
DGD卷积神经网络行人重识别
2018-01-23 06:19杨忠桃章东平井长兴
中国计量大学学报 2017年4期
杨忠桃,章东平, 杨 力, 井长兴
(中国计量大学 信息工程学院,浙江 杭州 310018)
在计算机视觉领域,行人重识别的目标是指定一张行人图像,在已有的其它非重叠摄像机视角下的行人图像库,识别出与此人的图像[1].由于不同的摄像头场景、视角、光照等因素的影响,会导致同一行人图像的变化较大,因此行人重识别问题仍然是一个非常具有挑战性的问题.当今社会,在地铁站、大型商场等[2]场所基本都安装了监控摄像头,智能的重识别系统可以节省大量的人力用来搜索感兴趣人物,因此提高行人重识别算法效果显得十分关键.
行人重识别研究主要分为:基于特征表示的方法和基于度量学习的方法.基于特征表示方法主要研究提取具有鲁棒性的鉴别特征来表示行人,基于度量学习方法主要研究通过学习一个距离函数,使同一行人的距离小于不同行人的距离.
近年来,深度学习在学习特征方面在大多数领域都取得了巨大的成功.它被应用在不同的计算机视觉任务上,例如图像分类[7]、语义分割、目标检测等.深度学习的成功离不开大量训练数据的驱动.在重识别领域,此前由于缺少数量规模较大的数据集,深度学习未能挖掘更具区分性的特征.随着类似CUHK03[11]、iLIDS[12]和PRID[6]等越来越多行人重识别数据集的公开,使深度学习提取更具鲁棒性特征的优点在重识别领域也得到了充分的展现.
在计算机视觉领域,一个数据域通常指的是一个数据集,它们含有相同的底层分布.例如在CUHK03中数据集采集来自大学校园,行人图像中大多含有书包、书籍等一些语义概念的特征.因此,若采用来自一个域的数据集来做深度学习的训练集,提取到的特征不具备很强的一般性,而多域数据联合学习就是研究解决这个问题的.多域数据联合学习就是结合多个域的数据来做训练集,得到的特征更具有一般性,使得模型更具有域适应性.本文提出了结合多域数据集,在DGD卷积神经网络得到特征提取器的基础上,对提取到的特征进行再筛选,提取出那些对同一标签行人更具有鉴别性的特征,使重识别效果得到了一定程度的提升.其过程如图1.
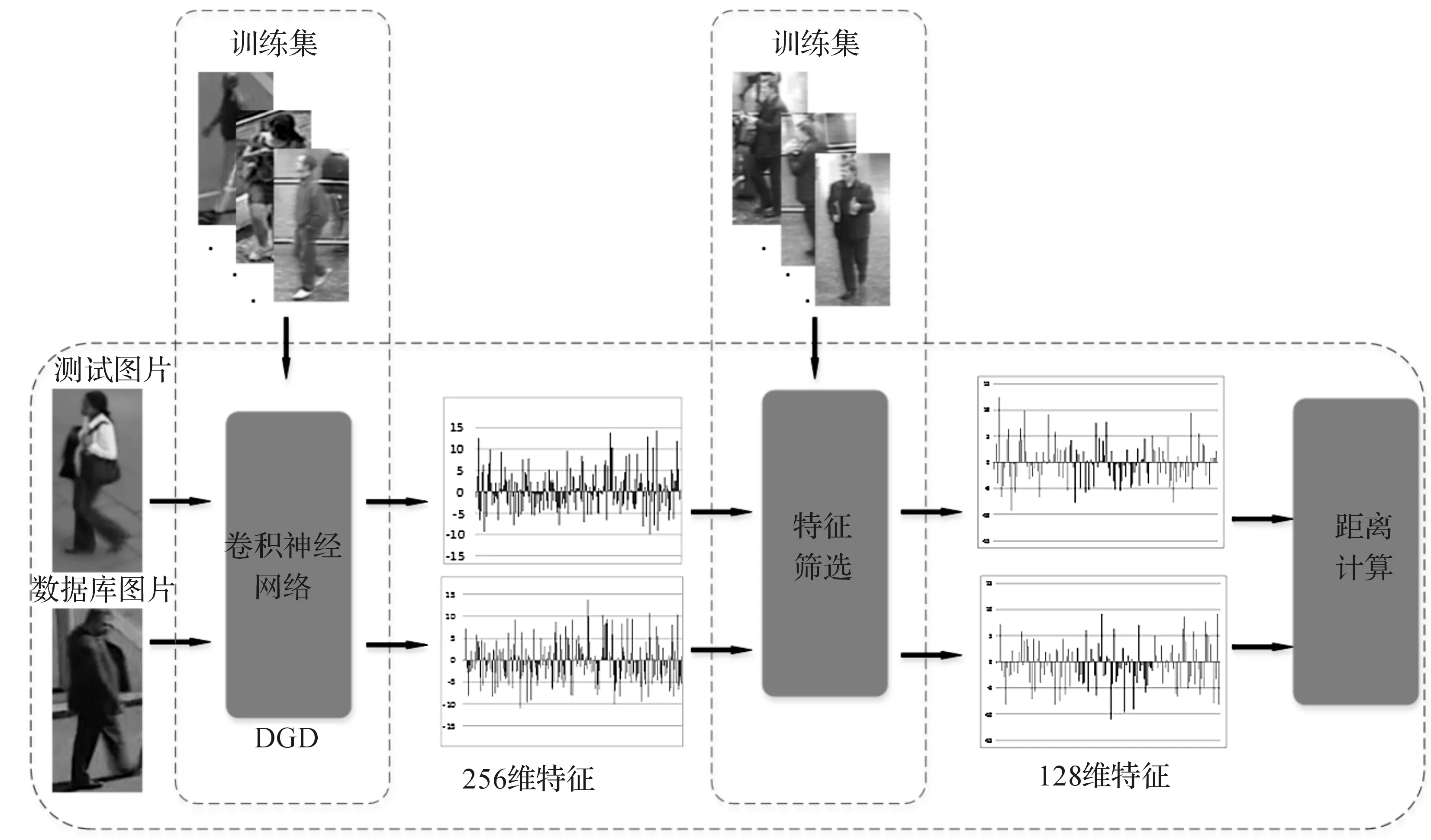
图1 所提出的算法行人重识别流程图Figure 1 Person re-identification flow chart of method we proposed
1 特征提取
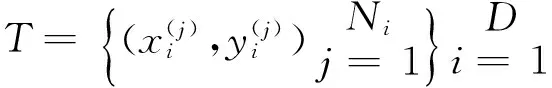

图2 学习特征提取器Figure 2 Learning feature extractor
1.1 深度卷积神经网络
卷积神经网络属于一种前馈神经网络,它是为识别二维图像而特殊设计的一种多层感知器,该网络结构对平移、缩放、倾斜、旋转或其他形式的变形具有一定程度的不变性[3].卷积神经网络和普通的神经网络一样,由神经元按不同的层结构组成,神经元带有可学习的权重和误差.卷积神经网络主要由卷积层、池化层和全连接层叠加组成.卷积层的作用是通过输入图片像素来学习要识别高级的语义特征.池化层的作用就是对输入的特征进行下采样,简化网络计算复杂度,增加了特征的旋转不变性.全连接层的作用是连接所有特征,将输出值送给分类器.本文设计的卷积神经网络由三个卷积层,六个Inception模型和两个全连接层组成.为了加快收敛,避免手动修改权值,在每个ReLU层之前都加了Batch Normalization层,网络结构如表1.
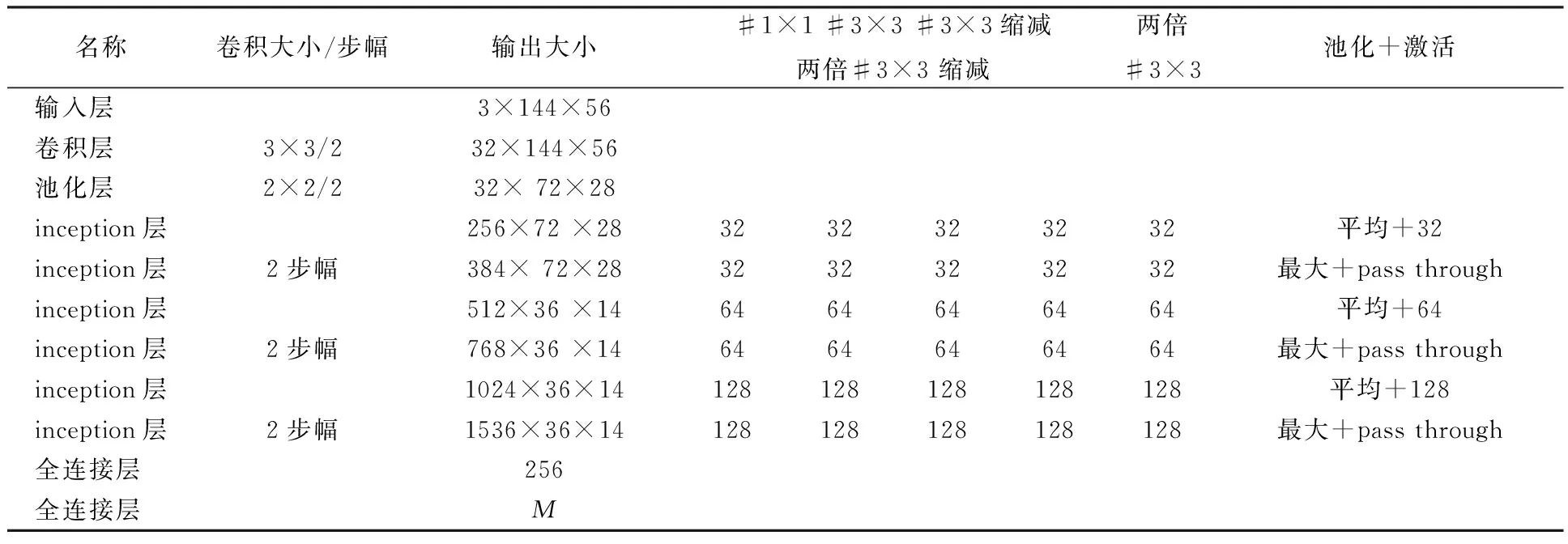
表1 卷积神经网络结构
1.2 Domain Guided Dropout
不同于传统的Dropout将每个神经元的概率都设置为0.5,Domain Guided Dropout[4]抑制了对某一域中特征非相关的神经元.对每个域都定义一个损失分值,即移除该神经元时,损失函数的增益.在一幅图片上第i个神经元的损失分值表示为si=L(g(x)/i)-L(g(x)),其中L是损失函数,g(x)表示样本的特征表达,g(x)/i表示将网络的第个神经元置为0.
根据损失分值,对神经元的处理方式有两种:
第一种是固定形式的,对未让损失函数变小的神经元都被置为零
(1)
第二种是随机形式的,使用伯努利分布
(2)
其中T用来控制si对概率的影响程度.当T接近于0或者接近于正无穷时,该等式相当于是标准Dropout.
2 特征筛选
通过DGD卷积神经网络的训练,学习获得了一个具有一般性的特征提取器g(·).输入两张行人图像,通过g(·)输出分别得到256维的行人特征.本文的目标就是通过多域数据集来进行再训练,筛选出256维行人特征中具有很强鉴别性的特征.
2.1 样本相对距离
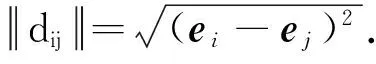
2.2 数据准备
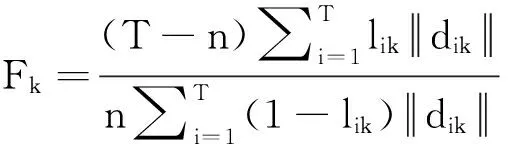
2.3 特征筛选
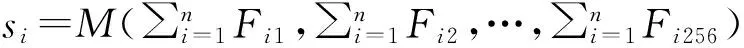
3 实验结果与分析
为了能够获取到丰富的样本类内变化,得到更多的对样本相对距离更具有正相关性的特征,基于单张图片的数据集不适合用来作为训练,同一标签的样本数量应不少于20张.在参考文献[4]的基础上,本文选择在公共数据集iLIDS、PRID、CUHK03进行实验来验证改进的基于DGD卷积神经网络算法性能.下面首先介绍下各个数据集的特点,然后对本文的实验结果与其他算法的结果进行对比并分析.
3.1 数据集
iLIDS数据集采集来自机场接待大厅,由两个不相交的摄像头拍摄组成.它包含了300个不同行人的600个图片序列,每个行人都含有来自两个不同摄像头的图片序列.图片序列的长度有23到192帧不等,相似的衣服、光照和视觉改变,复杂的背景和严重的遮挡,非常具有挑战性.PRID数据集采集来自两个不同的摄像头,分别监控人行航道和人行道,有相对简单的背景、较少的遮挡,两个摄像头视角分别包含385和749个人,但只有200个人是在两个视角里都出现过的.CUHK03采集来自一个大学校园,由5个不同的摄像机视角,包含了由人工标注及检测器检测到的1467个行人的13164张图像.实验中,本文采用CMC曲线排名第1的识别率来做算法的比较.
3.2 实验
将本文所提出的算法与DGD卷积神经网络算法及一些其它重识别算法在三个比较常用的数据集上进行对比实验.算法在iLIDS、PRID和CUHK03数据集上的实验结果分别如表2、表3和表4.

表2 iLIDS数据集上CMC top-1对比
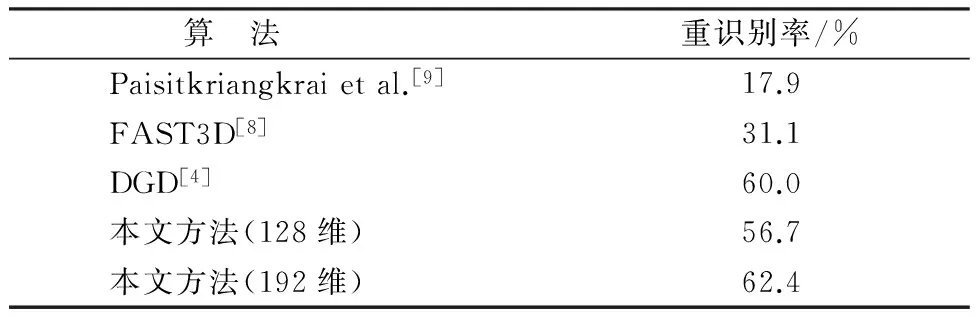
表3 PRID数据集上CMC top-1对比

表4 CUHK03数据集上CMC top-1对比
上述实验结果表明当筛选特征si中l降低到192时,重识别率会得到一定的提升,说明筛选过后的特征更具有鉴别性.但当降低到128时,重识别率下降,这说明过少的特征维度会使特征失去鉴别性从而影响重识别率.因此,本文选择将筛选过后按升序排列的前192维特征作为行人图像的表征特征.实验结果说明本文提出的对DGD卷积神经网络的优化算法是有效的,相对其它算法来说,它在行人重识别的准确率上有一定程度地提高.
4 结 语
本文提出了一种DGD卷积神经网络与样本相对距离结合的行人重识别算法.首先采用改进过的CNN模型训练多域数据集来获得一个特征提取器,输入行人图像来获得256维特征.然后在这256维特征的基础上进行特征筛选,通过多域数据集进行训练获得256维特征中对行人重识别更具有鉴别性的192维特征. 最后计算输入的行人图像在经过特征筛选的192维特征与行人图像库中图像的特征向量计算欧氏距离并进行排序.本文提出的算法与其他一些重识别算法相比,其性能有了一定的提升.
[1] 杜宇宁, 艾海舟. 基于统计推断的行人再识别算法[J]. 电子与信息学报, 2014, 36(7):1612-1618.
DU Y N, AI H Z. Pedestrian re-identification algorithm based on statistical interface[J].JournalofElectronics&InformationTechnology, 2014,36(7):1612-1618.
[2] ZHENG W S, GONG S, XIANG T. Reidentification by relative distance comparison[J].IEEETransactionsonPatternAnalysis&MachineIntelligence, 2013, 35(3):653.
[3] 刘冶,潘炎, 夏榕楷,等. FP-CNNH:一种基于深度卷积神经网络的快速图像哈希算法[J]. 计算机科学, 2016, 43(9):39-46.
LIU Y, PAN Y, XIA R K. FP-CNNH: A fast image hashing algorithm based on deep convolution neural network[J].ComputerScience, 2016, 43(9):39-46.
[4] XIAO T, LI H, OUYANG W, et al. Learningdeep feature representations with domain guided dropout for person re-identification[C]//ComputerVisionandPatternRecognition. Las Vegas :IEEE CVPR, 2016:1249-1258.
[5] LI W, WANG X.Locally Aligned Feature Transforms across Views[C] //ComputerVisionandPatternRecognition. Portland: IEEE CVPR, 2013:3594-3601.
[6] HIRZER M, BELEZNAI C, ROTH P M, et al. Person re-identification by descriptive and discriminative classification[C]//ScandinavianConferenceonImageAnalysis. Ystad: SCIA, 2011: 91-102.
[7] SCHMIDHUBER J. Multi-column deep neural networks for image classification[C]//ComputerVisionandPatternRecognition. RodAprovendis: IEEE CVPR, 2012: 3642-3649.
[8] LIU Z, CHEN J, WANG Y. A fast adaptive spatio-temporal 3D feature for video-based person re-identification[C]//IEEEInternationalConferenceonImageProcessing. Phoenix: IEEE ICIP, 2016: 4294-4298.
[9] PAISITHRIANGKRAI S, SHEN C, HENGEL A V D. Learning to rank in person re-identification with metric ensembles[C]//ComputerVisionandPatternRecognition. Boston: IEEE CVPR, 2015:1846-1855.
[10] AHMED E, JONES M, MARKS T K. An improved deep learning architecture for person re-identification[C]//ComputerVisionandPatternRecognition. Boston: IEEE CVPR, 2015:3908-3916.
[11] LI W, ZHAO R, XIAO T, et al. DeepReID: Deep filter pairing neural network for person re-identification[C]//ComputerVisionandPatternRecognition. Columbus: IEEE CVPR, 2014:152-159.
[12] WANG T, GONG S, ZHU X, et al. Person re-identification by video ranking[C]//EuropeanConferenceonComputerVisionSpringerInternationalPublishing. Amsterdam:IEEE ECCV, 2014:688-703.
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
军事文摘(2022年1期)2022-01-26
汽车工程师(2021年12期)2022-01-18
航空兵器(2021年5期)2021-11-12
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
军事文摘(2017年19期)2017-10-13
软件导刊(2017年9期)2017-09-29
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
