
结合卷积神经网络不同层的特征进行包类商品检索
2018-02-27 03:06骆正茂
计算机应用与软件 2018年1期
骆 正 茂
(浙江东方职业技术学院 浙江 温州 325011)
0 引 言
相对于传统的逛街购物方式,网上购物具有省时省力且物美价廉的优点。随着交易监督制度的完善、物流行业的发展以及电子商务的进步,网上购物越来越受到人们的认可,尤其是年轻人更愿意在网上购物。
包作为一种重要的商品,种类繁多款式多样,有着极大的购物需求。因此,如何让消费者在网购平台上快速地查找到称心如意的款式,是一个重要的问题。对于这个问题,现在各大电商主要采用的是基于关键字检索的方法。该方法的技术虽然比较成熟,但是依然存在一些问题。例如,在构建检索库的过程中,需要对每一种款式的包都做详细的文字描述,否则无法根据关键字进行搜索。但是,这是一项非常耗费人工的工作。并且,消费者有时候无法用文字准确地描述出自己想要购买的款式,基于关键字检索的方式就无法发挥其作用。因此,该策略具有极大的局限性。
基于内容的图像检索是计算机视觉领域的一个重要研究方向,能够很好地解决关键字检索中所面临的问题。首先,该方法对图像内容进行编码,将图像转换成一维向量表示。然后,通过距离度量等方式来比较向量之间的相似性,进而获得图像之间的相似性。因此,一个表征能力较优的向量计算方法成为衡量算法效果的一个关键因素。具有旋转不变性的局部描述子SIFT算法[1]的出现,以及Sivic和Zisserman关于词袋模型算法[2]的研究,极大地促进了基于内容的图像检索的发展。Fisher[3]和Vlad[4]所运用的聚合图像局部特征点算法使图像表征向量相对于词袋模型具有更好的表征能力。词袋算法和HE[5]算法相结合,也能够取得较好的图像检索结果。此外,一些几何验证方式[6-7]和扩展查询方法[8-9]的研究也提高了这种传统方法的效果。近年来,图形处理硬件(GPU)的计算能力的提升以及大规模图像训练集[10]的出现,都极大地促进了基于卷积神经网络的深度学习领域的发展。大量现有工作[11-13]证明,利用卷积神经网络训练得到的图像特征能够直接用来做图像的相似性检索并取得相对于传统算法更好的效果。因此,本文采用卷积神经网络来处理包类款式的图像检索问题。
针对卷积神经网络训练需要大量数据集的问题,本文整理了5 000幅有标签的包类款式图像训练集,同时提出了一种结合卷积神经网络不同层的特征来进行包类款式的图像内容检索方法。实验结果证明,本文方法能够较好地检索出相同或相似款式的包。
1 相关工作
基于卷积神经网络模型Alex_net,Krizhevsky[12]等获得了ImageNet LSVRC-2010大赛的冠军。从那时起,卷积神经网络吸引了越来越多学者的注意。随着研究的深入,卷积神经网络被应用于机器视觉的诸多领域,并且取得了很好的效果。在图像识别问题上,基于网络结构VGG_net[14]、 Google 公司的inception系列[15]以及何凯明等的Res_net[16]的卷积神经网络模型,分别获得了2014年、2015年、2016年的ImageNet 大赛的冠军。基于卷积神经网络的R-CNN[17-19]和YOLO[20-21]还能有效地解决通用目标检测问题。
Krizhevsky等[12]直接利用训练好的网络模型来提取图像特征,解决图像的相似性检索问题。在此基础上,Babenko等[11]将在待检索图像上微调好的网络模型的全连接层作为图像的特征。Azizpour等[22]采用max-pooling特定卷积层的方式进一步提高特定物体或者场景检索问题的效果。Babenko等[23]则提出运用sum-pooling结合白化归一化等方式来获得图像特征的表征能力。Yannis等[24]进一步提出了一种基于卷积层不同维度加权聚合的方法来计算图像特征表示。最近,一些方法基于图像局部区域和卷积层的特征结合来构建图像的特征表示,取得了不错的效果[25]。
虽然已经有很多关于卷积神经网络应用于图像检索方面的研究,但是基于卷积神经网络不同层的特征应用于包类款式的图像检索问题研究还比较少。一方面包类图像不是刚体比较容易受角度、亮度、尺度等因素影响。另一方面没有针对这类问题的公开数据集。因此文章提出了一种基于卷积神经网络不同层特征的方法来解决包类款式的图像检索问题,并且同时提供了一份包类款式数据集。
2 算法介绍
为了提高图像的表征能力从而增加检索的准确度。本文提出了一种结合卷积神经网络不同层的特征进行图像检索的方法。算法一共包括三个步骤,下面将对算法进行详细的介绍。
2.1 微调训练
卷积神经网络模型[12,14-16]拥有非常多的模型参数,因此具有很强的分类能力。同时,也因为其参数较多,所以需要大量的数据集进行训练。然而,很多任务往往并没有百万级的数据集。迁移学习被用来缓解这种问题。在大量数据集训练好的网络模型基础上,针对特定的任务利用少量的数据集进行微调训练,是一种简单且高效的迁移学习方法能够取得不错的效果。
为了能够得到较好表示包类商品图片的特征,算法首先利用少量数据集通过微调训练的方式得到一个对于包类商品图片分类能力较好的网络模型。图1中给出了一个微调训练的网络结构,固定或略微更新已经训练好的网络层的参数,重新训练修改后的网络层的参数。然后,通过优化多分类任务来训练网络模型的参数。定义损失函数如下:
(1)
式中:N表示训练集的图片数,pn表示第n张输入图片所有款式中的最大概率值,该值可以根据SoftMax计算得到,ln是第n张图片对应的款式标签。可以使用梯度下降法来优化该损失函数。

图1 微调网络结构
2.2 初次检索
图像检索主要包括建立特征索引库和近邻匹配两个步骤,接下来将围绕这两个方面来展开介绍。
第一步是建立特征索引库。假设检索库中共有M张图片,I表示其中一张图片。将I作为已经微调好的网络的输入,做一次前向传播操作。然后,提取网络中的高层特征和中层特征,通过特征拼接的方式将不用层的特征拼接在一起,做一次归一化操作得到图片I的一维特征向量VI,其向量维度用N表示。因此,对于检索库中的M张图片,分别采用这种方式提取图片的特征就可以得到一个M×N的矩阵。这个矩阵就是要建立的特征索引库。
第二步是近邻匹配。用q表示输入的查询图片。首先,计算出q的特征向量,计算方法与建立索引库时的方法相同。然后,计算出索引库中与向量Vq距离最相邻的k个向量,采用如下距离度量公式:
Sq,i=‖vq-vi‖2i∈{1,2,…,M}
(2)
简单地对所有的S值进行排序,即可获得k个距离最小的向量的索引,即所查询到的图像的索引。
2.3 扩展搜索
根据初次搜索查询到的k张图片的特征向量和查询图片的特征向量,求出这些向量的均值,得到一个新的特征向量。利用该特征向量再做一次搜索。这种利用初次查询的结果进行扩展查询的方式被证明能够取得一定的检索精度的提升[23-24],并且本文后面的实验部分也证明了该方法的有效性。
3 数据集和准确度度量
图2展示了训练集中的部分训练图片。训练集一共包含50种不同的款式,每个款式有100张图片。每种款式是由同一种款式的不同角度、亮度、背景、颜色的包类图片组成。测试集包含50种不同的款式(和训练集中的款式不同),每种款式包含20张图片。这些图片主要来源于蘑菇街网页上的商品展示区和用户评论区,因此数据集也考虑到了网页图片和现实图片的场景差异问题。

图2 部分训练集中的图片
本文采用查询结果的平均准确率来评估算法的准确度:
(3)
式中:a表示正确的查询结果,N表示所有的查询结果。
4 实验和分析
本文实验硬件环境为一台搭载英伟达GeForce GTX Titan-X显卡、英特尔i7处理器、32 GB内存的台式电脑,软件环境为Ubuntu14.04、开源深度学习框架Caffe[26]。本部分将通过实验来分析本文算法的可行性。
4.1 网络模型微调
随着深度学习研究的深入,近年来有许多网络结构被提出来。为了选择适合包类图片检索的网络结构,本文首先在ImageNet 数据集上进行网络模型的训练。然后在本文提供的检索测试集上通过计算mAP值来测量各种网络模型的检索效果。表1中给出了测量的结果,可以看出Google_net[15]比较适合本文的任务。因此,本文选择该卷积神经网络结构作为基础网络,在该网络上进行微调训练。
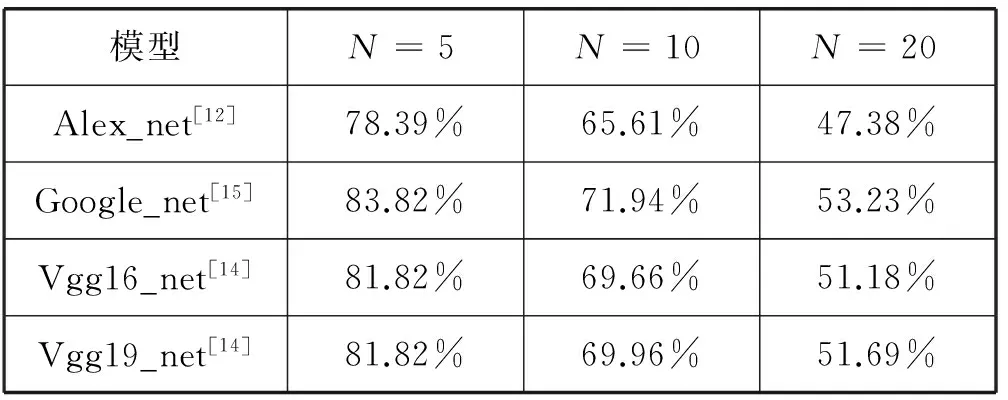
表1 各种网络模型在测试集上的检索效果比较
基于Caffe框架来进行网络的微调训练。首先,在原有的用来定义Google_net网络结构的train_val.prototxt文件中修改网络结构中loss1/classifer、loss2/classifer以及loss3/classifer层神经元的个数为50,同时修改对应的网络层的名称为loss1/classifer_modify、loss2/classifer_modify、以及loss3/classifer_modify。然后,在train_val.prototxt文件中分别设置这三层网络的学习率为lr=0.000 1,设置网络中其他层的学习率lr=0.000 01。最后在solver.prototxt文件中设置base_lr为0.001、weight_decay=0.000 4、momentum=0.9,采用增量梯度下降法来训练网络中的参数。该微调策略可以保证未修改层参数在原网络上略微改变的同时,加快修改层参数的学习速率。图3中给出了采用每层统一设置学习率和分层设置学习率的mAP值比较。从图中曲线可以看出,单独设置修改层的学习率的参数不仅能够加快学习速率,而且不易陷入局部最优的情况。
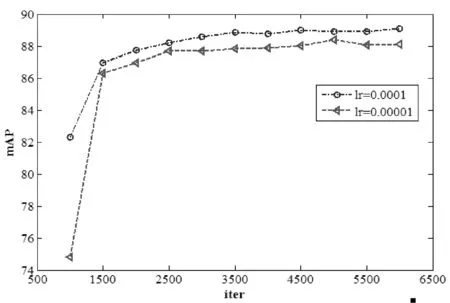
图3 统一设置学习率和分层设置学习率的结果比较
在训练的过程中,采用数据增强来扩充训练集。经过多次测试最终采用了图片镜像和改变亮度来扩充训练集。由原先的5 000张图片扩充到15 000张图片。经过数据增强训练得到的网络模型较未经数据增强的网络模型,在一方面能够防止过拟合,另一方面能够取得mAP值的提升,在本文测试集上约为1个点的提升。
4.2 结合Google_net网络不同层进行搜索
Google_net网络层数相比Alex_net和Vgg_net的层数较多。通过测试,提取网络的Inception_4c/1x1层的特征作为Middle-level特征,提取pool5/7x7_s1层的特征作为High-level特征能够取得较好的检索效果。由于Inception_4c/1x1是卷积层特征,接下来采用文献[22]的方法做了一次最大池化的操作得到一个128维的向量,然后对该向量做L2标准化,如图4所示。直接提取Pool5/7x7_s1层的特征得到一个1 024维的向量,同样做L2标准化。
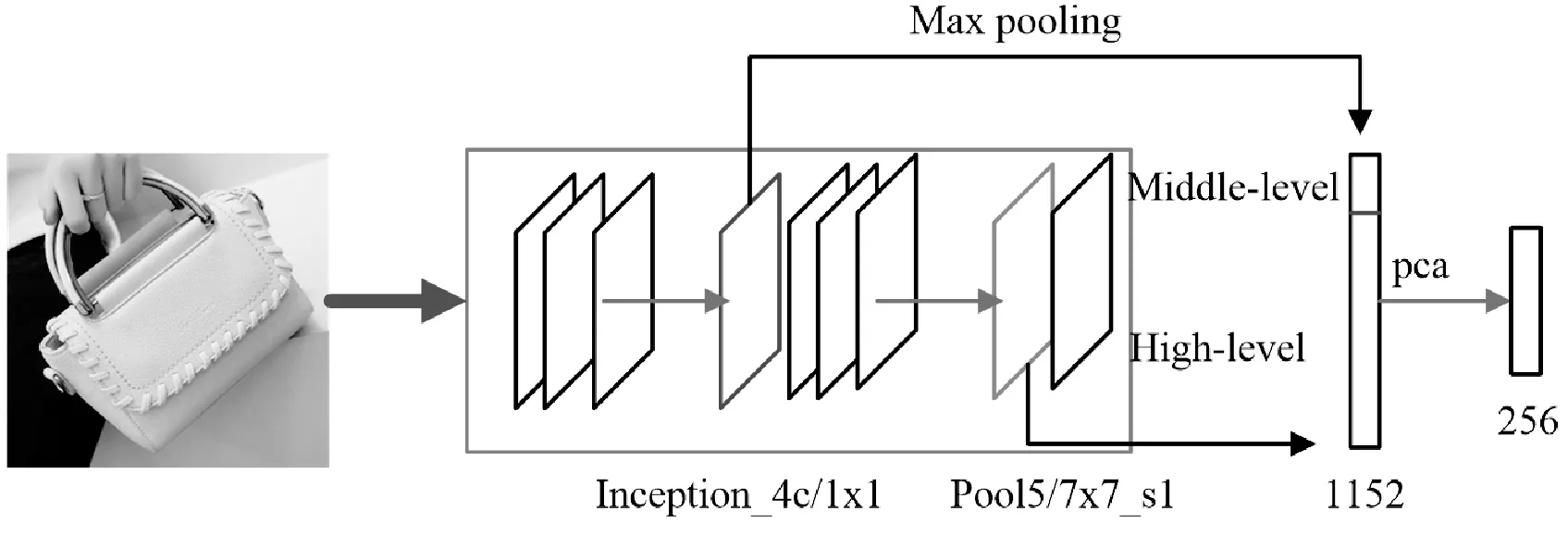
图4 提取输入图像的特征表示
直接拼接标准化后的两个向量,可以得到一个1152维的特征向量。由于该特征维度较大,为了节省存储空间,算法采用PCA来进行降维。表2中给出了在N=10时的不同降维维度的检索结果。从表2中可以发现,特征维度的降低并没有对检索效果带来很大的影响,还有可能出现结果变好的情况,这是因为PCA可能会减少一些不重要信息对检索带来的负面影响。因此,算法利用PCA把每张图片的特征向量从1152维降低到128维,能够在不影响检索精度的前提下极大地节约存储空间。

表2 PCA降维对检索结果的影响
将测试集中的所有图片通过上述方法获得图片的特征表示,并且建立索引表。然后,通过近邻搜索的方式进行查询,得到初次查询的结果。最后,根据初次查询的结果使用前5张最相近的图片的特征均值进行扩展查询,得到查询的最终结果。表3中列举了算法的在N=10时测试集上的使用多层和单层特征,以及扩展查询的检索结果比较。从结果中可以看出,通过结合不同层的特征能够带来检索精度的提升。并且扩展查询能进一步提高检索能力。

表3 不同算法的结果比较
表4给出了本文算法和一些传统的基于特征描述子的方法在N=10时测试集上的检索结果比较。从表中可以看出本文算法要比这些传统算法要好很多。这是因为有些包类商品表面比较光滑没有一些显著的局部信息,因此采用sift这种局部描述子和聚类算法相结合的方式就很难发挥其作用。

表4 和传统方法的结果比较
图5中给出了部分图片的搜索结果,左边第一列图片是输入的查询图片,右边是查询的结果。

图5 部分查询结果
该实验部分充分证明算法的有效性。表1中首先给出了基于文献[22]中直接利用在ImageNet数据集上训练好的网络来提取特征的方法解决包类图像相似检索的问题,该方法的top5准确度只能达到78.39%。为证明仅仅基于网络高层特征作为图像特征[11]的方法不适合做图像相似检索。表3给出了基于单层特征和本文提出的采用多层特征的效果比较。显然本文提出的基于多层特征融合的方法能够取得更好的检索精度。同时表4中和传统算法的对比,也证明了基于深度学习算法在包类图像相似检索问题上的高效性。综上所述本文提出的基于卷积神经网络不同层特征的方法,能够很好地应用于包类图像的相似检索。
4.3 实际应用
为了说明算法的实际应用价值,本部分介绍在实际场景下本文算法的应用。上传手机拍摄的包类图片来搜索相同款式的包类商品。由于这种情况下拍摄的图片往往包含比较复杂的背景,所以需要先做目标检测。本文采用Faster-rcnn[19]算法进行包的检测,图6中给出了一些检测的结果。然后,利用本文算法进行相同包类款式的检索。为了评估算法的所需要消耗的时间,本次实验构建了包含100万张不同种类商品的检索库。表5中给出了算法在各个阶段所花费的时间和总时间。实验结果表明,本文的算法通过和检测算法结合能够用于街拍图片的快速检索。

图6 包类商品检测的结果

阶段检测提取特征近邻匹配总计时间0.04s0.03s0.50s0.57s
5 结 语
本文介绍了一种结合卷积神经网络不同层的特征进行包类商品图像检索的方法。详细的实验结果与应用证明了本文方法能够取得较好的检索效果。但是,算法依然存在一些不足之处,比如模型只根据较少的训练集训练获得,因此模型的迁移能力有限。在今后的研究中,将进一步完善和解决本文算法所存在的问题。
[1] Lowe D G.Distinctive Image Features from Scale-Invariant Keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[2] Sivic J,Zisserman A.Video Google:A Text Retrieval Approach to Object Matching in Videos[C]//IEEE International Conference on Computer Vision.IEEE Computer Society,2003:1470.
[3] Perronnin F,Liu Y,Sanchez J,et al.Large-scale image retrieval with compressed Fisher vectors[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition.IEEE,2010:3384-3391.
[4] Jégou H,Perronnin F,Douze M,et al.Aggregating local image descriptors into compact codes[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2012,34(9):1704-1716.
[5] Jegou H,Douze M,Schmid C.Hamming Embedding and Weak Geometric Consistency for Large Scale Image Search[C]//European Conference on Computer Vision.Springer-Verlag,2008:304-317.
[6] Philbin J,Chum O,Isard M,et al.Object retrieval with large vocabularies and fast spatial matching[C]//Computer Vision and Pattern Recognition,2007.CVPR’07.IEEE Conference on.IEEE,2007:1-8.
[7] Shen X,Lin Z,Brandt J,et al.Spatially-Constrained Similarity Measure for Large-Scale Object Retrieval[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,36(6):1229-1241.
[8] Chum O,Mikulik A,Perdoch M,et al.Total recall II:Query expansion revisited[C]//IEEE Conference on Computer Vision & Pattern Recognition.IEEE,2011:889-896.
[9] Tolias G,Jégou H.Visual query expansion with or without geometry:Refining local descriptors by feature aggregation[J].Pattern Recognition,2014,47(10):3466-3476.
[10] Russakovsky O,Deng J,Su H,et al.ImageNet Large Scale Visual Recognition Challenge[J].International Journal of Computer Vision,2015,115(3):211-252.
[11] Babenko A,Slesarev A,Chigorin A,et al.Neural Codes for Image Retrieval[M]//Computer Vision-ECCV 2014.Springer International Publishing,2014:584-599.
[12] Krizhevsky A,Sutskever I,Hinton G E.ImageNet Classification with Deep Convolutional Neural Networks[J].Advances in Neural Information Processing Systems,2012,25(2):2012.
[13] Wan J,Wang D,Hoi S C H,et al.Deep Learning for Content-Based Image Retrieval:A Comprehensive Study[C]//ACM International Conference on Multimedia,2014:157-166.
[14] Simonyan K,Zisserman A.Very Deep Convolutional Networks for Large-Scale Image Recognition[J].Computer Science,2014.
[15] Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2015:1-9.
[16] He K,Zhang X,Ren S,et al.Deep Residual Learning for Image Recognition[C]//Computer Vision and Pattern Recognition.IEEE,2016:770-778.
[17] Girshick R,Donahue J,Darrell T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition.IEEE Computer Society,2014:580-587.
[18] Girshick R.Fast R-CNN[C]//IEEE International Conference on Computer Vision.IEEE Computer Society,2015:1440-1448.
[19] Ren S,He K,Girshick R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[20] Redmon J,Divvala S,Girshick R,et al.You Only Look Once:Unified,Real-Time Object Detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2016.
[21] Liu W,Anguelov D,Erhan D,et al.SSD:Single Shot MultiBox Detector[C]//European Conference on Computer Vision.Springer,Cham,2016:21-37.
[22] Azizpour H,Razavian A S,Sullivan J,et al.From generic to specific deep representations for visual recognition[C]//Computer Vision and Pattern Recognition Workshops.IEEE,2015:36-45.
[23] Babenko A,Lempitsky V.Aggregating Deep Convolutional Features for Image Retrieval[J].Computer Science,2015.
[24] Kalantidis Y,Mellina C,Osindero S.Cross-Dimensional Weighting for Aggregated Deep Convolutional Features[C]//European Conference on Computer Vision.Springer,Cham,2016:685-701.
[25] Tolias G,Sicre R,Jégou H.Particular object retrieval with integral max-pooling of CNN activations[J].Computer Science,2015.
[26] Jia Y,Shelhamer E,Donahue J,et al.Caffe:Convolutional Architecture for Fast Feature Embedding[C]//ACM International Conference on Multimedia.ACM,2014:675-678.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
毛纺科技(2021年8期)2021-10-14
电子制作(2019年13期)2020-01-14
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
小资CHIC!ELEGANCE(2018年17期)2018-06-15
北京航空航天大学学报(2018年1期)2018-04-20
Coco薇(2015年5期)2016-03-29
