
基于密度的K-means算法在轨迹数据聚类中的优化
2017-12-14 05:35:24郝美薇戴华林
计算机应用 2017年10期
郝美薇,戴华林,郝 琨
(天津城建大学 计算机与信息工程学院,天津 300384) (*通信作者电子邮箱angelsamle@126.com)
基于密度的K-means算法在轨迹数据聚类中的优化
郝美薇*,戴华林,郝 琨
(天津城建大学 计算机与信息工程学院,天津 300384) (*通信作者电子邮箱angelsamle@126.com)
针对传统的K-means算法无法预先明确聚类数目,对初始聚类中心选取敏感且易受离群孤点影响导致聚类结果稳定性和准确性欠佳的问题,提出一种改进的基于密度的K-means算法。该算法首先基于轨迹数据分布密度和增加轨迹数据关键点密度权值的方式选取高密度的轨迹数据点作为初始聚类中心进行K-means聚类,然后结合聚类有效函数类内类外划分指标对聚类结果进行评价,最后根据评价确定最佳聚类数目和最优聚类划分。理论研究与实验结果表明,该算法能够更好地提取轨迹关键点,保留关键路径信息,且与传统的K-means算法相比,聚类准确性提高了28个百分点,与具有噪声的基于密度的聚类算法相比,聚类准确性提高了17个百分点。所提算法在轨迹数据聚类中具有更好的稳定性和准确性。
K-means算法;基于密度;车辆活动特征;密度权值;初始聚类中心;类内类外划分指标
0 引言
伴随着大数据时代的到来,在移动定位服务的高速发展下,轨迹数据已经成为了一项重要的数字资源。由于轨迹数据通常存在着数据量庞大、数据质量较低的问题,因此如何对轨迹数据进行数据挖掘和可视化分析获取深层语义成为大数据分析的一大热点问题。聚类算法作为对轨迹数据特征提取的有效技术,被广泛应用于轨迹数据挖掘中。其中最有代表的轨迹数据聚类算法包括基于概率的聚类算法、基于划分的聚类算法、基于密度的聚类算法、基于子轨迹的聚类算法和基于流场的聚类算法[1]。而在这些聚类算法中又以基于划分和密度的聚类算法使用最为广泛。
K-means算法[1]作为典型的基于划分的聚类算法因其简单高效而被广泛使用。但它需要使用者根据相关经验或相关领域背景来确定聚类数目和初始聚类中心,且对初始聚类中心选择敏感,易受数据输入顺序影响,导致其聚类结果准确性和稳定性欠佳。针对这些问题,许多学者提出了不同的改进方案。基于密度考虑的改进方案有:文献[2]提出的聚类中心初始化算法(Cluster Center Initialization Algorithm, CCIA),通过样本数据点的密度分布信息进行聚类合并得到初始聚类中心;文献[3]提出的构建KD树(K-Dimensional tree, KD-tree),通过选取密度较大且相互远离的样本数据点作为初始聚类中心;文献[4]提出的选取大于平均密度的样本数据点作为初始聚类中心以及文献[5]提出的选取高密度区域中距离全局样本数据中心点最远的样本数据作为初始聚类中心。这些算法不适用于数据分布较为均匀的样本数据集,在根据密度筛选样本数据时有的算法还需要加入其他参数进行辅助判断。基于距离考虑的改进方案有:文献[6]提出的根据聚簇内样本距离小于聚簇间样本距离动态调整初始聚类中心选取;文献[7] 算法根据每个样本数据点到其聚类中心的距离给定一个特定加权系数进行聚类;文献[8]提出的在极小极大算法基础上确定初始聚类中心并根据欧氏距离进行分类。这些算法在面对较大规模的样本数据集时会增加算法时间复杂度,降低运算效率,且聚类结果易受到离群孤点的干扰。此外还有结合密度与距离的改进方案:文献[9]算法将样本数据集分为若干小子集并加入质心和权重两个特征,在此基础上进行局部聚类,但在高维度的样本数据集中计算复杂度会明显增加;文献[10]算法基于高密度且相互远离的原则根据平方误差标准确定聚类数目选取初始聚类中心,但在较大规模的样本数据集中算法效率明显降低。
轨迹数据的数据量庞大,数据结构较为复杂,而传统的K-means算法无法预先明确聚类数目,对初始聚类中心选取敏感且易受离群孤点影响导致聚类结果稳定性和准确性欠佳。针对这一问题,本文提出了一种改进的基于密度的K-means算法,通过标准差计算样本轨迹数据点的分布密度,并以密度感知筛选出车辆活动状态为转弯状态的样本轨迹数据点增加其密度权重,最终在聚类有效函数类内类外划分(Between-Within Proportion, BWP)指标的干预下,选取高密度且相互远离的样本数据点作为初始聚类中心并确定最佳聚类数目和聚类结果,获取轨迹路径中的关键点。该算法能够自动获取聚类数目和初始聚类中心,具有较强的抗噪点干扰性,同时根据车辆活动特征进行筛选有效地提高了聚类结果即轨迹关键点的准确性。
1 相关描述与定义
设轨迹数据点集P={p1,p2, …,pn}∈Rd*n,d=3,其中d代表轨迹数据样本维度,本文中的轨迹数据维度为三维即空间的经纬度坐标两个维度和时间维度;n代表轨迹数据样本总数。
对本文算法中提出的一些重要概念进行定义:
定义1 单个轨迹数据点的密度值。对于轨迹数据点中的任意一个样本轨迹数据点pi的密度Densr(pi)[11]具体定义如下:
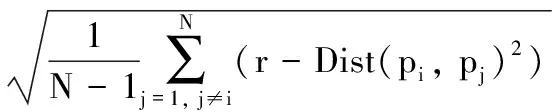
(1)
其中:r为给定的有效密度半径;N为该半径内所包含的轨迹数据点的总数;pj为以pi为圆心r为半径的圆内的第j个轨迹数据点;Dist(pi,pj)为轨迹数据点pi和pj欧氏距离。
定义2 转弯状态的轨迹数据点权值密度值。在识别轨迹数据点的直行和转弯状态之后,需要通过增加相应密度的权值提高该数据点的筛选概率,因此引入了转弯状态的轨迹数据点权值密度的概念。对于轨迹数据点中的任意一个样本转弯点pi的权值密度WDensr(pi)[7,11]具体定义如下:
WDensr(pi)=
(2)
定义3 轨迹数据点的平均距离。对于轨迹数据集而言,其轨迹数据点的平均距离avgDist[5]具体定义如下:

(3)
通过计算轨迹数据点间的平均距离,可以有效地反映轨迹数据集的整体离散程度,为更好地确定邻域半径提供有效依据。
定义4 邻域半径。邻域半径作为有效密度半径时不仅直接参与密度值的计算,同时还决定了可能包含轨迹数据点的多少,合适的邻域半径对于密度计算结果至关重要,邻域半径γ具体定义如下:
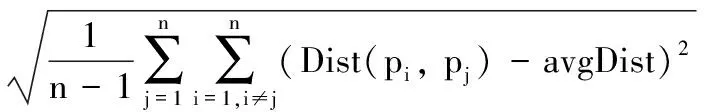
(4)
邻域半径采用计算轨迹数据点距离的标准差方式来确定,由于标准差能够有效反映变量与期望的偏差程度,因此通过计算距离的标准差可知标准差越小,邻域半径越小,所圈邻域内的轨迹数据点越紧密。
定义5 轨迹步长。车辆轨迹数据通常都是采用均匀时间间隔进行抽样获取的,轨迹步长则是用来反映一段轨迹中由所采轨迹数据点分割后的每段轨迹的长度,该长度可以间接反映轨迹中车辆活动的速度等属性,轨迹步长ε具体定义如下:
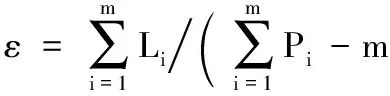
(5)
其中:m为样本轨迹数据的条数;Li为每条轨迹的长度即通过将每条轨迹路径按照时间序列顺序连接后计算每段轨迹的长度并求和;Pi为每条轨迹上的轨迹数据点总数。将求取的轨迹步长作为有效密度半径对数据点进行密度计算帮助判断其车辆活动特征,通常轨迹步长越短表明其当时车辆速度较低,且所圈轨迹数据点密度可能越大,通常认为车辆在转弯过程中轨迹数据点具有高密度低速率的特性。
2 改进的基于密度的K-means算法
2.1 基于密度的初始聚类中心的选取
传统K-means算法对初始聚类中心都是随机选取,易受到样本数据集中离群孤点的影响导致算法陷入局部最优解,从而直接影响聚类结果的准确性和稳定性。本文针对这一问题,提出了一种基于样本轨迹数据分布密度和增加轨迹数据关键点密度权值的方式来选取高密度的轨迹数据点作为初始聚类中心。
本文主要作了以下两点改进:1)通过计算轨迹数据集中各轨迹数据点的密度值,选取高密度的轨迹数据点作为初始点,从而有效地减小轨迹数据集中离群孤点对于聚类结果的影响,防止算法过早收敛陷入局部最优解;2)通过一种密度感知方法对车辆活动特征比如直行转弯状态进行分析,选择转弯状态的轨迹数据点增加其密度权重,增大轨迹关键点筛选的概率,提高最终聚类结果的准确性。
该算法首先选取轨迹数据中密度值较大的2K(K为聚类数目)个轨迹数据点作为初始聚类中心的核心对象,并筛选出其中为转弯状态的轨迹数据点增加其密度权重;然后按照其密度大小依次进行聚类合并,同时重新计算聚类中心的密度值,选取K个密度值较大的聚类中心作为初始聚类中心;最后将未被聚类的轨迹数据点标记为噪点从轨迹数据集中去除。
算法描述如下。
输入 含有n个对象的轨迹数据集X,期望划分的聚类数目K, 最小密度阈值minDen,邻域半径γ,轨迹步长ε。
输出 含有K个对象的初始聚类中心点集T,去除噪点的轨迹数据集P。
Begin:
1)令集合D={},D′={},W={},T={},P={}。
2)根据式(3),式(4)计算邻域半径γ;根据式(5)计算轨迹步长ε。
3)遍历集合X中的每一个对象xi,给xi加入密度标签,取r=γ,根据式(1)计算xi初始密度值Densr(xi)。
5)遍历集合X中的每一个对象xi。
5.1)取r=ε,根据式(1)计算xi密度值Densr(xi)。
5.2)如果Densr(xi)≥minDen,则将xi加入到集合D′中。
6)取集合D与集合D′中在空间维度和时间维度完全相同的对象加入集合W中。
7)遍历集合W中的每一个对象xi,给xi加入转弯标签,更新其密度标签,取r=γ,根据式(2)计算xi权值密度值WDensr(xi)。
Repeat:
8)取集合D中无中心点或边界点标签的第一个对象di。
8.1)将di作为一个新聚簇的聚簇中心点,加入中心点标签,遍历集合X中的每一个对象xi且xi≠di,如果xi是di的直接密度可达点且xi无中心点或边界点标签,则给xi加入边界点标签,纳入该聚簇内。
8.2)更新di密度标签,如果di有转弯标签,则取r=γ,根据式(2)计算di权值密度值WDensr(di);否则取r=γ,根据式(1)计算di密度值Densr(di)。
Until: 遍历集合D中全部对象,即集合D中的每个对象都含有中心点或边界点标签。
9)选取集合D中具有中心点标签且密度标签值较大的前K个对象加入集合T中。
10)遍历集合X中的每一个对象xi,如果xi无中心点或边界点标签,则给xi加入噪点标签;否则将xi加入集合P中。
11)输出结果。
End
2.2 聚类数目K值的优化选取
对于轨迹数据集这种数据结构未知的样本数据,通常采用聚类有效函数的内部度量方式对聚类结果进行评价。内部度量中公认比较优秀的指标包括CH(Calinski-Harabasz)指标[13]、DB(Davies-Bouldin)指标[14]、Wint(Weighted inter-intra)指标[15]、IGP(In-Group Proportion)指标[16]等。然而这些指标都存在一些自身的局限性,仅在其适用范围内针对一些特定的样本数据集能够取得较好的度量结果,对于超出适用范围的样本数据集,这些指标的聚类有效性检验通常并不理想,容易使算法陷入局部最优解而无法获取最优聚类数目。
本文中为了选取一个高质量的聚类结果要求每个聚类内样本尽可能地相似,不同聚类间样本尽可能地不同,采用距离度量方式即使聚簇内的样本距离极小化,聚簇间的样本距离极大化。本文算法选用了BWP指标BWP(j,i)[17],即第j类第i个样本数据的聚类离差距离bsw(j,i)与聚类距离baw(j,i)的比值来更好地反映聚簇内紧密度与聚簇间分离度,具体描述为:
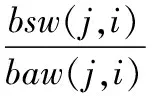
(6)
其中:b(j,i)为第j类第i个样本数据的最小类间距离,即该样本到其他每个聚簇内的各个样本平均距离的最小值。b(j,i)可描述为:
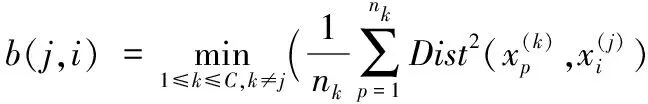
(7)
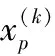
w(j,i)为第j类第i个样本数据的类内距离,即该样本到其所属聚簇内的各个样本的平均距离,具体描述为:
(8)
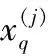
可以看出BWP(j,i)采用线性组合的方式来平衡最小类间距离b(j,i)和类内距离w(j,i)并保证函数目标一致。BWP(j,i)指标的范围为[-1,1]:当BWP(j,i)近似为1时表示该样本数据被聚类正确;近似为-1时表示该样本数据被聚类错误。
所有样本数据集的平均BWP指标越大,表明聚类结果质量越高,聚簇内样本越紧密,聚簇间样本越分离。因此平均BWP指标最大时聚类结果所对应的聚类数目Kopt值为最佳聚类数目K值,即
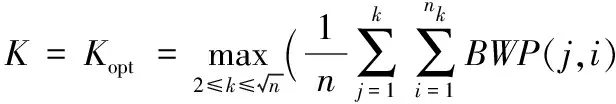
(9)
其中:N为样本总数;nk为第k个聚簇内的样本数据总数。
2.3 基于密度和BWP指标优化的K-means算法
算法描述如下。
输入 含有n个对象的轨迹数据集X,最小密度阈值minDen,邻域半径γ,轨迹步长ε。
输出 最佳聚类数目K,最佳聚类划分集T。
Begin:
1) 令集合X={},T′={},T={},S={};
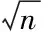
2.1) 根据基于密度的初始聚类中心的选取算法,选取k个初始聚类中心点;
2.2) 根据改进的K-means算法对去除噪声后的轨迹数据样本集进行聚类,聚类结果放入集合T′中;
2.3) 根据式(6)计算T′中聚类结果的平均BWP值avgBWP,并将(k,avgBWP)放入集合S中;
2.4) 将集合T′放入集合X中,之后令T={};
3) 比较集合S中的各对象的avgBWP值,取最大的avgBWP所在对象Target并记录该对象所在集合S中的下标index;
4)k=Target对象的k值,T=Xindex,其中Xindex为集合X中第index个对象;
5) 输出结果;
End
本文算法对于传统K-means算法进行了优化,保证了初始聚类中心能够在高密度的轨迹数据点中产生,相对于传统算法中的随机选取初始聚类中心能够更好地防止算法过早收敛陷入局部最优解中,有效提高聚类结果准确性。此外提出的选取初始聚类中心的算法能够粗略去除轨迹数据样本中的噪点,有利于提高聚类结果的准确性,有效避免了传统算法在选取初始聚类中心时反复迭代,在一定程度上提高了本文算法运行效率。通过BWP指标干预,本文算法能够自动获取最佳聚类数目K值,有效选取优质聚类结果,解决了对于轨迹数据样本数据结构未知时难以确定最佳聚类数目的难题,得到更为精准的聚类结果划分。
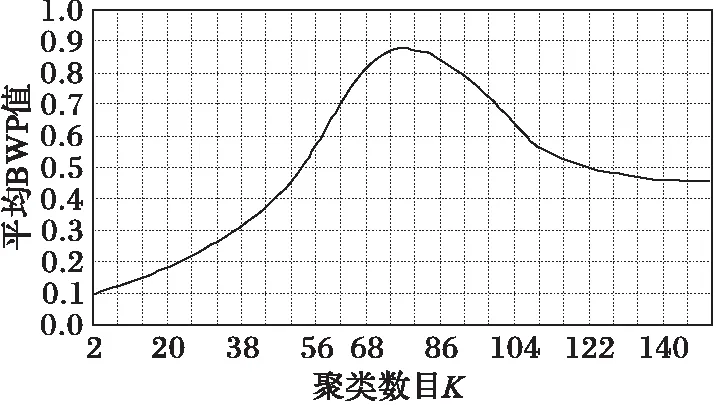
图1 轨迹数据集Data1聚类结果质量图
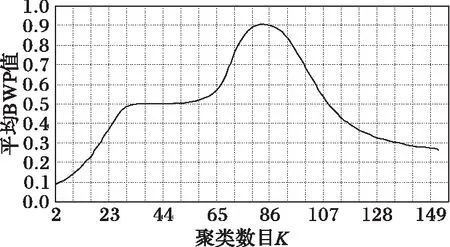
图2 轨迹数据集Data2聚类结果质量图
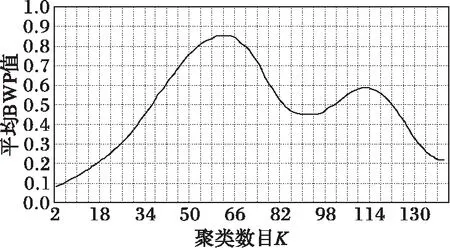
图3 轨迹数据集Data3聚类结果质量图
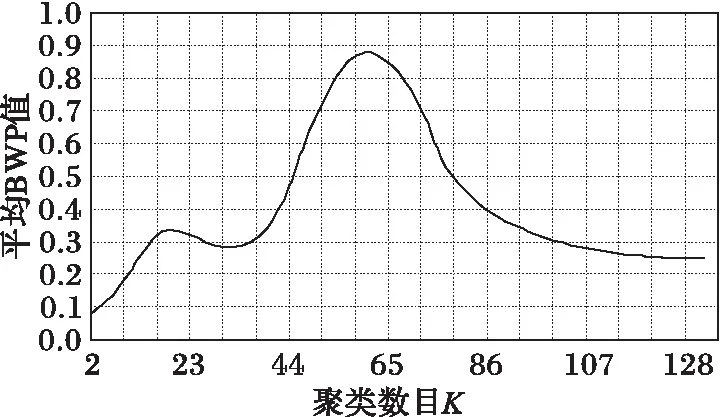
图4 轨迹数据集Data4聚类结果质量图
3 实验与分析
本文提出的改进的基于密度的K-means算法验证实验主要分为两大部分:一部分是采用本文算法对实验数据进行测试实验,分析其聚类结果;另一部分是将本文算法与传统的K-means算法和具有噪声的基于密度的聚类(Density-Based Spatial Clustering of Applications with Noise, DBSCAN)算法进行聚类结果和算法效率对比实验,验证本文算法的稳定性、准确性和有效性。
3.1 实验平台与实验数据
本文中实验分析选用Windows 7.0,Matlab2015b开发环境,基于百度地图开发的地图引擎,Intel Core i7 2.00 GHz CPU, 4.00 GB内存作为实验平台;由数据堂提供的真实出租车GPS数据,选取在2015年9月1日—10日的8:00—10:00,12:00—14:00,16:00—18:00,20:00—22:00共计四个时间段的北京市东城区的出租车GPS数据作为四组实验数据,每个样本实验数据包括车辆ID号、经纬度坐标点和时间信息。数据集详细描述如表1所示。
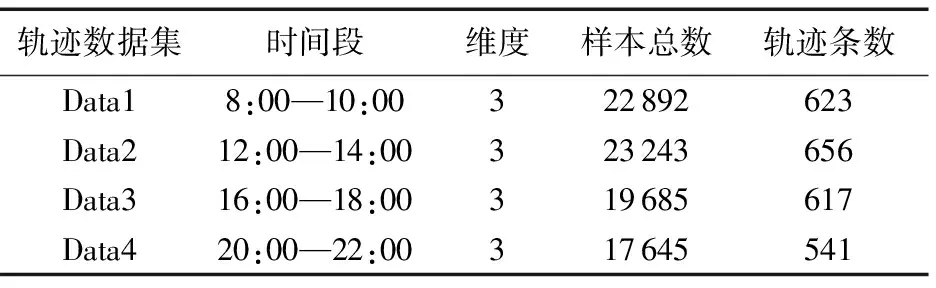
表1 实验轨迹数据集
3.2 改进的基于密度的K-means算法实验及分析
实验采用本文算法对四组实验数据进行测试,并为了便于观察聚类结果质量将每一组数据所取的聚类数目与平均BWP值拟合成关系曲线图,当平均BWP值最大时对应的K值为最佳聚类数目且此时所得轨迹数据聚类结果最优。轨迹数据集Data1的K值选取范围在区间[2,151]内,邻域半径γ=0.74,轨迹步长ε=0.37,其聚类结果如图1所示,当K=75时,对应的平均BWP值avgBWP75=0.882 507最大且该值接近于1表明轨迹数据集被正确聚类;轨迹数据集Data2的K值选取范围在区间[2,152]内,邻域半径γ=0.73,轨迹步长ε=0.36,其聚类结果如图2所示,当K=83时,对应的平均BWP值avgBWP83=0.907 683最大且该值接近于1表明轨迹数据集被正确聚类;轨迹数据集Data3的K值选取范围在区间[2,140]内,邻域半径γ=0.70,轨迹步长ε=0.35,其聚类结果如图3所示,当K=62时,对应的平均BWP值avgBWP62=0.854 317最大且该值接近于1表明轨迹数据集被正确聚类;轨迹数据集Data4的K值选取范围在区间[2,132]内,邻域半径γ=0.75,轨迹步长ε=0.38,其聚类结果如图4所示,当K=60时,对应的平均BWP值avgBWP60=0.881 316最大且该值接近于1表明轨迹数据集被正确聚类。
3.3 三种聚类算法对比实验及分析
为了验证本文算法的高效性,将本文算法与传统的K-means算法和DBSACN算法进行对比实验,主要包括聚类结果对比和算法效率对比两部分。
聚类结果对比主要是对聚类结果准确率、聚簇内距离、聚簇间距离、最佳聚类数目、聚类迭代次数五个方面进行分析。为了保证传统K-means算法的合理有效性,每个数据集在使用传统K-means算法进行聚类实验时会重复实验50次并取平均值作为最终聚类结果。三种算法的对比分析结果如表2所示。
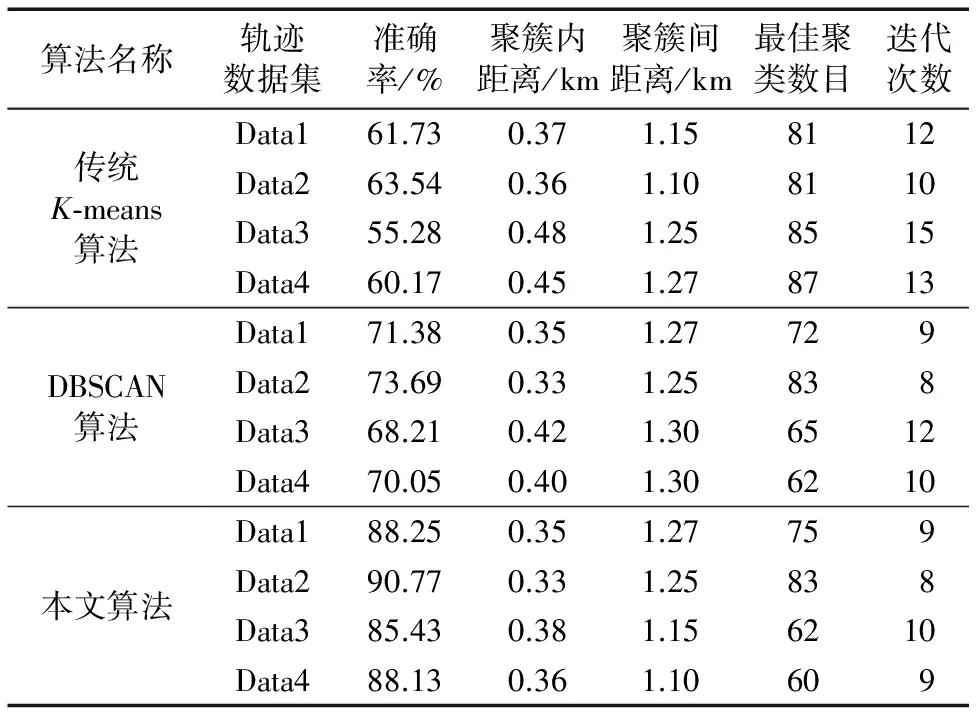
表2 三种算法的聚类结果对比

表3 三种算法的运算时间对比 s
从表2中可以看出,本文算法的准确率比传统K-means算法提高了约28个百分点,比DBSCAN算法提高了约17个百分点。相对于传统的K-means算法和DBSCAN算法其聚类迭代次数更少,表明本文算法对于初始聚类中心的选取合理有效。为了进一步验证三种算法在轨迹数据集中的聚类效果,选取轨迹数据集Data4的聚类结果进行热力图绘制效果如图5~7所示。
对比图5~7可以看出本文算法和DBSCAN算法在聚类划分上相对于传统K-means算法更为合理,能够更好地突出轨迹分布中车流量较大的路径点。此外,本文算法相对于其他两个算法具有更好地抗噪点干扰能力,轨迹数据的聚类结果更贴合实际道路,能够更好地提取实际轨迹信息。
实验结果表明,本文算法能够正确地对轨迹数据集进行聚类,有效提高了聚类结果的稳定性和准确性。聚类结果更加符合轨迹数据集的数据结构特征,能够准确提取轨迹中的关键路径点,有效避免轨迹数据集中噪点对于聚类结果的影响。
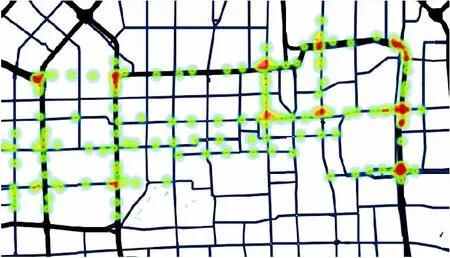
图5 本文算法实现的聚类结果热力图
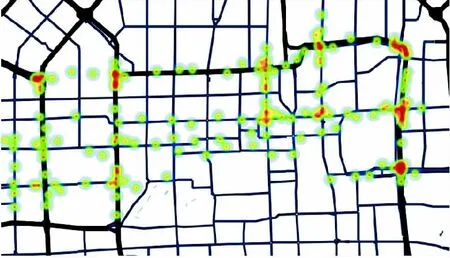
图6 基于DBSCAN算法实现的聚类结果热力图
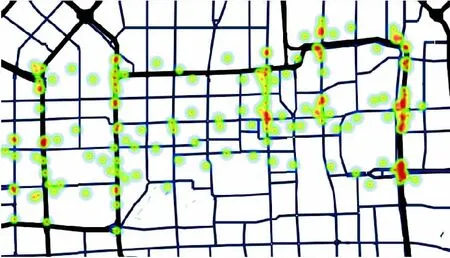
图7 基于传统K-means算法实现的聚类结果热力图
算法效率对比主要是对不同轨迹数据集中一次聚类迭代CPU所要消耗的时间进行对比,包括一次聚类迭代的最短时间、最长时间和平均时间。三种算法的对比分析结果如表3所示。
从表3的实验结果可看出:本文算法在每次迭代时CPU所消耗的平均时间与DBSCAN算法相当,尽管在计算选取初始聚类中心时时间复杂度有所增加,但对于轨迹数据这种数据结构较为复杂的样本数据集能够有效减少寻找初始聚类中心时的迭代次数,在一定程度上提高聚类算法运行效率。
4 结语
传统K-means算法需要根据使用者的自身经验或是相关知识背景实现确定聚类数目K值,并且由于通过随机选取确定初始聚类中心容易受到数据输入顺序和数据噪点的影响致使算法过早收敛陷入局部最优解,对于最终聚类结果的准确性和稳定性产生极大影响。针对以上问题,本文提出了一种改进的基于密度的K-means算法,结合BWP指标确定最佳聚类数目,将初始聚类中心选中在高密度的关键轨迹数据点,保证得到聚簇内紧密、聚簇间分散的高质量聚类结果。实验结果显示本文算法结果更为稳定且准确性更高,仿真结果也表明该算法能够更好地提取出轨迹数据的关键点。本文算法在计算样本间距和选取初始聚类中心时,时间复杂度有所增加,将在今后的研究中提高该部分的计算效率。
References)
[1] 王祖超, 袁晓如.轨迹数据可视分析研究[J]. 计算机辅助设计与图形学学报, 2015 27(1): 9-25. (WANG Z C, YUAN X R. Visual analysis of trajectory data[J]. Journal of Computer-Aided Design and Computer Graphics, 2015 27(1): 9-25.)
[2] KHAN S S, AHMAD A. Cluster center initialization algorithm forK-means clustering[J]. Expert Systems with Applications, 2004, 25(11): 1293-1302.
[3] REDMOND S J, HENEGHAN C. A method for initialising theK-means clustering algorithm using kd-trees[J]. Pattern Recognition Letters, 2007, 28(8): 965-973.
[4] FAN G L, LIU Y W, TONG J Q, et al. Application ofK-means algorithm to Web text mining based on average density optimization[J]. Journal of Digital Information Management, 2016, 14(1): 41.
[5] 何云斌, 刘雪娇, 王知强, 等.基于全局中心的高密度不唯一的K-means算法研究[J]. 计算机工程与应用, 2016, 52(1): 48-54. (HE Y B, LIU X J, WANG Z Q, et al. ImprovedK-means algorithm based on global center and nonuniqueness high-density points[J]. Computer Engineering and Applications, 2016, 52(1): 48-54.)
[6] ZHU M, WANG W, HUANG J. Improved initial cluster center selection inK-means clustering[J]. Engineering Computations, 2014, 31(8): 1661-1667.
[7] ZHANG T, MA F. Improved roughk-means clustering algorithm based on weighted distance measure with Gaussian function[J]. International Journal of Computer Mathematics, 2015, 94(1): 1-17.
[8] 张淑清, 黄震坤, 冯铭.一种优化的改进k_means算法[J]. 微电子学与计算机, 2015, 32(12): 36-39. (ZHANG S Q, HUANG Z K, FENG M. An optimizedK-means algorithm[J]. Microelectronics amp; Computer, 2015, 32(12): 36-39.)
[10] 张素洁, 赵怀慈.最优聚类个数和初始聚类中心点选取算法研究[J]. 计算机应用研究, 2017, 34(6): 1-5. (ZHANG S J, ZHAO H C. Algorithm research of optimal cluster number and initial cluster center[J]. Application Research of Computers, 2017, 34(6): 1-5.)
[11] RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks [J]. Science, 2014, 344(6191): 1492.
[12] REZAEE M R, LELIEVELDT B P F, REIBER J H C. A new cluster validity index for the fuzzy c-mean[J]. Pattern Recognition Letters, 1998, 19(3/4): 237-246.
[13] CALINSKI T, HARABASZ J. A dendrite method for cluster analysis[J]. Communications in Statistics, 1974, 3(1): 1-27.
[14] DAVIES D L, BOULDIN D W. A cluster separation measure[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1979, 1(2): 224.
[15] DIMITRIADOU E, DOLNICAR S, WEINGESSEL A. An examination of indexes for determining the number of clusters in binary data sets[J]. Psychometrika, 2002, 67(1): 137-159.
[16] KAPP A V, TIBSHIRANI R. Are clusters found in one dataset present in another dataset?[J]. Biostatistics, 2007, 8(1): 9-31.
[17] 周世兵, 徐振源, 唐旭清.K-means算法最佳聚类数确定方法[J]. 计算机应用, 2010,30(8): 1995-1998. (ZHOU S B, XU Z Y, TANG X Q. Method for determining optimal number of clusters inK-means clustering algorithm[J]. Journal of Computer Applications, 2010, 30(8): 1995-1998.)
Optimizationofdensity-basedK-meansalgorithmintrajectorydataclustering
HAO Meiwei*, DAI Hualin, HAO Kun
(CollegeofComputerandInformationEngineering,TianjinChengjianUniversity,Tianjin300384,China)
Since the traditionalK-means algorithm can hardly predefine the number of clusters, and performs sensitively to the initial clustering centers and outliers, which may result in unstable and inaccurate results, an improved density-basedK-means algorithm was proposed. Firstly, high-density trajectory data points were selected as the initial clustering centers to performK-means clustering by considering the density of the trajectory data distribution and increasing the weight of the density of important points. Secondly, the clustering results were evaluated by the Between-Within Proportion (BWP) index of cluster validity function. Finally, the optimal number of clusters and clustering were determined according to the clustering results evaluation. Theoretical researches and experimental results show that the improved algorithm can be better at extracting the trajectory key points and keeping the key path information. The accuracy of clustering results was 28 percentage points higher than that of the traditionalK-means algorithm and 17 percentage points higher than that of the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm. The proposed algorithm has a better stability and a higher accuracy in trajectory data clustering.
K-means algorithm; density-based; characteristics of vehicle activity; weight of density; initial clustering center; Between-Within Proportion (BWP) index
2017- 04- 14;
2017- 06- 21。
国家自然科学基金资助项目(61571318)。
郝美薇(1993—),女,新疆乌鲁木齐人,硕士研究生,主要研究方向:虚拟现实、大数据; 戴华林(1974—),男,湖南武冈人,教授,博士,主要研究方向:虚拟现实、数字图像处理; 郝琨(1979—),女,河北临西人,副教授,博士,主要研究方向:网络性能优化、无线传感网络、大数据分析。
1001- 9081(2017)10- 2946- 06
10.11772/j.issn.1001- 9081.2017.10.2946
TP301.6
A
This work is partially supported by the National Natural Science Foundation of China (61571318).
HAOMeiwei, born in 1993, M. S. candidate. Her research interests include virtual reality, big data.
DAIHualin, born in 1974, Ph. D., professor. His research interests include virtual reality, digital image processing.
HAOKun, born in 1979, Ph. D., associate professor. Her research interests include network performance optimization, wireless sensor network, big data analysis.
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
自动化学报(2018年7期)2018-08-20 02:59:04
现代装饰(2018年5期)2018-05-26 09:09:39
电子测试(2017年15期)2017-12-18 07:19:27
中国三峡(2017年2期)2017-06-09 08:15:29
周口师范学院学报(2016年5期)2016-10-17 06:36:47
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
