
基于随机旋转集成的降维方法
2017-11-13 08:27,
上海理工大学学报 2017年5期
,
(上海理工大学 管理学院,上海 200093)
基于随机旋转集成的降维方法
王椭,肖庆宪
(上海理工大学 管理学院,上海200093)
对随机旋转集成方法提出了一种针对降维问题的改进,得到了新的降维算法框架进行随机变换降维,可以显著减少降维过程中造成的信息损失.采用随机变换降维后,训练监督学习算法时可以获得更高的准确率和更好的泛化性能.通过在模拟数据上进行的实验,证明了使用多重共线性数据进行回归分析时,与传统降维算法相比,经随机变换降维处理后可以保留更多的信息,获得更小的均方误差.对随机变换降维在手写数字识别数据集上的表现进行了研究,证明了与一般性的降维算法相比,随机变换降维在图像分类问题上可以获得更高的准确率.
集成学习; 随机旋转集成; 降维; 多样性
高维数据的处理一直是机器学习领域的重要问题,尤其是近年来机器学习的几个重要应用方向,如计算机视觉、自然语言处理等,都必须面对高维数据带来的挑战.数据的维数越大,处理数据所需的时间消耗与储存空间消耗就越大,还可能存在许多与给定任务无关的特征甚至存在大量噪声,或是出现数据冗余、样本稀疏及多重共线性问题对数据分析造成干扰.要想克服这些高维数据带来的问题,必须对数据进行一定的加工和处理.
在过去的几十年里,有大量的降维方法被不断地提出并被深入研究,其中常用的包括传统的线性降维算法如PCA和LDA;核化线性降维算法如KPCA,流形学习算法如LE[1-4],ISOMAP[5-7]以及LTSA[8],度量学习算法如NCA[9].
部分降维算法如线性降维与核化线性降维试图在降维过程中使噪声被消去,保留尽可能多的有效信息;而另外一部分降维算法,如流形学习与度量学习,则试图找到保留数据在高维下的结构特征的低维映射,以此来解决高维数据带来的问题.
但是在实践中,由于样本与总体间的差异,噪声有可能不会被正确的识别,样本数据的结构特征也可能与总体存在差异.并且,将高维空间中的数据在低维空间中表示,这一数据压缩重构的过程不可避免地会造成信息的损失.很多情况下,将降维后的数据用于预测,其准确性会低于甚至远低于采用原数据进行预测.
为解决这些问题,本文借鉴随机旋转集成(random rotation ensemble)的思想,并对降维问题作出了针对性改进,提出了一种新的降维算法框架随机变换降维(RTDR).通过对原数据集进行随机变换,生成多个子数据集后再应用现有的降维算法,然后通过stacking算法对降维后的结果进行集成,可以极大地减少降维过程中造成的信息损失.这一过程本质上是在保留原数据集信息的情况下,对其在高维空间内进行扭曲变形,然后再生成对应的低维映射,最后将多个这样的低维映射进行集成.由于每个低维映射都能包含原数据集在高维空间的结构信息,并且由于经过随机变换获得,这些信息彼此之间不完全重叠.因此,在集成后,可以比单个低维映射保留更多的信息,并且在经过随机变换后,原数据集中可能被误判为噪声的一部分信息有可能在生成的子数据集中得到保留,同样能够得到减少信息损失的效果.
本文通过在模拟数据上的实验,验证了在使用具有多重共线性的数据进行回归分析时,随机变换降维可以有效克服多重共线性问题.并且与传统的降维算法相比,随机变换降维提取信息更充分,得到的均方误差更小.在经典的MNIST手写数字数据集上进行试验,证明了在图像分类问题中,与传统降维算法相比,采用随机变换降维准确率更高.
1 预备知识
1.1集成学习
集成学习(ensemble learning)是通过构建并结合多个学习器来完成学习任务的一类算法,通过将多个学习器结合,常可获得比单一学习器显著优越的泛化性能[10-13].Liu[14]基于集成学习的特性提出了EasyEnsemble,用于应对对数据集进行欠采样造成的信息损失.
在集成学习与降维算法结合时,集成学习可以从3方面提升降维算法的性能:a.通过集成多个低维映射,可以降低有效信息被误判为噪声的可能;b.通过集成多个低维投影,可以最大限度地保留数据在高维空间的性质;c.通过集成多个低维投影,可以有效减少数据由高维向低维投影时造成的信息损失.
但是只有用于集成的学习器具有足够好的多样性时才能得到理想的效果.多样性即个体学习器之间的差异,Krogh等[15]曾给出了误差-分歧分解(error-ambiguity decomposition),证明了对于回归任务,集成的泛化误差等于个体学习器泛化误差的加权均值减去个体学习器的加权分歧,说明了构造优秀的集成需要选择“好而不同”的个体学习器.
1.2随机旋转集成
2016年,Blaser等[16]发现将样本属性进行随机旋转,可以显著增强基学习器的多样性,并且基学习器的准确性仅会发生小幅下降,因此可以得到效果更好的集成学习算法,并由此提出了随机旋转集成.
假定x=[x1,x2,x3,…,xn]T表示一个具有n个特征的样本,D1,D2,D3,…,DL表示L个基学习器,随机旋转集成可由以下简单步骤来构造:
a. 对样本x的各特征作标准化处理;
b. 生成一个n×n的随机旋转矩阵Rn,i,RT=R-1,且|R|=1;
c. 将x乘以Rn,i,使特征空间进行随机旋转,采用旋转后的样本训练基分类器Di;
d. 重复步骤b,c;
e. 集成L个分类器的训练结果作为最终输出结果.
1.3stacking算法
stacking算法由Wolpert[17]提出.stacking算法使用多个不同类型的个体分类器,且将它们分为两层.首先使用多种不同的学习算法在同一训练集上进行训练,生成多个基分类器.基学习器分别对每个样本进行预测,预测结果作为新的属性,与样本的原始标签y结合起来作为新的训练集.第二层分类器在该训练集上进行训练,得到的结果作为最终的训练结果.
假定x=[x1,x2,x3,…,xn]T表示一个具有n个特征的样本,y为样本标签,D1,D2,D3,…,DL表示L个初级学习器,D表示次级学习器.stacking算法可经由以下简要步骤构造:
a. 采用(x,y)分别训练初级学习器D1,D2,D3,…,DL,得到的输出结果为Z1,Z2,Z3,…,ZL;
b. 构造新的数据集Z=[Z1,Z2,Z3,…,Zn]T;
c. 采用(Z,y)训练次级学习器D,得到的输出作为最终的输出结果.
1.4主成分分析(PCA)
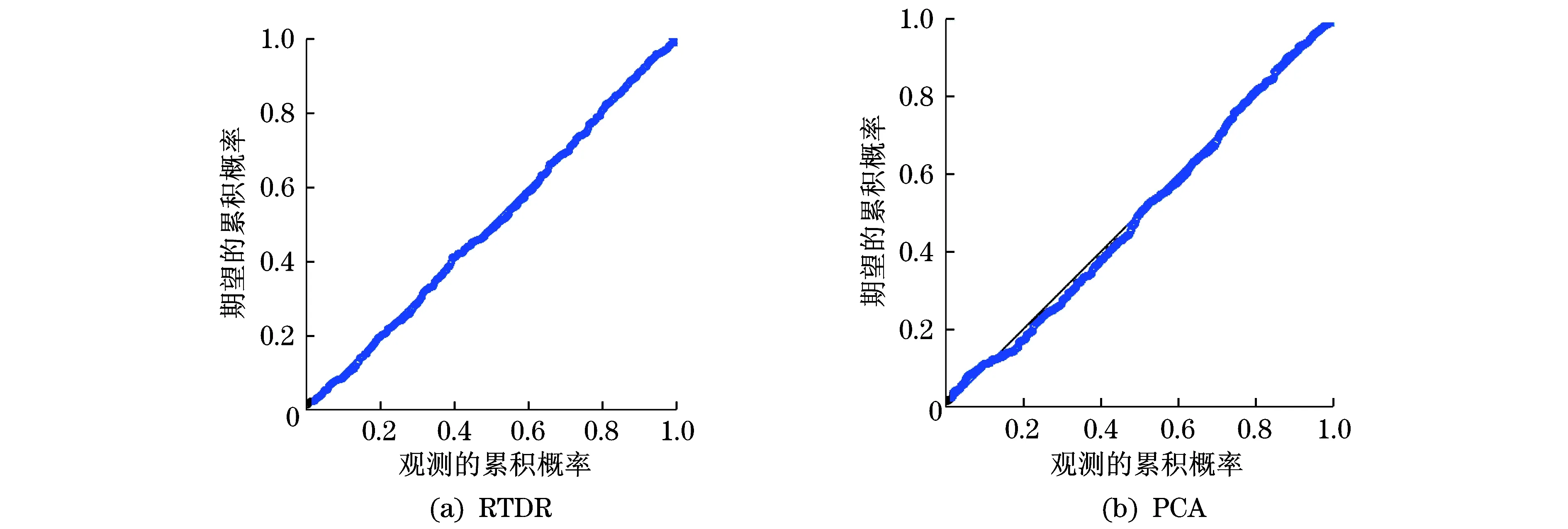
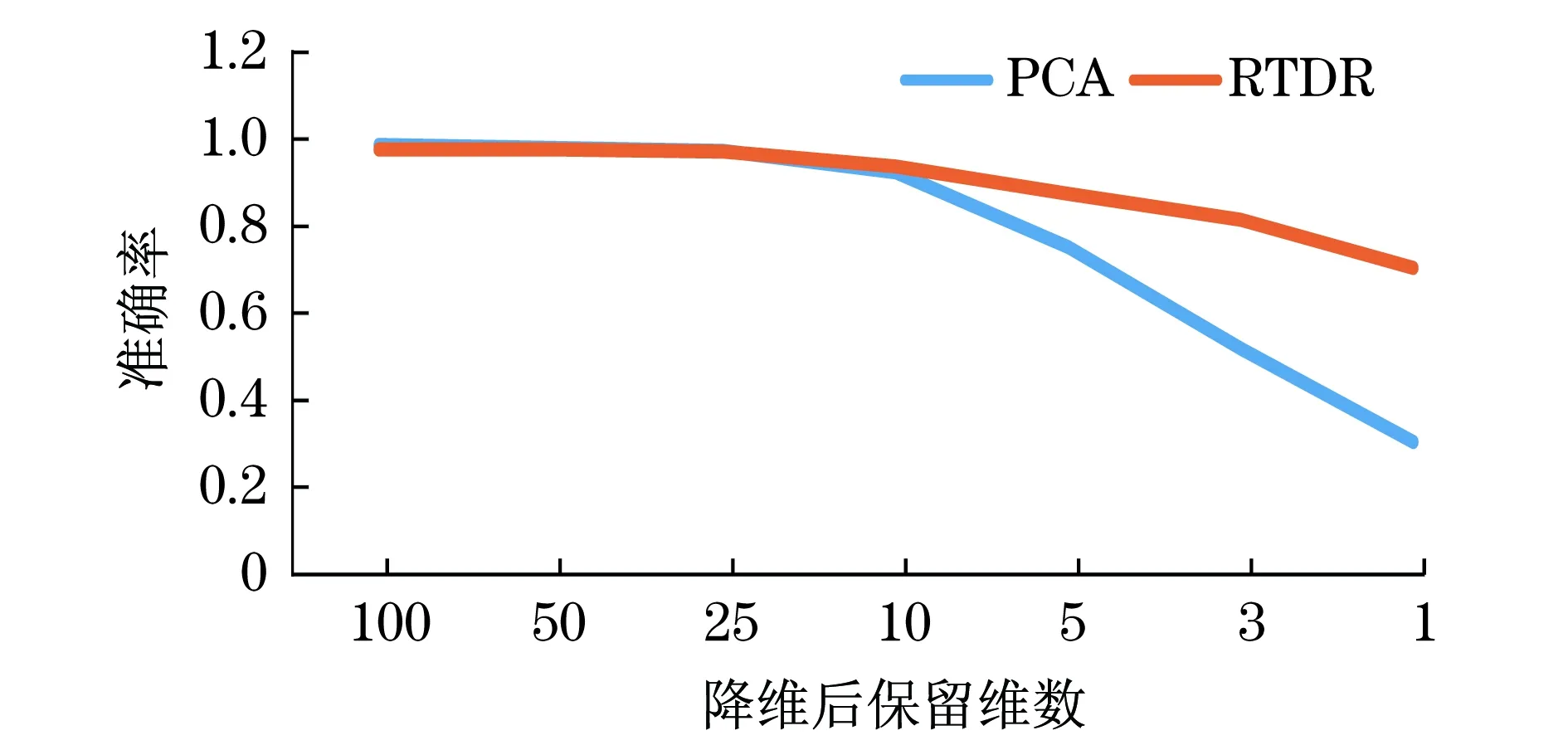
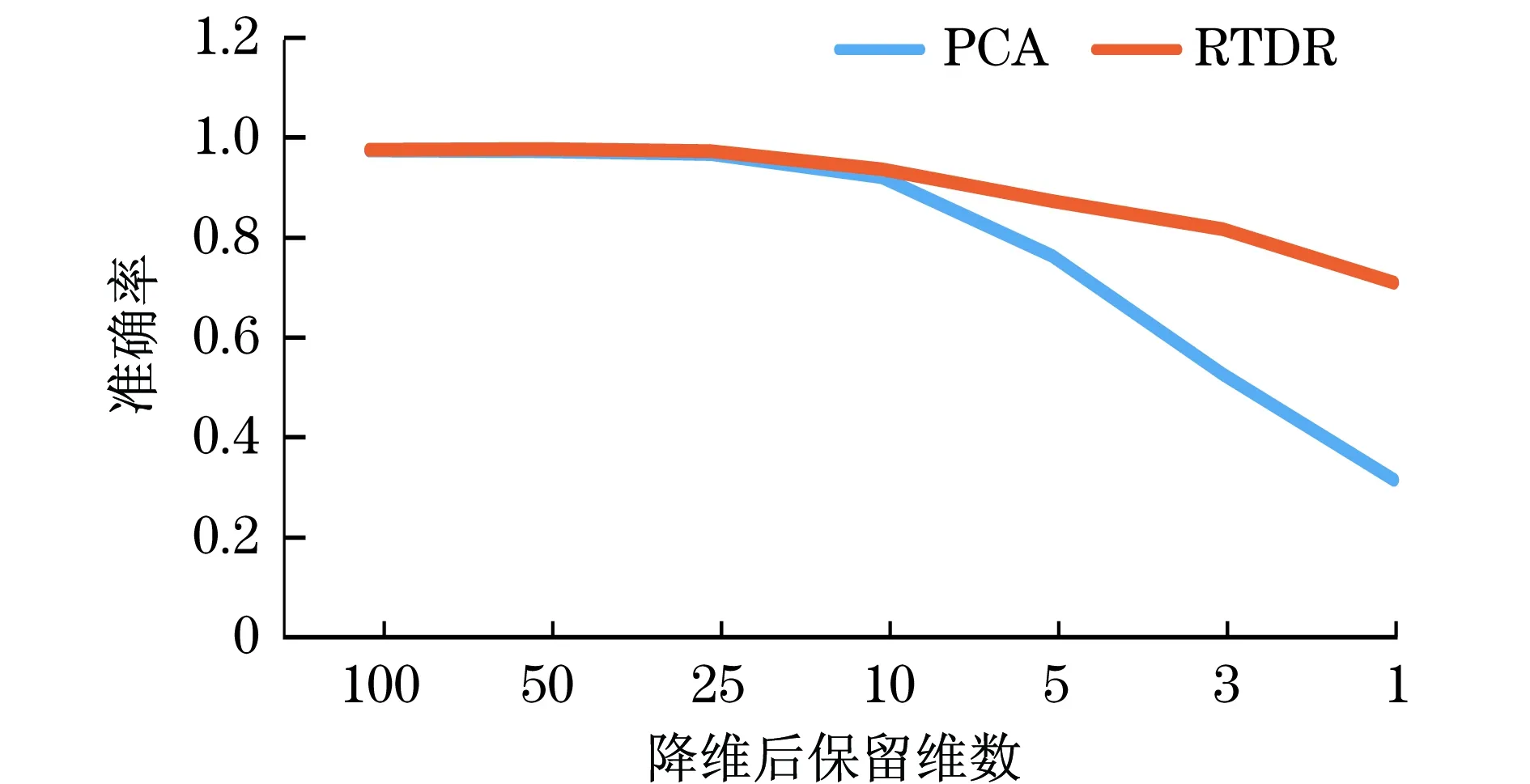
主成分分析(principal components analysis,PCA)[18-20]是一种经典的线性降维方法,它将一组观测变量X1,X2,…,Xn通过线性变化,转化为一组互不相关的变量W1,W2,…,Wn,称之为主成分.在变化过程中保持总方差不变,然后根据方差大小从W1,W2,…,Wn中挑出k(k a. 求初始矩阵X的n×n阶相关系数矩阵R; b. 求相关系数矩阵R的特征值λ1≥λ2≥λ3≥…≥λn,以及与各特征值相对应的一组长度为1且相互正交的特征向量a1,a2,…,an; 本文在MNIST数据集上采用RTDR与PCA进行了对比,验证了RTDR减少信息损失的效果. 2.1原理 本文基于随机旋转集成的思想,提出了一种新的降维算法——随机变换降维RTDR (random transform dimensionality reduction).对于降维而言,通过集成学习可以综合多个高维数据的低维映射信息,减少降维过程中的信息损失.以主成分分析为例,主成分分析构建了一个具有最大可分性的超平面(样本点在这个超平面上的投影能尽可能分开),以此来尽可能保存样本在高维空间的信息.但是事实上,其他方向的超平面同样可以保存样本的信息,并且性能可以接近于具有最大可分性的超平面.集合多个不同投影方向的信息,可以尽可能地还原出原数据集的信息,几何中的三视图则是这一思想的典型案例.将三维立体图形投影成3个二维图形(俯视图、正视图、侧视图),通过观察对比这3个图形,能够了解这一立体图形的形状和结构.但是很多情况下,只用一个投影,无法反映一个立体图形的结构. 为集成多个高维数据的低维映射的信息,RTDR以stacking算法为基础进行集成,以多个低维投影上的学习器的输出作为次级学习器的输入,通过这种形式实现集成多个低维投影的信息.stacking算法通常可以获得比个体学习器更好的性能[17],并已在有监督学习(如回归[21]、分类及距离[22])和无监督学习(如密度估计[23])上都取得了巨大的成功. 但是,Wolpert曾指出stacking方法的一个难点是如何为每个特定领域数据集配置合适的基分类器和元分类器(第二层学习器).因为第一层学习器之间的差异需要尽可能的大(否则输出结果几乎一致,第二层学习器将面对严重的多重共线性问题),通常第一层学习器需要选择不同类型的学习器进行组合,如将随机森林和logistic回归进行组合.但是,对特定问题,不同类型的学习器往往性能差异较大,用随机森林取得较高的准确率,而用logistic回归取得的正确率则较低.这样一来,较差的学习器的性能将会拖累学习器的整体性能,甚至可能出现集成后的学习器的性能比单个的优秀学习器的性能要差. 随机旋转集成可以在不损失原数据集信息的情况下生产多个子数据集,显著提升集成效果.将随机旋转集成应用于stacking算法,可以解决stacking算法基学习器选择难的问题,只需选择最恰当一类的学习器,然后通过随机旋转集成技术,即可获得任意多个新的差异较大但准确率接近的学习器. 随机旋转集成通过旋转的方式保留了子数据集的空间结构信息,通过将样本乘RT=R-1,且|R|=1的矩阵以随机角度进行旋转来生成子数据集.在监督学习问题上,这一方法在尽可能多地保留样本信息的情况下实现了多样性.但是,在降维问题上,由于子数据集的空间结构都是一致的,降维得到的结果反而失去了多样性,难以起到集成的效果和减少降维造成的信息损失. 为此,本文对具有n个特征的样本生成n×n的随机矩阵,随机矩阵由n个标准化的随机向量组成,将样本乘以随机矩阵进行随机变换,得到的新样本的各个特征都是原样本特征的线性组合,因此保留了原样本的绝大部分信息.并且由于新样本的每个特征都是原样本的特征乘以随机权重而获得,与随机旋转集成相比,对样本的空间结构进行一定程度的扭曲变形,实现了降维的多样性,保证了对降维进行集成的效果. 通过在模拟数据上的实验可以发现,在数据具有多重共线性问题时,进行回归估计会产生严重的偏差.在经过降维算法处理后,可以有效减小多重共线性造成的负面影响.而与一般性的降维算法相比,通过随机变换降维,可以获得更好的性能,进行预测得到的均方误差更小,并且残差更贴近于白噪声. 由于图像处理问题中,数据维度往往会远大于样本量,如果不进行降维处理,则难以对图片进行分类或者识别,因此本文在手写数字识别数据集上进行了对比实验.从本文实验结果可以看到,在通过随机变换得到的新样本上进行降维,然后再应用多层感知机(MLP),可以取得与直接在原数据上进行降维然后再应用MLP同等水平的准确性,甚至有些情况下准确性会更高.并且将多个随机变换后的样本降维再进行集成,从实验结果来看,准确性可以得到巨大的提升,降维程度越大提升效果越明显.这充分说明了随机变换降维(RTDR)生成的子数据集不仅保留了原数据集的绝大部分信息,并且具有多样性,获得了集成学习所需要的“好而不同”的基学习器,也证明了RTDR可以减少降维带来的信息损失. 2.2步骤 假定x=[x1,x2,x3,…,xn]T表示一个具有n个特征的样本,y为样本标签,D1,D2,D3,…,DL表示L个基学习器,D为次级学习器(本文实验中基学习器与次级学习器都采用MLP),F为降维算法(本文实验中采用PCA),RTDR可由以下步骤进行构造,算法的流程如图1所示. 图1 随机变换降维算法流程图Fig.1 Flow chart of the random transform dimension reduction algorithm b. 生成L个n×n随机变换矩阵R; e. 采用降维后的样本分别训练初级学习器D1,D2,D3,…,DL,得到 其中,Ωi为Di的参数,Loss为指定的损失函数; g. 采用(Z,y)训练次级学习器D,得到的输出作为最终的输出结果. 其中随机变换矩阵根据以下方式构造: (b) 重复以上步骤,获得n个向量w1,w2,…,wn,R=[w1,w2,…,wn]. 3.1实验介绍 多重共线性是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系,而使模型估计失真或难以估计准确的问题,在经济学研究中属于非常常见的现象.经济变量往往存在共同的趋势,或是在模型中引入了滞后项,这些都会导致多重共线性问题.通过降维算法对数据进行处理,是应对多重共线性的方法之一,经过降维处理后,可以获得更为稳定而准确的估计结果. 但是,在降维过程中,不可避免会抛弃一部分信息.以PCA为例,除了方差最大的若干个方向上的信息被保留外,其他信息都被舍弃了.通常假定这一部分信息是与因变量无关的,属于噪声,但这一假定并不总是成立.如图2所示,最大方差方向上的信息对判断样本点属于“”还是“”毫无帮助. 随机变换降维相对于传统的降维算法而言,可以保留更多的信息,并且通过集成,可以拓展算法的假设空间.因而在出现数据的特征不符合降维算法的假定时,采用随机变换降维处理后对数据进行回归分析得到的均方误差会更小,预测结果更准确. 图2 模拟数据散点图Fig.2 Scatter plot of simulated data 3.2数据构造 模拟实验采用的数据通过以下方式构造: a. 构造n维随机向量a,k维随机向量b,向量中的元素相互独立且服从均值为0,标准差为σ的正态分布. b. 构造n维随机向量xk+1,xk+2,…,xm(m>k),xk+1,xk+2,…,xm之间相互独立,且向量中的元素相互独立且服从标准正态分布.令x=aT×b, 由于完全的多重共线性在实际问题中较少出现,因此再对X中所有元素加上随机扰动,扰动项服从标准正态分布. c. 对XT进行奇异值分解,得到XT=WΣVT,其中m×m矩阵W是XTX的本征矢量矩阵,Σ是m×n的非负矩形对角矩阵,V是XXT的本征矢量矩阵. e. 以n行m列矩阵X作为自变量,n维向量Y作为因变量,构造成实验所需的数据集,在实际实验操作中,n与m设置为1 000. 3.3实验设置 本文采用随机生成的1 000个样本进行实验,其中600个样本用于训练,400个样本用于预测.回归分析采用多元线性模型,RTDR以多元线性模型为基学习器和次学习器,用于对照的降维算法为PCA.实验首先不作降维处理,直接应用多元线性回归并观察结果,然后分别应用RTDR与PCA将原数据由1 000维降至200维、190维……直到降至10维,并分别在降维后的数据集上应用多元线性回归模型并观察结果. 3.4实验结果 实验对具有多重共线性的模拟数据进行回归分析,分别采用了PCA和随机变换降维对数据进行了处理.在未进行降维处理前,直接采用多元线性回归得到的均方误差(MSE)为29.73,而经降维处理后,均方误差可以缩减为原来的10%左右,可以有效克服多重共线性对回归分析的影响.并且,采用随机变换降维得到的MSE更小,说明经随机变换降维处理,可以得到更准确的预测结果.均方误差对比结果如图3所示. 实验还对经RTDR与PCA处理后采用多元线性回归模型进行预测得到的残差进行比较.图4为通过RTDR与PCA将原数据降至150维时,对多元线性回归得到的残差采用P-P图进行检验,观察是否残差符合正态分布. 图3 RTDR与PCA的均方误差比较Fig.3 Comparison between the MSEs of RTDR and PCA 可以看到,RTDR的残差基本分布在P-P图的对角线上,与PCA得到的残差相比,与对角线的偏离程度要更小,说明RTDR的残差要更接近于正态分布.再对RTDR与PCA得到的残差进行观察,两者的标准差、偏度、峰度如表1所示. 图4 RTDR与PCA的残差P-P图比较Fig.4 Comparison between the P-P plots of RTDR’s residual and PCA 表1 RTDR与PCA残差的标准差、偏度、峰度比较Tab.1 Comparison between the standard deviations,skewnesses and kurtosises of RTDR’s residual and PCA 可以看到,RTDR残差的标准差更小,说明残差的分布要更为集中.尽管峰度与PCA得到的残差峰度相似,但偏度明显要比PCA的偏度更小,进一步说明RTDR的残差更接近于正态分布. 从模拟数据的结果可以看到,经过RTDR处理后再进行多元线性回归,不仅有效克服了多重共线性问题,并且相对于PCA而言,RTDR得到的预测结果更为稳定、准确,并且对信息的提取更为充分. 4.1实验数据 在图像处理问题中,由于图片可能具有千万级的像素,将图片转换为数据后,数据的维度也将是千万级的,远远大于可用于训练算法的样本数量,因而图像处理问题是降维算法的重要应用领域之一.因此,本文通过MNIST (mixed national institute of standards and technology database)数据集上的实验,检验了在图像分类问题中随机变换降维的性能,并与一般的降维算法进行了比较. MNIST数据集是一个大型的手写数字识别数据集,是验证图像处理算法的常用数据集之一,也被广泛应用于训练和测试机器学习算法.MNIST数据集来源于NIST数据集,有训练集60 000例,测试集10 000例. MNIST数据集中的每一张图片都是0~9的单个数字,每一张都是抗锯齿(anti-aliasing)的灰度图,图片大小28×28像素,数字部分被归一化为20×20的大小,位于图片的中间位置,保持了原来形状的比例.MNIST数据集中的图片如图5所示. 图5 MNIST数据集中的图片Fig.5 Images in MNIST dataset MNIST数据集的来源是两个数据集的混合:一个来自Census Bureau employees (SD-3);一个来自high-school students (SD-1).有训练样本60 000个,测试样本10 000个.训练样本和测试样本中,employee和student写的各占一半.60 000个训练样本一共由250个人写,训练样本和测试样本的来源人群没有交集,MNIST数据库也保留了手写数字与身份的对应关系.实验中,MNIST中的每张图片被表示成784维的向量. 4.2实验设置 本文在MNIST数据集上进行实验,分别通过RTDR与PCA将MNIST数据集中的样本由784维降至100维、50维、25维、10维、3维、1维,并应用MLP在降维后的样本上进行训练,比较MLP在不同降维处理后的效果. MLP的参数设置为,隐层数(hidden layer sizes)=50,最大迭代次数(max iter)=10,L1罚系数alpha=0.000 1,优化方法为sgd,学习率为0.1. 4.3RTDR基学习器与PCA的比较结果 RTDR首先会通过随机变换生成多个子数据集,在子数据集上经过PCA处理后应用MLP作为基学习器,基学习器的输出作为次级学习器的输入.为验证随机变换不会损失原数据集的信息,本文通过实验对比了RTDR基学习器的训练准确率与直接通过PCA处理后的数据集上MLP的准确率,比较结果如表2所示. 可以看到,RTDR的基学习器(经过随机变换后采用PCA处理然后应用MLP)的训练准确率与在直接PCA降维后的数据上采用MLP的准确率非常接近,在部分情况下甚至会高于直接采用PCA降维的数据的准确率,说明经过随机变换的处理不会造成原数据集的信息损失. 4.4RTDR次级学习器与PCA的比较结果 RTDR基学习器的输出作为次级学习器的输入,次级学习器的输出为最终的输出结果.本文将RTDR次级学习器的准确率与经过PCA处理后的数据集进行比较,验证RTDR可以显著地减少降维带来的信息损失. 图6和图7为通过PCA与RTDR将MNIST数据集中的数据降至100维、50维、25维、10维、5维、3维、1维时,在PCA处理过的数据上应用MLP和在RTDR处理过的数据上应用MLP作为次级学习器时,两者的准确率差异.可以看到,随着降维程度的增加,PCA与RTDR处理的数据上应用MLP的准确率都在不断下降,说明降维的过程中必然会带来信息损失,影响在降维后的数据集上采用监督学习算法进行预测的准确率.但是采用RTDR准确率的下降速率要明显低于采用PCA,在最低端情况下,将原数据集降至1维,采用PCA仅有0.3左右的准确率,但是采用RTDR仍然能有接近0.7的准确率.不同降维幅度下PCA与RTDR的次级学习器的准确率比较如图6和图7所示. 表2 RTDR基学习器与PCA训练准确率比较Tab.2 Comparison between the accuracies of the RTDR’s base learner and the training of PCA 图6 RTDR次级学习器与PCA训练准确率比较Fig.6 Comparison between the accuracies of the RTDR’s secondary learner and the training of PCA 图7 RTDR次级学习器与PCA测试准确率比较Fig.7 Comparison between the accuracies of the RTDR’s secondary learner and the testing of PCA 从实验结果可以看到,采用RTDR可以显著减少降维过程中带来的信息损失,经过RTDR处理后,可以有效解决多重共线性问题,并且用于预测时,相对于传统的降维算法可以获得更高的准确性和稳定性,并且提取信息更充分.采用RTDR进行降维的计算复杂度要高于直接采用PCA,但是RTDR的结构可以使其自然地采用分布式计算,减少计算所需要消耗的时间.但是,RTDR仍然存在有待改进的地方,主要包括两点:a.只适用于定量数据,不适合定性数据,对定性数据采用RTDR难以取得良好的效果也缺乏可解释性;b.RTDR只适用于将数据进行降维然后进行预测的问题,即只适用于监督学习的场景,对于无监督学习的情况不能采用RTDR. [1] BELKIN M,NIYOGI P.Laplacian eigenmaps for dimensionality reduction and data representation[J].Neural Computation,2003,15(6):1373-1396. [2] FRANZ T,ZIMMERMANN R,GÖRTZ S.Adaptive sampling for nonlinear dimensionality reduction based on manifold learning[M]∥BENNER P,OHLBERGER M,PATERA A,et al.Model Reduction of Parametrized Systems.Cham:Springer,2017. [3] LIU Y,GU Z L, CHEUNG Y M,et al.Multi-view manifold learning for media interestingness prediction[C]∥Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval.Bucharest,Romania:ACM,2017:308-314. [4] YANG L,WANG X.Online Appearance manifold learning for video classification and clustering[C]∥International Conference on Computational Science and Its Applications.Beijing:Springer,2016:551-561. [5] TENENBAUM J B,DE SILVA V,LANGFORD J C.A global geometric framework for nonlinear dimensionality reduction[J].Science,2000,290(5500):2319-2323. [6] YANG B,XIANG M,ZHANG Y P.Multi-manifold discriminant Isomap for visualization and classification[J].Pattern Recognition,2016,55:215-230. [7] QU T,QU T,CAI Z X,et al.An improved Isomap method for manifold learning[J].International Journal of Intelligent Computing and Cybernetics,2017,10(1):30-40. [8] ZHANG Z Y,ZHA H Y.Principal manifolds and nonlinear dimensionality reduction via tangent space alignment[J].Journal of Shanghai University (English Edition),2004,8(4):406-424. [9] GOLDBERGER J,ROWEIS S,HINTON G E,et al.Neighbourhood components analysis[C]∥Proceedings of the Conference on Neural Information Processing Systems.Cambridge:MIT Press,2004. [10] OPITZ D,MACLIN R.Popular ensemble methods:an empirical study[J].Journal of Artificial Intelligence Research,1999,11:169-198. [11] POLIKAR R.Ensemble based systems in decision making[J].IEEE Circuits and Systems Magazine,2006,6(3):21-45. [12] ROKACH L.Ensemble-based classifiers[J].Artificial Intelligence Review,2010,33(1-2):1-39. [13] ZHOU Z H.Ensemble methods:foundations and algorithms[M].Boca Raton:CRC press,2012. [14] LIU T Y.Easy ensemble and feature selection for imbalance data sets[C]∥International Joint Conference on Bioinformatics,Systems Biology and Intelligent Computing.Shanghai:IEEE,2009:517-520. [15] KROGH A,VEDELSBY J.Neural network ensembles,cross validation,and active learning[C]∥Proceedings of the 7th International Conference on Neural Information Processing Systems.Denver:MIT Press,1995:231-238. [16] BLASER R,FRYZLEWICZ P.Random rotation ensembles[J].Journal of Machine Learning Research,2016,17(4):1-26. [17] WOLPERT D H.Stacked generalization[J].Neural Networks,1992,5(2):241-259. [18] 徐雅静,汪远征.主成分分析应用方法的改进[J].数学的实践与认识,2006,36(6):68-75. [19] 马庆国.管理统计:数据获取、统计原理SPSS工具与应用研究[M].北京:科学出版社,2008:308-315. [20] 林海明.对主成分分析法运用中十个问题的解析[J].统计与决策,2007(8):16-18. [21] BREIMAN L.Stacked regressions[J].Machine Learning,1996,24(1):49-64. [22] OZAY M,VURAL F T Y.A new fuzzy stacked generalization technique and analysis of its performance[Z].arXiv preprint arXiv:1204.0171,2013. [23] SMYTH P,WOLPERT D.Linearly combining density estimators via stacking[J].Machine Learning,1999,36(1/2):59-83. DimensionReductionMethodBasedontheRandomRotationEnsemble WANG Tuo,XIAOQinxian (BusinessSchool,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China) For the random rotation ensemble method,a new dimension reduction algorithm named random transform dimension reduction was proposed,which can reduce the information loss caused by the reduction dimension.After the random transform dimension reduction,the training supervised learning algorithm can obtain higher accuracy and better generalization performance.Through the experiments on the simulated data,it is proved that the regression analysis using multiple collinearity data can retain more information and obtain smaller mean square error than the traditional dimensionality reduction method.The performance of the random transform dimension reduction in handwritten numeral recognition datasets was studied,and it is proved that,compared with the general dimensionality reduction algorithm,the random transform dimension reduction can achieve higher accuracy in image classification. ensemblelearning;randomrotationensemble;dimensionreduction;diversity 1007-6735(2017)05-0450-09 10.13255/j.cnki.jusst.2017.05.008 2017-03-16 王 椭(1993-),男,硕士研究生.研究方向:金融工程.E-mail:1210724980@qq.com 肖庆宪(1956-),男,教授.研究方向:金融工程.E-mail:qxxiao@163.com TP181 A (编辑:丁红艺)
2 随机变换降维算法的构造

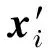

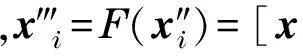
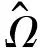


3 模拟实验




4 手写数字识别数据集(MNIST)实验


5 结束语
猜你喜欢
车主之友(2022年4期)2022-08-27
网络安全与数据管理(2022年3期)2022-05-23
科学与财富(2021年3期)2021-03-08
北京航空航天大学学报(2020年10期)2020-11-14
海峡姐妹(2019年12期)2020-01-14
自动化学报(2019年6期)2019-07-23
——以多重共线性内容为例
长沙航空职业技术学院学报(2019年2期)2019-07-13
温州大学学报(自然科学版)(2019年2期)2019-06-04
火控雷达技术(2016年1期)2016-02-06
河南科技(2015年8期)2015-03-11
