
基于关联规则模型的商品分类问题研究
2017-12-02 18:56伏兰兰黄秋萍卢叶园廖静甘宇健
软件导刊 2017年11期
伏兰兰 黄秋萍 卢叶园 廖静 甘宇健

摘要:关联规则是数据挖掘的重要方法之一, Apriori是传统关联规则中的经典算法。提出基于大量商品价格的数据集,分别建立单维和二维商品价格关联规则模型,挖掘单维和二维商品价格的强关联规则。通过对比分析单维和二维商品价格强关联规则,以发现同类或价格关联度高的相关产品。
关键词关键词:关联规则;商品分类;Apriori算法
DOIDOI:10.11907/rjdk.171888
中图分类号:TP319
文献标识码:A文章编号文章编号:16727800(2017)011018303
0引言
1993年Agrawal等[12]提出了第一个关联规则挖掘算法AIS,但性能较差。随后于1994年提出了项目集格空间理论,并依据该理论提出了著名的Apriori算法。1999年Pasquier等[3]研究人员提出了闭合项目集挖掘理论,得出基于此理论的CLOSE算法。2000年HanJiawei等[4]为了提高挖掘效率,减少对原数据集的读取次数及候选频繁项目集生成,提出了FP_GROWTH算法。但关联规则挖掘算法依然存在问题:筛选出的规则过多,不能得到真正实用的规则。杨刚[5]以房地产交易价格为研究对象,从房地产交易数据中挖掘得到关联规则,对未来房地产价格进行预测。刘志勇[6]研究频繁模式挖掘算法,提出将部分关联规则挖掘算法与并行计算技术结合。孟月昊等[7]提出一种基于规则前后部约束的关联规则挖掘算法AR_F&R。该算法根据用户需求,构造指定关联规则的前后部项集,得出针对用户需求的频繁项集和关联规则。本文利用计算机爬虫在网上抓取的商品价格数据,以Apriori算法建立单维和二维商品价格关联规则模型,挖掘出同时满足最小支持度和最小置信度的强关联规则,并对比分析单维和二维关联规则结果,由此对商品进行分类,利用分类结果对同类或相关度高的商品进行价格预测。
1关联规则理论
1.1关联规则挖掘原理
数据挖掘是指运用某一种方法分析数据,从中得到一些潜在的有用的信息,又称知识发现。关联规则挖掘是数据挖掘的重要方法,是从大量数据中挖掘出事物之间可能存在的某种关联或联系,最著名的案例就是啤酒与尿布的故事。关联规则可以定义为:假设给定一个交易数据集T,T由n个不同项目P和m个不同交易天数组成。如果有X→Y,就说X→Y是一条关联规则。其中XP,YP,X是关联规则的前件,Y是关联规则的后件。在关联规则挖掘过程中,需要先设置最小支持度和最小置信度,将满足条件的规则提取出来形成有价值的信息。挖掘工作分为两个步骤:①生成频繁项集:找出满足最小支持度的频繁项集;②生成关联规则:从频繁项集中生成满足最小置信度的关联规则。
1.2关联规则衡量指标
关联规则分析中的指标主要有支持度(Support)和置信度(Confidence)。支持度揭示X和Y同时出现的概率,置信度揭示X出现时,Y是否一定会出现。计算公式分别如式(1)和式(2)所示。
Supp(X→Y)=P(X∩Y)(1)
Conf(X→Y)=P(YX)=P(Y∩X)P(X)(2)
式(1)中P(X∩Y)代表支持度,式(2)中P(Y|X)代表置信度。对比式(1)和式(2),发现任何一条关联规则都是Conf(X→Y)≥(Supp(X→Y)。需要注意的是:支持度和置信度只是两个参考值,并非绝对。一条关联规则的支持度表示这条规则的可能性大小,如果一个规则支持度很小,表明它在交易集合中覆盖范围很小,很有可能是偶然发生的;若置信度很低,则表明很难根据X推出Y。若一条关联规则的支持度和置信度都很高,不代表这个规则之间就一定存在某种关联。
1.3Apriori算法
Apriori算法不僅可用来比较和评价其它算法性能,还可用来挖掘关联规则。主要思想是:假设存在某个项目集满足用户设定的支持度,那么该项目集称为频繁项目集。反之,称为非频繁项目集,它的非空子集也是非频繁项目集。同理,频繁项目集的非空子集也是频繁项目集。Apriori算法通过从低级到高级的方式向项目集进行逐层搜索,找出所有的频繁项目集。
2商品价格关联规则模型构建
2.1商品价格数据预处理
本文随机选择160种不同商品进行关联规则挖掘,利用Apriori算法分析不同商品价格之间的关联关系。商品价格数据长度为2013年11月20日至2015年11月20日共730天的价格数据,要求输入数据的维度相同,但笔者获取的数据存在一定的遗漏问题。为了解决维度不相同问题,需要在预处理时对数据进行补齐,补齐方法为将无价格的时间用上一日时间代替,如缺少2014年12月2日的价格则用2014年12月1日的价格代替。补齐数据后还要进一步处理成交易数据集。
商品价格间的关联关系表现为:当Y商品跟随X商品的价格变化时(正向变化或逆向变化),XY商品存在一定关联关系。因此,模型首先把商品的价格数据改成涨跌数据,用当天商品价格与昨日价格数据比较。若当日价格高,则为上涨,标记为1;不变则标记为0;下跌则标记为-1。
2.2模型实现
数据预处理后,需要设置最小支持度和置信度。经过数次调整后,确定了关联规则模型支持度和置信度。其中,设定单维关联规模的最小支持度为0.05,最小置信度为0.8;二维关联规则模型的最小支持度为0.15,最小置信度为0.8。计算完成后发现,商品在大多数时间价格不变,而人们关心的是商品价格波动,所以在筛选关联规则时,将商品价格不变的规则删去,再根据运行结果对商品进行分类。为获取更多信息,模型计算时保留价格不变的数据,以保持数据的完整性。在过滤掉多余的规则(如商品价格不变的规则)后,便可根据结果对商品进行分类,运用分析得出的结果进行价格预测。endprint
3商品价格关联规则分类结果
3.1商品数据的单维关联规则结果
设置最小支持度为0.05,最小置信度为0.8,建立商品价格的单维关联规则模型,结果如表1所示。由表1中的商品关联规则结果可知,维生素A上升→维生素C上升,维生素A下降→维生素E下降,说明维生素A、维生素C和维生素E三者之间的关联紧密。另外,从醋酸丁酯下降→醋酸乙酯下降、涤纶FDY下降→涤纶POY下降两条关联规则可知,醋酸丁酯和醋酸乙酯、涤纶FDY和涤纶POY这两对商品各自关联紧密。
较为意外的规则是:丁二烯下降→镀锌板下降,钴业下降→镀锌板下降,两者的支持度和置信度也颇高。进一步调查发现,丁二烯可作为制造镀锌板的防腐层涂料,所以不难理解其关联性,但是否就此归类还需进一步分析。至于钴业和镀锌板二者存在什么关系,需要收集更多数据加以验证。
此外,其它关联规则支持度,如“多晶硅上升→维生素E下降”和“党参上升→冷轧板下降”两个关联规则的支持度相对较小,进一步研究发现从2013年11月20日到2015年11月20日维生素E和冷轧板的价格基本上一直在下降,这种单边走势容易产生伪关联规则,导致用户得到错误结论。存在类似问题的规则还有六氟丙烯下降→维生素E下降和木糖醇下降→维生素E下降,防止类似问题的发生可通过对更长的价格数据进行关联分析。
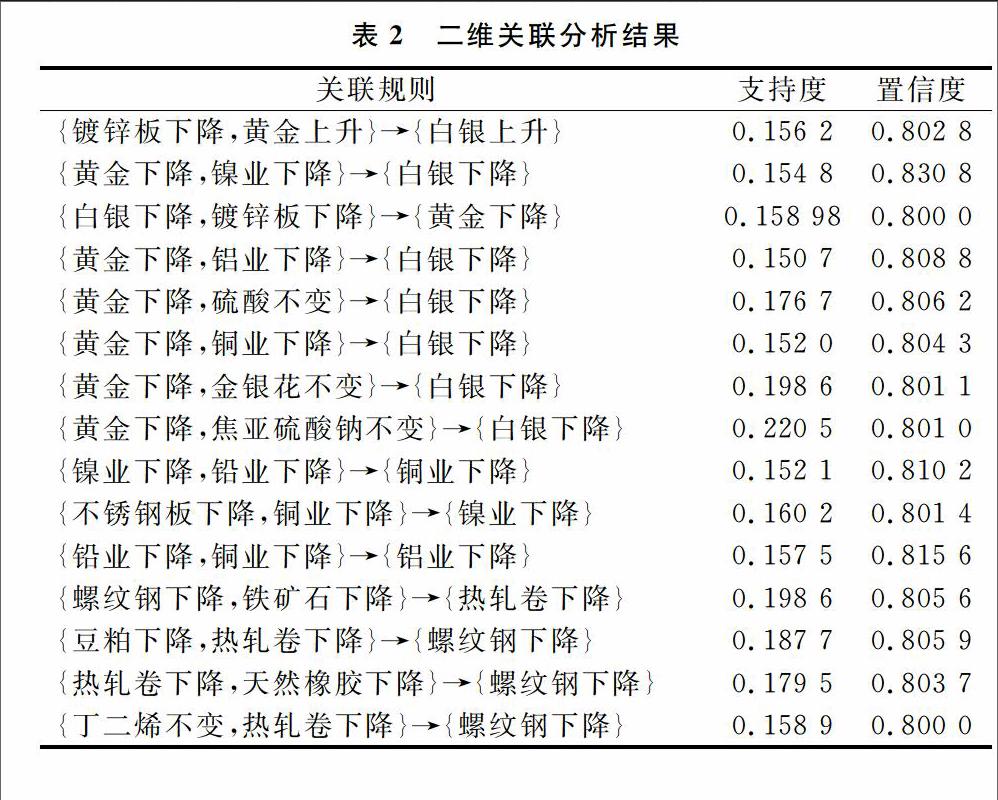
3.2商品数据的二维关联规则结果
计算完单维关联规则后,将最小支持度调整为0.15,进行二维关联规则挖掘,以提取出更有价值的规则。为了避免得到与单维关联规则前件和后件相同的二维关联规则,将二维关联规则中的前件和后件同时存在的规则删去。例如:存在规则{维生素A上升,大豆上升}→{维生素C上升},因该规则中的前件“维生素A上升”和后件“维生素C上升”同时出现在表1的规则中,可删去。根据这一筛选原则,提取出满足最小支持度和最小置信度的二维关联规则,结果如表2所示。由表2可知,在进行二维关联规则挖掘后,发现多条二维关联规则中同时包含黄金和白银或螺纹钢和热轧卷或铝业、铜业、镍业和铅业。因此可认为金银产品、螺纹钢和热轧卷及铝业、铜业、镍业和铅业这3类商品分别有着各自的关联性。
4结语
本文基于关联规则Apriori算法,分别建立了单维和二维商品价格关联规则模型,并对随机选取的160种商品价格数据进行分析。单维模型结果分析,可将维生素A、维生素C和维生素E,醋酸丁酯和醋酸乙酯,涤纶FDY和涤纶POY分为3类商品;二维模型结果分析,可将金银产品、螺纹钢和热轧卷及铝业、铜业、镍业和铅业分为3类商品。通过对比还发现,二维关联规则的模型结果包含了一维关联规则结果,说明通过建立多维关联规则模型,可挖掘出更多符合条件的关联规则。
在今后的研究工作中,要继续优化模型,提出更合理的商品价格关联模型,对更多商品进行正确分类。
参考文献参考文献:
[1]AGRAWAL, RAKESH. Mining association rules between sets of items in large databases[J].ACM SIGMOD Record,1993,22(2):207216.
[2]AGRAWAL, RAKESH, SRIKANT,et al. Fast algorithms for ming association rulers[M]. Readings in database systems, Morgan Kaufmann Publishers Inc,1998.
[3]NICOLAS PASQUIER, YVES, YVES BASTIDE, et al. Efficient mining of association rules using closed itemset lattices[J]. Information Systems,1999,24(1):2546.
[4]HAN JIAWEI, PEI JIAN,YIN YIWEN. Mining frequent patterns without candidate generation[C].Proc of the ACM SIGMOD International Conference on Management of Data. New York,NY:ACM,2000:112.
[5]楊刚.基于数据挖掘的房地产价格分析预测研究[D].南昌:南昌大学,2014.
[6]刘智勇.关联规则挖掘的并行化算法研究[D].南京:东南大学,2016.
[7]孟月昊,王朝霞,郭宇栋.基于规则前后部约束的关联规则挖掘算法[J].后勤工程学院学报,2017(5):125128.
责任编辑(责任编辑:杜能钢)endprint
