其中,α1,…,αp为自回归系数,β1,…,βq为滑动平均系数。随机项εn,εn-1,…,εn-q为相互独立的白噪声序列,且服从均值为0,方差为σ2的正态分布,即εn~N(0,σ2)。
ARMA预测模型并不能对影片上线初期的点播量进行预测,为了解决这个问题,本文采用KNN与ARMA相结合的方式对影片流行度进行预测。具体预测过程如下:
具有不同类型标签的影片,点播量也大不相同。如图2所示,视频的点播量与视频的类型也符合Zipf分布。在本文使用的数据集中,类型标签为剧情、喜剧、爱情的影片占了总数据量点播量的80%。
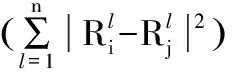
我们在教学中对时代背景的处理,看似无关宏旨,其实还是很重要的。要想恰当地处理好它,就要求教师对文本有清晰的认识,对教学目标的设置有准确的把握,对文本所涉及的背景有确凿的分析,因为这直接影响到学生对文本的理解,同时也会影响教学的节奏。但不管采用哪种方式,都要从学生出发,从阅读的规律出发,从具体的文本特点出发,只有适合的才是最好的。
(5)
其中θ1+θ2+…+θk=1。
2)获取测试样本的历史点播数据,并用公式(4)计算点播量C2m(tn)。
3)测试样本最终的点播量为:
Cm(tn)=νC1m(tn)+(1-ν)C2m(tn)
可以看出,“对高校部门决算报表分析文字说明属于无用分析以及不能正确运用决算分析的各种方法”这两方面因素是区内外高校认知最大的区别,这其中原因也是相关联的,因为不能正确使用决策分析方法,所以数据分析准确性及相关性不高,运用于实际工作就比较少。同时也能看出来区外财务人员对能正确运用决算分析的各种方法认同度更高。
(6)
3 实 验
3.1 数据集
本文通过编写爬虫程序,爬取了豆瓣电影(https://movie.douban.com)中标签含有“2016”及“中国”的所有资源的影片名、上映时间、主要演员及评论。该数据集包括685个资源,包含了电影、电视剧、真人秀、动画等,共有26个类型及2747名演员。为了使数据集更加易于处理,删除了评论数小于100的视频,最后剩512个资源。同时,还爬取了新浪微博名人影响力榜(http://data.weibo.com/top/influence/famous)及微博(http://weibo.com)中的标签含有明星、演员的用户及其粉丝数共2485个。
黄土高原地区植被覆盖整体呈东南覆盖高,西北地区覆盖低的空间分布。覆盖最高的生态区为燕山-太行山山地落叶阔叶林生态区,覆盖最低的为内蒙古高原中东部典型草原生态区、内蒙古高原中部-陇中荒漠生态区及内蒙古高原中部草原化荒漠生态区。植被覆盖多年平均的SEN变化趋势,变化幅度最大的为黄土高原农业与草原生态区,最小的是祁连山森林与高寒草原生态区,变幅不明显的则是内蒙古高原中部-陇中荒漠草原生态区。
3.2 性能评估
为了评价本文提出的模型在预测影片流行度的性能,本文将以天为单位时间计算点播量,与文献[16]中的朴素贝叶斯分类器(the Naive Bayes Classifier, NBC)和文献[17]中的ARMA模型进行比较。
去片后的裸眼视力频数分布如图1所示。71%(37/52)的儿童去片后裸眼视力集中在0.6~0.8。通过单因素回归分析,较差的去片裸眼视力与基础较长的眼轴(b=-0.09,β=-0.29,P=0.003)、较高的球镜度(b=0.07,β=0.36,P<0.001)、较高的柱镜度(b=0.12,β=0.22,P=0.030)有关,与角膜厚度、眼压、角膜曲率、瞳孔直径、角膜对称性、偏位程度等无关(见表2)。
召回率(recall)是广泛用于分类领域的度量值,反映了被正确预测的正例中预测正确的比重。召回率越高,分类器的预测越准。其计算方式如下:
2.2 安全过度梁式气管套管固定带的更换方法 一人独立可以操作。当气管套管固定带有潮湿或污染时,用2根过度固定带分别穿入并固定于外套管底板上的左右两侧的安全过度梁上,在患者颈后打结固定,并确保固定牢固,松紧一指为宜。然后用清洁的正式固定带替换固定于外套管底板上左右两侧的半圆孔上的被污染的固定带,于颈后3个外科结固定,松紧一指为宜。最后撤去安全过度梁式气管套管上的过度固定带。
(7)
其中TP代表预测准确的流行影片数量,TN代表测试集中流行影片的总数量。
平均平方根误差(Root Mean Square Error, RMSE)是用于测量时间序列预测结果精准度最广泛的度量标准之一,RMSE值越小,说明算法预测的精度越高。其规定如下:
十年树木,百年树人,教育是一项百年大计,对一个国家和民族复兴和发展具有重要的意义和作用。随着时代的发展和社会的进步,英语越来越受到人们的重视。学好英语已经不再是外交官与国家领导人的责任,更加是学生的重要课程,是新一代学生不可推卸的重任。目前,我国急缺高质量的英语人才,这对学生与英语教师提出了更加严格的要求。城乡小学生的实际英语水平却相差甚远,主要有教材版本不同、教学安排不合理、教师教学方法以及城乡小学生家长的重视等原因。
(8)
随着K的取值不同,模型的召回率如图6所示,当K<7时,分类器的召回率较低;当K=9时,分类器的召回率最高;当K>9时,召回率又开始降低。表1展示了与朴素贝叶斯分类器的对比结果,朴素贝叶斯分类器的召回率仅为31.47%,而本文提出的KNN模型的召回率高达89.05%,明显优于朴素贝叶斯分类器。
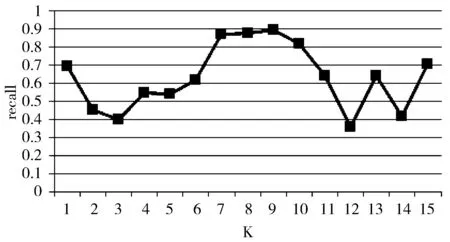
图6 近邻(K)个数与召回率的关系
表1 KNN算法与NBC模型召回率(%)

KNNNBCRecall89.0531.47
把本文的预测模型与文献[17]中的ARMA模型进行比较,ARMA模型在第4天时能达到较好的预测效果。本文预测影片上映后10天的播放量,其平均平方根误差RMSE如图7所示。从图中可以看出,本文提出的模型的RMSE低于ARMA,尤其是上映后3天,比ARMA模型的RMSE降低了约20%。随着上映时间的增加,2个模型的RMSE逐渐降低,并且在第4天后趋于平稳。
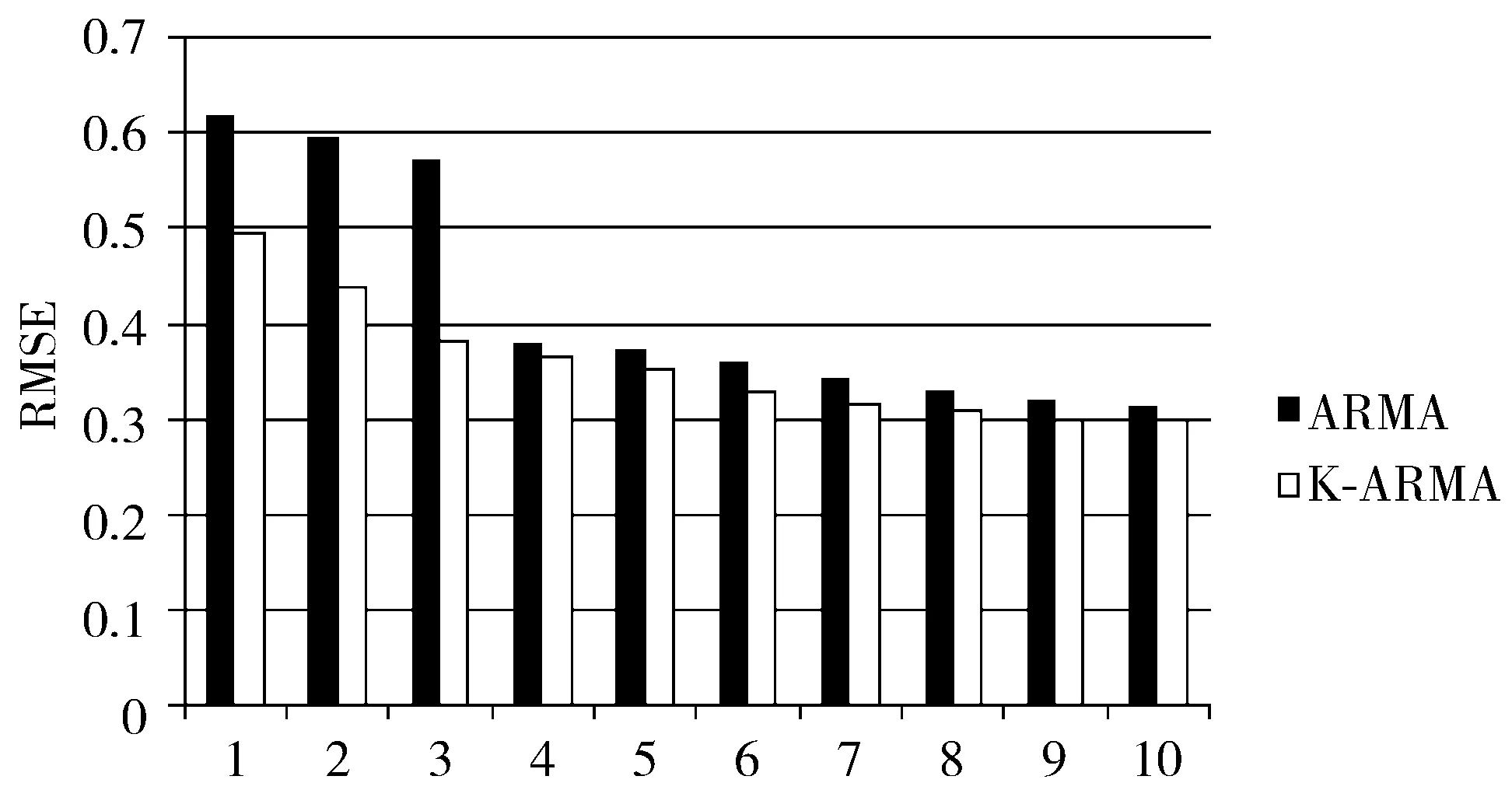
第i天图7 K-ARMA模型与ARMA模型RMSE比较
4 结束语
为了对影片的流行度进行预测,本文将预测问题分为2个过程,一是流行程度预测,二是点播量预测。通过对数据集进行分析获取影响影片流行度的特征,并结合影片在社交网络中的影响力对特征进行量化。然后使用量化后的特征对影片流行程度进行预测,根据预测结果,结合历史数据对影片的点播量进行预测。与对比模型相比,本文提出的模型预测结果更加准确,尤其是对影片上线前几天的预测。未来,将结合用户行为数据,增加预测的特征值,以提高模型的预测精度。
[1] Li Chenyu, Liu Jun, Ouyang Shuxin. Analysis and prediction of content popularity for online video service: A Youku case study[J]. China Communications, 2016,13(12):216-233.
[2] 高帅. 在线社会网络中影响力度量和流行度预测问题研究[D]. 济南:山东大学, 2015.
[3] Tan Zhiyi, Wang Yanfeng, Zhang Ya, et al. A novel time series approach for predicting the long-term popularity of online videos[J]. IEEE Transactions on Broadcasting, 2016,62(2):436-445.
[4] Li Suoheng, Xu Jie, Schaar M V D, et al. Trend-aware video caching through online learning[J]. IEEE Transactions on Multimedia, 2016,18(12):2503-2516.
[5] 朱琛刚,程光,胡一非,等. 基于流行度预测的互联网+电视节目缓存调度算法[J]. 计算机研究与发展, 2016,53(4):742-751.
[6] Liu Wensen, Wang Xiaoyi, Cao Zewen. Popularity prediction in microblog based on LR-DT[C]// IEEE International Conference on Behavioral, Economic and Socio-Cultural Computing. 2015:18-23.
[7] Abdelkrim E B, Salahuddin M A, Elbiaze H, et al. Ahybrid regression model for video popularity-based cache replacement in content delivery networks[C]// 2016 IEEE Global Communications Conference (GLOBECOM). 2016.
[8] Hassine N B, Marinca D, Minet P, et al. Expert-based on-line learning and prediction in Content Delivery Networks[C]// International Wireless Communications and Mobile Computing Conference. 2016:182-187.
[9] Krishnan S S, Sitaraman R K. Videostream quality impacts viewer behavior: Inferring causality using quasi-experimental designs[J]. IEEE/ACM Transactions on Networking, 2013,21(6):2001-2014.
[10] 杨传栋,余镇危,王行刚,等. 基于流行度预测的流媒体代理缓存替换算法[J]. 计算机工程, 2007,33(7):99-100.
[11] Tan Zhiyi, Zhang Ya, Li Chaofeng, et al. Lifetime popularity prediction for online videos[C]// IEEE International Symposium on Broadband Multimedia Systems and Broadcasting. 2014:1-6.
[12] 徐理想. 视频点播系统层级式缓存优化技术研究[D]. 合肥:中国科学技术大学, 2016.
[13] Zhang Shichao, Li Xuelong, Ming Zong, et al. Efficient kNN classification with different numbers of nearest neighbors[J]. IEEE Transactions on Neural Networks & Learning Systems, 2017,PP(99):1-12.
[14] Jain J, Hiwale S, Bhat P V. Classification of labour contractions using K-NN classifier[C]// International Conference on Systems in Medicine and Biology. 2016.
[15] Hassine N B, Milocco R, Minet P. ARMA based popularity prediction for caching in Content Delivery Networks[C]// IEEE 2017 Wireless Days. 2017:113-120.
[16] Ouyang Shuxin, Li Chenyu, Li Xueming. A peek into the future: Predicting the popularity of online videos[J]. IEEE Access, 2016,4:3026-3033.
[17] Chang Biao, Zhu Hengshu, Ge Yong, et al. Predicting the popularity of online serials with autoregressive models[C]// Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. 2014:1339-1348.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高一版(2021年2期)2021-03-19
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
数学学习与研究(2017年3期)2017-03-09
