
Hadoop技术在云数据中心的应用研究
2018-01-08 06:51李自尊冯建汤进
河南科技 2017年21期
李自尊 冯建 汤进
(黄委会信息中心数据中心,河南 郑州 450000)
Hadoop技术在云数据中心的应用研究
李自尊 冯建 汤进
(黄委会信息中心数据中心,河南 郑州 450000)
针对大数据时代如何存储、处理、分析、利用海量的电子数据,以及传统数据中心向云数据中心转型进程中大量服务器被闲置的问题,对Hadoop家族中的关键技术HDFS、MapReduce、Mahout进行深入研究,并在此基础上提出了基于云平台的Hadoop集群应用研究方案。方案包括Hadoop集群拓扑结构、开发运行环境部署流程及基于Hadoop集群的Mahout中贝叶斯分类算法的实现。实验作为整合数据中心资源进行规模部署Hadoop集群的研究基础,证明了Hadoop集群的可用性及其在数据分析方面良好的适应性。
Hadoop;云数据中心;Mahout;贝叶斯
1 研究背景
随着大数据时代的到来,如何存储、处理、分析、利用海量的电子数据,成为各个行业亟待解决的问题。Ha⁃doop是由Apache基金会开发的一个开源分布式系统的基础架构,提供用于构建分布式系统的数据存储、数据分析及协调处理工具,在大数据分析领域应用广泛,已经积累了大量用户[1]。国内外知名企业如Google、Facebook、eBay、百度及阿里巴巴等,都基于Hadoop进行数据挖掘和分析,许多高校和研究机构也将Hadoop应用到教学、实验和研究中[2]。
云数据中心采用云计算理念和虚拟化技术,集成整合数据中心现有基础资源,构建存储备份资源池、计算资源池,对资源统一管理、调配,具有高效、高可用及弹性部署等特点。传统数据中心向云数据中心转型的过程中,业务系统逐步由单台独立的服务器迁移至云平台,而这会导致大量的服务器闲置。整合旧有服务器,部署Ha⁃doop集群环境,可以有效利旧原有设备资源,实现资源的绿色循环使用[3]。
本文通过对Hadoop框架构建技术进行研究,综合利用数据中心云平台高效、弹性的特点,从研究实验的角度搭建基于云平台的Hadoop分布式运行环境,并开展基于机器学习算法的数据分析研究,同时基于桌面云服务,提供开发环境的快速部署,作为整合数据中心资源进行规模部署Hadoop集群的研究基础。
2 Hadoop关键技术
Hadoop作为开源的分布式系统基础架构,主要由分布式存储(HDFS)、分布式计算(MapReduce)等组成。用户可以在不了解Hadoop框架底层细节的情况下,利用Hadoop框架来开发分布式程序,适用于拥有大量计算机且偶尔有大量数据需要存储、分析的场景。
Hadoop已经发展成为包含很多项目的集合,虽然核心项目是HDFS和MapReduce,但与Hadoop相关的HBase、Pig、Hive、ChuKwa、Zookeeper等项目也是不可或缺的。它们提供了互补性服务或在核心层上提供了更高层的服务[4]。
2.1 HDFS
Hadoop由许多不同的文件系统组合而成,它提供了文件系统实现的各类接口,HDFS是众多文件系统中应用最多的一个文件系统实例,是分布式计算的存储基石。HDFS支持数据密级型分布式应用,采用主从(Master/Slave)结构模型,由一个命名节点NameNode和若干个数据节点DataNode组成。NameNode作为主服务器,管理文件系统命名空间和客户端访问,如打开、关闭、重命名文件或目录等,以及数据块到具体DataNode的映射;DataNode负责进行数据存储的同时,还负责响应客户端的读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。从内部来看,文件被分成若干个数据块(默认为64MB),而且放在一组DataNode上,由Na⁃meNode维护文件的元数据信息,具体如图1所示[5,6]。
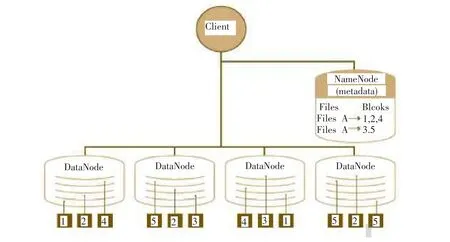
图1 HDFS数据存储示例
2.2 MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群中的多个节点上,执行并行计算,然后再把计算结果合并,从而得到最终结果。多节点计算,涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成。
Map和Reduce函数的输入输出都是键(key)-值(value)对的形式,而Map的输出就是Reduce的输入。Map中输出的键值对中所有键相同的值都会传递给同一个Reduce进行处理,Reduce将输入的键-值对转化合并为规模更小的键-值对组合[5,6]。
MapReduce计算模型如图2所示。
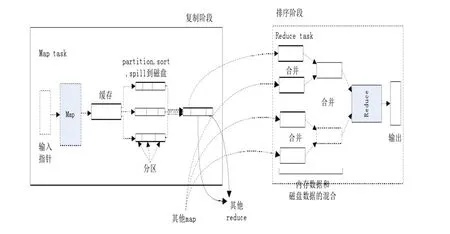
图2 MapReduce计算模型
2.3 Mahout
Mahout是一个强大的数据挖掘工具,其主要目标是建立可伸缩的机器学习算法,最大的优点就是基于Ha⁃doop实现,把很多以前运行于单机上的算法转化为MapReduce模式,大大提升了算法可处理的数据量和处理性能。目前,Mahout项目主要包括以下五部分[7,8]。①推荐引擎(协同过滤):获得用户的行为并从中发现用户可能喜欢的事务;②聚类:将诸如文本、文档之类的数据分成局部相关的组;③分类:利用已经存在的分类文档训练分类器,对未分类的文档进行分类;④频繁模式挖掘:挖掘数据中频繁出现的项集;⑤频繁子项挖掘:利用一个项集(查询记录或购物目录)去识别经常一起出现的项目。
3 基于云平台的Hadoop技术应用研究
3.1 基于云平台的Hadoop集群拓扑结构
云数据中心的建设采用虚拟化技术和云平台管理理念,新增必需的高性能资源池服务器及共享存储,集成整合数据中心现有基础资源,构建存储备份资源池、计算资源池,实现了物理资源的整合共享、灵活管理,方便了应用系统的部署,同时避免了业务重复建设造成的资源浪费,提高了服务器、存储的复用率。
在对传统数据中心进行云化改造的过程中,原有系统从旧有X86服务器逐步迁移至云平台,传统业务区将有大量的旧有X86服务器被闲置。Hadoop集群由于其内部冗余及高可靠性的工作机制,可以部署在任意数台普通的X86服务器中,因此,整合旧有X86服务器,部署Ha⁃doop集群环境,为偶尔需要进行大数据量的分析提供分布式平台,可以有效利旧原有设备资源,实现资源的绿色循环使用。
在进行研究阶段,借助云平台高效、弹性等特点,在云上部署Hadoop集群进行初步探索。同时,利用云平台的基于模板快速部署开发环境的特点,可以将配置复杂的Hadoop开发运行环境制作成模板,便捷发布,提高实验及开发效率。
3.2 Hadoop集群搭建
3.2.1 环境配置。①硬件环境配置:部署3个节点Hadoop集群开展实验研究,开通3台虚拟服务器,配置均为vCPU4个,内存8G,磁盘200G。②网络环境配置:Mas⁃ter作为NameNode、ResourceManager;Node1及Node2作为DataNode、NodeManager;3个节点的IP均在10.4.234.xx网段。③软件环境配置(见表1)。

表1 软件配置表
3.2.2 Hadoop开发运行环境部署流程。Hadoop开发运行环境搭建主要包括4部分内容,即软硬件环境准备、Hadoop集群部署、开发环境配置及Mahout模块配置,具体流程如图3所示。
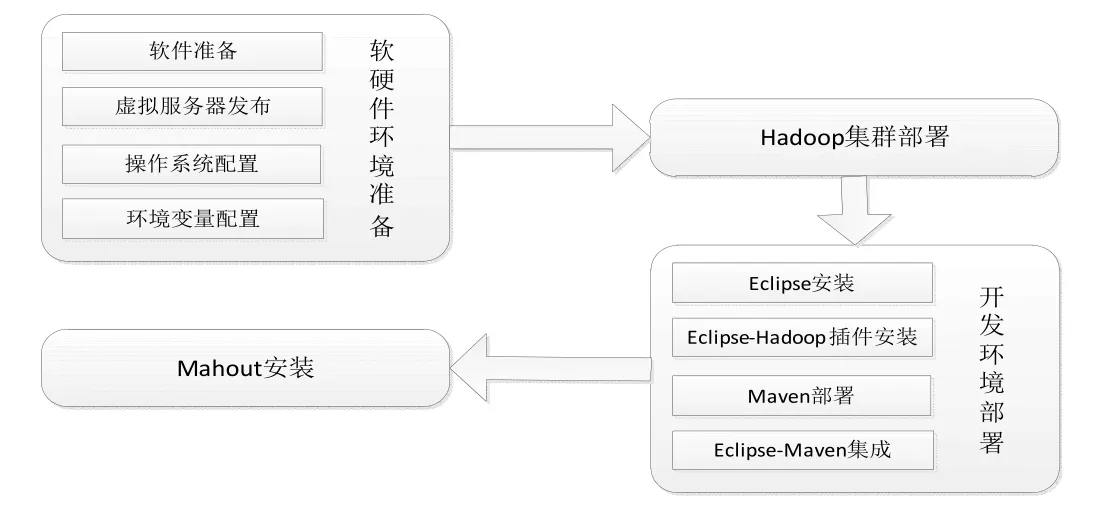
图3 Hadoop开发运行环境部署流程图
3.2.3 Hadoop集群部署。Hadoop集群的配置过程主要包括三个步骤:前期环境准备、Hadoop集群软件安装、安装效果验证。前期环境准备工作包括服务器防火墙设置、network及hosts文件配置及SSH配置;Hadoop集群软件安装工作包括Hadoop主节点软件部署、配置文件修改及从节点配置同步分发;安装效果验证工作包括Ha⁃doop集群初始化、集群启动、进程和管理界面检查及任务执行。
在部署过程中,需要修改的配置文件主要有5个,分别为:①hadoop-env.sh配置,指定JDK的安装位置;②core-site.xml:Hadoop核心的配置文件,配置HDFS的地址及端口号;③hdfs-site.xml:HDFS配置,配置副本数为2份;④mapred-site.xml:MapReduce配置文件,配置Job⁃tracker的地址及端口号;⑤yarn-site.xml:yarn配置文件,配置yarn进行资源管理调度的地址及端口号。
3.3 Hadoop技术应用
3.3.1 朴素贝叶斯算法实现。朴素贝叶斯算法是基于贝叶斯定理与特征条件独立假设的分类方法,其分类的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率哪个最大,就认为此待分类项属于哪个类别[9,10]。
本实验以20NewsGroup为例,针对文档分类的具体问题,在Hadoop集群上运行Mahout中的朴素贝叶斯算法,实现对文档分类模型的训练,并测试模型分类的效果。
20NewsGroup包含了被分成20个新闻组的20 000个新闻组文档,20个新闻组按照20个不同的类型进行组织,不同的类对应不同的主题。其中,60%用来进行训练贝叶斯分类算法,40%用来测试分类模型。具体实验流程如图4所示。
第一,准备数据,并将数据上传至HDFS。
//解压后得到20news-bydate-train和20news-bydatetest两个文件夹,上传至HDFS;
#tar-zvxf 20news-bydate.tar.gz.
#hdfs dfs-put 20news-bydate-train.
#hdfs dfs-put 20news-bydate-test.
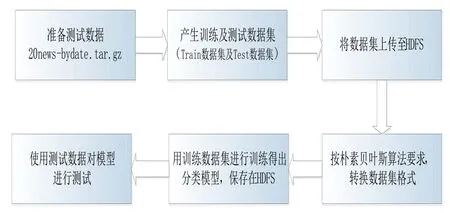
图4 基于Hadoop集群的文档分类流程图
第二,转换数据集格式。
//转换为序列文件(sequence files)
#mahoutseqdirectory-i20news-bydate-train-o 20news-bydate-train-seq
#mahoutseqdirectory-i20news-bydate-test-o 20news-bydate-test-seq
//转换为tf-idf向量
#mahoutseq2sparse-i20news-bydate-train-seqo 20news-bydate-train-vector-lnorm-nv-wt tfidf
#mahoutseq2sparse-i20news-bydate-test-seq-o 20news-bydate-test-vector-lnorm-nv-wt tfidf
第三,训练朴素贝叶斯模型。
#mahouttrainnb-i20news-bydate-train-vector/tfidf-vectors-o model-li labelindex-ow.
第四,测试朴素贝叶斯模型。
#mahout testnb-i 20news-bydate-train-vector/tfidfvectors-m model-l labelindex-ow-o test-result.
3.3.2 结果分析。通过上述实验,基于Hadoop集群运行Mahout中的贝叶斯算法对文档进行分类,生成分类结果向量模型表,并得到分类结果的准确率及标准差。可见,在云平台环境中的Hadoop集群搭建成功,可以进行数据的分布式存储及并行计算,同时对机器学习算法具有良好的兼容性。
4 结论
本文提出了一种基于云平台搭建Hadoop集群进行实验研究的方法,通过采用虚拟化技术和云平台管理理念,快速部署Hadoop集群运行开发环境,并采用其家族成员Mahout中的机器学习算法,构建文档分类模型,对基于Hadoop集群的数据分析模式进行研究,是整合数据中心资源进行规模部署Hadoop集群的有效探索途径。
[1] 王伟,陶然.基于虚拟化技术的Hadoop集群搭建与应用[J].软件导刊,2016(4):50.
[2] 牛怡晗,海沫.Hadoop平台下Mahout聚类算法的比较研究[J].计算机科学,2015(6A):465.
[3] 李自尊,冯建,汤进.基于虚拟化技术的云数据中心基础设施规划方案[J].河南科技,2015(3):1.
[4] 费珊珊.基于云计算Hadoop平台的数据挖掘研究[D].北京:北京邮电大学,2013.
[5] 道客巴巴.基于Hadoop的大数据应用分析[EB/OL].(2016-04-02)[2017-10-09].http://www.docin.com/p-1514875735.html.
[6] Tom White.Hadoop权威指南[M].北京:清华大学出版社,2015.
[7] 陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2012.
[8] Naive Bayes[EB/OL].[2017-10-09].http://mahout.apache.org/users/classification/bayesian.html.
[9] 王慧.基于Hadoop的并行挖掘算法的研究[D].北京:首都师范大学,2013.
[10] 曾宇平,徐飞龙.基于Hadoop的分布式朴素贝叶斯智能诊断系统[J].医学信息学杂志,2015(7):53.
The Hadoop Technology Application Research on Cloud Data Center
Li ZizunFeng JianTang Jin
(Data Center,The Yellow River Conservancy Commission Information Center,Zhengzhou Henan 450000)
To solve the issues of how to store,process,analyze and utilize the vast amount of electronic da⁃ta in the big data era,and utilize the large number of servers in the transition process of traditional data center to cloud data center,the article advanced a set of Hadoop cluster application research scheme based on cloud platform through in-depth study of the key technologies of HDFS,MapReduce,Mahout in the Hadoop family.The scheme includes the topology of the Hadoop cluster,the development process of development and operating environment,and the implementation of the bayesian classification algorithm in Mahout based on Hadoop cluster.
Hadoop;cloud data center;Mahout;bayesian algorithm
TP311.13
A
1003-5168(2017)11-0025-04
2017-10-09
李自尊(1990-),女,硕士,工程师,研究方向:数据中心运维管理。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
建材发展导向(2021年7期)2021-07-16
法律方法(2021年4期)2021-03-16
军事运筹与系统工程(2019年4期)2019-09-11
西藏艺术研究(2019年1期)2019-09-04
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
