郭 强,邹广天,连 菲,张 斯
(1.哈尔滨工业大学 建筑学院,哈尔滨150006;2.哈尔滨工业大学 建筑计划与设计研究所,哈尔滨 150006;3.黑龙江省寒地建筑科学重点实验室(哈尔滨工业大学), 哈尔滨 150006)
应用Web标注技术的建筑图像语义采集方法
郭 强1,2,3,邹广天1,2,3,连 菲1,2,3,张 斯1,2,3
(1.哈尔滨工业大学 建筑学院,哈尔滨150006;2.哈尔滨工业大学 建筑计划与设计研究所,哈尔滨 150006;3.黑龙江省寒地建筑科学重点实验室(哈尔滨工业大学), 哈尔滨 150006)
为解决建筑师难以快速地从互联网中检索到符合创作需求的建筑图像的问题,提出了应用Web标注技术的建筑图像语义采集方法.首先,从建筑学角度界定了建筑图像及建筑图像语义的概念和类型;其次,给出了该方法的总体框架和操作流程; 最后,以著名建筑网站为例进行案例演示,验证了该方法的可行性和有效性.操作流程细分为3个步骤,以人工添加和在线学习的方式建立建筑语义词典;运用数据采集软件,从建筑图像所在网页中分别采集图像名称、图像注释、图像周围文本、所在网页标题、所在网页正文、图像超链接网页标题6项图像相关文本;根据图像语义提取规则,从上述文本中提取建筑图像语义,与图像文件建立关联后存储到建筑图像数据库.案例检验结果表明,该方法是可行的,具有较强的操作性,能够自动、批量地从互联网中下载建筑图像,并采集图像名称、图像类别、图像主题、项目名称、项目类型等30多项特征,有效地克服了建筑图像查询效率较低的问题,进而提升了建筑师运用互联网图像进行创作的能力.
Web标注技术;建筑图像;建筑图像语义;建筑语义词典;图像语义采集
目前,国内外学者关于建筑图像的语义提取、查询与检索方面的研究较少.涂喆夫[1]从角点检测、特征线匹配、图像平面分割3个角度,提出了建筑图像的底层拓扑特征提取算法,但并未涉及建筑语义特征的提取方法.魏力恺[2]构建了建筑空间关系原型Space Grammar,并开发出基于此原型的建筑空间检索软件Architable,能够实现建筑图像检索,但这种方式需要做大量的准备工作,难以适用于互联网环境下的大规模图像检索.张颉等[3]基于Revit API,开发了建筑信息模型的空间拓扑关系提取和检索插件,但该插件只适用于Revit软件生成的图形文件的检索.
综上所述,当前缺少能够批量采集建筑图像语义特征的方法.为此,本文借鉴了计算机领域关于图像语义特征采集 (也称语义标注)的方法.它们分为2类: 1)基于图像内容的语义标注.该类型以1999年Mori等[4]提出的图像与语义概念之间建立联系的共生模型(Co-occurrence model)为基础,运用机器学习方法分析图像形状、颜色、纹理、边界等底层视觉特征,发现这些特征和高层概念之间的潜在对应关系,进而实现图像语义标注.随着模式识别、数据挖掘等技术的发展,许多新的方法被提出,包括基于全局特征的图像语义标注[5]、基于区域特征的图像语义标注[6]、基于图学习的图像语义标注[7]、基于图学习的跨媒体相关模型图像语义标注[8]等.建筑图像内容的复杂性导致建筑师都很难从图像中提取出项目名称、项目类型、建筑功能等特征,让计算机自动从图像中提取语义进行标注的难度较大.2)基于图像相关文本的语义标注(简称Web标注技术).该类型是运用数据采集和文本提取技术从图像所在网页的内容中提取出高层概念.相关方法包括基于外部信息源的Web图像语义标注[9]、基于网页关联特征的图像语义标注[10]、结合Web背景知识的图像语义标注[11]、基于增强稀疏性特征选择的网络图像标注[12-13]等.建筑图像的详细信息均蕴含于所在网页的图像名称、图像注释、网页正文等内容中.因此,基于上述研究成果,本文提出了一种应用Web标注技术的建筑图像语义采集方法.
1 概念界定
1.1 建筑图像
图像是一种视觉符号,是对客观对象的相似性、生动性的描述.建筑图像是一种用来记录和交流建筑物信息的媒介.对于建筑师来说,图像表达往往比文字描述更直观,也更易理解.
本文研究的建筑图像特指来源于建筑策划与设计机构网站、建筑案例专业网站、各类百科等网站的建筑图像.这些网站具有相似的特点: 1)同一网站的子网页具有相同的网页结构,便于批量采集; 2)同一网页的多幅图像共同反映了该栋建筑的完整信息.从图像性质看,它们是在建筑策划和建筑设计的过程中形成的,是建筑师与业主、建设者、使用者之间沟通的视觉语言,是建筑空间形态创作的视觉表现[14],见表1.从图像格式看,它们不仅包括JPEG、BMP、PNG等栅格图像,还包括DWG、SKP等矢量图形.

表1 建筑图像类型
1.2 建筑图像语义
Web图像特征分为底层视觉特征和抽象语义特征.底层视觉特征是指图像主题、主体、颜色、纹理及形状等.抽象语义特征是指通过图像包含的对象、场景的含义和目标进行高层推理,得到相关的语义描述[9].建筑图像语义属于后者,它的确定需要同时考虑图像语义采集的难度和图像检索需求,不仅包括图像名称、图像类型、图像主题等图像层面特征,也包括项目名称、项目类型、项目性质、建筑师、设计构思、设计评价等建筑层面特征.其中,设计构思细分为设计问题和应对策略两项,设计评价细分为评价内容和评价等级两项.表2列举了建筑图像的通用语义类型,在实际操作时,可以根据网页内容灵活设置.

表2 建筑图像语义类型
2 方法阐述
应用Web标注技术的建筑图像语义采集是指计算机能够按照预先设定的规则,自动下载网页中的建筑图像,同时采集与这些图像相关的描述文本,并从中提取出作为图像检索依据的建筑语义词的过程.它由“建筑语义词典建立(模块1)”、“建筑图像相关文本采集(模块2)”、“建筑图像语义提取(模块3)”3个模块构成,如图1所示.
模块1负责通过人工添加和在线学习的方式建立建筑语义词典.模块2负责运用数据采集软件,从指定的网页中下载建筑图像以及采集图像名称、图像注释、图像周围文本等图像相关文本.模块3负责运用建筑语义词典和文本抽取技术,从这些文本中提取图像语义词,与图像文件一同存储到建筑图像数据库.
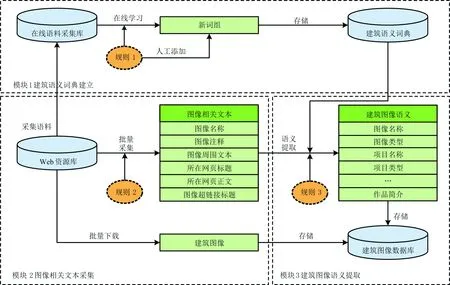
图1 应用Web标注技术的建筑图像语义采集方法的体系结构
2.1 建立建筑语义词典
建筑语义词典是帮助计算机“理解”自然语言的桥梁,是存储建筑术语和建筑语汇的词库.在互联网时代新的建筑词汇层出不穷,需要运用在线学习技术实现词典库的动态更新.为此,本文按照赵静[15]提出的专业领域语义词典构建方法,将百度百科词库和搜狗细胞词库作为在线语料采集库,对其语料进行中文分词、词语重组后,形成了新的语义词.按照职能分工的不同,建筑语义词典分为基础词典、同义词典、对照词典3个部分,其建立规则(规则1)如下.
1) 基础词典包含12类语义,分别为建筑类型、建筑性质、建筑位置、建筑造价、建筑理念、建筑人物、建筑形象、建筑空间、建筑规模、建筑技术、建筑图像及其他.每类语义可以逐级展开,语义词不要求太精细,但应尽量全面,并符合建筑师的语言描述习惯.
2) 基础词典采用层次型分类结构存储,用路径形式“一级类名|二级类名|…”表示.其中,父类包含子类,子类继承父类的属性.例如“建筑类型|公共建筑|博物馆|大庆市博物馆”.
3) 同义词典将含义相同的语义词整合成一组,有效避免了歧义问题,用“主导词:同义词:…”表示.例如“商业办公楼:写字楼”.
4) 对照词典包含由每个词的中文、汉语拼音、英文单词或缩写词组成的词组群,用“中文词、汉语拼音、英文单词、缩写词”表示.例如“中庭,zhongting, atrium,无”.
5) 建筑语义词典可以通过图像语义采集过程不断得到补充和丰富.自动组词规则为:当词典中已存在的类名前是名词或形容词时组成新词.例如“宁波(n)美术馆(n)”合并为“宁波美术馆”,并作为子类自动添加到该类中,结果为“建筑类型|公共建筑|美术馆|宁波美术馆”.

根据上述规则,可以快速建立比较完善的建筑语义词典,该词典将导入相关软件的用户词库中,用于进一步中文分词、语义词提取、同义词替换等操作.
2.2 采集图像相关文本
Shen等[16]认为图像名称、图像注释、图像周围文本、图像所在网页标题与图像语义密切相关.本文发现图像所在网页正文、图像超链接网页标题亦与图像语义相关.因此,将上述6项内容称为建筑图像相关文本,分别记作T1~T6.
图像相关文本采集主要借助数据采集软件. 鉴于软件的智能性,本文选用抓取、处理、分析、挖掘互联网数据的软件—火车采集器.首先,需要根据T1~T6在网页中的分布情况设置文本采集规则,即图像网址采集规则、图像相关文本采集规则、图像文件下载、存储、命名规则,通过编写前后截取、正则提取、XPath提取、JSON提取的表达式来实现.然后, 设置自动采集计划,执行文本采集.采集结果以字符串形式表达,并与采集的建筑图像文件一并存储到建筑图像数据库中.
图像周围文本是除图像名称、注释外最能反映图像主题的,采集难度最大的文本类型.它们往往和图像处在同一个
标签,即文本往往出现在Web图像的兄弟结点、父结点、或父结点的兄弟结点中.因此,本文采用基于DOM树的图像周围文本提取算法[10]来进行采集,其规则(规则2)见表3.
表3 基于DOM树的图像周围文本采集规则[10]
以筑龙网中的扎哈·哈迪德建筑代表作网页为例(如图2所示),按照上述规则,查找点到达建筑图像DIV结点时,发现有两个兄弟结点存在文字信息,将其作为图像周围文本,即“阿利耶夫文化中心”和“这是由扎哈·哈迪德在2007年设计的……”.

图2 扎哈·哈迪德建筑代表作网页截图
Fig.2 Webpages’ sreenshots of Zaha Hadid’s representative architectural works
2.3 提取建筑图像语义
在提取建筑图像语义之前,首先将建筑语义词典导入火车采集器的用户词库.根据表2的语义类型,建筑图像语义提取过程分为图像层面语义提取和建筑层面语义提取.
2.3.1 图像层面语义提取
图像类别是图像检索的关键特征之一,它分为调查记录图、建筑策划图、建筑设计图、建筑分析图、建筑实景图5类.每类细分为若干子类,子类前加上新的限定词,便可产生新的图像类别.它的提取步骤为:1)粗选语义候选词.运行火车采集器的中文分词功能,依次对T1~T3、T6的文本进行分词,去除介词、连词、副词等噪声词,生成语义候选集. 2)精选语义候选词.将语义候选词与用户词库的图像类别语义词进行匹配,将匹配成功的语义候选词提取出来作为图像类别值.
图像名称采用T1作为语义值.若T1不存在则采用项目名称和图像类型的组合来实现.例如阿利耶夫文化中心总体鸟瞰图、苏州博物馆二层平面图等.
图像主题需要运行中文分词功能,提取T3中的关键词,将T3及其关键词作为图像主题值.
2.3.2 建筑层面语义提取
建筑层面语义是描述图像中建筑物的关键特征,通常以项目概况的形式位于网页的开头、结尾或中间某一固定位置,其提取步骤如下.
Step1根据表2的语义类型,在火车采集器中分别设置各类型建筑语义的提取表达式.下列情况需要注意: 1)鉴于网页描述内容的不确定性和自然语言处理的难度,直接将网页正文内容作为设计构思的语义候选词,为后续全文检索提供便利. 2)鉴于自然语言处理的难度,直接将网页评论模块的信息作为评价内容,对评价内容进行情感分析,将获得的定量化数值作为评价等级.
Step2运用火车采集器的用户词库对Step1提取的语义词进行同义词、缩写词替换、中英文互译,获得最终语义词.
根据上述语义提取方法,建筑师能够批量地采集互联网中建筑图像的语义词.将这些语义词与图像文件建立索引后,以二维关系数据表的形式存储到建筑图像数据库中,便完成了建筑图像语义采集的全部过程.
3 案例检验
在库言库建筑网站(http://www.ikuku.cn)聚集了约4 500个全球优秀建筑设计作品,约120 000张高清建筑图像,建筑师批量地采集这些图像语义将对图像检索和深度解析产生重要意义.为验证方法的有效性和可行性,本文以其中的办公建筑图像语义采集为例进行演示,实验环境及软件配置见表4.

表4 实验环境及软件配置表
Step1分析网页结构.该网站的建筑作品页面均具有相似的布局,它分为左、右两部分,左侧从上到下依次为:项目名称、封面图片、作品介绍、建筑图像(平面、立面、剖面、渲染图、分析图、照片等)、用户评论.右侧从上到下依次为:项目位置、建筑师、设计团队、委托单位、建筑功能、建筑规模等特征.
Step2采集相关文本.将建筑语义词典加载到火车采集器的用户词库中;分别设置办公建筑图像网址采集规则、图像下载规则和图像相关文本采集规则.
Step3提取图像语义.运用火车采集器的标签组合功能,对图像相关文本采集规则进行二次编辑,即中文分词、语义匹配、同义词替换、中英文互译.点击执行后,软件将自动下载该网站的办公建筑图像,并提取其语义词.图3为西安广播电视中心总平面图的语义提取过程.
Step4存储图像数据.在火车采集器中设置图像语义发布模块,将其存储到MySQL数据库中.为降低建筑师操作的难度,本文采用Navicat Premium软件对建筑图像数据库进行可视化管理.图4为北京开心麻花办公总部照片的可视化管理界面.
由上述演示可知,与建筑师手动提取建筑图像的语义特征相比,本方法具有显著的优势,能够自动地、批量地采集互联网中的建筑图像语义,并不断检测最新发布的建筑图像,实现数据库的自动更新.
Fig.3 The semantic acquisition interface of Xi’ an Television & Broadcasting Center’s site plan

图4 建筑图像数据库可视化管理界面
Fig.4 A visual management interface of databases related to architectural images
4 结 论
1)为解决互联网环境下大规模建筑图像的语义特征难以提取和建筑师检索效率较低的问题,提出了应用Web标注技术的建筑图像语义采集方法.通过“建筑语义词典建立”、“建筑图像相关文本采集”、“建筑图像语义提取”3个模块,建筑师能够自动、批量地采集互联网中的建筑图像语义.
2)案例检验表明,该方法是可行的,具有较强的操作性,能有效地克服建筑图像查询效率低的问题.
3)将计算机领域的数据采集、文本抽取技术引入建筑学领域,能极大提升建筑师运用互联网图像的能力,进而加快计算机辅助建筑策划与设计的进程.
4)目前,该方法还存在一些不足,如只能针对具有相似网页结构的网站来采集,采集结果容易受到网页内容的限制而出现缺失值等,需要后续研究来完善.
[1] 涂喆夫.建筑图像的底层拓扑特征提取的算法研究[D]. 合肥: 中国科学技术大学, 2014.
TU Zhefu. Research on underlying topological feature extraction algorithm of architecture images[D]. Hefei: University of Science and Technology of China, 2014.
[2] 魏力恺.基于CBR和HTML5的建筑空间检索与生成研究[D].天津:天津大学, 2013.
WEI Likai. Architectural spatial retrieval and generating based on CBR and HTML5[D].Tianjin: Tianjin University, 2013.
[3] 张颉,李昌华,李智杰.基于拓扑特征的建筑信息模型检索方法[J].计算机应用研究, 2016, 33(3): 916-921. DOI: 10.3969/j.issn.1001-3695.2016.03.063.
ZHANG Jie, LI Changhua, LI Zhijie. Building information model retrieval based on topological features[J]. Application Research of Computers, 2016, 33(3): 916-921. DOI: 10.3969/j.issn.1001-3695.2016.03.063.
[4] MORI Y, TAKAHASHI H. Image-to-word transformation based on dividing and vector quantizing images with words[C]//Proceeding of the 7th ACM International Conference on Multimedia. Florida in the United States: ACM Press, 1999: 405-409.
[5] YAVLINSKY A, SCHOFIELD E, RUGER S. Automated image annotation using global features and robust nonparametric density estimation[C]// Proceedings of the 4th International Conference on Image and Video Retrieval. Berlin, Heidelberg: Springer-Verlag, 2005: 507-517. DOI: 10.1007/11526346_54.
[6] 邱泽宇,方全,桑基韬,等.基于区域上下文感知的图像标注[J].计算机学报, 2014, 37(6): 1390-1397. DOI:10.3724/SP.J.1016.2014.01390.
QIU Zeyu, FANG Quan, SANG Jitao, et al. Regional context-aware image annotation[J]. Chinese Journal of Computers, 2014, 37(6): 1390-1397. DOI:10.3724/SP.J.1016.2014.01390.
[7] 卢汉清,刘静.基于图学习的自动图像标注[J].计算机学报,2008, 31(9): 1629-1639. DOI: 10.3321/j.issn:0254-4164.2008.09.016.
LU Hanqing, LIU Jing. Image annotation based on graph learning[J]. Chinese Journal of Computers, 2008, 31(9): 1629-1639. DOI: 10.3321/j.issn:0254-4164.2008.09.016.
[8] 李玲,宋莹玮,杨秀华,等.应用图学习算法的跨媒体相关模型图像语义标注[J].光学精密工程, 2016, 24(1): 229-235. DOI:10.3788/OPE.20162401.0229.
LI Ling, SONG Yingwei, YANG Xiuhua, et al. Image semantic annotation of CMRM based on graph learning[J].Optics and Precision Engineering, 2016, 24(1): 229-235. DOI:10.3788/OPE.20162401.0229.
[9] 张华,张淼,孟祥增.基于外部信息源的WWW图像语义提取研究[J].计算机科学,2006, 33(4): 211-214. DOI: 10.3969/j.issn.1002-137X.2006.04.060.
ZHANG Hua, ZHANG Miao, MENG Xiangzeng. Methods of extracting WWW image semantics based on external information[J].Computer Science, 2006, 33(4): 211-214. DOI: 10.3969/j.issn.1002-137X.2006.04.060.
[10]陈涛.基于网页关联特征的互联网图像自动标注系统[D].杭州:浙江大学,2007.
CHEN Tao. Multi-feature based web image annotation system[D].Hangzhou: Zhejiang University, 2007.
[11]陈世亮,郭向东,董洋溢.结合Web背景知识的图像语义标注[J].计算机工程与应用,2013,49(4):166-169.
CHEN Shiliang, GUO Xiangdong, DONG Yangyi. Semantic annotation method for images by Web background knowledge[J]. Computer Engineering and Applications, 2013,49(4): 166-169.
[12]石翠萍,张钧萍,张晔.一种新的基于混合变换的图像稀疏表示[J].哈尔滨工业大学学报, 2014,46(9):36-42.DOI:10.11918/j.issn.0367-6234.2014.09.007.
SHI Cuiping, ZHANG Junping, ZHANG Ye. A novel image sparse representation based on the hybrid transform[J].Journal of Harbin Institute of Technology,2014,46(9):36-42.DOI:10.11918/j.issn.0367-6234.2014.09.007.
[13]史彩娟,阮秋琦.基于增强稀疏性特征选择的网络图像标注[J].软件学报,2015,26(7):1800-1811. DOI: 10.13328/j.cnki.jos.004687.
SHI Caijuan, RUAN Qiuqi. Feature selection with enhanced sparsity for web image annotation[J]. Journal of Software,2015,26(7):1800-1811. DOI: 10.13328/j.cnki.jos.004687.
[14]王一涵, 刘松茯. 当代西方建筑空间形态创作的视像转译研究[J]. 建筑学报,2016,(S1):65-70.
WANG Yihan, LIU Songfu. Research of the visual translation spatial from creation in the contemporary western[J]. Architectural Journal, 2016,(S1):65-70.
[15]赵静.大规模汉语语义词典构建[D].哈尔滨:哈尔滨工业大学,2011.
ZHAO Jing. Building a large scale Chinese semantic dictionary[D]. Harbin: Harbin Institute of Technology, 2011.
[16]SHEN Hengtao, OOI B C, TAN K L. Giving meanings to WWW images[C]//Proceeding of the 8th ACM International Conference on Multimedia. New York, NY: ACM, 2000: 39-47. DOI: 10.1145/354384.376098.
AsemanticacquisitionmethodofarchitecturalimagesbasedonWebannotationtechnology
GUO Qiang1,2,3, ZOU Guangtian1,2,3, LIAN Fei1,2,3, ZHANG Si1,2,3
(1.School of Architecture, Harbin Institute of Technology, Harbin 150006, China; 2.Architectural Planning and Design Institute, Harbin Institute of Technology, Harbin 150006, China;3.Heilongjiang Cold Region Architectural Science Key Laboratory (Harbin Institute of Technology), Harbin 150006, China)
To solve the problem that architects were always having problems in finding suitable architectural images effectively from websites, a semantic acquisition method of architectural images based on web annotation technology was proposed. First, the concepts and types of architectural images and semantics were defined. Second, the framework and operational processes of this method were illustrated. Finally, the feasibility and validity of this method were verified by famous building websites as examples. Regarding to operational process, there were three steps: building the architectural semantic dictionary by adding artificially and learning online; collecting 6 items of image-related texts (image’s name, image’s annotation, information around images, webpage’s title, webpage’s body, and the title of image’s hyperlink) from websites where the images were founded; collecting semantics of images according to certain rules, relating them to image files and keeping them to the database of architectural images. This study indicates that the proposed method is feasible and easy to be operated. Architectural images can be automatically downloaded in batches and more than 30 items of architectural semantic characteristics will be collected, such as names, categories, themes of architectural images, as well as names and types of projects. As a result, the semantic acquisition method of architectural images will effectively overcome the problem that architectural images are hard to be searched and it will help architects to improve their abilities of innovation by using images from websites.
Web annotation technology; architectural images; architectural images’ semantics; the architectural semantic dictionary; images’ semantics acquisition
10.11918/j.issn.0367-6234.201601001
TU18
A
0367-6234(2017)10-0158-06
2016-01-01
国家自然科学基金(51178132)
郭 强(1985—),男,博士研究生;
邹广天(1960—),男,教授,博士生导师
邹广天,zougt@hit.edu.cn
(编辑张 红)

