
基于用户实时反馈的点击率预估算法
2017-12-14 05:36:14杨诚
计算机应用 2017年10期
杨 诚
(常州信息职业技术学院 网络与通信工程学院,江苏 常州 213164) (*通信作者电子邮箱phlsage@163.com)
基于用户实时反馈的点击率预估算法
杨 诚*
(常州信息职业技术学院 网络与通信工程学院,江苏 常州 213164) (*通信作者电子邮箱phlsage@163.com)
当前主流的在线广告点击率(CTR)预估算法主要通过机器学习方法从大规模日志数据中挖掘用户与广告间的相关性从而提升点击率预估精度,其不足之处在于没有充分考虑用户实时行为对CTR的影响。对大规模真实在线广告日志进行分析后发现,在会话中,用户CTR的动态变化和用户先前的反馈行为高度相关,不同的用户行为对用户实时CTR的影响不尽相同。基于上述分析结果,提出一种基于用户实时反馈的点击率预估算法。首先,从大规模真实在线广告日志数据中定量分析用户反馈和点击率预估精度的相关关系;然后,根据分析结果将用户的反馈行为特征化;最后,使用机器学习方法对用户的行为进行建模,并根据用户的反馈实时动态调整广告投放,从而提升在线广告系统的点击率预估精度。实验结果表明,用户实时反馈特征和用户点击率高度相关;相比于传统没有用户实时反馈信息的预测模型,该算法在测试集上对AUC(Area Under the Curve)和RIG(Relative Information Gain)指标提升分别为0.83%和6.68%。实验结果表明,用户实时反馈特征显著提高点击率预估的精度。
机器学习;计算广告学;点击率预估;个性化;实时反馈
0 引言
随着互联网的快速发展,在线广告作为一个成功的商业模型,市场规模已达到百亿美元级别[1]。在线广告的点击率(Click Through Rate, CTR) 预估一直以来都是计算广告领域研究的核心问题。提高CTR预估精度可以同时提高广告平台、广告主和用户三方的利益:对广告平台而言,提高广告点击率可以提高平台收益;对广告主而言,高点击率意味着广告得到精确推送,有利于产品的推广和广告预算的优化使用;对用户而言,精准优质的广告可以带来更好的上网体验。因此,点击率预估一直以来都是业界研究热点。
CTR预估任务是根据用户历史广告点击数据预测未来用户对广告的点击情况。目前,国内外相关企业和机构在此问题上开展了广泛深入的研究。McMahan等[2]利用超大规模历史数据挖掘用户与广告的相关性,使用大规模机器学习方法训练预估模型,从而提高点击率预估的精度。Hillard等[3]针对用户搜索词历史数据的稀疏问题,提出了将户搜索词(query) 拆分成单词(unigram) 和词组 (phrase),然后根据这些单词和词组的平均点击率来估计搜索词和候选广告的相关性,以此提高CTR预估精度的算法。张志强等[4]针对广告数据特征高维稀疏的特点,提出了基于张量分解实现特征降维,然后使用深度学习方法建模调整广告投放的算法,以此提升广告点击率预估精度。Shen等[5]在点击率预估模型中重点考察用户的个性化偏好,提出了一种基于协同过滤和张量分解的方法,从历史数据中挖掘用户与展示广告间的相关性,以提升广告点击率预估精度。潘书敏等[6]提出了一种基于用户相似度和特征分化的点击率预估算法,通过对相似用户建模,挖掘不同用户类型的特征差异性,从而提升广告的点击率预估精度。
目前这些工作主要集中在通过历史数据挖掘、模型表达能力增强、特征稀疏性降维、广告创意与用户相关性提升,以及个性化建模等方面提升广告点击率预估精度,尚未考虑用户实时反馈对CTR预估精度的影响。事实上,用户的点击率并非恒定不变,而是伴随时间动态变化,当前利用用户历史点击率预测其未来点击率的做法还有很大提升空间。从这个角度出发,本文研究了用户实时反馈对CTR预估精度的影响。基于大规模数据比对分析,本文发现同一会话(Session)中用户的当前点击率与其先前行为呈高度相关性。举一个例子,假设用户在最近的网页浏览中忽视了大部分的广告,那么该用户点击下一个广告时的可能性将大大降低;相反,如果该用户点击了大部分推送给其的航班广告,那么该用户在见到下一个航班广告时的点击可能性将大大提升。因此,广告投放系统应当根据用户的反馈实时调整广告投放。例如:对喜欢点击广告的用户展示更多的广告,对经常忽视广告的用户应当减少甚至停止推送广告。
本文从多个维度定量地分析了用户实时反馈与用户CTR的相关关系,根据数据分析结果,提出了一种基于用户实时反馈的点击率预估算法。该算法将用户行为特征化,利用机器学习方法从大规模历史数据中对用户的实时行为进行建模,根据用户反馈实时调整广告投放,从而提升在线广告的点击率预估精度。
1 用户实时反馈行为分析
为了深入地理解实际生产环境中用户的不同行为在点击率预估问题中的作用,本章将从多个维度定量地分析和讨论同一会话中用户当前点击概率与用户先前的不同行为之间的相关关系。本文以某广告公司的真实广告历史点击日志[7]作为研究数据。该数据集共包括23天日志约2 400万条展示和被点击的广告样本。数据集的具体情况如表1所示。

表1 行为分析数据集基本情况
1.1 用户点击或忽视广告的次数与用户实时CTR的相关关系
用户点击或者忽视广告的行为是用户对广告系统最为直接的反馈。图1显示了从会话开始到当前的时间段内,用户点击的广告次数与用户实时CTR两者之间的关系,其中横轴表示用户先前的点击次数,纵轴表示符合该模式的这些用户当前时刻的平均CTR,即实时CTR。
从图1可以看出,用户的实时CTR与用户先前点击广告的次数呈正相关关系。如果用户先前点击的广告次数为0,那么该用户的实时CTR为0.081%,低于平均值0.084%;如果用户在此之前点击过一次广告,其实时CTR上升到12.44%,远高于平均CTR;若用户点击过两次广告,实时CTR则继续上升到25.27%。随着点击广告次数的增多,该用户的实时CTR也不断上升。
与图1中揭示的点击模式相反,用户忽视广告的个数越多,则用户的实时CTR越低。图2显示了在会话中,用户忽视的广告个数与实时CTR的关系。其中,横轴表示用户忽视的广告个数,纵轴表示实时CTR。这里,忽视的广告个数定义为用户见到却关闭或者没有点击的广告个数。从图2可以看出,随着用户忽视广告个数的增多,用户实时CTR随之呈下降趋势。
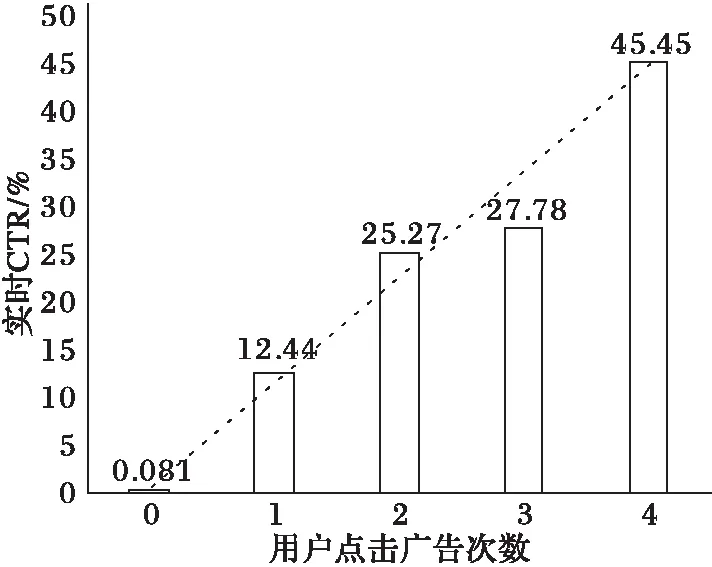
图1 会话中用户先前点击广告的次数与实时CTR的相关关系
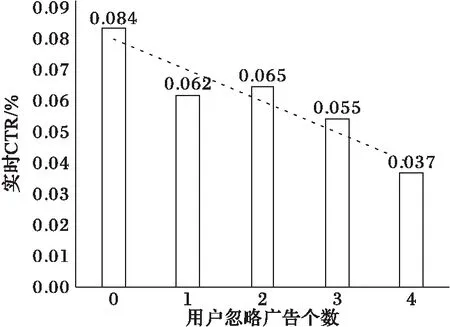
图2 会话中用户忽视的广告个数与CTR的相关关系
1.2 广告点击时间间隔与实时CTR的相关关系
除了点击或忽视广告等直接反馈,用户点击广告的时间分布也是一种反馈类型。本文针对会话中有多次点击记录的用户,分析了其当前CTR与其上一次点击时间的相关关系。图3显示点击数比例和相邻两次点击广告的时间间隔的相关性,其中横轴表示相邻两次点击的时间间隔,单位为分钟;纵轴表示点击数的百分比。由图3可知,超过80%的点击,其发生时间和上一次点击时间的间隔小于1 min。随着距离上一次点击时间的拉长,用户实时CTR不断下降。可见,用户点击广告的时间分布也是影响CTR预估的重要因素。
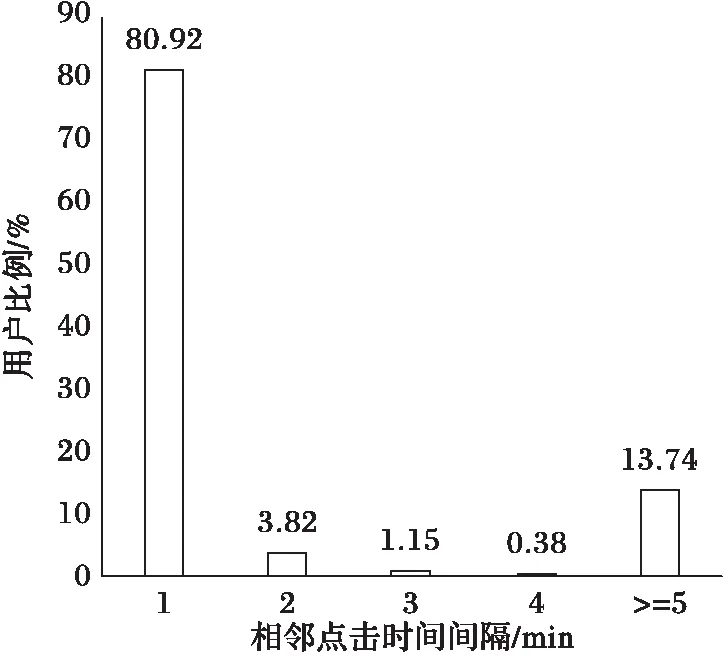
图3 会话中用户相邻两次点击的时间间隔比例
1.3 用户广告驻留时长与实时CTR的相关关系
一旦用户点击了某个广告,浏览器就会跳转到对应的广告页上。一般而言,用户在广告页上驻留时长反映了用户对于该广告的感兴趣程度[8]。从图3可知,大部分的连续点击发生在1 min之内,本节以这个时间段的数据为基础,分析用户在广告页上的驻留时长对用户实时CTR的影响。
图4显示了用户的驻留时长与实时CTR的相关关系。从图4中可以看出,用户在上一个广告页的驻留时长和实时CTR的具有高度相关性。广告驻留时长小于30 s的实时CTR显著高于驻留时长大于30 s的实时CTR,驻留时长超过30 s以后CTR呈明显下降趋势。可见,用户广告页驻留时长是影响CTR预估的又一重要因素。
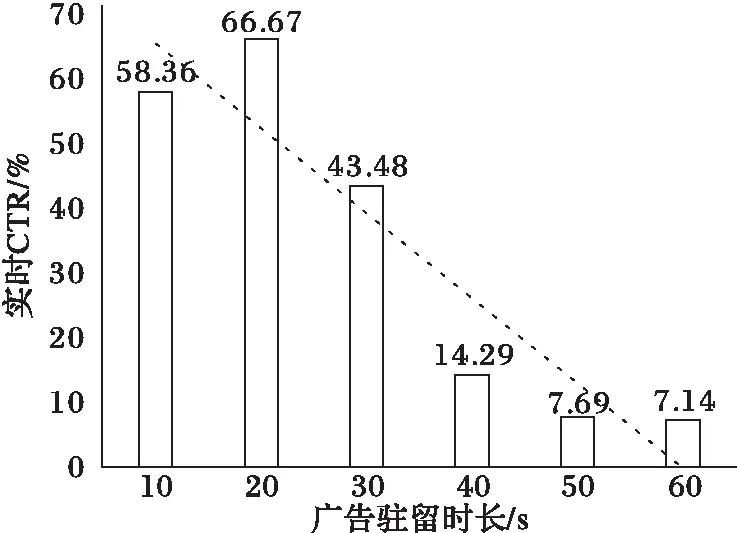
图4 用户在上一广告页上的驻留时长与其实时CTR的相关关系
1.4 广告类型与实时CTR的相关关系
用户对于广告类型的选择是另一种反馈类型。通过分析数据发现,在会话中很少有用户重复点击同一类型广告,点击两种类型广告的用户占大多数。图5显示了在会话中用户比例与被点击广告类型之间的关系。其中,横轴表示被点击的广告类型数,纵轴表示用户百分比。从图5中可知,在同一会话中,只有1.14%的用户会重复点击同一类型广告。这就意味着,如果用户已经点击了某个类型的广告,那么用户再次点击该类型广告的概率就会大大降低。
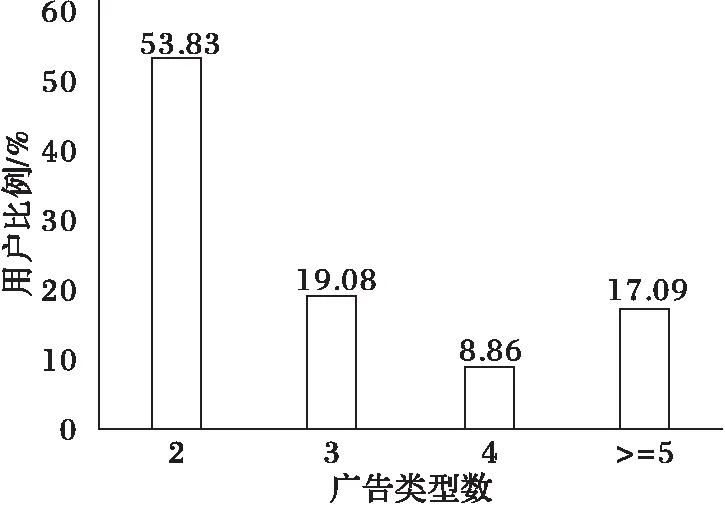
图5 会话中被点击广告的类型个数与用户比例的相关关系
以上数据分析结果表明,用户的行为反馈与其实时CTR高度相关,不同的用户行为导致用户实时CTR发生不同变化。用户点击或者忽视哪些广告,点击广告的时间分布,驻留广告页时长以及所点击的广告类型等不同用户行为反馈对实时CTR的影响不尽相同。因此,只要能从线下历史数据中挖掘用户反馈与实时CTR变化的相关关系,对用户实时行为进行建模,基于线上所获取/跟踪得到的用户行为,实时反馈到在线广告系统,以此动态调整广告投放,就可有效提升线上广告点击率。
基于上述分析结果,本文提出了一种基于用户实时反馈的点击率预估算法,多维度量化分析用户行为特征,利用机器学习方法从大规模历史数据中学习用户多维度反馈与其实时CTR之间的相关关系,对用户行为进行建模,根据用户反馈动态调整广告投放,从而提升广告点击率预估精度。
2 模型训练
广告点击率预估是机器学习领域中经典的有监督二分类问题。为了评估用户实时反馈特征对于提升点击率预估精度的作用,本文分别了选取目前业界广泛使用的线性分类器和非线性分类器两类模型作为预测模型,即LR(Logistic Regression)和GBDT(Gradient Boosting Decision Tree)[9]。
2.1 损失函数
本文选用交叉熵作为预测模型的损失函数(Loss Function), 目标是最大化正例的似然估计。
损失函数的定义为:
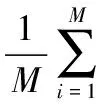
(1)
其中:M为训练样本的个数;pi为模型的输出概率;yi为样本的标签。
2.2 LR模型
LR模型支持大规模特征并行训练,模型简单稳定,结果可解释性强,目前广泛应用于点击率预估等问题[2]。LR点击率预估模型表达式为:
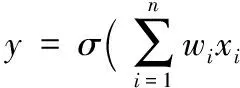
其中:wi为模型需要估计的参数;n为特征的维度;xi为样本的特征。所有特征的加权和通过sigmoid函数σ(x)映射到值域(0,1)内,即该模型输出概率y。σ(x)的表达式为:
σ(x)=1/(1+exp(-x))
因为LR模型为线性模型,所以可将wi视为特征xi对应的权重,即|wi|在模型中的相对大小反映了特征xi的重要性程度。
2.3 GBDT模型
GBDT模型[9]是解决回归和分类问题的经典模型,通常由若干决策树组合表示,具有拟合非线性特征的能力,广泛用于解决点击率预估等问题[10]。
GBDT模型的训练过程首先从一个简单的模型开始,通过不断迭代训练产生新的模型来减小已有模型和损失函数的残差(residual) 得到最终的模型。具体训练过程如算法1所示。
算法1 GBDT训练算法。
输入 训练集{(xi,yi)},i=1,2,…,M;损失函数L(y,F(x));算法迭代次数T。
输出 GBDT模型。
1)初始化模型为常数:
2)对于t=1,2,…,T:
2.1)计算残差:
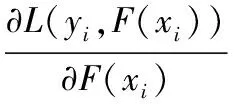
2.2)拟合残差r。即在数据集{(xi,rit)}i=1,2,…,M上训练,得到模型ht(x)。
2.3)求解γt[11]:
2.4)更新模型:
Ft(x)=Ft-1(x)+γtht(x)
3)输出Ft(x)。
算法1中的h(x)即为每轮迭代产生的新模型,一般用决策树表示。拟合决策树经典算法包括ID3(Iterative Dichotomiser 3)[12]、CART(Classification And Regression Tree)[13]等,算法的关键点在于如何选取特征值划分数据集。以ID3算法为例,该算法采用信息增益(Information Gain, IG) 作为指标来选取特征构成决策树的节点。从数据集中训练决策树的算法如算法2所示。
算法2 决策树训练算法ID3。
输入 数据集S;特征集合X={x1,x2,…,xn};算法迭代次数T。
输出 决策树模型。
1)从i=1,2,…,n, 在数据集S上计算IG(S,xi), 选取使得IG(S,xi)最大者的特征xi作为决策树的节点。其中,IG(S,xi)的计算公式为:
IG(S,x)=H(S)-H(S′)
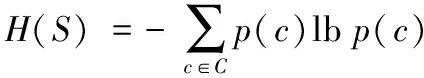
(2)
其中:S′表示根据特征xi划分的数据集的集合;H(S)表示数据集S中的熵;C表示数据集的类别集合;p(c)表示该类别所占的比例。在本文中,C={0,1},p(c)为数据中正例所占百分比,即CTR。
2)递归生成决策树子节点,即在数据集S′重复步骤1),选取特征xj(j≠i)作为特征xi的子节点。
3)输出决策树模型。
综合应用算法1和算法2,通过多次迭代训练即可得到GBDT预测模型。
从算法2中可以看出,信息增益IG(S,xi)值的大小反映了特征xi对数据集S的划分能力,即分类能力。特征越重要,IG(S,xi)值越大,分类能力越强。因此,IG是衡量特征xi相对于其他特征重要性程度的指标。
3 实验与结果分析
3.1 实验数据集
本文采用某广告公司的真实广告历史点击日志[7]作为训练和测试的数据集,样本包含有用户、广告主、域名、广告创意、广告展示和点击时间等字段信息。按照7∶3的比例,数据集被划分为训练集和测试集。
训练集和测试集的具体情况如表2所示。

表2 实验中训练和测试数据统计
3.2 特征设计
实验中设计的特征分为两类,即基本特征和用户实时反馈特征。其中,基本特征包含描述基本用户信息的相关特征和描述广告相关信息的特征,如用户编号、用户所在城市、用户上网代理(user Agent)信息、广告编号、广告展示位置和广告类型等。用户实时反馈特征主要根据第1章的分析结果设计而成,特征的设计细节及其描述如表3所示。

表3 用户实时反馈特征设计
实验设置中,对照模型只包含基本特征,测试模型包含全部特征。
3.3 评测指标
为了更好地理解用户实时反馈特征在点击率预估问题中的作用,本文从两个方面衡量用户实时反馈特征对于CTR预估精度的提升效果:一是从模型的预测性能出发,衡量实时反馈特征的有效程度;二是从特征与目标的相关性程度出发,衡量实时反馈特征的重要程度。
3.3.1 模型性能指标
本文采用AUC(Area Under the Curve)和RIG(Relative Information Gain)作为衡量预测模型性能的指标。
AUC是衡量模型分类能力的一种重要指标,在实际应用中被广泛采用[14]。AUC值是ROC(Receiver Operating Characteristic)曲线[15-16]的直观表示,即ROC曲线下面积。二值分类中,预测模型输出的p值大小表示样本属于正例的概率。对于分类问题,通常需要设定一个阈值t将样本判定为正例或者负例。AUC指标衡量了预测模型在任意阈值t下的分类能力。换句话说,AUC指标衡量了一个模型与其输出值大小无关的分类能力。AUC的取值为0~1,值越高,表示预测模型的分类性能越好。
RIG指标[14]是Log Loss函数的一种线性变换,衡量预测模型的输出p和期望CTR的接近程度。RIG值越高,表示预测模型在数据集上拟合得越好,输出的p值和实际CTR越接近。RIG的计算公式为:
RIG=1-L(y,p)/H(S)
其中:L(y,p)的计算见式(1);H(S)的计算见式(2)。
3.3.2 特征重要性指标
获取特征在预测模型中的重要性排名也称为特征重要性测试。一般而言,特征和目标相关性程度越高,则该特征越重要,预测模型的输出越依赖于该特征。
由2.2节可知,LR模型中的特征权重|wi|的相对大小反映特征xi在预测模型中的重要性。|wi|值越大,特征xi和目标y的相关性程度越高,对模型输出结果的影响越显著。因此,将LR模型中根据|wi|值由大到小排列,即可得到不同特征的重要性排名。
由2.3节可知,特征xi越重要,其划分数据集的能力越强,即IG(S,xi)的值越大。同理,IG(S,xi)的大小衡量了特征xi和目标y的相关性程度。在GBDT预测模型中,对所用特征关于IG从大到小排名,即可得到特征的重要性排名。
3.4 实验结果分析
表4列出了不同模型在测试集上的不同指标对比。从表4中可以看出,利用用户实时反馈信息的预测模型的各项指标显著优于没有用户实时反馈特征的对照模型。加了用户实时反馈信息的预测模型LR+User的AUC相对于对照模型LR,相对提升0.65%,RIG相对提升4.91%;预测模型GBDT+User相对于对照模型GBDT,AUC相对提升0.83%,RIG相对提升6.68%。显而易见,采用用户实时反馈信息的预测模型性能提升显著。
AUC和RIG两个指标的显著提升表明用户实时反馈特征不仅有利于提升预测模型的广告分类能力 (即点击和非点击两类),而且模型对于历史数据拟合得更好,模型的预估概率p和实际的CTR更加接近。

表4 不同模型的AUC和RIG指标
表5列出了用户实时反馈特征在LR和GBDT模型中的重要性排名。从表5可知,广告点击次数这一特征在LR和GBDT中的重要性排名分别为第二和第一,由此可见用户实时反馈特征对点击率模型的重要性。同时还可以看到,用户的实时反馈特征排名整体比较靠前,这说明相对于其他特征,用户实时反馈和用户的点击率相关程度更高,因此用户实时反馈特征对提升用户点击率预估精度至关重要。
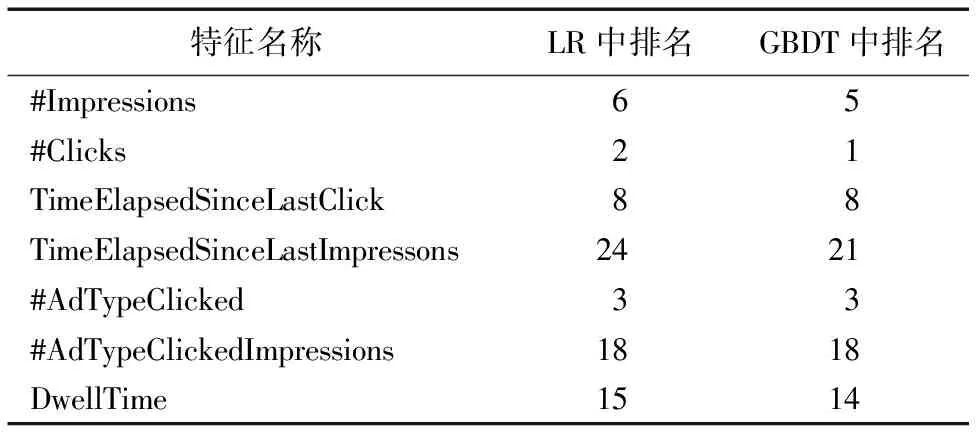
表5 用户反馈特征在LR和GBDT模型中的重要性排名
总体而言,用户实时反馈特征和用户点击率高度相关,无论从模型的最终预测效果还是从特征的重要性测试结果来看,实时反馈特征对于预测模型的点击率预估精度都有着不可忽视的影响。实验结果表明,对用户行为建模,然后根据用户反馈动态调整广告投放,可以显著提升点击率预估精度。
4 结语
在线广告的点击率预估问题一直以来都是机器学习领域中的热点难点,提高点击率预估精度对于广告平台、广告商和用户三方均有重要意义。本文从多个维度对用户实时反馈与用户实时CTR两者的关系进行了量化分析,提出了一种基于用户实时反馈的点击率预估算法。该算法对用户的实时行为特征进行建模,根据线上所跟踪和获取的用户反馈动态调整广告投放,从而提升模型点击率预估精度。基于真实数据集的实验验证了该算法的有效性,相比于对照模型,采用用户实时反馈特征的预测模型AUC指标相对提升0.83%,RIG指标相对提升4.91%。
References)
[1] 智颖. 2015全球广告预测报告[J]. 中国广告, 2015(3) : 118-119. (ZHI Y. 2015 global advertising forecast[J]. China Advertising, 2015(3): 118-119.)
[2] McMAHAN H B, HOLT G, SCULLEY D, et al. Ad click prediction: a view from the trenches[C]// KDD 2013: Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 1222-1230.
[3] HILLARD D, MANAVOGLU E, RAGHAVAN H, et al. The sum of its parts: reducing sparsity in click estimation with query segments[J]. Information Retrieval, 2011, 14(3): 315-36.
[4] 张志强, 周永, 谢晓芹, 等. 基于特征学习的广告点击率预估技术研究[J]. 计算机学报, 2016, 39(4) : 780-794. (ZHANG Z Q, ZHOU Y, XIE X Q, et al. Research on advertising click-through rate estimation based on feature learning[J]. Chinese Journal of Computers, 2016, 39(4): 780-794.)
[5] SHEN S, HU B, CHEN W, et al. Personalized click model through collaborative filtering[C]// WSDM 2012: Proceedings of the Fifth ACM International Conference on Web Search and Data Mining. New York: ACM, 2012: 323-332.
[6] 潘书敏, 颜娜, 谢瑾奎. 基于用户相似度和特征分化的广告点击率预测研究[J]. 计算机科学, 2017, 44(2) : 283-289. (PAN S M, YAN N, XIE J K. Study on advertising click-through rate prediction based on user similarity and feature differentiation[J]. Computer Science, 2017, 44(2): 283-289.)
[7] ZHANG W, YUAN S, WANG J, et al. Real-time bidding benchmarking with iPinYou dataset[EB/OL]. [2017- 01- 10]. https://arxiv.org/pdf/1407.7073.pdf.
[8] KIM Y, HASSAN A, WHITE R W, et al. Modeling dwell time to predict click-level satisfaction[C]// Proceedings of the 7th ACM International Conference on Web Search and Data Mining. New York: ACM, 2014: 193-202.
[9] FRIEDMAN J H. Stochastic gradient boosting[J]. Computational Statistics amp; Data Analysis, 2002, 38(4): 367-378.
[10] HE X, PAN J, JIN O, et al. Practical lessons from predicting clicks on ads at Facebook[C]// ADKDD 2014: Proceedings of the Eighth International Workshop on Data Mining for Online Advertising. New York: ACM, 2014: 1-9.
[12] QUINLAN J R. Induction of decision trees[J]. Machine Learning, 1986, 1(1): 81-106.
[13] BREIMAN L. Classification and Regression Trees[M]. Boca Raton, Florida, USA: CRC Press, 1984.
[14] YI J, CHEN Y, LI J, et al. Predictive model performance: offline and online evaluations[C]// KDD 2013: Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 7-14.
[15] SWETS J A. Measuring the accuracy of diagnostic systems[J]. Science, 1988, 240(4857): 1285.
[16] FAWCETT T. ROC graphs: notes and practical considerations for researchers[J]. Machine Learning, 2004, 31(1): 1-38.
Clickthroughratepredictionalgorithmbasedonuser’sreal-timefeedback
YANG Cheng*
(SchoolofNetworkandCommunicationEngineering,ChangzhouCollegeofInformationTechnology,ChangzhouJiangsu213164,China)
At present, most of the Click Through Rate (CTR) prediction algorithms for online advertising mainly focus on mining the correlation between users and advertisements from large-scale log data by using machine learning methods, but not considering the impact of user’s real-time feedback. After analyzing a lot of real world online advertising log data, it is found that the dynamic changes of CTR is highly correlated with previous feedback of user, which is that the different behaviors of users typically have different effects on real-time CTR. On the basis of the above analysis, an algorithm based on user’s real-time feedback was proposed. Firstly, the correlation between user’s feedback and real-time CTR were quantitatively analyzed on large scale of real world online advertising logs. Secondly, based on the analysis results, the user’s feedback was characterized and fed into machine learning model to model the user’s behavior. Finally, the online advertising impression was dynamically adjusted by user’s feedback, which improves the precision of CTR prediction. The experimental results on real world online advertising datasets show that the proposed algorithm improves the precision of CTR prediction significantly, compared with the contrast models, the metrics of Area Under the ROC Curve (AUC) and Relative Information Gain (RIG) are increased by 0.83% and 6.68%, respectively.
machine learning; computational advertising; Click Through Rate (CTR) prediction; personalization; real-time feedback
2017- 04- 17;
2017- 06- 08。
杨诚(1975—),男,江苏常州人,副教授,硕士,CCF会员,主要研究方向:机器学习、数据挖掘。
1001- 9081(2017)10- 2866- 05
10.11772/j.issn.1001- 9081.2017.10.2866
TP181
A
YANGCheng, born in 1975, M. S., associate professor. His research interests include machine learning, data mining.
猜你喜欢
矿山安全信息(2022年22期)2022-11-24 09:51:46
电子制作(2018年11期)2018-08-04 03:25:38
华东师范大学学报(自然科学版)(2018年3期)2018-05-14 10:27:18
测绘科学与工程(2016年5期)2016-04-17 06:51:15
当代化工研究(2016年2期)2016-03-20 16:21:21
海峡姐妹(2015年8期)2015-02-27 15:12:30
电子设计工程(2015年3期)2015-02-27 12:03:45
河南科技(2014年14期)2014-02-27 14:11:53
兴趣英语(2013年8期)2013-11-13 06:54:02
海外英语(2013年3期)2013-08-27 09:37:01
