
卷积神经网络及其研究进展
2018-01-05 08:17:32翟俊海张素芳郝璞
河北大学学报(自然科学版) 2017年6期
翟俊海,张素芳,郝璞
(1.河北大学 数学与信息科学学院 河北省机器学习与计算智能重点实验室,河北 保定 071002; 2.中国气象局气象干部培训学院 河北分院,河北 保定 071002)
卷积神经网络及其研究进展
翟俊海1,张素芳2,郝璞1
(1.河北大学 数学与信息科学学院 河北省机器学习与计算智能重点实验室,河北 保定 071002; 2.中国气象局气象干部培训学院 河北分院,河北 保定 071002)
深度学习是目前机器学习领域最热门的研究方向,轰动全球的AlphaGo就是用深度学习算法训练的.卷积神经网络是用深度学习算法训练的一种模型,它在计算机视觉领域应用广泛,而且获得了巨大的成功.本文的主要目的有2个:一是帮助读者深入理解卷积神经网络,包括网络结构、核心概念、操作和训练;二是对卷积神经网络的近期研究进展进行综述,重点综述了激活函数、池化、训练及应用4个方面的研究进展.另外,还对其面临的挑战和热点研究方向进行了讨论.本文将为从事相关研究的人员提供很好的帮助.
机器学习;深度学习;卷积神经网络;计算机视觉;训练算法
美国心理学家Mcculloch和Pitts于1943年首次提出了人工神经元模型,即著名的M-P模型[1],开启了人工神经网络的研究.在这70多年的时间里,神经网络研究曾经几起几落.Rosenblatt于1958年提出的感知机(Perceptron)模型[2],标志着神经网络研究迎来了第1次热潮,这次研究热潮持续了近10年,直到1969年,Minsky和Papert从数学的角度证明了单层神经网络逼近能力有限[3],甚至连简单的异或问题都不能解决,使神经网络研究陷入了第1次低潮.神经网络研究迎来第2次热潮的起点是Werbos在其博士论文中提出了误差反向传播的思想[4],但当时并没有引起研究人员的关注,直到1986年Rumelhart等成功实现了用反向传播算法[5](即著名的BP算法)训练多层神经网络,神经网络研究才真正迎来第2次研究的热潮,此后近10年,BP算法始终占据统治地位.但是BP算法也有自身的缺陷,例如容易产生过拟合、梯度消失、局部最优等问题.1995年Vapnik和Cortes提出了支持向量机[6](SVM: support vector machine),由于SVM具有坚实的理论基础,在应用中也表现出了比神经网络更好的效果,所以SVM成为热点研究内容,而神经网络研究则不冷不热.人类进入21世纪后,特别是随着大数据时代的到来,神经网络研究又迎来了一次研究热潮,这次研究热潮的起点是2006年加拿大多伦多大学Hinton教授和他的学生Salakhutdinov提出的深度学习思想[7].这次热潮的标志就是深度学习,从某种意义上来讲,深度学习是训练深度模型(如深度神经网络)的算法,这些模型包括:卷积神经网络、受限波尔兹曼机、信念网络和自动编码机[8].文献[9]对深度学习进行了全面深入的综述,具有很高的参考价值.
卷积神经网络(CNN)[10]是一种著名的深度学习模型,其名称的由来是因为卷积运算被引入到了这种模型中.CNN可以归类为多层前馈神经网络模型,但与传统的多层前馈神经网络不同,CNN的输入是二维模式(如图像),其连接权是二维权矩阵(也称为卷积核),基本操作是二维离散卷积和池化(Pooling).由于CNN可以直接处理二维模式,所以它在计算机视觉领域得到了非常广泛的应用.例如,CNN已成功应用于图像分类、目标检测和目标跟踪等许多领域.
实际上,卷积神经网络模型并不是2006年以后才提出的,早在1998年,LeCun等[10]就提出了一种称为LeNet的卷积神经网络模型,并用于手写数字识别.只是由于当时缺乏大规模的训练数据,计算机的计算能力也有限,所以LeNet在解决复杂问题(例如大规模的图像和视频分类问题)时,效果并不好.2006年以后,特别是随着大数据时代的到来,在高性能的计算平台(如高性能的PC机、图形工作站、云计算平台等)上用大规模的数据集训练复杂的模型成为可能.正是在这种背景下,研究人员提出了许多卷积神经网络模型.下面首先以LeNet为例介绍卷积神经网络的结构,并综述相关的研究;然后综述卷积神经网络的训练,包括训练的加速机制和几种常用的开源框架;接下来综述卷积神经网络的应用;最后总结了未来几年卷积神经网络研究的热点和面临的挑战.
1 卷积神经网络的结构
卷积神经网络是一种多层前馈神经网络,其基本构成要素包括卷积层、池化层(也称为采样层)和全连接层.图1是卷积神经网络LetNet的结构图,它有3个卷积层,2个采样层,1个全连接层,加上输入层和输出层共包含8层.从图1可以看出,卷积神经网络LeNet的输入层是二维模式(如图像);隐含层由多个卷积层和采样层交替构成,卷积层用于提取不同的图像特征,采样层用于降维.卷积层和采样层的输出都称为特征映射图(二维模式);全连接层一般是一个分类器(如单隐含层的神经网络).
1.1 卷积层
一般地,每一个卷积层都由若干个结点构成.卷积层通过卷积运算提取图像的不同特征,卷积层结点的结构如图2所示.

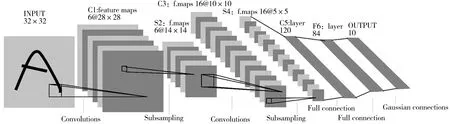
图1 卷积神经网络LetNet的结构[10]Fig.1 Architecture of convolutional neural network LetNet[10]
结点的输出特征图.卷积层结点的输出可用下面的公式表示:
(1)
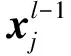
说明:
1)一般地,卷积核(也称为滤波器矩阵)是3×3或5×5的小矩阵;
2)在做卷积运算时,卷积核(滤波器矩阵)与对应的特征图(或图像)的一个局部区域相连接,这个局部区域称为卷积核的局部感受域.整个特征图(或整幅图像)共享卷积核权值,这称为权值共享.

图2 第l个卷积层第j个结点的结构Fig.2 Architecture of jth node in lth convolutional layer
关于卷积层,研究的重点主要在激活函数上.激活函数在卷积神经网络中起着重要作用,它将非线性性质引入到网络中,非线性性质是保证网络具有一致逼近能力的重要因素.另外,因为大多数前馈神经网络(也包括卷积神经网络)的训练算法都是基于误差反向传播的思想,激活函数的性质对梯度的计算具有很大的影响.例如,激活函数的输出饱和程度就严重影响着网络的收敛性,输出饱和程度越高,网络的收敛性越差.因此激活函数对卷积神经网络的训练速度或收敛性具有很大的影响.神经网络训练的稳定性一般通过将网络中的变量(包括网络结点的输入和输出)限定在一定的范围内.而激活函数就有对网络变量限界的作用,所以激活函数对网络训练的稳定性也有重要的影响.总之,激活函数对网络的收敛性、稳定性和一致逼近能力都有重要的影响.
卷积神经网络中的激活函数大致可分为2类:Sigmoid型的和非Sigmoid型的.Sigmoid型的激活函数具有连续性和可微性,它们将输入变量变换到一个有限区间.最常用的Sigmoid型激活函数包括logistic函数和tanh函数.logistic函数将输入变量变换到区间[0,1],其定义为
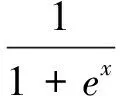
(2)
tanh函数将输入变量变换到区间[-1,1],其定义为

(3)
与logistic函数相比,tanh函数的梯度具有更好的渐变性,而这在神经网络的训练中是更期望的.另外,tanh函数关于原点是奇对称的,这种性质可使网络收敛更快.然而,tanh函数在两侧都具有比较大的饱和区域,这样难以逼近其边界值.因此研究人员通过在tanh函数中引入幅度参数和倾斜参数,提出了伸缩tanh函数[10],可以克服上述缺点.伸缩tanh函数的定义为

(4)
在LeCun等[10]提出的卷积神经网络LetNet中,使用的就是这种激活函数,而且LeCun等通过实验研究发现:α=1.715 9,β=0.666 7时,LetNet的性能最优.
实际上,在2012年以后提出的卷积神经网络模型中,大多用的都不是Sigmoid型的激活函数.例如,在著名的AlexNet模型中[11],使用的激活函数是ReLU (rectified linear unit).常用的非Sigmoid型的激活函数除ReLU外,还包括LReLU (Leaky ReLU)、BiFire (Bi-firing)等.
ReLU激活函数[11]是近年来最著名的非饱和激活函数之一,ReLU的定义为
ReLU(x)=max(x,0),
(5)
Krizhevsky等的工作显示,具用ReLU激活函数的卷积神经网络,即便没有预训练也能有效训练[11].
ReLU的不足之处是当神经元结点没有激活时,其梯度为0.这样可能导致初始没有激活的神经元结点,在梯度优化过程中,它们的权值不会得到调整.另外,由于零梯度还可能降低网络的训练速度.针对这一问题,Mass等[12]提出了LReLU (Leaky ReLU).其定义为
LReLU(x)=max(x,0)+λmin(x,0),
(6)
其中,λ∈是用户预定义的参数.如果将λ改为可学习的参数,则得到PReLU(ParametericReLU)[12-13].
BiFire是Li等提出的另一种新的非Sigmoid型激活函数[14],它能消除梯度扩散现象,其定义为
(7)
其中,A是一个光滑参数.
1.2 池化层
卷积层通过不同的卷积核提取图像的不同特征,而池化层(也称为采样层)通过不同的池化操作对图像进行降维,并提高图像特征的变换不变特性[15].常用的池化操作包括最大池化(max pooling)和平均池化(average pooling).池化操作和卷积操作有类似的地方,即池化窗口按着一定规则在输入特征图中,按从上到下,从左到右顺序的移动.最大池化对窗口所覆盖的子矩阵求其元素的最大值,作为池化输出特征图(一个矩阵)中的一个元素.
近几年,关于池化层的研究主要集中在新的池化操作及将其他技术(例如,Dropout技术、学习技术、自适应技术等)引入到池化中.在最大池化和平均池化的基础上,提出的新池化操作包括混合池化、Lp范数池化、空域金字塔池化等.
Yu等[16]将最大池化和平均池化结合起来,提出了混合池化方法.混合池化可用公式(8)描述.
(8)
其中,λ是取值为0和1的随机变量,Rij是池化区域或池化窗口,|Rij|表示Rij中所含元素个数,αm,n表示窗口中的元素.
Gulcehre等[17]将最大池化和平均池化的思想进行了推广,提出了Lp范数池化(Lp Pooling),其定义如下:

(9)
在文献[18]中,Estrach等对Lp范数池化进行了理论分析,得出了结论:“与最大池化和平均池化相比,Lp范数池化能获得更好的泛化性能”.
He等[19]提出的空域金字塔池化(spatial pyramid pooling)将不同尺度的池化特征图组合在一起,可以得到固定长度的输出特征图,不论输入特征图的大小是多少.在空域池化研究中,研究人员还提出了一些新的方法.例如,Xie等[20]提出了异构特征空域池化方法,Lee等[21]提出了沿时间轴的池化方法,Perlaza等[22]对频域池化和空域池化进行了比较研究.
近几年,研究人员还将其他一些技术等引入到池化中,提出了相应池化方法.例如,Wu等[23]将Dropout技术引入到池化中,提出了Dropout最大池化方法.Wang等[24]将自适应技术引入到池化中,提出了自适应池化方法.Sun等[25]将学习机制引入到池化运算中,提出了一种基于训练误差最小化的学习池化方法.
1.3 新的卷积神经网络模型
在LetNet模型的基础上,最近几年,研究人员提出了许多新的卷积神经网络模型.代表性的模型包括以下几种:
1)Krizhevsky等[11]于2012年提出的AlexNet模型.该模型以巨大的优势获得了当年ImageNet竞赛(也称为ILSVRC(ImageNet large scale visual recognition challenge)竞赛)的冠军,top-5的错误率为16.4%,第2名的top-5的错误率为26.2%.从结构上来讲,AlexNet和LeNet是类似的,但具有更宽和更深的结构.在AlexNet模型中,Krizhevsky等首次成功地应用了ReLU、Dropout和LRN(local response normalization)等技术,同时还使用了GPU(graphics processing unit)加速技术,并开源了他们在GPU上训练卷积神经网络的CUDA(compute unified device architecture)代码[26-27].AlexNet共有8个需要训练参数的层,不包括池化层和LRN层,前5层为卷积层,后3层为全连接层,最后一个全连接层是具有1 000个输出的softmax.AlexNet的成功,确立了其在计算机视觉中的统治地位.
2)Lin等[28]提出的NIN(Network In Network).NIN模型由堆叠在一起的3个MLP(MultiLayer Perceptron)卷积层和一个全局平均池化层构成.MLP卷积层由1×1的卷积层连接一个MLP层,MLP层的作用是增加单个卷积特征的有效性.从NIN的结构可以看出,其思想其实很简单.然而,其后的许多模型,例如,Google Inception Net和ResNet,都用到了NIN的基本思想.
3)Simonyan等[29]提出的VGGNet.该模型获得了2014年ILSVRC竞赛的亚军.与AlexNet模型相比,VGGNet除了包含更多的层(19层)之外,所有的卷积层都使用3×3同样大小的卷积核和2×2同样大小的池化窗口,池化操作采用最大池化.

5)He等提出的ResNet(Residual Neural Network)[34].该模型在2015年的ILSVRC竞赛中获得了冠军,top-5的错误率为3.57%.ResNet包含152层,是一个很深的网络,但是其参数量却比VGGNet低,性能非常优越.ResNet的基本构成模块是残差学习单元,包括2种:2层残差学习单元和3层残差学习单元.在2层残差学习单元中,卷积核大小都是3×3的;在3层残差学习单元中,包括2个大小为1×1的卷积核和一个3×3的卷积核,3×3的卷积核在2个1×1的卷积核之间.ResNet和普通CNN的最大区别在于,ResNet有很多旁路的支线将输入直接连接到后面的层,使得后面的层可以直接学习残差,简化了学习目标和学习难度[26].此外,ResNet通过直接将输入绕道传到输出,保护了信息的完整性,从某种程度上解决了普通CNN的信息丢失问题.
除了上面这些模型外,比较有代表性模型还有Zeiler等提出的ZFNet[35],Iandola等提出的DenseNet[36]和SqueezeNet[37].由于篇幅所限,对于这3种模型不再展开综述,有兴趣的读者可参考相关论文.
2 卷积神经网络的训练
2.1 损失函数
针对具体应用,用卷积神经网络解决实际问题时,选择合适的损失函数至关重要.除传统的均方误差损失函数外,常用的损失函数包括以下几种.
1)软最大化损失函数
给定训练集,D={(xi,yi)|i=1,2,…,niyi∈{1,2,…,k}},对于第i个样例,预测为第j类的后验概率用下面的软最大化函数进行计算:

软最大化损失函数定义如下[11]:
2)对比损失函数


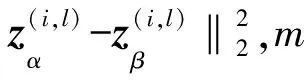
3)K-L散度损失函数
K-L散度是2个概率分布p(x)和q(x)之间的距离度量,其定义为
DKL(p‖q)
在文献[40]中,Kingma等针对自动编码器的训练,提出了一种基于K-L散度的损失函数,其定义如下:
L=Ez~qφ(z|x)logpθ(x|z)-DKL(qθ(z|x)‖p(z)),
其中,φ是编码器参数,θ是解码器参数.该损失函数也适用于卷积神经网络.
2.2 卷积神经网络的训练方法及加速策略
因为从宏观上看CNN属于多层前馈神经网络,所以可以用反向传播算法(BP算法)及其各种改进的版本[41](例如,共轭梯度反向传播算法、递归最小二乘反向传播算法、Levenberg-Marquardt反向传播算法等)进行训练.例如,在LetNet中用的是基于随机梯度下降[42]的随机对角线Levenberg-Marquardt反向传播算法[10].权参数更新公式为

其中,w是权参数,Ep是相对于模式p的瞬时均方误差损失函数,εk是学习率参数.
因为在卷积神经网络中存在权值共享,所以上面公式中的偏导数用下面的公式计算:
其中,uij是结点j到结点i的连接权,Vk是具有权值共享关系的结点编号对(ij)的集合,即结点i和结点j之间的连接共享权值wk.换句话说,对于任意的结点编号对(i,j),如果(i,j)∈Vk,则uij和wk之间有如下关系:
uij=wk.
一般地,学习速率εk不是一个常数.在LetNet中,εk是损失函数沿方向wk的二阶导数

其中,μ是一个常数,hkk是损失函数E关于wk的二阶导数的估计.hkk的计算公式如下:
去掉Hessian矩阵中的非对角线上的元素,上式变为

其中,N是训练集中的样例个数.
随着深度学习的发展,现在的卷积神经网络模型越来越复杂,训练复杂网络需要的数据集越来越大.这样,上述训练LetNet的反向传播算法已不能满足需要.近几年,研究人员提出了一些新的训练卷积神经网络的方法,这些方法都是设法加速网络的训练.根据加速机制,这些方法可大致分为2类:基于GPU或CPU(多核和众核)的硬加速方法和基于加速算法的软加速方法.
基于GPU或CPU(多核和众核)的硬加速方法是将训练卷积神经网络的算法用GPU编程实现,以提高训练的深度,其中,基于GPU的加速方法应用最普遍.在深度卷积神经网络发展中,具有重大影响的AlexNet[11]使用Dropout技术和GPU相结合的方法加速网络的训练.Dropout用于有选择地删除某些神经元,以避免模型过拟合,使用GPU加速训练,以减少训练时间.实际上,其他几种著名的卷积神经网络模型,例如VGGNet、GoogleNet、ResNet等,都是用GPU实现加速.其他代表性的工作包括:Li等[43]提出的2种基于GPU的加速卷积神经网络的训练方法.一种是用于加速卷积神经网络前向计算的图像组合方法,另一种是基于GPU的低内存消耗的训练卷积神经网络的方法,该方法可以训练任意大的网络.Mathieu等[44]提出的基于傅里叶变换的快速卷积神经网络训练方法.该方法对卷积层结点的输入特征图首先做二维离散快速傅里叶变换,然后在频域做卷积运算,并用GPU编程实现.因为相同的特征图傅里叶变换可以反复使用,所以可以加快卷积神经网络的训练.在基于多核和众核的加速方法中,代表性的工作包括:Rajeswar等[45]提出的多核处理器(Multi-core CPUs)和图形处理器(GPUs)的可扩展的卷积神经网络训练方法,与相应的串行训练方法相比,基于多核处理器的训练方法可提高10倍的训练速度,而基于图形处理器的训练方法可提高12倍的训练速度.Zlateski等[46]提出了2种卷积神经网络并行化训练方法,一种是基于多核处理器的并行化训练方法,另一种是基于众核处理器的并行化训练方法.前者能实现与几乎同等物理处理器核的加速效果,而后者可实现90倍加速比.另外,近几年研究人员还提出了基于云计算平台的加速方法.例如,Morcel等[47]提出了一种基于阿帕奇SPARK云计算环境的深度卷积网络训练方法,该方法对卷积操作的加速效果明显,在不同的数据集上可达到40~250倍的加速比.
软加速通过设计加速算法来提高卷积神经网络的训练速度.在这类方法中,除前面Inception V2模型中基于BN的加速方法外[31],研究人员还提出了许多其他的软加速方法.Girshick等[48-49]提出了一种基于区域的卷积神经网络快速训练方法.该方法采用了多任务损失函数,单阶段训练能更新所有网络层参数,具有很快的训练速度.Gusmao[50]提出了一种基于核召回的卷积神经网络快速训练方法.该方法的基本思想是开始用低分辨率核和输入特征图预训练卷积神经网络,然后利用卷积运算的空域扩展性质和全分辨率核精细调整网络参数.与其他方法相比,该方法可减少20%的训练时间,但没有任何精度损失.Cong等[51]将Strassen矩阵乘法的思想应用于卷积运算,提出了一种降低卷积神经网络计算量的快速方法.文献[51]的实验结果显示,计算量能最多减少47%.另外,文献[52]也是用矩阵快速计算方法加速卷积神经网络的训练.Zhang等[53]提出了一种基于响应重构的深度卷积神经网络加速训练方法,该方法通过求解一个具有低秩约束的非线性优化问题来加速深度卷积网络的训练,设计了求解该优化问题的广义奇异值分解方法.Korytkowski等[54]提出了一种基于多特征输入中间缓存技术的卷积神经网络快速训练方法.在该方法中,将多特征看作输入到各个网络层的n个通道图像,这样可加速卷积操作运算,提高网络的训练速度.受支持向量机加速计算的压缩技术和LASSO中筛选技术的启发,Zheng等[55]提出了一种用压缩和召回技术加速训练网络的方法.该方法不仅适用于加速训练卷积神经网络,也适用于其他的深度学习模型,如深度受限波尔兹曼机、深度信念网络、深度自动编码器.Kim等[56]将CNN和ELM结合起来,提出了一种卷积神经网络快速训练方法.在该方法中,在卷积层和池化层之间加入了一个附加层.在CNN的全连接层之后的附加层参数用ELM算法优化,其他的附加层参数用基于ELM的改进的反向传播学习规则进行优化.KIM等提出的方法有2个优点:1)在保持高测试精度的前提下,能极大地降低训练时间;2)用中小型数据集进行训练,也能得到理想的结果.Grinsven等[57]将样例选择的思想引入到卷积神经网络中,提出了一种用选择的样例加速卷积神经网络训练的方法.
目前,许多流行的深度学习开源框架,都提供了训练卷积神经网络的开源代码,有兴趣的读者可参考文献[26]和[27].
3 卷积神经网络的应用
因为卷积神经网络能直接处理图像数据,所以它在计算机视觉领域的应用最广泛.计算机视觉领域中的各种任务都有卷积神经网络大量成功的应用,包括图像分类、目标跟踪、目标检测等.另外,卷积神经网络在语音识别、文本分类中也有成功的应用.
3.1 图像分类
卷积神经网络在图像分类中的应用最有影响的工作是Krizhevsky等提出的AlexNet[11],该模型在2012年的ImageNet[58]大规模图像分类竞赛(ILSVRC)中以超过第二名10个百分点的成绩获得冠军.在这一工作的激励下,随后几年提出的几种卷积神经网络模型在图像分类中都取得了非常好的成绩.例如,在2014年进行的ILSVRC竞赛中,VGGNet和GoogLeNet的Top-5精度分别达到了92.7%和93.3%.在2015年,ResNet在1 000类的图像分类中,Top-5精度达到了96.43%,超过人类的分类能力.近几年,研究人员还提出了许多图像分类新方法.例如,Han等[59]针对卷积神经网络的密集型计算和密集型内存需求问题,提出了一种深度压缩方法.该方法包括3个阶段:剪枝、训练量化和哈夫曼编码.在大型图像数据库ImageNet上用AlexNet模型进行实验,在没有精度损失的前提下,内存需求减低了约35倍.用VGG-16进行实验,在没有精度损失的前提下,内存需求减低了约49倍.该论文获得了著名国际会议ICLR2016的最佳论文奖,它在将基于深度卷积神经网络的应用移植到嵌入式或移动设备上,具有重要的参考价值.
3.2 目标跟踪
针对可视对象的在线跟踪问题,Li等[60]利用单卷积神经网络,提出了一种鲁棒而且有效的跟踪算法.该算法用截断结构损失函数作为目标函数,通过鲁棒的样例选择机制,增强随机梯度下降算法训练卷积神经网络的效率.在文献[61]中,Fan等将目标跟踪问题建模为一个机器学习问题.在给定行人前一个位置和步幅的前提下,通过学习来估计行人当前的位置和步幅.在该方法中,卷积神经网络用于从视频的相邻2帧中一起学习行人的空间和时间特征.在文献[62]中,Ma等研究了用卷积神经网络进行可视目标跟踪的相关滤波器的设计与选择问题.针对不同的网络,提出了相应的设计与选择方法.
3.3 目标检测
目标检测是一个更加有挑战性的计算机视觉任务,目标检测是指在目标图像中把对象用矩形框框起来.近几年,研究人员先后提出了R-CNN[63]、Fast R-CNN[64]、Faster R-CNN[49]等代表性的方法.在计算机视觉著名数据集PASCAL VOC上的检测平均精度分别达到了53.3%、68.4%和75.9%.检测速度也越来越快,从R-CNN模型处理1张图片需要2 s多,到Faster R-CNN提高到了198 ms/张.针对目标检测问题,在这些工作的基础上,Zhang等[65]系统研究了具有很深的卷积神经网络的加速问题.Tome等[66]针对行人检测特定任务,提出了一种性能优于传统模型的卷积神经网络结构,能获得很好的检测效果,而且计算复杂度低.最近研究人员提出了2种目标检测的新方法:YOLO[67]和SSD[68],这2种方法能够通过单一通道检测直接预测类别.YOLO将目标检测问题转化为一个回归问题,进行求解.而SSD将包围盒的输出离散化为一组默认的包围盒.2种方法都取得了良好的检测效果.
3.4 其他应用
在计算机视觉领域之外,卷积神经网络应用较多的是语音识别.卷积神经网络能够减少语音信号中的谱变化和谱相关,Sainath等[69]利用这一特性,用卷积神经网络解决大规模语音识别问题,取得了良好的效果.在文献[70]中,Qian等研究了基于卷积神经网络的带噪声语音识别问题,通过选择合适的滤波器、池化,补零机制以及输入特征图的大小,来确定适于带噪声语音识别的卷积网络结构,以增加模型的鲁棒性.除了上面这些经典的应用之外,研究人员还研究了卷积神经网络在其他方面的应用,但这些应用相对较少.例如,Dong等[71]将卷积神经网络应用于从低分率图像生成高分辨率图像的方法.
4 结束语
对卷积神经网络及其研究进展进行了全面的讨论.本文可使读者:1)快速掌握卷积神经网络的核心概念(如权值共享、局部感受域、池化等),也能快速掌握卷积神经网络的结构、运算和训练.2)快速了解卷积神经网络近几年的发展现状、研究热点和应用情况.作者认为,未来几年卷积神经网络研究面临的挑战主要在以下3个方面:①卷积神经网络在多模态大数据(特别是多模态视频大数据)分类中的应用研究;②卷积神经网络在非平衡视频跟踪大数据中的应用研究;③卷积神经网络在云平台上并行化实现研究.热点研究方向包括:自动确定卷积神经网络参数的研究;与其他神经网络如:LSTM、RNN等结合的研究;与强化学习结合的研究;卷积神经网络非梯度下降训练研究.
[1] MCCULLOCH W S,PITTS W.A logical calculus of the ideas immanent in nervous activity[J].Bulletin of Mathematical Biology,1943,52(4):99-115.DOI:10.1007/BF02478259.DOI:10.1007/BF02478259.
[2] ROSENBLATT F.The perception: a probabilistic model for information storage and organization in the brain[J].Psychological Review,1958,65(6):386-408.DOI:10.1037/h0042519.
[3] MINSKY M,PAPERT S.Perceptrons[M].Oxford: MIT Press,1969.
[4] WERBOS P.Beyond regression: New tools for prediction and analysis in the behavioral sciences[D].Boston:PhD Thesis,Harvard University,1974.
[5] RUMELHART D E,HINTON G E,WILLIAMS R J.Learning representations by back-propagating errors[J].Nature,1986,323(6088):533-536.DOI:10.1038/323533a0.
[6] CORTES C,VAPNIK V.Support-vector networks[J].Machine Learning,1995,20(3):273-297.DOI: 10.1007/BF00994018.
[7] HINTON G E,SALAKHUTDINOV R R.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.DOI: 10.1126/science.1127647.
[8] LECUN Y,BENGIO Y,HINTON G E.Deep learning[J].Nature,2015,521:436-444.DOI:10.1038/nature14539.
[9] 余凯,贾磊,陈雨强,等.深度学习的昨天、今天和明天[J].计算机研究与发展,2013,50(9):1799-1804.DOI:10.7544/issn1000-1239.2013.20131180.
YU K,JIA L,CHEN Y Q,et al.Deep learning: Yesterday,Today and Tomorrow [J].Journal of Computer Research and Development,2013,50(9):1799-1804.DOI:10.7544/issn1000-1239.2013.20131180.)
[10] LECUN Y,BOTTOU L,BENGIO Y,et al.Gradient-based learning applied to document recognition [J].Proceedings of the IEEE,1998,86(11):2278-2324.DOI: 10.1109/5.726791.
[11] KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNet classification with deep convolutional neural networks [Z].International Conference on Neural Information Processing Systems,Lake Tahoe,Nevada,USA,2012.DOI: :10.1145/3065386.
[12] MAAS A L,HANNUN A Y,NG A Y.Rectifier nonlinearities improve neural network acoustic models [Z]The 30 th International Conference on Machine Learning,Atlanta,Georgia,USA,2013.
[13] HE K M,ZHANG X Y,REN S Q,et al.Delving deep into rectifiers: surpassing human-level performance on imagenet classification [Z]IEEE International Conference on Computer Vision (ICCV) ,Santiago,Chile,2015.DOI:10.1109/ICCV.2015.123.
[14] LI J C,NG W W Y,YEUNG D S,et al.Bi-firing deep neural networks[J].International Journal of Machine Learning & Cybernetics,2014,5(1):73-83.DOI:10.1007/s13042-013-0198-9.
[15] GOODFELLOW I,BENGIO Y,COURVILLE A.Deep Learning[M].Massachusetts:MIT Press,2016.
[16] YU D,WANG H,CHEN P,et al.Mixed pooling for convolutional neural networks [Z].The 9th international conference on rough sets and knowledge technology,Shanghai,China,2014.
[17] GULCEHRE C,CHO K,PASCANU R,et al.Learned-norm pooling for deep feedforward and recurrent neural networks[Z].European Conference on Machine Learning and Knowledge Discovery in Databases,Nancy,France,2014.DOI:10.1007/978-3-662-44848-9_34.
[18] ESTRACH J B,SZLAM A,LECUN Y.Signal recovery from Pooling Representations [Z].The 31st International Conference on Machine Learning,Beijing,China,2014.
[19] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,37(9):1904-16.DOI: 10.1109/TPAMI.2015.2389824.
[20] XIE L,TIAN Q,WANG M,et al.Spatial pooling of heterogeneous features for image classification[J].IEEE Transactions on Image Processing,2014,23(5):1994-2008. DOI: 10.1109/TIP.2014.2310117.
[21] LEE H,KIM G,KIM H G,et al.Deep CNNs along the time axis with intermap pooling for robustness to spectral variations[J].IEEE Signal Processing Letters,2016,23(10):1310-1314.DOI: 10.1109/LSP.2016.2589962.
[22] PERLAZA S M,FAWAZ N,LASAULCE S,et al.From spectrum pooling to space pooling: opportunistic interference alignment in MIMO cognitive networks[J].IEEE Transactions on Signal Processing,2010,58(7):3728-3741.DOI: 10.1109/TSP.2010.2046084.
[23] WU HBB,GU X D.Towards dropout training for convolutional neural networks[J].Neural Networks,2015,71:1-10.DOI:10.1016/j.neunet.2015.07.007.
[24] WANG J Z,WANG W M,WANG R G,et al.CSPS: An adaptive pooling method for image classification[J].IEEE Transactions on Multimedia,2016,18(6):1000-1010.DOI: 10.1109/TMM.2016.2544099.
[25] SUN M L,SONG Z J,JIANG X H,et al.Learning pooling for convolutional neural network[J].Neurocomputing,2017,224:96-104.DOI:10.1016/j.neucom.2016.10.049.
[26] 黄文坚,唐源.TensorFlow实战[M].北京: 电子工业出版社,2017.
[27] 乐毅,王斌.深度学习-Caffe之经典模型详解与实战[M].北京: 电子工业出版社,2017.
[28] LIN M,CHEN Q,YAN .Network in network [J/OL].[2014-03-04].https://arxiv.org/abs/1312.4400v3.
[29] SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large-scale Image recognition [J/OL].[2014-09-15].http://arxiv.org/abs/1409.1556v2.
[30] SZEGEDY C,LIU W,JIA Y,et al.Going deeper with convolutions[Z].IEEE Conference on Computer Vision and Pattern Recognition (CVPR2015),Boston,MA,USA,2015.DOI:10.1109/CVPR.2015.7298594.
[31] IOFFE S,SZEGEDY C.Batch normalization: accelerating deep network training by reducing internal covariate shift[J/OL].[2015-03-02].https://arxiv.org/abs/1502.03167v3.
[32] SZEGEDY C,VANHOUCKE V,IOFFE S,et al.Rethinking the inception architecture for computer vision[Z].IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016),Las Vegas,NV,United States,2016.DOI:10.1109/CVPR.2016.308.
[33] SZEGEDY C,IOFFE S,VANHOUCKE V,et al.Inception-v4,inception-ResNet and the impact of residual connections on learning [J/OL].[2016-08-23].https://arxiv.org/abs/1602.07261.
[34] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[Z].IEEE Conference on Computer Vision and Pattern Recognition(CVPR2016),Las Vegas,NV,United States,2016.DOI: 10.1109/CVPR.2016.90.
[35] ZEILER M D,FERGUS R.Visualizing and Understanding Convolutional Networks[C]//Computer Vision-ECCV 2014,Lecture Notes in Computer Science,2014,8689:818-833.DOI:10.1007/978-3-319-10590-1_53.
[36] IANDOLA F,MOSKEWICZ M,KARAYEV S,et al.DenseNet: implementing efficient ConvNet descriptor pyramids [J/OL].[2014-04-07]. https://arxiv.org/abs/1404.1869.
[37] IANDOLA F N,HAN S,MOSKEWICZ M W,et al.SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size[J/OL].[2016-09-04].https://arxiv.org/abs/1602.07360v4.
[38] CHOPRA S,HADSELL R,LECUN Y.Learning a similarity metric discriminatively,with application to face verification[Z].IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2005),San Diego,California,2005.DOI:10.1109/CVPR.2005.202.
[39] HADSELL R,CHOPRA S,LECUN Y.Dimensionality reduction by learning an invariant mapping[Z].IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006),New York,2006.DOI: 10.1109/CVPR.2016.435.
[40] KINGMA D P,WELLING M.Auto-encoding variational Bayes [J/OL].[2014-05-01].https://arxiv.org/abs/1312.6114.
[41] HAYKIN S.神经网络与机器学习(影印版)[M].北京:机械工业出版社,2009.
[42] BOTTOU L.Large-scale machine learning with stochastic gradient descent [Z].19th International Conference on Computational Statistics,Paris France,2010.DOI:10.1007/978-3-7908-2604-3_16.DOI:10.1016/j.neucom.2016.11.046.
[43] LI S J,DOU Y,NIU X,et al.A fast and memory saved GPU acceleration algorithm of convolutional neural networks for target detection[J].Neurocomputing,2017,230:48-59.
[44] MATHIEU M,HENAFF M,LECUN Y.Fast training of convolutional networks through PPTs [J/OL].[2014-03-06].https://arxiv.org/abs/arXiv:1312.5851v5.
[45] RAJESWAR M S,SANKAR A R,BALASUBRAMANIAM V N,et al.Scaling up the training of deep CNNs for human action recognition [Z].IEEE International Parallel and Distributed Processing Symposium Workshop (IPDPSW2015),Hyderabad,INDIA,2015.DOI: 10.1109/IPDPSW.2015.93.
[46] ZLATESKI A,LEE K,SEUNG H S.ZNN-A fast and scalable algorithm for training 3D convolutional networks on multi-core and many-core shared memory machines [Z].IEEE International Parallel and Distributed Processing Symposium (IPDPS2016),Chicago,IL,USA,2016.DOI:10.1109/IPDPS.2016.119.
[47] MORCEL R,EZZEDDINE M,AKKARY H.FPGA-based accelerator for deep convolutional neural networks for the SPARK environment [Z].IEEE International Conference on Smart Cloud (SMART-CLOUD2016),New York,USA,2016.DOI:10.1109/SmartCloud.2016.31.
[48] GIRSHICK R.Fast R-CNN [Z].2015 IEEE International Conference on Computer Vision(ICCV),Santiago, Chile,2015.
[49] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN: towards real-time object detection with region proposal networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,online first,DOI: 10.1109/TPAMI.2016.2577031.
[51] CONG J S,XIAO B J.Minimizing computation in convolutional neural networks [Z].The 24th International Conference on Artificial Neural Networks,Hamburg,Germany,2014.DOI:10.1007/978-3-319-11179-7_36.
[52] LAVIN A,GRAY S.Fast algorithms for convolutional neural networks [Z].2016 IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,Nevada,USA,2016.DOI: 10.1109/CVPR.2016.435.
[53] ZHANG X Y,ZOU J H,HE K M,et al.Accelerating very deep convolutional networks for classification and detection[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2016,38(10):1943-1955.DOI:10.1109/TPAMI.2015.2502579.
[54] KORYTKOWSKI M,STASZEWSKI P,WOLDAN P.Fast computing framework for convolutional neural networks [Z]. 2016 IEEE International Conferences on Big Data and Cloud Computing (BDCloud),Social Computing and Networking (SocialCom),Sustainable Computing and Communications (SustainCom),Atlanta,GA,USA,2016.DOI:10.1109/BDCloud-SocialCom-SustainCom.2016.28.
[55] ZHENG S,VISHNU A,DING C.Accelerating Deep Learning with Shrinkage and Recall [J/OL].[2016-09-19].http://arxiv.org/abs/1605.01369v2.
[56] KIM J,KIM J,JANG G J,et al.Fast learning method for convolutional neural networks using extreme learning machine and its application to lane detection[J].Neural Networks,2017,87:109-121.DOI: 10.1016/j.neunet.2016.12.002.
[57] GRINSVEN M J J P V,GINNEKEN B V,HOYNG C B,et al.Fast convolutional neural network training using selective data sampling: Application to hemorrhage detection in color fundus images[J].IEEE Transactions on Medical Imaging,2016,35(5):1273-1284.DOI: 10.1109/TMI.2016.2526689.
[58] DENG J,DONG W,SOCHER R,et al.ImageNet: A large-scale hierarchical image database [Z].IEEE Conference on Computer Vision and Pattern Recognition,2009(CVPR 2009),Miami,FL,USA,2009.DOI: 10.1109/CVPR.2009.5206848.
[59] HAN S,MAO H,DALLY W J.Deep compression: compressing deep neural networks with pruning,trained quantization and huffman coding[Z].International Conference on Learning Representations 2016 (ICLR 2016),San Juan,Puerto Ri 2016.DOI: 10.1109/TIP.2015.2510583.
[60] LI H,LI Y,PORIKLI F.DeepTrack: learning discriminative feature representations online for robust visual tracking[J].IEEE Transactions on Image Processing,2016,25(4):1834-1848.DOI: 10.1109/TIP.2015.2510583.
[61] FAN J L,XU W,WU Y,et al.Human tracking using convolutional neural networks[J].IEEE Transactions on Neural Networks,2010,21(10):1610-1623.DOI: 10.1109/TNN.2010.2066286.
[62] MA C,XU Y,NI B B,et al.When correlation filters meet convolutional neural networks for visual tracking[J].IEEE Signal Processing Letters,2016,23(10):1454-1458.DOI: 10.1109/LSP.2016.2601691.
[63] GIRSHICK R,DONAHUE J,DARRELL T,et al.Region-based convolutional networks for accurate object detection and segmentation[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2016,38(1):142-158.DOI: 10.1109/TPAMI.2015.2439281.
[64] GIRSHICK R.Fast R-CNN [Z].2015 IEEE International Conference on Computer Vision (ICCV2015),Santiago,Chile,2015.DOI: 10.1109/ICCV.2015.169.
[65] ZHANG X Y,ZOU J H,HE K M,et al.Accelerating very deep convolutional networks for classification and detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(10):1943-1955.DOI: 10.1109/TPAMI.2015.2439281.
[66] TOME D,MONTI F,BAROFFIO L,et al.Deep convolutional neural networks for pedestrian detection[J].Signal Processing: Image Communication,2016,47:482-489.DOI:10.1016/j.image.2016.05.007.
[67] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once: unified,real-time object detection[Z].2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Las Vegas,NV,United States,2016.DOI:10.1109/CVPR.2016.91.
[68] LIU W,ANGUELOV D,ERHAN D,et al.SSD: single shot multiBox detector[Z].European Conference on Computer Vision (ECCV 2016),Amsterdam,The Netherlands,2016.DOI: 10.1007/978-3-319-46448-0_2.
[69] SAINATH T N,KINGSBURY B,SAON G,et al.Deep convolutional neural networks for large-scale speech tasks[J].Neural Networks,2015,64:39-48.DOI:10.1016/j.neunet.2014.08.005.
[70] QIAN Y M,BI M X,TAN T,et al.Very deep convolutional neural networks for noise robust speech recognition[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2016,24(2):2263-2276.DOI: 10.1109/TASLP.2016.2602884.
[71] DONG C,LOY C C,HE K M,et al.Image super-resolution using deep convolutional networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(2):295-307.DOI: 10.1109/TPAMI.2015.2439281.
Convolutionalneuralnetworkanditsresearchadvances
ZHAIJunhai1,ZHANGSufang2,HAOPu1
(1.Key Laboratory of Machine Learning and Computational Intelligence,College of Mathematics and Information Science,Hebei University,Baoding 071002,China;2.Hebei Branch of Meteorological Cadres Training Institute,China Meteorological Administration,Baoding 071002,China)
Deep learning is the most popular research topic in the field of machine learning,AlphaGo which overwhelmingly impacts the world is trained with deep learning algorithms.Convolution neural network (CNN) is a model trained with deep learning algorithm,CNN is widely and successfully applied in computer version.The main purpose of this paper includes two aspects:one is to provide readers with some insights into CNN including its architecture,related concepts,operations and its training; the other is to present a comprehensive survey on research advances of CNN,mainly focusing on 4 aspects: activation functions,pooling,training and applications of CNN.Furthermore,the emerging challenges and hot research topics of CNN are also discussed.This paper can be very helpful to researchers in related field.
machine learning; deep learning; convolutional neural network; computer version; training algorithms
10.3969/j.issn.1000-1565.2017.06.012
2017-09-09
国家自然科学基金资助项目(71371063);河北省自然科学基金资助项目(F2017201026);河北大学自然科学研究计划项目(799207217071)
翟俊海(1964—),男,河北易县人,河北大学教授,博士,主要从事机器学习和数据挖掘方向研究.
E-mail:mczjh@126.com
张素芳(1966—),女,河北蠡县人,中国气象局气象干部培训学院河北分院副教授,主要从事机器学习方向研究.
E-mail:mczsf@126.com
TP181
A
1000-1565(2017)06-0640-12
孟素兰)
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
