
基于知识图谱表示学习的协同过滤推荐算法
2018-03-03 01:26吴玺煜陈启买贺超波
计算机工程 2018年2期
吴玺煜,陈启买,刘 海,贺超波
(1.华南师范大学 计算机学院,广州 510631; 2.仲恺农业工程学院 信息科学与技术学院,广州 510225)
0 概述
协同过滤是至今应用最广泛的推荐技术,已经成功地应用于电子商务[1]、网上学习[2]和新闻媒体[3]等工业界领域,在学术界内也一直受到大量学者关注。协同过滤推荐主要根据用户对资源的历史行为信息,寻找用户或者资源的近邻集合,以此来计算用户对资源的偏好值[4]。文献[5]将Facebook用户的个性数据融合进协同过滤中,用合并多领域数据集的方式提高了推荐的准确性。文献[6]从评分上下文信息着手,提出了一种融合奇异性和扩散过程的协同过滤模型,解决了信息过载问题。文献[7]融合了基于内容与协同过滤的推荐算法,提高了新闻推荐的性能。现有各种协同过滤算法都使用了用户隐性反馈数据(比如购买记录)、用户显性反馈数据(比如评分)等信息,准确地将用户所需要的物品推荐给对方。然而这些算法主要利用物品-用户评分矩阵这一外在信息,尚未充分考虑物品自身的内在信息。随着知识图谱技术的发展,业界已经积累了大量开放的语义数据,如Freebase[8]、DBpedia[9],包含了物品丰富的内涵知识。将内涵知识和外在评分融合在一起,可以使得传统协同过滤推荐算法的信息更加完备。文献[10]尝试使用了知识图谱的结构特征,将本体融进协同过滤算法。现有研究表明,知识图谱表示学习方法能将知识图谱嵌入到一个低维语义空间中,可以利用连续数值的向量反映知识图谱的结构特征。这种方法可以高效地计算实体间的语义联系。文献[11]尝试将知识图谱表示学习算法与基于隐性反馈的协同过滤相结合,把原始数据转化为偏好序列进行参数学习,加强了协同过滤推荐算法的性能。
围绕上述背景,本文提出基于知识图谱表示学习的协同过滤推荐算法。算法的出发点与文献[11]相近,后者使用用户隐性反馈数据,而本文算法是针对用户显性反馈数据,即物品-用户评分矩阵。算法通过知识图谱表示学习算法TransE[12]获取物品的语义信息,计算物品之间的语义相似性,在推荐过程中融入物品的语义信息,更好地为用户进行推荐。
1 相关理论
1.1 基于物品的协同过滤推荐
基于物品的协同过滤推荐[13]是一种基于最近邻的推荐系统算法,主要基于如下假设:用户倾向于喜欢相似的物品。在推荐系统中,算法通过计算物品之间的相似性,从而向用户推荐最合适的物品。整个推荐过程形式化表示如下:假设有m个用户U=(U1,U2,…,Um),n个物品I=(I1,I2,…,In),输入的数据集是一个m×n的物品-用户评分矩阵Rm×n:
(1)
其中,分数Rij为用户Ui对物品Ij的评分,且该评分代表用户i对物品j的喜好程度。矩阵元素之间的相似性度量主要采用余弦相似性实现,即通过计算两个向量之间夹角的余弦值,度量它们之间的相似性。假设A和B为2个向量,n是它们的维度,则它们的余弦相似性表示为:
(2)
该式计算结果的值越大,向量就越相似。当simcos(A,B)值为0表示两个向量完全不相似,1则是完全相似。
此外,针对物品-用户评分矩阵中评分相当稀疏的问题,文献[14]提出加入相似性权重重要性的策略,用于避免数值过分偏倚的问题。该方法采用了贝叶斯学派里收缩的思想,当只有少量评分用于相似性计算时,采取策略降低两者之间的相似性权重。因此,改进后的物品间相似性权重计算公式为:
(3)
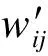
利用式(3),基于物品的协同过滤推荐算法将物品-用户评分矩阵转换成一个物品-物品相似性矩阵,并对这个相似性矩阵进行近邻选择。近邻选择是对U所挑选过的物品分别进行排序筛选,分为以下2个步骤:1)对于线下已经计算好的物品-物品相似性矩阵,进行预过滤近邻。2)对某一个用户,读取内存中的数据,使用Top-k进行选择推荐。推荐系统中用户和物品往往数量巨大,因此需要预先过滤物品间相似性度量的数量。本文采用了2种预过滤技术:Top-N过滤和阈值过滤。对于预测的评分,本文也使用了Top-k选择和正值选择,使推荐效果提高。
1.2 知识图谱表示学习
文献[15]提出的Word2Vec模型,可以将词汇嵌入到一个K维空间。这种分布式表示掀起了一股表示学习的热潮。表示学习这一古老而又新颖的话题,又一次焕发出新的光彩。该算法的核心思想是利用类比性的优点,更好地发现词与词之间的相关性。文献[12]将该思想应用于知识图谱领域,提出了一种知识图谱表示学习算法TransE。该算法的核心思想是将知识图谱中的实体与关系嵌入到一个低维的向量空间里面去,同时将两者转化为向量表示。因此,从直观上看,相近的实体在空间里的向量表示也是相近的。更进一步,在语义上有联系的实体,在空间里也有所关联。
基于上述思想,能够通过知识图谱表示学习,对知识图谱中实体和关系进行语义表示学习,通过将富有语义信息的知识图谱三元组嵌进n维语义空间并生成对应向量,从而实现了知识图谱的数值化。通过知识图谱表示学习,可以快速计算两个实体间的语义相似性,并方便地将知识图谱用到其他学习任务中。知识图谱表示学习的实现主要有2种方法:1)基于张量分解的方法;2)翻译的方法。前者包括了NTN[16]、RESCAL[17]等。后者包括了TransE、TransH[18]、TransR/CTransR[19]等。对于Freebase这类关系数目众多而又非常稀疏的大规模知识库,基于张量分解的方法效果不佳,选择翻译方法[20]更为合适。
2 基于知识图谱表示学习的协同过滤推荐算法
本文提出了一种基于知识图谱表示学习的协同过滤推荐算法,其基本思想是:对于协同过滤计算出来的最近邻,系统推荐给用户;而对于该用户喜欢的物品在语义上相似的物品,系统也可以推荐给用户。相对于协同过滤推荐算法仅使用外部评分,加入内涵知识(知识图谱)会得到更好的效果,提高推荐的有效性。
利用知识图谱表示学习算法,将推荐的物品嵌入到一个低维空间,然后计算物品之间的语义相似性,生成语义相似性矩阵,最终可以得到物品的语义近邻。同时,通过调节融合比例,对语义近邻和协同过滤潜在物品按比例融合,利用丰富的语义数据一定程度上解决了推荐系统的冷启动问题。图1给出了本文算法(记为TransE-CF)的流程图。
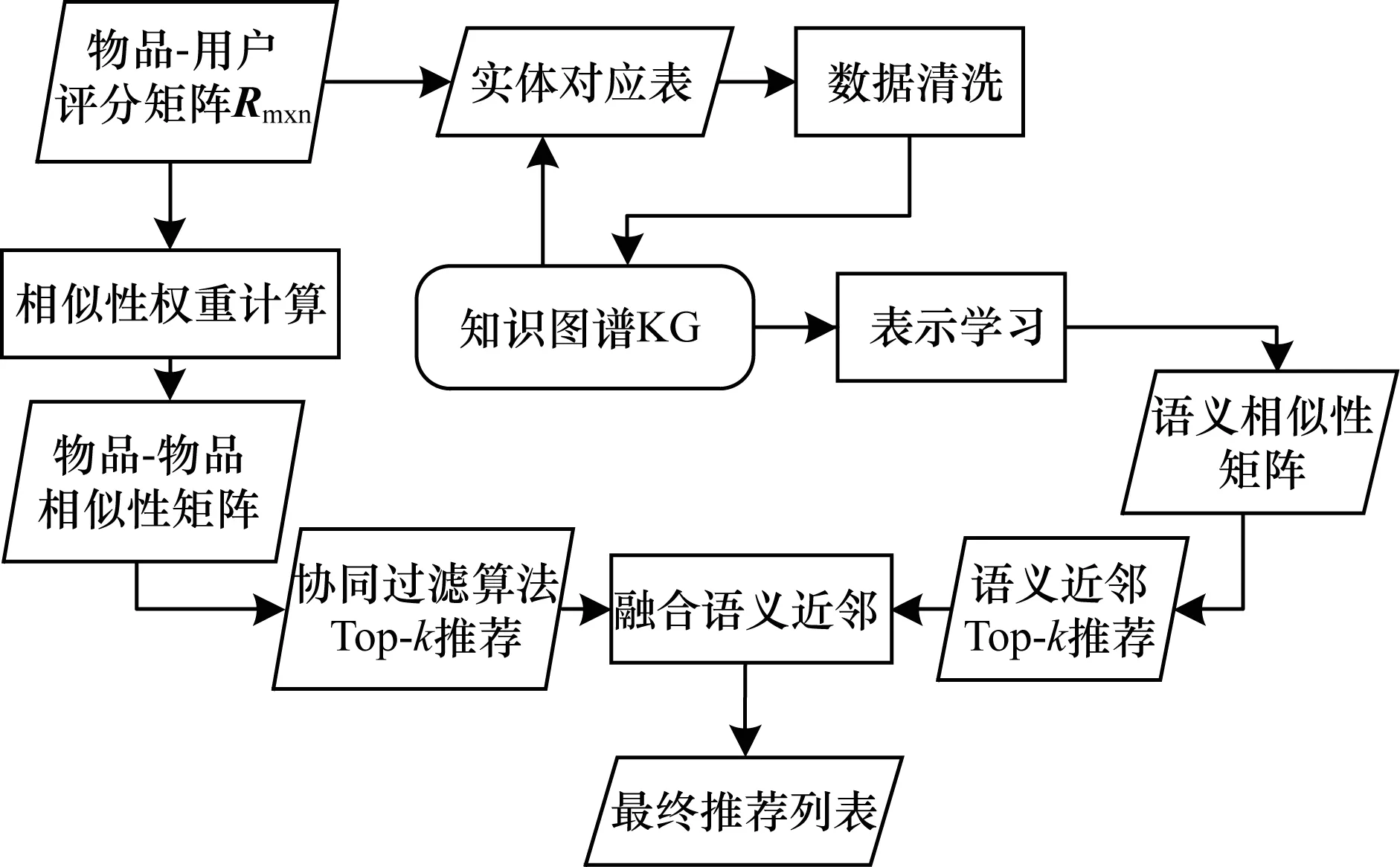
图1 TransE-CF算法流程
2.1 融合语义近邻集合的协同推荐过程
2.1.1 基于TransE算法的知识图谱表示学习
对于一个典型的知识图谱来说,可以通过有向图表示的三元组,以及三元组之间的相互链接构成一个网状的知识集合,这种三元组携带着实体自身的语义信息。其中实体作为节点,实体之间的关系作为边。
以电影领域为例,电影实体中主要包括了演员、类型、导演等主要特征。这些特征从一定程度上概括了这部电影。利用电影特征,可以得到类似图2所示的一个电影知识图谱的三元组。
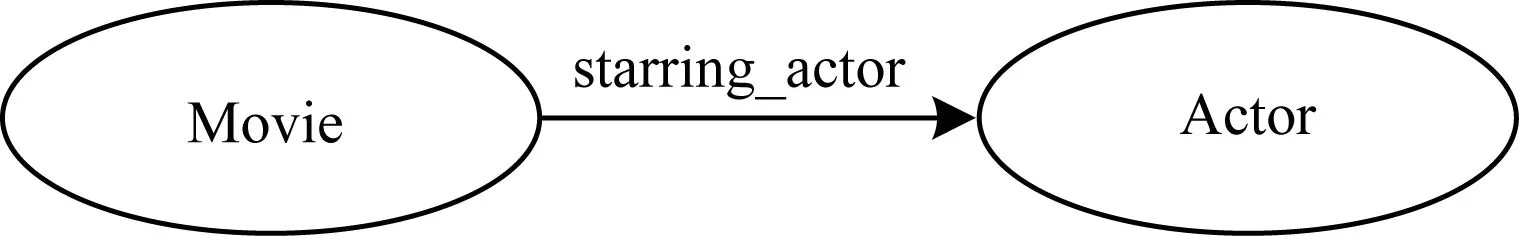
图2 知识图谱三元组
在图2中,电影实体Movie和演员实体Actor之间通过关联,构成三元组(M,starring_actor,A),再通过三元组之间的相互链接形成知识图谱。图3为Freebase中节选的部分电影及其属性所成的网状结构。从图3中可以看出,在知识图谱中越相似的2个节点,在语义上也往往十分接近。因此,对于电影推荐来说,不仅可以利用电影的用户评分信息,也可以使用电影自身的语义信息。协同过滤推荐认为两物品的用户评分分布相近,则它们被判定为近邻。同样地,如果该电影在知识图谱中相近,直观上也可以被判定为近邻。

图3 电影知识图谱
基于上述思想,本文使用在翻译方法上有较好性能的TransE算法,增强协同推荐算法中物品-用户评分矩阵中物品的语义信息。按照TransE算法的定义,对于知识图谱S中的一个三元组(h,r,t),可以用式(4)所示的损失公式进行训练:
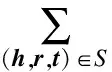
‖h′+r-t′‖]+
(4)
其中,h′和t′是错误的三元组向量,作为训练的负样本。该类负样本是将TransE算法定义的正样本,也就是原来正确三元组的头实体或者尾实体随机替换成其他实体而得。γ为间距大小,一般设γ=1。符号[·]+表示合页损失函数,形式化描述如式(5)所示。
(5)
在整个训练过程中,TransE采用了最大间距的思想,拉开正样本和负样本向量之间的距离进行训练学习。通过随机梯度下降不断迭代,使损失函数达到最优。最终的训练结果是:1)在知识图谱中相似的实体,在低维空间里面的距离相近;2)头节点的向量加上关系向量基本等于尾节点的向量。具体过程训练见文献[12]。
2.1.2 语义相似性度量
上一节所述的TransE算法将对象表示成为一组低维实值向量,且使得这些向量的值满足是一组连续实数的限定条件。在不同的知识图谱表示学习方法中,向量的含义有所不同,也就需要不同的相似性度量。式(6)给出了TransE算法中向量的表示形式:
‖h+r‖≈t
(6)
其中,h和t分别是头实体向量和尾实体向量,r是关系向量,式子中的范数‖·‖可以选择L1范数或者L2范数。在知识图谱里越接近的实体,向量也就越相似,如图4所示。
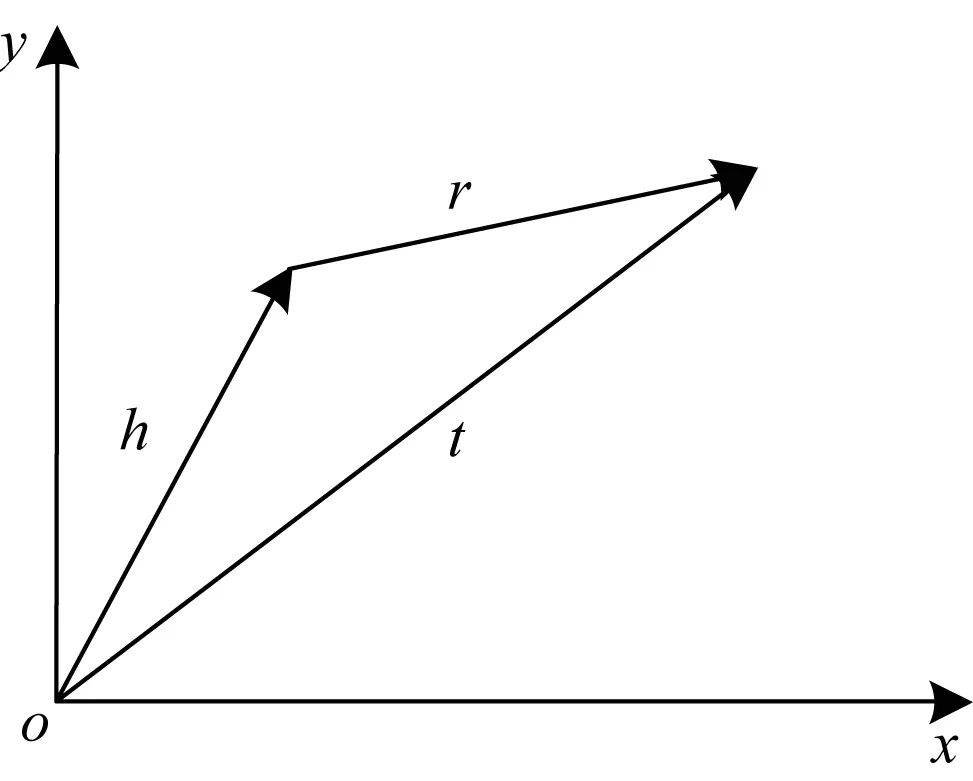
图4 TransE模型
由于TransE算法选择欧氏距离计算损失函数,因此本文采用同等范数的欧氏距离对实体进行相似性度量。其中,选择的欧氏距离的范围为[0,∞),相似性度量范围为[0,1]。对于A和B两个实体向量,通过数学变换使两个值域一一对应,最终的语义相似性度量公式如式(7)所示。
(7)
从上式中可以看出,当simsem(A,B)的计算的数值越接近1,实体向量A和B就越相似,即知识图谱里两者的关系就越紧密。相反,如果simsem(A,B)的数值为低,则意味着A和B关系越疏远,即语义相似度越低。
在利用语义相似性进行推荐时,使用和基于物品的协同过滤推荐类似的流程,根据式(7)生成了一个语义的物品-物品相似性矩阵,如表1所示。
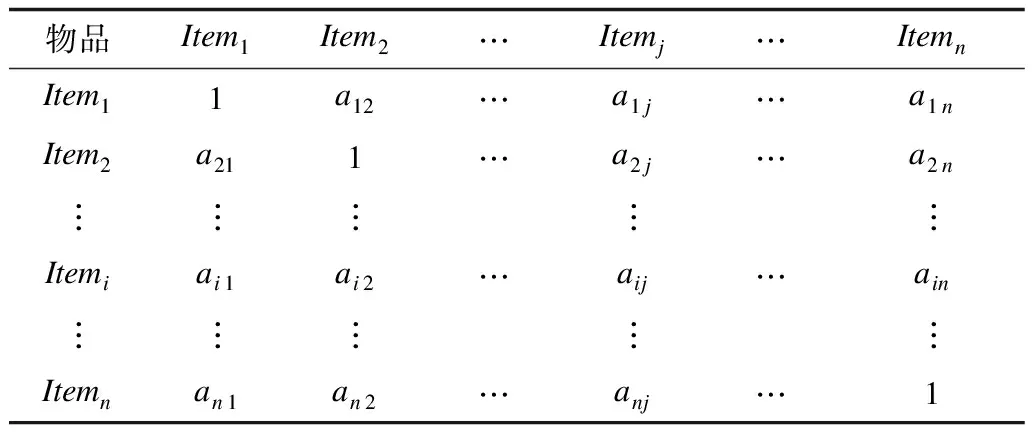
表1 语义的物品-物品相似性矩阵
在表1的相似性矩阵中,aij是序号为i的物品和序号为j的物品之间的语义相似性,通过式(7)计算而得,相似性矩阵元素满足条件aij=aji。矩阵第i行所构成的集合定义为序号i物品的语义近邻元素,简称为语义近邻。利用这种语义近邻,将基于协同过滤推荐得到的协同过滤近邻集进行语义融合替换,最终得到所需的推荐列表。
2.1.3 融合语义近邻

算法1融合语义近邻算法
输入协同过滤近邻集I,语义近邻集T
输出推荐集C
1.Set L=list(I),K=list(T)
2.for Li∈{Ll-n,Ll-n+1,…,Ll} do:
3. for Kj∈{K1,K2,…,Kn} do:
4. Li=Kj
5. end do
6.end do
7.Set C=set(L)
利用这一过程得到了最终的推荐集C。
2.2 算法描述
结合图1的算法流程,描述本文算法如下:
算法2TransE-CF算法
输入物品-用户评分矩阵Rm×n,该物品所在领域的知识图谱KG
输出基于知识图谱表示学习的协同过滤推荐算法TransE-CF
2)将物品与知识图谱KG中的实体进行一一对应,得到一个实体对应表。
3)将知识图谱KG中的实体和关系分别转化为向量集E和R。
4)根据式(7)对第3)步得到的结果分别计算物品间的语义相似性simsem(A,B),生成语义的物品-物品相似性矩阵,并根据2.1.3节对其进行过滤,得到语义近邻集合。
5)利用第2)步的结果,选择融合比例,根据算法1对第1)步生成的潜在推荐物品和第4)步所生成的语义近邻集合进行融合替换,得到最终推荐所需的物品集合推送给用户。
3 实验设置及结果分析
3.1 数据集
本节主要针对上述已提出的TransE-CF算法的有效性进行实验与分析,其中实验数据集为加州大学圣迭戈分校提供的Amazon的电影评分数据。该数据集为Amazon的商品评分及其元数据。对每条数据记录而言,主要描述了不同用户对电影的评分,分值从1分到5分逐渐增高,分别对应于用户对电影的差评到好评。同时,使用metadata将每条记录中电影的Amazon编号asin与知识图谱里该部电影的名字所表示的电影实体一一对应。
在知识图谱的数据集选择方面,本文选用了2012-11-09版本的Freebase中的电影本体。该电影本体数据主要包括了电影、导演、演员等本体对象。为了将Freebase提供的多个本体对象进行融合,本文用实体的名称替换了Freebase自身的id,提取出所需要的实体和关系。同时,为了降低噪声数据的影响,选择了Freebase中1979年以后发布的电影与Amazon评分进行匹配,并筛选去除了出现次数少于3次的关系,最终得到“genre” “starring_actor”等总共20个知识图谱的语义关系。
同时,为了使得Amazon评分数据和Freebase更好地匹配,本文对电影名称进行了进一步的处理。由于知识图谱采用的是无监督或者是半监督的关系抽取手段[21],因此Freebase中的电影名称抽取结果受限于该处理手段,存在物品名称和本体实体名称字面无法完全匹配的问题。例如,存在有的电影使用罗马数字II,而有的使用阿拉伯数字2。此外,例如电影Here Comes the Groom(1934)和电影Here Comes the Groom实质上是同一部电影但由于物品版本号的不同,造成Amazon电影名和Freebase电影本体的名称匹配时无法完全对应。
针对上述问题,本文采用了编辑距离和字符串规则匹配相结合的方式对电影名称进行了版本号删除等数据预清洗工作。通过编辑距离算法对原数据进行字符串字面相似性识别矫正,得到了较好的清洗结果。经过最终处理得到包括672 910项用户数据和41 255部电影数据,以及20个语义关系的实验数据集。本文对该评分数据集进行了划分,其中80%作为训练集,20%作为测试集,训练集用于构建评分矩阵,测试集用于测试算法性能。
3.2 评价指标
对于推荐系统算法推荐的结果,使用3个指标对其进行分析:准确率(Precision),召回率(Recall),F值(F-measure)。这3个指标可以从混淆矩阵中导出,如表2所示。

表2 混淆矩阵
根据混淆矩阵,有公式如下:
召回率(Recall):
(8)
准确率(Precision):
(9)
F值:
(10)
召回率反映了被推荐系统所推荐的物品占用户真正喜欢的物品的比重。准确率反映了推荐系统的推荐水平,能将用户喜欢的物品推荐给用户,而用户不喜欢的物品则不推荐。F值是准确率和召回率的加权平均,均匀地反映了推荐效果。
3.3 实验结果分析
实验硬件处理器型号为Intel(R) Core(TM) i7-6700,内存为8 GB;实验软件环境为Python 3.5。
3.3.1 混合比例的调整确定
本文所提出的算法中可调节的参数为两者的融合比例,在融合比例取不同值时,所取得的推荐效果也有所不同。选取Top-k的邻居数k=100,表示学习嵌入为200,实验从完全使用语义进行推荐(0∶10)到完全使用协同过滤进行推荐(10∶0)分别取值,图5~图7分别为准确率、召回率和F值曲线。对于每一组实验,均循环10次并取其平均值。

图5 k=100时的召回率
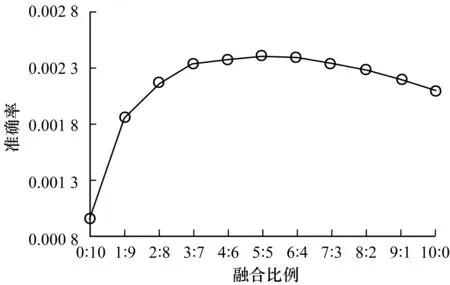
图6 k=100时的准确率
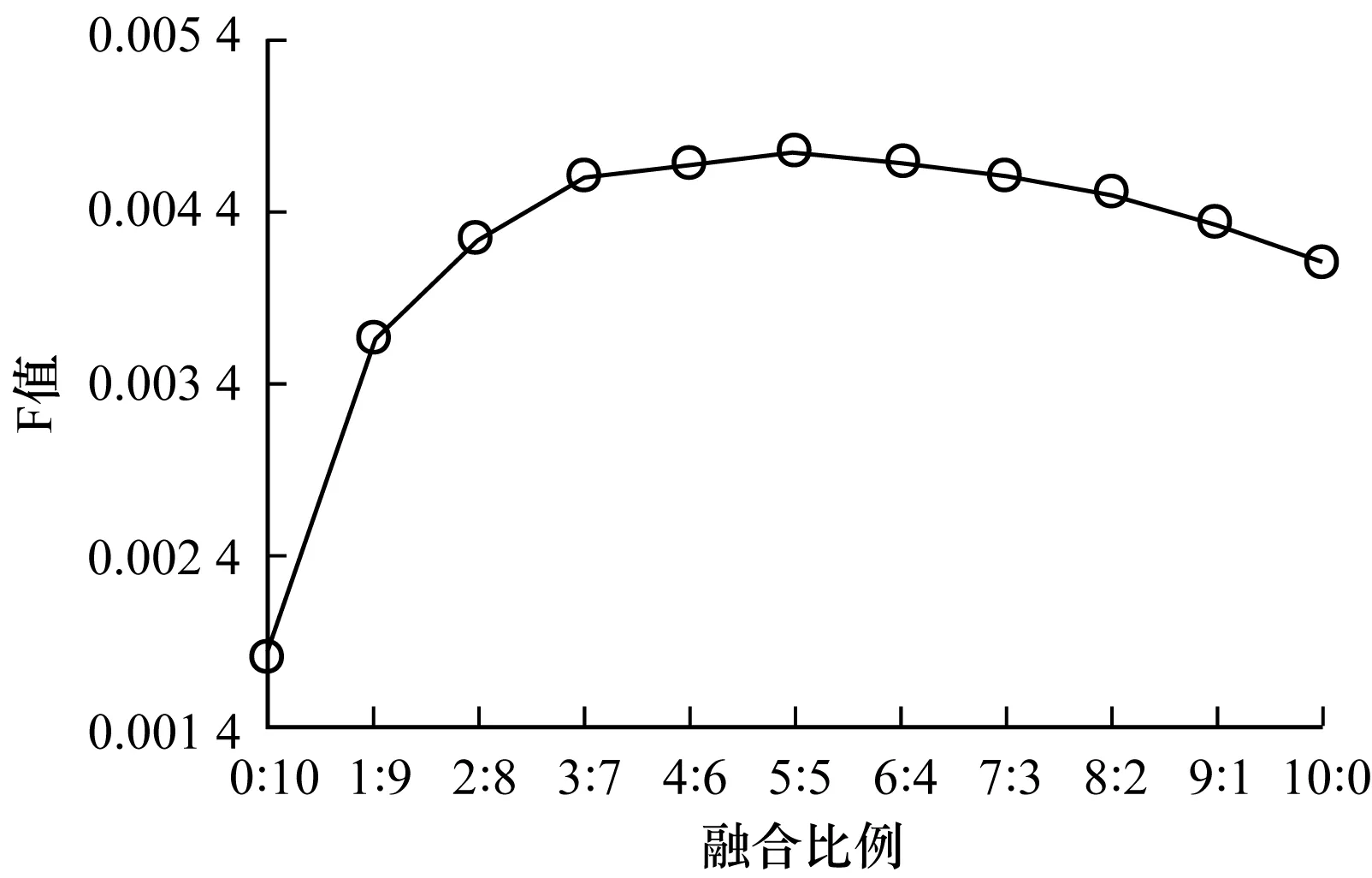
图7 k=100时的F值
从图5~图7可以看出,随着融合比例的提高,准确率、召回率和F值均有所提升,并在比例为5∶5时达到了顶峰。对于k=100的情况,融合比例为5∶5时效果最好。
3.3.2 表示学习的嵌入维度比较
知识图谱表示学习是将知识图谱嵌进一个低维的空间里,对于不同维度会有不同的效果。选取100维~500维分别进行实验,对于每一组实验,均循环10次并取其平均值。
从图8~图10可以看出各个维度对推荐效果的影响。从图中得出,在选取200维时取得最佳。
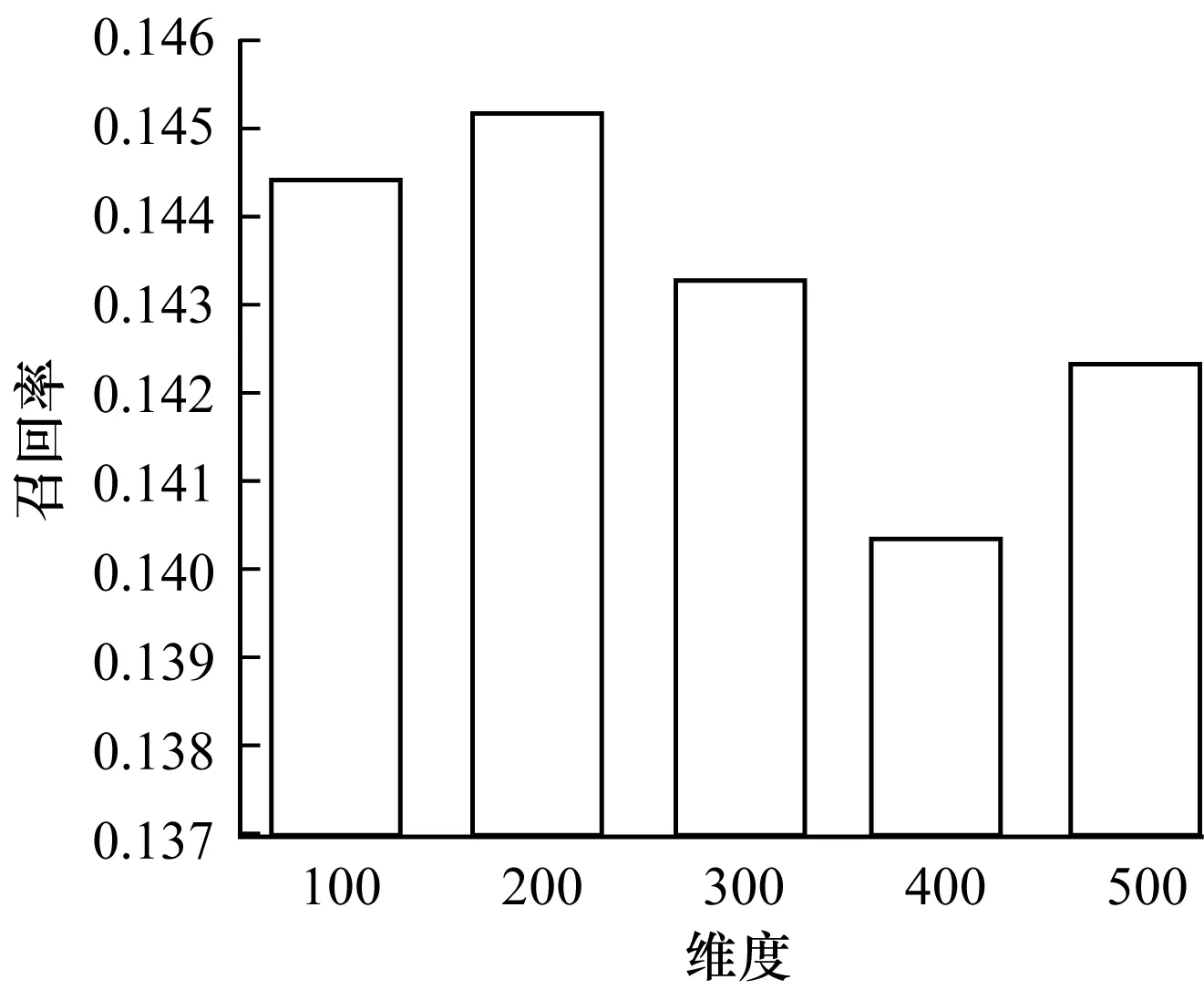
图8 不同维度的召回率

图9 不同维度的准确率
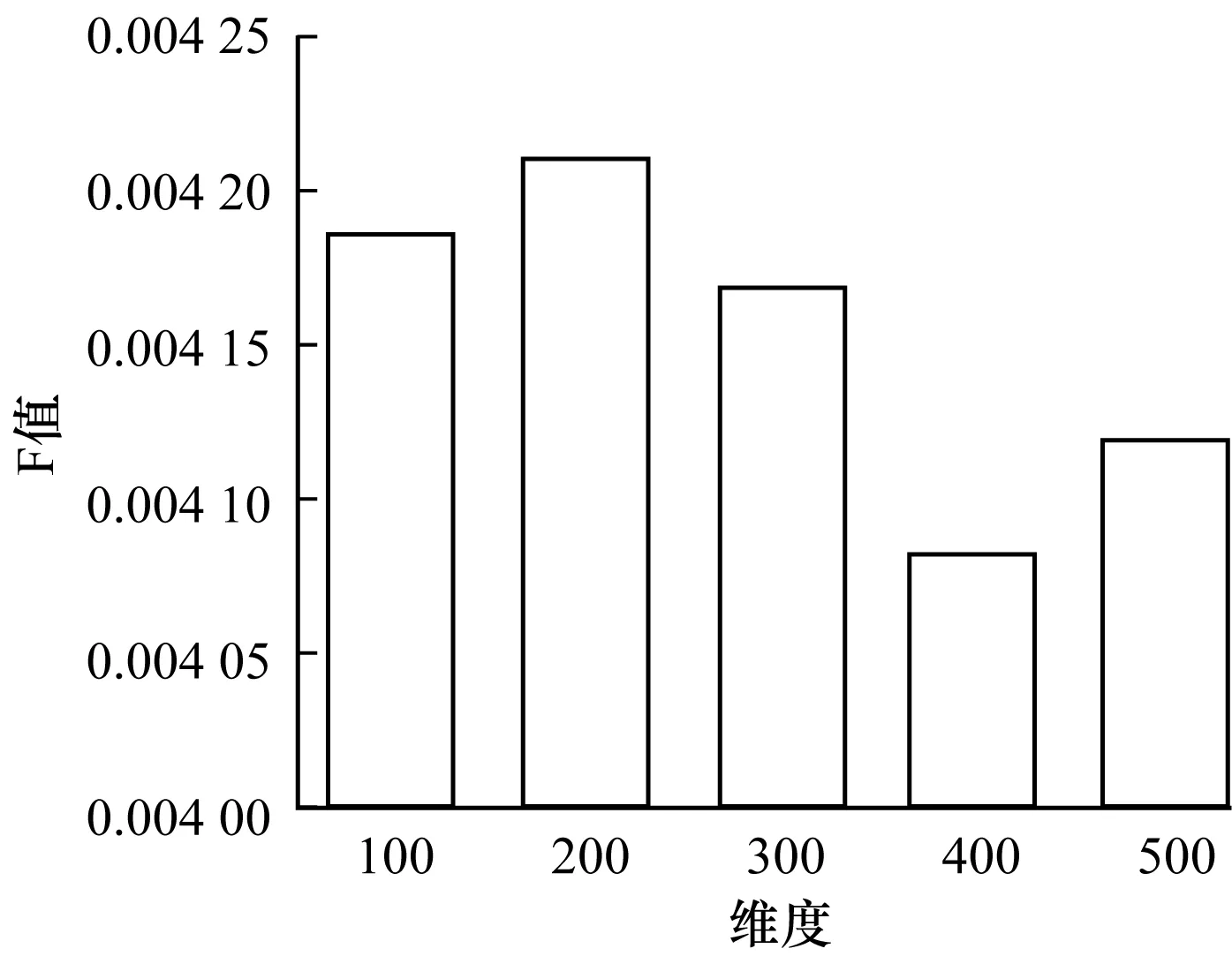
图10 不同维度的F值
3.3.3 算法比较
这里选取F值最高的比例作为代表,与其他协同过滤推荐算法进行比较。选取嵌入维度为200,k近邻数分别为60、80、100、120。对于每一组实验,均循环10次并取其平均值。
从图11~图13可以看出,本文提出的基于知识图谱表示学习的协同过滤推荐算法,优于协同过滤推荐算法,利用语义信息可以在一定程度上对协同过滤推荐算法进行改进,在召回率、准确率和F值上均有所提升,可以在语义上弥补基于物品的协同过滤算法的不足。
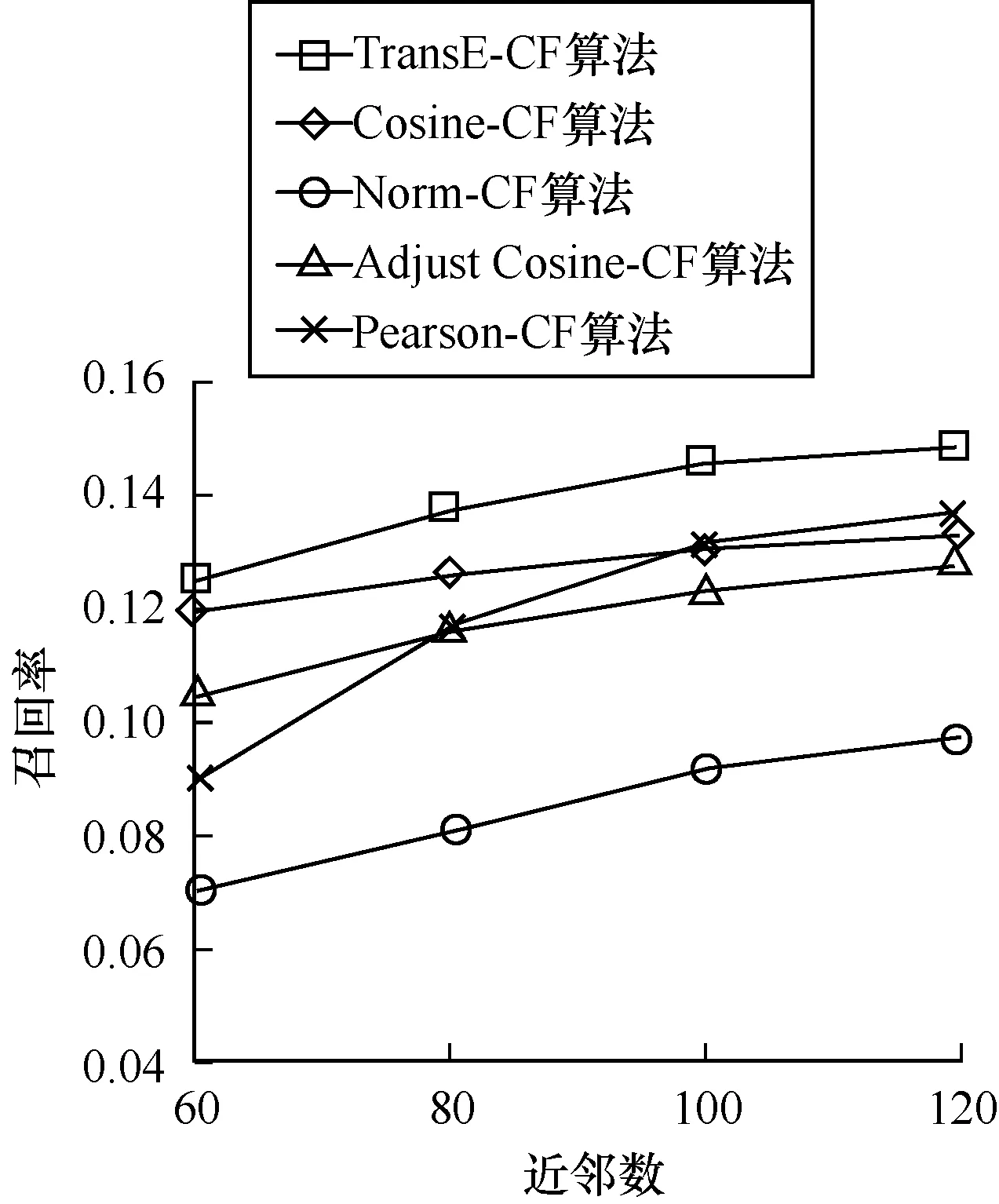
图11 不同k值的召回率
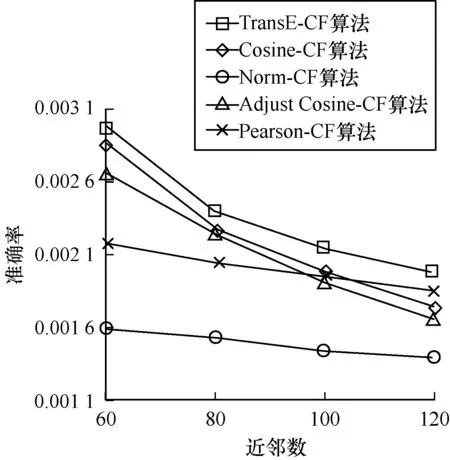
图12 不同k值的准确率
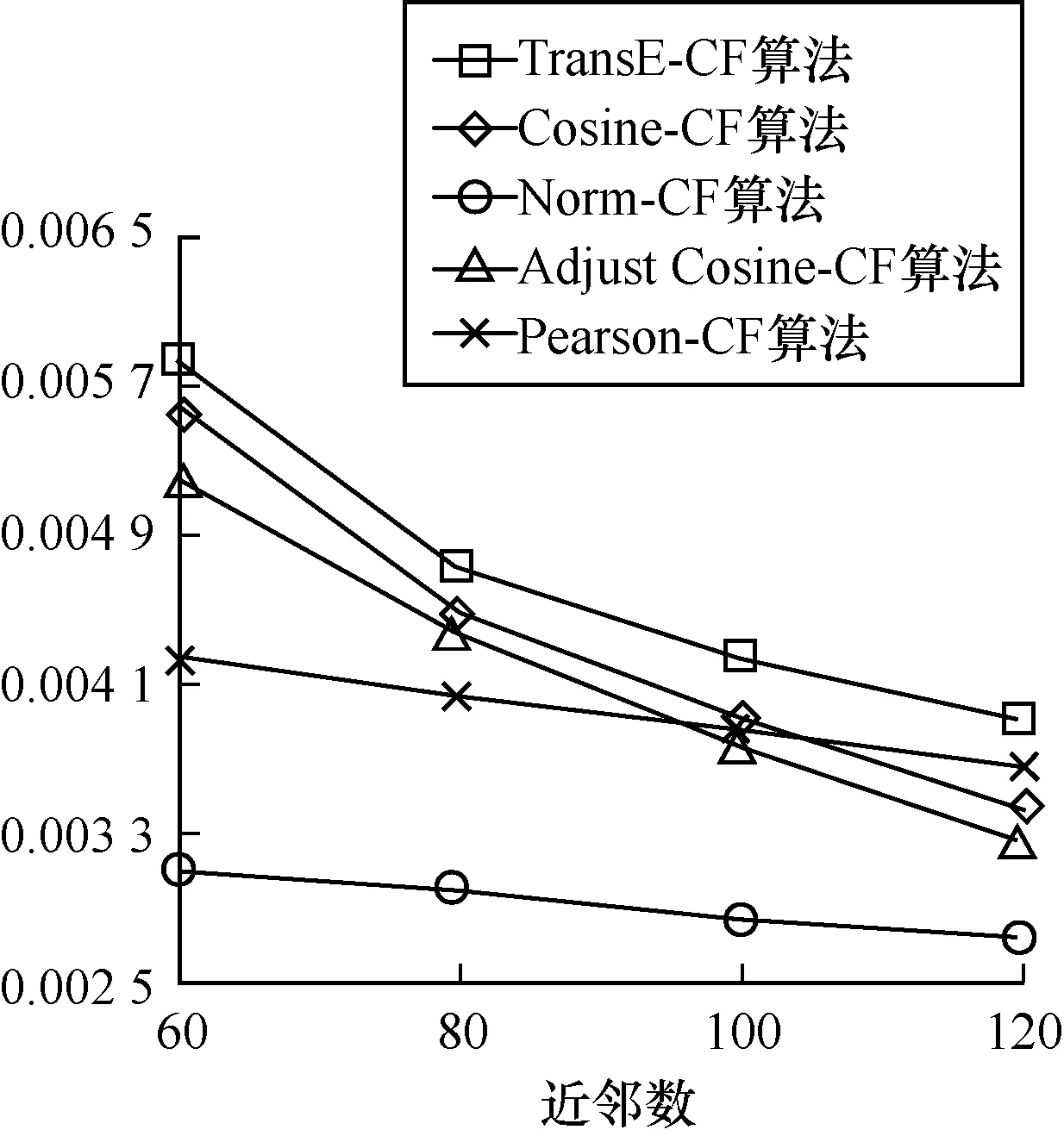
图13 不同k值的F值
4 结束语
本文提出了一种基于知识图谱表示学习的协同过滤推荐算法,既利用了物品本身内在的语义信息,又使用了物品外在的评分矩阵,能够更加全面地反映物品的属性。算法通过知识图谱表示学习将实体嵌入到低维空间里,计算实体间的语义相似性,并将其融入到推荐系统中,在语义的层面上增强了协同过滤推荐的效果,解决了协同过滤推荐未考虑语义的问题,提高协同过滤推荐的精度;同时又利用语义的信息,在一定程度上解决了冷启动问题。实验表明,基于知识图谱表示学习的协同过滤推荐算法能够提高推荐算法的效果。下一步将尝试把该算法应用于电影本体以外内容进行推荐,并进一步优化推荐性能。
[1] 李文海,许舒人.基于Hadoop的电子商务推荐系统的设计与实现[J].计算机工程与设计,2014,35(1):130-136.
[2] SONG Bo,GAO Jie.The Enhancement and Application of Collaborative Filtering in e-Learning System[C]//Proceedings of International Conference in Swarm Intelligence.Berlin,Germany:Springer,2014:188-195.
[3] GARCIN F,ZHOU K,FALTINGS B,et al.Person-alized News Recommendation Based on Collaborative Filtering[C]//Proceedings of International Joint Con-ferences on Web Intelligence and Intelligent Agent Tech-nology.Washington D.C.,USA:IEEE Press,2012:164-173.
[4] 文俊浩,袁培雷,曾 骏,等.基于标签主题的协同过滤推荐算法研究[J].计算机工程,2017,43(1):247-252,258.
[6] 杨兴耀,于 炯,吐尔根·依布拉音,等.融合奇异性和扩散过程的协同过滤模型[J].软件学报,2013,24(8):1868-1883.
[7] 杨 武,唐 瑞,卢 玲.基于内容的推荐与协同过滤融合的新闻推荐方法[J].计算机应用,2016,36(2):414-418.
[8] BOLLACKER K,EVANS C,PARITOSH P,et al.Freebase:A Collaboratively Created Graph Database for Structuring Human Knowledge[C]//Proceedings of ACM SIGMOD International Conference on Management of Data.New York,USA:ACM Press,2008:1247-1250.
[9] BIZER C,LEHMANN J,KOBILAROV G,et al.DBpedia——A Crystallization Point for the Web of Data[J].Web Semantics Science Services & Agents on the World Wide Web,2009,7(3):154-165.
[10] ZHANG Zijian,GONG Lin,XIE Jian.Ontology-based Collaborative Filtering Recommendation Algorithm[C]//Proceedings of International Conference on Brain Inspired Cognitive Systems.Berlin,Germany:Springer,2013:172-181.
[11] ZHANG Fuzheng,YUAN N J,LIAN Defu,et al.Collaborative Knowledge Base Embedding for Recom-mender Systems[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2016:353-362.
[12] BORDES A,USUNIER N,GARCIA-DURAN A,et al.Translating Embeddings for Modeling Multi-relational Data[C]//Proceedings of International Conference on Neural Information Processing Systems.New York,USA:ACM Press,2013:2787-2795.
[13] SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based Collaborative Filtering Recommendation Algori-thms[C]//Proceedings of International Conference on World Wide Web.New York,USA:ACM Press,2001:285-295.
[14] BELL R,KOREN Y,VOLINSKY C.Modeling Relation-ships at Multiple Scales to Improve Accuracy of Large Recommender Systems[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2007:95-104.
[15] MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed Representations of Words and Phrases and Their Com-positionality[C]//Proceedings of International Conference on Neural Information Processing Systems.New York,USA:ACM Press,2013:3111-3119.
[16] SOCHER R,CHEN Danqi,MANNING C D,et al.Reasoning with Neural Tensor Networks for Knowledge Base Completion[C]//Proceedings of International Conference on Neural Information Processing Systems.New York,USA:ACM Press,2013:926-934.
[17] NICKEL M,TRESP V,KRIEGEL H P.A Three-way Model for Collective Learning on Multi-relational Data[C]//Proceedings of the 28th International Conference on Machine Learning.Berlin,Germany:Springer,2011:809-816.
[18] WANG Zhen,ZHANG Jianwen,FENG Jianlin,et al.Knowledge Graph Embedding by Translating on Hyperplanes[C]//Proceedings of the 28th AAAI Conference on Artificial Intelligence.Berlin,Germany:Springer,2014:1112-1119.
[19] LIN Yankai,LIU Zhiyuan,ZHU Xuan,et al.Learning Entity and Relation Embeddings for Knowledge Graph Completion[C]//Proceedings of the 29th AAAI Con-ference on Artificial Intelligence.Berlin,Germany:Springer,2015:2181-2187.
[20] 刘 康,张元哲,纪国良,等.基于表示学习的知识库问答研究进展与展望[J].自动化学报,2016,42(6):807-818.
[21] 肖 明,邱小花,黄 界,等.知识图谱工具比较研究[J].图书馆杂志,2013,32(3):61-69.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
少先队活动(2020年12期)2021-01-14
河北画报(2020年8期)2020-10-27
开放教育研究(2020年2期)2020-03-31
中成药(2017年3期)2017-05-17
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
领导科学论坛(2016年9期)2016-06-05
浙江大学学报(工学版)(2016年2期)2016-06-05
长江学术(2016年4期)2016-03-11
