
在线校园新闻主题分析模型的建立与应用
2018-02-26 07:53朱凤山
电子技术与软件工程 2018年15期
朱凤山
摘要
我国的智慧校园建设和数字化校园建设已经持续多年,积累的相当数量的数字化信息,反映了各学校发展历程中的关切点。校园在线新闻是数字化校园与智慧校园建设的组成部分,建立新聞主题分析模型,对在线新闻进行智能化的挖掘、统计和分析,提供相应参考数据,有利于智慧校园建设和完善。新闻主题分析模型运用Python编程语言实现爬虫程序,建立数据获取模块,经清洗和结构化处理后,借助HanLp技术进行词语切分,实现中文语法分词,统计、分析在线新闻的隐含信息和潜在价值。最后使用该分析模型针对某高校近五年新闻数据,按照时间和主题进行了分析和汇总
【关键词】在线新闻 Python HanLP 主题分析模型
1 引言
智慧校园是在本世纪初,全球进入信息化大背景下,我国在十二五规划中明确提出来的,它以数字校园建设与发展为基本出发点与落脚点。2015年国务院颁发了《关于积极推进“互联网+”行动的指导意见》,进一步明确要求加快推进互联网、云计算、大数据、物联网等相关技术的创新应用,推动国家大数据战略和数据资源开放共享。“互联网+”行动引起了社会各行业、领域的广泛探讨,教育领域所提倡的智慧校园也包含在内。
随着大数据时代的到来,对数据进行分析、整理和归纳,从而为决策者提供决策支持,己受到各行各业的广泛关注的。国内外的很多研究者已经对如何高效利用大数据进行了广泛和深入的研究。高校门户网站是高校数字化校园与智慧校园建设的组成部分,承担着对外宣传的重任,同时又是在校师生获取信息的重要途径。科学、合理、高效的门户网站可以作为高校对外展示的一张名片,它反映了高校的信息化程度,是高校软实力的体现。因此,借鉴大数据分析技术,构建在线校园新闻主题分析模型,对高校在线新闻主题进行挖掘、分析、统计,对高校开展信息化建设和智慧校园建设都有积极意义。
智慧校园建设将成为教育信息化的最终形态。李有增认为智慧校园是融合提升高校教学、管理和服务的新模式,是教育信息化的高级形态。智慧校园所提倡的智慧,其内涵不是简单的数字信息化,而是创新和创造。建设智慧校园要结合云计算和大数据分析等科研技术,有效的对各种资源进行整合。在线校园新闻主题分析模型就是以大数据分析为基础,对高校所发布到门户网站上的校园新闻进行主题挖掘和分析,提供反馈结果,用以提升在线校园新闻管理的智慧程度。
2 分析模型的构建
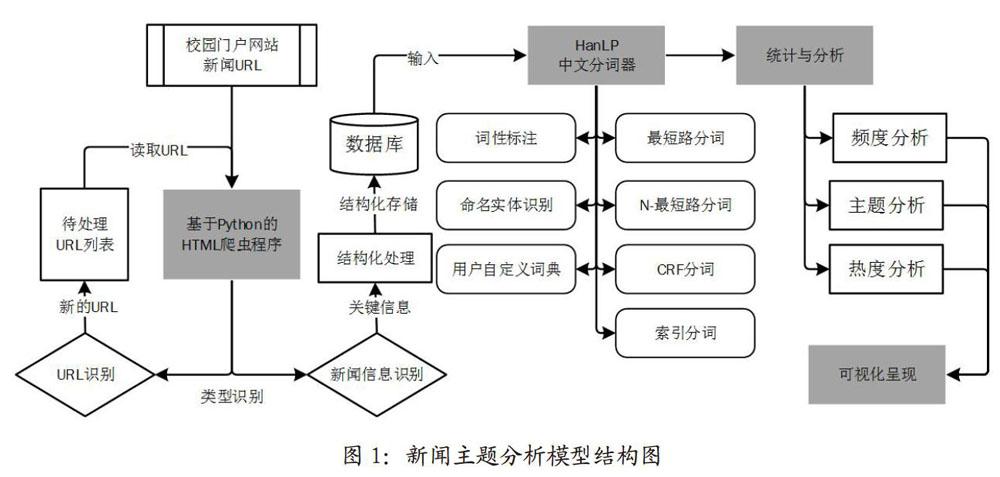
在线新闻主题分析模型依据所加工数据的流向划分,主要包括数据获取与结构化处理,中文分词处理,统计与分析,可视化呈现四个环节,如图1所示。
2.1 数据的获取与结构化处理
鉴于校园网新闻内容都是以HTML文本方式呈现,分析模型在获取数据时采用Python语言编写的“爬虫”来完成。Python编写“爬虫”程序时可以自行设计功能函数,通过多线程机制优化运行;也可以借助成熟的函数库或框架,如Beautiful Soup、Scrapy等。在本模型中采用的是前者。
为了让“爬虫”程序比较稳健,在实现过程中采取相应策略抵抗“反爬虫”程序。通过URL访问HTML页面时,动态更改user-agent,伪造用户代理,以防止服务器封杀。控制“爬虫”程序执行速率,随机每1~5秒执行一次爬取操作。读取到页面内容后,进行数据类型识别,如果是新闻信息数据,分发到数据清洗与整理模块;如果是新的页面URL链接,加入URL列表集合。“爬虫”程序从入口页面开始之后,不断从URL列表中提取新的页面,爬取所需内容,并进行标记,以防止重复爬取。结构化处理模块读取新闻信息以及相关属性,如新闻发布日期、发布者等,重新组织为结构化数据,借助pymysql模块存入Mysql数据库。由于所需采集数据具有很强的规律性,使用“爬虫”程序提取URL时,可以屏蔽无关链接,避免Python程序执行时耗费很长时间。如果需要处理的URL种类较多,且无固定分组模式,可以借助Python的多进程或多线程技术,采用缓存优化和并发性访问,从而可以提升执行性能。
2.2 新闻主题的分词
中文分词是基于HTML页面数据挖掘的前提。按照分词算法的不同,可以分为基于字符串匹配算法、基于理解的算法和基于统计的算法。根据分词与词性标注是否融合的不同,又可分为单纯分词的非融合算法和分词与标注同时进行的融合算法。目前,比较流行的中文分词算法是基于统计模型的机器学习方法。
在新闻主题分析模型中,采用的分词算法是由HanLP封装的。HanLP是由一系列模型与算法组成的开发工具包,用于提供自然语言处理技术在软件开发中的应用[4]。HanLP提供了多种分词算法的实现,如最短路分词、N-最短路分词、CRI分词等,中心思想是基于统计的自然语言处理。它较为完善的实现了词法分析、句法分析和语义理解等功能。HanLP工具包同时具备架构清晰、语料时新、可自定义词典等特点,hanlp.properties配置文件想具体信息如下,其中mywords.txt文件即为自定义的词典。
root=E:/eclipseSpace/test/
CoreDictionaryPath=data/dictionary/CoreNatureDictionary.txt
BiGramDictionaryPath=data/dictionary/CoreNatureDictionary.ngram.txt
CoreStopWordDictionaryPath=data/dictionary/stopwords.txt
CoreSynonymDictionaryDictionaryPath=data/dictionary/synonym/CoreSynonym.txt
PersonDictionaryPath=data/dictionary/person/nr.txl
PersonDictionaryTrPath=data/dictionary/person/nr.tr.txt
TraditionalChineseDictionaryPath=data/dictionary/tc/TraditionalChinese.txt
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt;mywords.txt;現代汉语补充词库.txt;全国地名大全.txt ns;人名词典.txt;机构名词典.txt;地名.txt
ns;data/dictionary/person/nrf.txt.nrf
CRFSegmentModelPath=data/model/segment/CR]SegmentModel.txt
HMMSegmentModelPath=data/model/segment/HMMSegmentModel.bin
ShowTermNature=true
2.3 统计分析与可视化呈现
分析模型的最终目的是对获取到的数据进行统计、分析,并予以呈现。可视化呈现利用数据窗口的直观、全面,对挖掘出的数据,通过视觉化,把信息变成了一种信息地图,避免迷失在数字信息中时。数据信息地可视化呈现,在大数据应用逐渐普及的情况下,显得尤为重要。
统计和分析模块主要从频度分析、主题分析和热度分析三个方面展开。频度分析是对特定时间段内,在线新闻发布数量的统计和分析;主题分析是对特定时间段内,所发布在线新闻的主题进行统计和分析;热度分析是对主题分析结果的进一步挖掘,寻找特定时间段内在线新闻的热点、关切点,它能反应高校比较重视的事件,体现高校管理的发展与变化趋势。
在实现可视化呈现时,选择Highcharts图标库。它是一套用Javascript语言编写实现的,支持所有主流浏览器和移动平台(android、iOS等),开源免费的轻量JS库。Highcharts可以较为简单的在Web页面或Web应用程序中添加具有交互性的图表,即为方便的呈现数据。
3 分析模型的应用
为检验在线校园新闻主题分析模型的应用效果,选择华北某省属高校的在线校园新闻进行实践应用测试。使用Python编写的“爬虫”程序,共获取数据4193条,时间跨度为2012-06-18到2018-06-01。为了便于统计和分析,截取2013-01-01到2017-12-31之间五年的数据,共计3687条数据,进行主题分词,频度分析和热度分析。
新闻主题的获取较为完善、清晰,没有混入其他文本信息和HTML元素,说明Python程序的执行较为稳定,预定模式匹配比较成功。
3.1 新闻发布频度分析
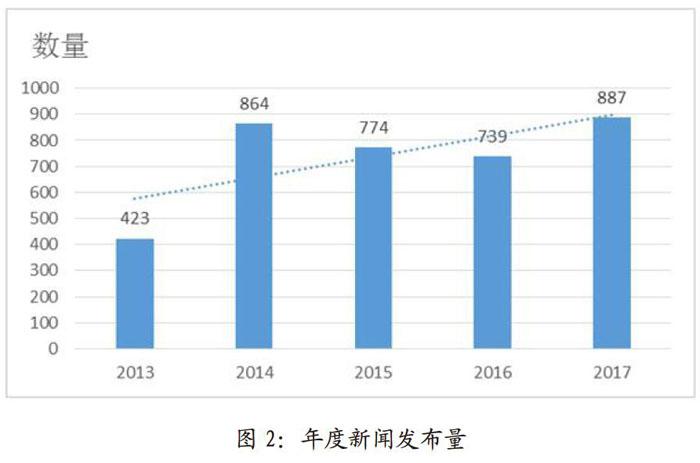
在被选数据集合中,该高校在线新闻发布量为2013年423篇,2014年864篇,2015年774篇,2016年739篇,2017年887篇,整体趋势为正向增长,如图2所示。在大力推广数字化校园建设,智慧校园建设的进程中,校园新闻可以作为传播和反映校园文化精神的载体。校园新闻可以服务于大学文化建设,同时可以作为校园文化建设的手段。积极、合理、适度的校园新闻发布量,是反映校园文化内涵、树立高校形象和办学特色的重要形式,能够增强教师和学生的凝聚力,使其有归属感,同时营造积极向上的数字化校园氛围。
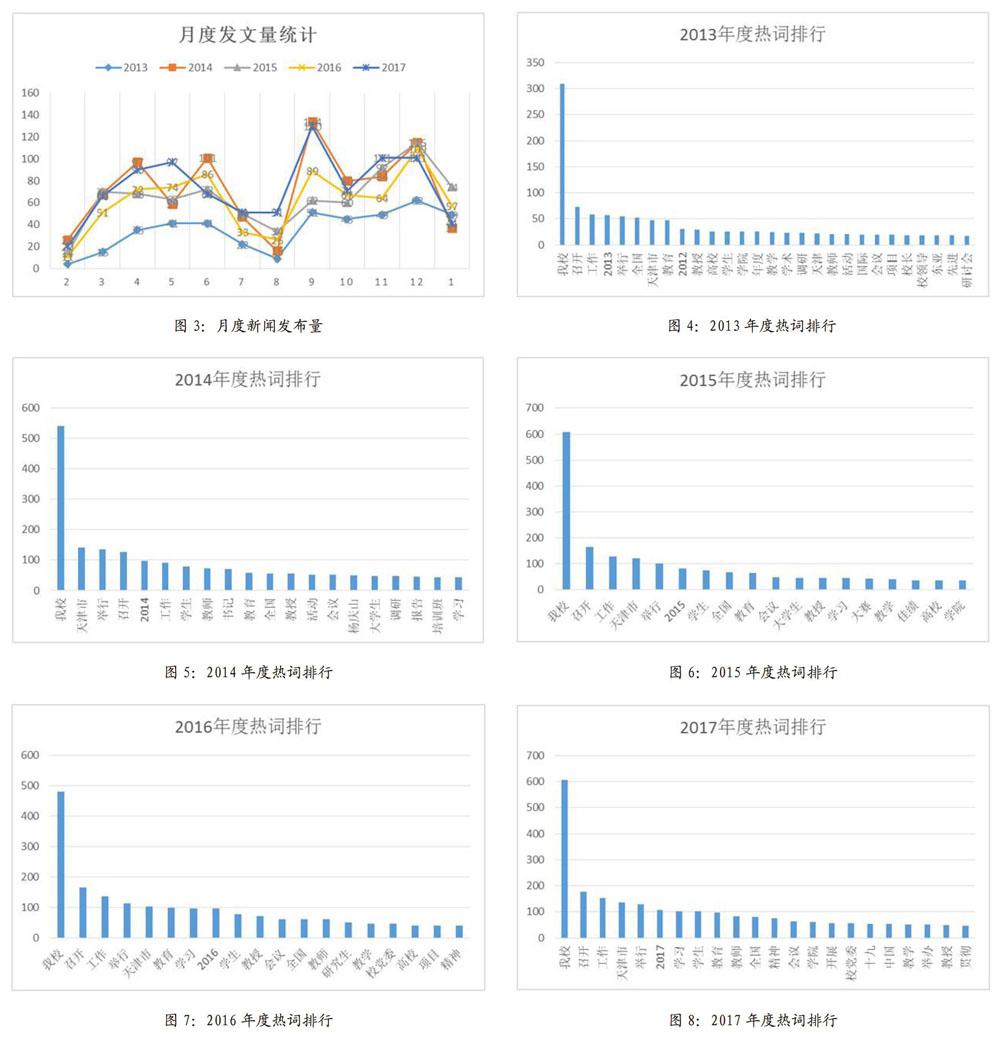
近五年的数据信息显示,校园新闻在月度发布量上与高校的学期时间跨度正向匹配。9月至转年1月为第一学期(上半学期);3月至7月为第二学期(下半学期),调整之后的月度新闻发布量如图3所示。寒暑假期间的新闻发布量最低,学期中新闻发布量较高。比较有意思的是,近五年的数据反映,两个学期的发文量并不平均,第一学期明显的发文量明显高于第二学期。
3.2 新闻主题与热度分析
经HanLP分词模块对所提取新闻主题分词后,进行数据清洗,主要从不完整的数据、错误的数据和重复的数据三个方面进行清洗。在数据处理过程中还过滤了与单位信息密切相关的数据。
整理之后的数据按照词语在新闻主题中出现次数高低拍序,出现次数越多,则意味着该词语具备更高的热度指数。2013年度,排名前五位的热度词汇有“我校”、“召开”、“工作”、“举行”、“全国”;2014年度,排名前五位的热度词汇有“我校”、“天津市”、“举行”、“召开”、“工作”;2015年度,排名前五位的热度词汇有“我校”、“召开”、“工作”、“天津市”、“举行”;2016年度,排名前五位的热度词汇有“我校”、“召开”、“工作”、“举行”、“天津市”;2017年度,排名前五位的热度词汇有“我校”、“召开”、“工作”、“天津市”、“举行”。各年度热词排行榜具体信息可以参考图4至图80
除去“我校”、“召开”、“举行”、“工作”等在新闻主题发布时较为常用的词汇,位于热度词汇排行榜中其他词汇则可以标明该所高校的新闻关切点所在,如“学生”、“学习”、“教育”、“教师”等,这些词汇在近5年的排行榜中都有所反应。
4 总结
基于Python和HanLp技术的在线新闻主题分析模型,使用Python采集Web数据,经数据清洗和结构化整理之后,借助HanLP中文语法工具分词,统计、分析在线新闻的隐含信息和潜在价值,体现了数据挖掘的意义,对校园信息化建设和信息化管理提供支持。
4.1 提供决策支持
在线新闻主题经过中文分词、聚类等方法,可以收集到相关信息,为管理者提供信息反馈和决策支持。通过抽取门户网站各主题的信息,对主题进行深入挖掘,可以让管理者更加深刻的从多角度的了解高校门户网站的内容发布情况,也可以作为高校领导对相关事件的决策判断基础。通过信息技术将数据所隐藏的信息发掘出来,实现数据价值的有效利用,为相关决策提供数据支撑。在此基础上,对挖掘出的数据进一步分类,这也数据挖掘领域的重要方向,通过描述性的数据特征,将归为一类的数据划分为一个领域。基于Python和HanLp技术的在线新闻主题分析模型可以分析高校门户网站主题新闻内容,从而找出高校新闻主题的相关信息,将信息进行归纳和总结,以便让管理者做出更加正确的决策。
4.2 提供纵向和横向对比数据
使用基于Python和HanLp技术的在线新闻主题分析模型,可以纵向分析同一学校在不同时间段、不同历史时期的关注点,找出该历史时期下的工作重点。纵向切分的时间段可以按照年、月、周为单位,这需要对分析模型中“统计和分析”模块的参数进行调整。同时,该分析模型可以应用于不同学校在线新闻主题的挖掘和分析,横向对比学校之间的关切点。综合使用纵向和横向对比数据,可以发现某一个特定时间段下,不同学校之间的发展变化,提供数据支撑。
4.3 分析模型存在的问题
当前,在线新闻主题分析模型是针对同一个高校新闻网站进行的,基于Python的爬虫模块在匹配新闻URl时,只限定于当前域,对域外的URL不进行处理,这种挖掘数据的方式,可以提高效率,但降低了灵活性。通过实践应用,分析模型在获取数据和分析数据时都可以比较高效、稳定。分析模型下一步需要完善的功能是可以比较智能的对所指定的多所高校新闻站点,自动的爬取数据;同时提供校际横向关切点数据分析功能模块。
参考文献
[1]潘庆超,吴东伟.高校门户网站设计与实现[J].电脑知识与技术,2014(04):838-840.
[2]蒋东兴,付小龙等.高校智慧校园技术参考模型设计[J].中国电化教育,2016(09):108-P114.
[3]陈琳,王蔚等.智慧校园的智慧本质探讨--兼论智慧校园“智慧缺失”及建设策略[J].远程教育杂志,2016(04):17-24.
[4]Han Language Processing[EB/OL],http://hanlp.linrunsoft.com/,2018-6-6.
[5]李有增,周全等.关于高校智慧校园建设的若干思考[J],中国电化教育,2018(01):112-117.
