
一种基于文本挖掘的铁路基础设施设备风险隐患识别模型
2018-03-01 18:57张秋艳
铁路计算机应用 2018年2期
李 擎,张秋艳,白 磊,2
(1.北京交通大学 交通运输学院,北京 100044;2.北京易华录信息技术股份有限公司,北京 100043)
随着铁路信息化的不断推进,管理者积累了大量与安全生产问题相关的检查数据。这些数据全面记录了铁路日常生产过程中发生的安全问题,但大部分都是长文本格式,管理者难以快速、高效理解与挖掘这些数据中隐藏的新的知识。
文本挖掘是指将可理解的、事先未知的、最终可用的知识从海量文本数据中抽取出来的过程,同时利用这些知识更高效地组织信息便于今后借鉴[1]。文本挖掘技术在生物学、医学、情报分析、人文科学等领域应用广泛[2-6]。
本文在分析铁路安全生产问题数据基础上,提出一种基于文本挖掘的铁路基础设施设备风险隐患识别模型(TMBI-RIR,Text Mining Based Identi-fication Model for Railway Infrastructure Risk),深入分析记录工务、电务和供电专业的设备质量问题的长文本形式的数据,确定铁路存在风险隐患的薄弱设备类型与易发病害类型,提升管理者安全风险管理水平。
1 铁路安全生产问题数据说明
1.1 安全生产问题数据表结构
原铁道部安全监察司的铁路安全检查管理信息系统已在全路推广应用多年,系统积累了大量的安全问题数据,其登录界面如图1所示。系统主要功能包括安全信息处理、安全信息查询、安全信息统计等,实现对铁路安全生产问题录入,班组、车间整改,铁路局、站段整改后复查的闭环管理,辅助管理者把握铁路日常生产中的安全风险隐患。

图1 铁路安全检查管理信息系统登录界面
系统中记录铁路安全生产问题的数据表结构见表1。其中,字段“大类”填写内容为通用、工务、电务、供电、车辆等,“字段类别”填写内容为设备质量、安全管理、现场作业、职工素质及其他。

表1 铁路安全生产问题数据表结构
1.2 问题详情描述字段分析
如表1所示,数据表中,问题详情描述字段内容是以长文本形式存在的(340字符),该字段包含了较为丰富的信息,如设备类型、病害类型、病害发生位置、病害严重程度等信息。表2是问题详情描述字段填写内容样例。管理者难以从大量的长文本形式的数据中分析出与病害类型、设备类型、病害发生位置等相关的新知识,本文采用基于文本挖掘的铁路基础设施设备风险隐患识别模型(TMBIRIR),挖掘长文本形式的铁路基础设施设备质量问题详情描述数据中潜在的有价值信息,为管理者识别铁路基础设施风险隐患提供支持。
2 TMBI-RIR
TMBI-RIR 采用基于层叠隐马尔科夫(CHMM)的中文分词算法对长文本形式的设备质量问题详情数据进行分词处理,根据分词结果统计词频,确定铁路薄弱设备类型与易发病害类型,并对分析结果以词云图的方式进行直观、清晰展示,模型计算流程如图2所示。

表2 问题详情描述字段填写内容样例
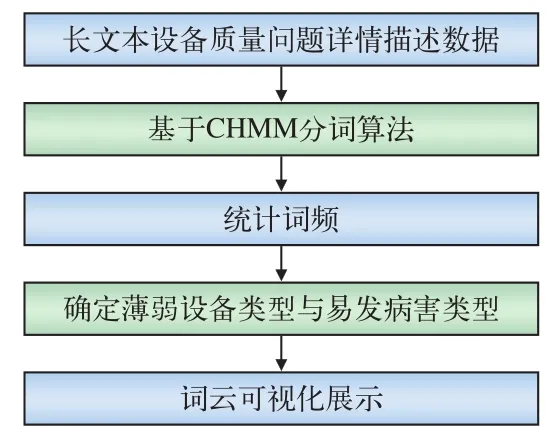
图2 模型TMBI-RIR算法流程图
2.1 记录设备质量问题的长文本形式数据分词
中文分词是指把一整段中文文字串切割成最小语义词条信息的过程[7]。采用CHMM中文分词算法,将记录设备质量问题的长文本形式数据切分成一个一个单独的词[8],其计算流程如图3所示。
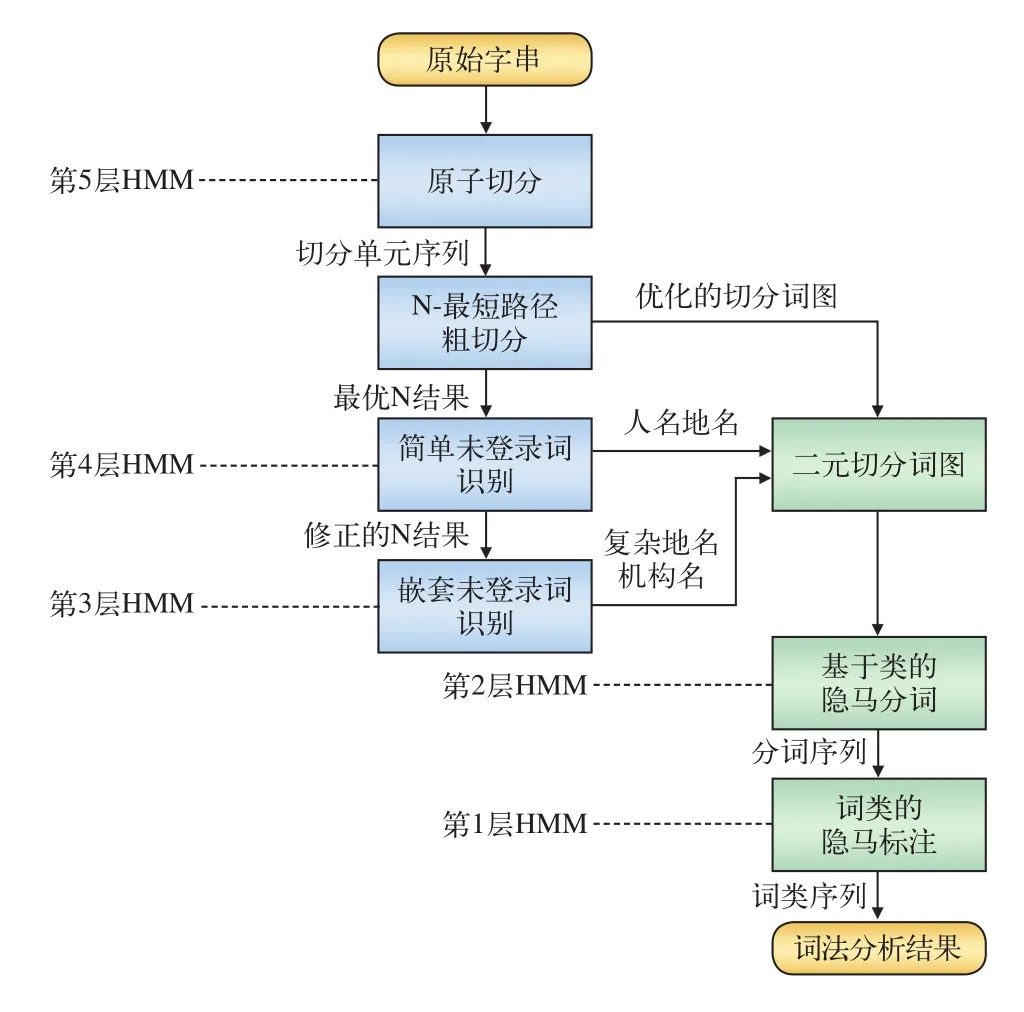
图3 基于CHMM分词算法的计算流程
原子切分是指将记录设备质量问题的长文本形式文字串切分为分词原子(如:单个汉字、标点或非汉字串等)序列。简单未登录词识别是指在上一步切分结果的基础上,利用一阶隐马尔科夫模型(HMM),识别出未登录词(如:线路名、车站名、管辖单位名等)。嵌套未登录词识别是指在上一步识别结果的基础上,利用一阶HMM,识别出嵌套了未登录词的复杂地名和机构名。基于类的HMM分词是指在识别出所有未登记词后,结合核心词典,利用一阶HMM,采用N-最短路径的切分排歧策略,对普通词和未登录词进行统一竞争和筛选,确定描述设备质量问题字符串的最终分词结果。词类的HMM标注是指在最终分词结果的基础上,利用一阶HMM,确定描述设备质量问题字符串中各单词的词性(如动词、名词)。
其中,基于类的隐马尔科夫分词算法(第2层HMM),见公式(1)。给定长文本形式设备质量问题字符串S,存在多种分词结果W=(w1,w2, …,wn),W∈ℑ ,C=(c1,c2,…,cn) 是分词结果W的词类别。分词序列W作为观测状态,对应的词类别C作为真实状态,依据隐马尔科夫算法,选取似然函数概率P(W)最大的分词结果W#作为最终的分词结果。W#可以通过Viterbi算法[9]得到。为计算方便,公式(1)可等价转化为公式(2)。其他层的隐马尔科夫HMM算法与之类似,不再重复论述。
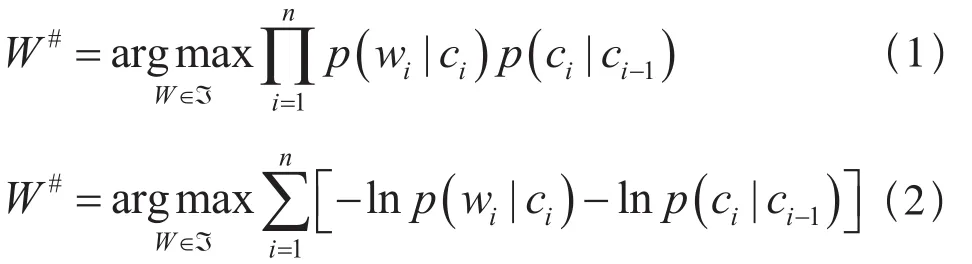
2.2 词频统计
词频统计是指计算每类单词在全部文档中出现的次数[10],单词的重要性一般是与它在文档中出现的频度成正比,使用较高频度的单词能较好地反映文本的特征。模型通过统计各类词的频度,找出哪些是高频词,确定出铁路基础设施易发病害类型、薄弱设备类型等。
2.3 词云可视化展示
词云是由单词组成的、形状类似云的彩色图形,是一种信息文本可视化技术[11]。每个单词的相对大小,由相应词频的高低决定,辅以多种色彩显示,直观反映单词重要性差异、展示关键信息。模型采用词云可视化技术,对分析出的易发病害类型、存在风险隐患薄弱设备类型进行直观、清晰展示。
3 实例验证
本实例收集整理了兰州铁路局铁路安全检查管理信息系统中的2012年1月~2016年4月期间4 662条描述工务、电务和供电专业的铁路基础设施设备质量问题的数据,验证TMBI-RIR的有效性。利用R编程语言[12]实现对模型的构建和求解。R是一个拥有强大统计分析及作图功能的数据分析工具,整合了包含大多数经典统计方法与最新技术的工具包。问题详情描述长文本形式数据的分析结果见表3和图4。

表3 铁路设备质量问题数据中前10个较高词频的单词

图4 铁路设备质量问题词云图
3.1 存在风险隐患的薄弱设备
分析表3和图4可知,存在质量问题的设备类型按照词频由高到底排列依次是:道岔、钢轨接头、轨枕、钢轨小腰、螺栓、扣件等。因此,存在风险隐患的薄弱设备为道岔、钢轨接头、轨枕等。
3.2 易发病害类型
根据表3和图4,易发病害类型按照词频从高到底排列依次是:高低、水平、轨距、三角坑等。因此,易发病害类型为为轨道不平顺的高低、水平、规矩等。
根据上述分析结果,存在风险隐患的薄弱设备均是工务专业的铁路基础设施设备。铁路管理者需对道岔、钢轨接头、轨枕等设备进行重点监控,对轨道不平顺中的高低、水平、轨距超限等病害加强管理。
4 结束语
为分析大量的记录铁路基础设施设备质量问题的长文本形式数据,本文提出了一种基于文本挖掘的铁路基础设施设备风险隐患识别模型(TMBI-RIR),通过统计各类单词出现的次数,确定出铁路存在风险隐患的薄弱设备类型及易发病害类型,并利用词云图对分析结果进行了可视化展示。作者采用兰州铁路局近5年的4 662条铁路基础设施设备质量问题数据,对提出模型的有效性进行了验证。研究成果可为铁路安全风险管理、养护维修决策提供有效的支持。
[1]Berry M W, Castellanos M. Survey of text mining II: Clustering,classification, and retrieval[M]. New York: Springer, 2008.
[2]陈勇跃, 田文芳, 吴金红. 主题领域研究热点跟踪及趋势预测的可视化分析方法研究[J]. 情报理论与实践,2017(6):117-121.
[3]陈 苗,刘 超,庄俊玲,等. 基于文本挖掘的临床带教评价分析[J]. 中国卫生统计,2017(1):59-60.
[4]史玉珍,吕琼帅. 基于进化模糊规则的Web新闻文本挖掘与分类方法[J]. 湘潭大学自然科学学报,2016,38(2):99-103.
[5]蔡 溢,杨 洋,殷红梅. 基于ROST文本挖掘软件的贵阳市城市旅游品牌受众感知研究[J]. 重庆师范大学学报:自然科学版,2015(1):126-134.
[6]杨张博,高山行. 基于文本挖掘和语义网络方法的战略导向交互现象研究—以生物技术企业为例[J]. 科学学与科学技术管理,2015(1):139-150.
[7]韩冬煦,常宝宝. 中文分词模型的领域适应性方法[J]. 计算机学报 ,2015,38(2):272-281.
[8]刘 群, 张华平,俞鸿魁,等. 基于层叠隐马模型的汉语词法分析[J]. 计算机研究与发展,2004(8):1421-1429.
[9]Viterbi A J. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm[J]. IEEE Transactions on Information Theory, 1967,13(2):260-269.
[10]郭曙纶. 汉语语料库应用教程[M]. 上海:上海交通大学出版社,2013.
[11]Afzal S, Maciejewski R, Yun J, et al. Spatial Text Visualization Using Automatic Typographic Maps[J]. IEEE Transactions on Visualization & Computer Graphics, 2012,18(12): 2556-2564.
[12]R Core Team. R: A Language and Environment for Statistical Computing[EB/OL].[2014-04-09].http:// www.R-project.org/.
猜你喜欢
江苏安全生产(2022年9期)2022-11-02
江苏安全生产(2022年8期)2022-11-01
大众科学(2022年8期)2022-08-26
江苏安全生产(2022年6期)2022-07-29
内江科技(2021年8期)2021-09-13
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中国修辞(2017年0期)2017-01-31
读者·校园版(2015年7期)2015-05-14
