
基于不平衡样本的企业财务困境预测研究
2018-03-04 04:04吕心洁
商场现代化 2018年24期
吕心洁


摘 要:本文基于SMOTE算法和随机森林算法提出了SMOTE-RF企业财务困境预测方法,即通过SMOTE算法构造人工数据增加少数类样本数量,以随机森林算法作为分类器对企业财务困境进行预测。实证结果表明,SMOTE-RF比SVM和神经网络具有更好的预测准确性和稳定性。
关键词:财务困境;不平衡样本;SMOTE;随机森林
一、引言
财务困境,又称财务危机,是企业危机的最综合、最显著的表现。财务困境的预测一直是实务界和理论界广泛持续进行的研究课题。正确地预测企业财务困境,对于保护相关利益主体、提高企业防范财务危机能力具有重要的现实意义。
但发生财务困境的企业只是少数,占企业总数量的比重极小。而当一个数据样本中一个或几个类别的数据数量远大于其他类别的数据数量时,这样的数据样本就是不平衡数据样本。因此,对上市企业的财务困境进行预测时,主要面对的是不平衡样本。综观财务困境预测研究文献,处理不平衡样本主要有三种方法:一是忽略不平衡样本的影响,如陈晓和陈治鸽,肖珉等。但忽略样本的不平衡性,会使得预测模型过多关注多数类样本,导致对少数类样本的分类性能下降。二是采用财务困境企业与非财务困境企业1:1配对的方法构建平衡样本,如Beaver,Altman,吴世农和卢贤义,乔卓等。构建平衡样本,固然可以提高预测模型的准确率。但根据Zmijewski的研究,若样本结构比例与现实中实际比例的偏差较大,会影响模型的实际预测能力。三是利用基于不平衡样本的改进算法。通过利用采样算法、设置惩罚系数等方法以克服样本不平衡性带来的影响。但构建的混合算法,在预测准确性、预测稳定性和泛化性上仍不够理想。
基于此,本文以沪深两市上市企业作为研究对象,构建SMOTE-RF财务困境预测模型,并以实际数据证明比其他预测模型(如SVM模型、神经网络模型)具有更好的预测效果。
二、SMOTE-RF方法
SMOTE-RF方法即是先利用SMOTE算法仿制数据样本中少数类样本的信息,构造人工数据以平衡数据比例结构,再通过随机森林方法对处理后的数据样本进行学习分类。该方法主要是针对于不平衡数据样本,能有效地提高模型对不平衡数据样本的预测能力。
1.SMOTE算法
2002年,Chawla首次提出了合成少数类过取样方法(SMOTE)。SMOTE方法主要是通过人工合成少数类样本以提高少数类样本的比例,降低数据结构比例的偏斜度。SMOTE方法可以增加新的并不存在的数据样本,所以在一定程度上避免了分类器的过度拟合。SMOTE算法首先对少数类的每一个样本x,搜索其k个最近邻样本,然后随机选取这k个最近邻中的一个样本记为y,再在x与y之间进行随机线性插值,构造新的少数类样本xnew。若需要增加更多的人造样本,只需重复上述步骤,直至所有少数类样本均处理完毕。
2.随机森林方法
三、实证分析
1.样本选取
目前,国内学术界普遍采用证监会定义ST企业的标准作为财务困境公司的判定依据。本文也遵从此做法,选取沪深两市2010年至2012年各年度的ST公司作为财务困境企业样本,其余非ST公司(不包括金融业)作为非财务困境企业样本。在预测时间上,本文以上市公司T-3年的财务指标数据建立预测模型,即用上市公司发生财务困境事件三年前的数据来预测该公司是否会在T年出现财务困境而被特别处理。财务困境样本公司的首次ST年份数据和所有样本公司的财务指标数据来自于国泰安数据库。
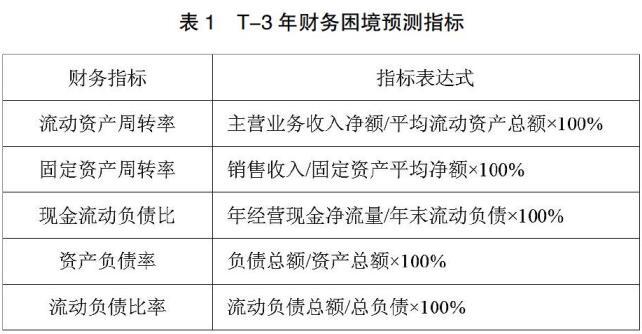
2.指标选择
本文采用的财务指标如表1所示。
3.评价标准
每年度被ST的公司相对于上市公司整體而言只是极少数。在样本数据中,ST企业与非ST企业的数量比最高达到了1:97,呈现出较强的不平衡性。因此,本文选取了针对不平衡问题的分类性能评价标准:Fmeasure和Gmean,公式如下:
其中,Sensitivity代表少数类正确率,Specificity代表多数类正确率,Precision代表少数类查准率。
4.预测结果及分析
为对比不同建模方法的预测能力,本文还建立了SVM模型和神经网络模型。模型参数如下:SMOTE-RF中,分类树的数目ntree取值200-1000,每个内部节点的候选特征数m取默认值sqrt(m);SVM的核函数选择径向基函数,gamma取值0.1,设置惩罚系数C为10、100、500、1000、2000;神经网络模型采用一个隐藏层数,隐藏层节点数为1-50。预测结果如表2所示。
比较各年度分类结果可以看出,SMOTE-RF的Gmean值和Fmeasure值最高,说明SMOTE-RF方法的预测性能要优于SVM和神经网络。同时,SMOTE-RF方法在三个年度对少数类样本、多数类样本的预测准确率以及Gmean值和Fmeasure值始终稳定在95%以上,表明SMOTE-RF方法具有较高的预测准确率和较好的预测稳定性。而SVM和神经网络对该类不平衡数据样本的预测能力则较弱,对多数类样本判别虽较准,但少数类样本判别正确率明显偏低,因此Gmean值和Fmeasure值也都较低。并且,SVM的预测波动幅度较大,也验证了”不平衡数据样本会对传统预测模型性能产生影响”的观点。
四、结论
通过利用SMOTE-RF方法对我国上市企业财务困境预测的实证研究可以看到,将发生财务困境的企业放到沪深两市所有企业中进行预测时,SMOTE-RF方法的预测准确率较高,误判率较小,泛化性能好,说明采用SMOTE-RF方法对上市企业整体进行财务困境预测是确实可行的。
参考文献:
[1]陈晓,陈治鸿.中国上市公司的财务困境[J].中国会计与财务研究,2000,4:55-72.
[2]消珉.我国企业集团上市公司财务预警与信用风险评估研究[D].电子科技大学,2012.5.
[3]W. Beaver. Financial Ratios as Predictors of Failure[J].Journal of Accounting Research,1966,4:71-111.
[4]E. I. Altman. Financial Ratios as Predictors of Failure[J].Journal of Accounting Research, 1996,4:71-111.
[5]吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001,6:46-55.
[6]乔卓.上市公司财务困境预测模型实证研究[J].财经科学,2002,7:21-24.
[7]Zmijewski. M.E. Methodological Issues Related to the Estimation of Financial Disterss Prediction Model[J].Journal of Accounting Research,1984,NO.22.
猜你喜欢
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
预测(2016年5期)2016-12-26
商情(2016年43期)2016-12-23
商(2016年34期)2016-11-24
电脑知识与技术(2016年23期)2016-11-02
中国市场(2016年30期)2016-07-18
商(2016年5期)2016-03-28
商(2016年4期)2016-03-24
