
基于采样技术的主动不平衡学习算法研究
2018-01-18 07:10:39李青雯于化龙
电子设计工程 2018年1期
李青雯 ,孙 丹 ,于化龙 ,2
(1.江苏科技大学计算机科学与工程学院,江苏镇江212003;2.东南大学自动化学院,江苏南京210095)
近年来,随着数据获取与数据存储技术的高速发展,各行各业均积累了海量的数据,如何对这海量数据进行分析成为了困扰机器学习与数据挖掘领域研究者的核心问题。如对这海量数据的类别进行标注,进而建立分类模型,无疑会大幅增加人力、物力与时间成本的开销,而主动学习则是可有效解决上述问题的利器。众所周知,主动学习通过迭代的方式来选取当前信息含量最大的样本,进而不断提升分类模型的质量,故其可在不明显损失分类性能的情况下,有效地降低训练样本的复杂性。
经过多年研究,研究人员已提出了多种有效的主动学习算法,但其几乎均忽略了一个重要问题,即在样本不平衡分布场景下,这些算法是否会仍旧有效。对于主动学习与类别不平衡学习的结合方式,目前一共有两种,其一是利用主动学习来解决类别不平衡分类问题,Ertekin等人[1-2]发现主动学习可有效缓解类别不平衡分布对分类器的负面影响;其二则是在类别不平衡场景下,如何保证主动学习的效率,Zhu及Hovy[3]对该问题进行了初步的研究,并提议:对于分布不均衡的数据,应在主动学习过程中引入平衡控制策略,从而保证在迭代过程中每一轮所生成的分类面都是公平公正的。本文主要关注上述的第二种结合方式,即如何在类别不平衡数据中保持主动学习的效率与性能。
文中考虑采用类别不平衡学习领域中最为简单与常用的样本采样技术来作为主动学习过程的平衡控制策略。并通过分析现有采样算法的不足之处,提出了一种适用于此类场景的边界过采样算法。特别地,为了加速主动学习的进程,我们采用极限学习机(Extreme Learning Machine,ELM)作为主动学习的基分类器,因其同时兼具泛化能力强与训练速度快两大优点,具体采用文献[4]中的“查询样本”选择策略。通过12个基准数据集对添加了“平衡控制”策略的主动学习算法与传统主动学习算法进行了比较,得出前者可大幅提升主动学习性能的结论。
1 基于池的主动学习模式概述
主动学习,即通过主动获取样本的方式来进行学习。其目的是通过标注尽可能少的样例来使分类性能最大化[5]。根据应用场景的不同,主动学习大致可以分为以下两类:基于流的主动学习模式和基于池的主动学习模式。本文侧重于基于池的主动学习模式,而图1则描述了在这一模式下的主动学习过程。
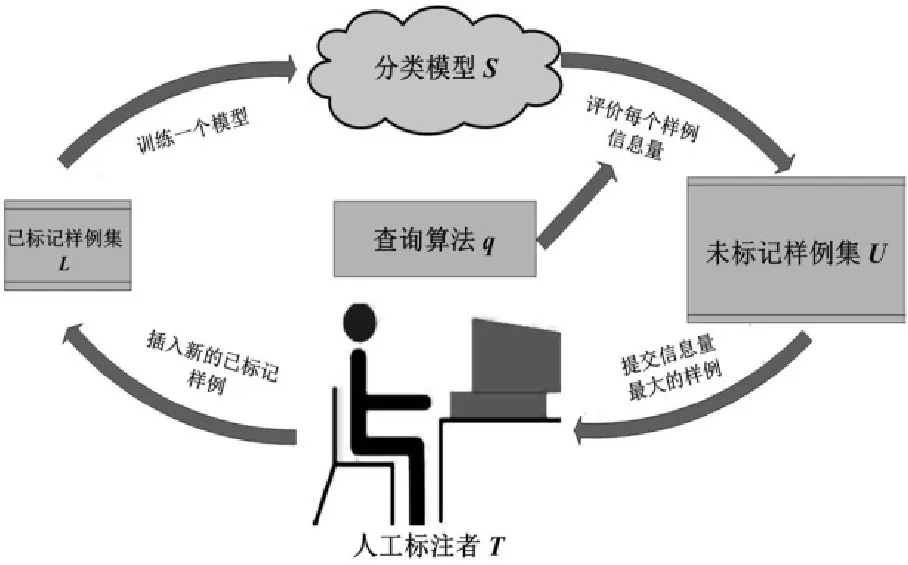
图1 基于池的主动学习模式过程示意图
从图1中,不难看出,在此类模式下,主动学习由以下5个基本构件组成:1)一个已标记样例集L;2)一个未标记样例集U;3)一个分类模型S;4)一个查询算法q及5)一个人工标注者T。最初,人工标注者T仅随机地标注少量的未标注样本,并将其置于已标记样例集L中,并训练一个初始的分类模型S。接下来,进入循环迭代过程:利用分类模型S评价未标记样例池U中的每一个样例,并利用查询算法q提取各样例的信息量,进而根据信息量大小对其进行排序,选取一个或一批信息量最大的样例提交给人工标注者T进行标注,最后再将标注的样例添加到已标记样例集L中,对分类模型S进行更新。上述过程循环往复,直至达到某个预设的停止条件为止。
然而,若已标注与未标记样例集均是类别分布不均衡的,则会对上述主动学习流程产生较大负面影响。若学习过程中每一轮所建立的分类模型都是偏倚的,那么必然会导致“查询样本”选择得不准确,进而影响到下一轮所更新模型的质量。此时,应引入平衡控制策略,文中考虑采用样本采样技术作为平衡控制策略。
2 方法
2.1 样本采样技术
样本采样技术是用于解决类别不平衡问题的基本技术之一。所谓样本采样,即是通过增加少数类样本或减少多数类样本的方式来获得相对平衡的训练集,以修正分类面偏倚的问题。其中,增加少数类样本的方法被称为过采样(Oversampling),而减少多数类样本的方法则被称为降采样(Undersampling)。随机过采样(ROS,Random Over-Sampling)与随机降采样(RUS,Random Under-Sampling)是最简单、也是最为常用的样本采样技术。但上述二者均有其各自的缺点,其中,前者会增加分类器建模的时空开销,并易于产生过适应的现象,而后者则会造成分类信息严重缺失,从而导致分类性能显著下降。为克服随机采样的缺点,Chawla等人[6]于2002年提出了一种新的过采样方法:SMOTE(Synthetic Minority Oversampling TEchnique)。不同于随机过采样方法,SMOTE通过在两个邻近的少数类样本间插入虚拟样本,有效解决了ROS方法易于陷入过适应的问题。
可以说,样本采样技术的最大优点在于其过程与分类器训练的过程是相互独立的,故若采用此项技术作为主动学习的平衡控制策略,可能更具实用性与便捷性。
2.2 边界过采样算法
考虑到在主动学习每一轮迭代时,所选取的“查询样本”往往都位于当前分类面,即分类边界附近,故若对少数类样本进行过采样,显然更应该集中在边界域。基于上述思想,对传统的SMOTE算法进行了改进,提出了一种边界过采样(BOS,Boundary Over-sampling)算法,使其仅能对边界少数类样本进行过采样,该算法的流程描述如下:
算法1:BOS算法
输 入 :训 练 集S={(xi,yi),i=1,2,…,N,yi∈{+,-}};多数类样本数N-,少数类样本数N+,其中,N-+N+=N;不平衡比率IR=N-/N+;近邻数K,边界样本比例λ
输出:过采样后的训练集S’={(xi,yi),i=1,2,…,N,i=1,2,…,2×N-,yi∈{+,-}}
算法步骤:
1)从训练集S中取出全部多数类与少数类样本,组成多数类样本集S-及少数样本集S+;保留全部的多数类训练样本,选取最靠近分类面的λ*N+个少数类样本,并置于一个独立的集合S+Neighbor;
2)置新生成样本集SNew为空;
3)Fori=1:|N--N+|
①在S+Neighbor中随机选取一个少数类样本x,作为主样本;
②在S中找到主样本x的K近邻样本,并将其置于近邻样本集SNer中;
③在SNer中随机指定一个主近邻样本x’;
④通过下式计算得到新的虚拟的边界少数类样本xnew:xnew=x+rand×(x’-x),其中,rand∈[0,1];
⑤ 添加xnew至SNew,即SNew=SNew∪xnew;
⑥置近邻样本集SNer为空;
End
4)得到过采样后的训练集S’=S∪SNew。
从上述算法流程不难看出:BOS算法是对SMOTE算法的一种改进,即仅在靠近边界区域的部分样本上执行SMOTE算法过程。当然,这个“部分”的范畴是由参数λ所指定的,可以说,该参数设置的好坏与否将直接影响到最终的采样效果。
2.3 极限学习机与主动极限学习机
极限学习机(ELM,Extreme Learning Machine)是由南洋理工大学Huang等人[7]于2006年所正式提出的一种单隐层前馈神经网络训练算法。ELM通过随机指定隐层参数,并利用最小二乘法求解输出层权重的方式来训练网络,故其具有泛化能力强、训练速度快等优点[8-9]。
设训练集包括N个训练样本,可将其表示为(xi,ti)∈Rn×Rm,其中,xi表示n×1维的输入向量,ti表示第i个训练样本的期望输出向量,n即代表训练样本的属性数,m则代表样本的类别数。若一个具有L个隐层节点的SLFN能以零误差拟合上述N个训练样本,则意味着存在βi,ai及bi,使得:
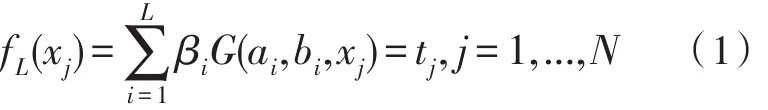
其中,ai和bi分别表示第i个隐层节点的权重与偏置,βi表示第i个隐层节点到各输出节点的连接权重,则式(1)可进一步简化为下式:

其中
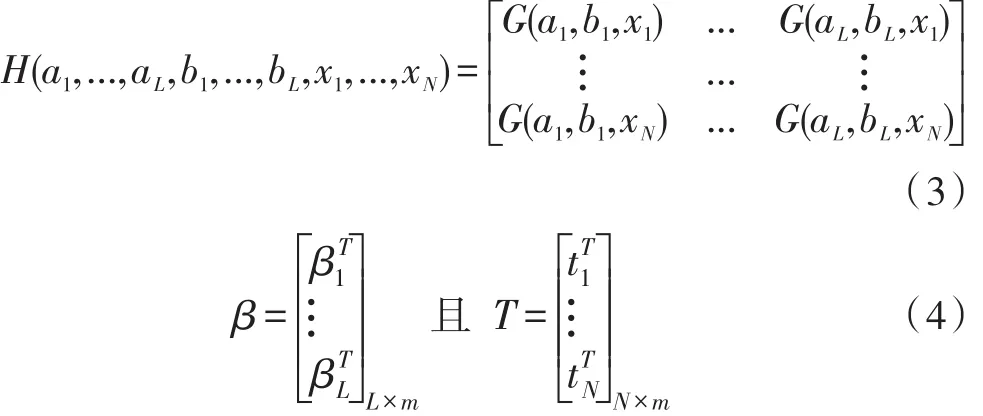
其中,G(ai,bi,xj)表示第j个训练样本在第i个隐层节点上的激活函数值,T为所有训练样本对应的期望输出矩阵,H被称为隐层输出矩阵,其第i列为第i个隐层节点在所有训练样本上的输出向量,第j行为第j个训练样本在整个隐藏层中对应的输出向量。
在ELM中,由于所有ai和bi均是在[-1,1]区间内随机所生成的,故输入样本、隐层权重与偏置、期望输出(类别标记)均已知,则输出权重矩阵β的近似解̂即可由下式直接计算得到的:

其中,H†为隐层输出矩阵的Moore-Penrose广义逆。根据其定义,可推知为该网络的最小范数最小二乘解。由于在求解过程中,约束了输出权重矩阵β的l2范数,使其最小化,故可保证网络具有较强的泛化性能。鉴于ELM的优点,其也在诸多应用领域得到了应用,如行为识别[10]、遥感图像分类[11]、电价预测[12]、风能生成预测[13]及生物信息学[14]等。
主动极限学习机,即AL-ELM算法,是Yu等人[4]所提出的一种以ELM作为基分类器,且以样本在ELM中的输出值作为不确定性度量准则,进而选取“查询样本”的主动学习算法。受篇幅所限,在此不再赘述,有关该算法的具体细节,可参见文献[4]。
2.4 结合采样技术的主动不平衡极限学习机算法
结合AL-ELM算法与样本采样技术,可知主动不平衡极限学习机算法的具体流程如下:
算法2:主动不平衡极限学习机算法
输入:初始已标注样本集L,未标注样本集U;样本采样算法P
输出:最终的极限学习机分类器M
算法步骤:
1)利用初始已标注样本集L训练一个初始的极限学习机分类器M;
2)采用M,并利用AL-ELM算法中的“查询样本”选择策略,选取并标注查询样本,进而将其置入集合Sselect中;
3)while(未达到学习停止条件)
①L=L+Sselect;
②U=U-Sselect;
③ 置Sselect为空;
④调用样本采样算法P对样本集L进行采样处理;
⑤利用已标注样本集样本集L对分类器M进行更新;
⑥采用M,并利用AL-ELM算法中的“查询样本”选择策略,在U中选取并标注查询样本,进而将其置入集合Sselect中;
⑦若达到学习停止条件,则退出,否则转步骤①;
End
4)输出最终训练的极限学习机分类器M。
从上述算法流程中,可以看出:其与传统的主动学习算法仅有一点不同,即该算法在提取并标注“查询样本”后,多出了一个平衡控制过程,而这一过程采用了样本采样的策略,采样算法既可以选择RUS、ROS、SMOTE,也可以选择本文所提出的BOS算法。
3 实验结果与分析
3.1 数据集描述
文中实验共采用了12个采集自Keel数据库[15]的基准数据集,用以比较传统的主动学习算法和采用了样本采样技术作为平衡控制策略的主动学习算法之间的性能。特别需要说明的是,实验所选取的数据集均为二类数据集,有关这些数据集的具体信息如表1所示。
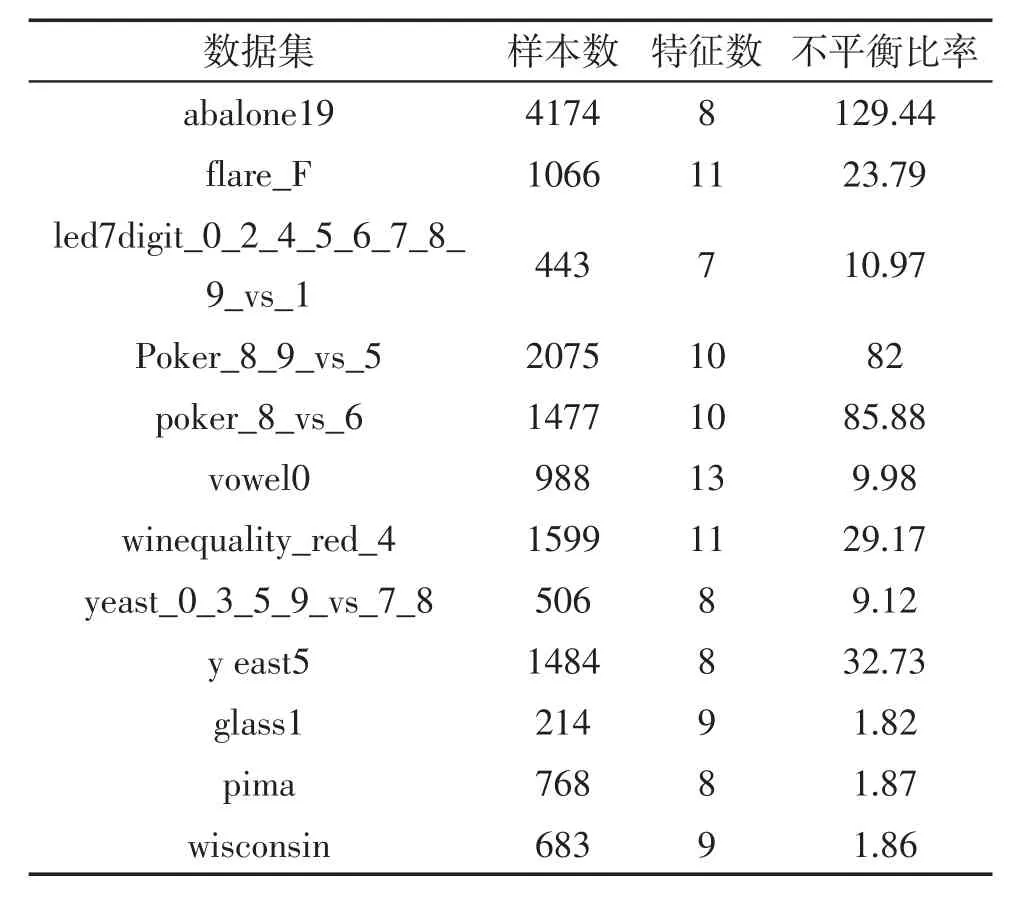
表1 实验所用数据集
3.2 实验设置
为证明样本的不平衡分布确实会对主动学习产生影响,同时也为了展示加入了平衡控制策略的算法的优越性,确定了如下5种比较算法:
1)AL-ELM:即基准的主动极限学习机算法[4];
2)AL-ELM-RUS:即以RUS算法作为平衡控制策略的主动极限学习机算法;
3)AL-ELM-ROS:即以ROS算法作为平衡控制策略的主动极限学习机算法;
4)AL-ELM-SMOTE:即以 SMOTE 算法作为平衡控制策略的主动极限学习机算法;
5)AL-ELM-BOS:即以BOS算法作为平衡控制策略的主动极限学习机算法;
在实验中,预设各数据集初始已标注样本比例为15%,未标记样本比例为55%,剩余的30%作为测试样本。主动学习考虑基于池的场景,以批处理方式进行,每轮标注初始未标注样本集规模的5%。为了窥探主动学习过程的全貌,故未预设学习停止条件,即意味着学习过程将随着未标注样本池中的样本耗尽位置。
此外,考虑到对于不平衡分类问题而言,整体分类精度不再是一种有效的性能测度,故采用G-mean测度及ALC测度[4]来反应各算法的性能。
最后,对于ELM分类器,其参数在各类算法上均保持统一设置,即激活函数选用Sigmoid,隐层节点数为100,惩罚因子则设为10000。
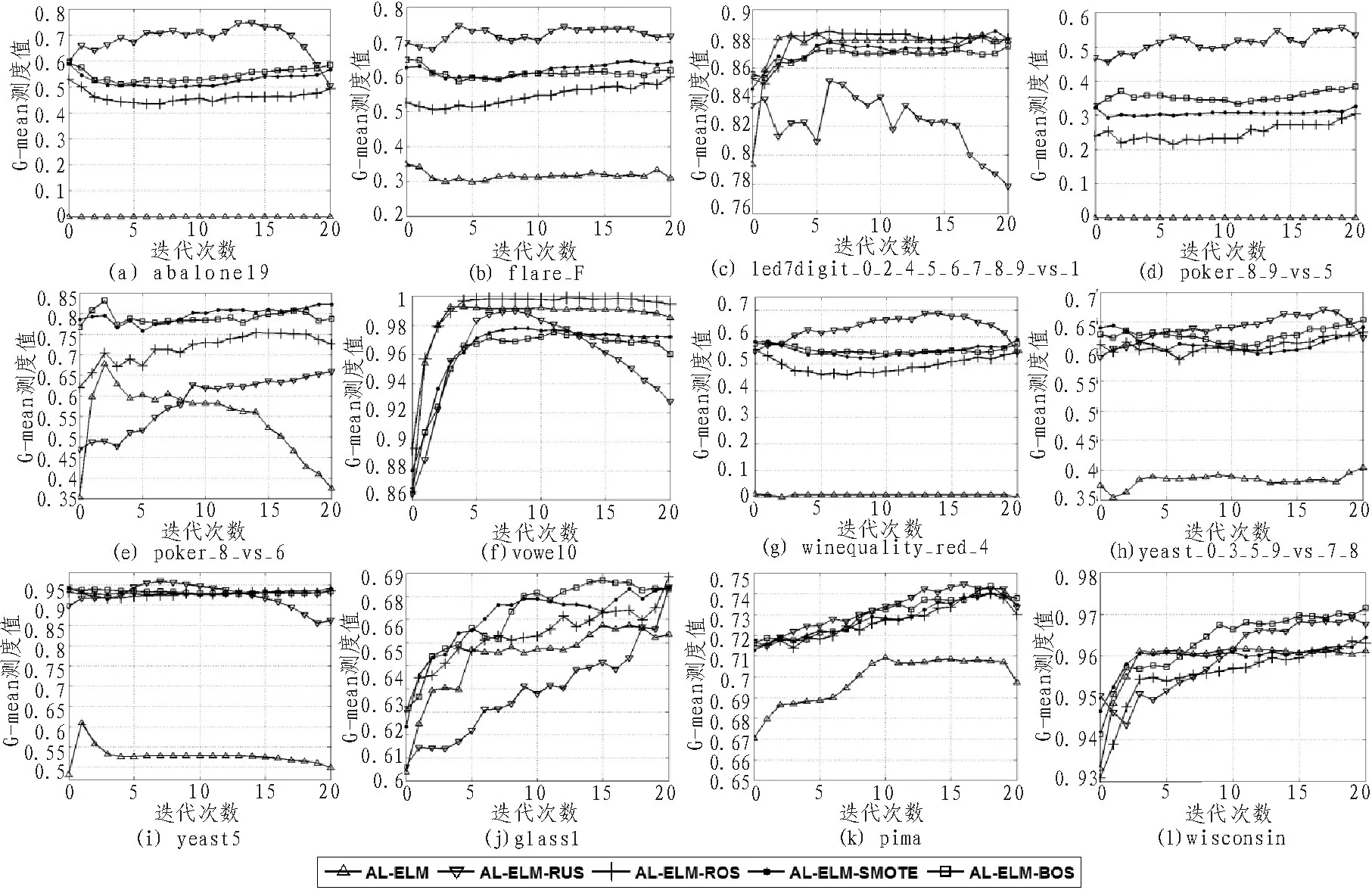
图2 五种学习算法在12个数据集上的学习曲线
3.3 结果与讨论
图2给出了5种主动学习算法在12个数据集上的学习曲线,而表2则给出了它们对应的ALC测度值和学习过程中能达到的MAX G-mean测度值,其中,用粗体标识每个数据集上最优的结果,粗斜体则标识第二好结果。
基于上述图表中的结果,可得出如下结论:
1)在绝大多数数据集上,采用样本采样技术做平衡控制策略的主动学习算法均要优于原始的主动学习算法。实际上,这一现象是易于解释的,这主要是因为前者采用了平衡控制策略,故在学习过程中的每一轮所训练的分类面位置均是相对公正的,故可保证所选取的“查询样本”的公正性,而后者则无法保证这一点。另从ALC和Max G-mean测度值中可以看出,原始的主动学习算法几乎总是处于较低水平。所以可以得出主动学习算法的性能确实会受到样本不平衡分布负面影响的结论。
2)AL-ELM-RUS算法在超过半数数据集上均获得了优于其它算法性能的结果。这种现象不仅体现在那些不平衡比率较低的数据集上,在某些极度不平衡数据集上,如abalone19数据集,也是如此。因此,我们相信这不仅与数据集的不平衡比率有关,可能还关联着诸多的因素,如样本的类重叠面积大小、训练样本的绝对数量、噪声样本的比率等[16]。此外,RUS算法也有着过采样算法所无法比拟的一个优势,那就是时间复杂度低。故在实际应用中,AL-ELM-RUS算法将是一个较好的备选方案。
3)相比于AL-ELM-ROS与AL-ELM-SMOTE算法,AL-ELM-BOS算法显然已在更多数据集上获得了较优的性能。这一现象也不难理解:首先,ROS算法易于导致分类模型陷入过适应;其次,SMOTE算法在生成虚拟少数类样本时,采取的是均匀采样,而主动学习所标注的多数类样本则普遍存在于分类边界附近,这就导致了在边界区域的样本分布不均衡;最后,BOS算法虽然继承自SMOTE算法,但其生成的少数类样本均分布于分类边界附近,这便可保证下一轮所生成分类面位置的合理性。
4)当然,也有一些特殊的情况存在,如在led7digit_0_2_4_5_6_7_8_9_vs_1和vowel0这两个数据集上,原始的AL-ELM算法的分类性能始终处于一个较高的水平,甚至要好于那些添加了平衡控制策略的主动学习算法。我们认为上述现象的出现仍与样本分布的特点相关,这两个数据集上不同类样本的分布显然具有更强的可分性。
基于上述分析,可凝练得出如下两点结论:1)在大多数情况下,样本的类别不平衡分布会对传统的主动学习算法产生负面影响;2)在主动学习的每一轮迭代过程中引入样本采样技术,确实可明显提升其性能,且采取随机降采样法或本文所提出的边界过采样法有望获得更好的性能。
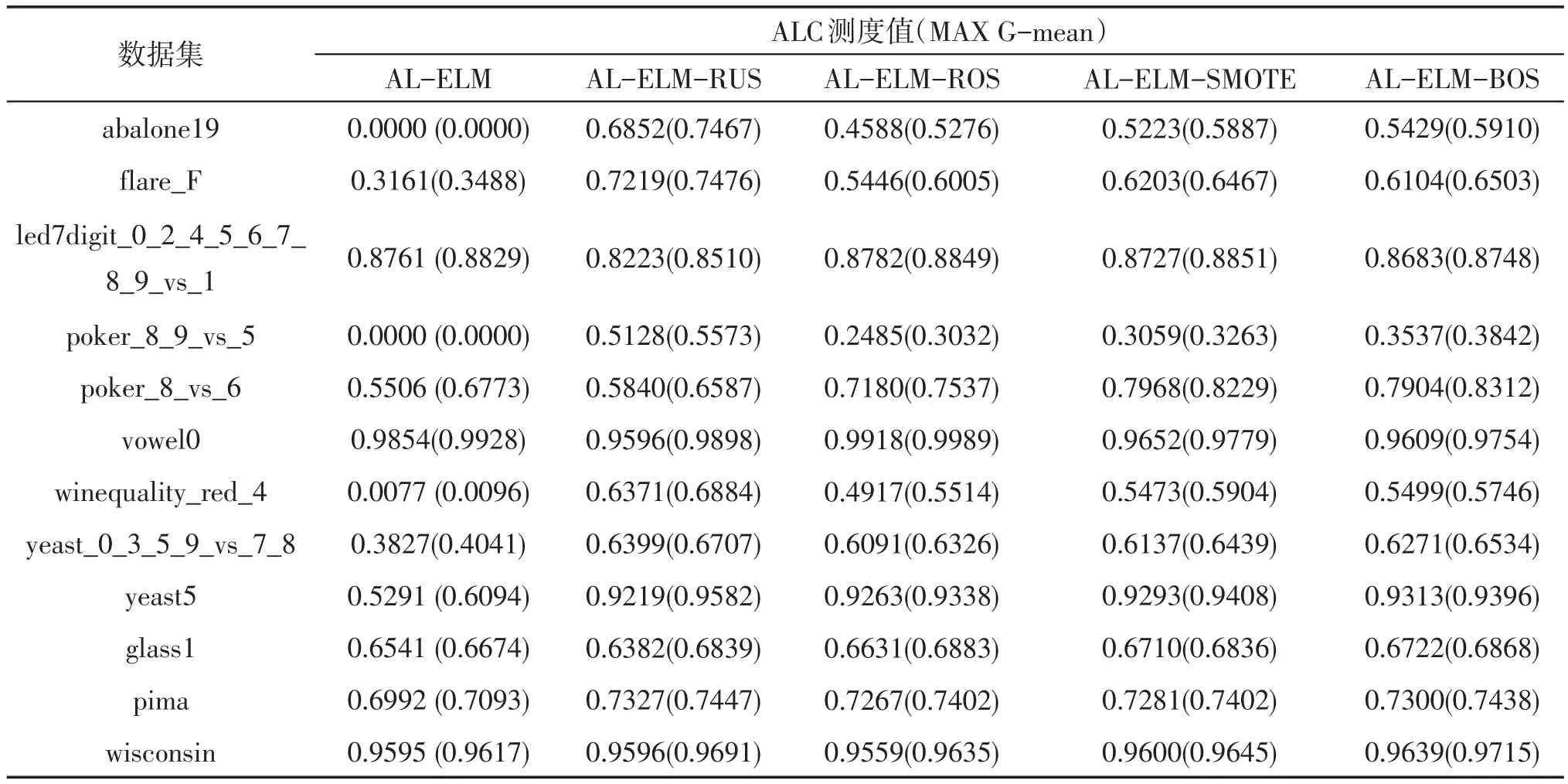
表2 5种学习算法在12个数据集上的ALC测度值和MAX G-mean值
4 结束语
针对在样本类别分布不均衡时,传统的主动学习算法可能失效这一问题展开了调查与研究。提出在主动学习过程中,引入样本采样技术作为平衡控制策略,并在分析其过程的基础上,对SMOTE算法进行了改进,进而提出了一种边界过采样算法,即BOS算法。考虑到极限学习机所具有的诸多优点,采用其作为主动学习的基分类器。通过12个基准二类不平衡数据集对上述算法思想进行了验证,表明了其有效性与可行性。在未来工作中,希望能将本文工作扩展应用于多类不平衡数据上,同时也希望能借鉴类别不平衡学习领域的最新成果,以提出更为有效与高效的平衡控制算法。
[1]Ertekin S,Huang J,Giles C L.Active learning for class imbalance problem[C]//Proceedings of the 30th annual international ACM SIGIR conference on research and developmentin information retrieval,ACM Press,2007:823-824.
[2]Ertekin S,Huang J,Bottou J,et al.Learning on the border:active learning in imbalanced data classification[C]//Proceedings of the sixteenth ACM conference on information and knowledge management,ACM Press,2007:127-136.
[3]Zhu J,Hovy E.Active Learning for Word Sense Disambiguation with Methods for Addressing the Class Imbalance Problem[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,Prague,2007:783-790.
[4]Yu H,Sun C,Yang W.AL-ELM:One uncertaintybased active learning algorithm using extreme learning machine[J].Neurocomputing,2015(166):140-150.
[5]Wang M,Hua X S.Active learning in multimedia annotation and retrieval:a survey[J].ACM Transactions on Intelligent System and Technology,2011,2(2):210-231.
[6]Chawla N,Bowyer K W,Hall L O.SMOTE:Synthetic Minority Over-Sampling Technique[J].Journal of Artificial Intelligence Research,2002,16(1):321-357.
[7]Huang G B,Zhu Q Y,Siew C K.Extreme learning machine:theory and applications[J].Neurocomputing,2006(70):489-501.
[8]Huang G B,Zhou H,Ding X,et al.Extreme learning machine for regression and multiclass classification[J].IEEE Transactions on Systems,Man and Cybernetics,Part B:Cybernetics,2012,42(2):513-529.
[9]Huang G,Huang G B,Song S,et al.Trends in Extreme Learning Machine:A Review[J].Neural Networks,2015,61:32-48.
[10]Minhas R,Baradarani A,Seifzadeh S,et al.Human action recognition using extreme learning machine based on visual vocabularies[J].Neurocomputing,2010,73(10-12):1906-1917.
[11]Samat A,Du P,Liu S,et al.ELMs:Ensemble ExtremeLearningMachinesforHyperspectral Image Classification[J].IEEE Journal of Selected Topics in Applied Earth Observations And Remote Sensing,2014,7(4):1060-1069.
[12]Chen X,Dong Z Y,Meng K,et al.Electricity Price Forecasting With Extreme Learning Machine and Bootstrapping[J].IEEE Transactionson Power Systems,2012,27(4):2055-2062.
[13]WanC,XuZ,PinsonP,etal.ProbabilisticForecasting of Wind Power Generation Using Extreme Learning Machine[J].IEEE Transactions on Power Systems,2014,29(29):1033-1044.
[14]Li L N,Ouyang J H,Chen H L,et al.A Computer Aided Diagnosis System for Thyroid Disease Using Extreme Learning Machine[J].Journal of Medical Systems,2012,36(5):3327-3337.
[15]Alcalá-Fdez,Fernandez A,Luengo J,et al.KEEL Data-Mining Software Tool:Data Set Repository,Integration of Algorithms and Experimental Analysis Framework[J].Journal of Multiple-Valued Logic and Soft Computing,2011(17):255-287.
[16]Lopez V,Fernandez A,Garcia S,et al.,An insight into classification with imbalanced data:Empirical results and current trends on using data intrinsic characteristics[J].Information Science,2013,250(11):113-141.
猜你喜欢
科技创新与应用(2020年6期)2020-02-29 10:39:27
人民珠江(2019年4期)2019-04-20 02:32:00
测控技术(2018年10期)2018-11-25 09:35:26
自动化学报(2018年2期)2018-04-12 05:46:21
制造技术与机床(2017年4期)2017-06-22 11:17:32
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
