
一种基于运营商大数据的信用风险控制模型
2018-01-18 07:10:48贾利娟朱斌杰
电子设计工程 2018年1期
贾利娟,朱斌杰
(1.陕西广播电视大学计算机与信息管理教学部,陕西西安710119;2.中国移动北京公司北京100007)
移动通信运营商积累大量的用户数据,包括用户基础信息、通信行为、上网行为、地理位置等数据。如何利用这些数据服务于征信领域是一个值得研究的问题。征信领域主要分为企业征信和个人征信两类,因为运营商积累的主要是个人通信用户的数据,所以这里主要研究个人征信问题。运营商的个人征信产品体系中主要包括征信验真、征信评级、业务追踪管理3个子产品,其中征信评级是最重要的产品。征信评级产品基于运营商的大数据为用户进行信用评级,信用评级应用于个人贷款、消费贷款、免押金租赁等金融和商业场景中,实现对业务场景下的业务风险控制。从数据挖掘的角度看信用评级问题就是数据挖掘中的分类预测问题,根据用户历史数据建立用户评级模型,基于评级模型得到每个用户的信用风险评级并应用于业务场景中。征信评级不仅应用于传统信贷场景,而且应用于互联网征信领域[1-5]。大数据征信评级中特别要注意用户的隐私问题[6]。现有基于大数据的征信模型都是基于信用场景下的数据[7-8],没有使用运营商大数据。
1 运营商征信系统
基于运营商大数据的征信系统由验真子系统、评级子系统、贷后管理子系统。验真子系统是对用户身份以及各种状态真伪进行判别并返回是否形式的输出。评级子系统通过运营商大数据建立用户信用评级模型,根据模型计算输出用户的信用评级。贷后管理子系统管理贷款用户的预警模型,输出预警信息。
如图1所示,征信系统在部署上分为3个区域:数据接入区、业务逻辑区、数据处理区。数据接入区从外围数据系统中接入所需数据,外围数据系统有CRM、BOSS、BI、网管系统、客服系统等。业务逻辑区处理业务逻辑响应用户请求。数据处理区包括数据预处理、数据挖掘、指标监控规则管理等功能。

图1 信用风险控制系统部署图
一个大数据系统要面临3个问题:大数据存储、大数据分析、大数据管理。Hdoop分布式云计算框架是大数据最有力的搭档,主要由分布式文件系统HDFS和MapRduce编程模型组成。本系统的核心在数据分析处理区,在预处理阶段与数据挖掘阶段都需要对海量大数据进行存储和计算,HADOOP技术是为处理大数据而生的技术,通过MapReduce模型把任务分配到分布式的计算机集群中,既降低了成本又提供了可伸缩性。
在挖掘周期和规则识别周期都比较长的情况下,对内容个性化规则挖掘的过程来说无需快速的查询时间,Hadoop架构是能够胜任的。如果挖掘周期和规则识别周期都比较短,可以考虑采用SPARK技术。SPARK同样能够实现Hadoop的基于MapReduce的并行计算,任务运行的中间结果保存在内存中,而不需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
2 征信评级模型
2.1 数据预处理
运营商的数据主要有用户基本信息、通信行为、上网行为、客服投诉行为、增值业务使用行为等数据。这些数据需要从分散在各个部门的系统集中到统一的大数据平台系统中。用户基本信息包括用户的实名认证数据,主要是身份信息,从身份证号码能解析出的信息包括籍贯、性别、年龄等信息。通信行为数据包括主要是话单数据、消费数据、终端数据,话单数据主要能解析出通话行为、短信行为、位置信息。DPI技术是运营商大数据分析的基础[9-12]。上网行为数据主要是对用户上网行为作出DPI解析,从而得到用户对网站以及APP类型的访问记录,然后根据访问记录可以得到用户偏好。通信网络是移动通信用户上网的通路,通信网元中的Gn口中可以提取每个用户的上网行为,包括APP使用行为或者网站访问行为。Gn口用户上网行为的获取是通过DPI解析技术来实现的。深度包解析DPI中的“深度”是和普通的报文分析层次比较而言的,普通报文检测仅分析IP包4层以下的内容,包括源地址、目的地址、源端口、目的端口以及协议类型,而DPI除了这些层次,还增加了应用层分析,能够识别各种应用及其内容。对这些原始数据进行处理解析得到所需的用户属性维度,然后对数据进行ETL工具把数据处理成标准的基础数据表。基础数据表是一张存储用户属性的宽表。从业务层面宽表包括身份特质、履约能力、立信历史、人际网络、行为特征等几个方面的数据,如图2所示。

图2 信用风险控制模型维度分类
身份特质数据对用户的基础信息进行画像。身份特质相关数据包括:会员级别、被举报次数、恶意投诉次数、年龄、性别、职业特征。性别、年龄数据来源于用户的实名制信息,从身份证信息上可以提取计算出性别和年龄数据。恶意投诉次数、会员级别来源于客服系统。被举报次数来源于客服系统以及骚扰电话智能识别模型。
履约能力对用户的消费能力进行画像。履约能力数据包括:账单金额、近3个月流量、缴费方式、承诺消费、账户余额、终端类型、省际漫游、国际漫游。履约能力相关的数据来源于CRM、BOSS系统。通过系统数据直接计算得到。
立信历史数据对历史信息用情况进行画像。立信历史数据包括:通信账户开立时长、固定电话、家庭宽带开立时长。通信账户开立时长就是用户的移动通信业务入网时间,固定电话、家庭宽带等业务的开立时长也是与立信历史相关的数据。
人际网络数据对用户的通信圈、即时通信朋友圈等人际关系进行画像。人际网络相关数据包括:本地朋友圈比例、国际长途、朋友圈质量、家庭套餐、亲情号码。本地朋友圈比例、国际长途、朋友圈质量主要通过话单数据来建立模型进行计算的。家庭套餐、亲情号码来源于相应的业务平台。
行为特征数据对用户的通信、上网等行为进行画像。行为特征相关数据包括:欠费次数、最近一年被查询次数、公检法、催收号码呼入、特服短信号码分析、一年稳定使用终端数量、补充业务、兴趣偏好分析。

表1 用户属性宽表
前面预处理环节完成了全网用户的属性数据处理工作,得到一张全网用户的属性数据宽表,如表1所示。这是进行数据挖掘环节的基础。用户征信评级模型是一个分类预测问题。数据挖掘根据历史数据挖掘出规则然后使用所得到的规则对未来预测。历史数据就是用作模型训练的数据,是指在同样场景下积累的已知结果的个体行为数据。可以根据不同应用场景建立不同的模型,以适应不同场景的需要。
2.2 数据挖掘流程
数据挖掘的流程分为5步,具体步骤如下:
第一步:获得训练数据。从业务积累的历史数据获得训练数据。训练数据主要包括用户标识主键和目标字段。目标字段与要预测的结果相对应,目标字段的取值是由用户真实行为产生的历史记录。根据目标字段取值的数量训练数据相应要取对应组数。
在某商城小额消费贷款业务场景下,业务开展过程中积累了一些用户使用贷款业务后是否按时还款的历史数据记录,根据用户是否及时还款把用户分为优质用户、风险用户两个级别,对两个级别的用户分别采取不同的业务方案。优质用户是能及时还款的用户,风险用户是指贷款后产生坏账的用户。这里目标字段有两个取值:优质用户、风险用户。在选择训练样本的时候需要对应提取出两组用户:优质用户、风险用户。两组用户组成了用户行为历史数据,记录数10万条,如表2所示。其中8万条做为训练数据如表2所示,2万条做为验证数据。
第二步:在用户属性宽表中提取出训练数据对应的属性数据,如表3所示。
第三步:聚类和分析算法都可以作为预测模型使用[13-14]。使用SPARK计算框架保障计算速度[15-16]。运行决策算法C4.5,决策树。算法的输入是第二步中的训练样本宽表。输出结果是一个根据属性重要程度从大到小排列的树,树的根节点属性最重要。从树的根节点到叶子所经过的一条路径上的属性组成一条判断规则。C4.5算法是基于基于ID3算法进行的扩展。ID3算法进行属性划分使用的参数是熵,熵是无序性(或不确定性)的度量指标。假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn),那信息熵定义为:


表2 用户行为历史数据表

表3 属性数据
ID3中计算的是“信息增益”,C4.5中则计算“信息增益率”:
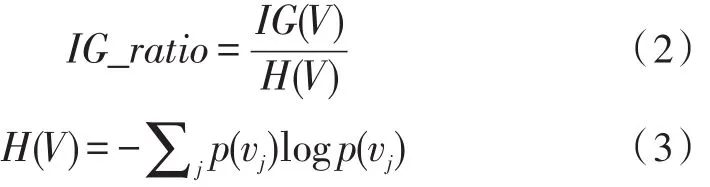
vj表示属性V的各种取值,在ID3中用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性,在C4.5中由于除以了H(V),可以削弱这种作用。
算法首先会计算所有属性的信息增益率,选出值最大的属性作为决策树根节点属性,然后在叶子节点中迭代此过程。C4.5算法本身是成熟的算法,决策树分类预测算法可以根据具体情况具体选择,R、SPSS、SAS等专业数据挖掘工具中都有相应的算法包供调用,算法输出的是决策树结果文件或者可视化的决策树。
第四步:基于决策树提取出规则,这些规则可以转化为数据库中IF-ELSE形式的查询语句。从决策树的根节点到叶子节点所经过的属性组成一条规则的判断条件属性,符合这些属性的用户被分组到对应的预测分组之中。可以把所有的路径提取出来作为规则库,也可以加上专家经验选取出符合业务逻辑的规则然后再加入到规则库中。前者是闭环自动的方式完成,效率较高,但准确率较低。后者加上了业务专家的经验,但挖掘过程不再是自动方式完成。
第五步:在业务逻辑区进行固化规则。固化的规则一组判断条件和结果的组合。当用户请求到达后根据规则进行判断评级,返回用户相应的等级。规则要根据评级的效果进行持续的优化。根据业务反馈的结果与评级的结果进行比较,判断评级的质量,进行指标。持续进行指标监控,并持续优化规则。
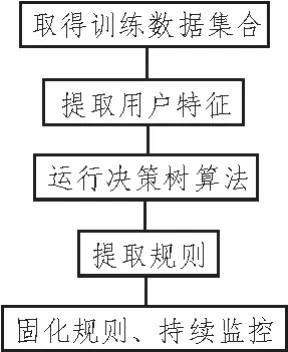
图3 数据挖掘流程图
3 模型评估
模型质量通过比对验证数据与模型预测结果来进行评估。通过8万条训练样本数据训练出决策树规则模型,然后通过2万条验证样本数据进行验证。验证样本数据的目标字段的实际类别是已知的,通过决策树规则得到目标字段的预测类别,然后与实际类别进行对比来评估模型,如表4所示。

表4 预测结果与实际结果对比表
正确率是指模型总体的正确率,是指模型能正确预测、识别1和0的对象数量与预测对象总数的比值。正确率是综合评价模型准确度的一个指标。

根据公式计算正确率为98.68%。模型正确识别为正的对象占全部观察对象中实际为正的对象数量比值,指风险用户的识别度,风险用户识别度越高业务风险越小。
4 结论
为了基于通信运营商大数据对个人信用风险进行控制,设计了一种基于运营商大数据的征信评级模型,提高了风险用户识别准确率。可以通过征信模型对外提供用户信用评级服务,需要与外部客户联合建立个性化模型,这是需要下一步要深入的研究的问题。
[1]张健华.互联网征信发展与监管[J].中国金融,2015(1):40-42.
[2]刘晓丛.基于P2P网贷的中小企业融资问题研究[J].时代金融,2014(1):216-217.
[3]赵雅敬.P2P网络借贷缓解科技型中小企业融资难问题研究[J].经济研究参考,2014(25):57-64.
[4]刘金燕.基于互联网金融的中小企业融资模式探讨[J].中国市场,2014(43):102-103.
[5]王朝霞,张婷婷.互联网金融在小微企业融资领域的应用现状及问题研究[J].中外企业家,2014(16):111-112.
[6]马义玲.我国个人信用征信过程中金融隐私权保护问题探讨[J].征信,2014(1):52-54.
[7]陈云,石松.基于PSO-BP集成的国内外企业信用风险评估[J].计算机应用研究,2014,31(9):2705-2710.
[8]崔东文.基于多元变量组合的回归支持向量机集成模型及其应用[J].水利水运工程学报,2014(2):66-73.
[9]谷红勋,张霖.DPI:运营商大数据安全运营的基石[J].网络空间安全,2016(7):23-26.
[10]何高峰,杨明,罗军舟,等.Tor匿名通信流量在线识别方法[J].软件学报,2013,24(3):540-556.
[11]董仕,丁伟.基于流记录偏好度的多分类器融合流量识别模型[J].通信学报,2013,34(10):143-152.
[12]赵博,郭虹,刘勤让,等.基于加权累积和检验的加密流量盲识别算法[J].软件学报,2013,24(6):1334-1345.
[13]何广才,周根宝.基于MapReduce的改进蚁群算法在TSP中的应用[J].内蒙古农业大学学报,2015,36(5):125-132.
[14]杨倩倩,生佳根,赵海田.K-means聚类算法在民航客户细分中的应用[J].电子设计工程,2015(12):25-27.
[15]胡俊,胡贤德,程家兴.基于Spark的大数据混合计算模型[J].计算机系统应用,2015(4):216-220.
[16]龚灿,卢军.基于Spark的实时情景推荐系统关键技术研究[J].电子测试,2016(4):48-50.
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
电力与能源(2017年6期)2017-05-14 06:19:37
股市动态分析(2016年22期)2016-12-27 17:06:46
消费者报道(2016年3期)2016-02-28 19:07:30
信息通信技术(2015年6期)2015-12-26 01:16:46
IT时代周刊(2015年9期)2015-11-11 05:51:43
IT时代周刊(2015年9期)2015-11-11 05:51:27
IT时代周刊(2015年9期)2015-11-11 05:51:24
IT时代周刊(2015年8期)2015-11-11 05:50:22
电子设计工程(2014年18期)2014-02-27 12:00:13
