
基于元音检测的俄语语音音节端点检测
2017-11-23 01:02易绵竹
郑州大学学报(理学版) 2017年4期
王 彤, 易绵竹
(信息工程大学 洛阳校区 工程系 河南 洛阳 471000)
DOI: 10.13705/j.issn.1671-6841.2017186
基于元音检测的俄语语音音节端点检测
王 彤, 易绵竹
(信息工程大学 洛阳校区 工程系 河南 洛阳 471000)
针对传统端点检测算法因忽视语言特点导致的检测精度不足问题,结合元音中心论、响度说、合张运动说等俄语音节理论,提出一种面向俄语语音的音节端点检测算法.算法利用共振峰能量检测元音,并根据元音动态调整门限,基于短时过零率和能熵比提取和切分音节.算法在元音检测中查准率为84.9%,查全率为87%,音节切分的正确率为78.6%,端点检测精度为91.6%,较传统算法剔除了音节间的无话帧,提高了端点检测的精度.
元音检测; 俄语语音音节切分; 端点检测
DOI: 10.13705/j.issn.1671-6841.2017186
0 引言
语音端点检测是语音信号处理的基础技术之一.狭义层面上,端点检测是指确定有话段的起止位置,以达到区分信号中有话段和无话段的目的.广义层面上,按照检测的细化程度,端点检测还包括对语音句、语段、语音词、音节、音素等多种粒度有话段起止位置的判定.语音的音素在组成音节时存在连读现象,音素之间因为相互融合造成界限模糊.音节是语流中相对独立的单元,音节之间的界限相对分明.通过音节的切分和端点检测,能够准确提取有效的语音帧序列,排除无声段或噪声段的干扰,为语音识别、语音检索等研究奠定基础.目前,学者采用时间长度高斯拟合算法[1]、时频二维能量特征算法[2]、元音主导的检测法[3-4]、多重分型消除波动分析法[5]等方法切分音节.结合俄语语音的特点,采用模态分解法[6]、基于梅尔频率统计的决策分类法[7]等方法切分俄语音节.国内对于俄语语音的研究多为面向汉俄语音比较及俄语语音教学,面向语言工程的研究还处于起步阶段.徐来娣[8]等研究俄语的音节理论并提出俄语音节切分方案,赵芳丽[9]等基于praat软件分析俄语读音,目前尚未发现介绍俄语语音音节切分算法的相关文献.
本文结合俄语音节理论,设计了基于元音检测的俄语语音音节端点检测算法,以期为俄语语音处理的相关工作提供支持.
1 俄语音节切分理论
俄语共含有33个字母,所有字母共表示42种音位,其中6个是元音,36个是辅音.俄语音节的构成遵循元音中心说,即每个音节中有且只有一个元音,没有复合元音;每个音节可以包含0~8个辅音,普遍存在辅音连缀现象,容易形成辅音群.俄语音节切分是一种纯粹的语音行为,音节的切分不会造成词义的变化,音节切分方式一般没有语义要素可以作为参考[8].
根据元音中心学说,辅音和辅音群不能单独构成音节,俄语词的首尾位置若为辅音或辅音群,则其应该属于与之最邻近元音所在的音节.关于俄语元音之间的辅音或辅音群的音节归属问题,不同学说各执一词,难成定论,代表学说包括呼气说、响度说、肌肉紧张说、合张运动说等.其中,具有工程实践指导意义的是合张运动说和响度说.
合张运动说从发音角度出发,将发音时发音器官活动的相互作用程度作为判定元音、辅音的结合紧密程度的依据.其主要观点为:俄语发辅音时发音器官闭合,发元音时发音器官张开,音节为先辅音后元音的一次合张运动,认为俄语可以看作开音节组成的序列.此外,运用实验语音学方法,得出元音发音主要受前方辅音影响,辅音及辅音群的发音变化主要受后方元音影响,将元音间的辅音划归为后方元音所在的音节.
响度说从听觉角度出发,以语音流各音节之间和音节内部的响度变化为切入点,归纳出非首音节内部具有响度由弱至强的递增规律.其主要观点为:俄语的音素可以按照响度渐强分为3级,清辅音(噪辅音)为第1级,浊辅音(响辅音)为第2级,元音为第3级,不同响度的音素组成音节.音节作为单词中相对独立的单元,其产生是一个响度渐强的过程,据此,将单词中响度递增前的最低点作为音节间的界限.
合张运动说和响度说分别从产生端和接收端研究俄语音节的本质,并制定具有可供语音学实践的音节切分方案.文献[8]发现二者均具有一定局限性.合张运动说忽视了俄语中存在闭音节,即存在元音间的辅音与前方元音结合更紧密的客观现象,如антитерроризм中元音a和元音и之间的辅音н同前方元音a结合形成鼻音.响度说无法实现词中两个连续元音的切分,如аудитория中的相连的元音a和元音y会被错误划归为同一音节.有时会因响辅音造成某些词的切分错误,如всегда,仅有两个音节,但受噪辅音в影响,出现两个响度最低点с和е,被切分为3个音节.
2 算法的描述
2.1 算法的设计思想
根据元音中心说,辅音和辅音群不能单独构成音节,语音段中的元音个数即为音节个数.因此,算法通过检测元音段确定音节个数,并以元音为中心确定各音节的位置边界.根据响度说,同一音节中的元音和辅音结合紧密,响度的变化表现为平缓的过程,不会出现局部突变.因此,以元音段为中心确定其所在音节中辅音段的参数变化范围,并动态设定阈值.根据合张运动说,辅音与后方的元音结合更紧密,因此采用优先以元音段为中心的前向搜索算法,以提取开音节所包含的辅音段;根据响度说,采用以元音段为中心的向后搜索算法,以提取闭音节所包含的辅音段.
2.2 算法的工作流程
首先对俄语语音进行预处理,包括加窗、分帧、中值平滑;然后采用基于共振峰能量的单参数双门限检测法提取元音段;之后以元音段为中心动态设定阈值,采用基于能熵比和短时过零率的双参数双门限检测法切分并提取音节段;最后将音节段组合成完整的有效语音段,实现较为精确的俄语语音端点检测.上述算法的工作流程如图1所示.

图1 基于元音检测的俄语语音音节端点检测流程图Fig.1 The flow chart of Russian syllable endpoint detection based on vowel segmentation
2.3 面向端点检测的双门限法分析
双门限法[10-11]根据所设置的参数和阈值逐级判决,由粗至精,循序完成端点检测.单参数检测法设有一个参数parm1,两个阈值thre1和thre2,其中thre1lt;thre2.首先,根据thre2进行粗判,若信号帧的pram1值高于thre2,则该帧肯定为语音帧;然后,取thre2与parm1的两个交汇点向两端扩展搜索,取thre1与parm1的交汇点作为最终判别结果.双参数检测法将单参数检测的起止位置作为第一级判决结果,并根据pram2进一步做第二级判决.检测过程如图2所示.
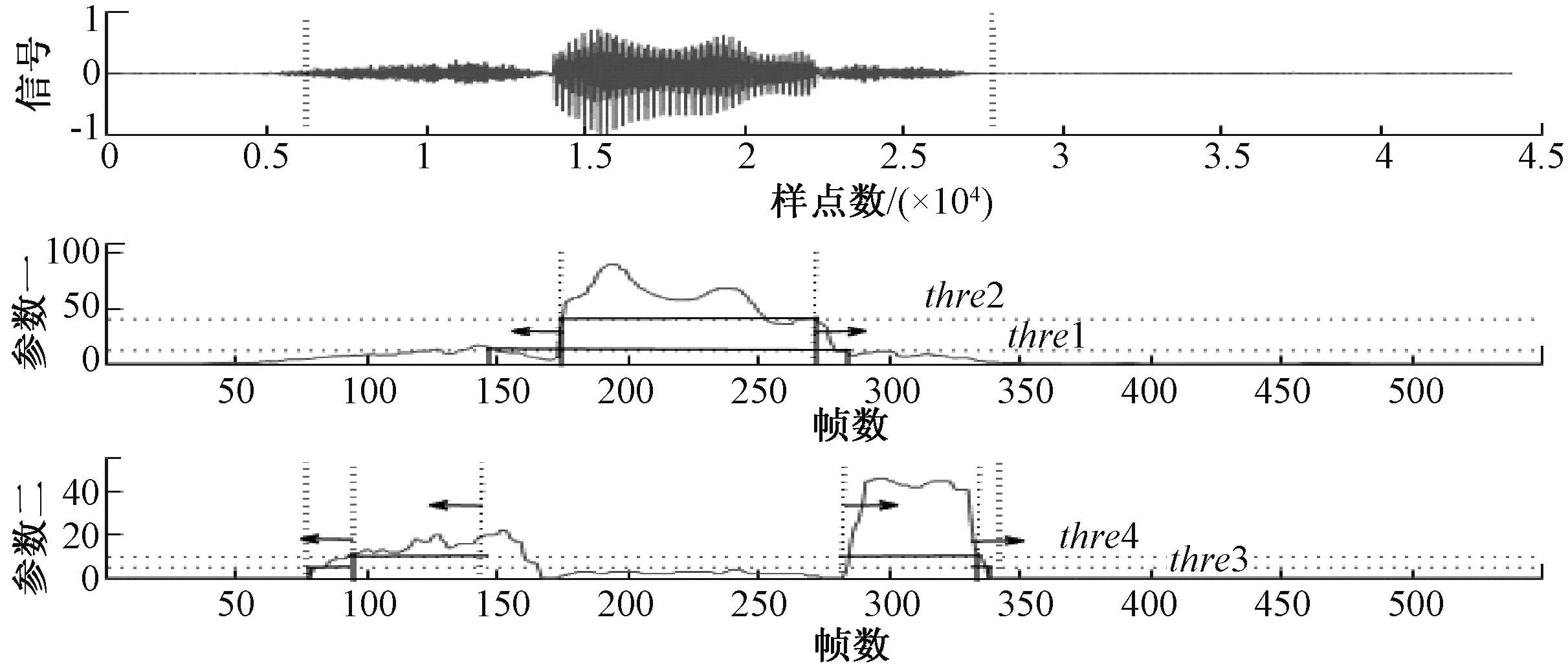
图2 双参数双门限检测法示意图Fig.2 Schematic diagram of double parameter and double threshold detection method
3 算法的实现
3.1 基于共振峰能量的元音检测
声音在通过共振腔时,不同频率的能量受腔体滤波作用,或强化或衰减,得以重新分配,共振峰是声音频率中能量相对集中的区域.浊音具有明显的共振峰,清音不具有明显的共振峰.俄语的元音都是浊音,辅音多为清音,且浊辅音与元音的共振峰具有明显差异.根据文献[12],选取学者Матусевич在1976年的专著《Современный русский язык.Фонетика》中的数据,如表1所示.

表1 俄语元音的共振峰频率表
俄语元音的第一、第二共振峰频率集中在250~2 000 Hz,据此,俄语元音共振峰能量FE(formant energy)的计算过程为:首先,令语音信号通过频率范围为250~2 000 Hz的FIR带通滤波器;然后,对滤波后的信号加窗分帧,求得各帧的短时能量即为共振峰能量.设窗长为N,x为滤波后的信号,w为窗函数,则在n时刻语音的FE值为
元音段提取的过程为:首先根据较低的阈值T1以及有话段最小连续帧长粗略提取有话段,对每个有话段,采取基于共振峰能量的单参数双门限法提取元音段.阈值分别为该语音段的FE中值,以及FE最大值与比例系数R的乘积.数字0~9的俄语语音的元音检测结果如图3所示.
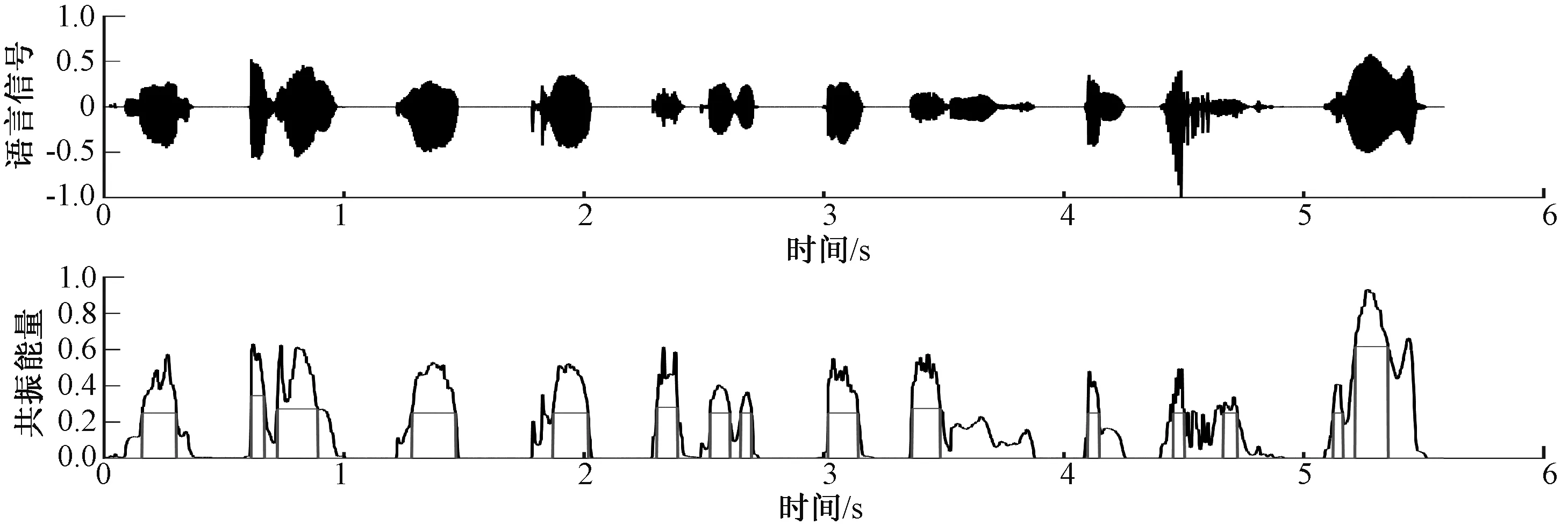
图3 元音检测效果示意图Fig.3 Figure of vowel detection results
3.2 基于元音检测的音节段提取
短时平均过零率可以在一定程度上反映信号的频率信息[13],清音的短时平均过零率高于浊音,且清音和浊音的短时平均过零率远高于背景噪声.辅音(尤其是清辅音)与背景噪音的短时平均过零率差别显著,因此,选择短时过零率作为检测参数.n时刻的短时平均过零率为

频率谱线能量密度表达各频率谱线的能量在信号中所占的比例.设M为信号帧频域变换后的谱线条数,P为各谱线的能量,则第k条谱线的概率密度为


谱熵(spectral entropy)用于反映各频率谱线的能量分布均匀程度,能熵比定义为能量E与谱熵H的比值[14],谱熵与能熵比的计算公式分别为:
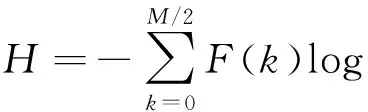

噪声的能量较小,且分散在各频率谱线中,谱熵值较大.语音信号能量较大,且相对集中在几个共振峰频率上,谱熵值较小.能熵比加大了语音和噪声参数的数值差距,对不同信噪比的环境适应性更强.音节切分的流程如图4所示.
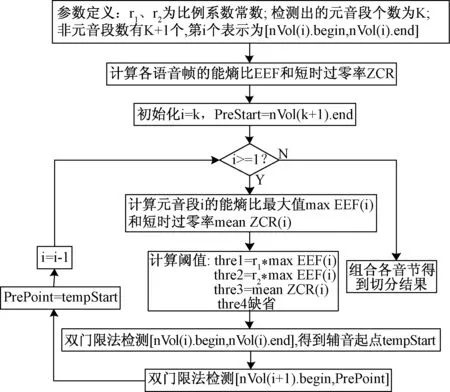
图4 音节切分的流程图Fig.4 Flow chart of syllable segmentation
本文算法与基于能量和过零率的双门限法对俄语数字0~9的音节切分结果如图5所示.
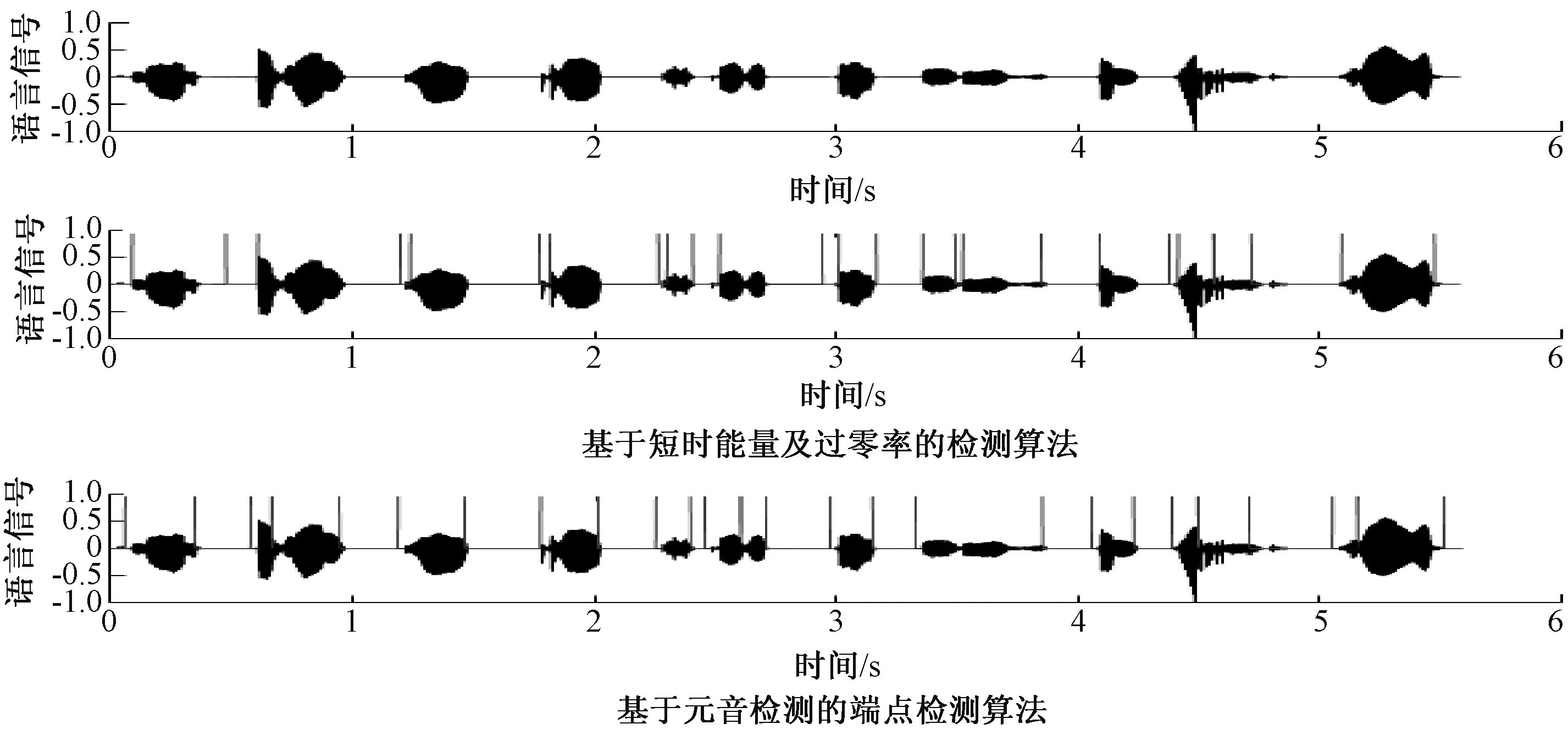
图5 音节切分效果对比图Fig.5 Comparison of two syllable segmentation results
4 实验及结果分析
实验数据为俄语母语者的广播语音,包括单元音词10个、双元音词20个、多元音词20个.将手工标注结果作为检测标准,基于查准率和查全率评价元音检测的结果,基于正确率评价音节切分的结果,基于调和参数为1的F值(F-measure)评价端点检测结果,并对比本文算法与基于能量和过零率的双门限算法的检测精度.元音检测中,端点误差不大于3帧视为正确,检测误差过大或错误检出辅音视为误检,元音未被检出视为漏检;音节检测中,端点误差不大于5帧视为正确.
参数设置如下:信号采样频率为8 kHz,加汉明窗,窗长为256,移动窗长为80,加窗后做幅值归一化以及五点中值平滑处理.元音检测实验中,选取切比雪夫二型带通滤波器,通带频率为250 Hz和2 000 Hz,阻带频率为200 Hz和2 100 Hz,通带波纹和阻带衰减为1和10.T1为0.25,有话段的最小连续帧长为15,共振峰阈值的比例系数R为0.65,元音的最短帧长为10.音节切分实验中,能熵比的门限比例系数r1为0.7,r2为0.85,短时过零率的阈值thre3为元音段的平均值,thre4缺省.
元音检测、音节切分及端点检测的实验结果如表2所示.

表2 元音检测及音节切分的结果统计表
实验数据显示:算法在俄语语音数据的元音段检测中,查准率达到84.9%,查全率达到87%,基于元音段检测的音节切分准确率达到78.6%.算法端点检测的精确度达到91.6%,高于双门限算法的87.6%.分析实验结果发现,算法主要通过降低音节间无声帧的误检,提高端点检测的精度.此外,连续语音中的非重读元音弱化,以及重度音节中的浊辅音与元音界限模糊导致的错误占全部错误的比例超过90%.后续工作将加入对重音变化等超音位音段的研究,以进一步优化算法.
5 结论
本文以元音中心说、合张运动说、响度说等俄语音节学说为理论基础,提出了一种基于元音的俄语语音音节端点检测算法.算法细分为元音提取和音节切分两个部分,元音提取部分紧扣单元音是形成俄语音节的充要条件这一命题,通过分析声学特征,找出元音区别于辅音的共振峰特性,进而计算共振峰能量,提取信号中的元音段.音节切分部分引入端点检测中的双门限算法,综合元音、辅音与无话段的区别,选取能熵比和短时过零率作为门限法的参数;根据元音与其前后辅音群结合的紧密程度确定检测范围和检测顺序;此外,考虑到语流中的音强、语速、环境等变化对检测的影响,根据提取的元音段动态设定门限阈值,提高了算法的自适应能力.最后,在俄语母语者的语音数据上验证了算法的有效性.本文算法面向俄语语音,实现了较为准确的元音检测和音节切分,较传统算法剔除了音节间短暂停顿所在的无用帧,提高了俄语语音端点检测的精度.
[1] 张扬,赵晓群,王缔罡. 基于音节时间长度高斯拟合的汉语音节切分方法[J]. 计算机应用,2016,36(5):1410-1414.
[2] 张扬,赵晓群,王缔罡. 基于时频二维能量特征的汉语音节切分方法[J]. 计算机应用,2016,36(11):3222-3228.
[3] 张利平,冯宏伟,王艳. 基于元音检测的汉语连续语音端点检测方法[J]. 计算机工程与应用,2010,46(27):114-116.
[4] YOO I C,YOOK D. Robust voice activity detection using the spectral peaks of vowel sounds[J]. ETRI Journal,2009,31(4):451-453.
[5] HE S F, ZHAO H. Automatic syllable segmentation algorithm of Chinese speech based on MF-DFA[J]. Speech communication, 2017,92:42-51.
[6] АЛИМУРАДОВ А К, КВИТКА Ю С, ЗАРЕЦКИЙ А П, et al. Помехоустойчивая обработка речевых сигналов на основе комплементарной множественной декомпозиции на эмпирические моды[J]. ТРУДЫ, 2016, 8(3): 43-53.
[7] SALISHEV S, BARABANOV A, KOCHAROV D, et al. Voice activity detector (VAD) based on long-term mel frequency band features[C]//19th International Conference on Text, Speech, and Dialogue. Czechoslovakia:Brno, 2016: 352-358.
[8] 徐来娣. 俄语音节理论研究与俄语音节切分优化方案[J]. 中国俄语教学,2009,28(4):69-72.
[9] 赵芳丽. 基于praat软件的俄语读音分析[J]. 计算机工程与应用,2012,48(11):133-136.
[10] 王炳锡,屈丹,彭煊,等.实用语音识别基础[M].北京:国防工业出版社,2005.
[11] ORTIZ P D,VILLA L F, SALAZAR C, et al. A simple but efficient voice activity detection algorithm through Hilbert transform and dynamic threshold for speech pathologies[J].Journal of physics:conference series, 2016, 705(1): 012037.
[12] 陈君华. 俄汉元音对比的新尝试[J]. 中国俄语教学,1997,16(1):55-57.
[13] 张雪英. 数字语音处理及matlab仿真[M]. 北京:电子工业出版社,2010.
[14] 宋知用. matlab在语音信号分析与合成中的应用[M]. 北京:北京航空航天大学出版社,2013.
(责任编辑:王海科)
SyllableEndpointDetectioninRussianSpeechBasedonVowelSegmentation
WANG Tong, YI Mianzhu
(DepartmentofEngineering,LuoyangBranchofInformationEngineeringUniversity,Luoyang471000,China)
Aiming to solve the problem that the traditional endpoint detection algorithm lacked accuracy due to ignoring the language features, an algorithm of syllable endpoint detection was presented based on Russian syllable theories, such as the vowel center theory, the loudness theory, the motion theory and so on. The formant energy was used to detect vowels, then the thresholds were adjusted according to vowel. Extracts and segments syllables were carried out based on short-time zero crossing rate and energy entropy ratio. The results showed that, the precision was 87%, and the recall rate was 84.9% in vowel detection of Russian speech, and the precision was 78.6% in syllable segmentation. In addition, the algorithm could improve the accuracy of endpoint detection by eliminating the invalid frames between the syllables.
vowel detection; Russian syllable segmentation; endpoint detection
2017-06-22
国家自然科学基金项目(11590771)
王彤(1993—),女,黑龙江齐齐哈尔人,主要从事计算机与应用语言研究,E-mail:463906155@qq.com;通信作者:易绵竹(1963—),男,四川营山人,教授,主要从事计算语言学研究,E-mail:1197751829@qq.com.
TP391
A
1671-6841(2017)04-0034-06
猜你喜欢
考试与评价·八年级版(2021年4期)2021-08-14
考试与评价·七年级版(2021年1期)2021-08-14
考试与评价·八年级版(2020年3期)2020-11-02
考试与评价·八年级版(2020年6期)2020-11-02
考试与评价·七年级版(2020年1期)2020-10-23
听力学及言语疾病杂志(2020年2期)2020-05-20
演艺科技(2017年8期)2017-09-25
老年世界(2017年2期)2017-03-16
小学生时代·大嘴英语(2014年6期)2014-11-04
汽车工程学报(2013年1期)2013-10-29
