
基于ReRAM的神经网络加速器发展概况
2018-02-20 00:43周川波
西部广播电视 2018年24期
周川波
(作者单位:四川广播电视台520发射传输台)
1 背景和研究进展
随着互联网发展、存储介质价格降低、数据来源越来越广泛,人们来到了大数据(Big Data)时代。深度学习[1-3](Deep Learning)可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示。这些方法在许多方面都带来了显著的改善,包括最先进的语音识别、视觉对象识别、对象检测、推荐系统[4-5]和许多其他领域,例如药物发现和基因等。深度学习能够发现大数据中的复杂结构。它是利用反向传播(Backpropagation,BP)算法来完成这个发现过程的。BP算法能够指导机器如何从前一层获取误差而改变本层的内部参数,这些内部参数可以用于计算表示。深度卷积网络在处理图像[6]、视频、语音和音频方面带来了突破,而递归网络在处理序列数据,比如文本和语音方面表现优秀。
深度学习方法虽然取得许多突破,但是也存在着模型参数数量大,训练慢等问题,除了改进训练算法,在软件层面加快速度外,利用硬件加速训练神经网络也引起了学术界的关注。在2016年的ISCA会议和MICRO会议,发表了许多有关身神经网络加速器的文章,下面简单介绍这两个会议的有关内容。
ISCA2016于6月18日至22日在韩国首尔召开,这次会议有近800名来自世界各地的工业界和学术界的专家学者参加,在参会人数上创下历史新高。本届会议共收到了291篇投稿论文,最终录用了57篇,接收率为19.6%。
在这次大会上,SK Hynix的执行副总裁Seok-Hee Lee做了关于存储技术的报告。由于CPU/GPU计算能力的迅速增长,未来系统性能的提高遇到了“存储墙”(Memory Wall)的瓶颈,使存储技术在计算机体系架构的重要性越来越高。除了继续研究基于传统的SRAM和DRAM的存储架构,新型存储技术,比如非易失性存储器(Non-volatile Memory)的研究越来越受到学术界和工业界的重视。这次大会57篇论文中,大约20篇都与Memory相关。
MICRO是计算机体系结构领域的顶级会议,重点关注处理器体系结构的设计等内容。自1968年创办以来,迄今已经举办了49届,MICRO2016于10月15日至19日在台北召开。本届会议共收到了283篇投稿论文,最终录用了61篇,接收率为21.6%。
从MICRO论文分析来看,目前体系结构研究的热点体现在两个方面:第一是对存储结构的关注,第二是对神经网络加速器的关注。
本文关注的是新型存储器和神经网络加速器研究的结合点——基于新型存储器ReRAM的神经网络加速器。与现在深度学习框架theano、tensorflow 使用软件仿真和GPU加速[7]不同,使用ReRAM可以直接在内存中完成神经网络计算,节省了数据在内存、CPU、GPU频繁迁移产生的事件和能源损耗。本文首先介绍了ReRAM的原理和结构[8-9],基于ReRAM提出了一个简单神经网络架构[10],PRIME[11]强化了ReRAM架构的处理能力,使其适应于不同的神经网络结构和较大规模数据,NEUTRAMS[12]消除了硬件约束,通过仿真层对硬件的抽象,使得在表示层设计的神经网络不需要修改即可实现在不同硬件架构上移植。
2 电阻式随机访问存储器
电阻式随机访问存储器[8-9](ReRAM),是一类通过改变单元(Cell)电阻来实现非易失性存储(Non-volatile Memory)的随机访问存储器。广义的定义下并没有指明实现电阻变化的材料,如非特别说明,本文所指的ReRAM是广义ReRAM的一个子类,即使用金属氧化物的ReRAM,这种ReRAM使用金属氧化物层来实现电阻的变化。
如图1(a),ReRAM单元是一种金属-绝缘体-金属(Metal-insulator-metal,MIM)结构,由顶层电极,底层电极和中间层金属氧化物组成。当有额外的电压通过时,ReRAM单元将从高阻态(High Resistance State,HRS)转换成低阻态(Low Resistance State,LRS),通常高阻态表示逻辑“0”,低阻态表示逻辑“1”。
图1(b)展示了ReRAM单元双极转换的I-V图,将一个单元从高阻态(逻辑“0”)转换成低阻态(逻辑“1”)称为置位(SET)操作,将一个单元从低阻态(逻辑“1”)转换成高阻态(逻辑“0”)称为重置(RESET)操作。通常使用正电压来进行置位操作,使用负电压来进行重置操作。进行SET操作时,正电压保持不变,观察到电流增加,也就是说电阻减小,成为低阻态。进行RESET操作时,负电压保持不变,电流趋向于零,也就是说电阻增大,成为高阻态。需要强调的是,目前情况下基于ReRAM的存储器耐久度达到了1 012数量级,而基于PCM的存储器耐久度在106~108。ReRAM有较好的耐久度。
图1(c)展示了ReRAM的Crossbar整列结构,这是最能有效利用面积的阵列组织方式。目前有两种通用的方法来提升ReRAM的密度、降低功耗,一种是多层的Crossbar架构(Multi-layer Crossbar Architecture),一种是多平面的单元结构(Multi-level Cell,MLC)。在MLC结构下,ReRAM的每个单元通过使用不同平面的电阻,可以实现存储超过1bit的信息。实现这种一个单元存储多bit信息需要非常好的写控制器件,目前已经能够做到一个单元存储7bit信息。
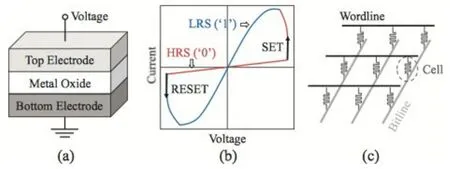
图1(a) ReRAM单元示意图 图1(b) 双极转换的I-V曲线图图1(c) Crossbar架构图解
因为Crossbar架构的高密度,ReRAM被认为是可以替代DRAM成为下一代主存的关键技术。但也存在一些障碍,其中就是ReRAM的读延迟与DRAM相当,但是写延迟要就比DRAM久(5倍以上),目前也有一些优化措施提升ReRAM的写性能,让ReRAM与DRAM的差距在10%以内。除了ReRAM,还有其他的非易失性存储器被研究者所关注,他们包括自旋转移力矩磁性随机访问存储器(Spin-transfer Torque Magnetic RAMSTT-RAM),相变存储器(Phase Change Memory)等等,这些存储器都能实现除数据存储之外的逻辑运算能力。在这些存储器中,ReRAM因为通过Crossbar结构对大规模矩阵向量进行有效计算,在神经计算中被广泛应用。
3 简单神经网络加速器架构
2015年,Prezioso等人在Nature上的文章[10]指出,他们制造了一个12×12的基于ReRAM的Crossbar原型,利用该原型实现了神经计算,并把3×3的黑白图片成功分成了三类。Prezioso等人从实验的角度证实了ReRAM存储器应用于神经计算的可能,这篇文章也成为了构造更庞大、更复杂神经网络加速器的基石。
Prezioso的ReRAM原型如图2,该结构集成了12×12的Crossbar,每个单元使用Al2O3/TiO2-x忆阻器(Memristor)。该原型芯片可用来实现图3中的简单神经网络。图3(b)中的单层感知机包含10个输入,3个输出,神经元之间的全连接构成了10×3=30个连接权重(Synaptic Weights)。感知机的输出fi通过非线性的激活函数得到:

其中Ii通过矩阵运算得到:

Vj(j=1,...,9)是与图片像素相关的输入信号,V10是偏置,β用来控制激活函数非线性程度的参数,Wij表示神经元之间的连接权重。这样一个简单神经网络已经可以用来执行一些模式识别任务了,例如,将3×3的黑白图片分成三类,图片的每个像素成为神经网络的一个输入。Prezioso等人使用的数据集包含N=30个图片(如图 3(c),这些图片包含“z”“v”“n”三个形状,每个形状还包含9个被“污染”的版本(翻转原始图片中的一个像素),因为数据集有限,它们不光被用来训练网络,也被用来测试网络。
在实际实现中,输入信号通过电压Vj来表示,取值为+0.1 V或者-0.1 V,代表黑像素点或者白像素点。对于偏置V10而言,通常为0.1 V。这种编码方式使得标准数据集很均衡,即每一个类中图片对应的输入信号和接近于零,这加速了训练的收敛。为了让网络的输出层同样有这种平衡性质,每个连接权重(突触)使用了两个忆阻器,因此Crossbar上忆阻器数量为30×2=60(如图4(a),Prezioso等人使用了额外的器件来保证每一列上虚拟地线条件(Virtual Ground Conditions)得到满足,减去了当前在相邻列使用的流式结构来生成不同的输出信号Ii,Prezioso等人确保Ohm定律能够应用于Crossbar的每一列,对于不同的权重。


图2 ReRAM Crossbar原型结构图
(a)输入图片,3 3简单二值灰度图,(b)用来分类图片的单层感知机,(c)输入的图片集合,(d)训练算法流程图。
其中Gij+表示忆阻器的有效电导率,也就是在电压0.1 V下I/V的比率。公式(1)同样也是通过外部元器件实现,这里β取值为2×105A-1。
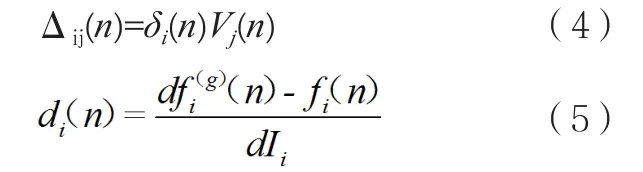
对于每一步训练而言(如图4(d)),训练集中中每个一样例依次输入 Crossbar,Crossbar 产生输出为 fi(n),n为样例的编号,权重的更新量依照如下公式计算:
其中fi(g)是第i个输出的目标值,在Prezioss等人的系统中,取值+0.85表示正确分类,取值-0.85表示错误分类。一旦全部的N个样例完成训练,所有的更新量Δij(n)计算完成,权重依照下面公式更新:
其中η是一个常数。
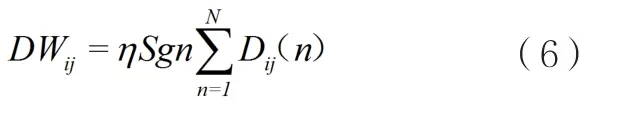
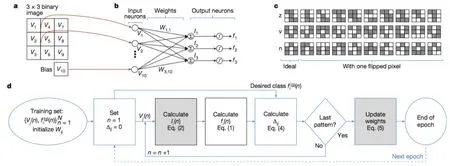
图3 简单图片分类任务
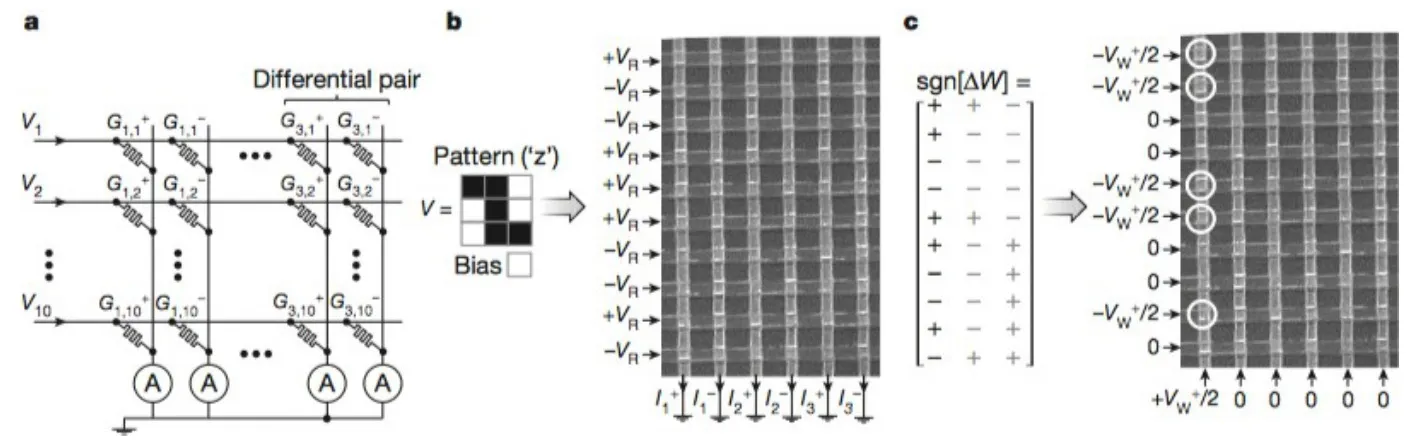
图4 进行图片分类任务时芯片的工作过程
(a)Crossbar上使用10×6的片段实现的单层感知机,(b)对二值图片’z’的分类操作过程,深色像素对应+VR,浅色像素对应VR,这里使用的读电压VR=0.1V,写电压VW=1.3V,(c)更新权重的操作过程(这里表示的是第一列)。
对于3×3二值灰度图片的分类结果如图5,通常能够在23代收敛。图5嵌套的图展示了权重W初始化值和训练至21代时值的分布情况。
Prezioso 等人设计的芯片,在Crossbar上能够直接完成公式2、公式3,通过额外的元器件,完成公式1、公式4、公式5的起算,实现了基本的神经网络计算,并完成简单的二值灰度图片分类任务。不可否定的是,该研究启发了学界基于ReRAM的神经网络加速器的研究。但是在大数据和规模极大的神经网络模型下,Prezioso等人的芯片在通用性、计算性能、功耗等方面都有待提升。下面我们将介绍性能和通用性更好的神经网络加速器架构PRIME。
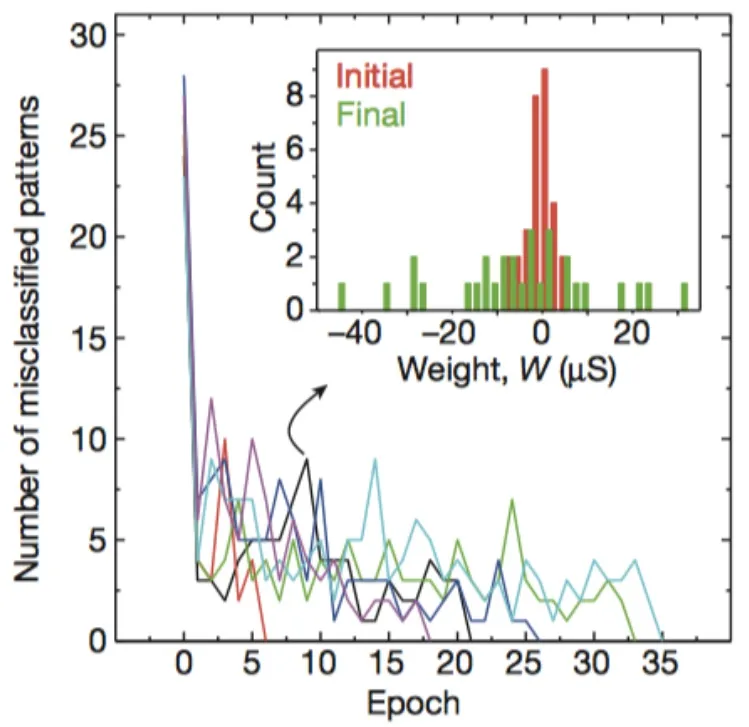
图5 迭代次数与错分数折线图
4 PRIME:适用范围更广的神经网络加速器架构
章节3实现的芯片原型结构简单,仅仅能够处理30个连接权重,对于处理大数据是不足够的。本章节介绍的基于ReRAM主存技术的神经网络加速器架构PRIME[11]是迟萍等人发表在ISCA2016上的最新成果。PRIME基于 PIM思 想(Processing In Memory),使用的Crossbar阵列不光能够被用来加速神经网络计算,还能够当成普通存储器使用。迟萍等人不光设计了微架构(Microarchitecture),还提供了软硬件接口,这使得开发者能够基于PRIME实现不同种类的神经网络。PRIME的实验效果非常好,相比前人的神经网络加速器,在迟萍等人的实验环境下,PRIME的性能提升了2360倍,功耗降低了895倍。PRIME的特点如下:
(1)存储架构既能用来加速神经网络计算,又能作为普通存储器。
(2)通过精心设计的电路和微架构,使得能在内存中进行神经网络计算,同时占用面积很小。
(3)PRIME采用了一种输入和突触组合方法来克服精度问题。
(4)PRIME提供了一组软硬件接口,使得开发者能够实现不同的神经网络,同时PRIME在编译期间优化神经网络映射时间,能够实现与其他计算单元之间的并行运算。
PRIME的设计概观如图6(c),与其他神经网络加速器不同(图6(a),图6(b),PRIME不需要额外的处理单元(Processing Units,PU),PRIME直接使用ReRAM单元来进行计算,为了完成这个目标,PRIME包含三部分,它们分别是内存子阵列,全函数子阵列,缓存子阵列。内存子阵列仅仅只有数据存储的能力(同传统内存子阵列相同),它们的微架构和电路设计同当前的ReRAM主存相似。全函数子阵列有两种操作模式,在主存模式下,全函数子阵列功能和传统主存相同,在计算模式下,全函数子阵列可以用来做神经网络计算,需要使用一个PRIME控制器来控制模式的切换。缓存子整列用来为全函数子阵列提供数据缓存,实际设计时,靠近全函数子阵列的主存子阵列被用来作为缓存子阵列。所有的缓存子阵列都有独立的数据接口,因此缓存访问不会占用主存访问的带宽。当不需要使用缓存时,缓存子阵列也可以用来作为普通的主存。使用全函数子阵列进行神经网络计算能够享受数据迁移的超高带宽,使用缓存子阵列也使神经网络计算可以与CPU并行。
PRIME架构如图7所示,有关要点如下:
第一,全函数子阵列的设计。解码器和驱动。PRIME改进了一些元件,如图7(A),这些元件解决了计算模型和内存之间的差异。
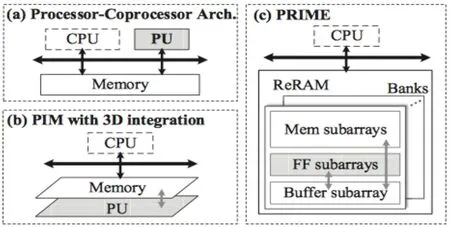
图6(a) 传统的处理器-协处理器架构 图6(b) 使用3D集成技术的PIM方法图6(c) PRIME设计概观
列多路器。图7(B)中的列多路起包含了模拟减法单元和sigmoid单元,这支撑了基本的神经网络计算。
读出放大器。如图7(C),读出放大器使得低精度的ReRAM单元支持高精度的神经网络计算。同时也提供了卷积神经网络操作相关的器件。
缓存连接。如图7(D),它建立在全函数子阵列和缓存子阵列之间,使得全函数子阵列能够访问缓存子阵列上的任意位置。
第二,缓存子阵列的设计。缓存子阵列被设计用来缓存全函数子阵列的输入输出数据。全函数子阵列不需要CPU的参与就可以直接访问缓存子阵列,使得它可以与CPU并行执行。
第三,PRIME 控制器。如图7(E),PRIME控制器解码指令,将控制信号传给全函数子阵列。PRIME控制器使得全函数子阵列可以在内存模式和计算模式之间转换。
第四,克服精度挑战。精度挑战包含几个方面:输入精度、权重精度、输出精度。在PRIME设计上,采用了不同的假定,分别是输入电压3-bit精度(8个层级的电压),4-bit精度的权重,6-bit精度的输出。需要指出的是,PRIME使用了2个3-bit来实现6-bit的输入信号,使用两个4-bit来实现8-bit的权重。
第五,实现的神经网络算法。PRIME实现了感知机层、卷积层、池化层、本地应答规则化层等等。
(A)针对不同电压源的字线(Wordline)驱动,(B)模拟减法和sigmoid电路的列多路器,(C)可重构的读出放大器,支持多层输出,加入了ReLU和4-1最大池化函数单元,用于卷积神经网络,(D)全函数子阵列和缓存子阵列之间的连接,(E)PRIME控制器
PRIME基于ReRAM,提升了神经网络计算的计算性能,降低了功耗,适用于MLP、CNN等网络结构,在MNIST数据集上取得了很好的实验效果,是一个值得关注的神经网络加速器架构。
5 NEUTRAMS:神经网络软硬件协同设计工具集
章节3介绍了一个实现神经网络计算的最简化的微架构,章节4进一步深化了架构的设计,使其能够支持大规模较复杂的神经网络。但是这两种方法都是基于特定的硬件,支持特定的神经网络,抽象化程度较低,YuJi等人在前人研究的基础上,提出了NEUTRAMS工具集[12],该工具集借鉴了计算机系统层层抽象的思想,提出了神经网络系统的分层结构,使得基于该工具集进行神经计算不依赖特定的硬件结构。NUTRAMS工具集的分层思想参考了计算机系统的分层思想(如图8(a)),NUTRAMS的结构(如图8)分为:表示层、转换层、映射层、仿真层。
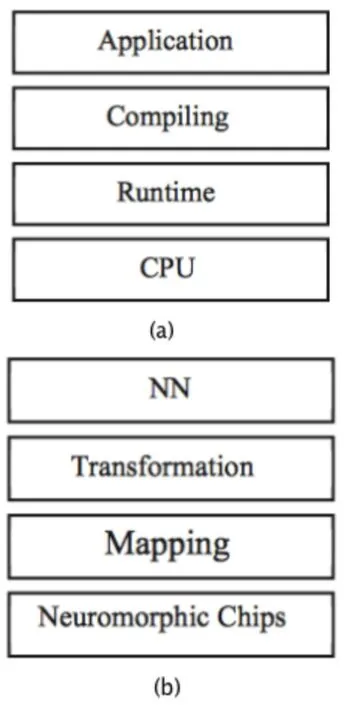
图8 与传统计算机系统架构类比
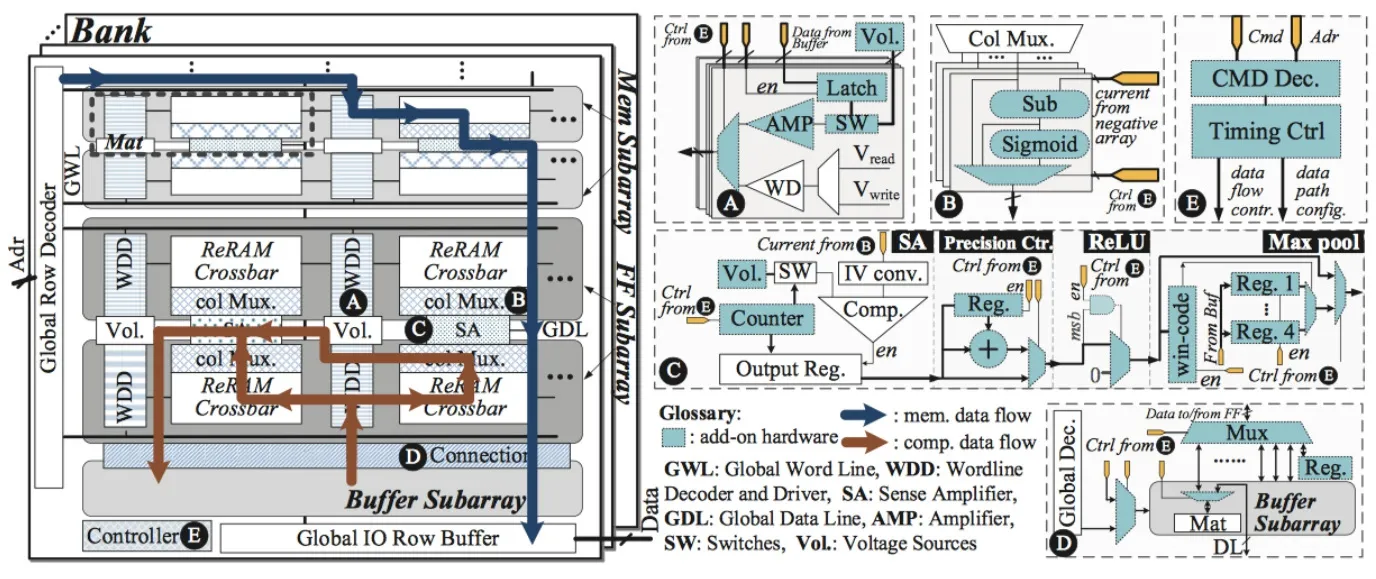
图7 PRIME架构
下面给出了NUTRAMS各层简介:
表示层,参照大部分神经网络模型给用户提供的接口,表示层大都提供了两种操作,分别为集群(Population,大规模神经元的集合,其实也就是神经网络所谓层的概念,如隐藏层,显示层)和映射(Projection,集群之间的连接,也就所谓的层与层之间的权重)。一个使用集群和映射操作的例子是:

创建一个神经网络需要两类信息:(1)节点信息,及神经元、突触种类;(2)边信息,即权重、延迟、其他用来描述映射的属性。这也就是表示层所有表示的信息,这类可以用于传统神经网络如多层感知器,也可以用卷积神经网络。
转换层,转换层是NUTRAMS的核心,就是在该层次突破了硬件的约束。YuJi等人使用的核心思想是分治算法,将复杂的神经网络连接划分成更小的连接,让其满足硬件约束。图9是一个数据流示意图,图9(A)是原始神经网结构,图9(B)图9(C)描述了两种减少权重的方法,一种是将前置集群拷贝,和后置集群分别连接,一种是将前置集群合并,与后置集群连接,图9(D)是原始神经网络的划分图,大规模的连接被划分成了小规模的连接,使直至该网络适合于特定的硬件架构。关于如何进行划分和怎么保证划分之后神经网络的计算精度,可以参考YuJi等人的论文。
映射层,映射层是用来将神经元分配到计算核心,构建连接关系,填写路由表。最优映射不光能够充分有效地利用芯片资源,也能够保证正确性。YuJi等人提出的映射方法倾向于将密切联系的神经元放在一起。根据之前的描述,经过转换层的转换,结果为相互连接的集群,每一个连接子矩阵(经过分治算法的划分得到的)满足硬件约束。然后所有的神经元被分配到虚拟核心上,再构建虚拟核心到物理核心的映射。YuJi等人使用了KL(Kernighan-Lin)划分策略,该策略将映射抽象成图的划分问题,尝试在划分边界上最小化联系。该方法首先随机生成一个映射格局,然后二分节点,联系紧密的模块保持在同一个划分中。这个过程将一直持续,直到临近的两个节点被放到任意的最终划分结果中。通过这种方法实现了联系的最小化,并构建了一个映射。
仿真层,仿真层是对硬件芯片的抽象,NUTRAMS将芯片划分成三类逻辑模块:计算核心、主存、片内网络(Network on Chip,NoC)。对于计算核心的仿真步骤为:(1)得到当前输入脉冲(Input Spike)和突触权重,(2)计算并更新神经元状态,(3)发射新脉冲。如果当前有很多输入,重复步骤(1)和步骤(2)。对于主存的仿真方法很直观,只需保存神经网络模型的突触权重即可。对于片内网络的仿真方法也是很直接的:源神经元发出的脉冲产生一个从源计算核心到目的计算核心的NoC数据包(X-Y路由策略)。
NEUTRAMS提供了更高层次的抽象,使得神经网络设计不在受硬件约束,相同的神经网络易于移植到不同的硬件芯片上。YuJi等人设计了将NUTRAMS工具集应用在PRIME架构上的实验,取得了很好的效果
6 总结
本文首先介绍了深度学习、ISCA、MICRO的有关内容和背景,重点关注基于ReRAM的神经网络加速器,然后介绍了ReRAM的原理和结构,介绍了基于ReRAM设计的简单神经网络架构,该架构仅仅支持30个连接权重,支持神经网络十分有限。PRIME架构极大的扩展了对神经网络计算的支持,针对不同网络(多层感知器,卷积神经网络)和较大规模数据集(MNIST)都取得了较好的实验效果。PRIME虽然对神经网络加速效果较好,但是其提供的软硬件接口仍然只针对PRIME架构本身,缺乏扩展性。
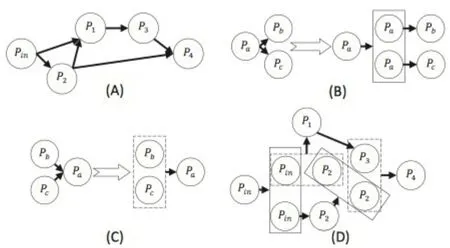
图9 数据流示意图
NEUTRAMS工具集是为了消除硬件约束提出来,该工具集通过仿真层对硬件的抽象,使得在表示层设计的神经网络不需要修改即可实现在不同硬件架构上移植。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
少先队活动(2021年6期)2021-07-22
北京航空航天大学学报(2021年6期)2021-07-20
汽车工程(2021年12期)2021-03-08
时代人物(2019年27期)2019-10-23
计算机测量与控制(2017年6期)2017-07-01
浙江大学学报(工学版)(2016年11期)2016-06-05
环球时报(2014-06-18)2014-06-18
