
面向多种场景的视频对象自动分割算法①
2017-12-12 08:59:36余欣纬柯余洋黄文超
计算机系统应用 2017年11期
余欣纬,柯余洋,熊 焰,黄文超
1(中国科学技术大学 计算机科学与技术学院,合肥 230027)2(合肥学院 计算机科学与技术系,合肥 230000)
面向多种场景的视频对象自动分割算法①
余欣纬1,柯余洋2,熊 焰1,黄文超1
1(中国科学技术大学 计算机科学与技术学院,合肥 230027)2(合肥学院 计算机科学与技术系,合肥 230000)
针对当前应用于视频对象分割的图割方法容易在复杂环境、镜头移动、光照不稳定等场景下鲁棒性不佳的问题,提出了结合光流和图割的视频对象分割算法.主要思路是通过分析前景对象的运动信息,得到单帧图像上前景区域的先验知识,从而改善分割结果.论文首先通过光流场采集视频中动作信息,并提取出前景对象先验区域,然后结合前景和背景先验区域建立图割模型,实现前景对象分割.最后为提高算法在不同场景下的鲁棒性,本文改进了传统的测地显著性模型,并基于视频本征的时域平滑性,提出了基于混合高斯模型的动态位置模型优化机制.在两个标准数据集上的实验结果表明,所提算法与当前其他视频对象分割算法相比,降低了分割结果的错误率,有效提高了在多种场景下的鲁棒性.
视频对象分割;光流;图割;测地显著性;混合高斯模型
?
近年来,随着计算机存储和处理能力、网络带宽和多媒体显示以及拍摄设备的不断发展,人们拍摄和获取视频的能力不断增强.视频由于其信息的丰富性和生动性而被越来越多的人所接受,成为人们在生活中娱乐、学习、记录的重要传播载体.这些不断增长的海量视频数据资源带来了信息冗余和如何高效管理的问题.因此,不断增长的大规模视频数据及其应用也促使了获取、分析以及理解这些视频数据的需求日益增长.如何降低视频内容理解难度,提取出视频中的关键信息成为学术界和工业界关心的焦点.而视频对象分割因为其具有能够有效处理视频中主要信息的特点在视频摘要、视频检索、视频活动分析等领域拥有广泛的应用.视频对象自动分割算法因为不需人工参与,可以在多种大规模视频数据处理场景中应用的特点,成为近年来的研究热点.
当前,自动化视频对象分割方法有诸多研究思路,包括:基于对象候选集筛选的方法、基于点追踪和聚类的方法以及基于图割的方法.基于图割的方法主要是通过将图像或视频分割问题转换为图的最小割问题,实现对图像或视频的前景对象分割.Khoreva等[1]提出了使用分类器计算图中边权值的方法,优化并提升了现有方法的分割结果.Ma等[2]利用在图的最大团算法,针对多处前景对象候选区域评分,得到分割结果.Zhang等[3]构造了一个分层的有向无环图来选取最终的目标区域,并利用视频帧间的光流信息对目标区域进行扩张,目标分割精度有所提升.但该方法是以像素点作为基本单元构建马尔科夫随机场,分割效率较低.尽管现有的自动化分割方法能够有效地检测并分割出视频前景对象区域,但在精度和场景鲁棒性上仍有较大提升空间.
为解决现有图割方法在多种场景中分割能力不佳的问题,本文提出了一个在多种场景中具有更好准确性和鲁棒性的视频对象分割算法.首先,通过分析视频中的运动信息,获得前景对象的先验知识,为之后的分割过程提供重要信息.在得到前景对象先验知识的基础上进行分割,能够较好地排除因背景因素导致的干扰,提高不同场景下的分割精度.然后,本文改进了传统的测地显著性计算模型[4],结合前景和背景先验区域计算得到分割结果.最后,为了解决一些场景中分割结果不佳的问题,本文基于混合高斯模型建立了动态位置模型优化机制,利用前景对象本征的位置平滑性优化分割结果.
1 前景对象先验知识提取
本文利用视频的动作信息分析得到前景对象的动作轮廓,在动作轮廓中包含的区域即为所求前景区域先验知识.相较于背景区域,符合人类认知特点的前景对象一般在图像和动作特征上具有独特性.首先,本文采用光流(Optical flow)计算得到视频序列中的动作模型.通过对光流向量梯度计算得到前景对象动作轮廓.针对传统梯度计算模型产生的背景噪声干扰问题,本文提出考虑向量长度和方向的混合梯度计算模型,能够较好地排除背景噪声和镜头动作的干扰.然后,本文改进了点包容性(Point in Polygon,PIP)算法[5,6]解决从不完整连续动作轮廓中提取前景先验区域的问题.最后,在某些场景中可能因为镜头抖动、背景遮挡或前景对象本身动作信息不明显而导致光流计算出现错误.针对上述问题,本文提出基于时域平滑性的前景区域优化方案,确保算法在上述场景中的鲁棒性.
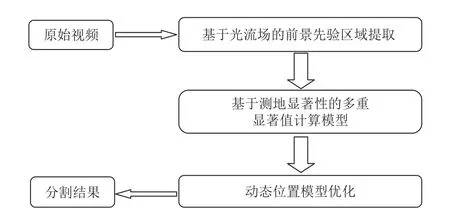
图1 本文算法流程图
1.1 光流
为了精确地提取视频中的动作信息,本文采用了光流场算法[7]建立视频的动作模型.光流是指时变图像中的模式运动速度.因为当物体在运动时,它在图像上对应点的亮度模式也在运动.光流表达了图像的变化,由于它包含了目标运动的信息,因此可被观察者用来确定目标的运动情况.由光流的定义可以引申出光流场,它是指图像中所有像素点构成的一种二维瞬时速度场,其中的二维速度矢量是景物中可见点的三维速度矢量在成像表面的投影.因此光流可以较为准确地描述被观察物体的运动信息.
本文对视频序列中相邻的帧图像计算得到光流场.光流场由光流向量组成,每个光流向量描述了对应像素点在相邻帧之间运动的方向和程度.
1.2 梯度计算模型
式为:
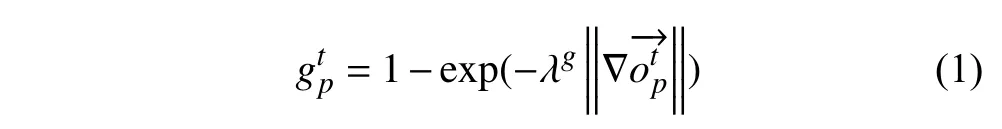
然而,上述传统梯度计算方法更容易受到镜头移动或晃动、背景噪声的干扰.在图2中,源图像序列中的动作信息包含:前景对象的跑动动作、背景噪声以及镜头的持续移动.根据(b)中梯度计算结果可以发现,式(1)虽然能够较好地提取出前景对象的运动轮廓,但同样容易受到镜头运动和背景噪声的干扰.使得(1)无法从光流图像中得到正确的前景对象先验知识.

图2 梯度计算模型对比结果
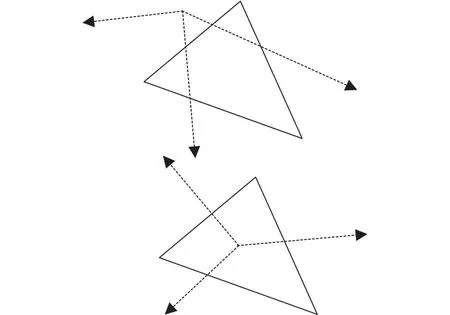
图3 点包容性算法原理图
本文将光流向量的方向纳入计算模型中,提出了混合梯度计算模型,较好地排除了镜头和背景因素的干扰.基于对像素点光流向量特性的观察,本文认为:当某一像素点处于不同物体的轮廓上时,由于不同物体的运动特征不一致,因而该像素点对应的光流向量应与相邻像素点的向量方向有较大的夹角.反之,如果某一像素点与相邻像素点都处于同一物体内部,则该像素点对应的光流向量方向会与相邻像素点一致.因此,本文提出基于向量方向的梯度计算公式:
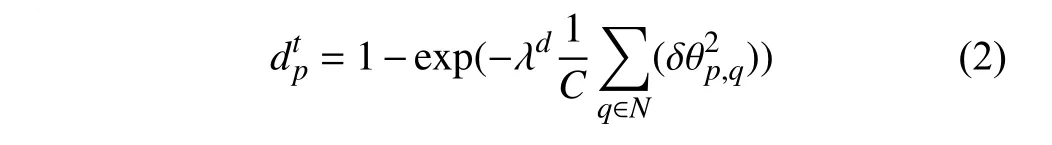
式中,N代表像素点p的相邻像素点集合;代表光流向量之间夹角的L2范数值;C表示像素点p的相邻像素个数,在本文方法中,C的值默认设定为4.通过式(2)可知,光流向量与相邻向量夹角越大,对应像素点计算得到的梯度值越大.
本文方法中结合了两种计算方法的混合梯度计算模型如下:
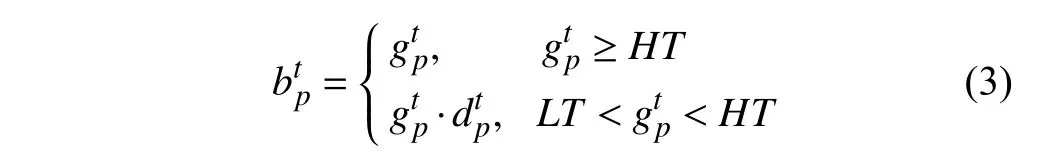
式中,HT代表较高的阈值,作用是将强烈的动作信息与可能出现混淆的像素点区分开.梯度值低于HT的像素点被认为难以分辨是否处于前景对象轮廓边缘,因而需要结合式(2)进一步计算.LT代表较低的阈值,作用是判断像素点是否存在动作信息,梯度值低于LT的像素点将被视为噪声干扰.HT与LT均为自适应阈值.通过使用混合梯度计算模型,能够较好地得到前景对象运动轮廓.
1.3 先验区域标注
在不设约束的任意视频中,人们难以预测前景对象的动作模式.由于动作模式的不确定性,通过梯度计算模型得到前景对象轮廓通常是不连续的.为从运动轮廓中标注出所需的前景先验区域,我们改进了点包容性算法[5,6].算法原理如图3所示,从平面上某一点向任意方向发出射线,如果射线与平面上的多边形边的交点个数均为奇数,则该点处于某一多边形内部;若交点个数均为偶数,则处于任意多边形的外部.针对动作轮廓不连续的问题,本文参照点包容性算法原理,对每个像素点计算水平、垂直、斜45度等八个方向的射线交点数,并采用多数投票法实现了正确的标注.
1.4 前景先验区域优化
为解决特殊场景下光流图像错误率较高导致无法提取先验区域的问题,本文提出了前景先验区域优化方案.在真实拍摄的视频中,容易出现镜头移动速度过快、镜头剧烈晃动、对焦不清出现模糊等问题.这些干扰会对光流计算产生较大影响,导致光流图像错误率较高,无法准确地得到前景对象先验区域.针对这一问题,本文提出的优化方案能够利用前景对象的时域平滑性较好地优化先验区域.由于前景对象在视频序列的时域上具有平滑性,因而可以利用相邻帧中先验区域结果补全错误帧的先验区域.本文考虑到在利用连续性补全的过程中,越是相邻的帧的先验区域越有更高的置信度.因而本文以需要优化的错误帧为对称轴建立高斯模型,更接近错误帧的帧图像像素点具有更高的权重.优化方案计算公式如下:


图4 前景先验区域优化示意图
2 测地显著性模型
测地显著性模型属于图割模型的一种.传统测地显著性模型[4]通过在图像上建立图结构,计算节点到背景区域的测地距离,根据距离大小实现前景区域的分割.在中心偏移假设[8]的基础上,传统模型将图像的边缘区域标记为背景先验区域,并计算其他节点到边缘节点的距离.由于前景对象相较于背景区域在外观、动作和位置等方面具有特征独特性,因而与边缘背景区域距离越远的节点,其前景显著值越高.本文改进了传统测地显著性模型,基于前景和背景先验区域分别计算距离,并提出了新的显著值计算模型.首先,本文对单帧图像进行过分割处理得到超像素图像,并在此基础上建立图结构.然后,通过计算和比较未标记节点分别到前景和背景先验区域的距离,实现对前景区域的分割.为了解决某些场景下中心偏移假设效果不佳的问题,本文提出了多重显著值计算模型,使得算法在一些特殊场景下仍有较好的分割结果.
2.1 图的建立
本文采用超像素作为单帧图像中进行前景区域分割的最小单位.超像素由一系列位置相邻且颜色、亮度、纹理等特征相似的像素点组成的小区域,这些小区域最大程度上保证了区域内所有像素点都属于同一个物体.在一些复杂场景下,以超像素为单位实现前景对象分割能够较好地保留物体的边缘特性,获得更好的分割结果.本文采用图割模型实现前景区域分割,以超像素为节点构图能够显著降低图结构的复杂度,提高建模和优化的效率.本文采用SLIC算法[9]实现超像素过分割处理,SLIC能够较好地保持图像局部的形状完整性和外观相似性.
在单帧图像Ti上,本文以超像素为节点,相邻超像素建立边建立了图结构.其中Vi代表Ti上的超像素集合,Ei代表图中相邻节点之间边的集合.在本文中,Ei中每条边的权值由超像素间外观特征差异决定.权值计算公式如下:

式中,xj和xk分别代表在节点j和k内部的平均颜色特征值.本文通过对节点包含的所有像素点RGB颜色空间值求均值得到平均颜色特征值.N(j)代表节点j的相邻节点集合.为方便计算,本文建立的邻接矩阵Wi以存储Ei中的边权值.
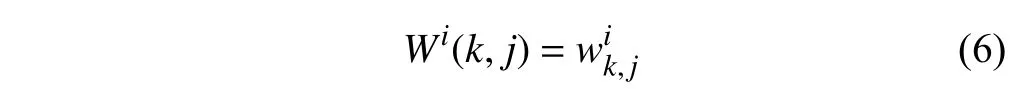
2.2 多重显著值计算模型
基于中心偏移假设[8],本文将图像的边缘节点结合标记为背景先验区域B.结合先前对动作信息分析得到的前景先验区域F,传统测地显著性模型[4]通过计算和比较剩余未标记节点集合U分别与B和F之间的测地距离,实现对前景对象的分割.单帧图像i中节点j的显著值计算公式如下:
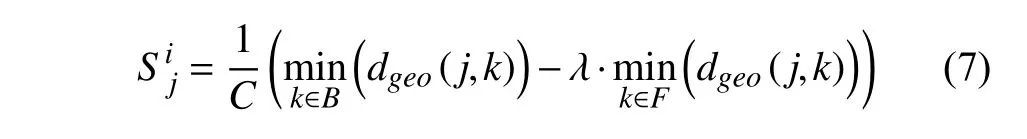
式中,C代表归一化的常数参数.代表节点之间的测地距离.λ是常系数,用于平衡两项距离值对所得显著值的贡献比,在本文方法中被设置为1.从式(7)中可以看出,的大小与到达B的距离成正比,与到达F的距离成反比.因而如果图中节点与背景先验区域特征相差较大且与前景先验区域特征接近,则该节点会获得较高的显著值,符合前景区域的特点.节点s和t之间的测地距离■计算公式如下:
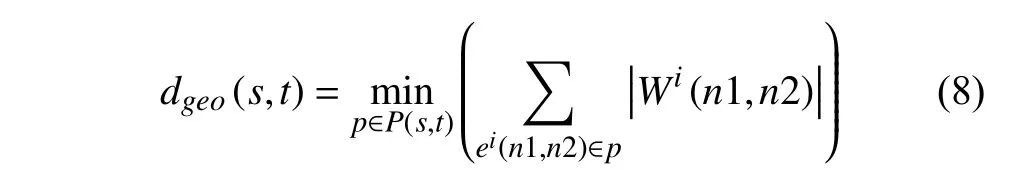

图5 多重显著值模型对比图
在实际场景中,一些视频中的前景对象会部分出现在单帧图像边缘上.对于包含这些场景的视频,应用传统模型无法得到正确的分割结果.针对这一问题,本文提出了多重显著值计算模型.通过分别计算未标记节点到每一条边缘的测地距离,得到四幅显著值图像,将其融合后得到最终的显著值图像.因而本文改进了式(7)中背景测地距离计算项.
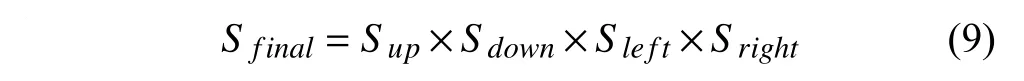
式中,Sup、Sdown、Sleft、Sright分别代表以单帧图像四条边缘为先验背景区域而计算得到的显著值图像,这些图像通过(7)计算得到.
此外,本文观察到图像边缘中的前景区域一般来说并不大.因而在多重显著值计算之前,本文加入了对图像边缘的预处理,以提高背景先验区域的准确性.本文基于颜色和空间特征对每条图像边缘进行聚类,并将一部分颜色特征相异于大多数节点的簇舍去,取剩下的节点作为先验背景区域.在本文方法中,采用了基于密度的DBSCAN聚类算法实现.
3 动态位置模型优化
本文采用多帧差分的混合高斯模型(Gaussian Mixture Model,GMM)建立了前景对象的动态位置模型,以提高算法在多种场景下的鲁棒性.Stauffer等[10]提出了基于混合高斯模型的背景建模方法,通过在每个像素点上建立K个高斯分布,实现图像分割.在某一时刻,像素点的历史像素值集合为:
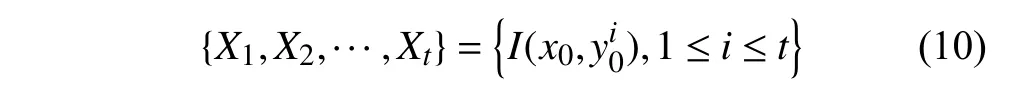
式中,i为视频序列,Xi为像素点在i时刻的像素值.当前像素点观测值的概率为:
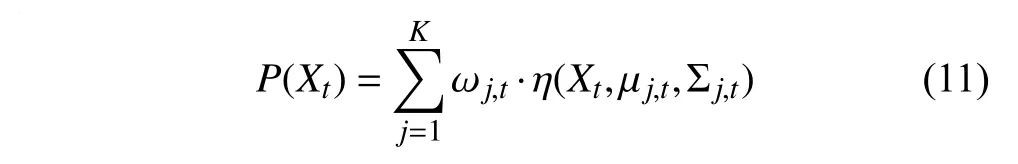
式中,K代表混合高斯模型中分布数量;代表第j个分布在时刻t的权重值;代表第j个高斯模型的均值和协方差,代表对应分布的标准差;代表高斯概率密度函数,计算公式为:
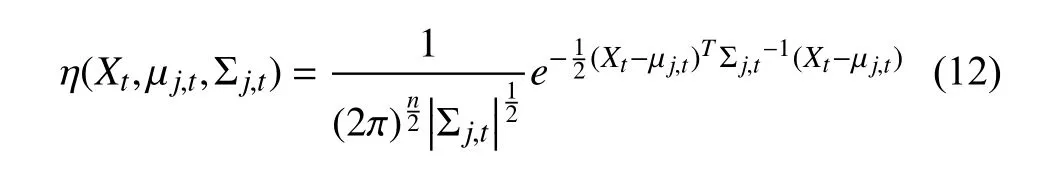
式中,n代表Xt的维度.
首先,文献[10]将混合高斯模型中的若干个分布按照优先级从大到小排列.然后,用像素点当前值Xt按序与混合高斯模型中所有分布相比较.若满足公式(13),则认为该像素点与其中某一分布匹配,并对匹配分布的参数、和进行更新.其他不匹配的分布只改变自身权重值.
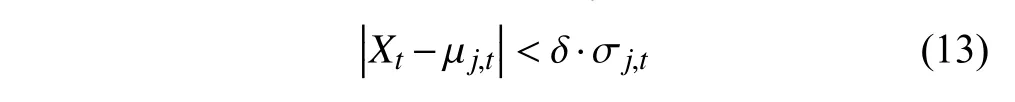
式中,δ一般取值为2.5~3.5.
若与混合高斯模型中所有分布均不匹配,则算法将根据当前像素值建立一个新的高斯分布(均值为Xt,初始化标准差及权重).如果当前分布数小于K,则新的高斯分布直接添加到混合高斯模型中.如果当前分布数等于K,则新的分布将取代优先级最小的分布.
本文采用混合高斯模型对视频序列建模,用单个或多个高斯分布表示前景对象的动态位置.此外,本文加入多帧差分优化建模结果,保证了动态位置模型的时域平滑性.
4 实验结果及分析
为了验证本文算法的有效性和鲁棒性,在两个标准数据集SegTrack和SegTrack v2上对本文算法和其他若干最优算法做了对比实验.SegTrack和SegTrack v2共包含14个不同的视频序列及超过1000幅帧图像,并涵盖了多种不同场景的视频,如:镜头快速移动、复杂环境和光照不佳等.能够较为全面地衡量算法在不同场景下的分割能力.实验中,本文选取文献[3]和[11]中算法的结果作对比.上述算法均为基于图割的视频对象分割算法并有较好分割能力.本文实验环境为:Intel i5-3450 @3.10 GHZ,8 GB内存,Windows 10环境下使用MATLAB 2015a实现算法.

图6 复杂环境场景的分割结果
图6中,前景对象处于复杂环境中,且背景环境中存在外观和纹理特征与前景物体相似的区域.文献[11]中算法严重受到了背景噪声的干扰,无法正确定位前景对象的位置.文献[3]算法结果未能完整分割出前景物体轮廓.本文算法分割结果较为完整准确.
图7和图8中,视频序列的拍摄镜头随前景对象快速移动,会产生大量的背景噪声.文献[11]的结果受到了噪声的较多影响,在前景对象周边产生了模糊.相较于文献[3],本文的分割结果更为完整,且较好地排除了噪声的干扰.

图7 镜头快速移动场景的分割结果

图8 前景对象动作特征复杂的分割结果
图9中,视频中整体光照条件不佳,且不同的区域明暗对比较为明显.本文算法在光照条件变动较为剧烈的情况下,仍保持了较好的准确性和鲁棒性.
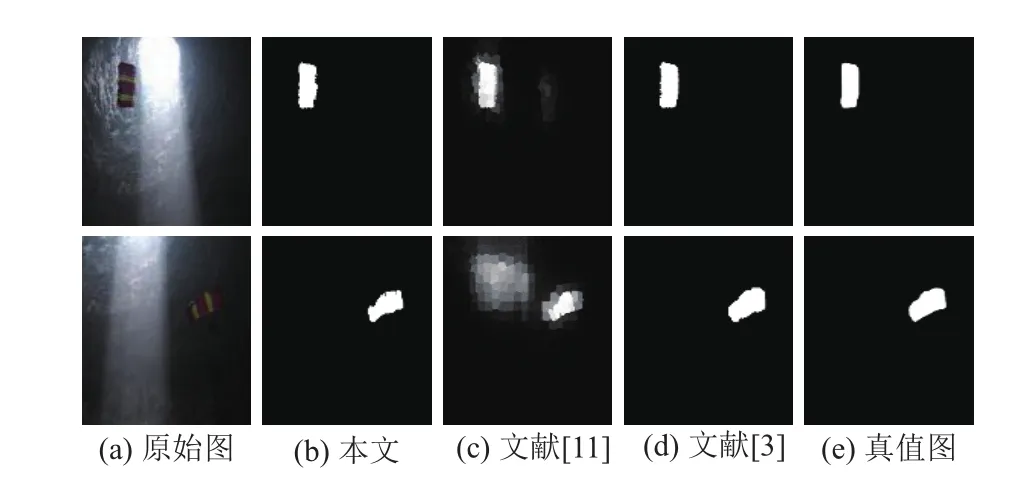
图9 光照条件不佳的分割结果
此外,以识别误差为标准在SegTrack数据集上比较了本文算法与文献[3]和[12]中算法的结果.识别误差计算公式如下:

式中,S代表任一算法的最终分割结果;GT代表数据集中提供的真实分割对照;F代表视频序列中帧图像的数量.通过计算每种算法在单个帧图像上的平均错分类像素个数,识别误差能够较好地衡量不同算法的分割能力.在同等实验条件下比较结果如表1所示.
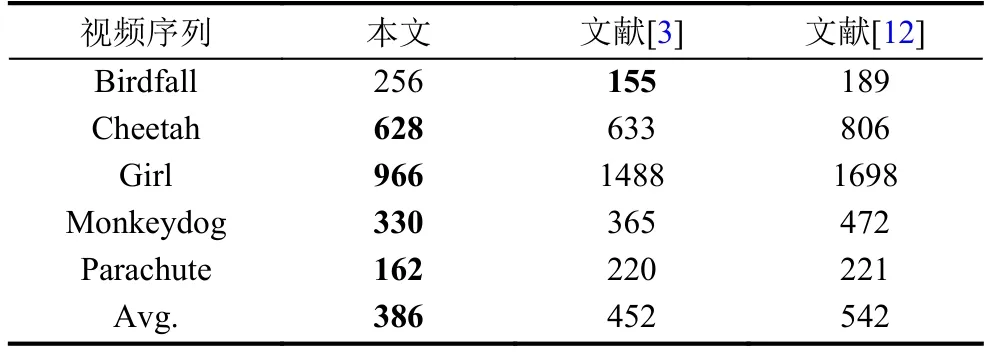
表1 SegTrack数据集上平均每帧错误率对比
实验结果表明,通过前景先验区域提取和改进后的测地显著性模型相结合,能够在前景对象动作模式较复杂的情况下较好地获得前景信息,也增强了算法在镜头移动或晃动场景中的鲁棒性,同时提高了算法在复杂背景环境中的分割能力.
综上所述,本文提出的算法相较于以前提出的图割算法具有更好的准确性.同时对多种视频中复杂环境、镜头移动以及光照变化的场景有较好的鲁棒性.
5 结语
提出了一种面向多种场景的视频对象自动分割算法.针对当前图割方法容易受到复杂环境、背景噪声等因素影响的问题,通过分析视频动作信息获得前景先验区域,为图割建模提供了重要的先验知识.同时改进了传统测地显著性模型,使算法能够应用于更多场景中.建立了动态位置模型,减少了背景因素对分割结果的干扰.实验结果证明了本文所提算法准确性相较于当前图割算法有了较好的提升,并在多种场景的视频中有更鲁棒的分割结果.
1 Khoreva A,Galasso F,Hein M,et al.Classifier based graph construction for video segmentation.Proc.of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston,MA,USA.2015.951–960.
2 Ma TY,Latecki LJ.Maximum weight cliques with mutex constraints for video object segmentation.Proc.of the 2012 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Providence,RI,USA.2012.670–677.
3 Zhang D,Javed O,Shah M.Video object segmentation through spatially accurate and temporally dense extraction of primary object regions.Proc.of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Portland,OR,USA.2013.628–635.
4 Wei YC,Wen F,Zhu WJ,et al.Geodesic saliency using background priors.Proc.of the 12th European conference on computer vision.Florence,Italy.2012.29–42.
5 Sutherland IE,Sproull RF,Schumacker RA.A characterization of ten hidden-surface algorithms.ACM Computing Surveys,1974,6(1):1–55.[doi:10.1145/356625.356626]
6 Shimrat M.Algorithm 112:Position of point relative to polygon.Communications of the ACM,1962,5(8):434.
7 Liu C.Beyond pixels:Exploring new representations and applications for motion analysis[Ph.D.Thesis].Cambridge,MA:Massachusetts Institute of Technology,2009.
8 Tatler BW.The central fixation bias in scene viewing:Selecting an optimal viewing position independently of motor biases and image feature distributions.Journal of Vision,2007,7(14):4.[doi:10.1167/7.14.4]
9 Achanta R,Shaji A,Smith K,et al.SLIC superpixels compared to state-of-the-art superpixel methods.IEEE Trans.on Pattern Analysis and Machine Intelligence,2012,34(11):2274–2282.[doi:10.1109/TPAMI.2012.120]
10 Stauffer C,Grimson WEL.Learning patterns of activity using real-time tracking.IEEE Trans.on Pattern Analysis and Machine Intelligence,2000,22(8):747–757.[doi:10.1109/34.868677]
11 Papazoglou A,Ferrari V.Fast object segmentation in unconstrained video.Proc.of the 2013 IEEE International Conference on Computer Vision (ICCV).Sydney,NSW,Australia.2013.1777–1784.
12 Wang WG,Shen JB,Porikli F.Saliency-aware geodesic video object segmentation.Proc.of the 2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Boston,MA,USA.2015.3395–3402.
Automatic Video Object Segmentation Algorithm for Multiple Scenes
YU Xin-Wei1,KE Yu-Yang2,XIONG Yan1,HUANG Wen-Chao11(School of Computer Science and Technology,University of Science and Technology of China,Hefei 230027,China)2(Department of Computer Science and Technology,Hefei University,Hefei 230000,China)
Aiming at the problems of poor robustness in the complex environment,lens movement and light instability,a video object segmentation algorithm combining optical flow and graph cutting is proposed.The main idea is to improve the segmentation result by analyzing the motion information of the foreground object and obtaining the prior knowledge of the foreground area on the single frame image.Firstly,the motion information in the video is collected by the optical flow field,and the prior knowledge of the foreground object is extracted.Then,the foreground object segmentation is realized by combining the priori areas of foreground and background.Finally,in order to improve the robustness of the algorithm in different scenarios,this paper improves the traditional geodesic saliency model,and employs the dynamic position model optimization mechanism based on Gaussian Mixture Model based on the intrinsic temporary smoothness of video.Experimental results on two benchmark datasets show that the proposed algorithm reduces the error rate of the segmentation results compared with other video object segmentation algorithms,which effectively improves the robustness in many scenarios.
video object segmentation;optical flow;graph cut;geodesic saliency;Gaussian mixture model
余欣纬,柯余洋,熊焰,黄文超.面向多种场景的视频对象自动分割算法.计算机系统应用,2017,26(11):152–158.http://www.c-sa.org.cn/1003-3254/6044.html
2017-02-21;修改时间:2017-03-09;采用时间:2017-03-13
?
猜你喜欢
建材发展导向(2021年6期)2021-06-09 05:57:08
今日农业(2020年17期)2020-12-15 12:34:28
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
中国外汇(2019年11期)2019-08-27 02:06:32
电脑知识与技术(2018年35期)2018-02-27 13:29:44
自动化学报(2017年5期)2017-05-14 06:20:44
自动化学报(2017年11期)2017-04-04 02:52:44
太空探索(2016年10期)2016-07-10 12:07:01
探测与控制学报(2015年4期)2015-12-15 15:00:56
东南法学(2015年2期)2015-06-05 12:21:36
