
面向监理工程的文本分类技术研究
2017-11-04 03:45杨春玉
重庆理工大学学报(自然科学) 2017年10期
陈 庄,杨春玉
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
面向监理工程的文本分类技术研究
陈 庄,杨春玉
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
针对监理工程中文本文档在管理过程中存在的一些困难,提出一种适用于监理工程的文本分类方法,旨在提高管理效率,简化工作方式。该方法在进行中文分词处理时,使用通用词典与手动构造的监理工程专业词典相结合的方式。对于特征提取,在使用TFIDF的基础上,结合一定的规则来调整特征权重,并采用朴素贝叶斯分类算法来构造分类器。实验结果表明:该方法在对监理通知单分类问题上能满足实质性的应用需求。
监理工程;问题分类;TFIDF;特征二次加权;朴素贝叶斯
随着监理工程行业信息化程度的提高,监理工程行业相关的文本大量积累。针对该情况,如何对杂乱无章的文本进行分类以便快速查找和管理是一个具有实际意义的研究课题。相对于传统的企业,监理公司的数据分析对项目的顺利进行有着极其重要的作用。监理单位的数据分析工作是对包括监理公司的内部管理活动及日常监理资料、公司与外部主体交往的记录内容的内、外两大类数据综合起来进行分析[2]。为进一步开展分析工作,对监理工程文本资料采用文本挖掘中的相关技术进行处理。本文主要采用文本分类技术对监理通知单进行分类,对监理问题按照质量、进度、施工、其他问题进行分类。如果采用传统人工分类方法进行分类工作,不仅耗费大量的时间与人力,而且效率低,引入自动分类机制将大大提升工作效率。
监理工程的主要工作是“三控、两管、一协调”,其中质量控制是人们首要的关注重点,而质量控制中最有价值的文档就是监理通知单。对监理通知单出现问题的原因进行分类统计就可以了解整个工程中出现最多的问题类别,有助于对该类问题加强管理。同时,分类统计结果可以反映施工单位的企业素质和管理水平,对今后的招投标工作和公司经营活动有一定的指导作用,对推动监理信息化进程,以及提升公司处理大量非结构化数据的能力具有一定的实际意义。本文提出了一种面向监理工程的文本分类技术,改善了质量控制问题分类的效果。
1 监理通知单文本分类
1.1 分类流程
文本分类是文本挖掘中的重要子领域,它将文本文档分配到一个或多个预定义的类或类别中[9]。文本分类过程主要分为2个阶段:训练和测试,具体主要包括中文分词、去除停用词、特征选择、构造特征向量空间模型、模型训练与评价。其中,特征选择是分类过程中最为关键和重要的一步,它的好坏直接影响分类效果。分类过程如图1所示。
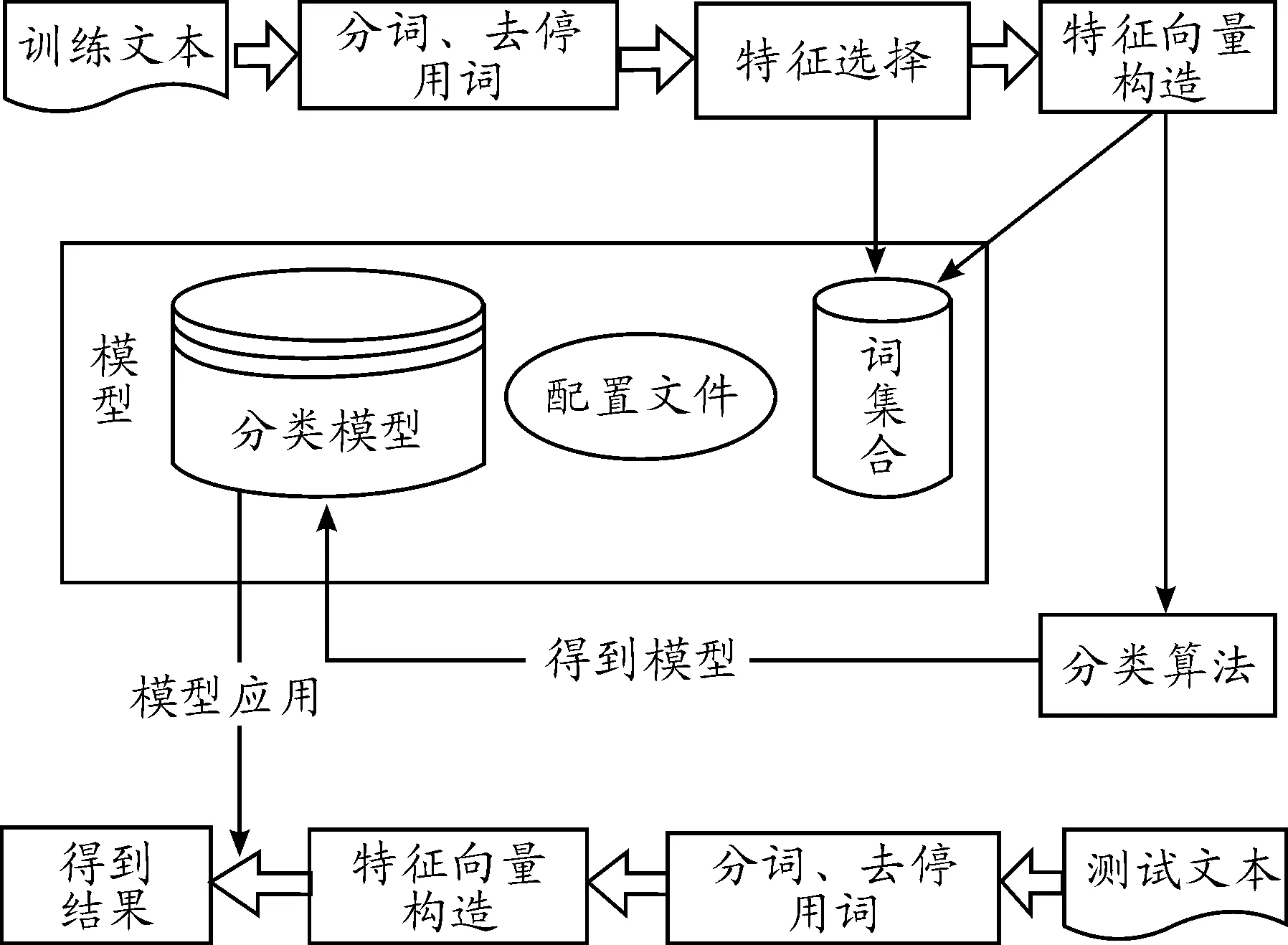
图1 文本分类过程
1.2 中文分词和去除停用词
领域专业文本包含较多的专业词汇,仅使用通用词典进行分词的准确率不高,而专业领域词典的制定确保了其权威性与完整性[7]。因此,应采用专业词典和通用词典相结合的方式进行词切分。本文采用的监理工程专业词典主要来源于手工录入。使用的监理工程专业词典部分词汇包括热轧板带、吊车梁、板坯库、塑钢门窗、啃轨、加热炉、脚螺栓孔、搅拌站等。
停用词的处理就是对分词后的词集合与停用词表进行匹配,匹配成功的词则删除,这些词是一些对分类无意义的虚词。
1.3 特征向量构建
文本分类算法不能直接在原始文本形式上处理。因此,需要在预处理阶段将文本转化为计算机能识别的信息,即对文本进行标识。目前,文本表示模型主要有布尔模型(boolean model)、概率模型(probabilistic model)、向量空间模型(vector space model)[3]。
本文采用最为广泛使用的向量空间模型(VSM),其基本思想是将文本表示成向量空间中的向量,1个文本对应1个向量,文本间的相似性度量用向量之间的夹角余弦表示。文本用特征项集表示为:
d={t1,t2,…,tn}
其中:ti为特征项,1≤i≤n。根据各个特征项ti在文本中的重要程度为其赋予一定权重wk,这时文本表示为
d={t1,w1,t2,w2,…,tn,wn}
1.4 特征选择
特征选择通俗来说就是选取一些最能代表一篇文档的词或短语,它是文本分类中最为重要的一步。目前,较为常用的特征选择算法有文档频率(DF)、TFIDF、互信息(MI)、卡方检验(CHI)、信息增益(IG)等[1]。其中,TFIDF算法是权重计算中经典的算法之一[8],本文采用TFIDF来计算特征权值。TFIDF的基本思想是假设一个词或短语在一篇文档中出现的频率高,而在其他文档中很少出现,则认为该词或短语具有很好的类别区分能力,适用于分类。
常用的TFIDF计算公式如下:
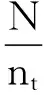
其中:wdt是所计算的特征项的权值;fdt代表词t在文档d中出现的频率,即词频TF;N表示所有的文档数,nt表示出现词t的文档数,log(N/nt)表示逆文档频率IDF。
1.5 特征二次加权
从实际应用出发,将文本分类系统应用于监理工程的文本描述之中。通过查看训练文本集,发现个别词汇在文本分类过程中所起的作用较大,个别术语含义比较贴切,能反映此通知单所代表的问题所在。主要表现在以下2个方面:
① 特定位置。词汇表现文本内容的强弱与词汇在监理通知单中的位置有一定联系。例如,出现在“事由”后面部分的文字,通常具有代表此通知单具体是哪类问题的表象。
② 特定关键词代表问题类别比较明显。对于监理通知单文本,由于数据集的样本数量有限,有些词汇集中出现在某一类别的文本中。根据相关经验,这些词汇很可能与某类别相关度较大,有益于文本分类,例如,“质量”“施工”“进度”等。
本文在使用TFIDF来计算特征权值后,对于集合中包含的这些特定关键词加大权值,从而增大不同类别问题文本的区分度。基于此建立一个关键词表KeyTable,对在特征项集合中出现过的关键词增加权重w′。通过实验发现,当w′=0.5时,实验能取得较好的结果。
关键词表KeyTable中的关键词有“质量”“施工”“进度”“整改”“安装”“措施”等。
2 分类器的构造
从数学角度来说,分类问题可以形式地表示如下:
已知集合:c={y1,y2,y3,…,yn}和I={x1,x2,x3,…,xn},确定映射规则y=f(x),使得任意xi有且仅有一个yi∈c,使得yi=f(xi)成立。
其中,c称为类别集合,类别集合中的每一个元素是一个类别;I称为项集合,项集合中的每一个元素是一个待分类项,f为分类器。
本文采用朴素贝叶斯[4](naive Bayesian)分类算法。与其他算法相比,朴素贝叶斯分类算法较为简单,且分类速度快,分类结果的准确率高。该方法的基本思想是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,条件概率最大的,就认为待分类项属于这个类别。
计算步骤如下:
① 假设x={t1,t2,t3,…,tn}为待分类项,其中ti为特征项;
② 有类别集合c={y1,y2,y3,…,yn};
③ 计算条件概率P(y1|x),P(y2|x),P(y3|x),…,P(yn|x);
④ 如果P(yk|x)=MAX{P(y1|x),P(y2|x),…,P(yn|x)},则x属于yk类。
其中,最为关键的一步是计算各个条件概率,计算过程可分解为以下步骤:
① 统计得到在各类别下各个特征项的条件概率估计值,即
② 假设各个特征项是条件独立的,则根据贝叶斯定理有:
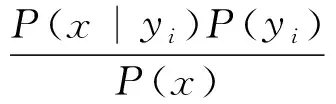
又因为各个特征项是条件独立的,所以有:
P(x|yi)P(yi)=P(t1|yi)P(t2|yi)…

3 实验
3.1 实验数据
本文采用的实验数据由重庆某监理咨询公司提供,包括5个工程项目中的监理通知单,共计 1 579个文本。监理问题分为4大类,质量问题占35.6%,施工问题占40.3%,进度问题占14.9%,其他问题占9.2%。问题分布情况如表1所示。

表1 问题分布情况
3.2 算法流程
输入:待分类文本X,类别集合c={y1,y2,y3,…,yn},监理通知单训练集T。
输出:待分类文本X的类别向量d(x)。
初始化:① 经过文本预处理阶段得到特征项集合x={t1,t2,t3,…,tn};
② 由式(1)计算特征项集合x中每个特征项ti的权值wi,得到d={t1,w1,t2,w2,…,tn,wn};
③ 根据特征项二次加权方法,为出现在KeyTable中的特征项ti的权值wi加上w′;
④ 由步骤③得到新的文本向量d′;
⑤ 将训练集T中所有的文本表示成向量;
⑥ 计算文本x与类别yi的相关度,即采用朴素贝叶斯分类方法计算条件概率P(y1|x),P(y2|x),P(y3|x),…,P(yn|x)
⑦ 比较条件概率的大小P(yk|x)=max{P(y1|x),P(y2|x),…,P(yn|x)},则得到x的类别yk。
3.3 评价指标
实验采用常用的查全率(recall)、查准率(precision)及F值来验证分类器的性能[5]。查全率r=分类器在cj上分类正确的文本数/cj真正包含的文本数;查准率p=分类器在cj上分类正确的文本数/分类器识别为cj类的文本数;F值=2×查全率×查准率/(查准率+查全率)[1]。
3.4 结果分析
为了验证改进后的方法在监理通知单分类上的实用性和有效性,分别进行下面2组实验。
实验一:实用性
一般提取方法(即直接采用TFIDF算法加权)与特征二次加权方法进行对比分析。为保公正性,2种方法都采用同种分词方法,即通用词典结合专业词典的分词方法,分类算法也都采用朴素贝叶斯分类方法。对实验所用的数据按照7∶3的比例划分,分别为测试集和训练集[6]。
采用一般提取方法的实验结果如表2所示,特征二次加权后的实验结果如表3所示。
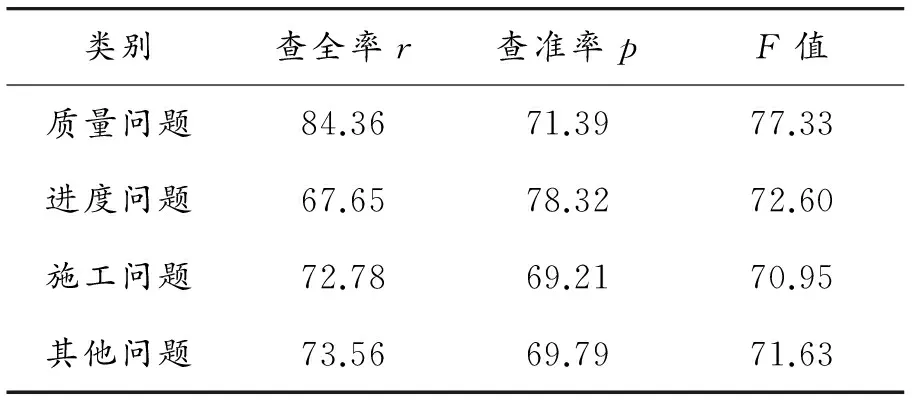
表2 一般提取方法 %
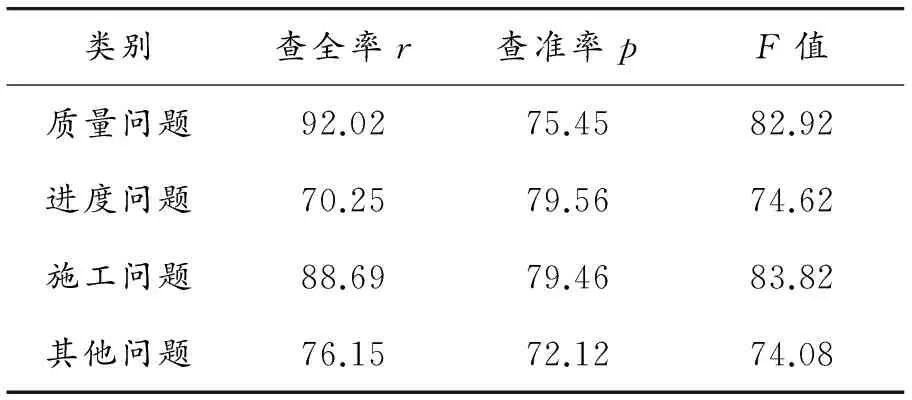
表3 特征二次加权方法 %
通过表2、3的对比可以得知:特征二次加权方法与直接使用TFIDF方法的分类结果在查全率和查准率上均有提高,都达到了预期的结果,有一定的实用价值。其中,质量问题与施工问题这两个类别的改善情况比较乐观,而另外两个类别的效果不是很明显。另外,施工问题的样本数量本身较多,再加上可以罗列的关键词也较多,因此它的准确率提高得相对明显。
实验二:有效性
由实验一可知:改进后的方法对监理通知单文本分类的结果有一定影响,为了降低偶然性,使用改变训练样本与测试样本的比例的方法进行多次实验,从而验证其有效性。用F值作为对比数据。图2为采用不同样本比例所得到的对比结果。

图2 不同训练样本比例2种方法的F值对比
从图2可以看出:改进后的算法F值随训练样本容量的增加呈上升趋势,取值范围为71.5%~84%。总体而言,改进算法相对于未改进前提升了性能,表明改进后的算法是有效的。
以上实验结果说明:结合使用专业词典和特征二次加权的方法在监理通知单文本分类的具体应用方面具有一定的提升作用。但是实验二显示:F值均小于85%,表明该算法仍存在一定的提升空间。
4 结束语
本文在原有文本分类方法上结合监理工程自身的一些特点,提出了一种适用于监理工程的文本分类方法,主要包括2点:① 针对中文分词词典存在未登录词汇,采用通用词典与专业词典相结合的方式,提高了分词的准确性;② 在特征提取的过程中,基于使用TFIDF计算特征权重进行了特征二次加权,增大了类别区分度,使分类结果更准确。经过实验验证,表明改进后的方法在实用性和有效性方面都有所提高,能满足实际需求。
[1] 宋阿羚,刘海峰,刘守生.基于位置及词频信息的优化CHI文本特征选择方法[J].计算机科学与应用,2015,5(9):322-330.
[2] 胡毅.通过数据分析强化监理信息的管理工作[J].逻辑学研究,2005,25(4):271-274.
[3] 徐涛,于洪志,加羊吉.基于改进卡方统计量的藏文文本表示方法[J].计算机工程,2014,40(6):185-189.
[4] 张亚萍,陈得宝,侯俊钦,等.朴素贝叶斯分类算法的改进及应用[J].计算机工程与应用,2011,47(15):134-137.
[5] 樊存佳,汪友生,边航.一种改进的KNN文本分类算法[J].国外电子测量技术,2015,34(12):39-43.
[6] 伍洋,钟鸣,姜艳,等.面向审计领域的短文本分类技术研究[J].微电子学与计算机,2015,32(1):5-10.
[7] 董丽丽,魏胜辉.一种面向机械领域文本分类器的设计[J].微电子学与计算机,2012,29(4):142-145.
[8] 施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009,29(b06):167-170.
[10] ZHANG H,ZHONG g G.Improving short text classification by learning vector representations of both words and hidden topics[J].Knowledge-Based Systems,2016,102:76-86.
(责任编辑杨黎丽)
StudyonTextCategorizationTechnologyforSupervisionEngineering
CHEN Zhuang, YANG Chunyu
(College of Computer Science and Engineering,Chongqing University of Technology, Chongqing 400054, China)
In order to solve the problems of management, such as query, statistics and confusion, a text categorization method is proposed to improve the management efficiency and simplify the working mode. Firstly, in Chinese word processing, supervision of professional dictionary uses generic dictionary with manually constructed combination; and then for feature extraction based on the use of TFIDF, according to certain rules to adjust the weights of features, finally we construct the classifier using Naive Bayesian classification algorithm. The experimental results show that this method can meet the practical application requirements in the classification of supervision notice.
supervision engineering; problem categorization; TFIDF; twice weighting for feature; Naive Bayesian
2017-06-22
重庆市研究生科研创新项目(CYS16222);重庆理工大学研究生创新基金资助项目(YCX2016229)
陈庄(1964—),男,博士,教授,主要从事企业信息化管理、网络与信息安全研究,E-mail:cz@cqut.edu.cn。
陈庄,杨春玉.面向监理工程的文本分类技术研究[J].重庆理工大学学报(自然科学),2017(10):187-191.
formatCHEN Zhuang, YANG Chunyu.Study on Text Categorization Technology for Supervision Engineering[J].Journal of Chongqing University of Technology(Natural Science),2017(10):187-191.
10.3969/j.issn.1674-8425(z).2017.10.030
TP391
A
1674-8425(2017)10-0187-05
猜你喜欢
现代特殊教育(2022年8期)2022-11-23
现代特殊教育(2022年8期)2022-11-23
纺织标准与质量(2022年4期)2022-09-05
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
民族古籍研究(2018年1期)2018-05-21
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
中关村(2014年5期)2014-05-15
中国中医药现代远程教育(2014年16期)2014-03-01
