
基于jsoiip的Web页面自适应转换系统的实现
2018-01-28 10:55顾问曹阳
电子技术与软件工程 2017年18期
关键词:自适应
顾问+曹阳
摘要
本文针对传统Web应用程序无法适配移动终端的问题,设计了一种基于jsoup的Web页面自适应转换系统,暑重对系统中文本信息提取和前端页面重组技术进行了研究分析,讨论了具体的实施方法,解决了Web页面自适应转换技术限制,为传统Web应用程序升级过程中提供了一种降低成本的有效方法。
【关键词】jsoup 自适应 转换系统
随着移动互联网的快速发展,Web应用程序能够适配多种终端己成为一种趋势。虽然已有一部分Web应用程序在升级改版过程中直接采用了响应式设计的方式,但由于系统升级改版存在的工作量大、成本高等问题,国内仍然有很多Web应用程序仅支持PC端访问,针对移动终端的开发工作进展十分缓慢。这也就意味着当用户使用PC的浏览器访问网页时能够正常显示,当用户使用移动终端的浏览器访问网页时,会出现文字和图片缩小显示的情况,导致用户只能在移动终端上对Web页面进行拖曳、放大等手势操作,与Web页面交互极为不便,用户体验较差。针对以上问题,本文提出了一种基于jsoup的Web页面自动转换系统,通过Web页面信息抽取、前端处理等相关技术将传统的Web页面转换为响应式Web页面,从而打破了移动终端无法适配传统Web网页的技术性限制。
1系统总体设计
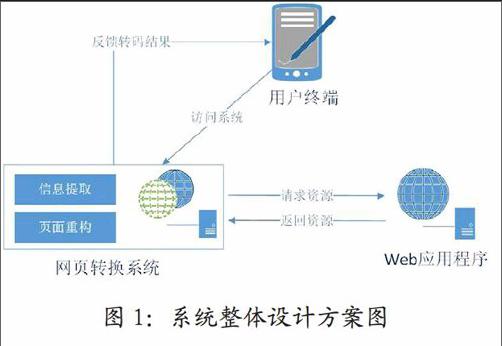
Web应用程序都部署在应用所有者的专用服務器中,非应用所有者无法对该应用程序直接进行修改,用户通过移动终端直接访问Web应用程序无法达到Web页面自动转换目的。因此,本文提出的Web页面自适应转换系统需要通过用户终端访问网页转换代理服务器来完成对目标Web应用程序的资源请求任务,网页转换代理服务器对请求返回的资源进行信息提取和页面重构工作,仅做资源加工处理而不进行资源存储,代理服务器直接将转码结果反馈给用户的访问终端。Web页面自适应技术方案的整体结构如图1所示。
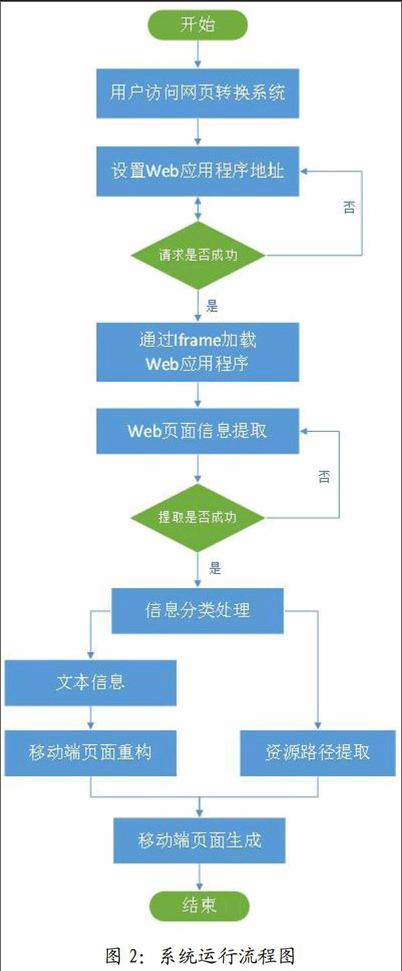
Web页面自适应转换系统的具体运行流程如图2所示。用户使用移动终端访问己部署Web应用程序转换系统的代理服务器,设置目标Web应用程序网络地址,网页转换系统通过Web页面的iframe浮动框架技术请求加载Web应用程序,方便用户观察目标Web应用程序是否能够正常访问。当Web应用程序加载完成后,网页转换系统的信息提取模块基于jsoup对Web页面进行信息提取工作,主要分为文本信息提取和资源路径的提取。文本信息提取是指提取目标网页中的重要文本内容,例如导航、信息列表、正文等;为了保证转换完成的网页继承目标网页的整体风格,资源路径提取是指通过代理服务器提取目标网页中资源路径,例如网页头部加载的CSS,Javascript以及文本内容对应的超链接。最后,基于Web前端处理技术将目标网页重构为适合移动终端访问的响应式页面,同时加载提取的资源路径,将最终生成的移动端页面反馈给用户。
2关键技术分析
2.1文本信息提取技术
本文提出的Web页面自适应技术通过网页转换代理服务器来向目标Web应用程序请求资源,每一次资源正确加载完成后,网页转换系统需要执行Web页面信息提取任务,其可以分解为Web页面文本提取和资源路径提取两项子任务。Web应用程序整体的资源路径通常会定义在Web页面头部,通过对页面头部进行HTML标签解析很容易能够获得。Web页面文本提取相对比较复杂,这也正是本文研究的Web页面自适应转换系统的关键技术之一。对国内外的文献进行分析可以发现,Web页面的文本提取技术基本可以分为两类:基于DOM的Web页面文本提取技术和非基于DOM的Web页面提取技术。通常很多研究者会采用基于DOM的Web页面文本提取技术,其技术发展比较成熟。Web页面的标签和标签之间、标签和内容之间都存在着层次关系,DOM树是描述Web页面结构的常用方法,DOM树的叶子节点通常就是要提取的文本信息。因此,通过一定的算法对Web页面的DOM树进行遍历,进行相应的筛查降噪处理之后,可以得到目标的文本内容。在实际的应用过程中,利用Web页面解析工具进行页面解析,并修正其中不规范的地方,构建Web页面的DOM树并进行递归遍历,识别其中的非主要文本信息,比如广告、图像等内容,将噪声节点移除即得到文本信息。比较经典的方法如2007年刘秉权等人提出的基于结构树解析的网页正文抽取方法。该算法除了把分散的Web页面解析为有序的DOM树以外,还利用了中文网页页面结构相似及文本信息分布聚集的特性,在移动平台的新闻信息自动分类系统中得到了很好的应用。文献2《网页信息提取与净化的研究》提出了一种让用户设置参数来对Web页面构建的DOM树进行节点筛查处理方法,并实现了对同一模板的Web页面集合可进行自动降噪处理,增强了系统的通用性和交互性。孙明柱等人提出了基于结构树的网页正文内容抽取方法,该算法思路是先需要对Web页面进行分块处理,处理结果同样利用DOM树原理进行解析,然后集合阈值计算和正则表达式,对于处理网页正文准确率较高。非基于DOM的Web页面提取技术比较著名就是微软亚洲研究院提出的VIPS基于视觉的网页分块算法。该算法从用户的视觉感官体验出发,根据Web页面的背景色、前景色、元素之间的间距来对Web页面进行视觉划分,建立相应的分割条和网页分块集,基于此基础再进行文本信息的抽取,算法规则十分复杂。目前很多Web页面的视觉特点也很复杂,VIPS算法针对此类页面时准确率和效率较差。因此,高乐等人提出一种改进的VIPS算法,算法针对标签的处理进行优化处理,并通过实验证明了改进算法正确率得到了提升。此外,还有一些不基于DOM树对网页文本提取的方法,例如《基于权值优化的网页正文内容提取算法》的通过统计分析Web页面正文内容特点,得到页面中各个文本内容块属性特征,并使用粒子群优化算法对特征权值及阈值进行了确定及优化。
综上所述,两大类Web页面的文本提取技术各有优缺点。基于DOM的Web页面文本提取技术相对成熟,可选择应用工具较多,例如HTMLparser、jsoup、nsoup都是常用的基于DOM的Web页面解析工具,通过对工具进行了系列的分析比较之后,最终选用了jsoup作为基础的文本信息提取工具。jsoupHTML解析器,可直接解析某个URL地址、HTML文本内容。提供了一套非常省力的API,可通过DOM,CSS以及类似于jQueiy的操作方法来取出和操作数据。同时,jsoup还支持对HTML文档进行清理,十分有利于Web页面转换系统的实现。为了降低研究对象的复杂度,选择了市场占有率较高的商用CMS系统(WebPlus)作为研究对象,该网站系统支持用户自定义网站模板,Web页面分块中的ID或者NAME属性值部分遵循Web标准的语义,例如页面的导航部分会出现“nav”关键字,处理相对比较容易,系统中建立关键词库进行自动匹配和识别;还有一部分页面分块ID或者NAME属性仅是定义模板时的专用编码,属性值并不遵循语义,可以根据编码的大小来决定文本信息出现的排列顺序,但也需要人为干预来进行辨识页面分块是否为预期的文本内容。

2017年24期
- 行业动态
- 工信部:5G发展进入第二阶段近期将发布测试最新成果
- 工信部:加快关键技术标准研制推动5G与车联网融合发展
- 电子商务为金砖合作未来十年注入新动能
- 半导体产业升级的关键——人工智能
- 90后乐当护理员 家政服务类APP更是刮起了龙卷风
- 聚焦网络空间安全 腾讯安全玄武实验室课题受关注
- 院校巡礼
- 创建文明城市做文明燕大人
- 网络天地
- 基于移动互联网气象服务的方法
- 物联网技术在医院信息化中的应用
- 软件工程技术在网络时代的发展
- 基于云服务的高校教学实践平台
- 贵州地区LTE网络的优化方法
- 利用现有网络推进信息化技术的发展
- 网络爬虫技术在电力产业中的应用
- 基于SNMP协议的通用数据采集系统
- 基于IP的全业务本地传输承载网架构及融合策略
- ASP动态网页技术
- 网络技术在电力通信中的应用
- P2P系统中一种负载均衡的超级节点选择策略
- 分布式网络爬虫框架Crawlzilla
- 人工智能在计算机网络技术中的应用
- 自媒体时代网络舆情危机应对策略
- 计算机网络技术在人工智能中的运用
- “互联网+3D打印”商业模式分析及建议
- 在线视频招聘模式发展前景
- 计算机网络技术中人工智能的应用
- 高职院校网络管理系统构建方法
- 计算机网络技术在电子信息工程领域中的应用
- 通信技术
- SDH理论、应用及发展
- 提高设备可靠性确保飞行安全
- 基于车载自组网的匿名认证机制
- 基于NFC技术下的近场通信Wi—Fi传输连接方案
- 无线电子通讯技术应用安全
- 广播电视信号传输技术及实施要点
- HTTP通信中常见认证方式的安全性分析
- 第五代移动通信技术浅析
- 地铁无线传输系统的构想
- 通讯技术在高铁中的应用
- 软件开发
- 基于Web的企业信息管理系统的设计开发
- 计算机软件开发技术的现状及应用
- 基于Java的飞行棋的设计与实现
- 故障定位系统的云服务器软件
- 秦皇岛旅游气象服务系统设计及实现
- 分层技术在计算机软件设计中的应用
- 河北省远程医疗云平台设计
- 医院门诊电子排队管理系统的建设
- 面向不同浏览器的B/S系统兼容性
- 基于Qt的无人直升机地面显控终端软件设计
- 软件开发技术在软件工程管理中的应用
- 基于MFC和Access的航电加载数据管理软件设计与实现
- 试析面向软件工程数据挖掘的开发测试技术
- 光学镜头光学机械一体化CAD软件设计的研究
- 空运物流监控系统设计
- 基于Zigbee的智慧校园空调管理系统设计与实现
- 软件应用
- Excel在办公中的应用
- 视频教学资源的格式转换技巧
- 计算机软件技术中插件技术的运用
- 东屹讯流媒体系统在智慧江都项目建设中的应用
- Photoshop的抠图技术的分析
- 微信平台在高校教学管理中的应用
- Excel电子表格软件在学生成绩统计分析中的有效应用
- 针对Java Web应用中错误异常处理方法的运用
- 云计算在互联网软件中的应用
- 图像与多媒体技术
- 基于Authorware三视图模拟识图系统的实现
- 博物馆虚拟成像技术的有效运用
- 基于张量高斯混合模型的SAR图像分割
- 基于自适应正则化的核模糊C—均值聚类图像分割
- 基于计算机视觉的昆虫识别的研究
- 数字图像处理技术及其应用
- 机载任务系统三维图形显示交互技术研究
- 纸币新旧检测的数字图像处理方法
- 电子技术
- MATLAB在数字信号处理中的应用
- 单片射频收发器下的无线测温系统设计
- 对脑电信号特征的驾驶疲劳检测方法
- 血糖检测中信息处理的理论与方法
- 电子仪器状态检测与典型故障的虚拟诊断技术
- 变频器驱动电路故障及其检修
- 变频技术在甲醇装置中的应用
- 基于MATLAB的雷达信号处理仿真
- 提高集成电路电磁兼容性的方法
- 控制工程在机械电子工程中的应用
- 硬盘播出系统中上载对安全播出的影响
- 基于DSP的雷达伺服控制系统
- 视觉信息下移动机器人目标识别算法
- 电路模拟技术在吸波结构中的应用
- 国内空间电子对抗技术发展对策
- 基于二维激光传感器的三维图像获取系统
- 燃煤锅炉超低排放后CEMS系统的优化完善
- 一种新型伪随机码编码机制
- 无人机任务规划系统
- PAE T6T与FA16 M线直接连接会造成长发的原因
- 电视产品ESD防护之接地系统设计
- 声波信号发射机设计与实现
- Simulation和Emulation方式模拟机性能对比分析
- 基于机器学习技术的机车音频文件自动分析系统的研究
- 智能电表用晶体谐振器选用及注意事项
- 一种基于DDS芯片AD9959的高精度信号发生器
- SMA—JB2A/SMA—JB2A—L型电缆组件的研制
- 自动化控制
- 基于工业自动控制系统抗干扰措施及其运用
- 220kV智能变电站继电保护及自动化
- 电气自动化技术在电气工程中的应用
- 电网调度自动化系统常见故障及处理
- 自动化控制在矿山提升机中的应用
- 控制系统中PLC对故障诊断的作用
- 污水厂自控及仪表系统的技术
- 基于PID算法板球控制系统的设计
- 机械制造业中自动化技术的应用
- 工业机器人在冲压自动化生产线中的设计与应用
- 基于矩阵编码的自动路测根因定位方法
- 楼宇自控的发展趋势及其安全技术
- 机械制造及其自动化的发展趋势分析
- 基于S7—1200PLC的钢铁企业空压机集中管控系统
- 船舶电气主要技术及发展趋势探究
- 计算机技术及应用
- 中职学校计算机机房的安全运行
- 计算机技术在通信领域的应用前景
- 双序列比对算法的研究与改进
- 计算机编程技术演变过程及发展趋势
- 计算机信息管理系统在财务管理中的应用
- 计算机软件工程管理与应用
- 虚拟云技术下无纸化考试的研究与应用
- 计算机程序抄袭检测系统的设计方案
- 计算机技术在医学信息处理中的应用
- 计算机科学与技术的现代化运用
- 基于混沌粒子群算法的多目标二维切割问题
- 高校多功能会议室建设的研究
- 可信技术在电力业务保障中的应用
- 数据库技术
- 基于Hadoop系统大数据平台在天津市地震局的应用
- Hadoop框架在电力大数据平台中的运用分析与研究
- 论述如何利用大数据推动计算机审计
- 中医远程医疗体系架构与运行机制研究
- 一种混合编程技术在宏观经济监测预警系统中的应用
- 基于大数据的电网运检项目资金完成率路径分析模型
- ORACLE数据库的使用技巧及维护要点
- 船舶及海洋结构物声振激励源预报模型分析
- 基于信息系统的医院后勤管理模式
- 存储虚拟化的优缺点及需求
- 大数据环境下图书馆的发展与转型
- MySQL数据库系统在教辅系统中的应用
- 基于云计算的政府智能数据服务平台研究与设计
- 云计算技术发展分析及其应用
- 点类应用场景监控布点模型
- 高清数字电视数据传输技术
- 数据可视化技术及其应用展望
- 计算机Oracle数据库的优化措施
- 基于FPGA的远程心电监护数据AES加密
- 基于ASP计算机应用基础课程网上考试系统设计
- 航显设备监控系统在机场中的应用
- 医疗大数据的疾病关联分析
- 企业信息系统应用控制设计工作程序
- 军工单位保密知识考试系统的设计
- 大数据分析在移动通信网络优化中的应用
- 高可靠长寿命产品可靠性建模与RUL预测方法
- 基于气象的空中交通管制实时决策专家系统的设计与实现
- 主配网调控一体化过程中图形平台的设计
- 基于代码分析的应用性能可视化
- 大数据条件下的数据挖掘技术及应用
- 一种基于城市物联网基站的智慧城市照明管理系统
- 基于jsoiip的Web页面自适应转换系统的实现
- 网上图书管理系统的设计
- 嵌入式技术
- ARM嵌入式Linux系统的实现
- 信息安全
- 烟草企业网络安全防护体系建设
- 机关单位计算机网络信息安全及策略
- 建立自主可控的网络安全体系
- 无线局域网安全接入技术的应用
- Web应用防火墙绕过技术
- 计算机网络的信息安全体系结构
- 提高智能电能表信息安全性的策略
- 关于大数据时代下网络安全建设的分析
- 网络安全技术在计算机维护中的应用
- 计算机病毒及防范措施
- 计算机信息管理技术在网络安全中的应用
- 高信息时代的商业网络隐患的防范技术
- 数据时代电子商务中交互信息的安全性
- 计算机恶意软件的危害及防范
- 计算机通信网络安全与防护策略
- 探索构建三网融合下广播电视网络安全对策
- 解读计算机网络信息管理及其安全防护策略
- 电力电子
- 高山发射台防雷接地系统的实践
- 输电线路光缆故障问题与解决方法
- 电气常用低压配电技术
- 电力变压器绕组变形的诊断
- 高压电气绝缘试验中常见的问题
- 富春江电厂定子局放在线监测在1号发电机中的应用
- 基于微电网孤网运行情况下的继电保护
- 农村电网智能化建设的关键技术
- 电力调控系统运行风险问题
- 建筑弱电智能化系统工程应用
- 基于节能降耗的电力计量技术应用创新
- 智能变电站的研究与应用
- 电力设备状态监测技术的运用
- 电力电子技术应用系统发展热点
- 优化配电变压器极限线损率的措施
- 220kV智能变电站检修二次安措优化技术
- 电力继电保护装置问题及防范对策
- 电力系统中智能变电站的继电保护技术
- 当前矿山机电设备维修中故障诊断技术运用问题探讨
- 智能变电站关键技术及其构建方式的探讨
- 医院配电房的改造方案
公司地址: 北京市西城区德外大街83号德胜国际中心B-11
客服热线:400-656-5456 客服专线:010-56265043 电子邮箱:longyuankf@126.com
电信与信息服务业务经营许可证:京icp证060024号
Dragonsource.com Inc. All Rights Reserved


2.2前端处理技术
本文研究Web页面自适应转换系统最终目的是将传统的Web页面转换为响应式Web页面,当页面文本信息和资源提取完成后,还需要通过前端处理技术进行Web页面重构,因此前端处理技术也是系统的关键技术之一。构建响应式Web页面一般主要以使用原生代码和基于前端框架两种方式。使用原生代码可以使得转换系统的前端响应式处理部分显得更为简洁,但是开发调试和页面集成测试工作量较大。基于前端开发框架成熟度较高,可以减少很多开发工作量,但是其中很多内容是不需要用到的,会导致系统代码臃肿,需要花费时间去做裁剪。对于Web页面自适应转换系统而言,原始的文本信息己经过处理,不需要考虑很多复杂情况,使用原生代码的方式更为合适。因此,首先需要将提取得到的信息内容进行单元划分,每一个单元中的内容相互关联,利用HTML标记将单元进行结构化定义,使用CSS3MediaQuery功能进行Web页面布局方面的自适应调整,并使用CSS设定文字大小和加载背景图片,给用户在多终端上提供良好的使用体验。
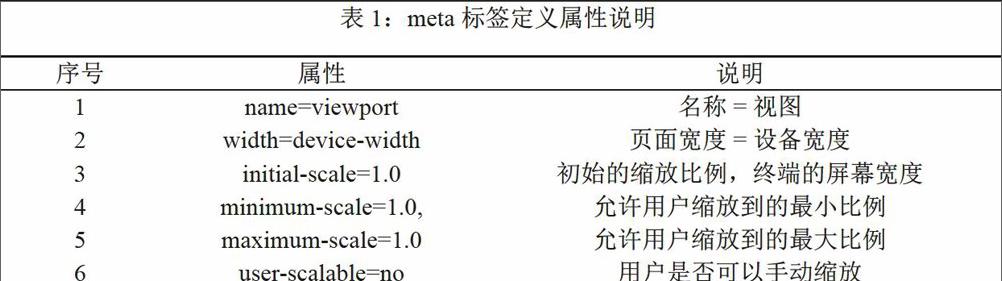
Web页面响应式布局通常需要meta标签定义、Media Query适配对应样式、内容响应化、图像响应化四个步骤。meta标签定义主要解决让视图宽度等于设备的宽度,在头部区域中加入标签代码:,默认的属性和属性值的含义如表1所示。
Media Query适配对应样式是Web响应式布局的核心部分,此功能能够和浏览器进行交流,MediaQuery通知了浏览器如何去呈现页面。例如需要兼容平板电脑和手机视图,可以定义如下:
/*平板电脑**/@mediaonlyscreenand(min-width:768px)and(max-width:1024px){}
/**手机**/@mediaonlyscreenand(width:320px)and(width:768px){}
根据访问终端的宽度来适配对应的样式,括号里面的样式会覆盖掉默认所定义的样式。此外,内容响应化和图像响应化也非常重要,例如多数传統Web应用程序用到的字体单位大部分都是像素,虽然在PC端上能够正常访问,但是在移动终端不做处理很容易出现自动换行问题,一般响应式的字体应关联的父容器的宽度才能适配移动终端屏幕。
3系统的实现
在研究过程中为了观察实验效果,增加了文本信息提取结果页面,需要用户点击转换按钮进行下一步转换功能。在实际的应用场景中,此操作对于用户来说应当是透明的,可以直接通过页面转换系统将传统网页转换为移动终端页面。图3中展示了基于jsoup对商用CMS系统(WebPlus)的某站点首页进行信息提取的结果。页面导航部分将二级菜单也进行了文本提取,因此在构建响应式页面时还需要进一步的处理。其余的文本内容块按文档流依次在页面中进行显示。
关键代码:
//通过ID获取网站导航eleNav=doc.getElementById("wp_nav_wl").getElementsByClass("nav-item").tagName("div");
myNavText=elementsNav.text();
//通过ID获取新闻列表eleLeftl=doc.getElementById(”wp—news—wl1").getElementsByTag("a");
mytext=elementsLeftl.text();
页面转换系统通过对页面重新进行响应式布局。使得页面能够适配移动终端的屏幕和分辨率的大小,转换得到的移动端页面如图4所示。移动终端页面中的背景图片、样式以及Javascript来源于目标网页。
4结束语
本文提出Web页面转换系统主要是基于jsoup针对商用CMS系统进行目标信息提取,然后利用HTML5和CSS3的相关技术进行页面转换,属于定制化转换方法,存在一定的局限性,不适用于其他一些Web应用程序,在今后的研究中需要在通用性方面进行加强。此外,还需要研究如何更快更准确地对传统Web页面进行实时转换,使系统运行效率和正确率进一步提高。
参考文献
[1]刘秉权,王喻红,葛冬梅,李佳.基于结构树解析的网页正文抽取方法[A].黑龙江省计算机学会.黑龙江省计算机学会2007年学术交流年会论文集[C]:2007:4.
[2]董之茵.网页信息提取与净化的研究[D].吉林大学,2008.
[3]孙明柱,魏海平.基于结构树的网页正文内容抽取方法[J].科学技术与工程,2011(28):6990-6993.
[4]高乐,张健,田贤忠.基于视觉的Web页面分块算法的改进与实现[J].计算机系统应用,2009(04):65-69.
[5]吴麒,陈兴蜀,谭駿.基于权值优化的网页正文内容提取算法[J].华南理工大学学报(自然科学版),2011(04):32-37.
[6]史晶,吴庆波,杨沙洲.移动终端个性
化页面显示优化技术研究[J].计算机工程,2012,38(18):277-279,281.
[7]Su Junming,Tseng Shian-Shyong,LinHuanyu,et al.A personalized learning content adaptation mechanism to meetdiverse user needs in mobile learning environments[J].User Modeling and User-adapted Interaction,2011,21(1/2):5-49.endprint
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国教育信息化·基础教育(2016年11期)2016-12-27
汽车科技(2016年5期)2016-11-14
中国新通信(2016年16期)2016-10-18
商场现代化(2016年7期)2016-04-27
