
机器学习分类算法在糖尿病诊断中的应用研究
2018-02-27 13:29吴兴惠周玉萍邢海花,龙海侠
电脑知识与技术 2018年35期
吴兴惠 周玉萍 邢海花,龙海侠
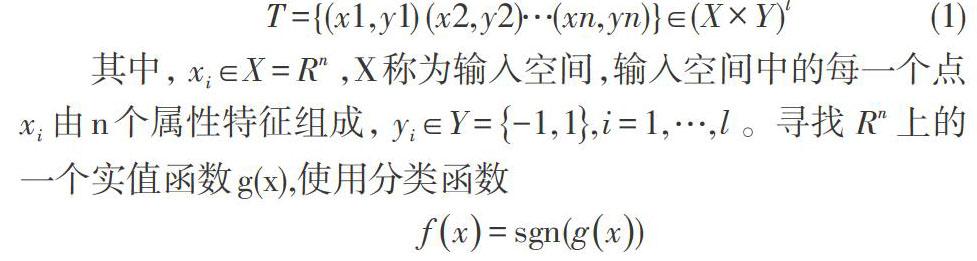
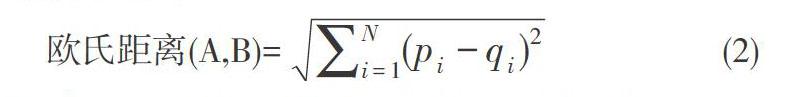
摘要:机器学习技术在疾病诊断等智能决策问题中起着至关重要的作用,该文主要介绍了机器学习中决策树、随机森林、支持向量机和k近邻算法,并将这四种算法建立的模型运用在糖尿病诊断上,通过参数的优化建立各自的模型,比较这四种模型对医学中的糖尿病数据的诊断价值。然后通过十折交叉验证方法比较这四种模型在该数据上的ROC值,选择最优的模型对糖尿病数据进行分析预测,结果表明,随机森林算法更适合糖尿病数据的预测。
关键词:机器学习;分类算法;糖尿病; 预测
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)35-0177-02
1 概述
近年来,随着人工智能与机器学习的不断发展[1-4],针对医疗智能诊断的研究工作越来越多,更多学者将机器学习技术用在医疗领域[7-10]。机器学习将医学知识的信息自动学习,归纳其中的规则,自己建立模型,然后进行预判。所以机器学习在医疗领域中可以起到的作用至关重要。目前糖尿病已经逐渐发展成为发病率比较最高的危害人类健康的疾病之一,对可能导致其的风险因素因素进行预测研究[5]。并且糖尿病还会大大增加其他疾病的发病概率,比如高血压、血脂异常、中风、眼疾和肾脏疾病。糖尿病及其并发症的医疗成本也是非常巨大的。因此早期的诊断与治疗是提高糖尿病的治愈率关键。
本文运用了机器学习算法中的随机森林、支持向量机、KNN、决策树四种分类算法[1-8]对糖尿病数据进行了数据进行分析,通过参数的选择建立各自比较好的模型,在选取参数时,选取测试集准确率较高的参数,作为建模最终选用的参数.并运用十折交叉验证的方法对四种算法进行准确率或误判率的比较,选择出判别此医疗数据最好的算法进行预测。
2 机器学习算法
2.1 随机森林
2.1.1 随机森林(Ramdom Forests,RF)原理
随机森林由Leo Breiman提出的一种基于 CART 决策树的组合分类器[1]。RF是一种组合分类器,由若干树形分类器[{hs(x,θk),k=1,…}]构成,其中x为输入向量,[θk]为独立同分布的随机向量,由每个树形分类器为x最可能的分类投一票,得票最多的分类结果为最终输出。随机森林可以处理的属性是离散的变量,也可以是连续变量,属性是离散的变量用ID3算法,连续的变量用C4.5算法。
2.1.2 随机森林构建
随机森林的构建主要包括产生训练集,选出分裂点,重复构建分类回归树以及投票,其步骤如下:
(1) 应用bootstrap法有放回地随机抽取N个新的自助样本集来构建N棵决策树,每次不被抽中的样本集组成了N个袋外数据(Out of Band,OOB)。
(2) 在每个内部节点处从M个特征中随机挑选m个特征(m<M),从这m个特征中按照节点不纯度选出最佳的分裂方式对该节点进行分裂。这些决策树均不进行剪枝。
(3) 集合 n多个决策树的预测结果,根据投票的方式取票数最高的类别作为新样本的类别。
在随机森林构建过程中,自助样本集从原始的训练样本集中随机选取,用于每一个树分类器的形成,每一棵树所应用的变量是从所有变量中随机选取,每次将有约三分之一的数据未被抽中,这部分数据称为袋外数据,它被用来预测分类的正确率,对每次預测结果进行汇总得到错误率的 OOB 估计,然后评估组合分类器判别的正确率。随机森林用R语言软件包RandomForest来实现。需要设置三个主要的参数:随机森林决策树节点分支所选择的变量个数(mtry),模型中决策树的数量(ntree)及终节点的最小样本数(nodesize)。
2.2 支持向量机
支持向量机是建立在统计学习理论的 VC 维理论和结构风险最小原理基础上的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,已在众多领域得到了广泛的应用[6,8]。支持向量机的定义是,根据给定的训练集
[T={(x1,y1) (x2,y2)…(xn,yn)}∈(X×Y)l] (1)
其中,[xi∈X=Rn],X称为输入空间,输入空间中的每一个点[xi]由n个属性特征组成,[yi∈Y=-1,1,i=1,…,l]。寻找[Rn]上的一个实值函数g(x),使用分类函数
[fx=sgn(gx)]
推断任意一个模式x相对应的y值的问题为分类问题。
2.3 K近邻算法
它是根据测试集自变量观测值与训练集自变量观测值距离最近的k个点对测试集的因变量取众数来分类的。对于训练数据集{([yi,xi]),i=1……,L},这里[xi=(xi1,xi2,…,xip)T];代表自变量的值,最近邻的确定是基于所选择的距离函数。显然,有三个度量必须选择的:距离的定义、核函数以及k。距离的计算默认的是欧氏距离,也是特征空间中数据点的临近度的计算。其公式如下所示:
欧氏距离(A,B)=[i=1N(pi-qi)2] (2)
常用的核函数有矩形核、三角核、三权核、余弦核等。
K近邻中的k值选择对于算法至关重要,如果太小,得到的观测值会有很高的方差,太大的话,方差会减小,但偏差会变得不可接受,因此必须进行交叉验证以确定合适的k值[1]。
2.4 决策树算法
决策树是一种倒树结构,它由根结点、内结点、叶结点和边组成。决根节点是最上面的结点,叶节点是给出判断结论的节点,内部节点是相对概念。构造决策树的作用就是分类或者回归,本文研究的是分类,也就是目标变量类别和属性之间的关系。当关系构造出来以后,我们就可以对测试数据集的类别进行预测了。决策树的构建过程包括两个步骤:决策树的生成和生成树的剪枝。树的生成是按照一定的划分条件逐层分类至不可再分或不需要再分,充分生成树。而剪枝是先找出固定叶节点数下拟合效果最优的树,即局部最优模型,再比较各个叶节点数下的局部最优模型,最终选择出全局最优模型。决策树的常用算法是分类回归树CART和C4.5算法[8]。
3 实验结果与分析
本文的实验目的是用机器学习的以上几种算法建立模型,比较这几种模型在糖尿病数据集上得到的准确率,选择准确率高的模型作为该数据集的模型。所用的数据来自UCI数据集里的皮马印第安人糖尿病数据集,该数据集含有768样本,8个属性变量和1个标签变量.其中,标签值为1代表患糖尿病,标签值为-0表示未患糖尿病.这九个属性分别是怀孕次数,血糖值,血压值,皮脂厚度,胰岛素量、BMI,糖尿病遗传函数,年龄。通过对类别的统计发现,值为1的样本有500个,值为-1的样本有268个。
3.1 模型建立
本实验在R语言的R-Studio环境下进行。首先对原始数据进行清洗预处理,本数据集的缺失数据采用的是随机森林迭代法的missForest( )方法填补缺失值。并且按照70/30的比例划分数据,建立训练集和测试集。
随机森林建模有2个参数需要人为控制,一个是随机森林建模中构建决策分支时随机抽样的变量个数mtry,另一个是每次迭代生成的随机森林中决策树数量ntree。本次实验的数据共有9个变量,可通过遍历设定mtry参数1至8进行8次建模,求出每次的错误率,选取错误率最低的mtry取值。根据遍历结果,当mtry=7时,错误率达到最低,将模型错误率与决策数量的关系可视化可得ntree的值为118。
KNN建模的关键是选择合适的参数k,在本实验中采用的是交叉验证方法,使用caret包中的trainControl()函数,得到最优的参数k=15,得到测试集上的正确率是74%。
构建SVM模型,我们使用的是e1071包,对非线性模型,常用的核函数有多项式核函数、径向基核函数、Sigmoid核函数。实验中使用tune.svm函数选择调优参数,使用十折交叉验证对参数进行调优。最后,选择Sigmoid核函数作为最优的建模模型。
在决策树模型建模过程中用到了Xgboost包,首先先建立模型网格,用十折交叉验证方法来训练调优参数,得到最优的参数组合来建立模型,用xgb.train()函数创建模型,用information包中的函数找出使误差最小化的最优概率阈值,得到最优模型。
3.2 模型评估
对于以上模型的评价指标主要有以下几个:混淆矩阵(Confusion Matrix)、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、平方根误差(RMSE)、AUC(ROC曲线下面积)。
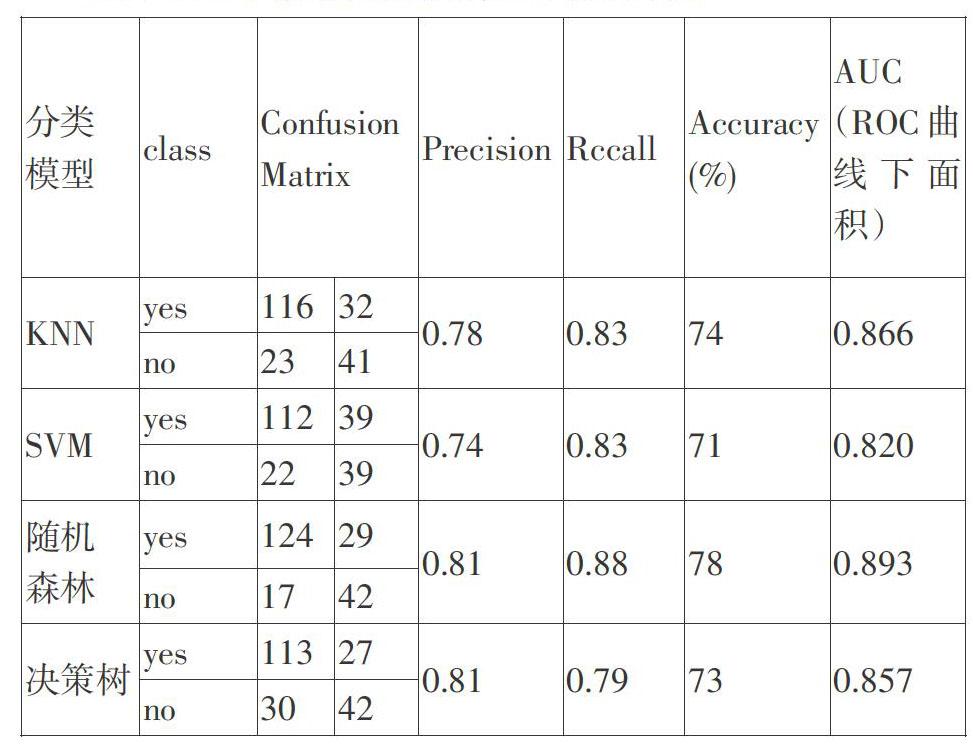
以下是基于糖尿病数据的分类结果比较:
[分类
模型 class Confusion
Matrix Precision Rccall Accuracy
(%) AUC(ROC曲线下面积) KNN yes 116 32 0.78 0.83 74 0.866 no 23 41 SVM yes 112 39 0.74 0.83 71 0.820 no 22 39 随机
森林 yes 124 29 0.81 0.88 78 0.893 no 17 42 决策树 yes 113 27 0.81 0.79 73 0.857 no 30 42 ]
本实验采用十折交叉验证预测得到AUC值。并纪录取值最大的一组,作为最优的训练集与测试集划分。使用最优划分构建线性分类器并预测。
从以上分析结果来看,在对糖尿病数据的预判上,随机森林模型的效果是这四种里最好的,其次是KNN和决策树,SVM的效果稍差些。
通過以上数据可以得出四种模型的误判率,其中,KNN的误判率为0.259,SVM的为0.287,随机森林的为0.217,决策树的为0.269。最后,选择误判率低、精确度高的随机森林模型作为糖尿病数据的预判模型。
4 结论
本文分别机器学习中随机森林、支持向量机、k近邻算法和决策树算法,并针对糖尿病数据分别应用这四种算法建立相应的模型,对模型的参数进行了优化,以靠近该算法的最佳模型。结果表明随机森林的平均准确率高于其他模型的,其误判率相对来说也是比较低的。最后通过十折交叉验证方法得到的ROC曲线图表明,随机森林模型在对糖尿病的预测精度高于其他模型。
对于运用机器学习对糖尿病的检测,最终选择了最好的随机森林模型.其次比较好的就是其次是KNN和决策树,SVM对糖尿病数据的预测效果稍差些。
参考文献:
[1] 杨帆,林琛.基于随机森林的潜在k近邻算法及其在基因表达数据分类中的应用[J].系统工程理论与实践,2012,32(4):815-825.
[2] 胡峰,程欣怡.基于粗糙集的多分类器集成学习算法[J].计算机工程与设计,2016,37(6):1610-1616.
[3] Xue Wang.Daowei Bi.Sheng Wang.Fault Recognitiong with Labeled Multi-category Support Vector Machine[J].IEEE Transaction on Neutral Computation,2007,24(4):45-50.
[4] R.Morpurgo,S.Mussi.An intelligent diagnostic support system[J].Expert Systems,2001,18(l):43-58.
[5] 梁丽军,刘子先,王化强.基于弹性网-SVM的疾病诊断关键特征识别[J].计算机应用研究,2015(5):1301-1304.
[6] 陈慧灵.面向智能决策问题的机器学习方法研究[D].吉林大学,2012.
[7] 宋辛科.基于支持向量机和决策树的多值分类器[J].计算机工程,2004.30(4):122-124.
[8] 刘振岩,王万森.机器学习在数据挖掘中的应用与发展[J].计算机工程与应用,2002(38):173-174.
[9] Sela. Rebecca J.,and Simonoff,Jeffey S.RE-EM trees:A data mining approach for Longitudinal and clustered data. Machine Learing,2012(86):169-207.
[10] 曾华军,张银奎.机器学习[M].北京:机械工业出版社,2003.
[通联编辑:光文玲]
猜你喜欢
黄河之声(2022年10期)2022-09-27
中老年保健(2022年5期)2022-08-24
中老年保健(2022年1期)2022-08-17
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中老年保健(2021年5期)2021-08-24
中老年保健(2021年11期)2021-08-22
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
