
基于高性能计算平台的TensorFlow应用探索与实践
2018-01-29 07:46:36王一超韦建文
实验室研究与探索 2017年12期
王一超, 韦建文
(上海交通大学 网络信息中心, 上海 200240)
0 引 言
深度学习作为近年来兴起的一种机器学习方法[1],可大幅提升包括图像识别在内的诸多模式识别问题的准确率。同时,该方法经由GPU大规模并行计算的助推,已经大幅缩短了其模型的训练时间,成为了学术与工业界炙手可热的机器学习方法[2-3]。当前,利用深度学习提升图像和语音识别精度的软件产品层出不穷,并且已大量应用于安防、人机交互、语音输入法等实际场景。在科研领域,越来越多的科学家也意识到了可以尝试利用深度学习替代传统的机器学习方法[4],提高模式识别或分类问题的精度[5]。在这一大背景下,为支撑校内高水平科研用户的需要,在校高性能计算平台上结合高性能计算软件栈的特点,部署了多款支持深度学习的软件框架,包括CNTK、MXnet、TensorFlow等。同时,在目前的交大超算平台上,利用TensorFlow框架下的图像识别模型训练,与最新的NVIDIA Minsky高性能工作站进行了性能对比测试,以验证平台对于深度学习应用的支持效果。
1 高性能计算平台
为应对校内各院系用户对计算需求的大幅增加,上海交通大学于2012年初成立校级高性能计算中心,挂靠校网络信息中心,为全校提供高性能计算的公共服务。该校级高性能计算平台于2013年建成并上线服务超算集群π,2013年6月世界排名158,国内高校第一,上海地区第一[6]。
1.1 硬件环境
π集群采用异构计算设计,计算资源由Intel至强多核处理器和NVIDIA GPU加速卡组成,经过2轮升级之后,目前整机的理论计算峰值性能为343TFlops,聚合存储能力达4PB,为国内高校领先的大规模GPU异构计算集群,具体硬件配置如表1所示。
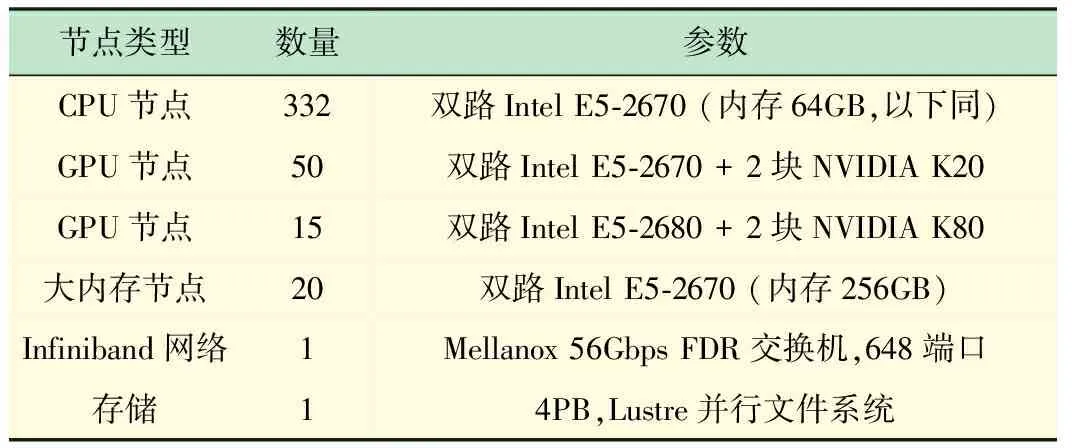
表1 π集群硬件配置
2016年发布的NVIDIA Pascal架构是目前最先进的GPU加速卡架构,相较于2013年建设集群时所采用的Kepler架构,不仅提升了浮点数运算能力和内存访问带宽,更支持了适应目前深度学习应用特点的半精度浮点数计算(即FP16)[7]。NVIDIA P100加速卡的半精度浮点数运算性能约为K80的单精度浮点数运算性能的逾3倍,由于深度学习对于精度要求较低,半精度即可胜任,所以现已在集群的GPU节点上部署测试P100加速卡。
1.2 软件环境
π集群利用module管理面向用户的全局软件环境,我们在集群上安装了诸多常用的开源软件及完整的编译环境,面向所有用户开放使用。用户仅需在自己账号下加载相关软件或者工具库,即module load指令,便可使用所需要的软件。这种配置方案节省了用户对于软件及编译环境的部署学习时间,同时我们对于全局软件环境的定期升级与维护,也保障了用户始终能在优化后的软件环境下运行计算作业,从而提升作业运行效率。
TensorFlow是由Google公司开发的一款支持不同深度学习应用的软件框架,在这款基于Python的软件框架上可以通过调用不同的程序接口,构建深度学习训练所需的流图,进行深度学习训练。目前人工智能领域最著名的案例,围棋软件AlphaGo正是基于该框架开发的[8]。TensorFlow今年刚刚推出了其1.0版本,目前更新速度较快,故本文中采用基于源代码的安装部署方式,目的是在于能使用最新的软件版本。以下将简述一下在π集群上部署TensorFlow的实践方法。
首先,用户需要加载正确的全局软件环境,包括完整的编译工具和GPU所需的CUDA并行库环境。
$ module purge
$ module load gcc/5.4 python/3.5 bazel cuda/8.0 cudnn/6.0
virtualenv是一款创建隔绝的Python环境的软件工具,它通过创建一个包含所有必要的可执行文件的文件夹,来解决依赖、版本以及间接权限问题。用户被允许在其HOME目录下创建一个Python的虚拟环境,然后使用pip管理所需软件包。
$ python3 virtualenv.py ~/python35-gcc
$ source ~/python35-gcc54/bin/activate
$ pip3 install numpy
用户通过git将TensorFlow源代码下载至其HOME目录下,并更新至最新版本,进行下一步编译和安装
$ git clone https://github.com/tensorflow/tensorflow
$ cd tensorflow; git checkout r1.0
利用bazel编译工具开启编译环境设置,在选项中,用户需要选择使用GPU,并指明CUDA和cuDNN的安装路径。
$ bazel build--config=opt--config=cuda //tensorflow/tools/pip_package:build_pip_package
用户最终将基于以上操作编译而成的基于pip的TensorFlow安装包安装到用户本地的python目录下。打开Python后,即可正常使用TensorFlow。
2 深度学习应用
深度学习中的卷积神经网络是由一个或多个卷积层和顶端的全连通层组成,同时也包括关联权重和池化层[9]。这种网络数学上就是许多卷积运算和矩阵运算的组合,而卷积运算通过一定的数学手段也可以通过矩阵运算完成。这些操作和GPU本来能做的那些图形点的矩阵运算是一样的。因此深度学习就可以非常恰当地用GPU进行加速了。
目前,交大高性能计算平台上的深度学习计算需求主要来自于语音识别和图像处理,计算机系和医学图像处理的团队对于在集群上利用GPU跑深度学习作业。当前他们的应用占了GPU应用的11%,仅次于传统科学计算领域的软件Amber,与GPU版本的Gromacs和Lammps相当(见图1)。
目前在π集群上使用最多的开源深度学习框架是Google公司开发的TensorFlow。TensorFlow是一个使用数据流图进行数值计算的开源软件库。数据流图中的节点表示数学运算, 数据流图中的边表示节点之间互联的多维数据数组[11]。而目前在图像识别领域使用最多的训练模型Inception,即如图2示例,是一个13层的网络模型。本文基于以上现状,在π集群上基于TensorFlow框架针对Inception模型进行测试实验[12],用以验证目前高性能计算集群对于深度学习应用的支持情况。

图1 π集群GPU应用利用率占比[10]

图2 TensorFlow框架下Inception模型的数据流图
3 性能分析
为分析深度学习应用在π集群上的实际性能,本文针对基于TensorFlow架构的Inception-V3模型进行训练性能的测试,图像测试集采用大规模数据集ImageNet,该数据集大小约1.5 TB,由逾22 000个种类和超过1 500万张图片组成。目前,国际上公认最具权威性的ImageNet国际计算机视觉挑战赛(ILSVRC)正是基于该数据集进行图像识别准确率的比拼的[13]。由于数据集体量较大,我们将ImageNet数据集下载并保存至π集群的并行文件系统上,以方便跨界点及多用户的共同访问。
3.1 测试环境
为了能和目前主流的深度学习专用工作站进行性能对比,本次实验不仅只在π集群的GPU测试节点(搭载了NVIDIA P100加速卡[14])上进行,我们还在同样搭载了NVIDIA P100加速卡且支持NVLink高速互联技术的IBM Minsky测试机上做了同样的训练测试。
如图3所示,NVLink高速互联技术相较于异构计算中常用的PCIe互联,访存带宽可以取得5倍的提升,从而缓解由主存与GPU显存之间传输效率低造成的性能瓶颈。具体的测试平台软硬件环境配置如表2所示。
3.2 性能结果对比
本文使用了ImageNet数据集训练Inception-V3图像识别模型,依次进行了1~4块GPU卡的训练测试,为保证负载的平均,batch值也相应做了调整,实验输入如表3所示。

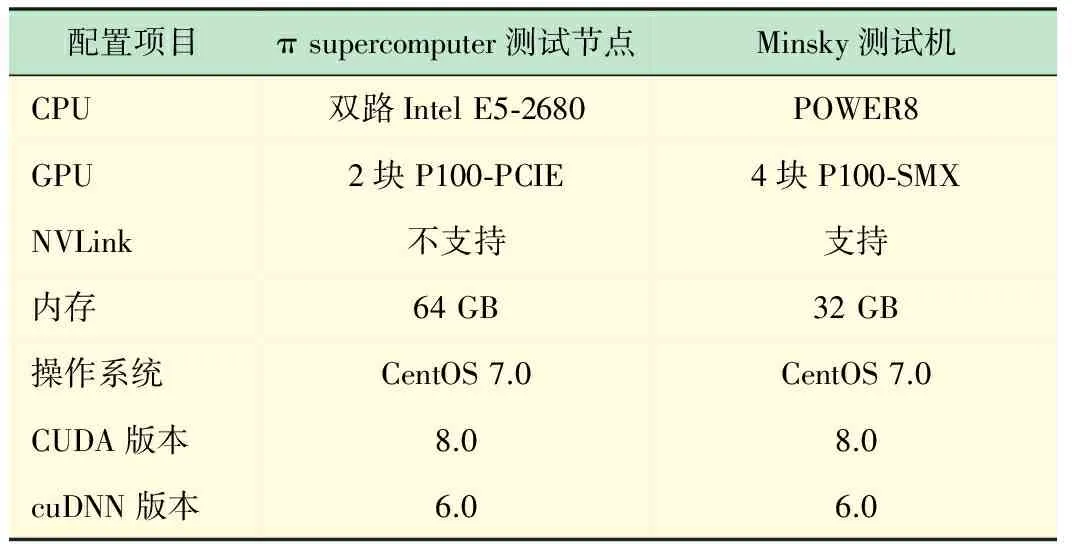
配置项目πsupercomputer测试节点Minsky测试机CPU双路IntelE5⁃2680POWER8GPU2块P100⁃PCIE4块P100⁃SMXNVLink不支持支持内存64GB32GB操作系统CentOS7.0CentOS7.0CUDA版本8.08.0cuDNN版本6.06.0

表3 深度学习应用测试输入
实验结果如图4所示,Minsky测试机相对于目前π集群的GPU单节点的1和2卡的性能非常接近,性能差在12%以内。而由于目前集群环境下的TensorFlow尚不支持分布式GPU节点并行,故无法在此情况下做相应对比测试,图4中展示了Minsky在4卡运行时的性能,相对之前的结果而言,呈线性增长。

图4 利用TensorFlow在Minsky和π集群上训练Inception-V3模型的性能对比
造成π集群节点与Minsky测试机上性能差异的原因主要有2点:①Minsky上配备的NVLink高速互联技术,提供了5倍于π测试节点上基于PCIe技术的传输带宽。从而使得数据在从主存传输至GPU设备内存的时间明显降低了,在1和2卡的实验中提升了性能;②Minsky测试机集成了4块P100-SMX GPU卡,该款加速卡相较于采用同样硬件架构的P100-PCIE版本,其核心的主频更高,因此计算能力有约16%的提升[15]。
综上所示,在2013年建成的π超算上成功部署了TensorFlow深度学习框架,在将GPU节点上的GPU加速卡从原有的NVIDIA Kepler架构升级至最新的Pascal架构后。在实验中,对比了其与2016年发布的Minsky测试机上Inception-V3模型的训练性能,实验结果显示性能差异在12%以内。由此可见,当前的集群硬件条件可以支持深度学习应用在单节点上的运行,但在未来的建设中,仍有待进一步考察高密度GPU节点对提升深度学习应用性能的帮助。
4 结 语
在这一轮新的人工智能大潮中,人们利用深度学习方法大踏步提升人工智能应用预期的同时,也越来越认识到计算性能对于未来人工智能能发展的重要性。日本政府近期也提出了发展面向人工智能的超级计算机战略。在高校一级的高性能计算平台上,人工智能的研究需求也理应得到满足,这就需要在已有的集群上更新软硬件环境,帮助用户更快地成功运行相关计算应用。本文分享了交大在高性能计算平台上配置部署深度学习软件框架,并实践对比了其与目前最先进的GPU工作站的性能,证明了校级高性能计算平台可以支撑深度学习用户的计算需求,但在分布式深度学习上的性能还有待评估。因为与传统的科学计算不同,深度学习应用由于极高的运算强度,对于多卡情况下的数据传输性能要求更高,故在工业界普遍采用单机多卡的高密度GPU节点方案[16],以提高其性能。在这一方面,在建设新一阶段的超算集群时,也可以对类似的高密度节点性能进行调研,以评估其实际应用价值。
[1] 李 航. 统计学习方法[M].北京:清华大学出版社,2012.
[2] 余 凯, 贾 磊, 陈雨强, 等, 深度学习的昨天、今天和明天[J]. 计算机研究与发展, 2013, 50(9): 1799-1804.
[3] 张建明,詹智财,成科扬,等.深度学习的研究与发展[J]. 江苏大学学报:自然科学版, 2015,36(2): 191-200.
[4] LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[5] 张焕龙, 胡士强, 杨国胜, 基于外观模型学习的视频目标跟踪方法综述[J]. 计算机研究与发展, 2015, 52(1): 177-190.
[6] 林新华, 顾一众, 上海交通大学高性能计算建设的理念与实践[J]. 华东师范大学学报(自然科学版),2015(S1): 298-303.
[7] GP100 Pascal Whitepaper [EB/OL]. https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf
[8] Silver D, Huang A, Maddison C J,etal. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587):484-489.
[9] 周志华.机器学习[M].北京:清华大学出版社,2016.
[10] 上海交通大学高性能计算中心年度报告2016[EB/OL]. http://hpc.sjtu.edu.cn/report2016_170607.pdf.
[11] 黄文坚, 唐 源.TensorFlow实战[M].北京:电子工业出版社,2017.
[12] Installing TensorFlow from Sources [EB/OL]. https://www.tensorflow.org/install/install_sources.
[13] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
[14] Deep Learning Performance with P100 GPUs[EB/OL]. http://en.community.dell.com/techcenter/high-performance-computing/b/general_hpc/archive/2016/11/11/deep-learning-performance-with-p100-gpus.
[15] Inside Pascal: NVIDIA’s Newest Computing Platform [EB/OL]. https://devblogs.nvidia.com/parallelforall/inside-pascal/.
[16] 顾乃杰, 赵 增, 吕亚飞,等, 基于多GPU的深度神经网络训练算法[J]. 小型微型计算机系统,2015(5): 1042-1046.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
电子制作(2017年19期)2017-02-02 07:08:49
知识就是力量(2017年2期)2017-01-21 18:29:36
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
山东工业技术(2016年15期)2016-12-01 05:31:04
