
一种基于半监督学习的工控网络入侵检测方法
2018-01-29 01:42张松清刘智国
网络安全与数据管理 2018年1期
张松清,刘智国
(中国电子信息产业集团有限公司第六研究所,北京 100083)
0 引言
当前,工控网络重要性日益凸显。随着计算机和网络技术的发展,工业控制广泛采用开放的工业通信协议、网络设施和通用软硬件,甚至与互联网和企业管理信息系统交换数据,针对工控网络的攻击也快速增多。工控领域的网络威胁极大地危害工业控制的正常运行,使得工业控制系统的脆弱性开始逐渐显现,针对工业控制系统的攻击行为快速增长[1]。2010年爆发的“震网”病毒、2012年的“火焰”超级病毒以及2014年的Havex 病毒等专门针对工业控制系统的病毒给用户造成了巨大的损失,同时也威胁到了国家安全。分析此后2015年发生的乌克兰电力遭受攻击事件,可以看出攻击的成本在降低,而攻击所带来的影响在进一步加重。2017年5月WannaCry勒索病毒席卷全球,影响到近百个国家上千家企业及公共组织。
工业控制系统是为了完成各种实时控制功能而设计的,当初并没有考虑到安全防护方面的问题,通过网络互联使它们在网络空间中暴露,无疑将给它们所控制的重要系统、关键基础设施等带来巨大的安全风险和隐患。为了避免工控安全事件的发生,有效地对网络攻击进行检测及提前预防显得至关重要。
目前已经有许多基于规则匹配的网络入侵检测方法[2],这类方法对已知的病毒、木马等威胁的检测效果明显。目前基于智能学习的网络入侵检测研究已成为趋势,包括支持向量机(SVM)、朴素贝叶斯网络、神经网络等。这些方法对有监督分类问题效果明显,而工控网络流量数据已有大量标记好的异常流量数据以及大量的无标注流量,有监督分类方法并不适合解决这一问题。本文提出一种基于半监督机器学习的工控网络入侵检测方法,该方法的运用能够提高未知威胁的检测能力。
1 入侵检测技术
1.1 概述
入侵检测技术是一种主动的保障信息安全的技术,可以有效弥补防火墙等传统安全防护技术被动防御的缺陷,因此针对复杂的工控系统网络攻击,入侵检测技术是有效发现和防御入侵的防护手段。
入侵检测技术包括特征检测和异常检测。特征检测有较高的检测准确率,存在的问题是无法检测未知的攻击;异常检测有较强的通用性,可以对未知攻击进行检测,有比较广阔的应用前景,其主要缺陷是误检率较高。
1.2 机器学习方法
机器学习是人工智能的核心。当前,已有大量基于机器学习的入侵检测技术的研究,包括基于聚类分析、数据挖掘、行为统计、神经网络等技术的入侵检测方法[3-4],然而这些技术存在处理速度慢、模型难以建立、误报率高、纯净训练数据难以获取等不足,无法满足工控系统较高的实时性和可用性要求。
研究基于机器学习的入侵检测技术对建立智能化的高效入侵检测模型,提高工控网络异常行为检测精度意义重大。本文针对工控系统网络数据的特点,提出一种基于半监督机器学习[5-8]的入侵检测方法,该方法可以提高网络攻击流量的检测准确率。
2 基于半监督学习的入侵检测方法
2.1 技术架构
该入侵检测技术由四个主要的功能模块组成,分别是网络数据获取、特征提取、模型训练以及网络流量检测,各主要模块之间相对独立,总体架构如图1所示。
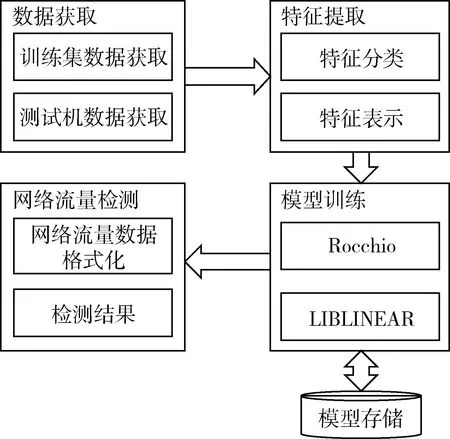
图1 系统总体架构图
2.2 模块设计
2.2.1网络数据获取
使用机器学习训练模型时,需要利用正负样本数据集。对于工控系统网络入侵检测,正样本数据就是入侵的异常网络流量,负样本为正常网络流量。
对于正样本数据,即入侵的异常网络数据,目前已有一些机构进行了标记,例如KDD99(MIT Lincoln实验室提供的1998 DARPA入侵检测评估数据集)以及密西西比州立大学关键基础设施保护中心于2014年提出的用于工控系统入侵检测评估的数据集等。但很少有对正常流量的标记,在实际网络数据中,标记样本需要人工完成,耗时耗力,而未标记样本既容易获取也非常充裕。
2.2.2特征提取
在某个时间周期内对网络流量进行捕获,这些网络流量由多次的TCP网络连接数据组成,每一次完整的TCP连接作为一次记录,对每次记录进行分析,统一处理。特征提取方式参考KDD99数据集的提取方式,共计41个特征,如表1所示。

表1 网络数据特征提取
这些特征中有的是数值型,有的是字符型,但是本文中的技术只能处理数值型的向量,因此,在模型训练之前需要先将输入数据作数值化处理以及正规化处理。例如,协议类型(TCP、UDP以及ICMP)可以用1、2和3表示;每条记录是否是攻击流量用1和-1表示,1代表正常流量,而-1表示攻击流量。
2.2.3模型训练
针对获取到的网络流量数据特点,该技术采用半监督分类的方式来训练模型。该方法结合了Rocchio以及LIBLINEAR[9]两种技术。
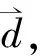
(1)
其中,α和β是调整训练样本相关与不相关性的影响参数。在分类中,对于每个测试集网络流量数据td,使用余弦相似性的方法来计算td与每个原型向量的相似性,td与哪个原型向量更相似,就把该原型向量的类型赋给td。
LIBLINEAR是由LIN C J博士设计和开发的,它是为线性分类问题而设计的。使用LIBLINEAR时,可以容易地处理百万到千万级别的数据,这是因为LIBLINEAR本身就是设计用于解决较大规模样本的模型训练。
模型训练的思路是先使用Rocchio技术从大量的未标记网络数据中挑选出可信赖的正常网络数据,然后再使用LIBLINEAR技术训练模型。该算法如图2所示。
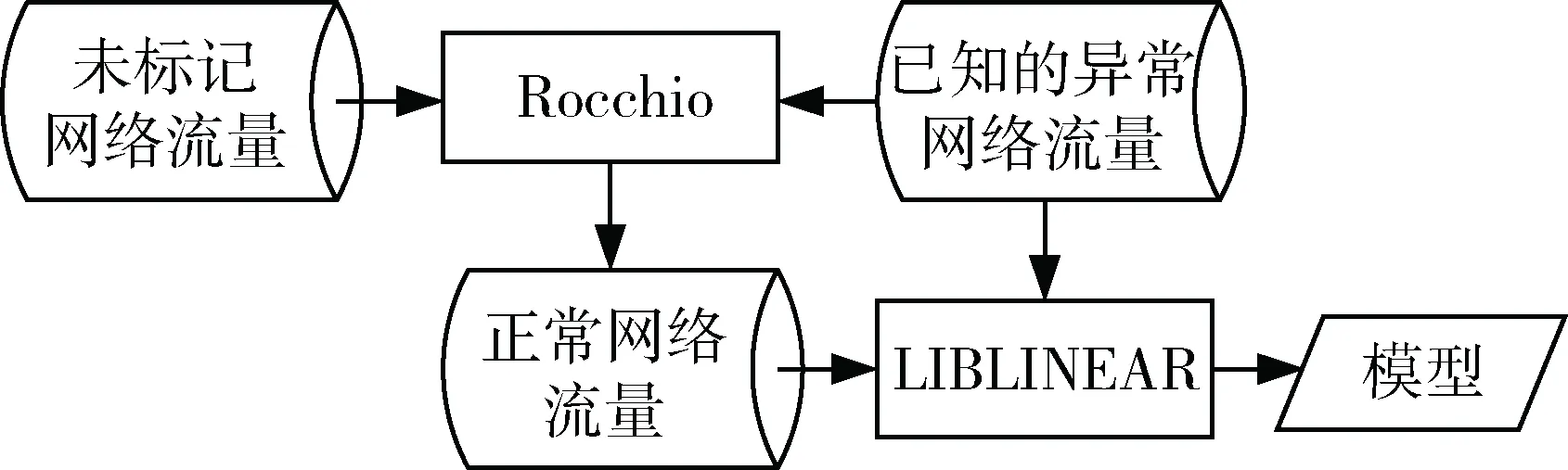
图2 半监督分类方法流程图
本文设计了一种使用Rocchio技术来从未标记网络数据(记为U)中提取可靠的负样例数据(记为RN)的方法,其中正样例数据记为P,算法的伪代码如公式2所示。
1. 将未标记网络流量数据U赋值成负类,正样本网络流量数据P赋值成正类
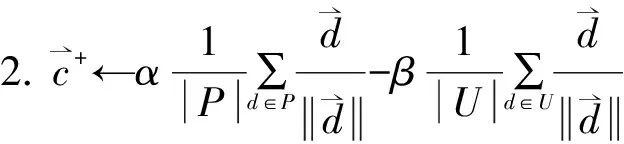
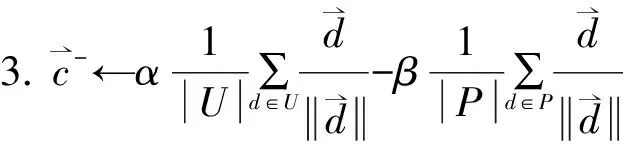
(2)
4. forU中的每条网络流量d′ do
6. RN←RN∪{d′}
在基于正样本的学习方法中,未标记数据集U中的负样本数据通常包含多种类型,在向量空间中,占有很大区域,而正样本数据通常是同一类型的,覆盖一个小得多的区域,如图3所示。Rocchio是线性分类器,假设真的有一个决策面S能够区分正负样本,那么,由于Rocchio中的向量叠加原理,正原型向量会比负原型向量更接近决策面S,这种方式识别出的负样本数据纯度很高。
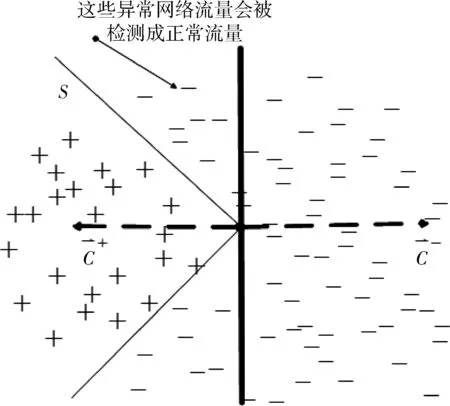
图3 Rocchio分类效果图
Rocchio学习到的模型通常比LIBLINEAR弱,而噪声对LIBLINEAR技术影响较大。为了更好地分类,本文提出将Rocchio与LIBLINEAR结合。使用Rocchio从U中提取出RN后,再使用P和RN来运行LIBLINEAR,最后生成一个分类效果较好的模型。
2.2.4网络入侵检测
通过机器学习算法获得了检测异常网络流量的模型后,可以用来对未知网络流量数据进行检测。流量检测流程如图4所示。先对待检测数据使用相同的特征提取过程,然后利用训练好的模型进行检测,从而识别出正常网络流量和异常网络流量。
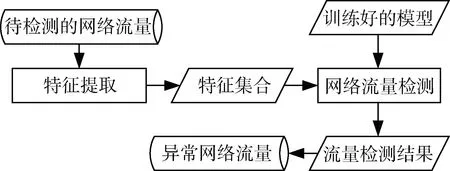
图4 网络流量检测流程图
3 验证与分析
3.1 实验结果
本文采用KDD99数据集进行实验,KDD99训练数据集包括494 021条记录,测试集包括311 029条记录。训练数据集中有22种攻击类型,测试集中增加了14种新的攻击类型。在测试检测算法时,使用指标precision和recall进行评估,其定义为:
(3)
(4)
检测的结果precision和recall值越高,效果越好,但实际上这两者并没有必然的关系。在实际应用中,两者也是相互制约的,因此,需要新的指标将二者结合,其中一个重要的指标就是F-measure。公式如下:
(5)
如果precision和recall同等重要,β值设为1,这样得到的结果称为F1。如果β比1大,recall比precision更重要;如果β比1小,precision比recall更重要。在网络入侵检测的研究中,recall(不遗漏任何异常流量)比precision(没有把正常流量识别成异常流量)是更重要的。没有检测出异常流量可能会导致网络入侵,或者对系统安全留下了隐患。因此,本文同时选取F1、F2及F3进行评估。
实验中从KDD99的训练集中随机选取10 000条异常网络数据作为训练集的正样本数据集,然后使用Rocchio方法从KDD99训练集中的剩余样本中识别出10 000条正常数据作为负样本数据,再使用LIBLINEAR进行模型训练。实验的测试集为从KDD99测试集中随机选取的6 000个样本,其中正样本数据1 550个。实验结果如表2所示。

表2 实验结果
表1中的检测结果依赖于各个环节的处理,技术实现时尽可能对各个部分进行了优化。
3.2 实验对比及影响因素分析
在本文的的半监督分类方法中,只有正样本数据,没有负样本数据。有一种方法可以只利用一种类型的数据进行模型训练,例如one-class SVM,实验发现使用one-class SVM方法,只用异常网络流量数据训练模型时,检测结果并不好,precision和recall值不足0.6。另外,Liu Bing等人实现了一种半监督分类工具,并且提供二进制文件下载[10]。该分类工具中包含S-EM和Roc-SVM两种方法,实验发现,S-EM检测结果中绝大多数测试集数据被识别成正样本数据,而Roc-SVM则刚好相反,对于本实验来说,效果并不理想。
本文中技术实现时包含很多环节,许多因素会对检测结果产生影响。其中一个因素是特征提取环节,选取不同特征对模型训练会有很大影响;另外一个影响因素是测试数据的选取,算法对网络异常流量检测具有通用性,但是针对不同的数据集,还需对算法的处理细节进行调整。
4 结论
工控系统的应用已经变得普及,工控网络也逐渐与互联网开始融合,使得工业控制系统的脆弱性正在逐渐显现。本文针对工控网络数据特点,结合多种机器学习算法,设计了一种基于半监督机器学习的入侵检测技术,使用该技术可以有效地检测出工控系统网络中的异常流量,从而及时发现和防御入侵攻击。未来的网络攻击变种会更具欺骗性,关于准确性这一问题还需要进行更具创新性的研究和更多细致完善的工作。
[1] 刘广生, 张松清. 智能电网信息安全威胁及对策分析[J]. 微型机与应用, 2017,36(5):8-10.
[2] 程冬梅, 严彪, 文辉,等. 基于规则匹配的分布式工控入侵检测系统设计与实现[J]. 信息网络安全, 2017(7):45-51.
[3] 罗耀锋. 面向工业控制系统的入侵检测方法的研究与设计[D]. 杭州:浙江大学, 2013.
[4] 杨安, 孙利民, 王小山, 等. 工业控制系统入侵检测技术综述[J]. 计算机研究与发展, 2016, 53(9):2039-2054.
[5] 刘建伟, 刘媛, 罗雄麟. 半监督学习方法[J]. 计算机学报, 2015,38(8):1592-1617.
[6] 牛罡, 罗爱宝, 商琳. 半监督文本分类综述[J]. 计算机科学与探索, 2011, 5(4):313-323.
[7] 杜芳华. 基于半监督学习的文本分类算法研究[D]. 北京:北京工业大学, 2014.
[8] 谭建平, 刘波, 肖燕珊. 基于半监督的SVM迁移学习文本分类算法[J]. 无线互联科技, 2016(4): 71-75.
[9] Fan Rongen, Chang Kaiwei, HSIEH C J, et al. LIBLINEAR: a library for large iinear classification[J]. Journal of Machine Learning Research, 2010, 9(12):1871-1874.
[10] Liu Bing, Li Xiaoli. LPU: learning from positive and unlabeled examples[EB/OL].(2003-07-10) https://www.cs.uic.edu/~liub/LPU/LPU-download.html.
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
中学生数理化·高一版(2021年2期)2021-03-19
知识经济·中国直销(2018年8期)2018-08-23
北京航空航天大学学报(2017年7期)2017-11-24
中国设备工程(2017年8期)2017-05-10
中国设备工程(2017年7期)2017-04-10
数学学习与研究(2017年3期)2017-03-09
信息安全与通信保密(2016年3期)2016-08-23
自动化学报(2016年5期)2016-04-16
