
基于结构特征的二进制代码安全缺陷分析模型
2017-11-10 08:02许团屈蕾蕾石文昌
网络与信息安全学报 2017年9期
许团,屈蕾蕾,石文昌
基于结构特征的二进制代码安全缺陷分析模型
许团,屈蕾蕾,石文昌
(中国人民大学信息学院,北京 100872)
针对现有方法检测复杂结构二进制代码安全缺陷的不足,提出新的分析模型,并给出其应用方法。首先以缺陷的源代码元素集合生成特征元素集合,抽取代码结构信息,构建分析模型。然后依据各类中间表示(IR, intermediate representation)语句的统计概率计算分析模型,查找满足特征模型的IR代码组,通过IR代码与二进制代码的转换关系,实现对二进制程序中代码安全缺陷的有效检测。分析模型可应用于二进制单线程程序和并行程序。实验结果表明,相对于现有方法,应用该分析模型能够更全面深入地检测出各类结构复杂的二进制代码安全缺陷,且准确率更高。
二进制分析;分析模型;软件安全缺陷检测;缺陷代码识别
1 引言
二进制程序中的安全缺陷是危害软件系统的安全性和可靠性的重要原因,目前二进制程序的安全性检测成为研究热点。根据有代表性的研究成果[1~3]可知,多数类型的软件安全缺陷是在程序代码的实现过程中产生。本文把程序代码实现过程中产生的各种类型软件安全缺陷称为代码安全缺陷,并把二进制程序中代码安全缺陷称为二进制代码安全缺陷。
近年来,各种结构复杂的二进制代码安全缺陷日益繁多。例如,后门、竞争条件及鉴权绕过等逻辑错误类型的代码安全缺陷。它们不仅存在于二进制单线程程序,而且分布于各种二进制并行程序。而符号执行[4,5]、污点分析[6,7]及模糊测试[8,9]等现有方法难以发现结构复杂的代码安全缺陷,也不能有效地应用于二进制并行程序,使软件系统面临安全性风险。分析现有方法的检测过程可知,这些方法均未深入解析二进制代码安全缺陷代码结构,不能有效地识别其结构特征,从而产生上述不足。
本文提出对二进制代码安全缺陷的分析模型。应用该模型,可以有效地解决现有方法的不足。本文创新点如下。
1) 给出对二进制代码安全缺陷的分析原理,基于该分析原理提出二进制代码安全缺陷分析模型的构建方法。该方法首先基于代码安全缺陷的源代码元素集合构建中间表示代码元素集合,以校验样本测试IR代码元素集合,获取缺陷IR代码的关键特征,建立特征元素集合。然后以IR语句的执行关系划分特征元素集合,并提取特征元素包含的结构信息生成分析模型。分析模型完整包含了代码安全缺陷的结构特征信息,能够为准确检测二进制程序中各类代码安全缺陷提供充分的支持及有效的判定标准。
2) 给出对二进制代码安全缺陷分析模型的应用原理,基于该应用原理提出分析模型的应用方法,依据分析模型中结构特征信息实施对二进制程序中代码安全缺陷的有效检测。首先基于IR语句的统计概率计算分析模型中各路径单元的权重,利用工具VTS获取二进制程序的IR执行路径集合。然后在IR执行路径中检测满足分析模型的IR代码组,并通过IR语句与机器指令之间的对应信息,检测出被测试二进制程序中代码安全缺陷。该方法既能够准确地查找出现有方法难以发现的各类结构复杂的二进制代码安全缺陷,也可以有效地应用于现有方法难以检测的二进制并行程序,并且其检测过程无需触发代码安全缺陷,能够有效地避免检测结果的误报和漏报。
2 模型构建
为了阐述二进制代码安全缺陷分析模型的构建方法,有必要给出以下若干定义。
定义1(程序执行路径)在二进制程序B的一次执行过程中,每一个线程执行的机器指令序列都称为一条指令序列。对B执行过程产生的任意一条指令序列,若移除其中不包含于B的机器指令,则得到的机器指令序列称为B的一条指令执行路径。若程序分析工具把B的一条指令执行路径转换为一条IR语句序列,则该IR语句序列称为B的一条IR执行路径。IR执行路径与指令执行路径统称为程序执行路径。
定义2(代码组)任意一个源程序P中语义相关的(≥1)个代码段构成一个源代码组。在P编译为二进制程序B的过程中,若P中一个源代码组编译生成(≥1)个机器指令段,则该个机器指令段构成一个二进制代码组,称为的机器码,称为的源码。当程序分析工具把B的指令执行路径转换为IR执行路径时,若包含的机器指令被转换为个IR语句段,则该个IR语句段构成一个IR代码组,称为和的IR码,称为的源码,称为的机器码。源代码组、二进制代码组及IR代码组统称为代码组。
定义3(缺陷IR代码)若类型软件安全的缺陷是在程序代码的实现过程中产生,则称其为类型代码安全缺陷。若源程序中一个类型代码安全缺陷包含(≥1)个代码段,则该个代码段构成的一个源代码组,称为类型缺陷源代码,并称的机器码及IR码分别为类型缺陷二进制代码及类型缺陷IR代码。
定义4(IR语句的匹配)设为一条程序语句,对中任意一项数据,称为的数据,记为∈。设u、u为两条IR语句,若它们之间满足以下条件:①u和u的语句类型相同;②对任意数据d∈u,存在数据d∈u,u中d的位置与u中d的位置相同,且d与d具有相同的类型。则称u与u匹配,记为u↔u。

基于上述概念可知,缺陷源代码、缺陷二进制代码及缺陷IR代码都是代码安全缺陷的具体存在形式,它们之间可以相互转换,对它们的代码结构进行有效的分析,是检测代码安全缺陷的基础和前提。本文对二进制代码安全缺陷的分析原理如图1所示。
首先把缺陷源代码转换为缺陷IR代码,基于校验样本提取出其代码特征。其次利用程序语句之间的执行关系,划分代码特征的组成部分。然后对各组成部分进行形式化抽象,获取其中代码结构的完整信息。由于IR语句与机器指令之间一一对应,且语义相同,所以上述过程获取的结构特征信息准确地描述了二进制代码安全缺陷的具体存在形式,能够作为检测二进制程序中代码安全缺陷的有效依据。
根据上述原理,给出构建任意类型二进制代码安全缺陷的分析模型的6个主要步骤。
步骤2 把源程序P编译为二进制程序B,应用工具VTS获取B的IR执行路径。VTS是基于开源软件Valgrind[10,11]和Taintgrind[12]实现的程序分析工具,能够监控B的动态执行过程。当B的动态执行过程结束,VTS不仅输出B的IR执行路径,而且输出IR语句、机器指令及源程序语句之间的对应信息,据此能够定位每一条源程序语句所对应的机器指令组和IR语句组。图2中示例为Linux C语句“if()”对应的机器指令组和IR语句组。

图1 二进制代码安全缺陷分析原理

图2 if(t)对应的机器指令组及IR语句组
步骤4 构建校验样本集合。首先收集候选校验样本,建立候选校验样本集合。对任意一个IR代码组,若其满足如下条件:①不是缺陷IR代码;②中IR语句与中IR语句一一对应,且每一对对应的IR语句之间都具有匹配关系。则选择作为候选校验样本,把放入候选校验样本集合。然后选择的一个子集,使以下条件成立:①对任意IR代码组λ,λ∈,λ与λ不匹配;②对任意IR代码组λ∈,存在IR代码组λ∈,满足:λ⇔λ。称为校验样本集合,其中IR代码组称为校验样本。
步骤5 构建特征元素集合。以IR代码元素集合和校验样本集合为输入,执行特征元素集合生成算法,得到集合,其中元素描述了缺陷IR代码的关键特征,称为特征元素。
算法1 特征元素集合生成算法Characterisic- ElementSetGenerate
输入 IR代码元素集合,校验样本集合
输出 特征元素集合
1)←
2) for each (u,,u)∈do
3) if PreOpt ((u,,u),,)==False then
4) RelationVectorOpt ((u,,u),,)
5) for each (u,,u)∈do
6) if FurOpt ((u,,u),,)==False then
7) RelationVectorOpt ((u,,u),,)
8) foreach (u,,u)∈do
9) if ER ((u,,u),,)==False then
10) RelationVectorOpt ((u,,u),,)
11) return
算法1中各函数分别执行不同的检测过程,下面分别阐述。
1) 函数PreOpt((u,,u),,)检测向量中语句关系。若包含数据共享关系,则返回True。否则,返回函数ElementRedundancy ((u,,u),,)。
2) 函数FurOpt ((u,,u),,)在向量中查找数据依赖关系。若中包含数据依赖关系,则返回True。否则,返回函数ER ((u,,u),,)。
3) 函数ER((u,,u),,)去除中(u,,u),并调用SampleMatching(,),若其返回True,则把(u,,u)加入集合,返回False。否则,返回True。
4) 函数RelationVectorOpt((u,,u),,)检测向量中冗余的语句关系,过程如下。
①查找中未检测的语句关系。若中不存在未检测的语句关系,则检测过程结束。否则,从中去除任意一项未检测的语句关系,设其为r。然后调用函数SampleMatching(,)。
②若函数SampleMatching返回True,则把r加入,并标记其为已检测。执行步骤①。
5) 函数SampleMatching(,)基于中校验样本检测集合。若存在校验样本∈,的语句与的语句之间具有一种一一对应关系,成立如下条件。
②对任意IR代码元素(u,,u)∈,若其中uu分别与的语句u、u对应,则u与u之间具有向量中全部关系。
则函数返回True。否则,函数返回False。
步骤6 生成二进制代码安全缺陷的分析模型。首先划分集合中元素,主要过程为:①把集合中不包含于任意一条IR执行路径的元素放入集合1;②把集合中不包含于1的元素分别放入集合1~L,使L(1≤≤)中元素包含于同一条IR执行路径;③把集合1~L分别作为元素加入集合2,得到2={1,…,L}。1~L及1称为的路径子集。
然后以集合序偶<1,2>为输入,执行分析模型生成算法,得到分析模型<1,2>,1中元素D(1≤≤)称为路径单元,2称为组合单元,2和D中元素称为模型元素。
算法2 分析模型生成算法AnalysisModel- Generate
输入 集合序偶<1,2>
输出 分析模型<1,2>

2) foreachL∈2do
4) foreach ((u,,u)∈Ldo
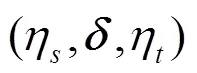
7)1←1∪{D}
8) foreach (u,,u)∈1do
11) return <1,2>
算法2中,函数Transform(u,,u)以字符串标记IR语句u、u的关键信息,并把各字符串分别组成向量η=(o,a1,···,a)、η=(o,a1,···,a)。η、η称为语句项,其中字符串o、o分别标记了u、u的语句类型,称为语句类型字符串,字符串a(1≤≤)、a(1≤≤)分别标记了u、u中单项数据的类型及位置等数据信息,称为数据字符串。该函数返回以语句项η、η及关系向量构成的模型元素(η,,η)。
若类型二进制代码安全缺陷具有多种分析模型,则每一种分析模型的构建过程都需要经过上述步骤。上述建模过程在两个层次上对二进制代码安全缺陷的结构进行分析:不仅在程序语句的层次把其结构分解为模型元素集合,而且在程序执行路径的层次把其结构分解为路径单元和组合单元。这使分析模型完整包含了二进制代码安全缺陷的结构特征信息,不仅其包含的(≥1)个路径单元可以准确地描述二进制代码安全缺陷的个不同组成部分,并且其包含的组合单元给出了该个组成部分应满足的必要条件。因此,分析模型能够为准确地检测二进制程序中代码安全缺陷提供充分支持及有效的判定标准。
3 模型应用
应用分析模型可以实现对二进制代码安全缺陷的有效检测,分析模型的应用原理如下。
1) 依据分析模型中信息建立二进制代码安全缺陷的判定标准。以分析模型包含的(≥1)个路径单元分别作为二进制代码安全缺陷中个不同组成部分的识别标准,并把分析模型中组合单元作为该个组成部分之间的匹配标准,由项识别标准与1项匹配标准共同构成二进制代码安全缺陷的判定标准。
2) 基于判定标准把检测内容划分为项查找任务和1项组合任务。其中项查找任务分别在被测试程序代码中查找满足不同识别标准的代码组,组合任务是在查找得到的代码组中选出满足匹配标准的×(≥1)个代码组,并把它们组成个二进制代码安全缺陷。
3) 依据各路径单元分别描述的结构特征确定检测过程中各项任务的执行次序,从而使检测过程具有最高的效率。
依据上述原理把分析模型应用于二进制代码安全缺陷的检测过程,得到分析模型的应用方法,其简称为模型应用方法。该方法依据分析模型中结构特征信息实施对二进制代码安全缺陷的有效检测。下面给出该方法的主要内容。基于分析模型,定义以下若干关系。
定义6 (语句项与IR语句的匹配)设η、u分别为语句项及IR语句。对η中任意字符串a,记为a∈η。若u中数据的信息与字符串a标记的数据信息相一致,则称符合a。若η与u之间成立以下条件:①η中字符串标记的语句类型和u的语句类型相同;②对于任意数据字符串a∈η,存在数据∈u,符合a。则称u为η的像,并称η与u匹配,记为ηu。
定义8(路径单元相关)设<1,2>是代码安全缺陷特征模型,D、D是1中2个路径单元。若成立如下任意一项条件:
则称路径单元D与D相关,记为D∩D。若条件①成立,则语句项η称为D与D的相关语句项。若条件②成立,则模型元素(η,,η)称为D与D的相关元素。
定义9(路径单元与IR代码组的相关匹配)设D∩D,Dλ,Dλ,λ与λ为不同的IR代码组。若成立以下条件:
①若D与D具有相关语句项η,则存在λ和λ的共同语句u,满足:η⇹u;
则称路径单元D、D与IR代码组λ、λ相关匹配。
基于上述关系,下面给出对任意类型二进制代码安全缺陷的5个主要检测步骤。
步骤1 建立分析模型。全面选择各种不同结构的类型缺陷源代码,然后应用它们分别建立分析模型。设共得到(≥1)种类型二进制代码安全缺陷的分析模型。
步骤2 建立分析模型的权重集合。主要过程如下。
①度量各种类型IR语句的相对比率。首先,随机选择个具有类型代码安全缺陷的有代表性的二进制程序,应用VTS获取它们各自次不同执行过程产生的IR执行路径:1,···,q。然后,分别统计1~q中不同类型IR语句所占的比率。该步骤中和的取值与特征模型的复杂度成正相关。

步骤3 获取被测试二进制程序的IR执行路径集合。首先根据被测试程序的类型和功能,生成测试数据集作为程序输入。然后应用VTS监控该二进制程序的不同动态执行过程,获得IR执行路径集合。
步骤4 缺陷IR代码检测。分别输入种分析模型,应用缺陷IR代码检测算法,在集合包含的IR执行路径中检测类型缺陷IR代码,如算法3所示。
算法3 缺陷IR代码检测算法FlawIRCode- Detection
输入 分析模型<1,2>及其权重集合,IR执行路径集合
输出 缺陷IR代码集合
4)2
5) for eachD∈1do
9) return
10)22∪{D}
11)12-{D}
12)12
13) else
15) return
16) for each (η,,η)∈2do

18) return
算法3中应用了多个函数,分别阐述各函数的功能如下。
1) 函数CorrelationUnit(D,1,2)在集合1中查找与D相关的路径单元,依据查找结果生成识别条件。该函数返回识别条件集合。
2) 函数SI(,D,,,)遍历集合中执行路径查找路径单元D的像,以中识别条件对D的像进行有效性验证,并根据有效的验证结果更新集合和。对于查找得到的任意一个D的像λ,若λ满足中所有识别条件,则把λ放入D的像集G∈,并把验证过程得到的各条相关匹配信息加入集合。该函数最后返回G。
3) 函数MW(,1,,1,,)首先基于集合中权重信息选择1中权重最大的路径单元。设得到1中权重最大的路径单元D。然后遍历中IR执行路径查找D的像,把查找得到的各IR代码组放入D的像集G。若检测结束后G不为空集,则把D、G分别放入集合1、,并从1中去除D。该函数最后返回集合G。
5) 函数GenerateInstance(,)基于集合中的信息,把中各集合包含的IR代码组组合为缺陷IR代码。若中集合不包含缺陷IR代码,则该函数返回空集。否则,该函数返回集合={1,···,ξ},其中ξ(1≤≤)为检测得到的一个类型缺陷IR代码。
步骤5 获取类型缺陷二进制代码。基于集合中缺陷IR代码,应用VTS输出的IR语句与机器指令之间的对应信息,查找出被测试二进制程序中个类型缺陷二进制代码,它们构成了该程序中个类型代码安全缺陷。
基于以上检测过程可知,上述模型应用方法具有如下功能和优点:①对任意类型代码安全缺陷的检测功能;②对结构复杂的代码安全缺陷的检测功能;③能够准确地识别代码安全缺陷,从而有效地避免检测结果的误报和漏报;④检测过程无需触发二进制代码安全缺陷。
4 实验验证
实验目的为验证二进制代码安全缺陷分析模型的实用性和有效性。为此,实验中对模型应用方法进行验证,实验内容包括:①方法的功能和优点验证;②方法的有效性验证。根据该方法实施的检测过程可知,上述实验内容能够准确地验证分析模型的实用性和有效性。
实验中被测试代码安全缺陷的选择标准如下:①其类型具有代表性,该类型的代码安全缺陷广泛存在于各类软件系统及二进制程序,且目前对其尚无有效的检测方法;②具有复杂的结构;③具有较大的识别难度;④具有较大的检测难度;⑤包含于结构较复杂的二进制程序。
基于以上选择标准,实验中选择二进制多线程程序中竞争条件(race condition)类型代码安全缺陷作为检测对象。基准测试程序如表1所示,B1~B3分别以算法1~3作为线程同步算法,其中算法1、2能够产生竞争条件。算法1~3是语义较复杂、有代表性的同步算法。Holzmann在其被引用4 680多次的论文“The Model Checker SPIN”[13]中给出算法1、2,其中算法2是对算法1的修正算法。Bang等在论文“Comments on ‘The Model Checker SPIN’”[14]中以实时进程代数ACSR[15]检测出算法2并未消除竞争条件,于是给出算法1的正确修正算法——算法3。

表1 基准测试程序
通过对B1~B3的测试,不仅可以有效地验证模型应用方法的功能和优点,而且能够准确地验证该方法的有效性,依据如下:①算法1~3是语义较复杂的同步算法,使B1~B3的二进制代码结构较复杂,具有较大的检测难度;②B1、B2中竞争条件类型代码安全缺陷包含复杂的代码结构,使它们具有较大的识别难度和检测难度;③B1~B3的代码结构相似,使B3中存在多个二进制代码组与B1、B2中缺陷二进制代码具有相似的代码结构,所以B3中这些代码组能够有效地检验模型应用方法对代码安全缺陷识别能力,从而验证该方法是否能够有效地避免检测结果的误报和漏报;④B1~B3的动态执行过程被实时监控,若产生竞争条件可以被及时发现和记录。
实验中,计算机硬件配置为Intel Core 2 Duo (CPU 2.4 GHz)、2 GB内存及4 MB二级缓存,操作系统为Ubuntu Linux 14.04 (4.4 HWE kernel),处理器架构为 X86/Linux。程序分析工具VTS中Valgrind版本为3.12.0。Linux C源代码应用GCC 5.3编译为二进制程序。
4.1 方法功能和优点验证
首先以模型应用方法测试B1~B3中竞争条件类型代码安全缺陷。测试结果如下:B1和B2中分别存在竞争条件类型代码安全缺陷1、2,如表2、表3所示。根据B1~B3的动态执行过程可知,该测试过程没有使B1~B3中线程之间产生竞争条件。

表2 χ1中机器指令

表3 χ2中机器指令
然后以文献[13,14]中的正确结论与上述测试结果进行对比分析,得到模型应用方法的测试结果完全正确,不存在误报和漏报。因此,该方法的功能和优点得到全面验证。
4.2 方法有效性验证
Helgrind[16]和DRD[17]是两款检测线程同步错误的成熟工具,能够有效地检测出多种类型的线程同步错误。由于Helgrind和DRD分别应用了国际上现有的多种实用检测方法,所以根据它们对B1~B3的检测结果可以准确地评估模型应用方法的有效性。
实验中以2017年6月最新发布的Helgrind和DRD对B1~B3检测,它们在完成检测后分别给出对多个数据变量的警告。其中Helgrind对B1中r_want的警告如图3所示,DRD对B3中state(0x0804a048)的警告如图4所示。经过检验,Helgrind和DRD的检测结果均漏报了B1和B2中竞争条件类型代码安全缺陷,且它们给出的各条警告均为误报。根据Helgrind和DRD的检测结果可以得到评估结论:相比较国际上现有检测方法,模型应用方法可以有效地应用于二进制并行程序,能够检测出现有方法难以发现的结构复杂的代码安全缺陷,具有更加全面和深入的检测能力,并且其检测结果具有更高的准确率。由此模型应用方法的有效性得到验证。

图3 Helgrind对B1中“r_want”的警告

图4 DRD对B3中“state”的警告
基于以上两项实验内容的结论可知,分析模型可以应用于任意类型二进制程序的代码安全缺陷检测过程,其包含的信息可以为识别与检测二进制代码安全缺陷提供充分的支持及有效的判定标准,使任意类型结构复杂的二进制代码安全缺陷能够被准确和高效地检测出来。所以二进制代码安全缺陷分析模型的实用性和有效性得到验证。
5 结束语
为实现对结构复杂的二进制代码安全缺陷的有效检测,本文给出对二进制代码安全缺陷的分析原理,提出二进制代码安全缺陷的分析模型,并依据分析模型的应用原理,给出分析模型的应用方法。首先提取缺陷IR代码的关键特征,抽象其中结构信息,生成二进制代码安全缺陷的分析模型。然后用工具VTS获取二进制程序的IR执行路径集合,基于各类语句的统计概率计算路径单元的权重,依据缺陷IR代码检测算法遍历IR执行路径,查找满足特征模型的IR代码组,并通过IR代码与二进制代码的转换信息,检测出二进制程序中代码安全缺陷。
实验结果表明,分析模型兼具实用性和有效性,应用分析模型可以检测出现有方法难以发现的各类结构复杂的二进制代码安全缺陷,分析模型的应用方法无需源代码,能够直接检测二进制应用程序,极大提高了检测结果准确率,具有简单、方便的优点。分析模型可以应用于软件开发维护、漏洞挖掘与利用及程序分析与测试等多种领域。同时,分析模型能够有效地应用于现有方法难以检测的二进制并行程序,所以随着网络和并行系统的发展,其具有广泛的应用前景。
[1] LANDWEHR C E, BULL A R, MCDERMOTT J P, et al. A taxonomy of computer program security flaws[J]. Computing Surveys , 1994, 26(3): 211-254.
[2] WEBER S, KARGER P A, PARADKAR A. A software flaw taxonomy: aiming tools at security[C]//The Workshop on Software Engineering for Secure Systems—Building Trustworthy Applications. 2005: 1-7.
[3] HUI Z, HUANG S, REN Z, et al. Review of software security defects taxonomy[C]//The 5th International Conference on Rough Set and Knowledge Technology, Lecture Notes in Computer Science. 2010: 310-321.
[4] ZHANG B, FENG C, WU B, et al. Detecting integer overflow in windows binary executables based on symbolic execution[C]//The 17th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing. 2016:385-390.
[5] SIDIROGLOU-DOUSKOS S, LAHTINEN ERIC, RITTENHOUSE N, et al. Targeted automatic integer overflow discovery using goal-directed conditional branch enforcement[C]//The Twentieth International Conference on Architectural Support for Programming Languages and Operating Systems.2015: 473-486.
[6] YADEGARI B, STEPHENS J, DEBRAY S. Analysis of exception-based control transfers[C]//The Seventh ACM on Conference on Data and Application Security and Privacy.2017: 205-216.
[7] MING J, WU D, WANG J, et al. StraightTaint: decoupled offline symbolic taint analysis[C]//The 31st IEEE/ACM International Conference on Automated Software Engineering.2016: 308-319.
[8] CHA S K, WOO M, BRUMLEY D. Program-adaptive mutational fuzzing[C]//The IEEE Symposium on Security and Privacy.2015: 725-741.
[9] PHAM V, BÖHME M, ROYCHOUDHURY A. Model-based whitebox fuzzing for program binaries[C]//The 31st IEEE/ACM International Conference on Automated Software Engineering. 2016: 543-553.
[10] The valgrind developers[EB/OL]. http://valgrind.org.
[11] NETHERCOTE N, SEWARD J. Valgrind: a framework for heavyweight dynamic binary instrumentation[J]. ACM SIGPLAN Notices, 2007, 42(6):89-100.
[12] [EB/OL]. https://github.com/wmkhoo/taintgrind.
[13] HOLZMANN G J. The model checker SPIN[J]. IEEE Transactions on Software Engineering, 1997, 23(5): 279-295.
[14] BANG K, CHOI J, YOO C. Comments on “the model checker SPIN”[J]. IEEE Transactions on Software Engineering, 2001,27(6): 573-576.
[15] BRÉMOND-GRÉGOIRE P, CHOI J, LEE I. A complete axiomatization of finite-state ACSR processes[J]. Information and Computation, 1997,138 (2): 124-159.
[16] The valgrind developers.[EB/OL]. http://valgrind.org/docs/manual/ hg-manual.html.
[17] The valgrind developers[EB/OL]. http://valgrind.org/docs/manual/ drd-manual.html.
Analysis model of binary code security flaws based on structure characteristics
XU Tuan, QU Lei-lei, SHI Wen-chang
(School of Information, Renmin University of China, Beijing 100872, China)
Aiming at the shortcomings of the existing methods to detect the security flaws that have complex structures, a new analysis model and its application method was proposed. First, analysis models based on key information of code structures extracted from path subsets of characteristic element sets that are generated by source code element sets of code security flaws were constructed. Then the analysis model according to the statistical probability of each kind of IR statement was calculated, and the IR code group which matched the feature model was found. Finally, through the translating relation between binary codes and IR codes, various code security flaws of binary program were found out. The analysis models can be applied to both common single-process binary programs and binary parallel programs. Experimental results show that compared with the existing methods, the application of the analysis model can be more comprehensive and in-depth in detecting various types of complex binary code security flaws with higher accuracy.
binary analysis, analysis model, software security detection, flaw code recognition
TP309.5
A
10.11959/j.issn.2096-109x.2017.00200
2017-07-24;
2017-08-13。
屈蕾蕾,daisyqvruc@163.com
国家自然科学基金资助项目(No.61472429);北京市自然科学基金资助项目(No.4122041)
The National Natural Science Foundation of China (No.61472429), The Natural Science Foundation of Beijing (No.4122041)
许团(1973-),男,黑龙江鹤岗人,中国人民大学博士生,主要研究方向为信息安全。

屈蕾蕾(1995-),女,新疆乌鲁木齐人,中国人民大学博士生,主要研究方向为可信计算、云安全。
石文昌(1964-),男,广西浦北人,中国人民大学教授、博士生导师,主要研究方向为系统安全、可信计算与数字取证。

猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
中等数学(2021年8期)2021-11-22
新世纪智能(语文备考)(2020年4期)2020-07-25
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
中国医学装备(2016年6期)2016-12-01
火控雷达技术(2016年2期)2016-02-06
燕山大学学报(2015年4期)2015-12-25
小学生·多元智能大王(2014年6期)2014-07-09
土木建筑工程信息技术(2013年3期)2013-10-17
