
基于CPU/GPU处理器的雷达脉冲压缩算法并行机制研究∗
2017-11-28 01:57张云雷席泽敏
舰船电子工程 2017年10期
彭 培 张云雷 李 轲 席泽敏
(海军工程大学电子工程学院 武汉 430033)
基于CPU/GPU处理器的雷达脉冲压缩算法并行机制研究∗
彭 培 张云雷 李 轲 席泽敏
(海军工程大学电子工程学院 武汉 430033)
为实现软件化雷达在不同信号处理器上的实时信号处理,需要研究通用高性能处理器,如CPU和GPU信号处理算法的并行机制。论文以雷达脉冲压缩运算模块为例,重点研究了利用GPU信号处理的并行机制。首先给出雷达脉冲压缩数学模型,然后针对算法实现流程,分别从片上缓存、内核线程和数据并行等方面设计了三种GPU并行优化策略。仿真测试表明,所提出的GPU并行机制与典型多核CPU平台相比,具有更好的实时性能。
CPU∕GPU;并行机制;软件化雷达;脉冲压缩
1 引言
随着数字化技术的不断成熟和发展,雷达系统将逐渐从传统的“以硬件技术为中心,面向专用功能”的专用雷达发展到“以软件技术为中心,面向实际需求”的软件化雷达[1]。传统的雷达系统功能多采用定制的专用电路实现,其紧耦合的特点决定了其硬件开发周期长,费用高等不便因素。软件化雷达通过采用开放式体系结构和通用处理器,可实现应用程序快速开发和升级。由于通用信号处理器特别是GPU处理器,具备通用性好,可扩展易升级等优点[2~3],在软件化雷达中得到重视。同时,近年来随着通用处理器,特别是服务器刀片和GPU处理器的快速发展,在越来越多地基雷达中获得应用。为适应雷达信号处理大容量大吞吐率要求,必须研究针对通用信号处理器的并行算法实现机制。当前,已经有不少关于GPU进行并行信号处理的论文[4~5],但是关于GPU并行化机制的研究并不多见。
本文以雷达信号处理典型算法——脉冲压缩算法为例,探讨通用信号处理器并行机制的实现。脉冲压缩是将发射的大时宽带宽积信号[6~7],通过匹配滤波器,输出窄脉冲信号,以解决平均功率和距离分辨力之间的矛盾,使雷达提高检测能力的同时不会降低距离分辨力。本文将基于CPU∕GPU的并行计算引入软件雷达脉冲压缩信号处理中,利用GPU细粒度多线程并发和适宜密集计算的特点发掘雷达信号处理潜在的并行性,从而利用GPU加速雷达信号处理运算速度。
2 脉冲压缩算法模型
脉冲压缩可以在时域实现,也可以在频域实现。时域实现是利用FIR滤波器实现时域脉冲压缩,时域脉压处理方法比较直观。当距离单元数较小时,相对运算量不大,采用时域脉压处理也可以满足实时性要求。但是当距离单元数很大,时域卷积的运算量很大,这时宜采用频域脉冲压缩方法[8]。为了提高运算速度,离散傅里叶变换可以采用快速傅里叶变换实现。如果采样数据长度为i点,需要将信号和匹配滤波器系数做2N≥i点离散傅里叶变换(DFT)变换。最后将雷达回波与匹配滤波器频域响应系数相乘,再经过IFFT变换,得到脉冲压缩处理结果。频域脉压处理实现如图1所示。

图1 脉冲压缩频域实现框图
由于匹配滤波器是与输入线性调频脉冲信号完全匹配,故噪声信号保持在原有电平上,而输出信号的峰值功率提高了D=τ⋅B倍。故采用脉冲压缩技术的雷达,使得在相同发射功率条件下,可有效改善信号信噪比,同时宽脉冲信号压缩成窄脉冲信号,具有良好的测距精度和距离分辨力。
图2是对发射脉冲信号宽度10μs,有效频谱宽度30MHz的线性调频信号的脉冲压缩仿真。脉压前的回波信号中,两个目标在时间上没有足够的分离以至于不能分辨开,然而脉压后目标分离,且识别为两个独立的目标,理论上只要相邻目标时间间隔上相隔 1 B,目标回波就能分开。
3 GPU并行机制优化设计
本文将基于雷达脉冲压缩的数学模型,将GPU并行计算设计划分为片上缓存设计、内核线程设计、数据并行设计三级优化,在每级优化中针对应用特性提供了不同的优化策略。以渐近的方式完成应用的全局优化过程。
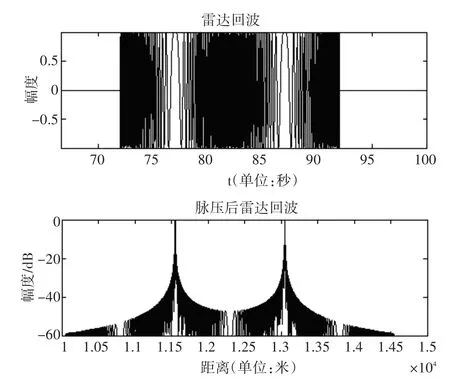
图2 雷达回波脉冲压缩效果
3.1 片上缓存设计
GPU有全局存储器、共享存储器、寄存器和纹理及常量存储器的高速缓存,其中共享内存有着几乎与寄存器一样快的访存速度,其中纹理存储器和常量存储器存储方式为只读。
GPU对全局存储器的访问延迟为400~600个时钟周期,对共享存储器的访问延迟约为5个时钟周期。内核函数将频繁访问且算法固定的变量转移至共享内存,这样可以减少访存延迟[9],将数据从GPU的全局存储器读取到共享存储器中进行内核函数运算,能够极大地提高处理速度。共享存储器中的线程通信把采样数据分批划分到共享内存,通过共享存储器合作计算可获得更好的加速性能。共享存储器能够开辟的空间有限,并且其生命周期同内核函数的调用保持一致。滤波器参数等以权库的形式分配在纹理存储器以提高访问效率。
3.2 内核线程设计
多核CPU并行运算中,可利用OpenMP编译指导语句和变量显式地指导并行化[10~11]。而在GPU数值计算中,是按照“Grid-Block-Thread”的三层组织结构来并行执行,其划分过程通过内核函数kernel的<<<dimBlock,dimThread >>>语句对其进行设置,每个kernel对应一个线程网格,线程网格内的多个线程块能够以任意顺序抢占执行。这种独立性允许内核函数kernel根据采样点的数量和算法来确定线程块。以一维实数向量X(i)和Y(i)求和计算为例,如图3所示,不同的线程按索引号访问向量X(i)和 Y(i)位于 Global Memory中数据元素,计算不同Id位置处的元素和,每一个线程块完成连续m个元素的求和操作。
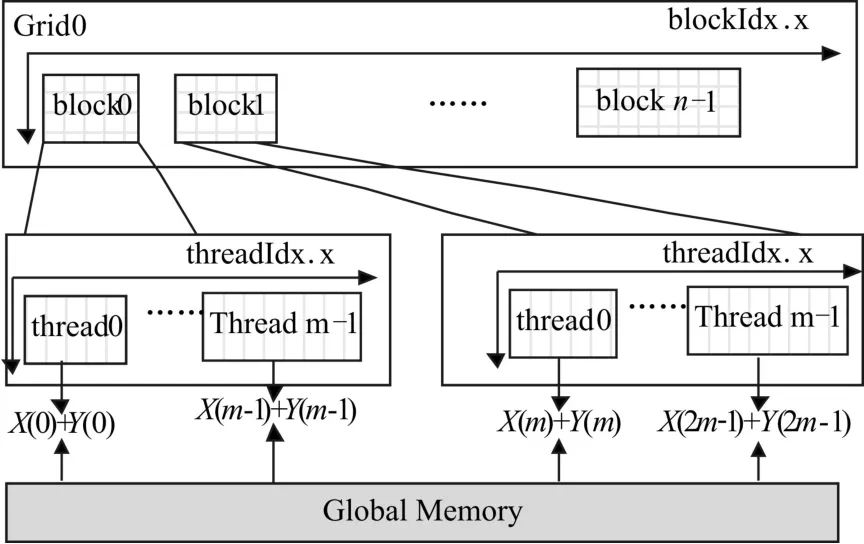
图3 线程任务分配方案图
CUDA利用SIMT执行模式,细粒度线程是以half-warp为单位同时对地址进行合并访问。是否满足合并访问对CUDA程序的速度产生数量级上的差异。CUDA设定的half-warp数量为16,所以每个block的维度m需设置成16的倍数,这里设定每个block中线程数threads.x的取值为256。假设每个脉冲重复周期上采样点数为Ns,Grid的维度设计为(Ns+threads.x-1)∕threads.x,使得一个 Grid中的block数量为整数,同时线程的规模只与采样点的数量有关,采样点在地址中的排列顺序也应与threadldx.x的方向一致,这样的线程安排也是为了满足对全局地址的合并访问条件,提高存储器访问的有效带宽。
3.3 数据并行设计
GPU计算的数据需要经过PCI-E总线在主机内存和设备显存之间进行通信。数据并行计算应力求重叠通信与计算的时间,进而减少应用的整体执行时间[12~13]。在进行GPU密集型计算前,先将预处理、逻辑控制和部分预计算分配在CPU上,然后利用cudaMemcpy函数将所需的数据从系统主存拷贝到设备显卡,从而改进计算访存比,以及各存储层次上的延迟隐藏。
4 并行脉冲压缩算法实现
脉冲压缩的重点在于设计接收机相频特性与发射信号相位共轭匹配的压缩网络,即根据雷达信号波形获得匹配滤波器系数,线性调频信号的脉压系数为复包络信号s(n)的共轭翻转,滤波器单位脉冲响应h(k)表达式为
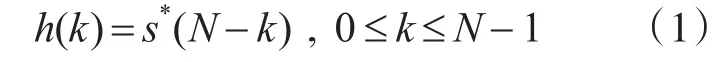
雷达脉冲压缩模块的实现核心是将正交相位检波的结果与匹配滤波器系数频域相乘,系统采用多个线程并行处理。每个线程独立维护采样点数值和滤波器系数,线程之间并行执行傅立叶变换和复数点乘。系统运行步骤如图4所示。
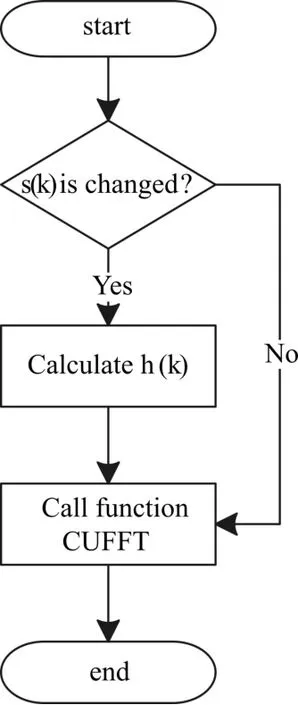
图4 系统程序流程图
具体说明如下:
第1步:判断雷达信号波形是否发生变化,发生变化执行第2步,否则执行第4步。
第2步:主机端根据雷达波形计算匹配滤波器系数。
第3步:将匹配滤波器系数传输到设备端。
第4步:调用CUFFT函数对正交分解信号和匹配滤波器系数在频域变换,并完成复数卷积。
5 仿真结果
为测试第4节并行算法效果,本文分别基于CPU和CPU∕GPU处理平台,实现应用映射和性能优化实验,其硬件参数及软件环境如表1所示。其中,CPU采用具有4核8线程的XEON E5620处理器,CPU∕GPU采用NVIDIA 的Tesla C2050。

表1 硬件参数及软件环境
在多核CPU和GPU的计算中,分别利用Intel.MKL.v10.0.2和CUDA Driver 4.1中的FFT函数库加速计算。这两种数学库分别针对多核CPU、GPU提供了高度优化、线程安全的FFT函数,充分利用处理器的多核、多线程处理能力。
表2所示为线性调频信号脉冲压缩处理测试结果,其中GPU平台处理时间包括内核计算时间和测试数据在内存和显存之间的传输时间。

表2 脉冲压缩处理对不同采样点数量的执行时间对比
由表2可以看出,在相同的采样点数量的情况下,GPU内核计算速度远远高于CPU,但是当采样点数量较少时,GPU的整体计算速度优势并不明显。这是因为采样点少时,不能最大发挥GPU并行计算能力,且数据的传输时间占用了一定比例。随采样点数量增加,GPU多线程细粒度的优势发挥出来,运算效能明显高于CPU,其中内核计算速度相对于CPU计算速度最大可达29倍。
6 结语
本文针对雷达信号脉冲压缩并行处理算法的特点,在CPU∕GPU并行计算架构上设计了并行加速机制,根据GPU物理架构实现了算法优化,基于实际硬件平台进行了仿真试验。实验结果表明基于GPU加速的雷达信号脉冲压缩算法与多核CPU相比具有较好的实时性。本文所提出的GPU加速机制,对于雷达信号处理其他模块算法来说具有通用性,可为GPU加速软件雷达信号处理运算进入工程应用阶段奠定良好的基础。
[1]汤俊,吴洪,魏鲲鹏.软件化雷达技术研究[J].雷达学报,2015,4(4):481-489.
[2]LI Zhong zhi,WANG Xue gang,YU Xuelian.Orthogonal Software Architecture Design for Radar Data Processing System with Object-oriented Component and COM Interface[J].WSEA Transaction on Computers,2011,10(2):61-70.
[3]Malanowski,M.Kulpa,J.Porczyk,et al.Real-time software implementation of Passive Radar[C]∕Radar Conference,2009:33-36.
[4]秦华,周沫,察豪,左炜.软件雷达信号处理的多GPU并行技术[J].西安电子科技大学学报,2013,40(03):145-151.
[5]陈文斌,杨瑞瑞,于俊清.基于GPU∕CPU混合架构的流程序多粒度划分与调度方法研究[J].计算机工程与科学,2017,39(01):15-26.
[6]马晓岩,向家彬.雷达信号处理[M].长沙:湖南科学技术出版社,1999:182-194.
[7] Skolnik M I. Radar Handbook[M].New York:Mc Graw-Hill Book Co,1990:125-130.
[8]David K B,Sergey A L.Radar Technology Encyclopedia(Electronic Edition)[M].Boston and London:Artech House,1998:115-120.
[9]Stanko,Stephan,et al.Synthetic aperture radar for all weather penetrating UAV application(SARAPE)-project presentation[C]∕Synthetic Aperture Radar,2012,EUSAR,9th European Conference on:290-293.
[10]Song J P,Ross J A,Shires D R.Hybrid Core Acceleration of UWB SIRE Radar Signal Processing[J].IEEE Transactions on Parallel and Distributed Systems.2011,22(1):46-57.
[11]肖汉.基于CPU+GPU的影像匹配高效能异构并行技术研究[D].武汉:武汉大学,2011.
[12]张保,董晓社,白秀秀等.GPU-CPU系统中基于剖分的全局性能优化方法[J].西安交通大学学报·信息科学版,2012,46(2):17-23.
[13]杨靖宇,张永生,李正国等.遥感影像正射纠正的GPU-CPU协同处理研究[J].武汉大学学报·信息科学版,2011,36(9):1043-1046.
Parallel Mechanism Study of Radar Pulse Compression based on CPU/GPU Processor
PENG Pei ZHANG YunleiLI KeXI Zemin
(College of Electronic Engineering,Navy University of Engineering,Wuhan 430033)
In order to achieve the real-time signal processing of software radar for various processors,it is essential to study the parallel mechanism for the general high performance processor,i.e.,CPU and GPU.Focusing on the parallel realization of GPU processor,this paper takes the pulse compression processing as an example.Firstly the algorithm model is presented,and then three parallel ways are designed,including the on-chip cache,kernel threads and data in parallel.The simulations show that the proposal mechanism for GPU has a better real-time property comparing to the multiple-kernel CPU.
CPU∕GPU,parallel mechanism,software radar,pulse compression
TN957.51
10.3969∕j.issn.1672-9730.2017.10.007
Class Number TN957.51
2017年4月8日,
2017年5月27日
彭培,硕士,助教,研究方向:雷达信号处理。张云雷,硕士,讲师,研究方向:MIMO雷达信号处理。李轲,博士,讲师,研究方向:目标跟踪与识别。席泽敏,博士,副教授,研究方向:故障诊断和雷达目标识别。
猜你喜欢
——信号处理
无线电工程(2022年10期)2022-10-24
计算机系统应用(2022年5期)2022-06-27
现代电子技术(2022年8期)2022-04-13
今日农业(2021年9期)2021-07-28
现代装饰(2021年1期)2021-03-29
网络安全技术与应用(2020年1期)2020-01-07
电子制作(2019年14期)2019-08-20
中国计算机报(2019年12期)2019-06-21
电子制作(2018年17期)2018-09-28
制导与引信(2017年3期)2017-11-02
