
数据驱动的软件可靠性模型在石油工业信息系统中的应用
2017-12-25 03:34:03刘洪太
石油工业技术监督 2017年11期
刘洪太
中国石油集团安全环保技术研究院 (北京 102206)
数据驱动的软件可靠性模型在石油工业信息系统中的应用
刘洪太
中国石油集团安全环保技术研究院 (北京 102206)
近年来,石油工业信息系统不断发展,规模和复杂度不断提高,系统的可靠性越来越受到重视。然而,石油工业信息系统的质量控制缺少有效的工具和方法,软件可靠性模型在石油工业信息系统中没有得到很好的应用,系统失效数据没有得到充分利用。介绍了3种软件可靠性模型,并应用数据驱动的软件可靠性模型来预测石油工业信息系统中的失效数据,最后使用SVMr软件可靠性模型进行模拟仿真实验。结果表明,数据驱动的软件可靠性模型可以很好地预测石油工业信息系统中的软件失效数据,预测结果具有较高的决策价值。
软件可靠性模型;数据驱动;失效数据;石油工业信息系统
随着计算机系统的迅速发展以及工业化、信息化的不断推进,石油工业信息系统已成为石油行业不可或缺的工具,石油工业信息系统的规模、复杂性以及重要性也在不断上升。一旦重要的石油工业信息系统发生故障,将会造成诸多工作上的不便或重大的经济损失,甚至会危机人身安全,影响到国家安危。石油工业信息系统的可靠性已成为企业领导和公众关注的重大问题。
石油信息系统具有其自身的特点:①对系统要求高。因其组织机构庞大,业务流程复杂,石油工业业务种类繁多,这就要求信息系统具有很好的适用性和扩展性。②安全性要求高。石油工业数据具有极高的保密性,一旦某些信息系统的数据泄露,将会造成不可预估的后果。③开发周期长。大型石油信息系统的构建时间一般都需要几年的时间,耗费巨大的人力、物力。近些年,石油工业信息系统还在不断地完善和开发。由于石油工业信息系统有其自身的特点,特别是大型复杂的石油信息系统,导致在开发和维护中系统的可靠性很难得到保障,开发质量难以维护,缺少合适的方法和工具保障系统的质量,造成了大量数据资源的浪费。
高效的软件可靠性模型对石油工业信息系统质量的改善有着重要的指导意义,也有助于解决信息系统开发过程中出现的问题。因此,对于快速发展的石油工业信息系统,如何充分利用软件失效数据,使用好的软件可靠性模型进行预测,对石油企业的发展具有长远的意义。
到目前为止,软件可靠性模型有了一定的发展,并且在数量上也突破了一百多个[1]。近些年,通过时序数据预测方法建立软件可靠性模型越来越受到重视,时序数据预测领域不仅为软件可靠性模型提供了理论基础,而且,很多分析与处理技术在建模数据处理上也有很好的应用。然而,在石油工业信息系统开发和维护中,使用数据驱动的软件可靠性模型对系统失效数据进行预测和分析并没有得到充分的应用。因此,笔者将数据驱动软件可靠性模型应用于石油工业信息系统,对软件失效数据进行预测。
1 软件可靠性概述
1.1 软件可靠性概念
软件可靠性在很长一段时间没有确切的定义。甚至软件的可靠性这个属性一直都是一个很受争议的属性,有人认为软件不存在这个属性,他们把此属性说成是“理想化”,有些人却认为该属性本身就存在,即软件正确性。这两种观念都是偏颇的。
通过总结前人的结论和经验,1983年美国IEEE Computer Society给予了“软件可靠性”一个统一且合理的解释[2]:①在既定的环境中,软件运行维持稳定的概率。此概率为软件从输入到输出出现错误的函数表达。②在既定的环境中和周期内,程序所能达到的预期功能效果的程度。
软件可靠性的兴起和发展主要源于3个方面的因素:一是需求。软件质量问题一直是客户最关心的问题,软件危机与20世纪90年代软件故障引发了许多重大事故,对顾客造成了重大的损失,严重影响了客户满意度。二是技术。这几年,信息产业遍布全球,各类软件层出不穷,软件可靠性以此为载体得到了长足发展和动力。三是可靠性工程。软件可靠性工程已经研究了多年,并有了相当成熟的理论和方法,为软件可靠性的研究提供了基础。
1.2 软件失效数据
软件失效数据在软件可靠性评估和软件可靠性建模领域都起着重要的作用。软件在测试或运行过程中没有得到想要的效果,称为软件失效。软件失效数据包含2种:一种是软件累积失效数据,由于缺陷导致了软件的失效,也可以称为软件累积缺陷数据;另一种为失效间隔数据。软件累积失效数据为软件从开始到某一时间点之间软件失效的次数;失效间隔数据为软件从上一个时间点到下一时间点之间发生的失效次数。
正确的搜集和处理软件失效数据是软件系统质量评估的基础。在实际中,大量的软件失效并不都适合用来进行预测软件可靠性,由于硬件错误或记录错误等都有可能造成失效数据采集的不准确。因此失效数据预处理和加工对于后期软件质量的评估起着至关重要的作用。
2 数据驱动的软件可靠性模型简介
数据驱动的软件可靠性模型是基于观测到的软件失效数据,将其视为一个时间序列进行建模与分析,并对软件将来的失效行为进行预测[3]。数据驱动的软件可靠性模型不需要对软件内部错误及失效过程做任何假设,因而其应用范围较广。数据驱动的软件可靠性模型主要包括基于时间序列分析的模型[4~5]、基于人工神经网络的模型和基于支持向量机的模型[6]等。
2.1 ARIMA模型
自回归求积移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)用来预测不稳定时间序列,在时间序列之上引入了k次序列和d阶差分。ARIMA模型对时间序列Xt(t=1,2,3…,N)的表达式[7]为:

式中,p为自回归周期数,q为移动平均周期数。

通常,k=1是比较合理的,代表ARIMA(p,d,q)模型,取k=1模型等式为:
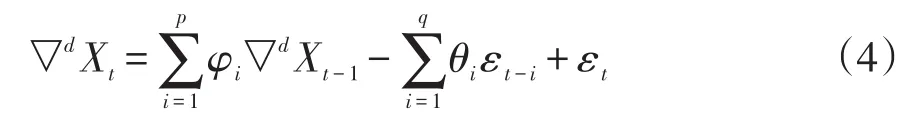
ARIMA模型用来研究时间序列,并通过差分使不稳定的数据变得稳定。通过Eviews软件可以分析出序列是否为稳定序列。序列稳定后,p和q的值就确定了。在p和q确定过程中,自相关函数和局部自相关函数是最重要的。自相关函数代表了每个序列值之间简单的关联关系。自相关函数系数的表达式见式(5):

对于时间序列X1,X2,X3…,Xt,和Xt-k之间的相关条件称为偏自相关函数,表达式见式(6):

式中,-1<Φkk<1,Φk,j递推公式见式(7):

在实际应用过程中,时间序列的自相关函数和偏自相关函数需要全面被监测,通过Eviews软件,可以得到自相关和偏自相关的数值,从而得到p和q的值。
2.2 SVMr软件可靠性模型
支持向量机起初应用于分类模型中,Vapnik提出,回归函数可以通过训练数据集反映输入与输出的关系模型[8],Xi为实际的输入,yi为实际的输出,1为训练数据对的总数。支持向量机回归模型公式见式(8):

其中Φ(X)是一个高维特征空间映射函数,将输入样本X映射到一个高维的特征空间,通过等式(8),低维空间中输入与输出的非线性关系可以被转换为高维中的线性形式,“维数灾难”的问题也在转换中得到了解决。式(8)中,W为权向量;b为阈值,对于给定的训练数据集采用ε不敏感损失函数,对应的支持向量机称为ε-支持向量机,则W和b的值可由以下约束优化问题求得:
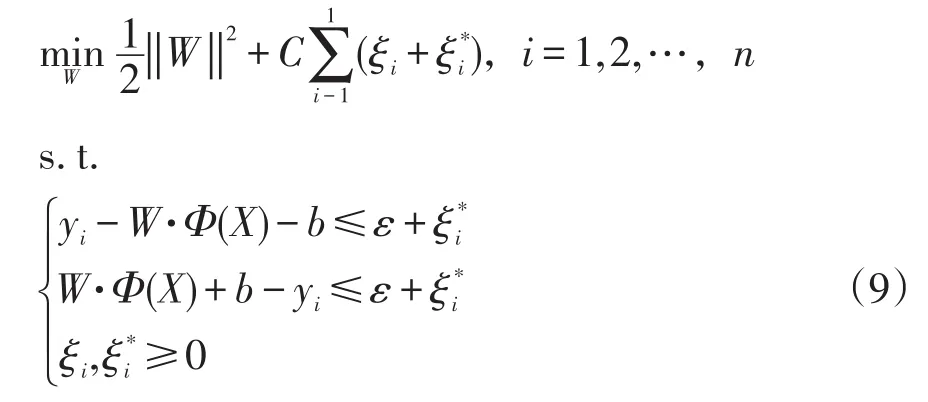
其中,C为惩罚因子,C>0,用于控制误差超出ε的样本的惩罚程度。式(9)的优化问题可通过引入拉格朗日函数将其转化为对偶问题,通过解对偶问题得到式(8)的解:
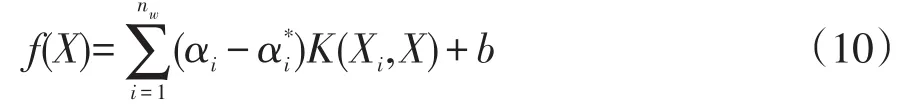
2.3 RBF神经网络可靠性模型
径向基(RBF)神经网络为前向两层神经网络,并含有单隐含层。RBF神经网络的思想是模拟人脑局部调整的网络结构,会在核函数的周围产生强烈的响应,RBF神经网络可以看作控制过程的局部逼近模型,其本质上具有非线性特性,处理非线性关系数据有很好的效果。RBF神经网络不需要样本数据具有特别的分布特性,有很好的泛化能力,并且具有即时学习能力和快速的收敛能力。图1为一般的RBF神经网络的结构图。
如图1所示,RBF神经网络的输入向量由n个输入数据组成,表示为X=[x1,x2,x3…,xn]T,在模型隐含层由m个元素组成的中间向量H=[h1,h2…,hm]T,hm称为径向基函数,操作符‖‖·代表一个p基,称为欧氏范数。本节使用高斯径向基函数来选择参数Φ,表示形式为式(11)。

图1 RBF神经网络的结构图

式中,Cj=[cj1,cj2,…,cjn]称为基函数的中心点,σj相应地称为它的径,即中心点宽度。t网络的第三层为综合输出-y,见式(12):

实数参数Wj,∀j=1,2,…,m为隐含层到输出层之间的权重。真实值和预测值之间的误差(y(k)--y(k))用来调整RBF神经网络参数。对于RBF输出权重的更新迭代算法,使用梯度下降方法进行。
3 数据驱动的软件可靠性模型在石油工业信息系统中的仿真应用
本文使用SVMr软件可靠性模型作为预测模型,在SVMr模型中,采用高斯核函数,模型参数惩罚因子取C=100,高斯核函数中σ=1,W=0.1。使用Matlab工具进行模拟仿真,使用HSE2.0(安全环保健康2.0)系统在开发和运维积累的系统失效数据作为实验数据,共选取225对采样点数据。每对采样点由软件累积执行时间和软件累积失效数量组成。数据示例见表1。
3.1 模型输入的选取
采用滑动窗口机制和粒子群(PSO)算法[9]在滑动窗口内选取对预测数据具有重要影响的某些失效数据作为模型输入。输入组合采用二进制形式表示,“0”表示未选择,“1”表示被选择,例如当 W=6,“010101”则代表2,4,6位置上的失效数据被选择作为模型输入。
仿真实验取前200个失效数据作为训练数据,后25个数据作为测试数据。通过文献[9]中给出的方法计算得到在W=7时,滑动窗口内得到最优的模型输入为 0111011,表示滑动窗口内 2、3、4、6、7 位置上的失效数据组合作为模型输入。

表1 HSE2.0系统累积执行时间和软件累积失效数量
3.2 评价标准
本实验选用平均绝对误差(MAE)、均方差(MSE)和平均绝对百分比误差(MAPE)作为预测结果评判标准:
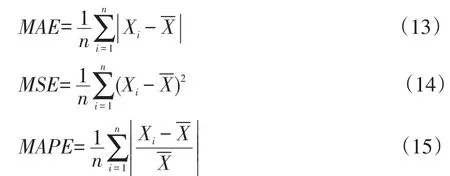
3.3 仿真实验
以下实验结果为SVMr软件可靠性模型对HSE2.0系统累计失效数据的预测结果,如图2和表2所示。
图2 SVMr模型对HSE2.0系统累计失效数据的预测结果图

表2 SVMr可靠性模型对HSE2.0系统累计失效数据预测性能
3.4 实验分析
本实验通过使用SVMr软件可靠性模型对HSE2.0系统累计失效数据进行预测,从仿真实验预测结果误差可以明显看出,使用SVMr软件可靠性模型能够精确预测HSE2.0系统累计失效数据,误差较小,评价标准MAE、MSE和MAPE较小。这说明提出的基于数据驱动的软件可靠性模型在石油工业信息系统中能够准确、客观地预测系统失效数据。
4 结论
笔者提出了将数据驱动的软件可靠性模型应用于石油工业信息系统,并通过SVMr软件可靠性模型进行仿真实验,证明了数据驱动的软件可靠性模型能够充分利用系统中产生的失效数据,获得精确的预测效果,为系统的开发和维护提供强有力的支持,为企业管理者提供决策指导。
[1]Whittaker J A,Voas J.Toward a More Reliable Theory of Software Reliability[J].Computer,2000,33(12):36-42.
[2]蔡开元.软件可靠性工程基础[M].北京:清华大学出版社,1995.
[3]Tian L,Noore A.Dynamic software reliability prediction:an approach based on support vector machines[J].International Journal of Reliability,Quality and Safety Engineering,2005,12(4):309-321.
[4]Burtschy B,Albeanu G,Boros D N,et al.Improving software reliability forecasting[J].Microelectronics and Reliability,1997,37(6):901-907.
[5]Guo J,Liu,H,Yang,X,et al.A software reliability time series growth model with Kalman filter[J].WSEAS Transactions on Computers,2006,5(1):1-7.
[6]贾冀婷.基于PSOABC-SVM的软件可靠性预测模型究[J].计算机系统应用,2014,23(7):161-164.
[7]Zheng T C,Gong S,Shi H B.The ARIMA prediction model of rain-induced dynamic attenuation characteristics[C].International Symposium on Antennas,Propagation&Em Theory.2012:587-590.
[8]Vapnik VN.The nature of statistical learning theory[M].2nd Edition.New York:SpringerVerlag,1995.
[9]李克文,刘洪太.基于时序数据的软件可靠性模型组合新方法[J].计算机应用,2014,34(S2):208-210.
In recent years,the petroleum industry information system has been developing continuously,and the scale and complexity have been continuously improved.The reliability of the system has been paid more and more attention to.However,in the past,the effective tools and methods for controlling the quality of the petroleum industry information system lacked,software reliability model was not well used in the petroleum industry information system,and the system failure data were not fully utilized.For this reason,3 kinds of software reliability models are introduced,the data-driven software reliability models are used for predicting the failure data in the petroleum industry information system,and finally simulation experiment is carried out using SVMr software reliability model.The simulation results show that the data-driven software reliability model can very well predict the software failure data in the petroleum industry information system,and the prediction results have high decision-making value.
software reliability model;data driven;failure data;petroleum industry information system
刘洪太(1988-),男,硕士,主要从事软件质量与可靠性方向的研究工作。
王 梅
2017-09-08
猜你喜欢
石油工业技术监督(2022年9期)2022-09-23 04:15:46
哈尔滨轴承(2022年1期)2022-05-23 13:13:18
石油工业技术监督(2021年6期)2021-06-22 09:58:42
信息安全研究(2018年11期)2018-11-15 09:00:26
电子制作(2018年11期)2018-08-04 03:25:54
消费导刊(2017年20期)2018-01-03 06:26:40
现代工业经济和信息化(2016年12期)2016-05-17 05:37:57
现代工业经济和信息化(2016年1期)2016-05-17 05:33:48
全国新书目(2014年7期)2014-09-19 20:45:40
铁路通信信号工程技术(2014年5期)2014-02-28 16:57:12
