
基于主题模型的垃圾邮件过滤系统的设计与实现
2017-12-04 02:42寇晓淮程华
电信科学 2017年11期
寇晓淮,程华
(华东理工大学信息科学与工程学院,上海200237)
基于主题模型的垃圾邮件过滤系统的设计与实现
寇晓淮,程华
(华东理工大学信息科学与工程学院,上海200237)
垃圾邮件过滤技术在保证信息安全、提高资源利用、分拣信息数据等方面都发挥着重要作用。然而,垃圾邮件的出现影响了用户的体验,并且会造成不必要的经济与时间损失。针对现有的垃圾邮件过滤技术的不足,基于多个主题词理论,构建了基于朴素贝叶斯的垃圾邮件分类方法。在邮件主题获取中,采用主题模型LDA得到邮件的相关主题及主题词;并进一步采用Word2Vec寻找主题词的同义词和关联词,扩展主题词集合。在邮件分类中,对训练数据集进行统计学习得到词语的先验概率;基于扩展的主题词集合及其概率,通过贝叶斯公式推导得到某个主题和某封邮件的联合概率,以此作为垃圾邮件判定的依据。同时,基于主题模型的垃圾邮件过滤系统具有简洁易应用的特点。通过与其他典型垃圾邮件过滤方法的对比实验,证明基于主题模型的垃圾邮件分类方法及基于Word2Vec的改进方法均能有效提高垃圾邮件过滤的准确度。
文本分类;垃圾邮件;主题模型;贝叶斯原理
1 引言
伴随着互联网的发展和普及,电子邮件已经成为人们日常工作、生活中通信、交流的重要手段。但由于早期的SMTP缺乏发件人认证、大量开放式邮件中转服务器以及互联网分布式管理性质等原因,垃圾邮件已经成为亟待解决的问题。从电子邮件出现以来,研究者就在垃圾邮件拦截方面做出了大量的研究工作。然而,垃圾邮件制造者总会找到更加隐蔽且混淆的手段来躲避相关算法的检测。对于此类研究工作,目前仍然存在两个重要的问题:邮件是一种快速且便捷的通信方式,而大面积的广告推广动机促成了大量为非正当利益而开发的反过滤技术;中文词语的丰富性和特殊性导致垃圾邮件与正常邮件区分难度较大,很多国外的优秀算法在移植过程中将遭遇新的挑战。
针对以上问题,本文深入分析和比较传统垃圾邮件处理方法,指出了现有垃圾邮件过滤方法的不足,对主题模型算法及其在自然语言处理中的应用进行了研究,指出了主题模型算法应用于垃圾邮件过滤的可行性与能够解决的问题;提出了基于主题模型的垃圾邮件过滤算法;设计并实现了一种基于主题模型的垃圾邮件过滤模型,通过与其他方法的对比实验,证明本文基于主题模型的垃圾邮件过滤方法及基于Word2Vec[1]的改进方法均明显提升了过滤准确度,具有较高的应用价值。
2 基于邮件过滤的相关技术
2.1 面向内容的电子邮件过滤技术
常见的邮箱对于垃圾邮件的过滤策略中,基于内容对邮件过滤的方法有黑白名单、手工建立过滤规则等。手工建立规则的方法通过用户建立一系列规则来判定垃圾邮件。显然,这些方法的主观性会造成大量合法邮件的误判和垃圾邮件的漏判,并且很难做到实时的手工维护,对邮件服务商的人力及经济造成很大压力。因此,垃圾邮件工具逐渐倾向于引入基于内容的机器学习判别方法[2,3]。
基于内容垃圾邮件判别的机器学习方法,一般步骤如下。
步骤1获取训练数据集合,通过多种手段渠道获取各类电子邮件,并备注该电子邮件是否是垃圾邮件。
步骤2建立模型,使用训练集合训练模型,更新模型中的参数。
步骤3使用训练好的模型,对新的电子邮件进行过滤。
总结起来就是通过已有的训练集合(正例、反例)训练出相应的垃圾邮件规则(包括显式规则或隐式规则),然后将规则应用到新的邮件判别中。
最近几年,国内外研究者在此领域已经取得了大量的研究成果。Sheu等人[4]利用决策树模型构建了三步法垃圾邮件过滤模式。Feng等人[5]提出了基于朴素贝叶斯分类器的训练集分类方法,提升了数据处理的顽健性,提出的SVM-NB方法能够达到较高的垃圾邮件检测精度。而Bansal等人[6]构建了基于穿梭判定算法的垃圾词语检测方法,并且在谷歌邮件系统中做了初步的应用。另外,广告产业的发展为垃圾邮件拦截与过滤提出了新的要求,Chan等人[7]在此方向上做了针对性研究,推出了广告环境下的垃圾邮件过滤方法。除此之外,一些其他的研究成果也引起了学术界和 IT产业界的广泛关注[8-10]。曹玉东等人[11]基于改进的局部敏感散列算法实现了图像型垃圾邮件过滤,将垃圾邮件过滤方法的应用范围扩大。
2.2 垃圾邮件常用文本分类方法
(1)Decision Tree方法
决策树利用熵的概念对每次决策产生的结果进行分类[4]。决策树使用树状结构对目标分类,树中每个节点表示某个对象,每个分叉路径代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
决策树也可以被称为分类树,它是非常常用的分类方法。从另一个角度来说,决策树是一种监督学习方法。在给定样本机器类别属性后,决策树通过学习能够得到一个固定的分类器,从而给出新进数据的具体类别。
(2)AdaBoost方法
自适应增强(adaptive boosting,AdaBoost)是加权组合多个弱分类器分类结果,进而得到更好的分类器的方法。Carreras和 Nicholas[12,13]将AdaBoost引入垃圾邮件过滤,获得了很高的性能。AdaBoost方法的自适应在于:后面的分类器会在那些被之前分类器分错的样本上训练。AdaBoost方法对于噪声数据和异常数据很敏感。但在一些问题中,相比于大多数学习算法,AdaBoost方法对于过拟合问题不够敏感。AdaBoost方法中使用的分类器可能很弱(比如出现很大错误率),但其分类效果只要比随机好一点(比如它的二分类错误率略小于 0.5),就能够改善最终模型。
(3)Rough Sets方法
Rough Sets算法是一种比较新颖的算法,粗糙集理论对于数据的挖掘提供了一个新的概念和
2.3 用于垃圾邮件过滤的贝叶斯方法
研究方法。将Rough Sets引入垃圾邮件过滤,采用11种非文本属性(包括收信人数、中继个数等)来进行邮件分类(正常、广告和反动)。
具体来说,所有属性分为2种属性:1类为条件属性,1类为决策属性。本文姑且把决策属性设置在数据列的最后一列,算法的步骤依次判断条件属性是否能被约简,如果能被约简,此输出约简属性后的规则,规则的形式大体类似于IF-THEN的规则。
(4)kNN方法
k-近邻方法(k-nearest neighbour,kNN)在线性模型中是最常见的方法,通过选择特征与数据集合中所有特征对比最近的几个样本的标签平均值表示。
对于邮件的垃圾分类,一方面邮件就是文本,属于文本分类领域。另一方面,由邮件中的某些关键词来推断是否是垃圾邮件,就是一种贝叶斯条件概率方法的应用。数据挖掘领域主要使用两种贝叶斯方法,即朴素贝叶斯方法和贝叶斯网络方法。贝叶斯方法的一个显著特点,就是在知道结果的情况下了解假设的情况,也就是说,当对某些知识知之甚少,或者毫不知情的时候,贝叶斯方法具有独特优势。
在垃圾邮件检测过程中,其主要依据正常邮件与垃圾邮件的先验概率。而贝叶斯分类模型能够通过适当的独立性假设来简化分布,也就是朴素贝叶斯假设。在这样的假设条件下,能够形成朴素贝叶斯网络。
贝叶斯分类算法是基于概率统计原理的一种分类方法,它具有运算速度快、方法简单、分类精度高等优点,因而被广泛应用在文本分类领域,并表现出非常好的效果。
目前,贝叶斯过滤算法被广泛使用于智能和概率系统中,它具有单词学习的模式和频率,而不需要提前预设任何规则。具体来说,贝叶斯过滤技术能够根据垃圾邮件与正常邮件的联系与特点进行判断。与传统的关键词检测过滤技术相比,贝叶斯过滤算法更加复杂且智能,而反过滤方法不能破解过滤器内部的配置,从而提升了安全性与顽健性。
2.4 基于朴素贝叶斯的文本分类及流程
朴素贝叶斯分类器是垃圾邮件内容过滤中智能应用的分类方法。利用这种方法,可以根据训练集自动训练,训练的结果反映了训练集的性质。因此训练者可以利用一定数量的垃圾邮件和非垃圾邮件,训练邮件过滤器,从而达到高效、准确过滤垃圾邮件的目的。
朴素贝叶斯分类的流程如图1表示。
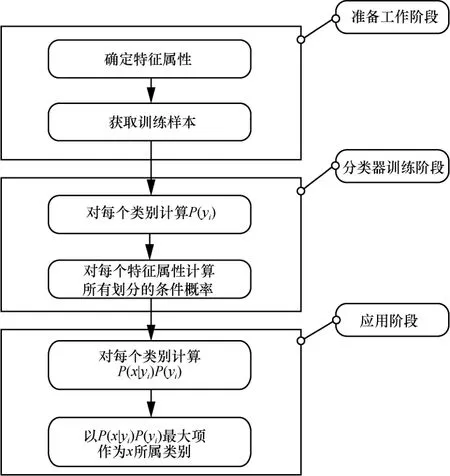
图1 朴素贝叶斯分类流程
然而,朴素贝叶斯分类也有缺陷,它的假设是基于“各特征项相互条件独立”。在很多的实际问题中,如果此下设表现不够明显,甚至出现不成立时,错误的分类将会出现,从而影响算法的最终表现。在本文中,贝叶斯模型的使用将会被改善,而具体的内容将会在第3节中被介绍。
3 主题模型在垃圾邮件过滤中的研究
3.1 基于关键词的垃圾邮件过滤
3.1.1 算法思想
主要算法思想是基于关键词技术,采用朴素贝叶斯分类方法得到关键词,分析邮件内容分类到垃圾邮件的置信概率,进而产生分类结果。这种方法的优势在于复杂度低,且应用范围较广。3.1.2 基于关键词的邮件过滤算法流程
从内容上看,邮件过滤可以看成一个二值分类问题,即把邮件分为垃圾邮件类和合法邮件类。基于关键词的邮件过滤算法流程简单来讲是朴素贝叶斯方法,贝叶斯过滤算法大致由以下基本步骤组成。
步骤 1收集大量的垃圾邮件和合法邮件,建立垃圾邮件集和合法邮件集。
步骤 2提取邮件主题和邮件体中的独立字符串,例如sale、cash等作为token串并统计提取出的token串出现的次数即字频。按照上述的方法分别处理垃圾邮件集和合法邮件集中的所有邮件。采用贝叶斯文本分类法对训练样本学习,得到P(S|W)。
步骤 3每一个邮件集对应一个散列表,合法邮件集对应表 hashtable_good,垃圾邮件集对应表hashtable_bad,表中存储token串到字频的映射关系。
步骤 4计算每个散列表中 token串出现的概率,可以得到 P1(ti)和 P2(ti), P1(ti)表示 ti在hashtable_good中的值(也就是token串ti在合法邮件中的概率);P2(ti)表示ti在hashtable_bad中的值(也就是token串ti在垃圾邮件中的概率):

步骤 5由步骤 2中贝叶斯文本分类法得到的 P(S|W),综合考虑散列表 hashtable_good和hashtable_bad,推断出当新来的邮件中出现某个token串时,该新邮件为垃圾邮件的概率。计算式为:
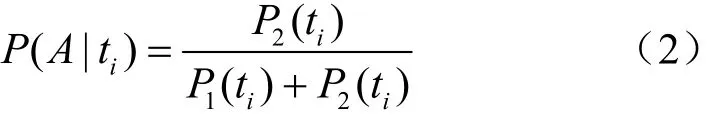
其中,A事件表示邮件为垃圾邮件;t1,t2,…,tn代表token串;P(A|ti)表示当token串ti出现在所收到的邮件中时,该邮件为垃圾邮件的概率。
假设该邮件共得到N个 token串t1,t2,…,tn,hashtable_probability中对应的值为 P1,P2,…,Pn,P(A|t1,t2,…,tn)表示在邮件中同时出现多个token串t1,t2,…,tn时,该邮件为垃圾邮件的概率。
由联合概率公式可得:

当 P(A|t1,t2,…,tn)超过预定阈值(例如 0.95)时,就可以判断邮件为垃圾邮件。
3.2 LDA主题模型
LDA(latent Dirichlet allocation)的产生和发展历经TF-IDF、LSA、pLSA等多种主题模型方法,由于LDA模型的良好的数学基础和灵活的扩展性,一经提出即得到了来自各个领域研究者的关注,被广泛应用在文本挖掘及信息处理的研究中[14]。
LDA模型最初是作为一种文本分类和主题聚类方法被提出,它将文档集中每篇文档的主题以概率分布形式给出,从而通过分析便能够得到聚类结果。与此同时,它是一种典型的词袋模型。也就是说,每篇文档将会被分解为一组词,而不用考虑先后顺序。
LDA是一个三层的贝叶斯概率生成模型,由“主题—词语”和“文档—主题”构成。在LDA模型中需要求解“词语—主题”和“主题—文档”两个模型参数。LDA假设文本集D中各文本w有如下生成过程,如图2所示,T表示主题的个数,D表示文档的个数,Nd表示第d篇文档中词语的个数。

图2 LDA模型
步骤1 确定文档中的词语数N,使之服从参数为ξ的泊松分布。
步骤3对于文本中N个词中的每一个wn:确定一个主题 zn,使之服从参数为θ的多项式分布;依照概率 p( wn|zn,β)选择每一个词语wn。
3.3 基于主题模型的垃圾邮件过滤方法
基于主题模型抽取垃圾邮件的主题,对已知的垃圾邮件样本进行训练,提取垃圾邮件的特征,采用贝叶斯估计分类算法,构造垃圾邮件的过滤器。利用得到的垃圾邮件过滤器,对新的邮件进行分析、判断,区分垃圾邮件和合法邮件,实现垃圾邮件的过滤。
具体实现步骤如下。
步骤 1采集一定数量的垃圾邮件与合法邮件,建立相应的垃圾邮件集和合法邮件集,计算词频得到每个词语出现的情况下该邮件是垃圾邮件的概率P(S|W)。
步骤 2利用 LDA主题模型对邮件进行主题抽取,分类算法对已知的垃圾邮件样本进行训练,对垃圾邮件集和合法邮件集中的邮件进行解析,并提取邮件的特征,统计相应数据。LDA是一种文档主体生成模型,也成为一个三层贝叶斯概率模型,包含词、主体、文档这三层结构。生成模型,即一篇文章的每个词都是通过以一定的概率选择了一个主题,并从这个主题中以一定的概率选择这个词语的过程得到的。
步骤 3由联合概率公式计算每个主题中所有词语的联合概率;得到每个主题出现的情况下该邮件是垃圾邮件的概率;构造邮件分类器。
步骤 4采用贝叶斯分类器。选取一个判断垃圾邮件适当的阈值,利用所建立的邮件分类器实现对邮件的分类。
预应力钢丝绳的一端直接穿入端部锚具的开口,另一端通过张拉器进行张拉。采用对称张拉的原则,以防结构产生扭转、侧弯。张拉时从两侧向中间对称前进,钢丝绳布置如图5所示。
3.4 模型的改进
传统判断两个文档相似性的办法是查看两个文档共同出现的单词的多少,如TF-IDF等,但这种办法没有考虑到文字背后的语义关联,有可能两个文档说的是相似的内容但并没有词语上的交集。LDA提取出来的邮件主题关键词能够表达邮件较高级别的主题内容,能够消除主题关键词之间的歧义。但是此时每个主题关键词并不是使用向量表达,此时本文使用Word2Vec方法,将词语转化为向量空间,有利于计算词语之间的相似程度。同时使用主题词向量距离计算方式计算距离主题最近的词语,即用Word2Vec生成每个主题中词语的关联词,作为主题词语的扩容,在此基础上再进行垃圾邮件判断。
4 垃圾邮件过滤器的设计及实验分析
4.1 邮件样本集的选取
4.1.1 垃圾邮件过滤的语料库
本文采用的垃圾邮件语料库从网上采集,包含正常邮件和垃圾邮件各8 000封。图3为比较典型的用于广告的垃圾邮件案例。
用这两类邮件建立垃圾邮件过滤器中词的先验概率。过程如下。
首先,解析所有邮件,提取每一个词。然后,计算每个词语在正常邮件和垃圾邮件中的出现频率。例如,假定“发票”这个词,在8 000封垃圾邮件中,有200封包含这个词,那么它的出现频率就是2.5%;而在8 000封正常邮件中,只有2封包含这个词,那么出现频率就是0.025%。有可能某个词在已有的某一类邮件语料中未出现,为了避免该词的先验概率出现为0的情况,设定该词的出现频次为 1。假设某个词只出现在垃圾邮件中,正常邮件中没有,就设定它在正常邮件的出现频率是0.012 5%(1/8 000),反之亦然。随着邮件数量的增加,词的先验概率计算结果会更接近于真实情况。
4.1.2 垃圾邮件评价指标
为了对垃圾邮件过滤系统的效果做分析,需要一个评价体系来进行评估,即一个系统可以判定未知文档是否属于某类。假定有N个邮件文档通过分类器分别分类,可以用表1来表示人工与系统对邮件的评判情况。A为人工与系统都评判为垃圾的邮件数;B为人工评判为正常,而系统评判为垃圾的邮件数;C为系统评判为正常,而人工评判为垃圾的邮件数;D为人工与系统都评判为正常的邮件数。

表1 垃圾邮件测评
定义如下几个指标来检测算法对垃圾邮件的过滤效果。
(1)召回率(recall)
描述收到一封垃圾邮件时,分类器判定为垃圾邮件的概率,召回率越高,表示分类器对邮件分类效果越显著,计算式为:

(2)正确率(precision)
描述分类器对正常邮件和垃圾邮件都能正确分辨的概率,将垃圾邮件判为垃圾邮件和将非垃圾邮件判为合法邮件的概率,正确率越高表示分类器的效果越理想,计算式为:
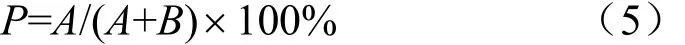
(3)误判率(misjudge)

图3 垃圾邮件案例
描述正常邮件的误判率,将非垃圾邮件判为垃圾邮件的概率,这是描述一个分类器是否有效的关键指标,如果误判率很高,则说明分类器没有起到很好的分类效果,误判率越低表示正常邮件被判为垃圾邮件的概率越小,计算式为:

(4)精确率(accuracy)
分类器对正常邮件分类的正确性,精确率越高表示邮件对正常邮件的判别越正确,计算式为:

在对实验结果的评估中将会比较以上数值。准确率 P 是邮件被正确分类的概率,召回率是指实验方法将邮件正确分类的概率,F1值则是指β=1时的F值,是最常用的F值之一,可以看作模型准确率和召回率的一种加权平均。这3个值都是数值越高所代表的分类效果越优秀。
4.2 实验结果与分析
4.2.1 LDA主题抽取
步骤 1首先用 jieba分词算法分词后得到300个分词文件,名称如1-seg.txt、2-seg.txt等。例如,“合金”“批发”“朋友”“爸妈”等词语。
步骤2再用LDA主题模型算法解析300封邮件,得到20个主题词组,如:“0.090*‘交涉’+0.090*‘小白脸’+0.090*‘力阻’+ 0.090*‘撕破脸’+ 0.090*‘私事’”。
步骤3最后得到300×20维的权值矩阵,300表示300封邮件,20表示20个主题,即每封邮件和20个主题之间的相关度。
采用 LDA主题模型算法,从测试集中选取300封邮件进行主题抽取20个主题,主题词确定为10个,选取两个具有代表性的主题,结果见表2。4.2.2 LDA反垃圾邮件过滤实验结果与分析
为了有效地验证该方法的可行性,选用正常邮件和垃圾邮件各8 000封,共16 000封作为训练集;另取正常邮件和垃圾邮件各150封,共300封作为测试集。用本文基于LDA的垃圾邮件过滤方法进行实验,其中主题数确定为20个,主题词为10个,共完成5组实验,结果见表3。

表2 主题模型结果

表3 基于LDA的垃圾邮件过滤方法测试结果
在实验中,把垃圾邮件的概率跟合法邮件的概率做比较,需要选择判定垃圾邮件概率的阈值。阈值的控制比较重要,如果太大则会漏掉大量垃圾邮件,通过实验确定最佳阈值为0.43左右。
(1)与其他方法比较
为了更好地说明本文设计算法的有效性,本文选取了积累典型的垃圾邮件过滤方法进行比较,包括基于Naïve Bayes的邮件过滤方法[15,16]、基于SVM的邮件过滤方法[17]、基于kNN的邮件过滤方法[18]、基于MTM(message topic model)的邮件过滤方法[3]、基于决策树的三步邮件过滤方法[4]、基于SVM-NB的邮件过滤方法[5]。其中,前3种方法是以简单机器学习为基础的邮件过滤方法,MTM方法建立了一种有效的方式,用来检测邮件主题词,三步邮件过滤法是以决策树为基础的,而SVM-NB方法是基于朴素贝叶斯分类分类的方式,对比见表4。
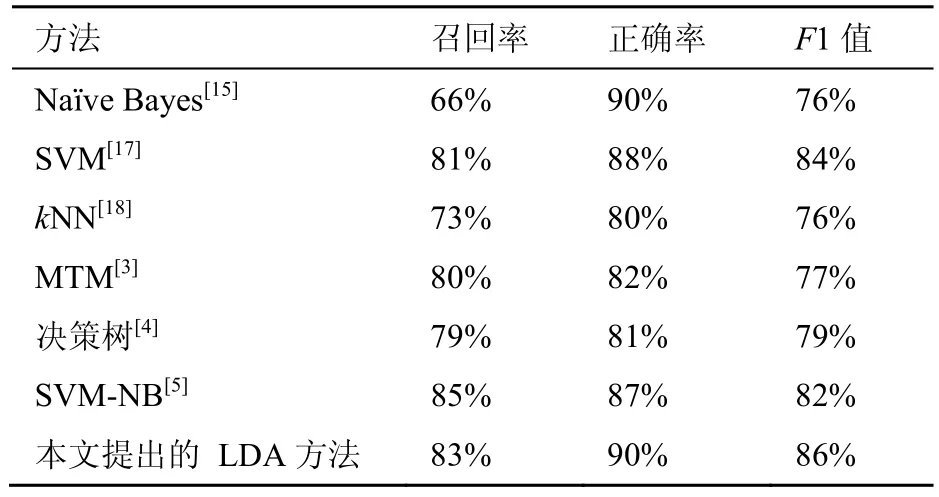
表4 各种不同方法邮件测试结果
由表4可知,本文基于LDA的垃圾邮件过滤方法使垃圾邮件的召回率相比Naïve Bayes方法、SVM方法、kNN方法、MTM方法、决策树方法有很大提升,分别上升了17%、2%、10%、3%、4%;识别正确率和Naïve Bayes相同,而相比SVM方法、kNN方法则分别提高了2%、10%;F1值相比Naïve Bayes方法、SVM方法、kNN方法、MTM方法、决策树方法以及SVM-NB方法分别提高了10%、2%、10%、3%、4%、2%。
在基于决策树三步邮件过滤方法中,它利用决策树模型构建了三步法垃圾邮件过滤模式。对于SVM-NB算法,它提出了基于朴素贝叶斯分类器的训练集分类方法,提升了数据处理的顽健性,此方法能够达到较高的垃圾邮件检测精度。相比于这两种方法,本文推出的LDA算法能够更好地提取文本特征,从而达到更高的分类精度。基于LDA的垃圾邮件过滤方法在垃圾邮件正确率方面和 Naïve Bayes方法相同,在垃圾邮件的召回率方面高于这3种方法,并且具有较高的F1测试值。这说明该方法在性能上要优于Naïve Bayes、SVM、kNN方法。
(2)采用不同主题数的结果比较
在实验(1)中,选择主题数为20个,主题词为10个,共完成了5组实验,并且与另外3种邮件过滤方法进行了比较。在本实验中选择主题词仍为10个,分别选择主题数为10、15、20、25个进行实验,结果见表5。
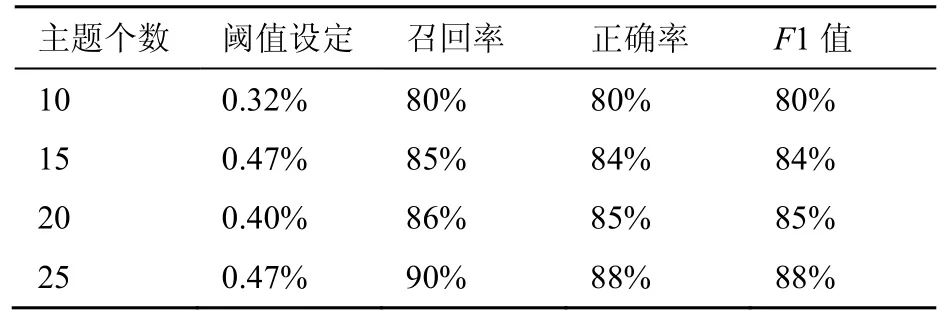
表5 不同主题数下的测试结果
分析实验结果如图4、图5所示,在选取合适阈值的条件下,系统的召回率和正确率随着主题数的增加而提高。其原因是,随着主题数的增加,对测试集邮件的语义划分更明确,进而使得系统的召回率和正确率明显提升。基于这样的原理,本方法可以取得较好的垃圾邮件过滤结果。4.2.3 基于改进的主题垃圾邮件过滤方法实验结果与分析
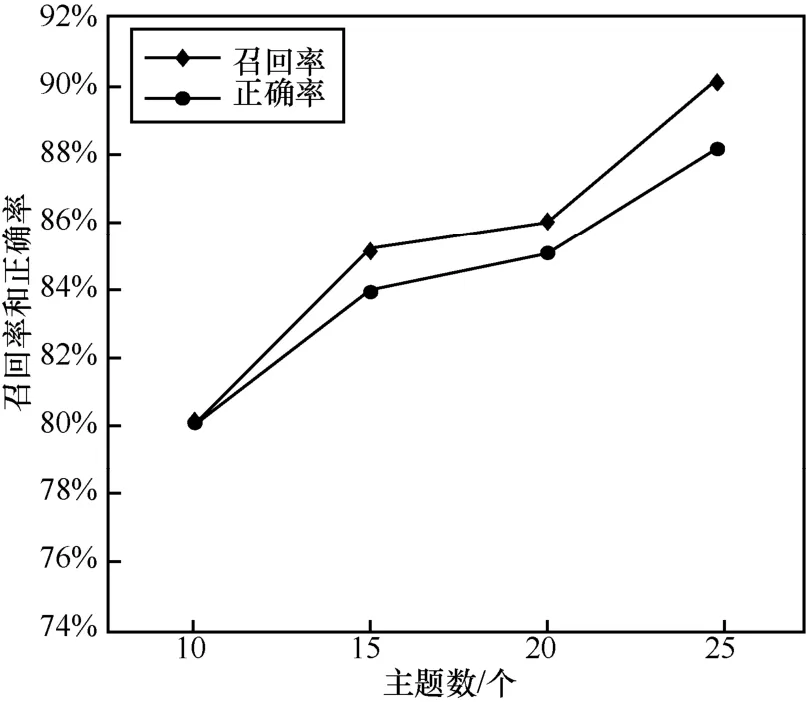
图4 不同主题数下的召回率和正确率

图5 不同主题数下的阈值
改进的方法主要将获得的主题进行扩展,用Word2Vec方法得到每个主题中词的几个相关的词,将获得的词重新构建主题组。
下面列举几个主题词经过 Word2Vec计算后得到的结果,如图6所示。
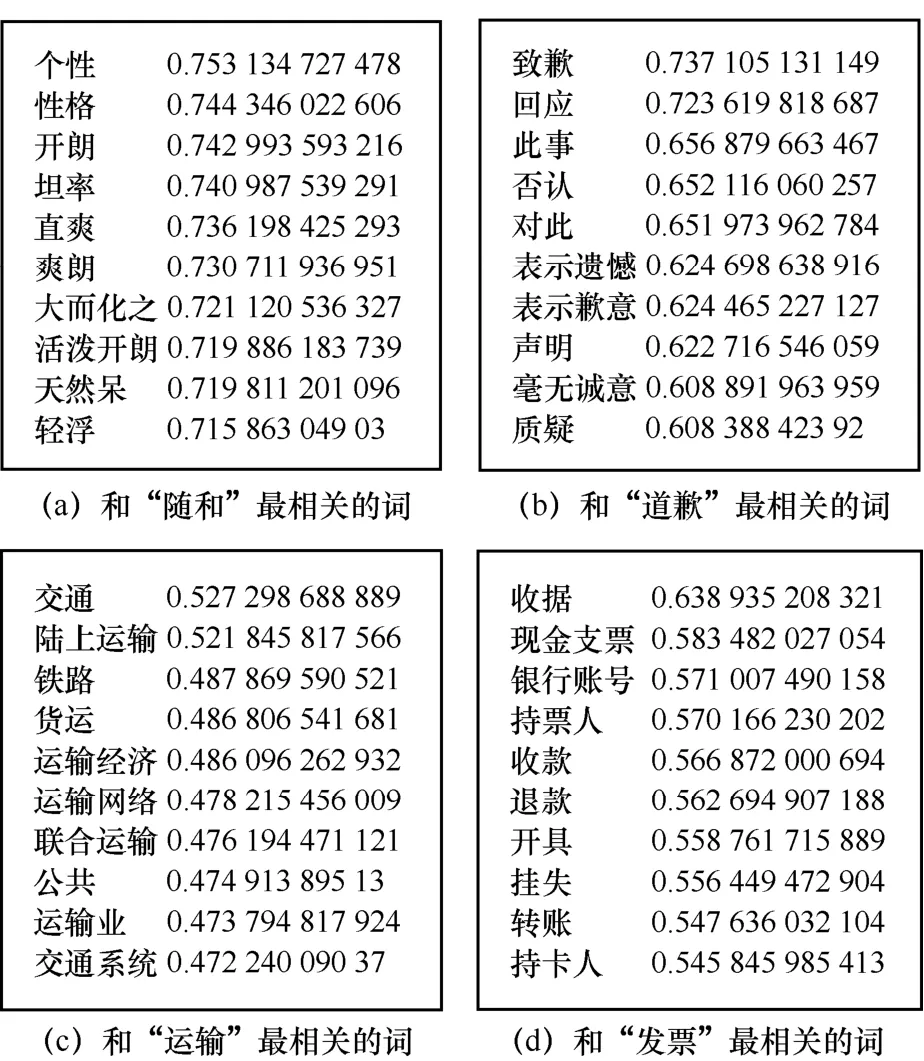
图6 主题词经过Word2Vec计算后得到的结果
以其中一个主题为例,通过Word2Vec扩展原主题词为12个词,见表6。

表6 原主题与扩展主题
这里实验过程分两个步骤。
步骤1 将重建的主题组再次经LDA算法获得权值矩阵。
步骤2 再用测试集进行测试,得到最终的实验结果。
在本实验中选择主题数为 20个,主题词由10个扩展为12个,共完成了5组实验。
测试结果见表7。

表7 基于Word2Vec改进的垃圾邮件过滤方法测试结果
分析表7,改进方法在增加2个关联主题词的情况下,在F1值上比原方法改进明显,在5次实验中有3次获得了较大的提高,证明了改进方法的有效性。
5 结束语
本文对基于主题模型的垃圾邮件过滤系统的设计与实现进行了分析和验证,与传统的关键词检测过滤技术相比,贝叶斯过滤算法更加有效且智能,从而提升了系统的安全性与顽健性。通过与其他典型垃圾邮件过滤方法的对比及验证,证明基于主题模型的垃圾邮件分类方法及基于Word2Vec的改进方法均能有效提高垃圾邮件过滤的准确度。
在未来的研究中,基于语义的文本分类具有非常大的潜力。针对自然语言的具体层次结构,机器学习与深度学习的方式已经在其他领域表现出非常强大的处理能力。在这种背景下,邮件拦截方法的设计可以参考相关研究成果进行深入探索。总之,未来的邮件拦截系统将会具有非常大的改进空间,因此相关的研究需要被重点关注。
[1] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[2] 祝毅鸣, 张波. 实时黑名单在垃圾邮件过滤系统中的应用[J].科技资讯,2012(12):33.ZHU Y M, ZHANG B. Application of real time blacklist in spam filtering system[J]. Science & Technology Information,2012(12):33.
[3] MA J, ZHANG Y, WANG Z, et al. A message topic model for multi-grain SMS spam filtering[J]. International Journal of Technology & Human Interaction, 2016, 12(2):83-95.
[4] SHEN J J, CHEN Y K, CHU K T, et al. An intelligent three-phase spam filtering method based on decision tree data mining[J]. Security & Communication Networks, 2016, 9(17):4013-4026.
[5] FENG W, SUN J, ZHANG L, et al. A support vector machine based naive Bayes algorithm for spam filtering[C]// 2016 Performance Computing and Communications Conference, Dec 9-11, 2016, Las Vegas, NV, USA. New Jersey: IEEE Press,2017:1-8.
[6] BANSAL R P, HAMILTON I R A. O'CONNELL B M, et al.System and method to control email whitelists: US, US 8676903 B2[P]. 2014.
[7] CHAN P P K, YANG C, YEUNG D S, et al. Spam filtering for short messages in adversarial environment[J]. Neurocomputing,2015, 155(C):167-176.
[8] DEVI K S, RAVI R. A new feature selection algorithm for Efficient Spam Filtering using Adaboost and Hashing techniques[J].Indian Journal of Science & Technology, 2015, 8(13).
[9] AFZAL H, MEHMOOD K. Spam filtering of bi-lingual tweets using machine learning[C]// International Conference on Advanced Communication Technology, Jan 31-Feb 3, 2016,Pyeongchang, South Korea. New Jersey: IEEE Press, 2016.
[10] DAS M, BHOMICK A, SINGH Y J, et al. A modular approach towards image spam filtering using multiple classifiers[C]//2014 IEEE International Conference on Computational Intelligence and Computing Research. Dec 20, 2014, Coimbatore, India. New Jersey: IEEE Press, 2015:1-8.
[11] 曹玉东, 刘艳洋, 贾旭, 等. 基于改进的局部敏感散列算法实现图像型垃圾邮件过滤[J]. 计算机应用研究, 2016,33(6):1693-1696.CAO Y D, LIU Y Y, JIA X, et al. Image spam filtering with improved LSH algorithm[J]. Application Research of Computers,2016, 33(6):1693-1696.
[12] 徐凯, 陈平华, 刘双印. 基于 Adaboost-Bayes算法的中文文本分类系统[J]. 微电子学与计算机, 2016, 33(6):63-67.XU K, CHEN P H, LIU S Y. A Chinese text classification system based on Adaboost-Bayes algorithm[J]. Microelectronics & Computer, 2016, 33(6):63-67.
[13] 周庆良. 一种基于 Adaboost和分类回归树的垃圾邮件过滤算法[D]. 武汉: 华中科技大学, 2016.ZHOU Q L. A spam filtering algorithm based on Adaboost and classification regression tree[D]. Wuhan: Huazhong University of Science and Technology, 2016.
[14] SMITH D A, MCMANIS C. Classification of text to subject using LDA[C]//2015 IEEE International Conference on Semantic Computing (ICSC), Feb 7- Feb 9, 2015, Anaheim, CA, USA.New Jersey: IEEE Press, 2015: 131-135.
[15] 赵治国, 谭敏生, 李志敏. 基于改进贝叶斯的垃圾邮件过滤算法综述[J]. 南华大学学报: 自然科学版, 2006, 20(1): 33-38.ZHAO Z G, TAN M S, LI Z M. Review of spam filter algorithms based on improved Bayes[J]. Journal of Nanhua University(Science and Technology), 2006, 20(1): 33-38.
[16] 林巧民, 许建真, 许棣华, 等. 基于贝叶斯算法的垃圾邮件过滤技术[J]. 南京师范大学学报: 工程技术版, 2005, 5(4):61-64.LIN Q M, XU J Z, XU D H, et al. Research on Bayes-based spam filtering[J]. Journal of Nanjing Normal University(Engineering and Technology), 2005, 5(4): 61-64.
[17] LI L, MAO T, HUANG D. Extracting location names from Chinese texts based on SVM and KNN[C]// 2005 IEEE International Conference on Natural Language Processing and Knowledge Engineering(IEEE NLP-KE'05), Oct 30-Nov 1, Wuhan,China. New Jersey: IEEE Press, 2005: 371-375.
[18] 林文香. 改进的KNN算法在过滤垃圾邮件中的应用研究[D].长沙: 湖南大学, 2010.LIN W X. Application of improved KNN algorithm in spam e-mail filtering[D]. Changsha: Hunan University, 2010.
Design and implementation of spam filtering system based on topic model
KOU Xiaohuai, CHENG Hua
College of Information Science and Engineering, East China University of Science and Technology, Shanghai 200237, China
Spam filtering technology plays a key role in many areas including information security, transmission efficiency, and automatic information classification. However, the emergence of spam affects the user's sense of experience, and can cause unnecessary economic and time loss. The deficiency of spam filtering technology was researched, and a method of spam classification based on naive Bayesian was put forward based on multiple keywords.In the subject of mail, the theme model was used by LDA to get the related subject and keyword of the message, and Word2Vec was further used to search keyword synonyms and related words, extending the keyword collection. In the classification of mails, the transcendental probability of the words in the training dataset was obtained by statistical learning. Based on the extended keyword collection and its probability, the joint probability of a subject and a message was deduced by the Bayesian formula as a basis for the spam judgment. At the same time, the spam filtering system based on topic model was simple and easy to apply. By comparing experiments with other typical spam filtering method, it is proved that the method of spam classification based on theme model and the improved method based on Word2Vec can effectively improve the accuracy of spam filtering.
text classification, spam, topic model, Bayesian theory
TP393
A
10.11959/j.issn.1000−0801.2017313
2017−05−12;
2017−09−16
寇晓淮(1989−),男,华东理工大学信息科学与工程学院硕士生,主要研究方向为信息分析与处理、智能信号处理和网络与信息安全。

程华(1975−),男,博士,华东理工大学信息科学与工程学院副教授,主要研究方向为信息安全、信号处理、网络行为学和流量工程。
猜你喜欢
承德医学院学报(2022年2期)2022-05-23
英语文摘(2021年10期)2021-11-22
潍坊学院学报(2020年2期)2021-01-18
疯狂英语·新阅版(2020年11期)2020-12-21
网络安全和信息化(2018年4期)2018-11-09
车迷(2018年12期)2018-07-26
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
现代计算机(2016年11期)2016-02-28
电子器件(2015年5期)2015-12-29
