
大数据技术在电力大用户用电特征分类中的应用
2018-01-24 07:20沈建良陆春光倪琳娜
浙江电力 2017年12期
沈建良,陆春光,袁 健,倪琳娜,张 岩
(国网浙江省电力有限公司电力科学研究院,杭州 310014)
0 引言
伴随新一代智能化电力系统建设的全面展开,坚强智能电网的迅速发展使信息通信技术正以前所未有的广度和深度与电网生产、企业管理快速融合,信息通信系统已经成为智能电网的“中枢神经”,支撑着新一代电网生产和管理发展。
随着电力体制改革的推进,按照“放开两头、管住中间”的原则,售电市场将逐步成为更加开放的市场,电力企业将面临更加严峻的竞争局面[1]。同时,体验经济的到来使得传统的无差别客户服务模式已经无法满足客户日渐差异化的服务需求,对电力客户进行细分并给予精准的差异化服务已经成为未来发展方向。因此,以信息化平台积累的电力用户数据为基础,利用大数据技术对电力用户特性进行深入分析,并实行差异化的服务策略,对电力行业提升客户满意度有着重要的意义。
1 研究背景及研究思路
随着用电信息采集系统的建设应用,电力系统积累了海量的用电信息数据[2]。充分利用这些基于电力实际业务产生的数据,通过大数据分析方法进行数据挖掘分析[3],电力企业能够为用户提供大量的高附加值服务,有利于电网安全运行以及电力营销增值服务的开展。
大工业用户用电量大,经济价值高,在售电市场放开后会是各类售电公司争取的对象,也是电力企业需要重点关注和维护的对象。用电信息采集系统收集了大工业用户的海量详细负荷数据,反映了用户的用电行为和用电特征。在此基础上根据用电特性对大工业用户进行分组识别,可以为不同群组的特征制定差异化服务策略。
用电负荷数据呈现连续性和波动性,由每个用户的用电负荷数据绘制成的用电负荷曲线能够直观反映该用户的用电负荷波动特征,因此用电负荷数据可以看成是时间序列数据[4]。对时间序列进行相似性度量可以有效地帮助分析时间序列,也是时间序列聚类与分类过程中必不可少的处理阶段之一[5]。时间序列的相似性是通过距离度量来确定的,最常用的相似性度量方法是欧式距离度量[6]。但欧式距离仅适用于2个等长序列的比较,且对时间轴上的变化以及序列上的噪声等干扰很敏感,不能很好地描述高维时间序列的整体关系。
在度量2组时间序列间的距离时,使用基于DTW(动态时间规整算法),能够有效反映时间序列数据的相似度,得到所有用户用电负荷数据的距离矩阵。采用K-means聚类算法,对所有用户的DTW距离进行聚类,从而得到具有不同负荷特性的群组,实现对用户的分群研究。
2 算法原理介绍
2.1 DTW算法介绍
DTW算法能够衡量2个离散序列的相似程度或距离,通过动态地在时间轴上的扭曲和变动,对序列进行压缩或者延展以达到更好的匹对,简单且灵活地实现模板匹配问题,能够解决很多离散时间序列匹配的问题[7]。
假设2个时间序列Q和C表示为Q=q1,q2,…,qi, …, qn和C=c1, c2,…, cj, …, cm。 定义一个 n 行 m 列的距离矩阵D=[d(qi, cj)], 其中 d(qi,cj)为两序列中qi和cj两点的距离。在距离矩阵中,定义时间序列相似关系的一组连续的矩阵元素的集合为弯曲路径,记为W=w1,w2,…,wl,…,wL。弯曲路径必须满足有界性、边界条件、连续性和单调性条件。一般仅关心具有最小长度的路径,计算过程采用迭代方法:
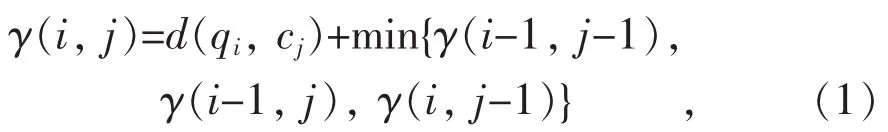
式中: γ(i, j)代表 qi和 cj的弯曲路径的最小长度;d(qi, cj)为两点之间的距离;min{γ(i-1,j-1), γ(i-1,j),γ(i, j-1)}表示取前一步弯曲路径的最小值。
根据2个序列的最小路径长度计算其DTW距离[8], 如公式(2)所示:
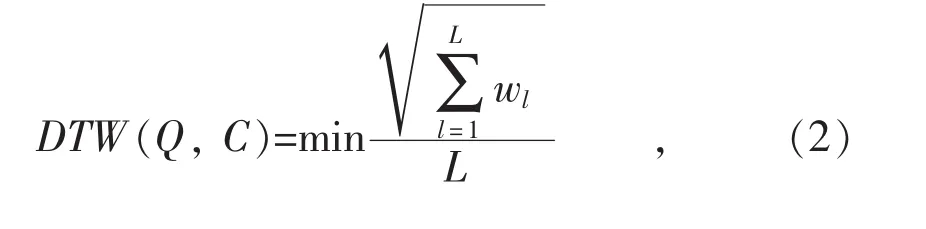
式中:L为弯曲路径的长度;wl为弯曲半径;DTW为连接所有步长的总最短距离。
DTW距离越小,两序列相似程度越大。为降低计算的时间复杂度,通常将弯曲路径限制在一定宽度的窗口内,或限定在斜率确定的平行四边形内。另外,对时间维度过长或存在异常点的时间序列,常用时间序列近似方法将其表示为长度较短的序列。
2.2 K-means聚类算法介绍
聚类是根据一定的算法规则,对一群样本进行类别划分的算法过程,聚类结果呈现为组内差异最小化、组间差异最大化[9]。K-means算法是典型的基于距离的聚类算法[10],其将样本聚类成k个簇,以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。具体算法描述如下:
首先,随机选取 k个聚类质心点为μ1,μ2,μ3,…,μk∈Rn。
其次,通过公式(3)计算每个样本点到所有质心的距离,选取距离最近的那个簇作为c(i):
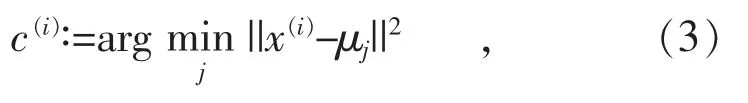
式中: x(i)表示第 i个样本的中心; c(i)代表样例 i与k个类中距离最近的那个类,c(i)的值是1到k中的一个。
对于每一个类j,重新计算该类的质心:

式中:μj反映了对属于同一个类的样本中心点的猜测,I{c(i)=j}表示判断第 i个样例是否属于第 j类,如果是取1,不是则取0。重复迭代式(3)、式(4)直到质心不变或变化很小。
3 建模实例
以某省纺织印染业大工业用户用电负荷特性的深度分析为例,针对用户每日96点(采集间隔15 min)的用电负荷数据,采用DTW算法计算用户负荷曲线相似性距离矩阵,并利用K-means聚类算法对样本用户进行聚类,通过模型调参得到最优的模型结果。
3.1 样本选择
选择某省2017年8月纺织印染业大工业用户每日96点的负荷数据[11],随机抽取19 682条样本,共96个变量,如表1所示。
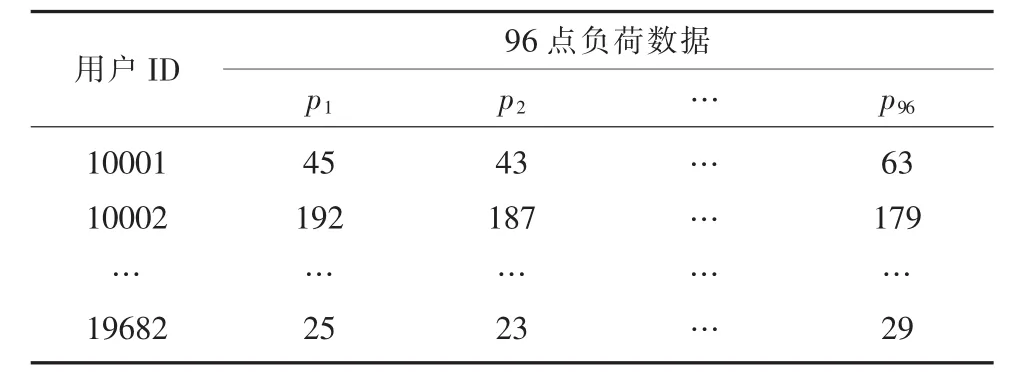
表1 样本负荷数据
3.2 数据预处理
在进行分析之前,对原始数据进行必要的数据预处理,以使数据规范化。数据预处理包括缺失值处理和归一化处理。
3.2.1 缺失值处理
由于采集不成功或者数据同步过程中出现信号丢失等原因,导致原始数据中的96点负荷数据中包含有缺失值,对分析造成影响,需要对空缺数据进行合理的填补。补全的方法一般有简单删除法、均值插补、多重插补等方法。根据不同的情况,采用不同的缺失值处理办法:
(1)对于缺失值比例高于30%的样本,采用简单删除法,在样本中去掉该数据。
(2)对于缺失值比例小于等于30%的样本,采用均值插补法进行缺失值填充。
3.2.2 数据归一化
由于用户的规模不同,用电负荷差异性相差很大,在比较不同用电用户的用电负荷曲线特征时,数值的大小会影响相似度计算,需要进行数据归一化处理,如公式(5)所示:

式中:P代表每个用户的负荷;ob代表企业编号;j为[1,96]区间的整数,代表一个整天共96个时间节点;max,min分别代表该企业每日负荷的最大值和最小值。经过归一化处理后,字段的取值介于[0,1]之间,使所有用户的用电负荷数据由物理系统数值变成相对值关系数据,达到缩小和统一量纲的目的。
3.2.3 数据降维
考虑到DTW计算复杂度为O(nm),以及负荷本身的可伸缩性,将计算得出的24 h平均负荷作为时间序列的特征,从而实现时间序列的特征提取和数据降维[12-13]。
3.3 聚类分析
将基于DTW算法得到的计算距离,通过K-means算法进行聚类。
(1)确定聚类个数。
K-means聚类首先需要确定聚类个数,常用的评估聚类效果的指标有SSE,DBI,CHI,Calin sky criterion等[14-16],此处采用常见的SSE指标,如图1所示,来确定K值。

图1 聚类分析SSE指标
通过SSE指标图分析,确定最终的分类个数为K=4。
(2)随机选择聚类中心。
在确定聚类个数后,随机选择4个样本作为聚类中心,剩余样本为19 678个。
(3)第一次分类。
将选择的4个聚类中心标记为O1,O2,O3,O4,针对剩余的19 678个样本,分别计算其与4个聚类中心点的DTW距离,取最小距离值作为该样本的类别,即:
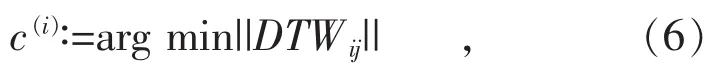
式中:j=1,2,3,4,表示将样本i划分为j类的规则,即若样本i与j类的DTW距离最小,则该样本属于j类。
(4)重新计算类中心。
在步骤(3)中,将所有的样本都划分到初始化的类别中,每个类中包含若干个样本。然后重新计算类中心,第j类的中心为:
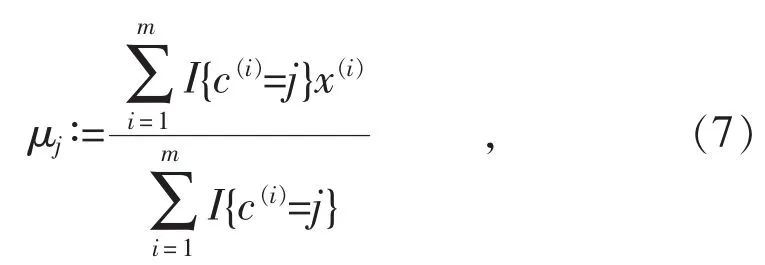
式中:I{c(i)=j}表示判断第 i个样本是否属于第j类, 如果是取 1, 不是则取 0。 x(i)表示第 i个样本的中心,整个公式表示计算第j类的类中心。
(5)迭代重复。
迭代重复第(3)、第(4)步,直到所有的样本都不能再分配为止,即为结果收敛,停止迭代。此时每个样本的聚类结果为最终的聚类结果。
本研究最终聚类的结果如表2所示。
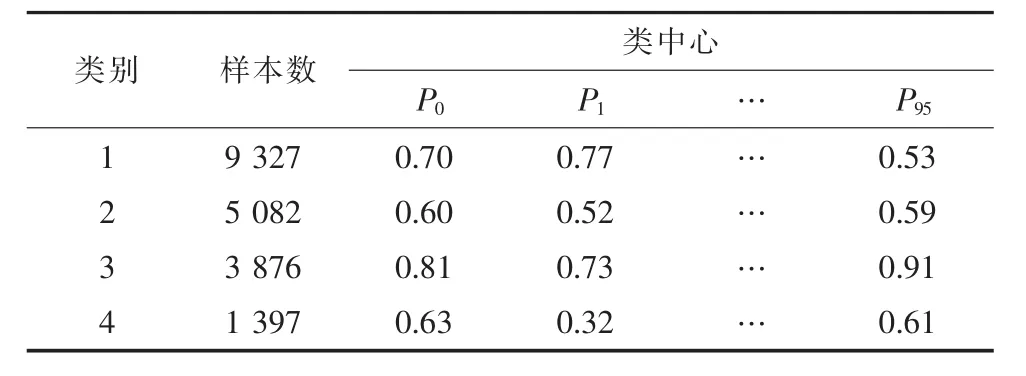
表2 聚类结果
4 用户负荷特性聚类结果
通过聚类分析,将19 682个纺织印染业客户聚类为4个类别,且每个类别的差异性特征明显,分别为:24 h生产型用户、白天生产型用户、双峰生产型用户以及夜间生产型用户。
4.1 24 h生产型用户
此类用户的用电负荷曲线表明其全天24 h都处于工作状态,不存在明显的峰谷生产行为,如图2所示。
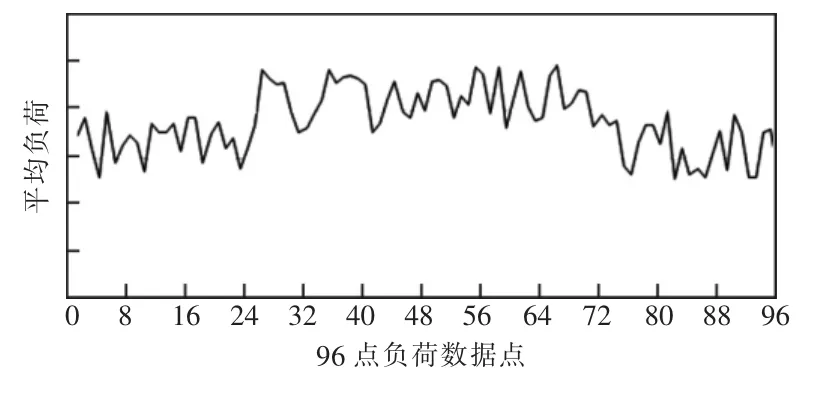
图2 24 h生产型用户负荷特征
针对此类用户,推荐其办理峰谷用电,并建议其生产时段依据峰谷用电进行调整,从而达到节省用电成本、平衡电网实时负荷的目的。
4.2 白天生产型用户
此类用户的用电负荷曲线表明其在白天处于连续用电高峰,而在晚间处于用电负荷低谷,如图3所示,主要集中在人力成本较高的劳动密集型企业。

图3 白天生产型用户负荷特征
建议此类用户进行避峰生产,同时办理峰谷用电。在实际中,具体到每一个用户,再根据用户的其他属性,给予差异化的精准服务策略。
4.3 双峰生产型用户
此类用户的用电负荷在上午和下午均出现高峰,中午时段有明显低谷,负荷曲线呈现M型的双峰形状,如图4所示。
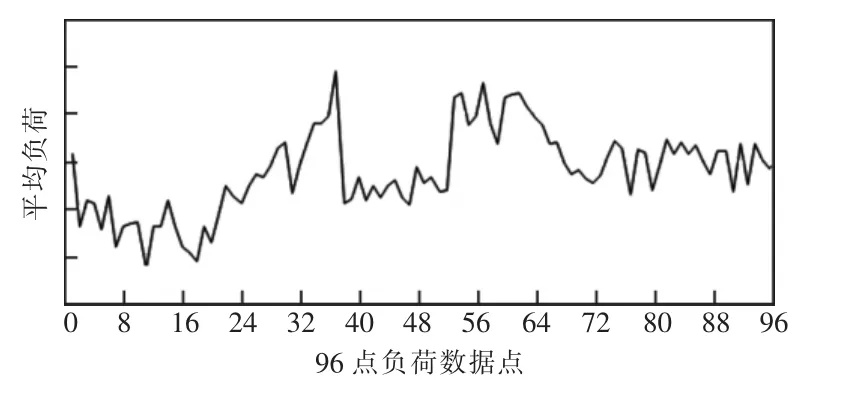
图4 双峰生产型用户负荷特征
此类用户的负荷特性与人员的作息比较相符,多属于生产和管理相结合型。针对此类用户,可以为其提供电能替代推荐,如电采暖、电制冷。
4.4 夜间生产型用户
此类用户只在夜间生产,白天几乎不生产,如图5所示,夜间用电的成因各不相同,诸如政策影响导致的限产,生产特性安排的夜间生产,下半夜的谷时段电价更低。
此类用户通过分析其历史用电特性,分析其是否属于连续性夜间生产型。对于连续夜间生产型用户,给予安全用电指导关怀;对于临时性夜间生产型,给予办理峰谷用电、增/减容用电提醒。
另外,分别针对以上4类用户设计相应的电费套餐,在电力市场化和售电侧市场进一步放开后,及时推出相应套餐吸引客户,抢占市场先机。

图5 夜间生产型用户负荷特征
5 结语
实例结果表明,采用DTW算法对电力大用户的用电负荷数据进行相似度度量,并通过K-means聚类算法对用户进行聚类分析,能够对用户的用电负荷曲线特征进行良好的度量和区分,实现用户负荷曲线的聚类和负荷特性分析。
通过对纺织印染业电力大用户的用电负荷曲线进行聚类分析,发现存在4种明显差异的用电特征。在售电侧放开的市场环境下,针对不同类型的用户群体,设计差异化的用电套餐及服务策略,为市场化售电未雨绸缪,对提升企业竞争力具有非常重要的现实意义。
猜你喜欢
中学生数理化·中考版(2020年12期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
活力(2019年15期)2019-09-25
小学生必读(中年级版)(2018年10期)2019-01-04
消费导刊(2018年8期)2018-05-25
雷达学报(2017年6期)2017-03-26
商场现代化(2016年15期)2016-08-23
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
印刷技术·数字印艺(2015年12期)2016-02-18
