
一种结合直达声补偿策略的混响抑制算法
2017-12-29 06:15:33陈长海
网络安全与数据管理 2017年24期
陈长海
(福州瑞芯微电子股份有限公司,福建 福州 350003)
一种结合直达声补偿策略的混响抑制算法
陈长海
(福州瑞芯微电子股份有限公司,福建 福州350003)
混响是声音经过室内墙壁等物体反射、吸收后多径传播叠加产生的,是导致语音识别系统性能下降的主要因素之一。基于TF-GSC的混响消除算法在估计混响功率谱时可能会出现过估计的现象,导致输出语音失真。提出一种直达声补偿策略,并将其应用到混响抑制算法中去。实验结果表明,直达声补偿策略减小了输出语音失真,提高了输出语音质量。
混响;TF-GSC;直达声补偿;混响功率谱估计
0 引言
随着人工智能技术研究与应用的兴起,越来越多的产品可以实现人机交互,人们可以通过语音控制机器执行一些操作。例如智能电视,用户可以通过语音控制换台、音量的调整,甚至可以利用智能电视进行一些社交活动[1]。实时语音识别系统是实现人机交互的桥梁[2],随着人机交互应用场景的复杂化,对语音识别系统性能的要求也越来越高。
室内麦克风采集到的语音信号通常包含噪声和混响,使得语音信号的保真度和清晰度下降,从而导致实时语音识别系统性能的降低。其中,混响是声音经过室内墙壁等物体反射、吸收后,由多径传播产生的。麦克风接收到的语音信号在时序上可以分为三个部分:直达声、早期反射声、后期混响声。后期混响会掩盖弱语音部分,影响语音的清晰度[3-4]。为了提高语音识别系统的性能,必须抑制后期混响。现有的混响处理算法可以分为两大类:混响消除和混响抑制[5]。混响消除的思路是对房间声学系统求逆,因此需要对房间声学系统进行估计,计算量较大;混响抑制算法利用谱增强策略来抑制语音中的混响,避免了房间声学系统估计这一难题。
本文提出了一种直达声补偿策略,并将其应用到基于TF-GSC的混响消除算法中,从而改善算法的性能。
1 混响理论
房间混响信号是由声源信号s(n)和房间声学冲激响应函数h(n)卷积产生的。h(n)可分为三个部分:直达路径、前期反射和后期反射,如图1所示。
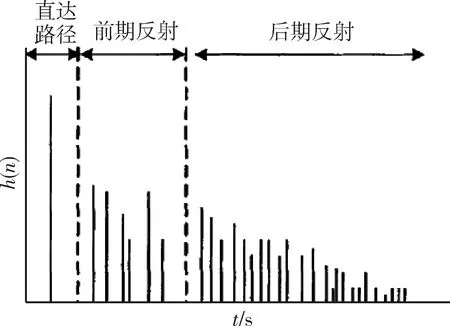
图1 房间冲激响应示意
混响时间为400 ms的某一房间的房间冲激响应如图2所示。
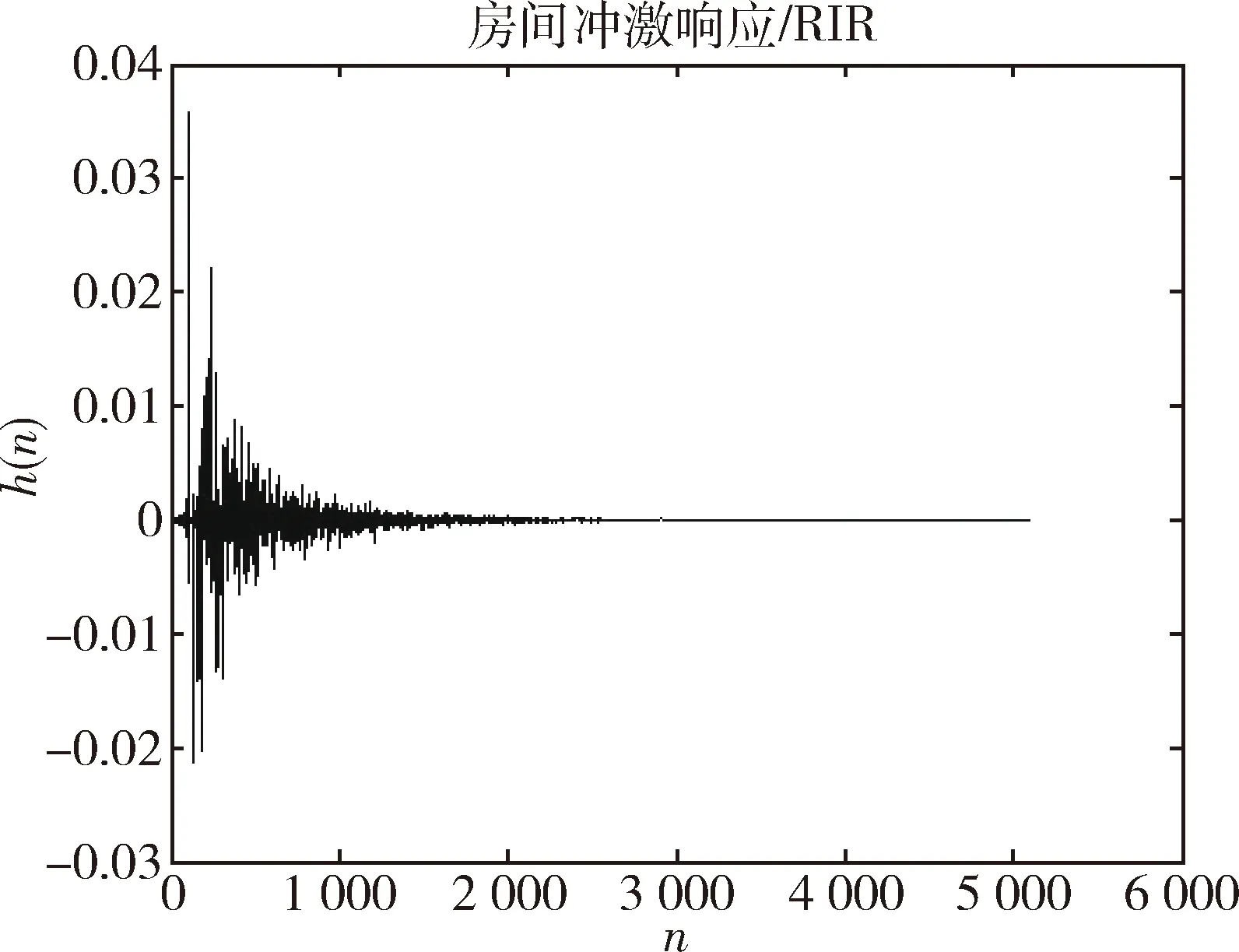
图2 混响时间为400 ms的房间冲激响应
对于第i路麦克风在某离散时间n时的混响信号可以表示为:
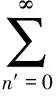
(1)
因此,第i路麦克风接收到的信号可以表示为:
xi(n)=zi(n)+vi(n)
(2)
其中vi(n)表示背景噪声。
对输入的阵列语音信号加窗分帧(每帧长度在30 ms以内)后,通过短时傅里叶变换[6]由时域变换到频域,式(2)的频域表示如下:
Xi(m,k)=Zi(m,k)+Vi(m,k)
=Di(m,k)+Ri(m,k)+Vi(m,k)
(3)
其中m表示帧索引,k表示频率索引,Di和Ri分别表示第i路麦克风输入信号中的直达声(包括直达声和早期反射,为了简化统称直达声)和后期混响声。混响消除算法的目的是尽可能地去除Ri(m,k)。
2 基于TF-GSC的混响消除算法
HABETS E[7]等人提出了一种基于TF-GSC的噪声和混响消除算法,算法的原理图如图3所示(以4麦克风为例)。
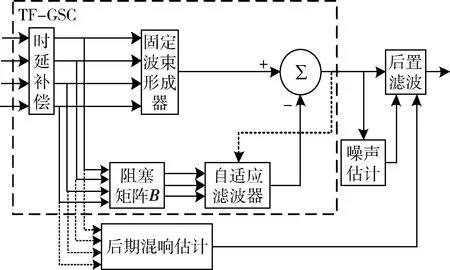
图3 基于TF-GSC的混响抑制算法框图
由图3可知,算法主要包含四个部分,分别是TF-GSC、噪声功率谱估计[8]、混响功率谱估计以及后置单通道滤波器。
2.1 基于传输函数的广义旁瓣抵消器
基于传输函数的广义旁瓣抵消器(TF-GSC)是广义旁瓣抵消器的改进形式,其结构理论上可以处理任何的声学传输函数,适合混响等复杂条件下阵列语音信号的处理[9]。其基本结构如图3虚线框中部分所示。它主要由非自适应部分和自适应部分组成,非自适应部分主要是一个固定波束形成器,自适应部分由一个阻塞矩阵和一个自适应滤波器组成。
对输入阵列信号进行时延补偿[10],使得各路输入信号中的期望信号时域同步,加窗分帧后通过短时傅里叶变换由时域转换到频域。传输函数比(Transfer Function Ratio)矢量如下:
(4)
其中Ai(k)表示声源到第i路麦克风的传输函数的频域形式。
固定波束形成器的系数矩阵为:
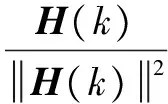
(5)
阻塞矩阵B相当于一个空域滤波器,目的是阻塞期望方向上的信号,留下非期望方向的干扰信号组合;TF-GSC的阻塞矩阵的频域形式如下:
(6)
其中*表示共轭。
实际环境中的Ai(k)是未知的,因此传输函数比也是未知的,需要对其进行估计,通常是利用信号之间互功率谱密度的来进行求解,如式(7)所示。
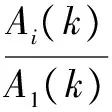
(7)
其中Φxix1表示第i路麦克风的输入与第1路麦克风的输入之间的互功率谱密度,〈 〉表示帧平均。
自适应滤波部分采用的是自适应LMS算法,自适应滤波器的系数矩阵G计算如下:
G(m+1,k)=G(m,k)+μU(m,k)Y*(m,k)
(8)
U(k,m)=B†(k)X(m,k)
(9)
其中μ表示LMS算法的步长,U(k,m)表示阻塞矩阵的输出,†表示共轭转置,*表示共轭,XT(m,k)表示输入:
XT(m,k)=[X1(m,k),X2(m,k),X2(m,k),X4(m,k)]
(10)
最终的输出:
Y(m,k)=W†(k)X(m,k)-G†(m,k)U(k,m)
(11)
2.2 问题分析
Habets算法估计后期混响采用的是Polack混响统计模型,这种随机模型对大部分的声学环境的模拟都是相当精准的。KUTTRUF H[11]认为只有当声源到麦克风的距离大于临界距离时,Polack混响统计模型才有效,这里的临界距离是指此距离上的直达声能量与前期和后期反射的能量相等。这也就意味着当直达声的能量小于前期和后期反射信号的能量时,Polack模型才有效。实际处理过程中,某些帧的语音信号可能不满足临界条件,导致后期混响功率谱出现过估计,造成输出信号的谱失真,如图4所示。

图4 Habets算法输入输出语谱图对比
3 本文提出的直达声补偿策略
利用Polack混响模型估计后期混响时可能会出现过估计的现象[7]。输入阵列语音包含直达声(包含早期反射)、后期混响以及外界噪声,假设噪声的估计准确,则剩下的直达声和后期混响的总功率谱密度是定值,后期混响的过估计会导致直达声的估计出现偏差,导致系统的输出结果出现失真现象。本文提出了一种直达声补偿策略,引入动态变量κi(m)利用下面的式子来估计混响声(包括直达声和后期混响,即输入信号去掉噪声后的剩余部分):
(12)
其中κi(m)表示第i路麦克风的第m帧的直达声补偿系数,这个系数与直达声和后期混响的能量有关。
(13)
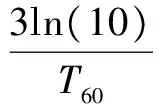
直达声补偿系数κi(m)的更新满足以下策略:

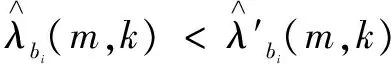
因此,κi(m)的值的更新可以根据下面的式子进行自动调整:

(14)
其中μk表示步长,且满足0<μk<1。
利用基于TF-GSC的混响抑制算法去除混响时,利用本文提出的直达声补偿策略估计混响功率谱,可以防止混响功率谱出现过估计。
4 实验结果
本次仿真实验采用间距为10 cm的线性麦克风阵列,麦克风数目为4,房间大小为4 m×5 m×3.5 m,声源到麦克风阵列的距离设置成3种情况:1.5 m、2 m和2.5 m,墙壁的吸声系数设置为[0.8,0.8,0.8,0.8,0.7,0.4]。纯净声源取自TIMIT标准语音库,采样频率为16 kHz,长度为3.5 s,语音信号的内容为:She had your dark suit in greasy wash water all year。利用Eric A. Lehmann编写的Image-source method 工具箱来获取仿真混响语音信号。
仿真房间冲激响应曲线图和纯净源语音的波形图以及语谱图如图5和图6所示。
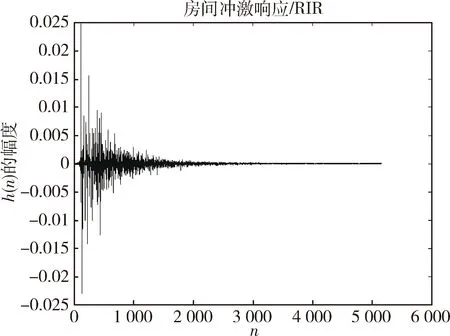
图5 仿真实验环境房间冲激响应
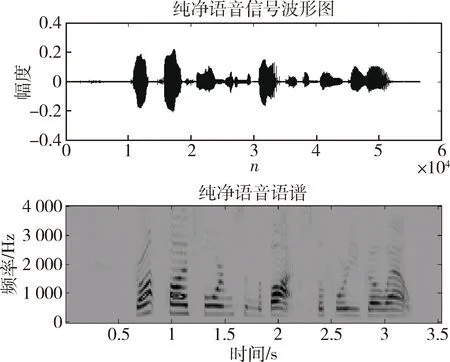
图6 纯净语音的波形图和语谱图
混响程度不同的几组仿真语音波形图和语谱图分别如图7和图8所示。
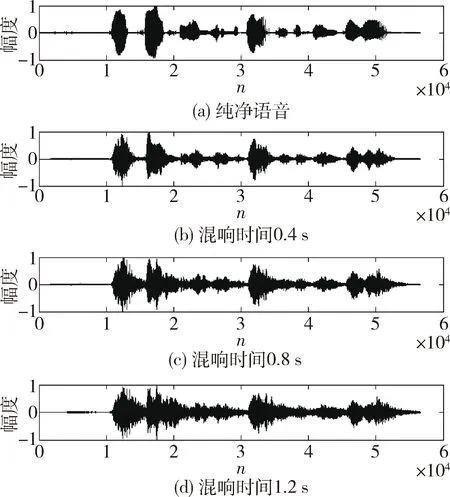
图7 混响时间分别为0.4 s、0.8 s以及1.2 s的混响语音信号与纯净语音信号波形对比
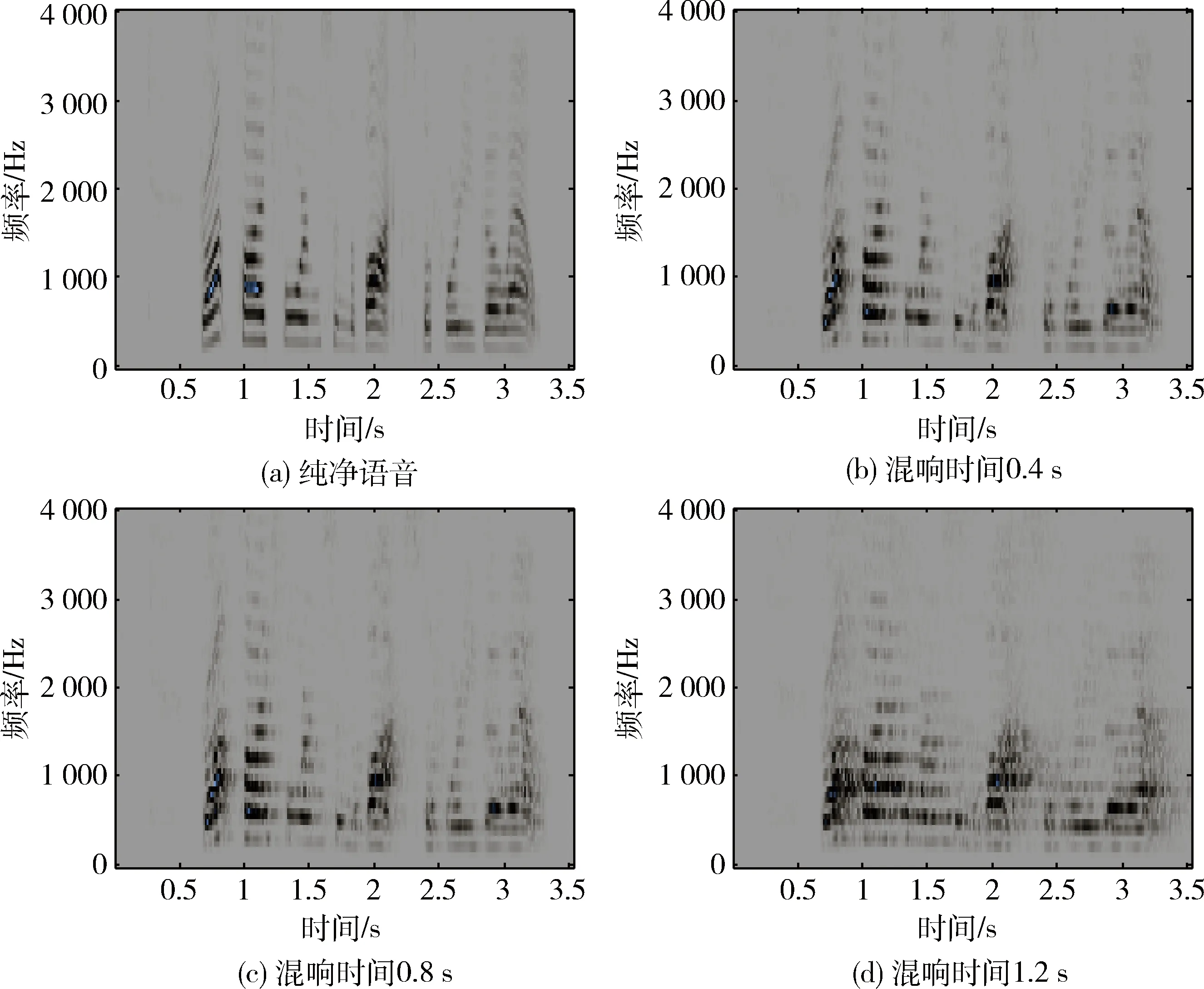
图8 混响时间分别为0.4 s、0.8 s以及1.2 s的混响语音信号与纯净语音信号语谱图对比
由图7和图8可以发现,混响会导致语音中声音的间隔变得模糊,导致语音的质量严重下降。
为了验证本文提出的直达声补偿策略的有效性,分别用没有结合直达声补偿策略的基于TF-GSC的混响消除算法和结合直达声补偿策略的基于TF-GSC的混响消除算法对混响语音进行处理,混响时间为0.4 s的混响语音经过两种算法处理后的波形图和语谱图如图9和10所示。
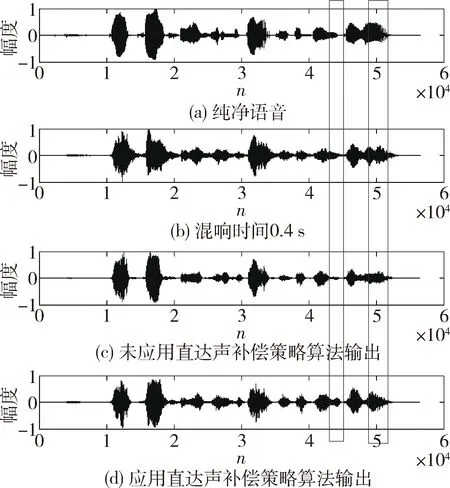
图9 直达声补偿策略应用前后波形图对比
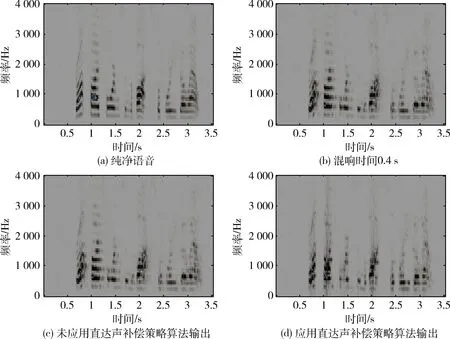
图10 直达声补偿策略应用前后语谱图对比
观察图9和图10可以发现,基于TF-GSC的混响抑制算法结合直达声补偿策略后,输出语音失真减小,图9虚线方框选中部分十分明显,由此可以证明本文提出的直达声补偿策略是有效的。
5 结论
传统的基于TF-GSC的混响抑制算法需要估计混响的功率谱,有时会出现过估计的现象。本文提出一种直达声补偿策略,并将其应用到混响抑制算法中去。经实验验证,本文提出的直达声补偿策略能够防止混响功率谱出现过估计,减小算法输出的失真。该策略适用于语音识别系统的前端处理模块,能够很好地对输入语音进行预处理。
[1] 袁洪,邓忠平. 智能电视发展趋势与挑战[J].网络新媒体技术,2012,1(1):4-9.
[2] 谢凌云. 实时语音识别系统的快速算法研究[D].北京:中国科学院声学研究所,2004.
[3] 栗晓丽,徐柏龄. 混响声场中语音识别方法研究[J]. 南京大学学报(自然科学),2003,39(4):525-531.
[4] OMOLOGO M,SVAIZER P,MATASSONI M. Environmental conditions and acoustic transduction in hands-free speech recognition[J]. Speech Communication,1998,25(1-3):75-95.
[5] MCAULAY R,MALPASS M. Speech enhancement using a soft-decision noise suppression filter[J]. IEEE Transactions on Acoustics Speech & Signal Processing,1980,28(2):137-145.
[7] HABETS E. Single and multi-microphone speech dereverberation using spectral enhancement[D]. Technische Universiteitndhoven,2007.
[6] 朱冰莲,杨磊. 心音信号的短时傅立叶变换分析[J]. 重庆大学学报(自然科学版),2004,27(8):83-85.
[8] COHEN I. Noise spectrum estimation in adverse environments: improved minima controlled recursive averaging[J]. IEEE Transactions on Speech & Audio Processing,2003,11(5):466-475.
[9] EPHRAIM Y,MALAH D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on Acoustics Speech & Signal Processing,1985,33(2):443-445.
[10] 崔玮玮,曹志刚,魏建强.声源定位中的时延估计技术[J]. 数据采集与处理,2007,22(1):90-99.
[11] KUTTRUFF H. Room acoustics[M]. Spon Press,London,Taylor & Francis,2000.
A speech dereverberation algorithm with the combination of direct path strategy
Chen Changhai
(Fuzhou RockChip Electronics Co.,Ltd.,Fuzhou 350003,China)
The reverberation is generated when the speech signal is reflected and absorbed by wall and other objects,and is superimposed by multipath propagation,which is one of the main reasons that degrade the performance of speech recognition systems. The dereverberation algorithm based on TF-GSC may lead to excessive estimation of reverberation power spectrum,resulting in the distortion of output. In this paper,a direct path compensation strategy is proposed and applied to the dereverberation algorithm. The experimental results show that the direct path compensation strategy reduces the output speech distortion and improves the quality of output speech.
reverberation; TF-GSC; direct path compensation; reverberation power spectrum
TP312
A
10.19358/j.issn.1674-7720.2017.24.010
陈长海.一种结合直达声补偿策略的混响抑制算法J.微型机与应用,2017,36(24):32-36.
2017-06-23)
陈长海(1984-),男,硕士研究生,主要研究方向:智能音频和智能车载产品。
猜你喜欢
实验室研究与探索(2023年7期)2023-10-26 05:23:48
电讯技术(2022年12期)2022-12-30 06:22:40
软件导刊(2020年11期)2020-01-05 07:00:06
复旦学报(自然科学版)(2019年3期)2019-07-19 09:48:04
复旦学报(自然科学版)(2019年3期)2019-07-19 09:48:04
电子测试(2018年23期)2018-12-29 11:11:24
舰船电子工程(2018年11期)2018-11-26 07:55:08
剧作家(2018年2期)2018-09-10 01:47:18
小学科学(2016年12期)2017-01-06 19:36:17
西北工业大学学报(2015年3期)2015-12-14 13:08:44
