
基于隐语义模型的个性化推荐
2018-01-03 01:58:30范慧婷钟春琳龚海华
计算机应用与软件 2017年12期
范慧婷 钟春琳 龚海华
(中国科学技术大学计算机科学与技术学院 安徽 合肥 230027)
基于隐语义模型的个性化推荐
范慧婷 钟春琳 龚海华
(中国科学技术大学计算机科学与技术学院 安徽 合肥 230027)
许多传统的推荐方法如协同过滤和低秩矩阵分解都存在物品或用户方面的稀疏性和冷启动问题。为了克服这两方面的问题,提出一种基于隐语义模型的个性化推荐方法。通过对用户行为进行分析,利用隐语义模型推断出用户潜在的兴趣因子,从而构建用户兴趣特征矩阵来进行个性化推荐。对现实的电影数据的实验证明了所提方法的有效性,并在准确率、召回率和覆盖率方面均优于传统的协同过滤方法和基于内容的方法。
隐语义模型 稀疏性 冷启动 个性化推荐
0 引 言
随着互联网的快速发展,海量的信息呈现在用户面前,比如各类新闻、电影、音乐、电子商务提供的商品等。这些信息种类繁杂,质量和价值参差不齐,用户(信息消费者)需要花费大量的时间从中获得自己想要的信息,造成信息过载。这时就需要有技术或工具能够帮用户过滤掉不感兴趣或者与所想要的信息不相关的信息。相对于经典过滤工具如门户网站(方案是分类目录)和搜索引擎这类“被动”地让用户获取信息的方式,推荐系统考虑了用户的个性化需求,是一种向用户推荐可能感兴趣的信息的智能化工具,能够有效地解决信息过载问题[1]。
为了提供个性化推荐,系统需要收集用户的各种数据。例如为了给用户推荐电影,系统需要收集用户的历史观影记录。推荐系统通过挖掘用户的历史行为,为用户兴趣建模来找到用户对物品的偏好,从而主动地向用户推荐他们可能感兴趣的但之前没有过行为的物品。
1 相关工作
目前现存的大部分个性化推荐方法可以分为基于内容的推荐、协同过滤以及混合方法[2-4]。下面将分别介绍这几种方法及其优缺点。
1.1 基于内容的推荐
基于内容的推荐方法为用户推荐与过去所喜欢物品类似的物品[5]。例如我们知道某个用户喜欢浏览金融类的新闻和哪些新闻是金融类的,则系统可能会推荐《保护主义或再次引发债务危机》这样一篇新闻。该方法的前提是需要用户历史记录(包括用户已知的偏好、兴趣等属性信息)以及物品相关的特征信息,即需要丰富的领域知识。同时也设定用户曾经喜欢的物品的特征能够反映用户的偏好[6]。然后计算用户与待推荐物品的相似度,最后为用户推荐相似度高的物品。相似度的计算是该方法的关键部分,需要把用户和物品映射到相同的特征空间。假设数据集中有I={Item1,Item2,…,Itemn}和m个用户U={User1,User2,…,Userm},为了描述每个用户和物品的属性(内容),把它们都表示为一个特征集合,即我们需要得到Itemi={wi1,wi2,…,wik},其中wik(1≤i≤n,k≤n)是物品i第k个特征的权重,以及Useri={wi1,wi2,…,wik},同理,wik(1≤i≤m,k≤m)是用户i第k个特征的权重。
权重的众多计算方法中,常用的是TF-IDF[7]。这个计算方法是一种基于文本的统计方法,在自然语言处理领域中应用十分广泛,可以用来提取关键词。词频(TF)是指一个词在指定文件中出现的次数,逆文档频率(IDF)度量一个词的重要性(权重)。如果按照词频来提取一篇文档的特征,或者能表示这篇文档的关键词会有一个很大的问题,因为停顿词,如“的”、“是”、“在”,出现次数很多但却不能表征一篇文档,所以我们要给不同的词添加不同权重。比如停顿词应该给一个很小的权重,而那些在其他文档中很少出现的且本文档中出现次数多的词应该给一个较大的权重。TF-IDF的函数为:
TF-IDF(ti,dj)=TF(ti,dj)×IDFi
(1)
式中:
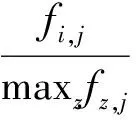
(2)
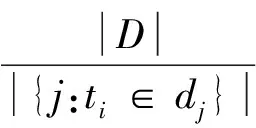
(3)
式(2)中maxzfz,j是在文档dj中所有词tz的出现次数fz,j上计算得到的最大值,式(3)中|D|是语料库中文档总数,|{j:ti∈dj}|是包含词ti的文档集合的数量。如果词ti不在语料库中,则除数会为零,所以一般情况下分母使用|{j:ti∈dj}|+1。
为了使权重落在[0,1]区间且用户或物品能够用相同数量的特征来表示,需要将式(1)归一化:
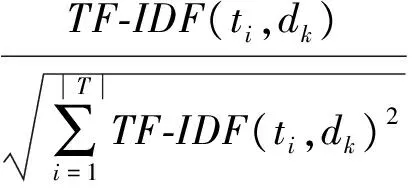
(4)
现在我们需要得到基于内容的推荐中用户特征和待推荐物品特征的相似度。计算相似度的方法有很多,广泛应用的是利用余弦相似度。所以Useri与Itemj的相似度为:
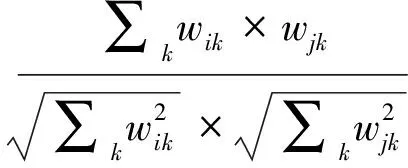
(5)
1.2 基于协同过滤的推荐
基于协同过滤的推荐根据用户对物品的评分或者其他行为(如点击、购买)来进行推荐,不同于基于内容的推荐,该方法不需要得到用户或物品的大量信息。例如学生Bob喜欢书籍A、书籍D,学生John喜欢书籍B、书籍C,学生Alice喜欢书籍A、书籍B、书籍D,从这些信息中我们发现学生Bob和学生Alice的对书籍的偏好比较类似,所以系统会把Alice喜欢的而Bob没有看过的书籍B推荐给Bob。基于协同过滤的推荐又分为基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。
1.2.1 基于用户的协同推荐
该方法首先挖掘与目标用户兴趣、偏好相似的用户群体,然后根据这个群体中用户的历史兴趣偏好为目标用户推荐未曾有过行为的物品。
首先需要计算两个用户间的兴趣/偏好相似度,找到与目标用户兴趣相似的用户群体。为了得到用户兴趣/偏好的相似度,主要利用用户行为的相似度。假设有用户u和用户v,N(u)、N(v)分别表示用户u、v历史行为中有过正反馈的物品集。正反馈是指明确表现了用户对物品喜好的行为中用户喜欢某物品的行为,比如用户在观影网站中对某部电影评分5分(最高分)的行为为正反馈。计算用户u、v的兴趣/偏好相似度可以通过Jaccard公式:

(6)
或者通过余弦相似度:
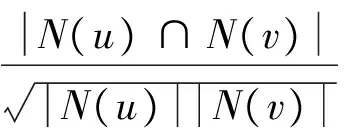
(7)
得到用户之间的兴趣/偏好相似度后,基于用户的协同过滤算法得到与目标用户兴趣最相似的K个用户,然后为目标用户推荐这K个用户喜欢的而目标用户以前没有行为的物品。用户u对物品i的感兴趣程度可以用以下公式计算:
(8)
式中:
1)S(u,K)为与用户u兴趣最相似的K个用户集合;
2)N(i)表示对物品i有过行为的用户集合;
3)wuv是用户u和用户v的兴趣相似度;
4)rvi表示用户v对物品i的兴趣,比如用户对电影的评分数据。
1.2.2 基于物品的协同过滤算法
该协同过滤算法给用户推荐的物品和他们之前喜欢的物品是相似的[8-9]。基于内容推荐算法根据物品的内容属性来计算物品间的相似度,而基于物品的协同过滤算法是根据用户的历史行为来计算物品间的相似度,比如物品i和物品j相似度高是由于喜欢物品i的用户基本也喜欢物品j。物品i和物品j的相似度计算公式为:
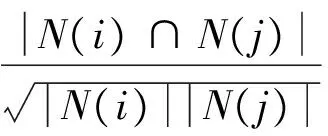
(9)
式中:N(i)、N(j)分别是喜欢物品i、j的用户数,|N(i)∩N(j)|为既喜欢物品i又喜欢物品j的用户数。
最相似的K个物品,并通过下面的公式计算用户u对物品i的兴趣:
(10)
式中:
1)S(i,K)为与物品i最相似的K个物品集合;
2)N(u)是用户u喜欢的物品集合;
3)wij是物品i和物品j的相似度;
传统的钻井施工经验及模式在施工中根深蒂固,抓住“三个一”精准化钻井施工模式这一关键,推动“五个转变”,实现钻井工作的高端化。
4)rui表示用户u对物品i的兴趣。
1.2.3 基于隐语义模型的协同过滤算法
前两种协同过滤算法属于基于领域的模型,因为它们主要关注用户之间或物品之间的相似性。而隐语义模型把用户和物品映射到相同的隐语义空间,通过隐含特征把用户的兴趣和物品进行关联[10],这些隐含的特征可以解释用户的喜好(评分)。比如在对用户Alice进行电影推荐时,我们可以首先对他的兴趣分类,然后从分类中推荐符合他喜好的物品。假设有用户-物品评分矩阵Cm×n(m个用户,n个物品),通过不断对训练数据进行迭代学习,可以把Cm×n分解成用户特征矩阵P(P∈Rm×f,f是指特征数)和物品特征矩阵X(X∈Rn×f),如公式所示:
Cm×n=P×XT
(11)
在这里,通过下面的式(12)计算用户u对物品i的兴趣:
(12)
式中:pu、xi分别是P、X中的行向量。
1.3 基于混合的推荐
上述的各种推荐算法都有其一定的局限性,比如基于内容的推荐,其推荐结果只是那些与用户曾经有过行为的物品相似度高的物品,缺乏新颖性。基于用户的协同过滤推荐在网站的用户越来越多时,维护用户相似度矩阵代价很大。基于物品的协同过滤推荐,当物品列表更新很快时会很不稳定。如果能够将几种算法组合在一种推荐算法里,充分利用各种算法的优点,使推荐结果令用户更加满意的话,混合推荐就应运而生了。Burke[11]提出了七种不同的混合策略:加权、交叉、切换、串联、分层、特征组合和特征补充。目前,基于协同过滤和基于内容的推荐方法的混合推荐是最常见的[12-17]。文献[5]中提出了两种主要的混合思路:推荐结果混合和推荐算法混合。前者是将两种或者多种推荐方法的推荐结果混合得到最终的推荐结果[13,17],后者是以某种推荐方法为基准,混合其他的推荐方法[18-19]。
2 使用隐语义模型为用户兴趣建模
前面已经简单介绍了隐语义模型,用其来进行协同过滤的主要目标是揭示用户隐藏的特征,当为用户兴趣建模时能够得到更加全面的兴趣特征。上文中提到的方法都存在项目或者用户的数据稀疏性和冷启动问题,本文将通过充分利用用户行为隐性反馈和隐语义模型来解决这两个问题。
用户的行为分为两种:显示反馈和隐式反馈。显示反馈主要是用户的评分行为,能明显地反映用户的兴趣/偏好,比如对电影评分5分代表喜欢,1分代表不喜欢。而隐式反馈主要是用户行为日志,比如浏览新闻日志、听歌日志,这些行为能隐含地表达用户的兴趣/偏好。在隐式反馈数据集中,又可以分为正反馈和负反馈。正反馈指用户的行为表明他喜欢某种物品,负反馈指用户的行为表明他对某种物品不感兴趣。比如,浏览新闻时用户点击一条新闻或者再其上细想超过一个阈值时间能够表明该用户确定的偏好,而没有点击或者花极少的时间在一条新闻上则可以解释为负反馈。如果用户在某个物品集上反馈信息,我们就能尝试为该用户的兴趣建模。很多时候,数据集中用户的负反馈信息很少,我们需要为其生成负反馈。
如何给每个用户生成负反馈信息,文献[20]中提出了以下几种方法:
1) 把某用户没有过行为的物品作为负反馈;
2) 在某用户没有过行为的物品中均匀采样得到一些物品作为负反馈;
3) 在第二种方法中保证采样时该用户的正负反馈信息数相当;
4) 在第二种方法中保证偏重对不热门的物品进行采样。
这几种方法中,第一种方法副本太多,计算难度大且精度很差。文献[20]中的作者比较了后三种方法,发现第三种方法好于第二种,第二种好于第四种。所以我们采用的方法是在保证正负反馈信息量相当的同时,选取那些用户没有行为却很热门的物品。
2.2 利用隐语义模型为用户兴趣建模
为了解决数据稀疏性问题,我们在为每个用户的兴趣建模时使用所有用户的数据。我们方法的核心思想是为所有用户建立一个隐因子空间,在这个空间里即使是从所有可用的数据中学习得到用户的兴趣模型,但是仍能保证每个用户的兴趣有自己的特征,是可区分的。
首先,我们把每个用户的兴趣特征矩阵Pm×f分为两个部分:
2) 一个从物品特征到潜在因子的映射S∈Rk×f,由所有用户共享。
所以用户的兴趣特征矩阵P构建为P=US。接下来就把问题转化为如何学习得到U和S。这里我们用U、S和X来近似用户-物品交互矩阵C,即:
C≈USXT
(13)
通过优化如下AUC损失函数我们可以学习到U和S。
λu‖U‖2+λs‖S‖2
(14)
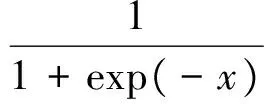
(15)
(16)
(17)
根据随机梯度下降法,通过式(15)、式(16)我们求得了U和S的偏导数,也即梯度,现在需要找到合适的样本。我们采用了自助抽样法来随机得到正-负反馈样本对,再利用下面两个公式不断交替更新U和S直到收敛:
(18)
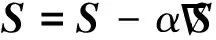
(19)
式中:α是迭代步长或学习速率,其取值需要不断地实验得到。因为α太大容易导致结果在最优值附近震荡,而太小收敛的速度太慢。
因子特征矩阵S是解决稀疏性和冷启动问题的关键。那些只有有限交互数据的用户能够通过S从其他用户的交互数据中获益,因为S是对所有用户共享的,而且在迭代中每个用户的实例都会用来更新S一次。所以,即使一个用户在与物品交互后只获得了他很少的特征,我们仍然能够用S推断得到较广范围的特征。
3 实 验
我们进行了实验来验证我们所提方法在为用户兴趣建模方面的性能,并评估了我们的方法在用户推荐结果上的指标。
实验所使用的数据是MoiveLens 10M数据集,其中有71 567 用户的10 000 054条评分数据和10 681部电影的95 580条标签。
首先建立用户-电影矩阵,然后用所有用户与90%电影的交互矩阵作为训练集,剩下的10%作为测试数据集。实验中,我们的隐因子个数设为10,学习速率α为0.02,λu和λs均为0.01,之后我们进行了本文所提出算法与基于内容的推荐和基于物品的协同过滤推荐在准确率、召回率和覆盖率三个指标上的比较。这三个评价指标的计算公式如下:
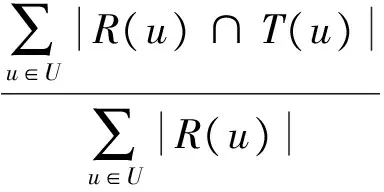
(20)
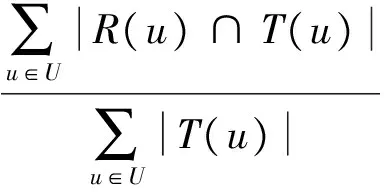
(21)

(22)
式中:R(u)是为用户u推荐的列表,T(u)是用户u的观看列表。
通过实验,我们得到表1、表2所示的结果。

表1 不同推荐算法的TOP5推荐结果

表2 不同推荐算法的TOP10推荐结果
通过实验结果可以发现,我们提出的基于隐语义模型的推荐算法在这三个指标上都优于传统的基于内容的推荐和基于物品的协同过滤推荐。
4 结 语
我们提出了基于隐语义模型的推荐算法为用户兴趣建模,然后根据用户兴趣进行推荐物品。隐语义模型是推荐精度最高的单一模型,利用这一优势,我们在电影推荐中使用了这一模型,并且通过实验验证了这一方法的优越性。
今后的研究需要解决在使用隐语义模型进行推荐时,如何解决当数据规模大时,其计算效率的提高。
[1] Resnick P,Varian H R.Recommender systems[J].Communications of the ACM,1997,40(3):56-58.
[2] 许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[3] 刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[4] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):70-80.
[5] Lops Pasquale,De Gemmis M,Semeraro G.Content-based recommender systems:State of the art and trends[M].Recommender Systems Handbook.Springer US,2011:73-105.
[6] Jiang Peng,Zhu Yadong,Zhang Yi,et al.Life-stage Prediction for product recommendation in E-commerce[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’15).ACM,2015:1879-1888.
[7] Salton Gerar.Automatic Text Processing:the Transformation,Analysis and Retrieval of Information by Computer[M].Boston:Addison-Wesley Longman Publishing Co.,Inc.,1989.
[8] Deshpande Mukund,Karypis George.Item-based top-N recommendation algorithms[J].ACM Transactions on Information Systems (TOIS),2004,22(1):143-177.
[9] Linden Greg,Smith Brent,York Jeremy.Amazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[10] 项亮.推荐系统实战[M].北京:人民邮电出版社,2012.
[11] Burke Robin.Hybrid recommender systems:survey and experiments[J].User Modeling and User-adapted Interaction,2002,12(4):331-370.
[12] Balabanovic M,Shoham Y.Fab:Content-based collaborative recommendation[J].Communications of the ACM,1997,40(3):66-72.
[13] Claypool M,Gokhale A,Miranda T,et al.Combining content-based and collaborative filters in an online newspaper[C]//Proc of the ACM SIGIR’99 Workshop Recommender Systems:Algorithms and Evaluation.New York:ACM Press,1999.
[14] Yu Xiao,Ren Xiang,Sun Yizhou,et al.Personalized entity recommendation:a heterogeneous information network approach[C]//Proceedings of the 7th ACM international conference on Web search and data mining (WSDM’14).ACM,2014:283-292.
[15] Vahedian Fatemeh.Weighted hybrid recommendation for heterogeneous networks[C]//Proceedings of the 8th ACM Conference on Recommender systems (RecSys’14).ACM,2014:429-432.
[16] Schwab I,Kobsa A,Koychev I.Learning user interests through positive examples using content analysis and collaborative filtering[J].Internal Memo,GMD,St.Augustin,Germany,2001.
[17] Tran Thomas,Cohen Robin.Hybrid recommender systems for electronic commerce[C]//Proc Knowledge-Base Electronic Markets,papers from the AAAI Workshop.Menlo Park:AAAI Press,2000:78-83.
[18] Zhang Y C,Blattner M,Yu Y K.Heat conduction process on community networks as a recommendation model[J].Physical review letters,2007,99(15):154301.
[19] Zhou T,Su R Q,Liu R R,et al.Accurate and diverse recommendations via elimination redundant correlations[J].New Journal of Physics,2009,11.
[20] Pan Rong,Zhou Yunhong,Cao Bin,et al.One-class collaborative filtering[C]//The Eighth IEEE International Conference on Data Mining(ICDM),2008.
LATENTFACTORMODELBASEDPERSONALIZEDRECOMMENDATION
Fan Huiting Zhong Chunlin Gong Haihua
(SchoolofComputerScienceandTechnology,UniversityofScienceandTechnologyofChina,Hefei230027,Anhui,China)
Many traditional recommendation methods, such as collaborative filtering or low rank matrix factorization, have data sparsity and cold-start problems on items or users. In order to overcome these two problems, this paper proposes a personalized recommendation method based on the latent factor model. By analyzing behaviors of users, we utilize latent factor model to infer user interest feature vector so as to make a personalized recommendation. Our two kinds of experiments on realistic movie data demonstrate the efficacy of the proposed method, as well as the superiority compared to traditional collaborative filtering methods and content-based methods.
Latent factor model Data sparsity Cold-start Personalized recommendation
2017-04-05。范慧婷,硕士生,主研领域:推荐系统,隐私保护。钟春琳,硕士生。龚海华,硕士生。
TP391
A
10.3969/j.issn.1000-386x.2017.12.039
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
四川大学学报(自然科学版)(2021年1期)2021-01-26 07:39:14
开放教育研究(2020年2期)2020-03-31 01:54:14
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
电子制作(2019年23期)2019-02-23 13:21:36
现代语文(2016年21期)2016-05-25 13:13:44
河北软件职业技术学院学报(2015年3期)2016-01-01 07:29:50
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
大连民族大学学报(2015年2期)2015-02-27 08:28:11
