
使用最小串行策略的均质脉冲神经膜系统的计算通用性
2017-11-07 12:09:05李立江克勤
中山大学学报(自然科学版)(中英文) 2017年5期
李立,江克勤
(1. 安庆广播电视大学, 安徽 安庆 246003;2. 安庆师范大学计算机与信息学院,安徽 安庆 246133)
使用最小串行策略的均质脉冲神经膜系统的计算通用性
李立1,江克勤2
(1. 安庆广播电视大学, 安徽 安庆 246003;2. 安庆师范大学计算机与信息学院,安徽 安庆 246133)
脉冲神经膜系统是根据神经网络中神经元相互之间依靠突触来处理脉冲的生物现象而提出的,具有良好的计算性能及潜在的应用价值。使用最小串行策略的脉冲神经膜系统是一类特殊的脉冲神经膜计算模型,为了验证其在均质情况下的通用性,引入了带权值的突触,构建了均质的基于最小脉冲数目的串行脉冲神经膜系统。使用自动机理论和形式语言,通过模拟注册机证明了作为数的产生装置和接受装置,使用最小串行策略的均质脉冲神经膜系统都是通用的。
膜计算;脉冲神经膜系统;串行性;均质性;注册机
膜计算模型是由欧洲科学院院士、罗马尼亚科学院院士Pǎun于1998年在芬兰图尔库计算机中心的研究报告中首次提出,论文于2000年发表[1],由于膜计算具有良好的计算性能和潜在的应用价值,该方向已成为计算机科学快速发展的新兴领域之一。2006年Ionescu等[2]提出的脉冲神经膜系统是一种特殊的类神经膜计算模型。脉冲神经膜系统中基本的计算单元是神经元,神经元之间通过突触传递信号,其中每个神经元中含有若干个激发规则和遗忘规则。
脉冲神经膜系统提出后,受到国内外学者的广泛关注,基于各种不同的生物动机,提出了一些特殊的脉冲神经膜系统[3-7],Ibarra等[8]在2009年提出的基于脉冲数目的串行脉冲神经膜系统就是其中的一种。基于最小(或最大)脉冲数目的串行脉冲神经膜系统的串行性是由最小(或最大)脉冲数目引起的,同一时刻只有一个拥有最小(或最大)脉冲数目的活跃神经元(即满足激发规则的神经元)可以被激发。Pǎun等[9]研究了基于最大脉冲数目的串行脉冲神经膜系统的小通用性。江克勤等研究了基于最小脉冲数目的小通用串行脉冲神经膜系统[10-11]。本文研究的是均质情况下基于最小脉冲数目的串行脉冲神经膜系统的通用性。在系统中引入均质性和带权值的突触,构造了加法模块、减法模块、输入模块和输出模块,通过模拟注册机来证明使用最小串行策略的均质脉冲神经膜系统在产生模式和接受模式下都是通用的。
1 相关定义及概念
1.1 基于最小脉冲数目的串行脉冲神经膜系统
一个度为m(m≥1)的脉冲神经膜系统形式化定义[2]如下:
∏=(O,σ1,σ2,…,σm,syn,in,out)
其中:
(i)O={a}表示脉冲的集合;
(ii)σ1,σ2,…,σm代表m个神经元,每个神经元的表示形式为σi=(ni,Ri)(1≤i≤m),其中ni≥0表示神经元σi中包含的初始脉冲数;Ri是由下列两种形式的规则构成的有限集合:
①E/ac→a;d(c≥1,d≥0),E为a的正则表达式,d称为时延,即神经元从被激发到发送脉冲所间隔的时间。
②as→λ(s≥1),对Ri中的任意规则E/ac→a;d,都满足as∉L(E);
①中表示的是激发规则,如果神经元σi包含k个脉冲,满足ak∈L(E)(k≥c),则规则E/ac→a;d可以被激发,神经元σi将消耗c个脉冲,并在d个单位时间后向与它有突触连接的每个神经元送去一个脉冲。当d=0时,脉冲被立即送出;当d≥1时,若在第t步利用规则激发,则在第t、t+1、…、t+d-1步神经元σi都是封闭的,不能接收和发送任何脉冲,到第t+d步,脉冲被送出,神经元恢复到开放状态。②中的规则称为遗忘规则,如果神经元σi包含s个脉冲,则Ri中的遗忘规则as→λ将被使用,消耗其中的s个脉冲,而且没有新的脉冲产生。若规则E/ac→a;d满足E=ac,则可以写成ac→a;d若同时d=0,则可以直接简写为ac→a。
(iii) syn⊆{1,2,…,m}×{1,2,…,m}表示神经元之间的突触连接,对每个1≤i≤m,都有(i,i)∉syn;
(iv) in,out∈{1,2,…,m},其中in代表输入神经元,out代表输出神经元。
在标准脉冲神经膜系统中,所有神经元是并行工作的,在每一个时间单元,所有满足条件的神经元都必须使用对应规则激发。基于最小脉冲数目的串行脉冲神经膜系统的工作模式不同于标准的脉冲神经膜系统,假设用一个全局时钟标记整个系统的运行时间,在计算的每一步,当有多个活跃神经元时,只有其中拥有最小脉冲数目的活跃神经元可以使用对应规则激发。如果同一时刻拥有最小脉冲数目的活跃神经元不止一个,则非确定性地选择其中之一开始激发。
1.2 均质性
均质性是许多计算模型的重要特性之一,如在细胞自动机中,每个细胞取有限的离散状态,遵循同样的作用规则,大量细胞通过简单的相互作用而构成动态系统的演化[12]。2009年曾湘祥等[13]将均质性引入标准脉冲神经膜系统,并证明了其通用性[13-14]。在均质脉冲神经膜系统中,所有神经元有相同的规则集合,即对于系统Π中的任意神经元σi=(ni,Ri)(1≤i≤m),有R1=R2=…=Rm,这些神经元以一种统一的方式工作。均质脉冲神经膜系统分为突触上带权值和不带权值两类,带权的突触(i,j,r)∈syn表示如果神经元σi向神经元σj发出1个脉冲,则神经元σj会接收到r个脉冲。本文中,我们是在基于最小脉冲数目的串行脉冲神经膜系统中引入均质性和带权的突触。在下文第2节的证明中用图形表示带权均质脉冲神经膜系统的各模块,模块中的神经元用椭圆表示,用带数字的箭头表示突触,若某个突触的权值是1,则数字不用标出。
1.3 注册机
注册机M=(m,H,l0,lh,I)[15],其中m是注册器的数目,H是指令的标签集合,I是指令集合,两者一一对应,l0是起始指令,lh是终止指令。注册机有三种形式的指令:
1) 加法指令li:(ADD(r),lj,lk)。先将存储在注册器r中的数值加1,再随机选择指令lj或指令lk来执行。
2) 减法指令li:(SUB(r),lj,lk)。如果注册器r中存储的数值不为0,则先将该数减1,再执行指令lj;如果注册器r中存储的数是0,则执行指令lk。
3) 终止指令lh:HALT。注册机M能在产生和接受两种模式下运行。在产生模式下,计算初始状态时,各注册器都为空。M首先执行的是l0,然后按照相应的指令进行操作,每一步执行一条指令。当注册机执行到lh时,表示M的计算停止,则存放在注册器1中的数值即为M所产生的数。在接受模式下,计算初始状态时,先把一个自然数n存储在某个注册器中,其余的都是空注册器。M首先执行l0,然后按照相应的指令进行操作,如果计算能够终止于lh,则称M可以接受数n。注册机在产生模式和接受模式下都具有计算完备性。
本文将在基于最小脉冲数目的串行脉冲神经膜系统中引入均质性和带权值的突触,通过模拟注册机来证明这类所有神经元中规则相同且含带权突触的系统在产生模式和接受模式下的通用性。
2 基于最小脉冲数目的均质串行脉冲神经膜系统的计算通用性
本节研究基于最小脉冲数目的均质串行脉冲神经膜系统的计算能力,证明该系统是通用的产生装置和接受装置。用NαHSNP(weightk)表示使用最小串行策略的均质脉冲神经膜系统产生或接受的数的集合簇,其中α∈{gen,acc}(gen表示系统工作在产生模式,acc表示系统工作在接受模式),weightk表示系统中的突触的权不超过k。当系统工作在产生模式时,系统可以产生形如0b104n-21的脉冲串;当系统工作在接受模式时,要计算(接受)的数n编码为t2-t1-1的形式,其中t1,t2分别是输入神经元输入前两个脉冲的时刻。
2.1 产生模式下基于最小脉冲数目的均质串行脉冲神经膜系统
定理1NgenHSNP(weight17)=NRE。
证明由Turing-Church猜想可知:NgenHSNP(weight17)⊆NRE,因此只需要证明NRE⊆NgenHSNP(weight17)即可。
构建一个基于最小脉冲数目的均质串行脉冲神经膜系统Π来模拟运行M=(m,H,l0,lh,I),假设在停机格局时,注册机M中除了注册器1之外,其余注册器都为空,并且在计算过程中,注册器1中的内容只增不减。在系统Π中,所有神经元具有相同的规则集,如图1所示。系统Π由加法、减法和输出三个模块组成,分别如图2、图3和图4所示。

图1 系统Π中的神经元Fig.1 The neurons of system Π
对M中的各注册器r,系统Π都有一个神经元σr与之对应,其中的脉冲数对应r中存储的数。如果r中存储的数为n≥0,则神经元σr中包含5n+5个脉冲,即当神经元σr中的脉冲数为5时,表示此时r为空。对M中的每个指令li,系统Π都有一个神经元σli与之对应。一旦神经元σli收到一个脉冲后,达到激发条件,就开始模拟M中的指令li:(op(r),lj,lk):通过op(r)(对注册器r进行加或减操作),最后送出一个脉冲到神经元σlj或σlk。当激发神经元σlh后,系统Π就完成了模拟M的工作,此时两次激发神经元σout的时间间隔就对应为存储在注册器1中所产生的数。
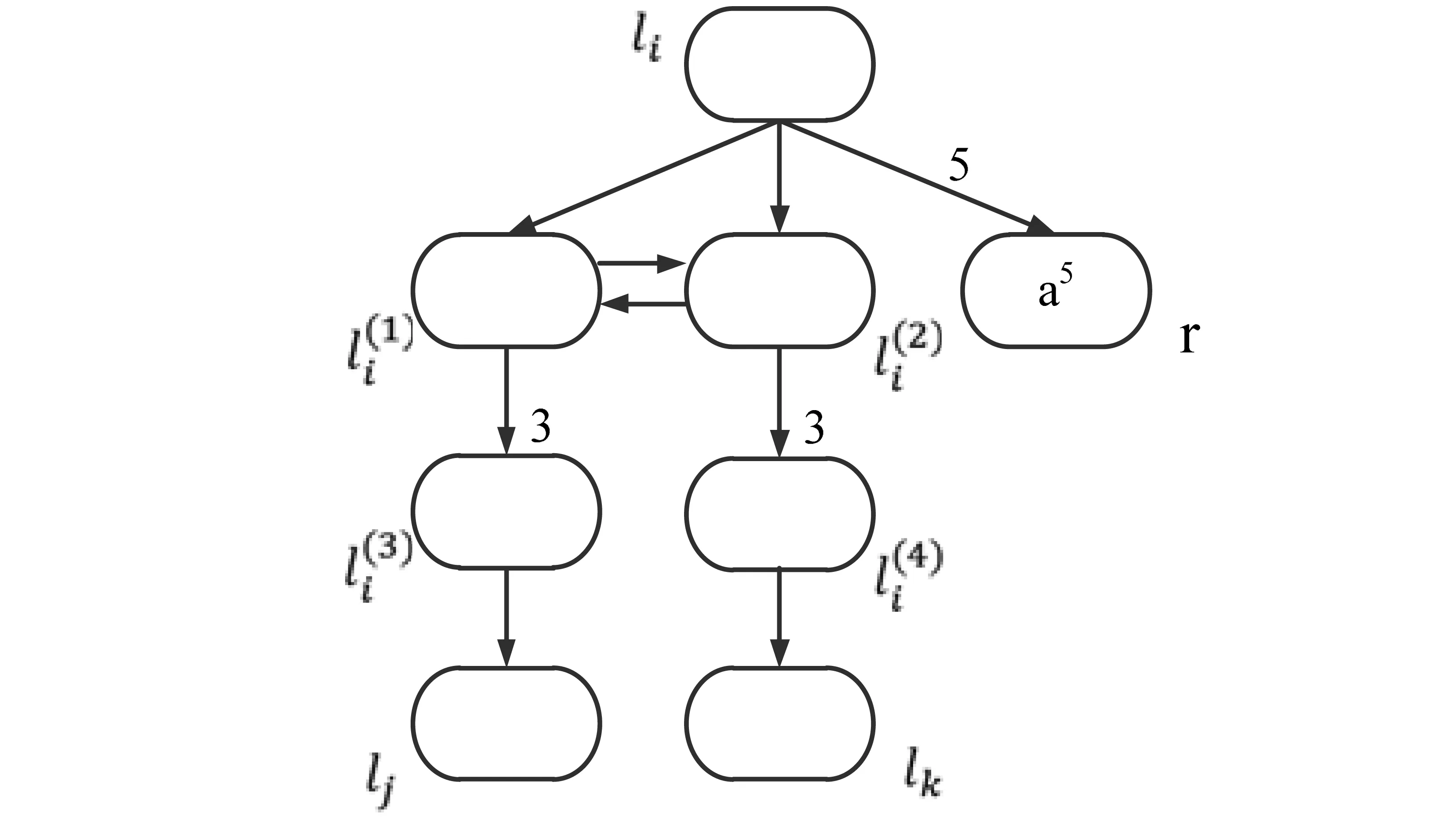
图2 系统Π的加法模块Fig.2 The ADD module of system Π

因此,从神经元σli的激发开始,系统向注册器r的神经元σr送入5个脉冲,然后非确定性地选择激发神经元σlj或σlk,系统Π正确地模拟了加法指令li:(ADD(r),lj,lk)。

图3 系统Π的减法模块Fig.3 The SUB module of system Π
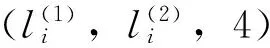
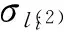

因此,从神经元σli的激发开始,如果注册器r中存储的数大于0,则减去1,系统Π结束于神经元σlj;如果注册器r中存储的数等于0,系统结束于神经元σlk。系统Π正确地模拟了减法指令li:(SUB(r),lj,lk)。
对某个注册器r来说,可能会存在多个减法指令和加法指令作用其上,加法模块和减法模块之间可能的相互影响分析如下:
在如图2所示的加法模块中,神经元σr每次都是收到5个脉冲,不会激发其中的任何规则,因此在加法模块之间以及加法模块和减法模块之间都没有相互影响。
2.1.3 输出模块 系统Π中使用最小串行策略的输出模块如上所示,当系统Π执行到了终止指令lh,此时神经元σ1中的脉冲数为5n+5(即注册器1中存储的数为n)。当神经元σlh收到一个脉冲后,开始激发,向神经元σout和σ1各发送一个脉冲。下一步,由于突触(lh,1,8)的权为8,神经元σout和σ1分别拥有1个和5n+13个脉冲,都可以激发,根据最小串行的使用策略,神经元σout优先激发,使用规则a→a,向环境送出第一个脉冲,假设此时是第t步。第t+1步神经元σ1开始激发,使用规则a8(a5)+/a5→a,向神经元σout和σd1各发送一个脉冲。由于突触(1,out,7)和突触(1,d1,17)的权分别为7和17,第t+2步神经元σout和σ1分别拥有7个和17个脉冲,神经元σ1拥有5n+8个脉冲,神经元σ1和σd1都可以激发。根据神经元σ1中脉冲数的不同,分析如下:

图4 系统Π的输出模块Fig.4 The OUTPUT module of system Π
(i) 若n=1,神经元σ1中的脉冲数是13个,将优先激发,使用规则a8(a5)+/a5→a,剩余8个脉冲,不再激发,同时向神经元σout和σd1各发送一个脉冲。由于突触(1,out,7)和突触(1,d1,17)的权分别为7和17,第t+3步神经元σout和σd1分别拥有14个和34个脉冲,神经元σout是系统中当前唯一的活跃神经元,使用规则a14→a,向环境送出第二个脉冲,计算停止,此时产生的脉冲串为0b1021。
(ii) 若n≥2,神经元σd1优先激发,使用规则a17→a,向神经元σout和σd2各发送一个脉冲。由于突触(d1,out,3)的权为3,第t+3步,神经元σout和σd2各拥有10个和1个脉冲,神经元σd2可以激发,使用规则a→a,向神经元σout发送一个脉冲,由于突触(d2,out,2)的权为2,第t+4步,神经元σout拥有12个脉冲,使用遗忘规则a12→λ,移去收到的12个脉冲。第t+5步,神经元σ1激发,接着神经元σd1、神经元σd2、神经元σout和神经元σ1依次激发,不断重复,直到第t+4n-2步,神经元σ1、σd1和σout中的脉冲数分别为13、17和7,神经元σ1和σd1都可以激发,根据最小串行策略,神经元σ1再次激发,使用规则a8(a5)+/a5→a,剩余8个脉冲,神经元σ1不再激发,同时向神经元σout和σd1各发送一个脉冲。由于突触突触(1,out,7)和突触(1,d1,17)的权分别为7和17,第t+4n-1步,神经元σout和σd1分别拥有14个和34个脉冲,此时神经元σout是系统中当前唯一的活跃神经元,使用规则a14→a,向环境送出第二个脉冲,计算停止,此时产生的脉冲串为0b104n-21。
综合以上对加法、减法和输出3个模块的描述,我们得到在使用最小串行策略下,系统Π正确地模拟了注册机M,并且系统各模块中突触的权最大为17,因此,NRE⊆NgenHSNP(weight17)成立,定理1得证。
2.2 接受模式下基于最小脉冲数目的均质串行脉冲神经膜系统
定理2NaccHSNP(weight5)=NRE。
证明由Turing-Church猜想可知:NaccHSNP(weight5)⊆NRE,因此只需要证明NRE⊆NaccHSNP(weight5)即可。在接受模式下,构造一个基于最小脉冲数目的带权均质串行脉冲神经膜系统Π′来模拟注册机M=(m,H,l0,lh,I),系统Π′中各模块所含神经元的规则如图1组成。注册器1中存储一个数,其余注册器都是空的,如果计算最终停止,则该数就被接受。系统Π′由输入模块、加法模块和减法模块组成,其中加法模块和减法模块与定理1中的图2和图3相同,输入模块如图5所示。系统Π′要计算(接受)的数n编码为t2-t1-1的形式,其中t1,t2分别是输入神经元输入前两个脉冲的时刻。

图5 系统Π′的输入模块Fig.5 The INPUT module of system Π′
系统Π′中使用最小串行策略的输入模块如图5所示,初始时神经元σd1,σd2,σd3和σ1分别含有7个、8个、8个和5个脉冲。假设第t步输入神经元σin从环境收到第一个脉冲,利用规则a→a开始激发,向神经元σd1和σd3各发送一个脉冲。由于突触(in,d3,5)的权为5,第t+1步神经元σd1和σd3分别拥有8个和13个脉冲,只有神经元可以σd3激发,利用规则a8(a5)+/a5→a,向神经元σd2和σ1各发送1个脉冲,由于突触(d3,d2,5)和(d3,1,5)的权都为5,此步神经元σd2和σ1都收到5个脉冲。第t+2步神经元σd2拥有13个脉冲,可以激发,利用规则a8(a5)+/a5→a,向神经元σd3和σ1各发送1个脉冲,由于突触(d2,d3,5)和(d2,1,5)的权都为5,此步神经元σd3和σ1都收到5个脉冲。第t+3步神经元σd3拥有13个脉冲,是系统中唯一的活跃神经元,恢复到第t+1步时的状态,之后,神经元σd2和σd3将交替激发,神经元σ1每步均收到5个脉冲。
若第t+n+1(n≥1)步,神经元σin从环境收到第二个脉冲,此时神经元σin、σd1和σ1的脉冲数分别为1、8和5n+5,神经元σd2和σd3的脉冲数是13和8(当n为奇数时)或者8和13(当n为偶数时),根据最小串行的使用策略,神经元σin优先激发,利用规则a→a开始激发,向神经元σd1和σd3各发送一个脉冲。第t+n+2步神经元σd1和σd3的脉冲数分别为9和13(或18),神经元σd1激发,利用规则a9/a2→a,向神经元σl0、σd2和σd3各发送1个脉冲。第t+n+3步,由于突触(d1,d2,2)和(d1,d3,2)的权都为2,此步神经元σl0脉冲数为1,σd2和σd3分别拥有脉冲数为15和15,或者是10和20。神经元σl0是系统中唯一的活跃神经元,利用规则a→a开始激发,系统Π′开始模拟注册机M中的起始指令σl0。系统从环境收到前两个脉冲的时刻分别为第t步和第t+n+1步,表明系统要接收的数为(t+n+1)-t-1=n。 综合以上对加法、减法和输入三个模块的描述,我们得到在使用最小串行策略下,系统Π′正确地模拟了注册机M,并且系统各模块中突触的权最大为5,因此,NRE⊆NaccHSNP(weight5)成立,定理2得证。
3 结 论
本文在基于最小脉冲数目的串行脉冲神经膜系统中引入均质性和带权值的突触,证明了这类所有神经元中规则相同且含带权突触的系统在产生模式和接受模式下都是通用的。本文解决了文献[16]提出的均质脉冲神经膜系统在最小串行策略下是否具有通用性的问题。
对于使用最小串行策略的脉冲神经膜系统,还有许多问题值得做进一步的探究,比如:将该系统与数据挖掘中的聚类算法相结合[17-19],构建新的模型;利用该系统来有效解决计算困难问题;设计应用型的均质脉冲神经膜系统等。这些都是基于最小脉冲数目的串行脉冲神经膜系统以后的研究方向。
[2] IONESCU M, PUN G, YOKOMORI T. Spiking neural P systems [J]. Fundamenta Informaticae, 2006, 71(2/3): 279-308.
[3] 潘林强,张兴义,曾湘祥,等. 脉冲神经膜计算系统的研究进展及展望[J]. 计算机学报, 2008, 31(12): 2090-2096.
PAN L Q, ZHANG X Y, ZENG X X, et al. Research advances and prospect of spiking neural P systems [J]. Chinese Journal of Computers, 2008, 31(12): 2090-2096.
[4] IONESCU M, PUN G,YOKOMORI T. Spiking neural P systems with an exhaustive use of rules [J]. International Journal of Unconventional Computing, 2007, 3(2): 135-154.
[5] PAN L Q, HOOGEBOOM H J. Spiking neural P systems with astrocytes [J]. Neural Computation, 2012, 24(3): 805-825.
[6] SONG T, PAN L Q, PUN G. Asynchronous spiking neural P systems with local synchronization [J]. Information Sciences, 2013, 21(9): 197-207.
[7] SONG T, PAN L Q, PUN G. Spiking neural P systems with rules on synapses [J]. Theoretical Computer Science, 2014, 529(1): 82-95.
[8] IBARRA O H, PUN A, RODRíGUEZ-PATN A. Sequential SNP systems based on min/max spike number [J]. Theoretical Computer Science, 2009, 410(30): 2982-2991.
[10] JIANG K Q, SONG T, PAN L Q. Universality of sequential spiking neural P systems based on minimum spike number [J]. Theoretical Computer Science, 2013, 499(12): 88-97.
[11] JIANG K Q, HUANG Y F, XU J B, et al. Small universal sequential spiking neural P systems based on minimum spike number [J]. Romanian Journal of Information, 2014, 17(1): 5-18.
[12] WOLFRAM S. Cellular automata as models of complexity [J]. Nature, 1984, 311(4): 419-424.
[13] ZENG X X, ZHANG X Y, PAN L Q. Homogeneous spiking neural P systems [J]. Fundamenta Informaticae, 2009, 97(1): 275-294.
[14] 彭献武,樊晓平,刘建勋,等. 通用的不带延迟的同质脉冲神经膜系统[J]. 计算机工程与科学, 2013, 35(3): 1-7.
PENG X W, FANG X P, LIU J X, et al. Universal homogeneous spiking neural P systems without delays [J]. Computer Engineering & Science, 2013, 35(3): 1-7.
[15] KOREC I. Small universal register machines [J].Theoretical Computer Science, 1996, 168(2):267-301.
[16] JIANG K Q, SONG T, PAN L Q. Homogeneous spiking neural P systems working in sequential mode induced by maximum spike number [J]. International Journal of Computer Mathematics, 2013, 90(4): 831-844.
[17] 杨发权,李赞,罗中良. 基于聚类与神经网络的无线信号联合调制识别新方法[J]. 中山大学学报(自然科学版), 2015, 54(2):24-29.
YANG F Q, LI Z, LUO Z L. A new specific combination method of wireless communication modulation recognition based on clustering and neural network [J]. Acta Scientiarum Naturalium Universitatis Sunyatseni, 2015, 54(2):24-29.
[18] 黄敏,李尔达,袁媛,等. 基于路网拓扑的聚类分析算法研究与实现[J]. 中山大学学报(自然科学版), 2015, 54(6):99-103.
HUANG M, LI E D, YUAN Y, et al. Research and implementation of clustering analysis algorithm based on road network topology [J]. Acta Scientiarum Naturalium Universitatis Sunyatseni, 2015, 54(6):99-103.
[19] 朱俊勇,逯峰. 基于稀疏子空间聚类的跨域人脸迁移学习方法[J]. 中山大学学报(自然科学版), 2016, 55(5):1-7.
ZHU J Y, LU F. Cross-domain face transfer learning based on sparse subspace clustering [J]. Acta Scientiarum Naturalium Universitatis Sunyatseni, 2016, 55(5):1-7.
ComputationaluniversalityofhomogeneousspikingneuralPsystemsworkinginsequentialmodeinducedbyminimumspikenumber
LILi1,JIANGKeqin2
(1.Anqing Radio and Television University, Anqing 246003, China;2.School of Computer and Information, Anqing Normal University, Anqing 246133, China)
Spiking neural P system is proposed based on the biological phenomenon that the neurons in the neural network are processed by synapses. It has good performance and potential application value. Spiking neural P system working in sequential mode induced by minimum spike number is a special kind of spiking neural computational models. In order to verify the universality of the homogeneous system, weighted synapses are introduced, and the homogeneous spiking neural P systems working in sequential mode induced by minimum spike number are constructed. It is proved that such systems are universal as both generative and acceptive devices by using automata theory, formal language and register machines.
membrane computing; spiking neural P system; sequentiality; homogeneity;register machine
TP301
A
0529-6579(2017)05-0034-07
10.13471/j.cnki.acta.snus.2017.05.005
2016-12-16
国家自然科学基金(61033003);安徽省自然科学基金(1408085MF131);安徽高校自然科学研究重点项目(KJ2017A942)
李立(1980年生),女;研究方向膜计算和数据挖掘;E-mail:lily@aqtvu.cn
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
中国设备工程(2020年16期)2020-08-28 09:04:16
科学技术创新(2020年20期)2020-08-11 04:10:38
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
通信电源技术(2018年8期)2018-10-15 07:02:20
数学物理学报(2016年5期)2016-08-24 07:38:38
油气地质与采收率(2014年6期)2014-12-16 17:45:18
机电信息(2014年27期)2014-02-27 15:53:56
设备管理与维修(2013年4期)2013-05-03 10:44:02
