
基于LDA主题相似度的SVM迁移学习
2017-12-01 06:43白治江
网络安全与数据管理 2017年22期
唐 亚,白治江
(上海海事大学 信息工程学院,上海 201306)
基于LDA主题相似度的SVM迁移学习
唐 亚,白治江
(上海海事大学 信息工程学院,上海201306)
针对文本分类领域中的迁移学习方法,提出了一种基于LDA(LatentDirichletAllocation)主题生成模型相似度的支持向量机(SVM)迁移学习新思路。基于此思想,提出了迁移学习算法LDA-TSVM。本算法通过对目标域的主题进行分类,依据主题分类信息熵对训练数据进行筛选,分别计算每个训练样本的权重,使得训练集与目标集有很高的相似度,从而达到迁移学习的目的。本算法不仅未引入辅助集,而且还考虑了样本本身的差异,有效地提高了源域数据集与目标域数据集的相似性。实验结果表明了新迁移算法的有效性。
迁移学习;LDA;信息熵;分类;支持向量机
0 引言
传统的机器学习是建立在两个基本的假设上:(1)用于学习的训练数据与测试数据服从相同的数据分布;(2)必须有足够可利用的训练样本。然而这些条件在许多实际应用中并不成立。通常,新的数据领域中只有少量的有标记数据,而直接对该领域数据进行大量的人工标注代价昂贵,甚至可能不存在大量的样本供用户进行标注。然而人们在其他相关领域中已经积累了大量数据,尽管它们可能已经过时,但仍然包含一些可供借鉴的知识。这正是迁移学习所要解决的问题[1-3]。
迁移学习是指通过已有的知识来学习新的知识,从而解决新的问题。例如人的举一反三能力,学会C语言的人,对Java和Python等其他语言也可以很快掌握;会下象棋的人,学习国际象棋也会很容易。这就是人类在相似领域通过知识的迁移解决新的问题的能力。然而,传统的机器学习和数据挖掘中仅仅只关注同一个领域或相同的任务,即学会了下象棋,对国际象棋的学习也没有任何帮助,从头学习反而浪费了大量的时间和精力。根据源域和目标域的相似度,可以将迁移学习分为归纳式迁移学习、无监督迁移学习和直推式迁移学习。其中归纳式迁移学习是目前研究的热门,即源域包含有大量标签数据,而目标域已标签的数据不足以训练可用的模型,同时源域和目标域分布不同。
本文研究的同样是归纳式迁移学习,提出了一种新的归纳式迁移学习算法(LDA-TSVM),该算法是基于主题模型相似度,依据信息熵对训练集进行筛选,选出与目标相关度高的样本数据和少量已标记的目标数据,分别计算出每个样本的权重,最后用SVM进行训练,将原始领域学习到的模型成功迁移到目标领域。
1 LDA模型
LDA模型是一种文档主题生成模型。它是非监督机器学习技术对文本数据的主题信息进行建模的方法。它有3层生成式贝叶斯网络结构[4],基于这样一种前提假设:文档是由若干个隐含主题构成,而这些主题是由文本中若干个特定词汇构成,忽略文档中的句法结构和词语出现的先后顺序[5]。其结构图如图1所示,LDA模型的层次结构依次为文档集合层、主题层(C1,C2,…,Cn)和特征词层。
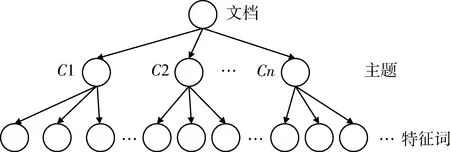
图1 LDA模型隐含主题的拓扑结构示意图
如图2所示,LDA模型是有向概率图模型[6],α和β表示语料级别的参数,其中α是与文档中主题分布相关的狄利克雷超参数,β是各个主题对应的单词概率分布相关的狄利克雷超参数,一般依据经验提前设定。 本文依据LDA概率主题模型生成文本的过程[7]对数据集进行主题建模。
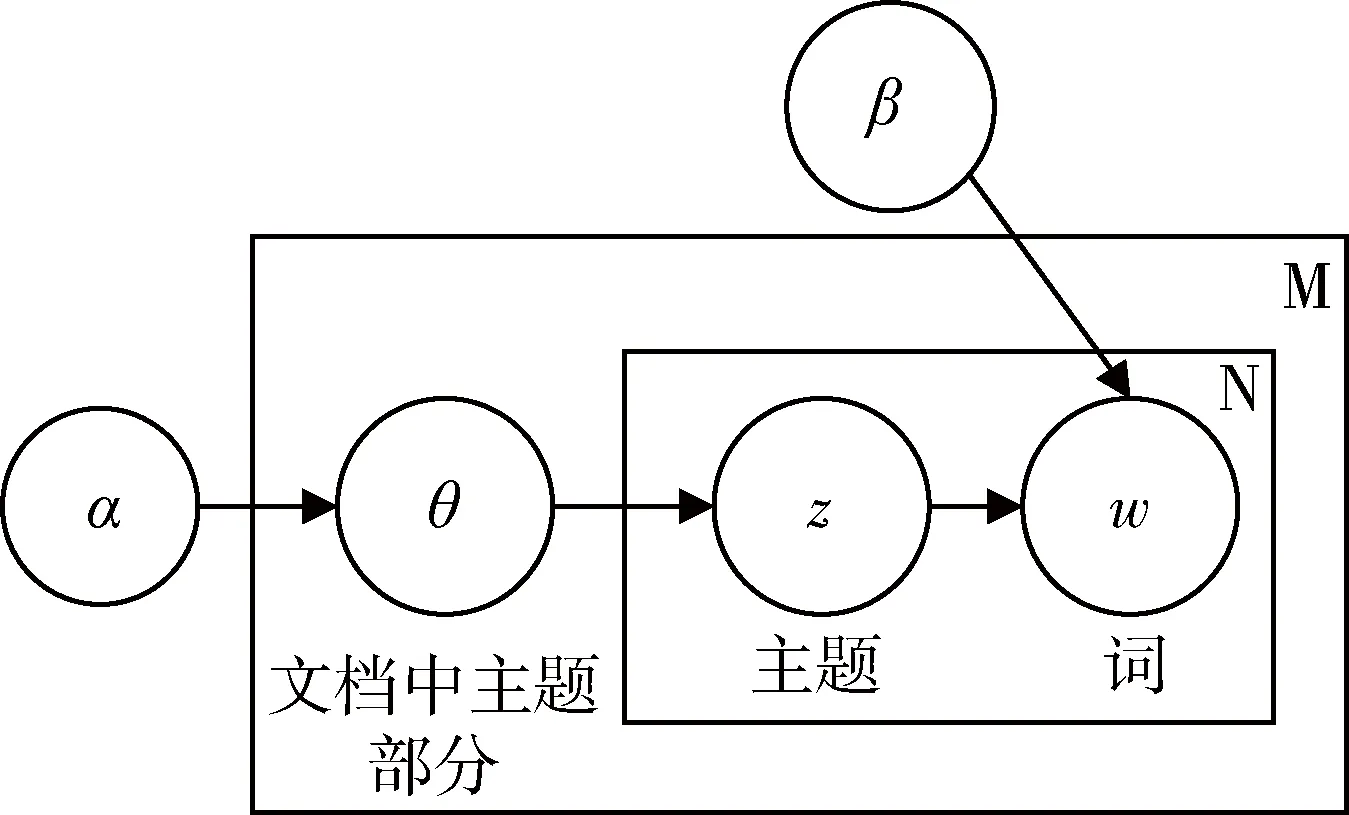
图2 LDA模型有向概率图
2 基于LDA主题相似度的SVM迁移学习方法
本文提出的LDA-TSVM算法主要考虑源域和目标域的主题相似度,从样本本身的差异着手,去除影响迁移效果的噪声数据,达到更好的迁移效果。
2.1LDA-TSVM算法思想
LDA-TSVM算法思想是,对相似但不相同的两个领域数据Td、Ts(Td为训练样本集,Ts为目标样本集)分别做LDA主题模型分类,在LDA建模时需要对所建模型做相应的评估,即在对文本进行LDA迭代时,依据信息熵的理论得到信息熵最小的一次迭代系数,即为LDA模型的迭代参数的最优解。当获得最优主题分类模型后,通过对训练集和目标集的主题进行相似度的计算筛选出训练样本主题集中相似度最高的几个主题。将以上筛选出的主题中的所有训练样本以及少量已标签的目标集样本共同作为最终的训练集,对训练集加上相应的权重值后,通过分类器SVM进行训练。图3即为LDA-TSVM算法模型的流程框架图。
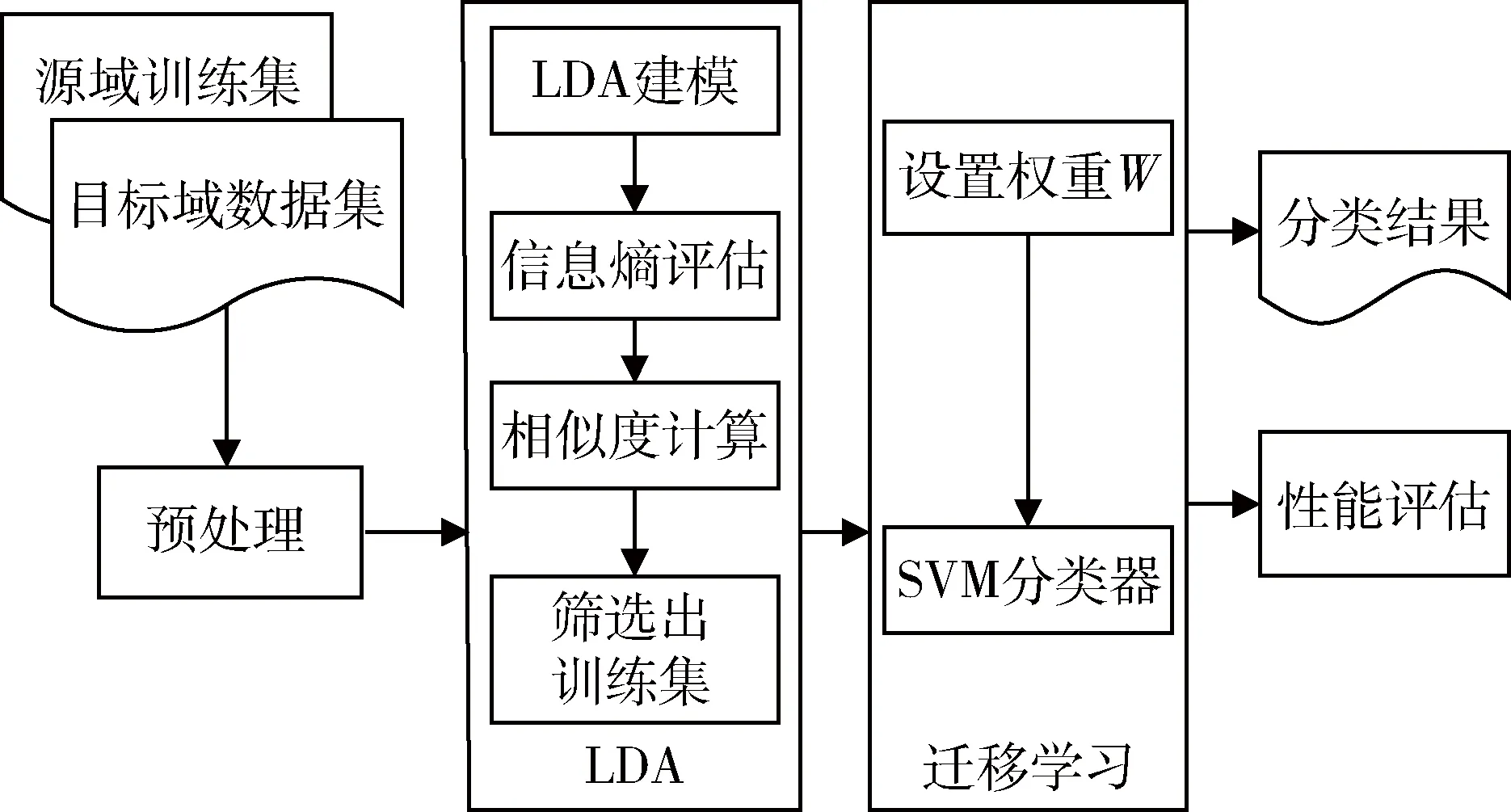
图3 LDA-TSVM算法模型的流程框架图
2.2LDA-TSVM算法流程
基于以上思想设计的基于主题相似度的SVM迁移学习算法LDA-TSVM如下:
输入:Td,Ts;
输出:h;
(1)对训练集Td、目标集Ts分别做LDA主题模型分类,得到训练集主题TopicDi(i=1,2,3,…,m)、文档主题概率矩阵Ad和主题词概率矩阵Bd、目标集主题TopicSj(j=1,2,3,…,n)、文档主题概率矩阵As和主题词概率矩阵Bs;
(2)对LDA主题模型分别进行评估,分别计算训练集样本分布类的信息熵以及目标域中已标记T的样本分布类信息熵,得到最优的LDA迭代参数K,L;
(3)计算训练集和目标集的主题相似度,筛选出训练集中与目标集主题相似度最高的N(1≤Nlt;m)个主题;
(4)为每个筛选后的训练集Td增加权重W=1+Pd(Pd为Ad中每个文档相对该主题的概率),已标记的目标集T的权重设为1;
(6)用SVM在集合Ntrain上训练,得到分类器h;
(7)结束。
2.3LDA信息熵评估
在以上应用LDA对测试集和目标集进行主题分类时,对于LDA主题分类模型的评估,即算法的迭代参数进行选择时,应用到了信息论中信息熵的理论。
熵这个概念来自于统计热力学,它是系统混乱程度的量度,若系统的混乱程度越高,则其熵值就越高;反之,若系统是接近有序的,则其熵值越低。信息理论中,熵通常也称作信息熵或Shannon熵,用熵来表示不确定性和无组织性的度量,它主要刻画信息含量的多少。
因此在LDA模型里,依据以上理论推断,信息熵越小,分类的模型纯度越高,效果越好。经过实验表明,该评估方法是有效的。现进行如下定义:类别标签数C,LDA主题建模后的主题数为N,主题Tj=(t1,t2,t3,…,tN),j为LDA迭代次数,ti为第j次迭代的第i个主题,信息熵函数为H(),数据集为D,主题ti下的文档集为Di,数据集的文档个数为D。则有以下公式:
(1)
其中根据信息熵公式,对于任意一个随机变量C,每个主题的信息熵Hi有:
(2)
其中P(c)为该主题下文本属于类c的分布概率。
根据之前的推断,可得到信息熵取最小值时的迭代系数Tmin:

(3)
Tmin即为LDA模型的迭代参数的最优主题划分。
2.4相似度计算
当获得最优主题分类模型后,假设m为训练集主题数,n为目标集主题数,接下来一步便是训练集和目标集的主题相似度的计算。本算法应用了欧几里得最小距离,其思想是算出每个训练集主题的词向量对于每个目标集主题的词向量的相似度Sij(i=1,2,3,…,m,j=1,2,3,…,n),选择每个训练集主题对于所有目标集主题的最小值作为这个主题对于目标集的距离Si(i=1,2,3,…,m),即Si=minSij(j=1,2,3,…,n)。筛选出相似度最高的N(1≤N≤m)个主题作为最终的训练集。若训练集词向量为Vd,目标集主题词向量为Vs,则其中两向量之间相似度S算法的算法流程如下:
输入:Vd,Vs;
输出:S;
(1)依次提取训练集词向量Vd=(x1,x2,x3,…,xk),目标集主题词向量Vs=(y1,y2,y3,…,yl);
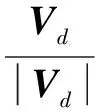

(4)对两向量做欧几里得距离计算:
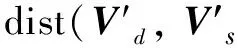
(4)
(5)结束。
3 实验设计与结果分析
3.1实验数据
本文实验数据集是20Newsgroup,它是文本分类中常用的语料库,分为7个大类别和20个子类别,大约20 000个新闻类文档。使用与文献[8]中相类似的预处理方法来生成本文所需要的数据集分布,即将大类别下不同子类别的数据重新组合来生成原始领域和目标领域数据集,使得原始领域和目标领域的分布相似但分布不相同。如表1所示,从rec大类中选择autos和motorcycle小类,从talk中选择politics.guns和politics.mics小类,用这四小类作为训练集,其中rec类的样本为正,talk类的样本为负。然后以rec大类中剩下的sport.basketball小类,talk大类中剩下的politics.mideast小类作为目标集。同理对rec和sci两大类进行重新组合。因为各大类中选取的小类有所不同,这就使得训练集和目标集的分布达到一定的差异性。为了验证其差异性,通过相对熵来进行计算,相对熵又称为KL散度(Kullback-Leibler divergence),常被用来衡量两个概率分布的差异。KL散度的计算公式如下:
(5)
其中p(x)和q(x)为两个概率分布函数。利用公式(5),可计算出实验中训练集与目标集的KL散度分别为1.102和1.055,因此它们的训练集与目标集的分布都达到了实验所需要的差异性。

表1 20Newsgroup数据集分布
3.2实验性能对比
在对数据集进行LDA分类时,依据数据集的数量特点,将训练集主题数选为5,alpha为11,beta为0.01,测试集主题数选为2,alpha为26,beta为0.01,依据第2.3节的理论,计算出训练集迭代次数为500,测试集迭代次数为120。为验证LDA-TSVM算法的有效性,本文分别从传统机器学习和迁移学习两个方面设计多组实验进行了对比,如表2所示。
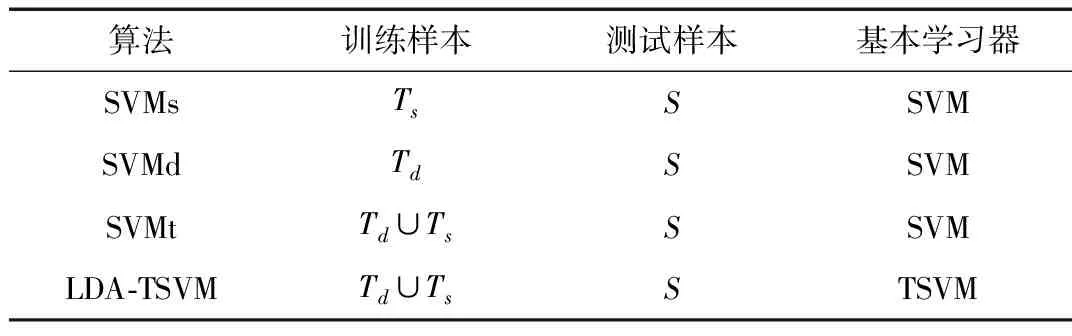
表2 实验中采用的对比算法
表2中,SVMs、SVMd和SWMt分别表示经典的SVMlight[9]算法,它们的训练集分别为Ts、Td、Td∪Ts,经过对比实验结果的精确度以证明本文算法的优越性。以上算法均在Windows 10操作系统、12 GB内存、Intel core i7 2.5 GHZ CPU、Java和Python编程环境下实验。
3.3实验结果与分析
实验中采用Precision、Recall、F1-Measure等数据衡量实验的结果。表3、表4展示了传统机器学习算法和迁移学习算法在数据集上的分类结果。
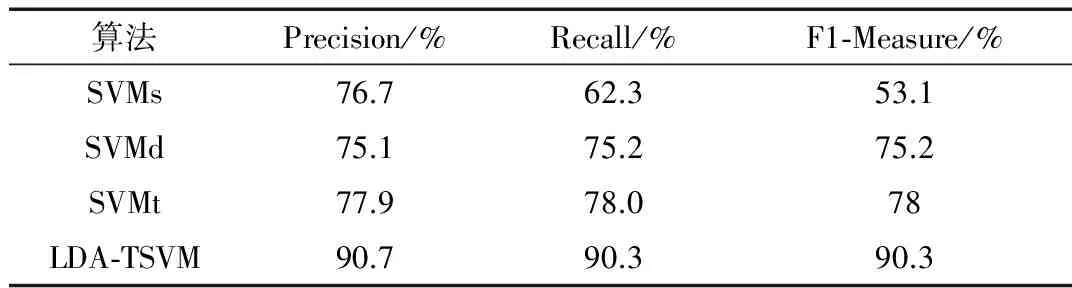
表3 数据集rec/talk的LDA-TSVM实验结果
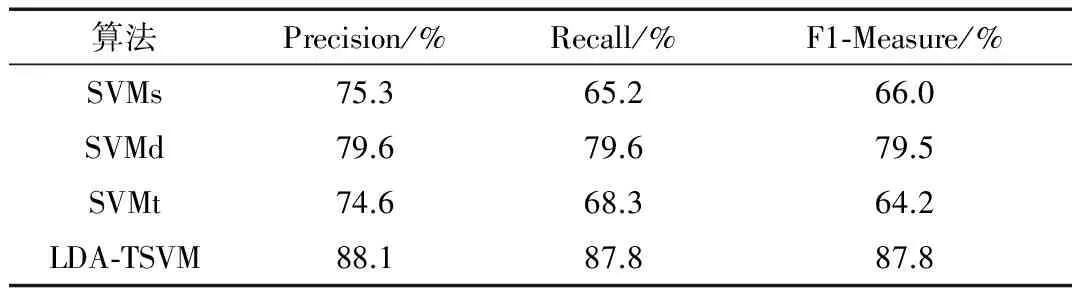
表4 数据集rec/sci的LDA-TSVM实验结果
通过实验结果可以看出,在rec/talk属性的实验中,LDA-TSVM分类比传统的SVM提高了14%,F1-Measure提高了37.2%,Recall值提高了28%,相比于SVMd以及SVMt都有将近15%的提高,这是因为LDA-TSVM算法过滤了训练样本中的有害样本,使得训练集与目标集的相似度有了一定的提高。在属性rec/sci的实验中,从SVMs与SVMt的比较中发现,SVMt的分类结果略差于SVMs,这一现象的出现是由于在SVMt的训练过程中,包含了一些有害样本,使得SVMt算法的训练精度相比于SVMs有所降低,该现象也表明了消除有害样本对迁移学习的重要性。
在实验中还发现,随着目标域数据集中已标签样本数的增加,不同算法的分类精度也有着一定的影响。 实验在rec/talk 数据集上进行。其中已标签样本数依次取样本总数的1%,5%,10%, 20%, 30%, 40%, 50%,分别比较SVMs、LDA-TSVM两方法的分类精度, 如图4所示。
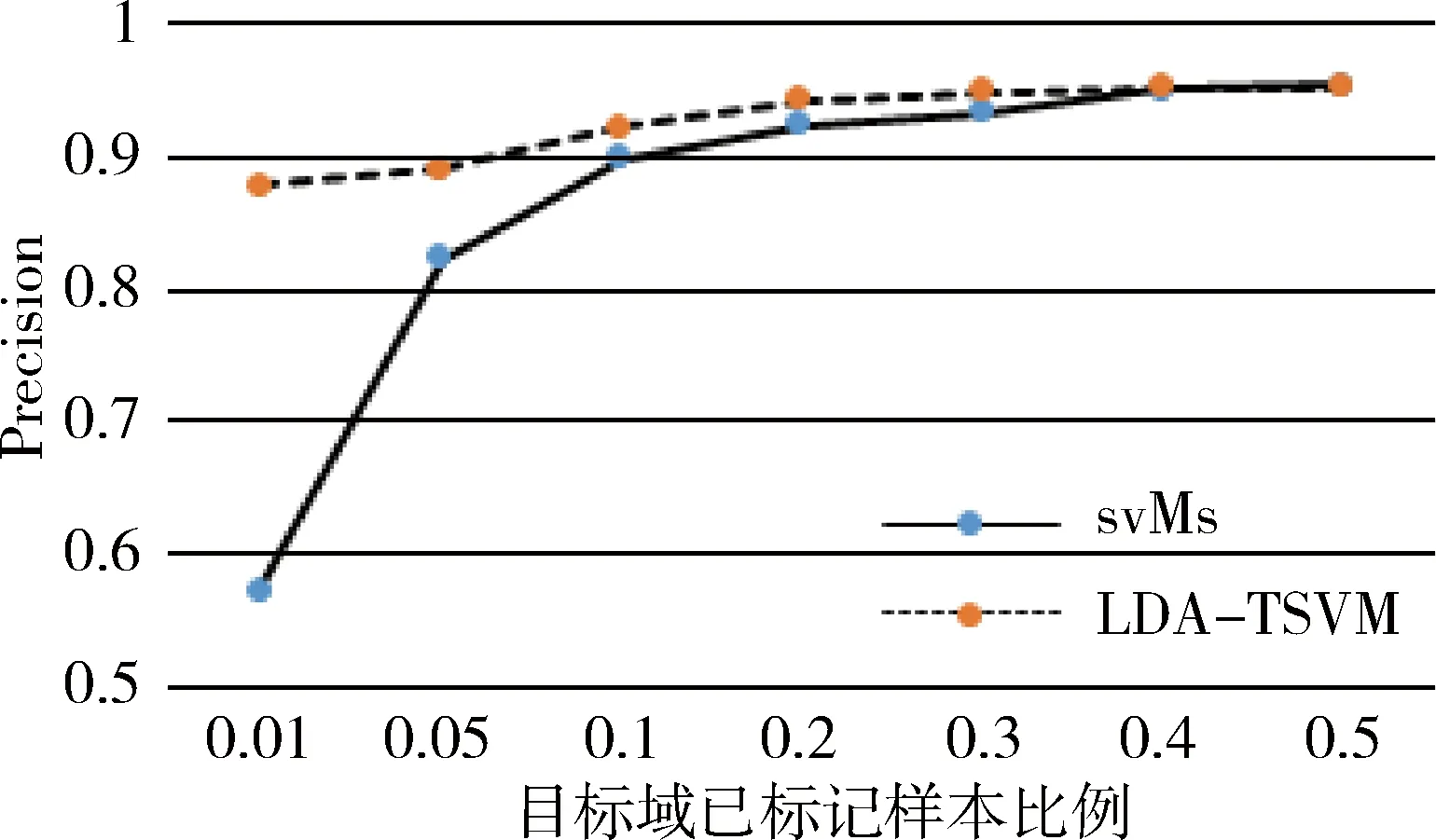
图4 目标域已标记样本变化对分类精度的影响
由图4可知,随着目标域已标记样本数量增加,SVMs分类精度也增加,当比例达到30%时分类精度趋于稳定;当目标域已标记样本小于10%时,LDA-TSVM效果显著高于SVMs,大于10%时效果相当,当增大到50%时,LDA-TSVM效果则不如SVMs,这是因为源域数据集中不仅有有助于目标域训练的有用数据,同时也存在一些有害数据。当已标记样本的数量不足以训练出一个模型时,源域中有用的数据会帮助目标域训练,然而当已标记的样本数足够训练出一个较好的分类模型时,有害数据则会对分类效果产生负作用。
4 结论
本文采用迁移学习的思想,针对数据不同主题分类的相似度计算,依据主题分类信息熵对训练数据筛选出对目标域有用的数据进行训练,从而达到迁移学习的效果,提出了LDA-TSVM算法。如何快速选择合适的参数是一个关键性问题,对本算法性能有很大的影响。使用LDA进行评估的时候去掉部分主题的文档,可能造成数据分布不平衡的问题[10],后续工作会对此深入研究。
[1] PAN S J, Yang Qiang. A survey on transfer learning [J]. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10):1345-1359.
[2] Tao Jianwen, CHUNG F L, Wang Shitong. A kernel learning framework for domain adaptation learning[J]. Science China Information Sciences, 2012, 55(9): 1983-2007.
[3] Tao Jianwen, CHUNG F L, Wang Shitong. On minimum distribution discrepancy support vector machine for domain adaptation[J]. Pattern Recognition, 2012, 45(11):3962-3984.
[4] Dong Xiaolei,Wang Licheng, Cao Zhenfu. New public key cryptosystems with lite certification authority[EB/OL].(2013-3-16)[2017-04-20]http://ePrint.iacr.org/2016/154.
[5] 潘耘, 王励成, 曹珍富,等. 基于轻量级CA的无线传感器网络密钥预分配方案[J]. 通信学报, 2009, 30(3):130-134.
[6] 徐戈, 王厚峰. 自然语言处理中主题模型的发展[J]. 计算机学报, 2011, 34(8):1423-1436.
[7] 张明慧, 王红玲, 周国栋. 基于LDA主题特征的自动文摘方法[J]. 计算机应用与软件, 2011, 28(10):20-22.
[8] Wu Pengcheng, DIETTERICH T G. Improving SVM accuracy by training on auxiliary data sources[J]. ICML’04 Proceedings of the twenty-first International Conference on Machine Learning, 2004.
[9] JOACHIMS T. Learning to classify text using support vector machines[M]. Kluwer Academic Publishers, 2002.
[10] 徐丽丽, 闫德勤. 不平衡数据加权集成学习算法[J]. 微型机与应用, 2015, 34(23):7-10.
2017-04-24)
唐亚(1988-),男,硕士,主要研究方向:信息处理与模式识别。
白治江(1962-),男,博士,副教授,主要研究方向:模式识别、人工智能。
SVM transfer learning based on LDA subject similarity
Tang Ya, Bai Zhijiang
(Information Engineering College, Shanghai Maritime University, Shanghai 201306, China)
In order to discuss the method of transfer learning in the field of text classification, a new transfer learning method of Support Vector Machine (SVM) based on the LDA(Latent Dirichlet Allocation) similarity is presented. Based on this method, this paper proposes transfer learning algorithm LDA-TSVM. By classifying the subject of target domain, the algorithm selects the training data according to the information entropy of subject classification and calculates weights of the training samples respectively to improve the similarity between the training set and the non-classified set, so as to achieve the purpose of transfer learning. This algorithm does not introduce the auxiliary set, and considers the differences of the sample itself, which effectively enhances the similarity between the data set from the source domain and the data set from the target domain. Extensive experiments have verified the efficiency of the new transfer algorithm.
transfer learning; LDA; information entropy; classification; SVM
TP31
A
10.19358/j.issn.1674- 7720.2017.22.017
唐亚,白治江.基于LDA主题相似度的SVM迁移学习J.微型机与应用,2017,36(22):62-65.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
