
大规模多维网络数据分析框架的研究与实现*
2017-12-13 05:44:34王泽奥吴心宇张子兴
计算机与生活 2017年12期
王泽奥,吴 斌,吴心宇,张子兴
北京邮电大学 计算机学院,北京 100080
大规模多维网络数据分析框架的研究与实现*
王泽奥+,吴 斌,吴心宇,张子兴
北京邮电大学 计算机学院,北京 100080
随着互联网的快速发展和计算机应用的不断增加,大量的图数据特别是社会网络数据不断生成。多维信息网络已经成为表示这些图数据的通用方式。但是在多维信息网络中,节点的类型多种多样,节点的属性也不尽相同,如何对多维信息网络数据进行多角度多粒度的分析,挖掘其中的隐藏信息,成为人们关注的焦点。图联机分析处理技术(graph online analytical processing,GraphOLAP)可以对图数据进行快速的联机分析以及查询操作。借助于GraphOLAP的现有成果,针对多维信息网络的特点,提出了新的数据立方体框架。引入主节点的概念来指导元路径的生成,通过元路径指导网络的上卷下钻,提出属性转化和同质转化来丰富OLAP操作。最后讨论了优化的物化策略,使用并行计算框架Spark来实现算法,通过多个数据集验证了框架的有效性和高效性。
GraphOLAP;数据立方体;元路径;Spark
1 背景介绍
近年来随着社交网络、生物网络以及化合物网络等领域的不断发展,出现了大量的多属性图数据。研究如何对图数据进行多层次多角度的分析有着重要的意义。这些网络如DBLP合作网络、社交网络FACEBOOK、IMDB电影合作网络等,其中蕴含大量的实体信息以及实体之间的关联信息,深层次挖掘此类信息是非常有必要的。实体类型和联系的多元化是分析和挖掘此类信息网络的难点。联机分析处理技术(online analytical processing,OLAP)能够提供用户从不同维度、不同粒度观察对象的视图,是数据仓库和数据挖掘领域的核心技术之一,近年来得到了广泛的研究应用。但是OLAP基于的传统数据立方体是同一种实体类型的多维数据模型,不能有效契合图数据分析的需求。
图联机分析处理技术(graph online analytical processing,GraphOLAP)结合了复杂网络分析与联机分析处理技术,将数据仓库中专门用于分析多维数据的联机分析处理技术引入到复杂网络分析当中,用来解决复杂网络中的多维度多角度分析问题,从而展示不同层次和不同粒度上的网络结构和特性。
在传统信息模型中,信息存储为事实表和维度表。事实表中包含所有实体及其之间的关系,维度表中包含数据的多维属性。通过立方体来指导OLAP的维度操作,通过聚集函数来描述不同维度聚集时的聚集方式,通过度量来描述不同维度下的分析结果。对于多属性图数据来说,数据与数据之间存在关联,这些关联蕴含着许多隐藏信息有待挖掘与分析。但是传统的数据是记录的形式,数据之间没有关联,利用传统OLAP分析会丢掉这些关联关系,不能对图进行充分有效的挖掘与分析。
对于多属性图的分析,除了传统图分析方法如最短路径、中介行、模式匹配等,采用OLAP查询来进行信息发现和决策制定也有很大的发挥空间。这里根据用户可能感兴趣的点举几个简单的例子:
查询1获取点属性或边属性信息。这些查询往往能够通过对点属性或边属性的简单查询得到。如“用户群体中有多少中国人”或者是“电影都有哪些类型”。
查询2获取点和边的属性组合之后的聚集信息,这些查询需要将实体节点按照某一维度进行聚集操作之后得到结果。如“有多少男人喜欢看喜剧片”“演员国籍与电影类别之间的网络结构是什么样子的”。
查询3查询特定实体关系的网络属性信息。这些查询需要合并实体间的关系,形成新的实体关系以及新网络。如“男人喜欢的电影是由哪个国家的演员参演的”。
对于查询1,可以直接在节点表中进行查询,得到节点的维度属性。查询2需要将原图中的一些节点按照需要进行聚集操作得到新的聚集网络。查询3关注的是不同实体间的相互关系,根据异质网络元路径聚集进一步得到新的实体关系。
传统的基于RDB(relation data base)的OLAP系统已经难以满足这些查询需求,除了查询1中的实体类型查询可以基于节点的维度表进行查询,其他查询操作都要经过多表连接操作。当数据量很大时,数据库的多表连接经常会成为数据库计算的瓶颈。而且传统的数据立方体也不能很好地表现图的结构以及图的复杂网络属性。因此设计适合大规模多维信息网络的立方体,建立多维信息网络的OLAP操作是十分有必要的。
随着社交网络的兴起,网络数据的规模也在不断增加。传统的集中式计算已经不能满足需求,引入并行化计算框架是非常有意义的。目前,常用的并行计算框架有Hadoop、Spark,并行图计算框架有HAMA、GraphX、GraphLab等。这些并行图计算框架对于图类型数据的迭代操作有很好的优化,能有效地计算图的相关结构特征,如pagerank、shortest path、bipartite matching、semi-clustering等。但是对于多维信息网络的OLAP操作会导致节点数量、属性以及节点间的联系发生改变,这种改变会进一步导致网络结构改变以及网络类型改变。现有的图计算框架更适用于图遍历的迭代操作和图分隔的优化操作,对于图中节点类型以及拓扑结构发生重大变化的支持并不是很好。传统的并行计算框架Hadoop和Spark虽然不是专门为了图计算设计,但是通过建立合适的图立方体模型,也可以进行图的挖掘分析[1]。因此选用Spark来完成对于立方体的相关操作。
在这些需求的引导下,本文提出了一种新的数据立方体模型,引入了主节点的概念,融入异质网络特性,并基于新的数据立方体模型赋予传统的上卷下钻新的含义。针对新的模型,设计了更多新的OLAP操作,为丰富查询提供了模型上的支持。为了挖掘图中的隐藏信息,设计了带多维层次聚类算法来进行群体划分和特征分析。为了提高查询效率,设计了优化的物化策略。模型是用并行化计算框架Spark完成的,支持大规模多维信息网络的分析处理。通过多个真实网络数据集实验,验证了模型的有效性和高效性。
本文的贡献如下:
(1)定义了新的数据立方体模型StarGraphCube,将主节点的概念引入进来指导网络元路径的生成,由网络元路径指导OLAP操作的进行。并且根据立方体模型,丰富了GraphOLAP的操作,使得网络分析更加多样性。
(2)针对新的模型,提出了优化的物化策略,使得维度操作的效率更高。
(3)使用并行计算框架实现,通过对大规模真实数据的实验,验证了模型对大规模数据能够进行有效并且高效的分析。
本文组织结构如下:第2章定义了StarGraph-Cube模型以及一些新的OLAP分析操作;第3章讨论了优化的物化策略;第4章是模型在大规模数据集上的实验;第5章介绍相关工作;第6章总结全文。
2 星型数据模型
和传统的OLAP立方体模型一样,GraphOLAP需要通过数据立方体模型建立图和数据仓库之间的关联[2]。本文建立StarGraphCube模型,引入主节点的概念指导网络元路径的生成,能够分析挖掘更多的潜在信息。
首先定义一些概念来清晰地描述本文的模型。由于现实中很多网络可以被抽象成多维异质信息网络,可以定义如下。
定义1(多维异质信息网络)一个多维异质信息网络N表示为N=(V,E,T,A),其中V表示节点的集合;E⊆V×V表示边集合;T={T1,T2,…,Tn}表示节点的类型集合,∀u∈V,由于T(u)=Ti,1≤i≤n,即每个节点,只能取值一种节点类型,当n>1时,网络为异质网络;A={A1,A2,…,An}表示不同类型节点的维度属性集合,与节点类型对应,每一种节点类型Ti有相应的维度属性集合Ai=(Ai1,Ai2,…,Aim)。对于∀v∈V,T(v)=Tj,1≤j≤n,都有一个维度元组A(v)=(Aj1(v),Aj2(v),…,Ajm(v)),其中Ajk(v)表示节点v上的第k个属性,即节点的第k维,1≤k≤m。
定义2(二元关系元路径)对于多维异质信息网络模型N=(V,E,T,A),V是节点集合,E是节点的关系集合,T为节点的类型集合,A为节点的维度属性集合。二元关系元路径可表示为P(T1,Tn,list)=T1→T2→…→Ti→…→Tn,其中T1表示二元关系元路径的起点,Tn表示二元关系元路径的终点,Ti表示元路径中第i个节点类型,list表示二元关系路径起点与终点间的路径节点列表,路径长度为|list|+1;Ti→Ti+1是异质网络Schema的一条连通路径。当关系元路径确定时,可以用P(T1,Tn)来代表P(T1,Tn,list)。为了简化问题,不允许除了起点和终点的路径上存在环。
关系元路径代表了不同类型节点之间的关系连接。两个不同类型的节点实体的关系路径可能会存在多条,定义二元关系元路径集合来表示这些起点和终点相同的元路径集合。
定义3(二元关系元路径集合)关系元路径的定义基于异质信息网络模型N=(V,E,T,A),V是节点集合,E是节点的关系集合,T为节点的类型集合,A为节点的维度属性集合。对于给定的两个实体T1与Tn,两个实体间可能存在多条可达路径(规定除去起点与终点的路径中不存在环),这些路径的集合为二元关系元路径集合,表示为Pset(T1,Tn)={P(T1,Tn,list1),P(T1,Tn,list2),…,P(T1,Tn,listn)}。
定义4(n元关系元路径)基于异质信息网络模型N=(V,E,T,A),V是节点集合,E是节点的关系集合,T为节点的类型集合,A为节点的维度属性集合。n元关系元路径可表示为P(T1,T2,…,Ti,…,Tn,list)=T1→T2→…→Ti→…→Tn,其中Ti表示n元中的第i元节点类型,list记录了n元关系路径除去起点T1与终点Tn的路径序列。最终的n元关系元路径是异质网络Schema的一条路径,并且该路径依次经过T1,T2,…,Ti,…,Tn。同样,规定相邻类型之间的路径不存在环,即Ti→…→Ti+1的路径中不存在环。当n=2时,n元关系元路径为二元关系元路径。
定义5(n元关系元路径集合)基于异质信息网络模型N=(V,E,T,A)与n元关系元路径的定义,对于给定的n个实体的序列,在异质网络Schema中可能会存在多条通过这些类型节点的n元关系元路径,所有路径形成的集合为n元关系元路径集合,表示为Pset(T1,T2,…,Tn)={P(T1,T2,…,Tn,list1),P(T1,T2,…,Tn,list2),…,P(T1,T2,…,Tn,listn)}。n=2时,n元关系元路径集合为二元关系元路径集合。
定义6(实体类型主节点)给定一个异质信息网络N=(V,E,T,A),其中T={Ti|i=1,2,…,n}。针对每个节点类型Ti,引入主节点VTi={Vi|T=Ti}代表同类型的所有节点。用R表示所有主节点的集合,V′=V∪R,E′=E,A′=A,则异质信息网络可以表示为N′=(V′,E′,A′)。
引入主节点之后可以指导网络元路径的生成。对于n元关系元路径P(T1,T2,…,Ti,…,Tn,list)=T1→T2→…→Ti→…→Tn的生成,可以分为两步进行:第一步,用主节点来构建元路径;第二步在每个主节点中VTi=V1→V2→…→Vi→…→Vn。
定义7(二元关系元路径聚集网络)给定一个异质信息网络N=(V,E,T,A)以及一条二元关系元路径P(T1,T2,…,Ti,…,Tn,list)=T1→T2→ … →Ti→ … →Tn。在二元关系元路径的指导下,将T1→T2→…→Ti→…→Tn转换为;再合并为,形成聚集网络N′=(V′,E′,T′,A′),其中T′={T1,Tn},A′={A1,An},V′是类型为T1、Tn的节点集合,E′是合并形成的节点的边集合。
定义8(n元关系元路径聚集网络)给定一个异质信息网络N=(V,E,T,A)以及一条n元关系元路径P(T1,T2,…,Ti,…,Tn,list),在n元关系元路径的作用下,与二元关系元路径网络的聚集方式相同,将网络中不同节点的类型按照关系元路径P(T1,T2,…,Ti,…,Tn,list)合并成聚集网络N′=(V′,E′,T′,A′),其中T′={T1,T2,…,Tn},A′={A1,A2,…,An},V′是类型为T1,T2,…,Tn的节点集合,E′是合并形成的节点的边集合。
对于由原始网络可以得到的n元关系元路径聚集网络Nn与n+1元关系元路径聚集网络Nn+1,由Nn+1不一定能够得到n元关系元路径聚集网络Nn。
本文提出StarGraphCube模型,能够对多维异质信息网络进行更加丰富的OLAP操作。
定义9(StarGraphCube)给定一个多维异质信息网络N=(V,E,T,A),网络中一共有n种不同类型的节点,对于第Ti种类型的节点共有|Ai|种不同的维度属性,通过这些不同类型节点以及不同维度进行所有可能的聚集组合得到。将聚合操作分成两步:第一步通过主节点构建n元关系元路径P(T1,T2,…,Ti,…,Tn,list),得到n元关系元路径聚集网络;第二步通过在主节点内进行某一维度的聚集,选定特定的维度集合A′,得到最终的聚集网络。通过对聚集网络进行查询操作,能够便于OLAP操作,对于进一步处理有着重要的意义。
StarGraphCube首先根据关系元路径的指导在主节点构成实体立方体,立方体的每个方体是对应的n元关系元路径合集,每一个实体方体可以产生2|T|-1个聚集方体,每个方体对应的n元关系元路径集合包含的关系元路径不确定,因此聚集网络的数量不能确定。对于聚集得到的实体方体,在n元关系元路径的指导下进一步聚集,有n种节点类型T1,T2,…,Tn,对应维度A1,A2,…,An一共有个聚集立方体。
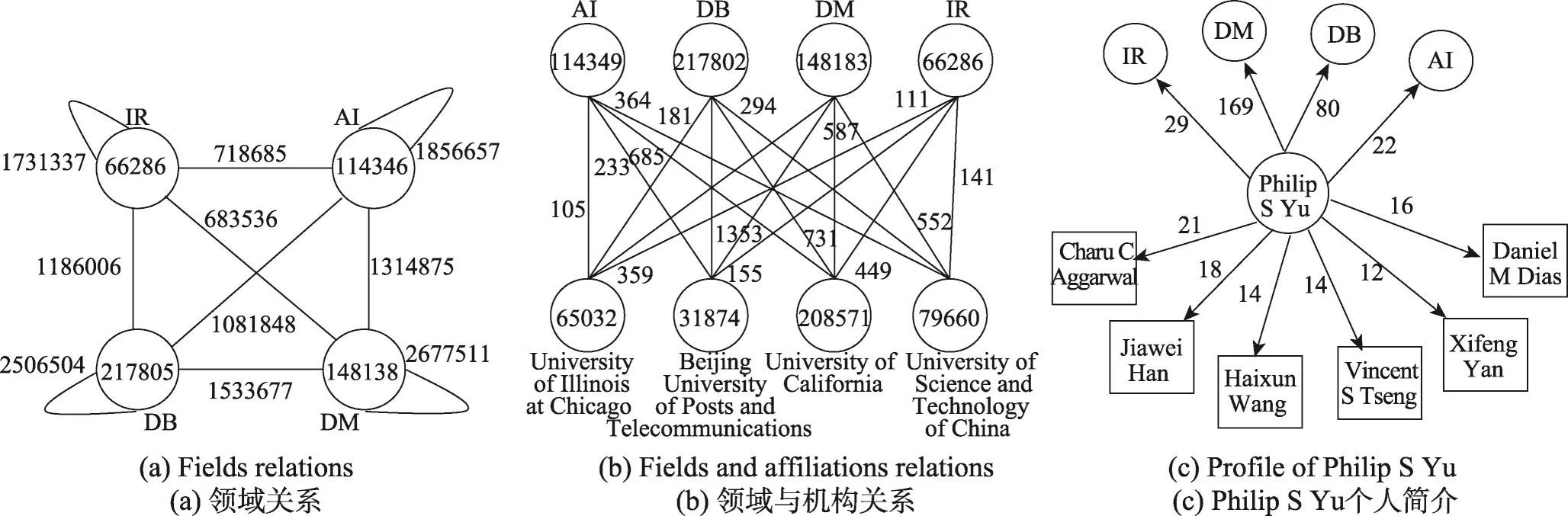
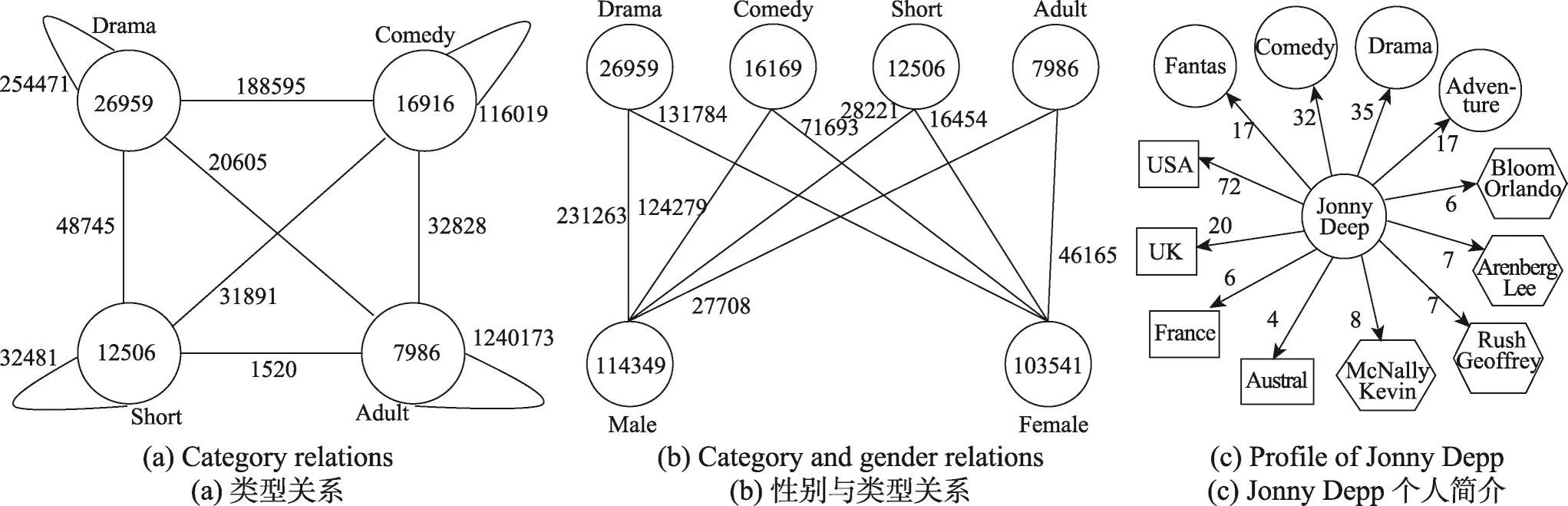
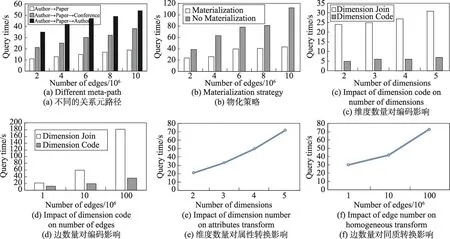
图1(a)展示了异质网络的架构。一共有3种实体A、B、C。A对应于User,B对应于Movie,C对应于Actor。A有1个维度属性,B有两个维度属性,C有两个维度属性。该多维异质网络形成的实体关系体模型如图1(b)所示,共可以形成23-1=7个聚集方体,其中<*,*,*>为特殊方体,每个方体中可能包括多条元路径,如方体 在StarGraphCube中实体立方体通过关系元路径引导网络聚集,可以满足查询3的需求;实体立方体通过关系元路径引导维度上的聚集操作,可以满足查询2的需求,实体立方体结合维度聚集操作,可以满足查询1、查询2和查询3的复合查询需求。如在第1章提到的“有多少男人喜欢看喜剧片”,首先选取 在传统OLAP中,上卷与下钻是最重要的两个操作。在StarGraphCube中,上卷下钻操作主要在实体立方体上进行。上卷意味着从底层的n元关系元路径聚集得到相应的n-m元关系元路径聚集网络(0<m<n),对应的逆向操作为下钻操作。 同质转换操作:给定一个多维异质信息网络N=(V,E,T,A),选定节点类型集合T,对其中某一个节点类型Ti,若在实体立方体中类型为Ti的节点Vi、Vj与同一个节点存在边的关系,则在节点Vi与Vj之间构建同质的边。 同质转换操作给人们发现同质节点之间的隐藏信息做铺垫。在多维异质信息网络中,实体的类型多种多样,同实体间的关系主要通过其他类型实体节点进行建立。通过同质转换操作,发掘异质网络中的同质网络信息,进行群体划分和分析。 属性转换:给定一个多维异质信息网络N=(V,E,T,A),选定某一类型节点集合Tt,对每一个节点类型Tti与维度集合Ai中的m个维度属性{Aij,1≤j≤m},将这m个维度属性值变换成节点加入节点集合形成新的节点集合V′与类型集合T′。对于新节点Aij与Aij′,若属于同一节点或者隶属的节点之间存在边,则建立两者之间的边关系并加入边集形成E′。最终得到属性转换网络N′=(V′,E′,T′,A)。 同质转换操作的算法如下: 算法1同质转换 属性转换操作的算法如下: 算法2属性转化 在实体立方体上的上卷下钻操作需要根据关系元路径重组网络节点,计算的复杂度很高。对于大规模网络这些操作是十分耗时的,因此提出了下面的一些优化算法。 二元关系元路径聚集操作将网络中的多个实体属性在二元关系元路径P(T1,Tn,list)=T1→T2→…→Ti→…→Tn的指导下,形成以起点和终点类型构成的网络。可以将相邻的节点做join操作,逐步合并中间路径节点,最终得到T1→Tn的网络。join操作的复杂度和边的大小与计算方法有关系,若原始网络有l条边,join的复杂度为O(α(l))。二元关系元路径长度为|list|+1,则最终的复杂度为O(α(l)×(|list|+1))。二元关系元路径的长度增加,计算复杂度也会逐渐增加,同时起点与终点的关联性越弱,得到的网络可分析性越弱。因此一般聚集网络的二元关系元路径不会太长,否则得到的图就没有分析的意义。二元关系元路径的聚集网络的计算可以表示N′=agg2meta(N,T1,Tn,list),其中N表示多维信息网络,T1表示起点类型,Tn表示终点类型,list表示二元关系元路径序列。N′为二元关系元路径聚集网络,生成算法见算法1。遍历的循环可以使用Spark的map函数生成对应边的RDD,利用RDD的join函数对算法1进行并行操作。 对于n元关系元路径的聚集网络计算,根据定义可知n元关系元路径可以由n-1个二元关系元路径拼接而成,故二元关系元路径指导的网络聚集操作可以转换成n-1个二元关系元路径网络指导的聚集操作,最后将n-1个聚集网络合并。 立方体的物化策略一共有3种:不物化、部分物化和完全物化。不物化策略是指在每一次的计算过程中,都直接生成所需网络再计算结果。这种策略不需要耗费很多内存空间,但是当数据量很大时,每一步的计算时间会显著增加,不适合大数据量的操作。完全物化策略是指在计算初期,就将数据立方体的所有网络计算出来并保存。这种方法在数据立方体的维度较多的情况下,计算初期需要花费大量时间并且占用大量的内存。部分物化策略是在计算初期,按照一定方案将数据立方体的部分网络计算出来并保存。这种方式兼顾了时间和空间效率,因此本文选择这种物化策略。 对于实体立方体,由于关系元路径的多样性,每一个方体可能会产生多个聚集网络,整个立方体的聚集网络不容易计算出来。而由于n元关系元路径可以利用n-1个对应的二元关系元路径聚集网络得到,对于n元关系元路径产生的聚集网络,是路径中的一点,则二元关系元路径的计算可以通过将P(T1,Ti,list)和P(Ti,Tn,list)的聚集网络连接得到。因此物化策略选择优先物化二元关系元路径聚集网络,初始物化所有二元关系元路径集合的最短元路径聚集网络。若一共有n种类型的实体,则物化产生n(n-1)/2个聚集网络。 另外在物化过程中,如果要计算二元关系元路径聚集网络,可以先检查是否已经物化过。如果之前已经物化过,则可以直接利用。 传统的OLAP查询中,事实表往往比维度表大很多,维度表所占的事实表比例基本都在1%左右,一般不会超过3%。数据规模越大,维度表所占比例越低。而且数据仓库查询具有高输入低输出的特点。在SSB标准测试集中,任何一个查询输出记录都在1 000条以下[3]。直接将维度表进行维度编码压缩,融入事实表中,能够大大减少事实表与维度表的连接操作,而且输出结果数据量很小,解码时间也很短,运行效率会大大提升。 对于节点的维度进行编码并存入边表中,这样在进行维度操作时可以只进行边表的计算,而不需要边表与维度表的连接操作。使用位运算与二进制,对节点名称、节点类型、节点维度一次进行等位编码,最终形成节点存入边表中,编码形式为节点类型编码+节点名称编码+节点维度编码。其中节点类型编码位数为,T为节点类型,|T|+1表示维度上卷下钻形成的节点。节点编码算法如下。 (1)节点编码 由定义可得编码实例:User U3 Male China:000 010 0 01。通过前3位得到类型,类型000表示User;接下来3位表示用户编码,010表示用户名称U3;接下来1位表示用户性别,0代表男性;最后2位表示用户国家,01表示USA。 (2)维度上卷编码 例如图中的movie Category聚集形成Comedy节点,首先是类型编码100,之后是上卷的类型编码,Movie为001,上卷维度数量为1,编码为1。上卷维度在movie类型中是第0个编号,编码为0,取值Comedy编码为01,如果后面还有编码则表示下个类型的上卷维度。最终Comedy编码为1000011001。 本文将在4个节点的本地集群上进行模型和算法的实验。每个节点由2个E5-2620 6(12)@2.0 GHz CPU,64 GB内存和500 GB SATA disks构成。实验的环境主要是基于Hadoop 2.6.0和Spark 1.5.1。 本文将在真实数据集和模拟数据集上进行实验验证。其中真实数据集为MAG(Microsoft academic graph)和IMDB数据集,模拟数据集为使用模拟算法生成的数据集。真实数据集主要用来验证模型的有效性,而模拟数据用来验证模型的高效性。 该数据集是由微软在2016年发布,主要包含作者、论文和会议的关系,其中不同的实体有不同的维度属性。数据集中包含114 698 044个作者,126 909 021篇论文,1 283个会议。在有效性实验中,重点关注了4个领域:database(DB)、data mining(DM)、artificial intelligence(AI)和information retrieval(IR)。 实验中,通过建立StarGraphCube模型以及关系元路径的聚集和维度的聚集进行作者合作网络的分析。 首先以二元关系元路径P(Author,Author)=Author→Paper→Author聚集得到作者合作网络。选定Philip S Yu作为研究对象,可以得到与他合作最紧密的作者,在field维度上聚集得到选定的4个领域之间的关系。从图2(a)中可以知道,DB领域作者与DM领域作者合作的频率比和AI、IR领域作者合作的频率更高,而且DB领域的作者更倾向于跟自己领域的作者合作。IR领域的作者倾向于跟非自己领域的作者合作,跟DB领域作者合作的频率比AI、DM的频率更高。对P(Author,Paper)=Author→Paper聚集网络进行field维度上卷,可以得到作者与field的网络。从图2(c)中可以看出,Philip S Yu的主要领域是datamining,并且和CharuCAggarwal的合作最为紧密。 该数据集从IMDB的官网爬取,主要包含用户、电影和演员之间的关系,其中不同的实体有不同的维度属性。数据集中包含Movies:129 918,Actors:832 087。在有效性实验中,主要选取了4种电影类型Drama、Comedy、Short和Adult进行研究。 在本次实验中,重点关注了Drama、Comedy、Short、Adult这4种类型的电影。通过建立Star Graph-Cube模型以及关系元路径的聚集与维度的聚集进行科研网络的分析。 首先以二元关系元路径P(Movie,Movie)=Movie→Actor→Movie聚集得到电影的关系网络图。将Movie进行类型维度的上卷,聚集函数采用count(*),得到4个类型电影的关系如图3(a)。 同时也可以对单点进行分析。通过二元关系元路径P(Actor,Movie)=Actor→Movie的聚集网络进行Movie的类型维度上卷,可以得到Actor和电影类型的关系网络。通过电影的发行国家维度上卷得到Actor和电影发行国家之间的关系。通过二元关系元路径P(Actor,Actor)=Actor→Movie→Actor聚集得到演员合作关系网络,可以知道与演员合作最密切的其他演员。如图3(c)中Jonny Depp经常出演的电影类型是Comedy和Drama,大多数电影都是由美国公司发行的。 在该实验中使用MAG数据进行实验,将MAG数据集分为5份,每一份的大小分别为2×106,4×106,6×106,8×106,10×106。 Fig.2 Experiments on MAG datasets图2 MAG实验结果 Fig.3 Experiments on IMDB datasets图3 IMDB实验结果 首先对不同的二元关系元路径聚集网络进行实验。选取P1(Author,Paper)=Author→Paper,P2(Author,Conference)=Author→Paper→Conference,P2(Author,Author)=Author→Paper→Author。实验结果如图4(a)所示。由P1(Author,Paper)与P2(Author,Conference)的比较可以看出,随着路径的增加,需要的时间也会增加。由P2(Author,Conference)和P3(Author,Author)的比较可以知道,P2产生的作者和会议的网络,依赖关系紧密,产生的网络规模较小。而P3产生的是作者合作网络,同一篇文章的合作者较多,产生的网络规模较大。因此相同长度元路径的聚集网络,需要的时间也会不同。由图可知,随着边数的增加,消耗的时间是线性变化的,即O(α(l))=O(l),最终的时间复杂度是O(l×|list|+1)。 然后对物化策略进行实验。选取关系元路径P(Author,Author)=Author→Paper→Conference→Paper→Author进行聚集操作。物化Author→Paper→Conference路径的聚集网络,则不物化的聚集操作需要进行4次join操作。对于物化后,则只需要进行1次join操作,实验结果如图4(b)。通过物化可以减少重复的聚集计算,提高运行效率。 该实验使用模拟的多维网络数据。首先验证维度属性编码对性能的提升,从维度数目和网络规模两个角度出发进行实验。从维度数目角度生成维度数目为3、5、7、9的网络,分别采用点边join方式与本文提出维度编码的方式进行维度roll up,得到的结果如图4(c)所示。从图中可知,维度编码能够大大提高网络聚集的效率,随着网络维度的增加,点边join方法与维度编码方法性能变化相似,消耗的时间都有所增加。这是由于维度增加,需要的存储空间更多导致的。从网络规模的角度生成了边数分别为1×106,10×106和100×106的多维网络,并分别进行了聚集操作,得到的结果如图4(d)所示。可以看出,随着网络规模的增加,维度编码对效率的提升也不断增加,维度编码的方式也更加有优势。通过维度编码能够大大提高对大规模网络的分析性能。 然后,研究了属性转换操作。图4(e)呈现了属性转换的维度数量与时间的关系。可以看出,随着属性转换的维度数量的增加,消耗的时间有加速上升的趋势。这是因为属性转换生成的网络以维度属性为节点,随着属性转换成维度,生成的网络规模呈非线性增加的规律。 接着,研究了同质转换操作,图4(f)呈现了同质转换的边数量与时间的关系。可以看出,随着同质转换的边数量呈指数增长,消耗的时间也在不断增加。这是因为随着边数量的增加,同一个节点的邻居数量也在不断增加,建立同类型节点间的关系概率也在不断增加。 Fig.4 Efficiency experiment results图4 高效性验证 传统OLAP的研究起步较早,技术规范相对比较成熟,对于相关领域的应用也比较深入。但是对于图数据的GraphOLAP研究尚且处于起步阶段。 最开始吴巍[4]提出了Link OLAP的概念,通过将面向实体的分析扩展到面向连接的分析,结合复杂网络中的网络可视化技术,将OLAP技术应用到面向连接的分析,突破了以往传统OLAP系统中单调的二维表格表现形式,OLAP的研究也逐渐转向关联的属性度量和图。 Chen等人[5]首次正式提出了GraphOLAP的概念,并且定义了信息维、拓扑维以及在这些维度上面的上卷下钻切块切片等操作,第一次较为系统地提出了GraphOLAP的概念,但是对于整个GraphOLAP的系统框架没有进行概述。 李川等人[6]设计了一种适合GraphOLAP的数据仓库模型——双星模型,提出了信息维聚集算法和拓扑维聚集算法,并将理论的GraphOLAP进行了实现,但是使用的功能场景相对单一。 Zhao等人[7]针对数据仓库和多维网络分析的Graph Cube模型,将传统OLAP中立方体的概念与图融合,并利用传统OLAP的概念,将方体查询引入到图数据分析上,提出了crossboid查询,使得图数据也可以像表数据进行复杂的查询。除此之外还实现了物化操作,将图数据对应到传统数据仓库以及OLAP操作,重点实现了OLAP多维分析的查询功能,使得传统的数据仓库以及OLAP的功能得到拓展。 Yin等人[8]提出了HMGraph OLAP模型,引入了实体维的概念,支持异质网络的分析,并且加入了旋转和拉伸操作,在物化方面也采用相应的策略。 Denis等人[9]将GraphOLAP的操作算法用并行框架实现,并与传统的集中式算法进行了对比,对大规模数据有着较好的效果。 Wang等人[10]利用Hadoop实现了Pagrol并行图分析系统,并且改进了图立方体模型,加入了边维度属性的上卷下钻,通过一些优化操作使得系统有效高效地运行。 Wang等人[11]针对异质网络分析能力不足的问题,引入了关系元路径的概念,设计了TSMH Graph Cube模型,并且扩展了上卷下钻的语义,给出了优化的物化策略,引入了并行计算框架来进行大数据处理。 除此之外,Hannachi[12]、Weiler[13]、Liu等人[14]也提出了针对社交网络的立方体模型,Qu[15]、Jakawat等人[16]对文献数据以及知识网络实现了GraphOLAP的模型系统,Sun[17]、Shi等人[18]将数据库和内链接的数据视为异质信息网络,并研究如何利用实体的语义信息和网络中的内链接,Junghanns等人[19]将Hadoop引入到OLAP中以处理大规模的图数据,Beheshti等人[20]扩展了应用场景以便于能够对RDF数据进行处理。Cuzzocrea等人[21]研究了如何将云计算应用到大数据上以处理大规模的图数据。 本文针对现有GraphOLAP对异质网络分析能力不足的问题,引入关系元路径的概念,提出了主节点引导元路径聚集,并且设计了星型数据模型以便于在异质网络中引入关系元路径,在此基础上提出了同质转换操作和属性转换操作以丰富模型操作。针对模型提出了优先物化二元关系元路径的物化策略和维度聚集时的维度编码算法来进行join操作的优化。最后引入了Spark并行计算框架,使得模型处理大规模的图数据的能力大大加强。通过真实数据与模拟数据的实验,验证了本文模型框架的有效性与高效性。 [1]Cohen J.Graph twiddling in a MapReduce world[J].Computing in Science&Engineering,2009,11(4):29-41. [2]Li Chuan,Yu P S,Zhao Lei,et al.Infonetolaper:integrating InfoNetWarehouse and InfoNetCube with InfoNetOLAP[J].Proceedings of the VLDB Endowment,2011,4(12):1422-1425. [3]Wang Huiju,Qin Xiongpai,Wang Shan,et al.Scalable OLAP queries processing towards large cluster[J].Chinese Journal of Computers,2015,38(1):45-58. [4]Wu Wei.Complex network virtualization and link OLAP[D].Beijing:Beijing University of Posts and Telecommunications,2007. [5]Chen Chen,Yan Xifeng,Zhu Feida,et al.Graph OLAP:towards online analytical processing on graphs[C]//Proceedings of the 8th International Conference on Data Mining,Pisa,Italy,Dec 15-19,2008.Washington:IEEE Computer Society,2008:103-112. [6]Li Chuan,Zhao Lei,Tang Changjie,et al.Modeling,design and implementation of Graph OLAPing[J].Journal of Software,2011,22(2):258-268. [7]Zhao Peixiang,Li Xiaolei,Xin Dong,et al.Graph Cube:on warehousing and OLAP multidimensional networks[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data,Athens,Greece,Jun 12-16,2011.New York:ACM,2011:853-864. [8]Yin Mu,Wu Bin,Zeng Zengfeng.HMGraph OLAP:a novel framework for multi-dimensional heterogeneous network analysis[C]//Proceedings of the 15th International Workshop on Data Warehousing and OLAP,Maui,USA,Nov 2,2012.New York:ACM,2012:137-144. [9]Denis B,Ghrab A,Skhiri S.A distributed approach for graphoriented multidimensional analysis[C]//Proceedings of the 2013 International Conference on Big Data,Santa Clara,USA,Oct 6-9,2013.Piscataway,USA:IEEE,2013:9-16. [10]Wang Zhengkui,Fan Qi,Wang Huiju,et al.Pagrol:parallel graph OLAP over large-scale attributed graphs[C]//Proceedings of the 30th International Conference on Data Engineering,Chicago,USA,Mar 31-Apr 4,2014.Washington:IEEE Computer Society,2014:496-507. [11]Wang Pengsen,Wu Bin,Wang Bai.TSMH Graph Cube:a novel framework for large scale multi-dimensional network analysis[C]//Proceedings of the 2015 International Conference on Data Science and Advanced Analytics,Paris,France,Oct 19-21,2015.Piscataway,USA:IEEE,2015:1-10. [12]Hannachi L,Benblidia N,Bentayeb F,et al.Social microblogging cube[C]//Proceedings of the 16th International Workshop on Data Warehousing and OLAP,San Francisco,USA,Oct 28,2013.New York:ACM,2013:19-26. [13]Rehman N U,Weiler A,Scholl M H.OLAPing social media:the case of Twitter[C]//Proceedings of the 2013 International Conference on Advances in Social Networks Analysis and Mining,Niagara,Canada,Aug 25-29,2013.New York:ACM,2013:1139-1146. [14]Liu Xiong,Tang Kaizhi,Hancock J,et al.A text cube approach to human,social and cultural behavior in the Twitter stream[C]//LNCS 7812:Proceedings of the 6th International Conference on Social Computing,Behavioral-Cultural Modeling,and Prediction,Washington,Apr 2-5,2013.Berlin,Heidel-berg:Springer,2013:321-330. [15]Qu Qiang,Zhu Feida,Yan Xifeng,et al.Efficient topological OLAP on information networks[C]//LNCS 6587:Proceedings of the 16th International Conference on Database Systems for Advanced Applications,Hong Kong,China,Apr 22-25,2011.Berlin,Heidelberg:Springer,2011:389-403. [16]Jakawat W,Favre C,Loudcher S.OLAP on information networks:a new framework for dealing with bibliographic data[J].Advances in Intelligent Systems&Computing,2013,241:361-370. [17]Sun Yizhou,Han Jiawei,Yan Xifeng,et al.Mining knowledge from interconnected data:a heterogeneous information network analysis approach[J].Proceedings of the VLDB Endowment,2012,5(12):2022-2023. [18]Shi Chuan,Kong Xiangnan,Yu P S,et al.Relevance search in heterogeneous networks[C]//Proceedings of the 15th International Conference on Extending Database Technology,Berlin,Germany,Mar 27-30,2012.New York:ACM,2012:180-191. [19]Junghanns M,Petermann A,Gómez K,et al.GRADOOP:scalable graph data management and analytics with Hadoop[J].arXiv:1506.00548,2015. [20]Beheshti S M R,Benatallah B,Motahari-Nezhad H R.Scalable graph-based OLAP analytics over process execution data[J].Distributed&Parallel Databases,2016,34(3):379-423. [21]Cuzzocrea A,Moussa R,Xu Guandong,et al.Cloud-based OLAP over big data:application scenarios and performance analysis[C]//Proceedings of the 15th International Symposium on Cluster,Cloud and Grid Computing,Shenzhen,China,May 4-7,2015.Washington:IEEE Computer Society,2015:921-927. 附中文参考文献: [3]王会举,覃雄派,王珊,等.面向大规模机群的可扩展OLAP查询技术[J].计算机学报,2015,38(1):45-58. [4]吴巍.复杂网络可视化与Link OLAP[D].北京:北京邮电大学,2007. [6]李川,赵磊,唐常杰,等.Graph OLAPing的建模、设计与实现[J].软件学报,2011,22(2):258-268. Research and Implementation of Framework for Large-Scale Multi-Dimensional NetworkAnalysis* WANG Ze'ao+,WU Bin,WU Xinyu,ZHANG Zixing College of Computer Science,Beijing University of Posts and Telecommunications,Beijing 100080,China 2016-09,Accepted 2016-11. With the rapid development of the Internet and the increasing of computer applications,a large number of graph data especially social networks are generated.Multi-dimensional information networks have become a common way to represent these data.However in the multi-dimensional information networks there are multiple types of nodes and attributes.How to process the analysis of multi-view and multi-granularity and mine the hidden information has become the focus of current research.Graph online analytical processing(GraphOLAP)can process a quick online analysis and query operation of graph data.With the existing achievement of GraphOLAP,this paper proposes a new Graph-Cube framework according to the characteristics of multi-dimensional information network.This paper introduces the concept of meta-path and uses main node to guide the aggregation of the meta-path.Then this paper uses meta-path to guide the roll-up/drill-down operation of the network and proposes attributes transform and homogeneous transform operation of the Graph-Cube.Finally,this paper discusses the materialization strategy and implements the framework in Spark.The experimental results on real and simulation datasets prove the efficiency and effectiveness of the proposed framework. GraphOLAP;Graph-Cube;meta-path;Spark +Corresponding author:E-mail:tytyal@163.com 10.3778/j.issn.1673-9418.1609012 *The National Natural Science Foundation of China under Grant No.71231002(国家自然科学基金);the Special Fund for Beijing Common Construction Project(北京市共建项目专项). CNKI网络优先出版:2016-11-11,http://www.cnki.net/kcms/detail/11.5602.TP.20161111.1627.002.html WANG Ze'ao,WU Bin,WU Xinyu,et al.Research and implementation of framework for large-scale multidimensional network analysis.Journal of Frontiers of Computer Science and Technology,2017,11(12):1941-1952. A TP399 WANG Ze'ao was born in 1993.He is an M.S.candidate at Beijing University of Posts and Telecommunications.His research interests include data mining and social network analysis,etc. 王泽奥(1993—),男,四川安岳人,北京邮电大学硕士研究生,主要研究领域为数据挖掘,社会网络分析等。 WU Bin was born in 1969.He is a professor and Ph.D.supervisor at Beijing University of Posts and Telecommunications.His research interests include data mining and complex network,etc. 吴斌(1969—),男,湖南长沙人,博士,北京邮电大学教授、博士生导师,主要研究领域为数据挖掘,复杂网络等。 WU Xinyu was born in 1993.He is an M.S.candidate at Beijing University of Posts and Telecommunications.His research interests include data mining and social network analysis,etc. 吴心宇(1993—),男,福建莆田人,北京邮电大学硕士研究生,主要研究领域为数据挖掘,社会网络分析等。 ZHANG Zixing was born in 1994.He is an M.S.candidate at Beijing University of Posts and Telecommunications.His research interests include data mining and social network analysis,etc. 张子兴(1994—),男,河北遵化人,北京邮电大学硕士研究生,主要研究领域为数据挖掘,社会网络分析等。


3 优化物化策略
3.1 操作优化
3.2 实体立方体物化
3.3 维度编码
4 实验验证
4.1 有效性验证
4.1.1 MAG数据集
4.1.2 IMDB数据集
4.2 高效性验证
4.2.1 实体立方体效能验证
4.2.2 维度属性编码
5 相关工作
6 总结



 猜你喜欢
科普童话·学霸日记(2023年7期)2023-08-21 09:49:46中华诗词(2019年7期)2019-11-25 01:43:00中学生天地(A版)(2017年6期)2017-06-23 18:32:36太空探索(2016年9期)2016-07-12 09:59:53小学生导刊(低年级)(2016年6期)2016-07-02 22:22:15灯与照明(2016年4期)2016-06-05 09:01:45中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24云南师范大学学报(自然科学版)(2015年5期)2015-12-26 12:46:16中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:26物理实验(2015年10期)2015-02-28 17:36:52
猜你喜欢
科普童话·学霸日记(2023年7期)2023-08-21 09:49:46中华诗词(2019年7期)2019-11-25 01:43:00中学生天地(A版)(2017年6期)2017-06-23 18:32:36太空探索(2016年9期)2016-07-12 09:59:53小学生导刊(低年级)(2016年6期)2016-07-02 22:22:15灯与照明(2016年4期)2016-06-05 09:01:45中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24云南师范大学学报(自然科学版)(2015年5期)2015-12-26 12:46:16中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:26物理实验(2015年10期)2015-02-28 17:36:52
