
数据挖掘在学生成绩分析中的应用
2017-11-08 20:59沈伟明
商情 2012年48期
沈伟明
[摘要]学校里每年都存放着大量的学生信息,这些信息的大部分是用于今后查对,如果这些成千LYY的信息只用于核对和备案,可以说这是一种信息浪费。如何充分地利用這些数据,使其潜在的使用价值得到充分的挖掘和利用,为学校决策者提供决策依据,科学指导教学。本文利用现有学生成绩数据库,应用改进的数据挖掘Apfiofi算法进行了情况分类,分析《c语言程序设计》课程成绩优秀直接影响《数据结构》课程成绩优秀.学校可以调整教学内容和改进教学方法以适应学生的学习和教学质量的提高。
[关键词]数据挖掘;关联规则;Apfiofi算法
一、数据挖掘概述
1.1数据挖掘
数据挖掘是近几年来新兴的一种对数据处理的技术,又称为数据库中的知识发现,就是从大量的、不完全、有噪声的、模糊的、随机的数据中,提取隐含在其中的,人们事先不知道的,但又是潜在有用的信息和知识(模型或规则)的过程,是一类深层次的数据分析方法。数据挖掘的第一步就是将手中的信息进行预处理操作后存放在数据仓库中。数据预处理包括数据清理与数据集成,数据清理的内容有消除噪声和不一致数据,对于本文研究的学生成绩数据库,因为在学生成绩输入过程中可能出现输入失误。数据集成就是将多种数据源统一为一种存储方式,在研究的学生成绩信息大部分是以电子表格(EXCEL)和WPs文件格式存储的,除此之外还有文本格式(TXT)与其它格式,要研究多年来所有学生的信息,必须把它们放在一个统一数据库中以便数据挖掘系统进行挖掘。数据挖掘在最近几年里已被数据库界广泛研究,其中关联规则的挖掘是一个重要的方面.
1.2关联规则
关联规则挖掘是在大量数据中项集之间发现有趣的关联或相关联系,是一种简单却很实用的分析规则。满足x的数据库元组也很可能会满足Y。关联规则挖掘问题可以划分成两个子问题:发现频繁项目集;生成关联规则。
1.3Apfiofi算法
首先设计一个保存有所有项集的类,它的主要属性有PID:PID项集;Sup_count:PID项集的支持计数,还包含一个主要方法,目的是判断PID对象是否是频繁项集。然后,我们要找到频繁集项,根据事务表的存储方式,对表进行简单l的SQL查询就可得到支持计数,从而判断是否是频繁一项集。找到频繁一项集就可以通过频繁k项集找了频繁k+1项集,主要过程为:构造出频繁k项集的Lu和Lv,对其进行连接步计算,如果可以连接,则生成候选的k+1项集;对通过连接步生成的候选k+1项集通过频繁k项集进行MN,缩小候选k+1项集;统计选k+1项集的支持度,通过对事物集进行SQL统计,计算出k+1项集的支持技术,若满足最小支持度,则标记为频繁项集。最后,对所有频繁项集L找出其所有非空真子集Lu,计算Lu和L-Lu的置信度,这个即是频繁项集又满足最低之心度的项集即为一条关联规则。至此,Apfiofi算法在程序中基本实现,运行程序,测试器有效性和效率,完成关联规则并给出结果。
二、方案实施实例
1、挖掘对象及目标:本例以我校2009级计算机应用技术专业毕业班的学生成绩为原始数据,采用关联规则和Apfiofi算法对该数据进行分析,大致说明数据挖掘在高校成绩管理中的应用。
2、数据采集:成绩数据库中包括了学生的平时作业成绩及课程的考试成绩。这个数据库由教师在教学过程中产生。
3、模型的选定:分析学生各科目成绩的之间的影响关系,例如:某学生《c语言程序设计》优秀与《数据结构》优秀的关系。我们采用关联规则中最著名的Apfiofi算法。
4、集成数据:将采集到的多个数据库的数据进行合并操作。
5、清理数据:在统计学生成绩源表数据时,会存在一些属性缺少属性值的情况,对于这些缺少属性值的属性,采用清理技术来填补空缺的数据值.本文采用忽略元祖的方法把没有参加考试学生及成绩数据不完整的记录n除掉.最后得到有效记录数据。
6、转换数据:使用统一的格式表示成绩数据,便于数据挖掘、本文挖掘的是软件专业学生备门课程之间的优秀关系,使用关联规则挖掘成绩数据需要逻辑性数据,所以大于90分成绩定义属性值为“1”。
三、Apriori算法数据挖掘
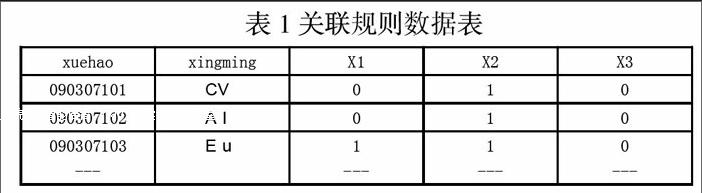
1)建立事务数据表,根据挖掘要求,只保留优秀成绩,没有获得优秀的学生记录做n除处理。2)频繁项集的数据表.表中用来存放项目名称xl,X2及包含此项目的记录数。3)将数据表中支持度计数小于最小支持度的记录n除,得到最终频繁l项集.4)求后继各频繁项目集.5)把最终频繁项集中小于最小置信度。值的记录n除,从而产生规则信息,存人数据表1。
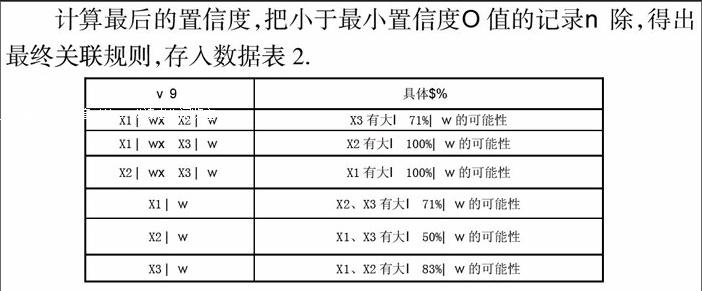
计算最后的置信度,把小于最小置信度0值的记录n除,得出最终关联规则,存入数据表2
总之,随着数据分析技术的发展,数据挖掘在学校教学管理方面有着巨大的应用潜力,高校的教育管理者应该充分认识到信息的重要性,提高信息的利用效率。endprint
猜你喜欢
西部交通科技(2021年9期)2021-01-11
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
电子技术与软件工程(2016年22期)2016-12-26
移动通信(2016年20期)2016-12-10
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
哈尔滨理工大学学报(2016年2期)2016-09-12
计算机教育(2006年9期)2006-09-22
