
长白山野生中草药植物图像检索方法研究
2018-02-01 14:39王艳周小平王睿孙冰雪
中国中医药信息杂志 2018年2期
关键词:中草药
王艳+周小平+王睿+孙冰雪


摘要:目的 研究基于视觉词袋的图像检索方法并应用于长白山中草药植物图像检索领域。方法 采用SURF算法提取图像视觉特征,稀疏编码方法构造视觉词典,并提出支持向量机(SVM)和近似最近邻(ANN)相结合的改进方法完成分类器分类训练。结果 选取2500张中草药图像作为检索样本,在视觉单词数量为500的情况下,平均检索时间为481 ms,平均查准率为88.95%。结论 本方法能有效提高图像检索效率与准确度,同时表现出较好的鲁棒性。
关键词:中草药;图像检索;视觉词袋
DOI:10.3969/j.issn.1005-5304.2018.02.021
中图分类号:R2-05;R282.74 文献标识码:A 文章编号:1005-5304(2018)02-0095-04
Research on Image Retrieval Method of Wild Chinese Herbal Medicine Plants
in Changbai Mountain
WANG Yan, ZHOU Xiao-ping, WANG Rui, SUN Bing-xue
College of Pharmacy, Jilin University, Changchun 130012, China
Abstract: Objective To study the visual word bag based image retrieval method and apply it in the field of image retrieval of wild Chinese herbal medicine plants in Changbai Mountain. Methods SURF operator was used to extract visual features. Then sparse coding method was used to structure visual dictionary. The classifier was trained by combination of support vector machine (SVM) and approximate nearest neighbors (ANN) method. Results Totally 2500 photos of Chinese herbal medicine plants were chosen. When the visual word number was 500, the average retrieval time was 481 ms, and the average query accuracy was 88.95%. Conclusion The method can effectively improve the efficiency and accuracy of image retrieval, and has better robust.
Keywords: Chinese herbal medicine; image retrieval; visual word bag
長白山位于吉林省东南部,属国家级自然保护区,森林资源丰富、植物种类繁多,共有野生植物2700余种,其中药用植物1000余种,名贵药用植物有人参、党参、东北刺参、黄芪、天麻、红景天和灵芝等,是我国著名的北药基地[1]。为高效检索和鉴别中草药植物图像,本研究探索基于内容的图像检索方法在中草药图像检索领域的应用。
传统图像检索过程中,先通过人工对图像文字标注,再用关键字检索图像,这种依据图像描述的字符匹配程度提供检索结果的方法,简称为“字找图”,既耗时又主观多义。基于内容的图像检索可克服“字找图”方式的不足,直接从待检索的图像视觉特征出发,在图像库中找出与之相似的图像,这种依据视觉相似程度给出图像检索结果的方法,简称为“图找图”[2-3]。在基于内容的图像检索中,视觉词袋模型(bag of visual word,BoVW)已成为较常见的方法。针对传统基于SIFT(scale invariant feature transform)图像特征提取耗时过长的问题,本研究采用基于SURF(speeded up robust features)的图像特征快速提取方法。此外,对基于BoVW的视觉词典构造方法和分类器训练方法进行改进优化,从而有效提升中草药图像信息检索的效率与准确度。
1 视觉词袋模型基本原理
BoVW基本原理是将图像理解为一组视觉特征单词的集合,统计每个视觉特征单词在图像中出现的频率并生成频率直方图向量,以该向量对图像进行表示,然后将特征向量导入分类器进行分类[4],算法流程见图1。
算法流程具体表述如下:
步骤1:特征提取与描述。图像特征主要包括图像的颜色、形状、纹理和空间关系等一些定量的特征,这些特征可以通过图像特征检测算法自动提取与描述,一般采用SIFT算法进行特征提取[5]。
步骤2:视觉词典构造。利用K-means算法将图像特征描述子进行聚类形成视觉词典,每个聚类中心对应视觉词典中的1个单词[6]。
视觉词典构造的具体步骤:
①给定图像特征描述子待聚类数据集,随机选取K个对象作为初始聚类中心。
②根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分。
③重新计算每个有变化聚类的均值。
④计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果不满足条件则返回到步骤②。endprint
步骤3:图像映射到视觉词典。视觉词典生成后,统计每幅图像对应词典中的单词出现的频率,将每幅图像映射成1个K维的图像描述向量,其中K表示聚类中心的数量,即视觉单词的数量。
步骤4:训练分类器分类。主要采用支持向量机(support vector machine,SVM)进行分类[7]。SVM的学习策略是间隔最大化,可形式化为求解凸二次规划问题,利用寻优算法求解目标函数全局最小值。
2 基于视觉词袋的图像检索改进方法
2.1 基于SURF的图像特征提取与描述
SURF算法是基于尺度空间理论,该算法是对SIFT算法的一种改进,优势在于能够大大提升特征提取速率,同时表现出更好的鲁棒性[8]。
2.1.1 图像特征提取
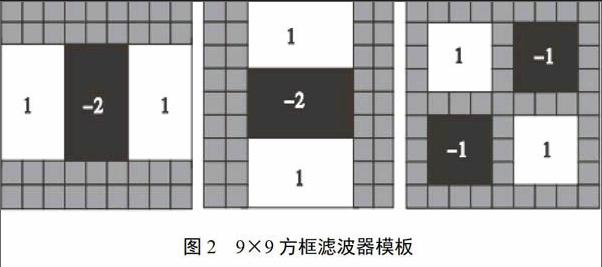
SURF算法采用方框滤波器构造fast-Hessian矩阵,9×9方框滤波器模板见图2。在原图上,通过扩大滤波器尺寸形成不同尺度的图像金字塔,并使用积分对图像卷积进行加速。
2.1.2 图像特征描述
首先计算每个特征点主方向。然后,选定一个以特征点为中心的正方形区域,把该区域划分为4×4个子区域,计算每个子区域5×5个采样点相对于主方向的水平和垂直方向的Harr小波响应值,分别计为dx和dy,并给这些响应值赋予不同的高斯权重系数,得到1个四维矢量V:
由①式可知,SURF特征描述向量的维数是16×4=64维。为了保持对光照不变性,需要对向量进行归一化处理,得到特征描述子,见图3。
2.2 基于稀疏编码的视觉词典构造
基于K-means聚类的视觉词典构造方法存在的主要问题是将图像特征硬性划分到一个与其距离最近的视觉单词类中,未考虑该特征可能与多个类中的视觉单词距离最近,降低了与其他类视觉单词的相似度和自身表达的准确性。本研究采用基于稀疏编码(sparse coding)视觉词典构造方法[9],可使图像特征用与其最近的多个视觉单词进行线性表示。稀疏编码本质是一个目标向量可以由少量的基向量经线性拟合而成,线性拟合中非零元素表示该图像特征与相对应的视觉单词的相似度,使输入特征与输出特征表示之间的差值最小。稀疏编码通常构造一个目标函数,如②式所示。
②式中加了一个对ui的L1正則化约束,λ为正则化参数,向量ui只有一个元素为1,其余为0,||ui||1为稀疏惩罚项。
基于稀疏编码的视觉词典构造过程分为训练阶段和编码阶段。训练阶段通过不断迭代,使目标函数收敛到最小值,从而得到一组能够表示输入特征的特征基向量即视觉词典。编码阶段首先固定视觉词典V并调整U,使目标函数最小值时得到输入量所对应的稀疏向量,该稀疏向量就是输入特征对应于视觉词典的稀疏表示。
2.3 图像映射到视觉词典
图像表示是将图像特征及语义内容表示出来的过程,视觉词典生成后,统计每幅图像对应词典中的单词出现的频率,将每幅图像映射成一个K维的图像描述向量,其中K表示聚类中心的数量,即视觉词典中视觉单词的个数。
BoVW中的图像表示是一个将图像特征与视觉词典中的视觉单词进行匹配的过程,在特征匹配过程中,采用了快速最近邻逼近(fast approximate nearest neighbors,FANN)搜索策略,该算法指出最佳近邻搜索与数据集特性有关,采用分层聚类树算法用于搜索特定数据集[10]。采用该方法可实现快速图像特征匹配。
2.4 训练分类器分类
图像特征表示为频率直方图向量后,选择分类器进行分类。为精细化对同一种类中草药植物进行分类检索,需要采用细粒度的图像分类检索方案。本研究采用一种将SVM和近似最近邻(approximate nearest neighbors,ANN)分类相结合的方法完成分类器分类训练[11-12]。在分类阶段计算输入特征样本和最优分类超平面的距离,如果距离差大于给定阈值直接应用SVM分类,否则代入以每类所有的SVM作为代表点的ANN分类。该方法比单独采用SVM分类具有更高的分类准确率。
3 结果与分析
3.1 实验测试环境
实验测试采用操作系统Windows 7 SP1 64位旗舰版,处理器Intel Core i7-4790K,内存32GB(DDR3 1333 MHz),显卡芯片华硕GeForce GTX980 Ti,程序开发工具为MATLAB R2016b。
3.2 实验测试方案
为验证本研究提出算法的有效性,选取吉林大学长白山野外实习中草药图像数据库中2500张图像构建检索图像样本库,单张图像大小为640×480像素。待检索图像类别直接从样本库中随机选取,每次检索结果按照相似度由高到低排序,前9幅图像作为检索结果。长白山五味子图像检索结果见图4,第一幅图像为待检索图像本身。
结果的量化评价指标为查准率和检索时间。查准率指检索结果中用户满意图像数量与检索返回全部图像的比值。检索时间指图像检索程序CPU运行时间。分别采用不同数量视觉单词进行图像检索实验,计算平均查准率和平均检索时间,实验测试量化评价结果见表1。 表1显示,随着视觉单词数量的增加,平均查准率逐渐增高,检索时间也相应增长。基本可以满足用户对图像检索查准率及检索效率的要求。
4 结语
本研究对基于BoVW的图像检索方法在中草药图像检索中的应用进行了探索,提出了基于改进的BoVW图像检索方法。采用基于SURF方法提取和描述图像的视觉特征,并利用稀疏编码方法构造视觉词典,然后提出了一种SVM和ANN相结合的方法用于提升分类器分类训练的细粒度。结果表明,上述方法能有效提升图像检索效率和准确率,并保持传统BoVW算法的鲁棒性。
参考文献:endprint
[1] 刘富贵,于俊林.长白山区野生中草药信息库的构建[J].东北林业大学学报,2010,38(12):124-126.
[2] 王建勤,张兴运.基于内容的图像检索原理与应用于中药显微鉴定的前景展望[J].中草药,2001,32(2):180-182.
[3] 木提拉·哈米提,孙静,严传波,等.基于内容的医学图像检索技术在维吾尔药材图像检索中的应用前景[J].新疆医科大学学报,2015,38(7):819-822.
[4] 张祯伟,石朝侠.改进视觉词袋模型的快速图像检索方法[J].计算机应用,2016,25(12):126-131.
[5] PANCHAL P M, PANCHAL S R, SHAH S K. A comparison of SIFT and SURF[J]. Computer and Communication Engineering,2013,1(2):323- 327.
[6] 赵洁,涂泳秋,周苏娟,等.基于聚类-反馈机制的植物鲜药图像检索系统设计[J].中国中医药信息杂志,2016,23(8):10-12.
[7] 蒋芸,李战怀.基于改进的SVM分类器的医学图像分类新方法[J].计算机应用研究,2008,25(1):53-55.
[8] BAY H, TUYTELAARS T, VAN GOOL L. SURF:speeded up robust features[J]. Computer Vision and Image Understanding,2008, 110(3):346-359.
[9] 罗会兰,郭敏杰,孔繁胜.一种基于多级空间视觉词典集体的图像分类方法[J].电子学报,2015,43(4):684-693.
[10] MUJA M, LOWE D G. Lowe. Scalable nearest neighbor algorithms for high dimensional data[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(11):2227-2240.
[11] 李蓉,葉世伟,史忠植.SVM-KNN分类器—— 一种提高SVM分类精度的新方法[J].电子学报,2002,30(5):745-748.
[12] REN J, ANN V S. SVM: Which one performs better in classification of MCCs in mammogram imaging[J]. Knowledge-Based Systems,2012, 26:144-153.endprint
猜你喜欢
今日畜牧兽医(2022年10期)2022-12-23
今日农业(2022年16期)2022-09-22
今日农业(2021年17期)2021-11-26
口腔护理用品工业(2021年4期)2021-11-02
今日农业(2020年18期)2020-12-14
天然产物研究与开发(2018年7期)2018-08-21
家庭用药(2016年9期)2016-12-03
广东饲料(2016年7期)2016-12-01
西南军医(2016年6期)2016-01-23
兽医导刊(2015年13期)2015-12-16
